基于强化学习的随机系统Pareto优化控制方法
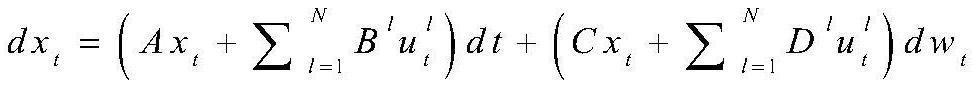
本发明属于线性系统控制,涉及一种随机线性系统多目标多主体最优控制无模型求解方法,特别是一种基于强化学习的随机系统pareto优化控制方法。
背景技术:
1、随着现代工业的大规模发展,实际系统呈现多参与主体、多目标的特征,其各自的优化目标往往存在竞争或合作的博弈关系。如何制定有效的控制策略,既能兼顾各个主体的效益,又能使整体利益达到最大化是当今社会关注的热点问题,pareto合作博弈是使整体效益达到最优,实现有限资源的最大化分配,达到“在不损害他人的情况下,已经不可能使自己变得更好”的一种理想方案。
2、在目前的研究中,解决线性系统pareto最优控制问题都需要求解riccati方程或线性矩阵不等式(lmi)。但是,求解riccati方程或lmi都必须已知系统模型参数,当系统动态模型未知时,该方法无效。
技术实现思路
1、本发明的目的是针对现有的技术存在上述问题,提出了一种基于强化学习的随机系统pareto优化控制方法,将强化学习应用到pareto最优控制上,即使系统模型参数未知也可以在线的给出最优控制,以解决多主体多目标的合作博弈最优问题。
2、本发明的目的可通过下列技术方案来实现:一种基于强化学习的随机系统pareto优化控制方法,包括以下步骤:
3、s1、对多主体、多目标随机系统进行简化和参数化处理:
4、1)、选取多主体、多目标的线性随机系统如下:
5、
6、其中xt∈rn是系统状态向量,是参与者l的控制输入集合,wt是定义在完备滤波概率空间上的一维实数随机变量,为自然滤波,a代表假设未知的系统动态参数矩阵,系数{bl,c,dl}l∈n是具有适当维数的已知矩阵;
7、2)、参与者相互合作设计多目标函数如下:
8、
9、其中,及为数学期望;系统的容许控制集为凸集;
10、3)、将用联合控制率u=col(u1,u2,…,un)∈rm表示,多目标函数通过参数化方法加权求和得到加权和成本函数如下:
11、
12、s2、对系统施加能稳控制输入,记录系统状态以及成本函数反馈值:
13、1)、根据贝尔曼定理以及伊藤定律,强化学习中用于策略评估以及策略提升的方程为:
14、
15、ki+1=-(d′pid+rα)-1(b′pi+d′pic)
16、2)、将初始能稳控制u0=k0x作用于系统,令t=0在时间域[t,t+nδt]上,每隔δt时刻记录一次系统状态以及成本函数数值,其中n>n(n+1)/2,得到原始数据组如下:
17、
18、
19、s3、通过表示去掉重复项,结合最小二乘法给出策略评估实施方法:
20、1)、记向量化算子x=(x1,x 2,...,x n)′,其中x i是方阵x的第i行;
21、定义算子算子其中
22、
23、
24、2)、用表示算子ψ作用下的-表示中的h矩阵,表示算子作用下的h矩阵;
25、获得其中ν=n(n+1)/2;
26、定义有:
27、
28、
29、3)、借助-表示以及向量化算子,策略评估过程被写成:
30、
31、其中q=qα+k′irαki;
32、综上,用-表示方法去除数据矩阵中的重复元素,包括:定义向量化算子;定义h矩阵;利用向量化算子和h矩阵表示矩阵。
33、s4、基于强化学习方法和-表示出在线求解算法;
34、1)、对于对称矩阵pi∈rv,有n(n+1)/2个未知参数,为完成一次策略评估至少在f≥n(n+1)/2个δt区间上取f次数据;
35、2)、根据最小二乘定理策略评估过程对应的拟合方程式写成:
36、
37、其中
38、
39、
40、3)、使用-表示改写s2过程中所得原始数据组,并通过策略评估拟合方程获得更新后的矩阵p0;
41、根据策略提升步骤获得更新后的控制率u1=k1x;
42、将更新后的控制u1=k1x作用于系统令t=t+nδt在时间域[t,t+nδt]上,每隔δt时刻记录一次系统状态以及成本函数数值,然后进行新的策略评估和策略提升;
43、4)、重复以上步骤直到||pi+1-pi||≤ε,
44、记k*=ki+1,将u*=k*xt为最终控制输入,即u*=k*xt为pareto最优控制。
45、在上述的基于强化学习的随机系统pareto优化控制方法中,步骤s1的3)中,判断每个目标函数的凸性并利用加权求和方法将每个目标函数赋予权重,包括:
46、a、判断目标函数参数矩阵的正定性,或零初始条件下目标函数最小值是否为零;
47、b、给出加权和后的目标函数。
48、在上述的基于强化学习的随机系统pareto优化控制方法中,步骤s2的2)中,给定初始能稳控制增益收集系统反馈信息,包括:
49、a、将任意初始能稳控制输入作用于系统;
50、b、记录n组控制输入、系统状态、目标函数数值,将其组成数据矩阵。
51、在上述的基于强化学习的随机系统pareto优化控制方法中,步骤s4中,强化学习方法的具体运行规则,包括:
52、a、给定容许误差;
53、b、判断更新前后矩阵p值误差是否小于给定容许误差;
54、c、若更新前后矩阵p值误差小于容许误差则算法停止,最新更新控制输出为pareto最优控制输出;
55、d、否则将更新后的策略继续施加到系统,收集数据,评估和更新策略,直至误差满足容许误差。
56、综上,策略评估和策略提升,包括:基于策略评估方程以及数据矩阵进行策略评估获得更新后的矩阵p值;根据更新后的p值以及部分已知的系统模型对控制策略进行更新。
57、与现有技术相比,本基于强化学习的随机系统pareto优化控制方法具有以下优点:
58、1、本发明引入参数化方法解决了多目标强化学习问题。通过在线收集的系统状态信息进行策略评估和策略提升,不断优化控制增益。在线求解过程不需要完整的系统模型信息,而且得到的控制策略最终收敛于模型已知情形数值求解出的最优策略。这同时还避免了对复杂的riccati方程进行求解。
59、2、本发明首次将-表示应用到策略迭代算法当中,消除了运算过程中的重复项,使得计算过程更加简洁快速。
技术特征:
1.一种基于强化学习的随机系统pareto优化控制方法,其特征在于,包括以下步骤:
2.如权利要求1所述的基于强化学习的随机系统pareto优化控制方法,其特征在于,步骤s1的3)中,判断每个目标函数的凸性并利用加权求和方法将每个目标函数赋予权重,包括:
3.如权利要求1所述的基于强化学习的随机系统pareto优化控制方法,其特征在于,步骤s2的2)中,给定初始能稳控制增益收集系统反馈信息,包括:
4.如权利要求1所述的基于强化学习的随机系统pareto优化控制方法,其特征在于,步骤s4中,强化学习方法的具体运行规则,包括:
技术总结
本发明提供一种基于强化学习的随机系统Pareto优化控制方法,在保证目标函数为凸函数且容许控制集为凸集的情况下,对目标函数进行加权求和,将多目标优化问题转换为最小化权和后目标函数的问题。将初始能稳控制输入作用于线性随机系统,每隔δt时刻收集一次当前系统状态、控制输入、目标函数数值,共收集N次。根据贝尔曼定理和‑表示技术将所收集数据组成数据矩阵。依托最小二乘法,利用数据矩阵实现强化学习中的策略评估过程,获得更新后矩阵P。根据更新后矩阵P以及部分已知的系统模型,更新控制策略。将更新后的控制策略作用于线性随机系统,再次收集N组数据进行策略评估和策略更新,直至前后两次的控制策略误差满足容许误差。
技术研发人员:蒋秀珊,张天良,梁秀山,陈云,孙宇飞
受保护的技术使用者:中国石油大学(华东)
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!