一种无人驾驶控制方法及系统
本发明涉及无人驾驶,具体涉及一种无人驾驶控制方法及系统。
背景技术:
1、深度强化学习结合了神经网络的强大特征提取和感知能力,以及强化学习的目标学习能力,以获得更大的累积回报为目标,多维度探索动作,并根据一系列动作的选取和状态的呈现形成策略,可以应用在自动驾驶、机器人控制、视频游戏、无人机、交通路径导航和规划等众多领域,成为人工智能发展史上浓墨重彩的一笔。强化学习究其概念与“试错”二字划不开关系,现有技术中结合了深度学习和强化学习的模型,不仅复现性差,而且样本利用率非常低,改进后也始终是脱离不开离散动作空间的问题以及维度灾难的束缚,现实生活中实际的条件大多连续复杂,且面临收敛和调参困难的问题。
技术实现思路
1、(一)发明目的
2、本发明的目的是提供一种能加快算法收敛、提高学习效率的无人驾驶控制方法及系统。
3、(二)技术方案
4、为解决上述问题,本发明的提供了一种无人驾驶控制方法,包括:
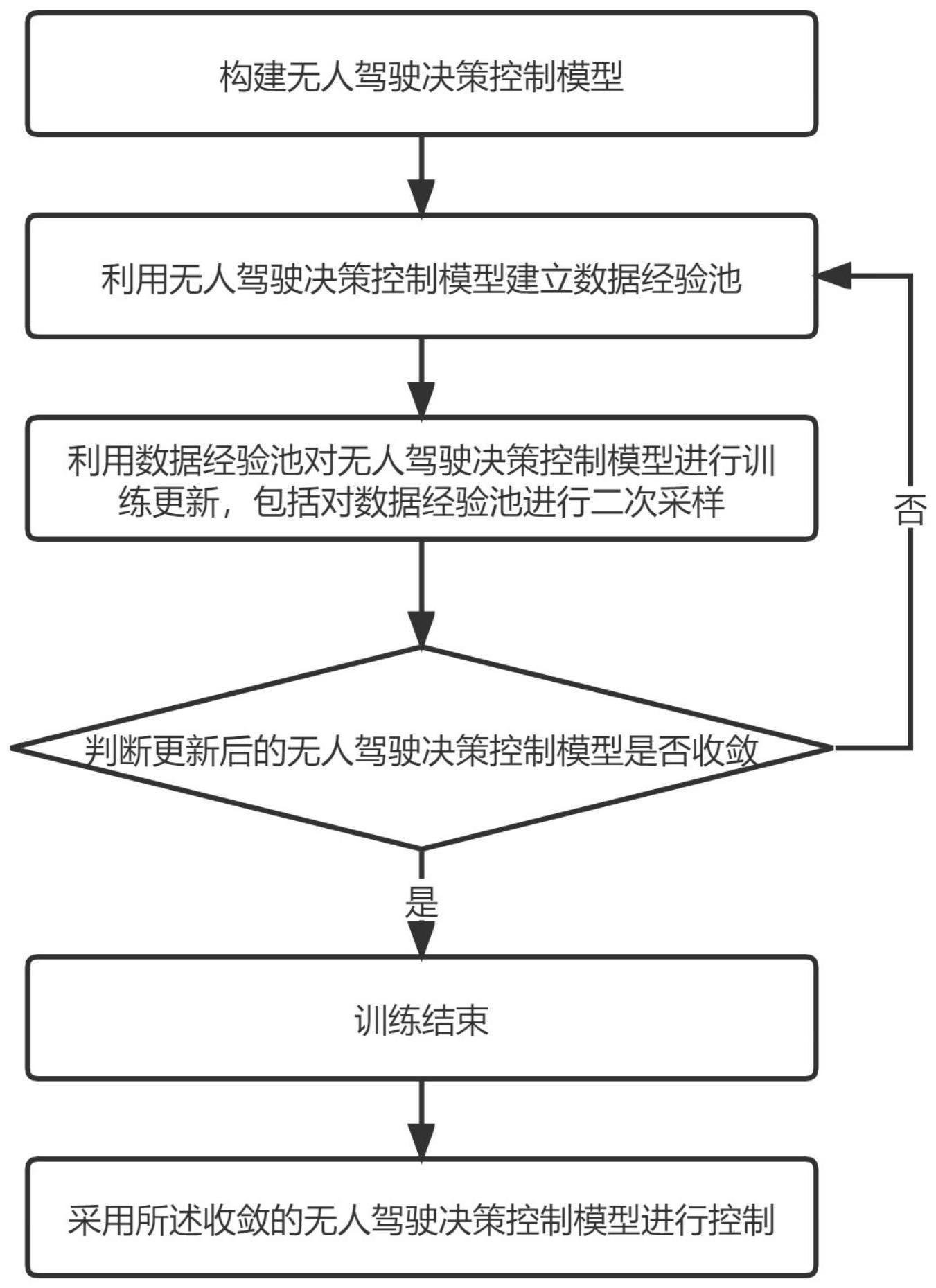
5、构建无人驾驶决策控制模型;
6、利用所述无人驾驶决策控制模型建立第一数据经验池;
7、利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,获得更新后的无人驾驶决策控制模型;所述训练更新包括对所述第一数据经验池进行二次采样;
8、判断所述更新后的无人驾驶决策控制模型是否收敛,若收敛,则训练结束;
9、采用所述收敛的无人驾驶决策控制模型进行控制。
10、优选地,利用所述无人驾驶决策控制模型建立第一数据经验池包括:
11、初始化所述无人驾驶决策控制模型的参数;
12、获取无人驾驶车辆的当前状态,所述当前状态包括环境信息;
13、将所述环境信息输入所述无人驾驶决策控制模型,获得无人驾驶车辆执行驾驶行为的动作;
14、控制所述无人驾驶车辆执行所获得的动作,根据预设的奖励函数,计算获得奖励值;
15、根据预设的状态转移规则和当前状态,获得下一个状态;
16、重复上述步骤获得多组元组信息,所述元组信息包括当前状态、动作、奖励值和下一个状态;获取多个序列,利用所述多个序列建立第一数据经验池,所述序列包括一个周期内的多组元组信息。
17、优选地,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新包括:
18、根据预设的累计回报计算公式,分别计算第一数据经验池中每个序列的累计回报,所述计算公式包括:
19、rt=rt+γrt+1+γ2rt+2+…+γt-t+1rt-1
20、其中,t为一个周期的总时长,rt表示在第t时刻获取到的奖励值,rt+1表示在第t+1时刻获取到的奖励值,rt-1表示在第t-1时刻获取到的奖励值,γ为折扣因子,γ的取值大于0且小于1。
21、优选地,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,还包括:
22、根据预设的第一优先级规则,对第一数据经验池中多个序列进行累积回报的第一优先级排序;
23、所述预设的第一优先级规则包括:根据每个序列对应累积回报的数值进行降序排列,获得第二数据经验池。
24、优选地,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,还包括:
25、对第二数据经验池进行第一采样,获得第一采样序列;
26、将第一采样序列根据预设的第二优先级规则进行第二优先级排序;
27、对进行过第二优先级排序的第一采样序列进行第二采样,获得第二采样序列。
28、优选地,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,还包括:
29、初始化所述无人驾驶决策控制模型的参数,所述参数包括第一参数、第二参数、第三参数和第四参数;
30、将第二采样序列中动作结合熵,获得结合熵的动作;
31、将第二采样序列以及结合熵的动作输入到无人驾驶决策控制模型中,根据预设的第一损失函数计算第一损失值,根据所述第一损失值更新第一参数;
32、根据预设的第二损失函数计算第二损失值,根据所述第二损失值更新第二参数;
33、根据预设的第三损失函数计算第三损失值,根据所述第三损失值更新第三参数;
34、按照预设的更新规则对第四参数进行更新。
35、优选地,所述预设的第一损失函数包括:
36、
37、其中,ψ为第一参数,st表示当前状态,vψ(st)表示当前状态值函数,qθ(st,at)表示软q值函数,πφ(at|st)表示策略函数,表示当前状态st符合当前分布条件下求期望,表示在动作符合当前策略πφ的条件下求期望。
38、优选地,所述预设的第二损失函数包括:
39、
40、其中,θ为第二参数,st表示当前状态,qθ(st,at)表示软q值函数,表示软q值函数估计值,表示当前状态st和动作at符合当前分布条件下求期望。
41、优选地,所述预设的第三损失函数包括:
42、
43、其中,φ为第三参数,ε是一个正态分布,表示当前状态st符合当前分布且εt符合正态分布的条件下求期望,πφ(fφ(εt;st)|st)表示在当前状态st的条件下得到fφ(εt;st),并作为πφ的自变量,qθ(st,fφ(εt;st)表示在st,fφ(εt;st)的条件下计算qθ函数。
44、优选地,一种无人驾驶控制系统,包括:
45、构建模块:构建无人驾驶决策控制模型;
46、建立模块:利用所述无人驾驶决策控制模型建立第一数据经验池;
47、更新模块:利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,获得更新后的无人驾驶决策控制模型;所述训练更新包括对所述第一数据经验池进行二次采样;
48、控制模块:判断所述更新后的无人驾驶决策控制模型是否收敛,若收敛,则训练结束;采用所述收敛的无人驾驶决策控制模型进行控制。
49、(三)有益效果
50、本发明的上述技术方案具有如下有益的技术效果:
51、本发明通过二次采样对构建的无人驾驶决策控制模型进行训练更新,通过对第一数据经验池中的数据的二次采样,实现对数据经验池中的样本数据的充分利用,提高智能体学习效率,加快算法收敛。
技术特征:
1.一种无人驾驶控制方法,其特征在于,包括:
2.根据权利要求1所述无人驾驶控制方法,其特征在于:利用所述无人驾驶决策控制模型建立第一数据经验池包括:
3.根据权利要求1所述无人驾驶控制方法,其特征在于,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新包括:
4.根据权利要求3所述无人驾驶控制方法,其特征在于,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,还包括:
5.根据权利要求4所述无人驾驶控制方法,其特征在于,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,还包括:
6.根据权利要求5所述无人驾驶控制方法,其特征在于,利用所述第一数据经验池对所述无人驾驶决策控制模型进行训练更新,还包括:
7.根据权利要求6所述无人驾驶控制方法,其特征在于,所述预设的第一损失函数包括:
8.根据权利要求6所述无人驾驶控制方法,其特征在于,所述预设的第二损失函数包括:
9.根据权利要求6所述无人驾驶控制方法,其特征在于,所述预设的第三损失函数包括:
10.一种无人驾驶控制系统,其特征在于,包括:
技术总结
本发明涉及一种无人驾驶控制方法和系统,包括:构建无人驾驶决策控制模型;利用所述无人驾驶决策控制模型建立数据经验池;利用所述数据经验池对所述无人驾驶决策控制模型进行训练更新,获得更新后的无人驾驶决策控制模型;所述训练更新包括对所述数据经验池进行二次采样;判断所述更新后的无人驾驶决策控制模型是否收敛,若收敛,则训练结束;采用所述收敛的无人驾驶决策控制模型进行控制。本发明通过二次采样对构建的无人驾驶决策控制模型进行训练更新,通过对数据经验池中的数据的二次采样,实现对数据经验池中的样本数据的充分利用,提高智能体学习效率,加快算法收敛。
技术研发人员:郭瑞,岳天舒,史弘扬
受保护的技术使用者:辽宁工程技术大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!