一种基于强化学习的自动驾驶船舶主动容错路径跟踪控制方法
本发明涉及自动驾驶船舶,具体的,涉及一种基于强化学习的自动驾驶船舶主动容错路径跟踪控制方法。
背景技术:
1、近年来,自动驾驶船舶(asv)由于有希望替代人工操纵船舶执行危险、复杂及昂贵的海上任务(如全球航运、环境监测、资源勘探等)而受到广泛关注。执行任务时,需要asv在复杂环境下自主执行各项基本任务,如任务规划、轨迹跟踪、避碰等。同时,asv需具备足够的安全性和可靠性以避免灾难性后果。在目前的应用中,由于制导、导航和控制技术的进步,asv已经能够在正常条件下执行相应任务。然而,长时间运行时,asv的安全性和可靠性容易受到系统模块故障、系统组件退化或传感器故障等的影响,从而性能下降、系统不稳定,甚至造成不可估量的损失。容错控制(ftc)是一种在遇到传感器故障或系统模块缺陷等问题后恢复系统性能并保持系统安全运行的技术,asv的安全性和可靠性问题激发了对ftc的大量研究。
2、一种ftc方案是直接采用鲁棒控制方法或自适应控制方法。这种方案属于被动ftc,其关键在于控制器对系统不确定性、外部干扰和所有低量级的预期故障保持足够的鲁棒性。因此,在被动ftc中,控制器以单一的结构适应所有情况,包括正常和故障情况。然而在实际应用中,系统故障只是少数情况,这种“以不变应万变”的方式过于保守,且其容错能力也有限,特别是在系统存在不确定性或外部干扰的情况下。考虑到被动ftc的上述局限性,研究人员致力于寻找一种替代方案,该方案能够通过使用故障诊断和识别机制(fdi)监测系统正常状况以主动响应系统故障,也就是主动ftc,主动ftc可以自行重新配置以恢复系统性能并确保系统安全运行。大多数ftc算法,无论被动或主动,都属于基于模型的方法。被动ftc需要知道系统故障的“最坏情况”,以便设计鲁棒控制器。主动ftc虽然比被动ftc更加灵活,但需要故障模型以构建控制重构机制,但是,想要获得asv在不同故障下的所有退化模型几乎是不可能的。因此,为了减少对系统建模的依赖,强化学习(rl)被认为是动态系统ftc的一种有效方法。基于rl的控制方法通过奖励有利输入和惩罚不利输入来最大化奖励函数,整个学习过程使用系统与环境交互产生的数据样本。基于rl的控制方法基本不需要系统模型,因此它被认为是一种无模型方法,这种无模型特性恰好适用于具有显著模型不确定性和传感器故障的asv。基于rl,在各种故障的精确退化模型未知时仍可以得到主动ftc控制律,但如果对控制律的初始值不做假设,则需要纯无模型rl来保证闭环稳定性。将rl应用于ftc问题时,尽管模型信息不再必需,许多现有的基于rl的算法最终还是会学习成为一种最优鲁棒被动控制律,以确保系统在“最坏情况”下的性能,利用rl开发主动ftc控制律仍然是一个悬而未决的问题。
技术实现思路
1、针对现有的asv控制方法无法克服传感器故障和模型不确定的问题,本发明提出一种基于强化学习的asv主动容错路径跟踪控制方法。
2、采用的技术方案及步骤如下:
3、一种基于强化学习的asv主动容错路径跟踪控制方法,所述方法包括步骤如下:
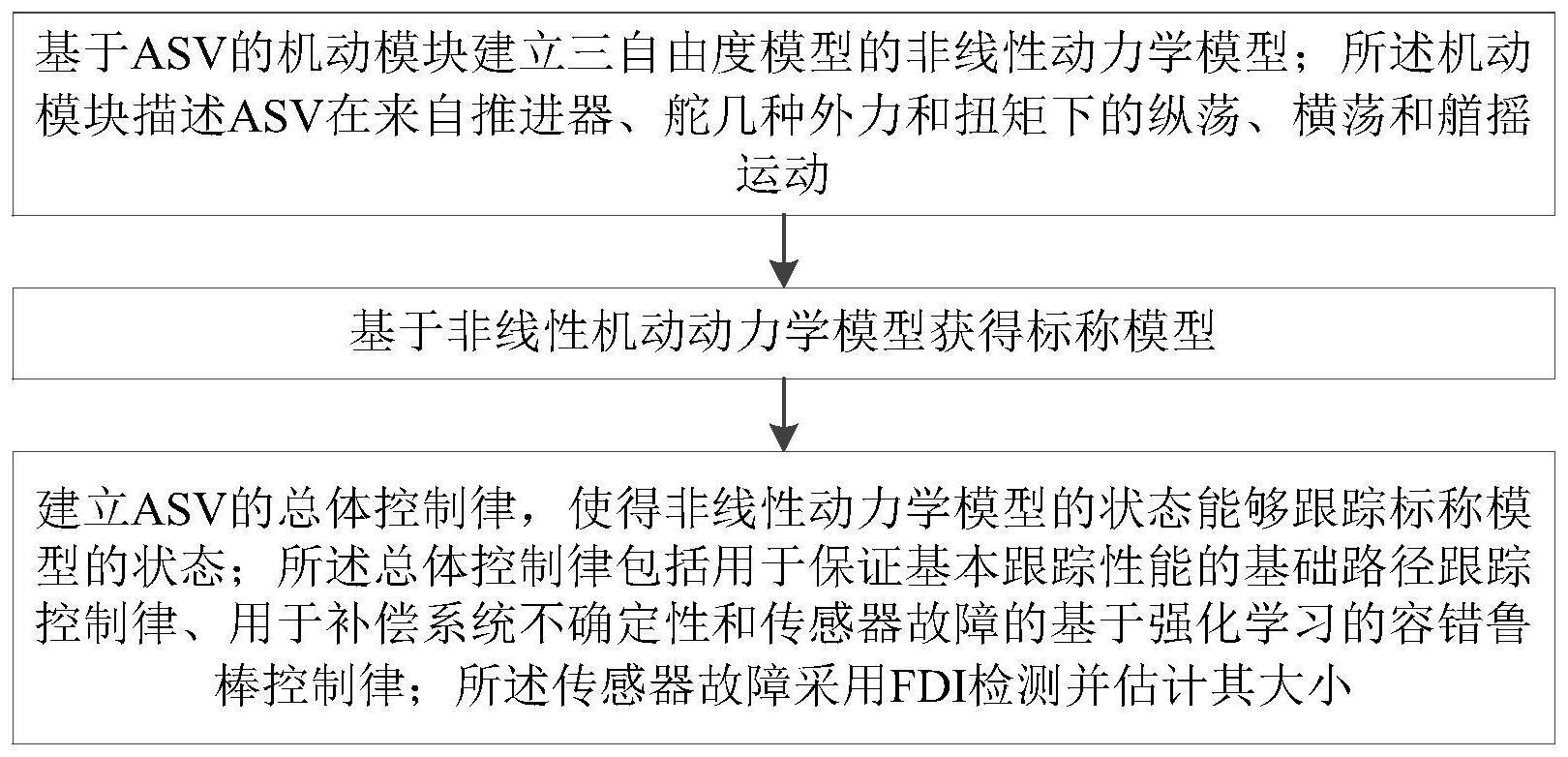
4、基于asv的机动模块建立三自由度非线性动力学模型,所述机动模块描述asv在来自推进器、舵几种外力和扭矩下的纵荡、横荡和艏摇运动;
5、基于非线性动力学模型获得标称模型;
6、建立asv的总体控制律,使得非线性动力学模型的状态能够跟踪标称模型的状态;所述总体控制律包括用于保证基本跟踪的基础路径跟踪控制律、用于补偿系统不确定性和传感器故障的基于强化学习的容错鲁棒控制律;所述传感器故障采用fdi检测并估计其大小。
7、本发明的有益效果如下:
8、利用强化学习的无模型特性,减少容错控制设计对模型信息的依赖;引入基于模型的基础路径跟踪控制律,提高学习效率,降低对传感器故障估计精度的依赖。
技术特征:
1.一种基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述方法包括步骤如下:
2.根据权利要求1所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述非线性动力学模型公式如下:
3.根据权利要求2所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述的标称模型,表达式如下:
4.根据权利要求3所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述的基础路径跟踪控制律采用基于视距方法结合参考路径计算得到,其包括asv的外环速度和航向角组成的制导律、内环跟踪控制律。
5.根据权利要求4所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:采用基于视距方法结合参考路径计算asv的外环速度和航向角组成的制导律,具体如下:
6.根据权利要求5所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:设εu=up-ur,εψ=ψp-ψr,εr=rp-rr,其中,为参考航向角速度,基于标称模型(6)和制导律(9),建立的内环跟踪控制律的公式如下:
7.根据权利要求6所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述的传感器故障包括加速度计故障、陀螺仪故障;其中,加速度计故障,计算如下:
8.根据权利要求7所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述基于强化学习的容错鲁棒控制律,由两个强化学习模块同时作用以补偿asv中的模型不确定性和传感器故障得到;因此,将基于强化学习的容错鲁棒控制律写为:
9.根据权利要求8所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述强化学习使用离散时间步长的数据样本学习控制策略,包括系统输入和状态数据;设样本时间步长固定为δt,为状态观测器在t时刻的估计状态,为故障诊断和估计器在t时刻的估计误差,ul,t是强化学习模块控制在t时刻的控制律,因此,t时刻的状态信号s为:
10.根据权利要求9所述的基于强化学习的asv主动容错路径跟踪控制方法,其特征在于:所述奖励函数的表达式如下:
技术总结
本发明公开了一种基于强化学习的自动驾驶船舶(ASV)主动容错路径跟踪控制方法,如下:基于ASV的机动模块建立三自由度非线性动力学模型;基于非线性动力学模型获得标称模型;建立ASV的总体控制律,使得非线性动力学模型的状态能够跟踪标称模型的状态;所述总体控制律包括用于保证基本跟踪性能的基础路径跟踪控制律、用于补偿系统不确定性和传感器故障的基于强化学习的容错鲁棒控制律;所述传感器故障采用故障诊断和识别机制(FDI)检测并估计其大小。本发明利用强化学习的无模型特性,减少容错控制设计对模型信息的依赖;引入基于模型的基础路径跟踪控制律,提高学习效率,降低对传感器故障估计精度的依赖。
技术研发人员:张清瑞,刘赟韵,于程浩,章登宇
受保护的技术使用者:中山大学·深圳
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!