一种移动机器人动态避障方法、系统、设备及介质
本发明涉及路径规划领域,特别是涉及一种移动机器人动态避障方法、系统、设备及介质。
背景技术:
1、目前,移动机器人被广泛应用于安保巡检、仓储搬运、应急消防等领域。随着应用范围的不断拓展,移动机器人需要在各种不同场景中稳定高效地行走。在面对复杂的动态环境时,设计并规划出一条安全可行的路径,同时具备动态避障能力已成为移动机器人领域的关键研究内容。
2、近年来,深度强化学习由于集成了深度学习在感知上强大的理解能力,以及强化学习的自适应决策能力,在机器人路径规划领域研究中逐步得到应用。lin等提出一种基于深度q学习网络(deep q-learning network,dqn)的转向控制策略,使汽车自动驾驶进行路径跟踪。黄岩松等提出一种基于dqn的agv小车全局路径规划求解模型。chen等人提出一种基于深度强化学习的分布式避障算法以减少机器人完成避障任务抵达目的地的时间;王程博等提出对无人驾驶船舶在未知环境干扰下的深度强化学习避障算法。目前采用传统深度强化学习算法dqn的避障方法因价值函数奖励值易出现高估现象造成其收敛速度慢、稳定性差,降低了机器人动态避障的效果。
技术实现思路
1、本发明的目的是提供一种移动机器人动态避障方法、系统、设备及介质,以解决传统深度强化学习算法dqn的避障方法因价值函数奖励值易出现高估现象导致机器人动态避障的效果差的问题。
2、为实现上述目的,本发明提供了如下方案:
3、一种移动机器人动态避障方法,包括:
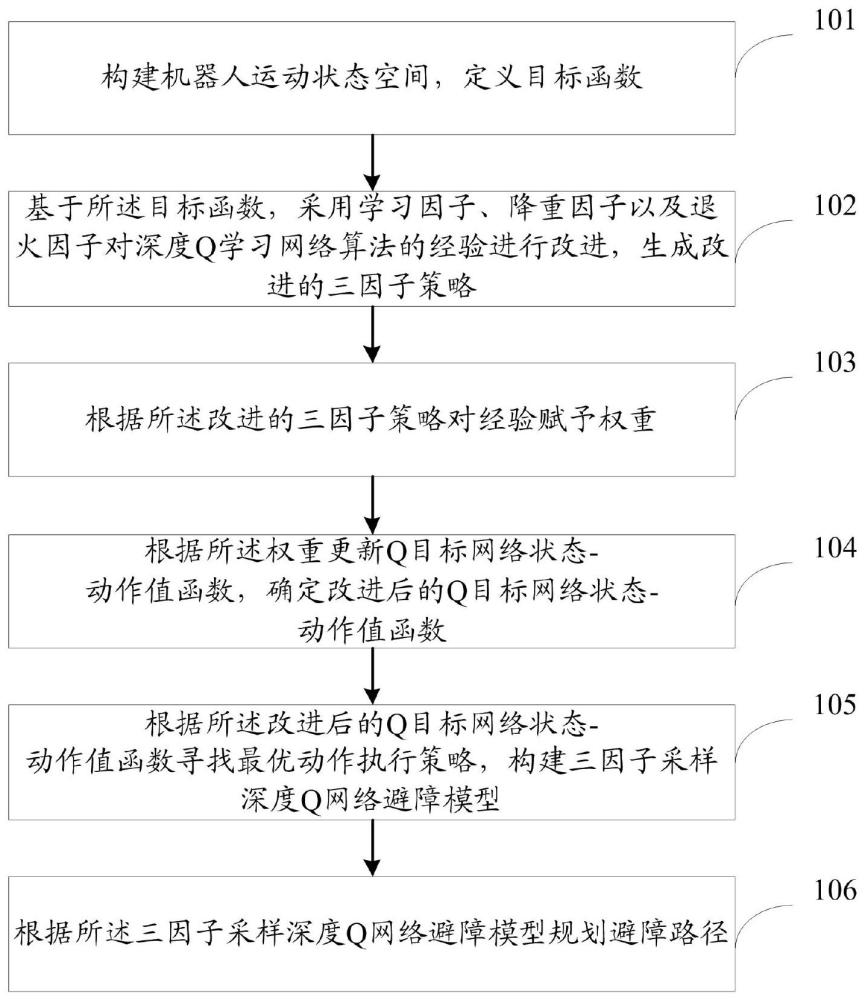
4、构建机器人运动状态空间,定义目标函数;所述目标函数用于预测下一运动状态下的机器人位置信息;
5、基于所述目标函数,采用学习因子、降重因子以及退火因子对深度q学习网络算法的经验进行改进,生成改进的三因子策略;所述学习因子用于控制采样在随机策略和贪婪策略的偏好,以提升成功经验采样概率;所述降重因子用于降低重复采样概率;所述退火因子用于通过调整经验权重降低采样误差;
6、根据所述改进的三因子策略对经验赋予权重;
7、根据所述权重更新q目标网络状态-动作值函数,确定改进后的q目标网络状态-动作值函数;所述q目标网络状态-动作值函数是根据所述目标函数,通过在经验回放池中采集经验确定的;所述经验回放池用于存入五元组,所述五元组包括当前状态、当前动作、当前状态的奖励值、下一状态以及折扣因子;
8、根据所述改进后的q目标网络状态-动作值函数寻找最优动作执行策略,构建三因子采样深度q网络避障模型;
9、根据所述三因子采样深度q网络避障模型规划避障路径。
10、可选的,所述学习因子的取值更新过程为:
11、初始采样时,设置学习因子α=0;α=1或0;
12、将每10次避障过程采集的经验作为一个经验组,并对每个经验组赋予相同的α值;
13、当所述经验组中的避障成功经验占比高于70%时,在采集下一个经验组时保持α值不变;
14、当所述经验组中的避障成功经验占比不高于70%时,改变α值。
15、可选的,加入所述学习因子后,所述经验回收池中第i条经验被采样的概率p(i)为:
16、其中,pi为第i条经验的优先级,所述优先级为时序差分误差tderror由大到小的序号的倒数,tderror=|r+γmaxq(s',a')-q(s,a)|,r为当前状态的奖励值,γ为折扣因子,q(s',a')为q目标网络对应的行动价值,s'为下一状态,a'为下一动作,q(s,a)为q估计网络对应的行动价值,s为当前状态,a为当前动作;pk为第k条经验的优先级,k为经验样本总数。
17、可选的,加入所述降重因子后,所述经验回收池中第i条经验被采样的概率p(i)*为:
18、其中,λ为降重因子,a为每条经验被重复采样的次数。
19、可选的,加入所述退火因子后,所述权重θi为:
20、其中,β为退火因子,n为采样次数,k为经验回收池的经验容量。
21、可选的,所述改进后的q目标网络状态-动作值函数qπ(s',a'θi)为:
22、其中,s为状态集,为当前状态到下一状态的转移概率;e为期望值;为当前状态到结束状态的累计奖励值。
23、可选的,在每个状态下,动作执行策略π(a|s)为:
24、π(a|s)=p*[a=a|s=s];其中,p*为任意动作和状态下的经验采样概率。
25、一种移动机器人动态避障系统,包括:
26、目标函数定义模块,用于构建机器人运动状态空间,定义目标函数;所述目标函数用于预测下一运动状态下的机器人位置信息;
27、改进的三因子策略生成模块,用于基于所述目标函数,采用学习因子、降重因子以及退火因子对深度q学习网络算法的经验进行改进,生成改进的三因子策略;所述学习因子用于控制采样在随机策略和贪婪策略的偏好,以提升成功经验采样概率;所述降重因子用于降低重复采样概率;所述退火因子用于通过调整经验权重降低采样误差;
28、权重确定模块,用于根据所述改进的三因子策略对经验赋予权重;
29、改进后的q目标网络状态-动作值函数确定模块,用于根据所述权重更新q目标网络状态-动作值函数,确定改进后的q目标网络状态-动作值函数;所述q目标网络状态-动作值函数是根据所述目标函数,通过在经验回放池中采集经验确定的;所述经验回放池用于存入五元组,所述五元组包括当前状态、当前动作、当前状态的奖励值、下一状态以及折扣因子;
30、三因子采样深度q网络避障模型构建模块,用于根据所述改进后的q目标网络状态-动作值函数寻找最优动作执行策略,构建三因子采样深度q网络避障模型;
31、避障路径规划模块,用于根据所述三因子采样深度q网络避障模型规划避障路径。
32、一种电子设备,包括存储器及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行上述移动机器人动态避障方法。
33、一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现上述移动机器人动态避障方法。
34、根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明实施例采用学习因子和降重因子提高成功经验的优先级,对回放经验按优先级采样,提高采样效率;然后,通过退火因子减少价值函数奖励值误差,提升反馈奖励值并降低损失值,改善收敛稳定性,从而提高了机器人动态避障的效果。
技术特征:
1.一种移动机器人动态避障方法,其特征在于,包括:
2.根据权利要求1所述的移动机器人动态避障方法,其特征在于,所述学习因子的取值更新过程为:
3.根据权利要求2所述的移动机器人动态避障方法,其特征在于,加入所述学习因子后,所述经验回收池中第i条经验被采样的概率p(i)为:
4.根据权利要求3所述的移动机器人动态避障方法,其特征在于,加入所述降重因子后,所述经验回收池中第i条经验被采样的概率p(i)*为:
5.根据权利要求4所述的移动机器人动态避障方法,其特征在于,加入所述退火因子后,所述权重θi为:
6.根据权利要求5所述的移动机器人动态避障方法,其特征在于,所述改进后的q目标网络状态-动作值函数qπ(s',a'|θi)为:
7.根据权利要求6所述的移动机器人动态避障方法,其特征在于,在每个状态下,动作执行策略π(a|s)为:
8.一种移动机器人动态避障系统,其特征在于,包括:
9.一种电子设备,其特征在于,包括存储器及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行如权利要求1-7中任一项所述的移动机器人动态避障方法。
10.一种计算机可读存储介质,其特征在于,其存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1-7中任一项所述的移动机器人动态避障方法。
技术总结
本发明提供了一种移动机器人动态避障方法、系统、设备及介质,涉及路径规划领域,方法包括:构建机器人运动状态空间,定义目标函数;基于所述目标函数,采用学习因子、降重因子以及退火因子对深度Q学习网络算法的经验进行改进,生成改进的三因子策略;根据所述改进的三因子策略对经验赋予权重;根据所述权重更新Q目标网络状态‑动作值函数,确定改进后的Q目标网络状态‑动作值函数;根据所述改进后的Q目标网络状态‑动作值函数寻找最优动作执行策略,构建三因子采样深度Q网络避障模型;根据所述三因子采样深度Q网络避障模型规划避障路径。本发明能够提高机器人动态避障效果。
技术研发人员:王宇钢,张阴硕
受保护的技术使用者:辽宁工业大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!