一种分布式搜索方法与流程
本发明涉及搜索领域,尤其涉及一种分布式搜索方法。
背景技术:
目前,基于数据库的全文检索,是在数据库上增加了一个全文检索的模块,该模块功能和数据库集成在一起,占用数据库服务器的资源。在查询压力比较大的情形下,经常导致数据库服务器负载过高,不能向应用提供正常服务。
技术实现要素:
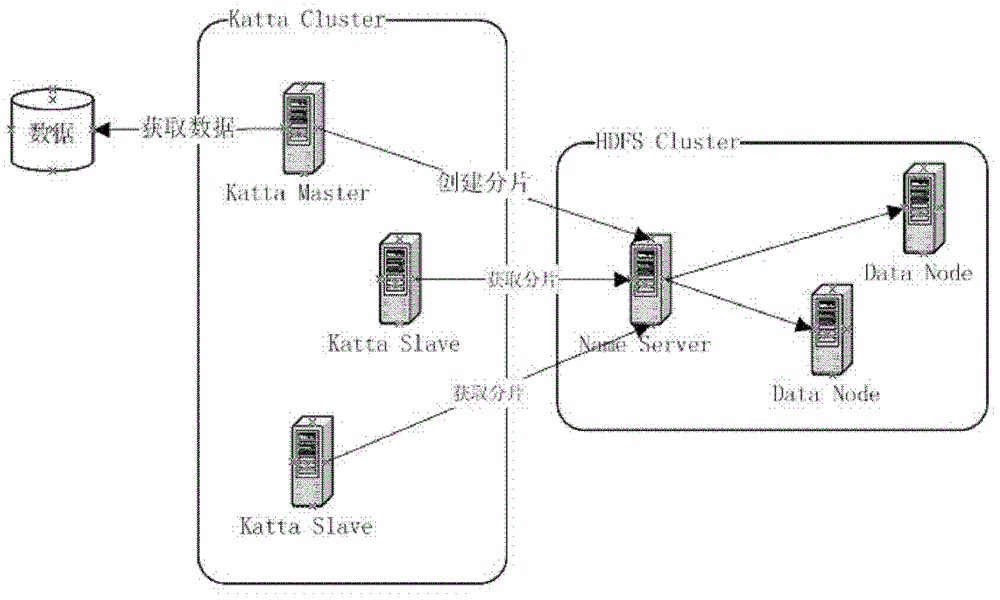
为了解决上述技术问题,本发明的目的在于提供一种基于文件系统的全文检索,把全文检索的功能独立出来,成为一个单独的服务,这样可以和数据库分开部署,从而减轻数据库的压力,同时增强检索服务的性能的分布式搜索的架构。本发明的完整技术方案是,一种分布式搜索方法,包括一个搜索引擎集群,所述搜索引擎集群位于数据库之前、应用之后,所述搜索引擎集群包括Zookeeper、Katta、HDFS、Solr;Solr用于创建索引:通过连接到数据库,获取数据行,创建索引分片;HDFS用于存储索引:通过其中的Hadoop控制台,存储分片到HDFS上;Katta用于部署、更新以及查询索引:通过Katta控制台,发布索引分片,Katta自动部署分片到索引节点;未满的分片需要继续填充索引文档,然后更新到已发布的节点上;应用发出的查询,由Katta客户端处理:首先向索引节点发出获取索引ID的请求,进行排序等处理,然后根据ID发出获取具体的文档;Zookeeper作为分布式协调器的一部分。所述索引分片的大小小于等于10G或小于等于1500万行。由上可见,本发明与现在技术相比有如下有益效果:本发明提供一种基 于文件系统的全文检索,把全文检索的功能独立出来,成为一个单独的服务,这样可以和数据库分开部署,从而减轻数据库的压力,同时增强检索服务的性能,数据库压力降低,整体性能得到提升,同时可扩展性强。附图说明此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,并不构成对本发明的不当限定,在附图中:图1为本发明逻辑原理图;图2为本发明的创建索引的示意图;图3为本发明的查询处理的示意图;图4为本发明的实施例1原理示意图。具体实施方式下面将结合附图以及具体实施例来详细说明本发明,在此本发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。实施例1:本实施例一种分布式搜索方法,如图所示,在数据库之前,应用之后,增加三台服务器,作为搜索引擎集群。包括一个搜索引擎集群,所述搜索引擎集群采用Zookeeper、Katta、HDFS、Solr为基础架构;Solr用于创建索引:通过连接到数据库,获取数据行,创建索引分片;HDFS用于存储索引:通过其中的Hadoop控制台,存储分片到HDFS上;Katta用于部署、更新以及查询索引:通过Katta控制台,发布索引分片,Katta自动部署分片到索引节点;未满的分片需要继续填充索引文档,然后更新到已发布的节点上;应用发出的查询,由Katta客户端处理:首先向索引节点发出获取索引ID的请求,进行排序等处理,然后根据ID发出获取具体的文档;Zookeeper作为分布式协调器的一部分。每台服务器至少充当三种角色:1.HDFS服务器,作为分布式存储系统的一部分2.ZkServer服务器,作为分布式协调器的一部分3.Katta查询处理服务器,作为分布式搜索服务的一部分其中MasterNode服务器作为主控服务器,处理创建索引的工作,同时作为查询服务器,接收所有的查询请求,并且转发给后续的SlaveNode服务器;SlaveNode服务器主要作为查询处理服务器,真正处理查询请求,返回查询结果。由上可见,本发明提供一种基于文件系统的全文检索,把全文检索的功能独立出来,成为一个单独的服务,这样可以和数据库分开部署,从而减轻数据库的压力,同时增强检索服务的性能,数据库压力降低,整体性能得到提升,同时可扩展性强。以上对本发明实施例所提供的技术方案进行了详细介绍,本文中应用了具体个例对本发明实施例的原理以及实施方式进行了阐述,以上实施例的说明只适用于帮助理解本发明实施例的原理;同时,对于本领域的一般技术人员,依据本发明实施例,在具体实施方式以及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1