通过基于核的学习对社交强度进行建模的制作方法
本发明涉及对社交强度进行建模,尤其涉及通过基于核的学习对社交强度进行建模。
背景技术:
社交网络挖掘已经在工业界和学术界吸引了大量的兴趣。大多数传统的研究着重于检测人和人之间的二元关系连结(例如,朋友或不是朋友)。这种粗糙的指标并不能很精确地给出关于人和人之间社交关系强度的洞察。最近的研究已经试图解决对社交关系的强度进行建模的问题,而非简单的二元联接。推断精确的社交强度可促进各种各样的应用,包括朋友联接预测、项目推荐、社交搜索等等。
目前,已经对社交媒体社区中用户的社交强度建模(SSM)进行了一定的研究。比如,以Flickr(其是最流行的在线照片共享站点之一)作为社交媒体平台为例,Flickr包括丰富的用户生成的内容,例如所共享的照片、用户注释的标签、评论等等。类似于其他社交联网站点(例如,Facebook和LinkedIn),每个Flickr用户可将其他用户添加到他自己的联系人列表来表明他们之间的朋友关系。用户也能创建并加入感兴趣的分组,在这些分组中,用户相互之间共享照片以及评论。除了用户之间显式的相互联接,所上传的照片以及它们相关联的元数据(例如,标签、评论等等)也可被用来推断用户之间的隐含关系。
然而,在先前的研究中,Flickr数据挖掘主要关注的是仅针对图像或仅针对标签的分析,其他的丰富元数据并没有被很好地使用。目前,利用Flickr之类的社交联网站点上可用的多模态信息对社交强度建模依旧是个挑战。
技术实现要素:
提供本发明内容是为了介绍将在以下具体实施方式中进一步描述的频繁对象挖掘的简化概念。本发明内容并不旨在标识所要求保护的主题的必要特征,也不旨在用于帮助确定所要求保护的主题的范围。
本发明提出了新的用于社交强度建模的两阶段基于核的学习框架,其通过优化地组合多个核来有效地集成异类(heterogeneous)数据,并通过基于核的排序学习(learning to rank)方式来排序学习社交强度。
本发明提出了一种用于测量社交网站内用户相似性的方法。首先,计算社交网站上可用的各个模态中用于测量用户相似性的核。接着,采用基于核的学习技术将计算出的核进行组合以得出最优核。
本发明还提出了一种用于对社交网站内用户的社交强度进行建模的方法。首先,将社交网站上可用的各个模态中用于测量用户相似性的核进行组合以得出最优核。接着,基于该最优核,导出排序学习框架来推断用户之间的社交强度。
通过阅读下面的详细描述并参考相关联的附图,这些及其他特点和优点将变得显而易见。可以理解,前述一般描述和以下的详细描述都是说明性的,并且不限制所要求保护的各方面。
附图说明
本发明上述的以及其他的特征、性质和优势将通过下面结合附图和实施例的详细描述而变得更加明显,在附图中,相同的附图标记始终表示相同的特征,其中:
图1示出了根据本发明的各实施例的框架。
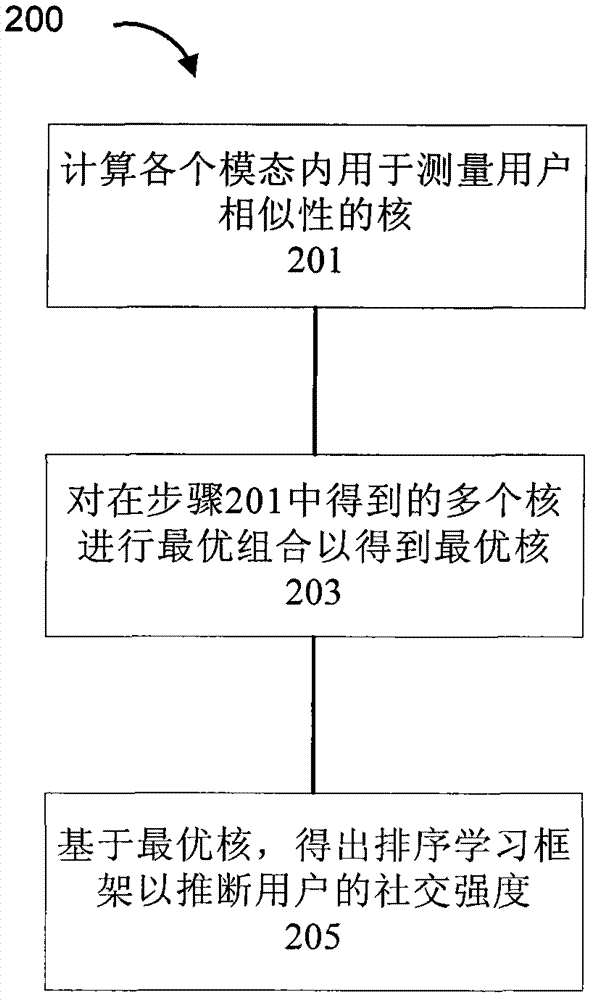
图2示出了根据本发明的各实施例的用于对社交强度进行建模的方法的流程图。
具体实施方式
图1显示了根据本发明的各实施例的基于核的排序学习框架。在第一学习阶段,本发明基于核目标对齐(KTA)原理,通过学习最优组合权重来组合多个邻近(proximity)图。在第二阶段,本发明使用从第一阶段学习的最优核来得出基于核的排序学习方法,以对社交强度进行建模。例如,图1的第一个框(最左面的框)显示了与用户相关联的数据,基于该数据,在图1的第二个框内构建了三幅图(出于说明目的,仅仅呈现了三种类型的图)。在图1的第三个框中,首先,通过将文本图和可视图的组合与朋友图最大地对齐来学习权重θ,接着,采用具有逻辑亏损(logistic loss)的排序学习框架来估计社交强度。所学习的社交强度能在第四框中示出的各种应用中使用。
本发明所提出的两阶段学习方法能够通过研究多模态异类数据以系统和全面的方式来对用户的社交强度进行建模。需要注意的是,虽然本发明将Flickr作为社交媒体社区的一个示例(因为Flickr打开了公共通道使得能够访问它的丰富上下文),本发明所提出的基于学习的方法能被应用到任何类型的社区,诸如Facebook和LinkedIn,在这些社区中,用户也与丰富多模态元数据相关联。
社交强度建模的问题定义
首先,给出社交强度建模的问题定义。表1列出了关键标记。需要注意的是,虽然采用Flickr作为示例社交社区,但是完全可以理解可以采用其他类型的社交社区。
表1
一般地,给定Flickr用户的集合,社交强度建模问题的目标是要学习函数使得f(ui,uj)测量用户ui和用户uj之间的社交关系强度。
以上社交强度建模问题中的一个基本的元素是Flickr用户每个Flickr用户被建模为三维元组其中是由用户ui上传的Flickr照片的集合,是出现在用户ui的联系人列表中的用户的集合,是用户ui所参加的感兴趣的分组的集合。
和表明Flickr用户显式的社交关系和组织,而可用于发现用户之间的某些隐含关系。联系人列表表明用户之间的二元社交连结。注意的是,由给出的朋友关系通常是不对称的,但是这可由本发明的排序学习框架来自然地处理。
集合是用户ui所参加的感兴趣的分组。对于每个其是由经注册的Flickr用户创建并自组织的。属于同一分组的用户倾向于分享同样感兴趣的照片。
图像对于寻找隐含的社交关系是有用的,这是因为它们包括丰富上下文信息,这些上下文信息表达用户之间的兴趣以及社交行为。在本发明中,Flickr图像被定义为5维元组其中是具有某个固定长度的特征表示的可视内容,dx是可视描述符的尺寸;是表示与X相关联的标签的向量,di是标签词表(tag vocabulary)的大小;D是X创建的日期;是P所创建的位置;是P的评论的集合,其中第一个分量U是发布评论的用户,而第二个分量C是评论的内容。
除了上传的照片X之外的丰富上下文信息对不同用户之间的社交行为进行编码。在本发明中,结合这些丰富上下文信息来对社交强度进行建模。
社交强度建模
对于社交强度建模而言,第一个挑战是如何有效地组合与用户相关联的异类数据。本发明计算不同模态下的相似性K,其类似于核机器(kernel machine)(诸如支持向量机)中的核函数。因此,这启示了可以采用多核学习(multiple kernel learning,MKL)方案来结合多个模态,本发明由此采用最新的MKL算法来对每个模态进行加权。
其次,由于社交强度实质上是对一对人之间的亲密程度进行排序,因此,本发明采用成对(pair-wise)排序学习框架用于进一步基于第一阶段中学习的K来调整社交强度。相比于衍生(generative)模型,这种有辨别力(discriminative)的框架通常能产生更好的普遍化能力。此外,这既避免了潜在的变量假设又避免了衍生模型函数的参数形式的假设,使得学习更加紧凑和精确。
接下来,本发明首先讨论如何通过对不同模态的Flickr数据定义各种核函数{K}来测量Flickr用户的相似性。接着,本发明讨论一种核学习技术,用于根据核目标对齐原理来确定多个核的最优组合权重。最后,基于学习到的核,本发明将社交强度建模问题阐明为成对基于核的排序学习任务,其能以迭代的方式如输入向量机(import vector machine)那样被高效地解决。
现在参照图2,描述了用于对社交强度进行建模的方法200。在步骤201,计算各个模态内用于测量用户相似性的核。
一般地,集合S上的核实质上定义测量内的数据实例之间相似性的方式。本发明提出了在不同的模态内用于测量Flickr用户相似性的候选核函数,这些候选核函数将进一步被其他核方法用以推断社交强度。
可视空间内的用户相似性
对于可视特征表示,本发明采用(可视)词袋(BoW,bag-of-word)模型。首先,提取每个图像的范围恒定特征转换(SIFT)的本地描述符。所有这些描述符通过K-方式(K-means)群集过程被量化到dx组中。给定一图像,将它的每个SIFT描述符分配给最接近的群集。接着,每个图像被转换为固定长度的特征向量dx是可视词表(visual vocabulary)的大小。该向量的第i个分量计算分配给群集i的SIFT描述符的频率。通过以下高斯核来测量图像xi和xj之间的可视相似性:
其中,σ是核参数。对于特定用户u,本发明使用属于用户u的图像的质心来表示在可视空间内的该用户,即:
其中,|u|是属于用户u的图像的数量,xi是由用户u上传的一幅图像。由此,可视空间内用户ui和用户uj之间的相似性K1(ui,uj)为:
由于获得最优带宽参数σ是困难的,本发明按经验将其设定为平均欧几里德距离。
文本空间内的用户相似性
每幅被上传的照片可以与用户提供的一组标签相关联。本发明采用词袋模型来表示用户的文本信息。本发明收集所有标签并构建具有大小dt的标签词表。通过传统的tf-idf加权方法,用户的标签被转换为中的特征向量。在此,逆文档频率(inverse document frequency)是包括该标签的用户的数量。通过这种方式,用户ui可由向量来表示。本发明使用标准化的线性核来测量文本空间内的用户相似性,其被广泛地用于文本分类:
相比于可视核K1,基于标签的核K2携带更多的语义信息。
通过相互评论的用户相似性
用户之间的交互反映出用户彼此之间的社交联系。例如,如果两个用户经常对对方的照片发表评论,则很有可能在他们之间存在强烈的社交连结。一般而言,在现实世界中是朋友的人将更加频繁地通信。本发明可收集用户之间的相互评论信息来构造对称链图,其中,每个顶点表示一用户,每个边权重是两个用户之间评论的数量。由此,得到:
K3(ui,uj):=ui和uj之间评论的数量。
当i=j时,核值是用户ui向他自己发表评论的频率。
通过共同兴趣分组的用户相似性
Flickr用户可创建并参加Flickr兴趣分组,其包括共享相同的兴趣或喜欢某些风格的照片的用户的集合。这样的兴趣分组可帮助用户找到他们所感兴趣的人或照片。直观地,之间存在强烈社交联系的人更加有可能参加相同的兴趣分组,因为他们可相互影响并分享类似的兴趣。因此,使用共同兴趣分组的数量来测量人们之间的相似性:
K4(ui,uj):=ui和uj都参加的分组的数量。
当i=j时,核值是用户ui所参加的分组的数量。
通过共有朋友的用户相似性
每个Flickr用户都具有联系人列表,其可被视为“朋友”。当两个用户共享多个共同的朋友时,可以合理地推断他们之间具有强烈的社交联系。自然地,将该数量计算为核值以量化该模态:
K5(ui,uj):=既属于ui又属于uj的朋友的数量。
通过地理标签的用户相似性
社交媒体站点内的图像通常与地理标签相关联,其指示照片被拍摄处的维度和经度参数。如果两个用户经常到相同的地方旅行,那么可以合理地得出他们之间是相似的(因为他们愿意到相同的地方旅行)。类似于文本空间中的表示,使用地理标签袋(bag-of-geotag)来计算用户之间的相似性:
K6(ui,uj):=既是ui拍摄照片也是uj拍摄照片的地方的数量。
在K6的对角处,值是用户已经去过的地方的数量。原始地理标签具有经度和维度对的形式,本发明通过将整个地球划分成小块来将它离散。每个位置由其对应的小块来表示。
通过最喜爱的照片的用户相似性
Flickr所提供的一个重要的功能是用户能够标记他们自己最喜爱的照片。假设最喜爱的照片的数量与社交强度相关,得到:
K7(ui,uj):=既是ui最喜爱的又是uj最喜爱的照片的数量。
该假设下的理论基础是,喜欢相同照片的用户有可能是朋友。虽然这在现实世界中并不是真的。但是,通过KTA算法,学习这些核的权重,提供了关于哪些模态实际上能为检测多媒体搜索社区内的社交强度提供信息的洞察。
相似性测量K1~7并不必需是正半定(positive semi-definite,p.s.d)。本发明通过将适当的单位矩阵添加到对应的相似性矩阵来使得这些相似性测量成为p.s.d以构建核。
在步骤203,对在步骤201中得到的多个核进行最优组合以得到最优核。
以上,已经定义了不同模态内用于相似性测量的核函数。接下来,将讨论如何找到将这些模态进行组合的最优方式,这对社交强度建模而言是关键的一步。特别地,所需要的是确定多个核的线性组合以融合所有模态来测量相似性,由权重向量参数化为:
其中,Kt是在用户的第t个视图下定义的核,Nk是模态(或视图)的数量。
一种方式是手动地设定不同模态的权重,然而,这在很大程度上依赖于域知识并且不能找到最优组合。本发明阐述一种基于核的学习技术,以根据KTA原理找到多个核的最优组合。
尤其,给定目标矩阵Y其对用户之间现有的已知关系进行编码(通过显式朋友列表),采用如下定义的核对齐(kernel alignment)来测量核K相对于目标矩阵Y的质量:
让K,是两个核矩阵,使得||K||F≠0并且||Y||F≠0,那么,K和Y之间的对齐被定义为,
注意的是,核矩阵一般需要被居中(centered)这个居中步骤可被计算为:
给定由矩阵Y表示的目标图,将对K的对齐ρ最大化来解核。从Flickr平台观察到Y。例如,在朋友预测任务中,Y是从每个Flickr用户的简档中构造的共有联系人图。假设目标核矩阵具有与等式(1)等同的形式,其中0≤θt≤1,∑t||θt||2=1。由此,目标变量从减少到
最优化问题的解θ*被给为θ*=θ*/||θ*||,其中θ*是以下二次程序的解:
其中,a是向量M是矩阵对于k,
由此可见,能够确保最优解被高效地计算。
在步骤205,基于在步骤203得到的最优核,得出排序学习框架以推断用户的社交强度。
在具有等式(1)形式的相似性测量接下来考虑有辨别力的模型来估计两个用户之间的社交强度。让y是值为{1,-1}的指示两个用户之间是否存在联系的潜在变量。社交联系强度推断旨在估计概率P(yij=1|ui,uj)。为了该目的,本发明基于训练对来构建模型。Flickr用户之间的联系来自Flickr用户简档中的共有联系人即,当且仅当uj在ui的联系人列表中时,yij=1。
首先,引入由参数化的线性模型f(ui,uj)=wTΦ(ui,uj)来预测ui和uj之间的社交强度,其中函数将用户对映射到某个特定视图或模态下的特征表示。因此,通过最小化正则化亏损来解w:
其中,λ是控制正则化和预测亏损之间平衡的超参数。函数测量预测的亏损。本发明采用逻辑亏损而非传统的基于SVM模型的铰链亏损(hinge loss),因为其允许预测概率的自然估计。由此,本发明能通过以下公式来估计两个用户的社交强度:
为了便于讨论,用表示一对用户。根据陈述者理论(representor theorem),以上问题的解能被表示为:f(v)=∑jαjK(v,vj),其中α是训练对的权重,vj:=[uj1,uj2]是经排序的“支持”用户对。由此,等同物可被写为:
其中,Np是训练对的数量,是从核函数(即,在用户对上定义的)中求出的核矩阵。两个对vi和vj的核被计算为:
其中,对用户对采用成对核,并且具有等式(1)的形式。等同物能和输入向量机那样被高效地求解。
训练对选择
构建训练对对于效力和效率而言是重要的。当用户uj出现在用户ui的联系人列表时,很有可能在现实生活中uj是ui的朋友或者由uj上传的内容是ui所感兴趣的。因此,在训练模型时,可以将(ui,uj)直接视为正对(positive pair)。然而,负对(negative pair)也是重要的。常见的是,用户ui没有注意到他的朋友uj已经注册,因此,ui没有将uj添加到他的联系人列表中。在这种情况下,将(ui,uj)视为负训练对,所学习的模型将不能有效地预测这种潜在的朋友。实际上,本发明重要的应用之一就是要揭示这种潜在的朋友,这要求对采样负对的详细统计。
此外,存在用于训练对采样的计算必要性。假设,每个用户平均具有Np个朋友,那么将总共具有O(Np×(Nu-Np)×Nu)训练对。这样大的范围使得难以直接应用成对排序学习算法。另一方面,某些训练对对学习模型而言不是有用的。因此,本发明提出用于采样训练对的两阶段方案。
首先,选择最不可能是朋友的用户对来构造负训练对。为此,对于每个用户ui,以升序对值Kt(ui,uj)进行排序,其中与ui具有小的相似性的用户从ui的潜在朋友列表中排除。由于具有对用户定义的多个Nk核,不清楚采用哪个核来用于采样目的。在这里,本发明使用较为保守的方案,即,选择所有相似性测量Kt下出现在用户ui的前N(N>Ne)个用户中的前Ne个用户。对于构造正训练对,在根据联系人列表滤出朋友后使用K3,即,计算相互评论的核,来将与ui最频繁通信的用户确定为正对。
第二,在训练阶段期间采用IVM中的活动样本选择方案。由于许多样本并不有助于产生有用的解,本发明活动地在每个迭代处选择一对来扩展支持向量集合。通过这种方式,学习能被显著地加速,同时所学习的模型的效率也能被保存。
综上,本发明所提出的框架依赖来自各种模态的一系列相似性测量,而不需要关于如何得到这些测量的任何假设。因此,对于本发明的任何扩展仅仅需要设计新的特征或添加新的因素来实例化这些测量。
应用
本发明所提出的社交强度建模能应用到各种应用中,包括但不限于,朋友预测,协作推荐,以用户为目标的广告,用户搜索和浏览,社区可视化等等。
朋友预测:在Flickr中,每个用户能添加其他用户到他/她的联系人列表中。然而,当用户在现实生活中是互相认识的或者他们对某些风格的照片都具有非常类似的兴趣,那么由于有限的搜索和浏览功能,他们之间的朋友链接没有显式地存在。本发明的框架能通过利用各种内容和上下文信息来预测Flickr用户之间的隐含朋友链接。
协作推荐:通过向用户推荐适当的对象(例如,感兴趣的分组和最喜爱的照片)对于提升用户体验而言是非常有用的。这样的项目推荐任务可从经建模的强度中受益,因为这些项的流行度是与人们之间的社交强度相关的。可基于所学习的社交强度图来设计亲密度传播算法。
以用户为目标的广告:类似于推荐,本发明能向包括相似用户的所连接的组件提供以用户为目标的广告,使得通过在相似用户之间的传播,广告与用户兴趣相关。
用户搜索和浏览:根据与发起查询的用户之间的社交强度,可以将用户搜索结果排序。用户则更加可能找到他所感兴趣的目标。这种技术能弥补匹配查询的提供信息的单词的缺失。由此,可以期望的是,基于传统简单关键词匹配的结果能被显著地提升。
社区可视化:可通过根据所估计的关系强度来调整链接或对链接打上阴影来提升可视化人们的社交网络的应用。
上述实施例是提供给熟悉本领域内的人员来实现或使用本发明的,熟悉本领域的人员能对上述实施例做出种种修改或变化而不脱离本发明的发明思想,因而本发明的保护范围并不被上述实施例所限,而应该是符合权利要求书提到的创新性特征的最大范围。
- 还没有人留言评论。精彩留言会获得点赞!