对实体关系模式进行聚类、提取的方法和设备与流程
本申请总体上涉及数据处理和数据挖掘的领域,尤其涉及对实体之间的实体关系模式进行聚类、提取的方法和设备。
背景技术:
随着信息技术的发展,产生了海量的并且仍在不断增长的信息,例如新闻、博客、微博中的信息等。所产生的信息中包含很多实体以及各个实体之间的实体关系模式。如果能够从所产生的信息中提取各个实体及其之间的实体关系模式,则可以利用所提取的各个实体及其之间的实体关系模式更有效地进行信息检索、知识挖掘、科学假设产生等等。但是,所产生的信息一般是非结构化的,各种信息中的各个实体及其之间的实体关系模式也具有各种不同的表述。因此,难以高效地和准确地从海量的、非结构化的信息中提取各个实体及其之间的实体关系模式。因此,期望提供一种能够高效地和准确地从海量的、非结构化的信息中提取各个实体及其之间的实体关系模式的方法和设备,以及能够高效地和准确地对实体关系模式进行聚类的方法和设备。
技术实现要素:
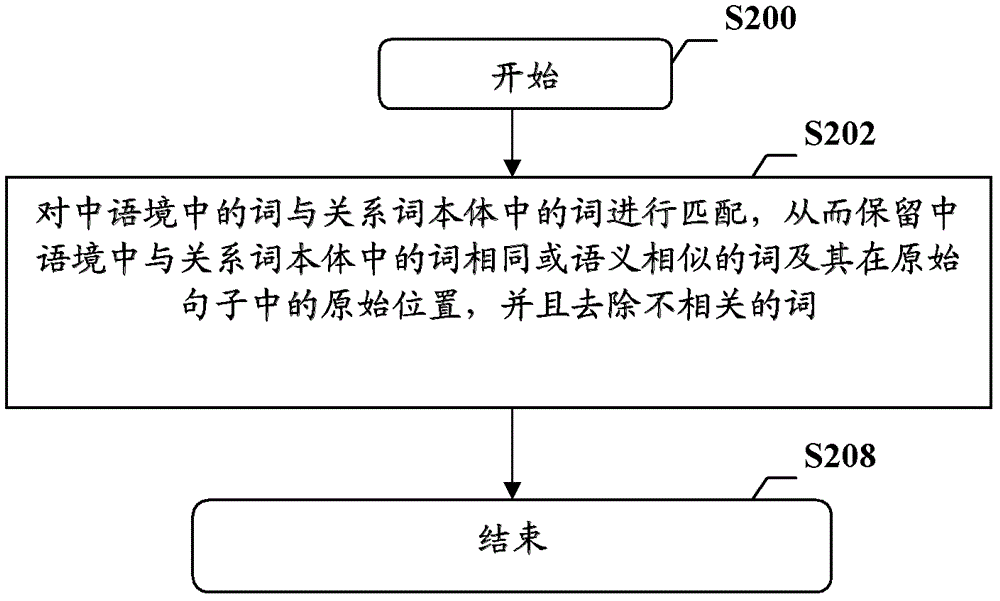
在下文中将给出关于本发明的简要概述,以便提供关于本发明的某些方面的基本理解。应当理解,这个概述并不是关于本发明的穷举性概述。它并不是意图确定本发明的关键或重要部分,也不是意图限定本发明的范围。其目的仅仅是以简化的形式给出某些概念,以此作为稍后论述的更详细描述的前序。根据本发明的实施例,提供了一种对实体关系模式进行聚类的方法,包括:对原始句子进行预处理,以识别原始句子中表示实体的实体词;根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;提取拆分后的子句的实体关系模式,其中,子句的实体关系模式用实体词及实体词之间的中语境组成的关系元组来表示;计算所提取的子句的实体关系模式之间的第一相似度;以及根据所计算的子句的实体关系模式之间的第一相似度,将子句的实体关系模式聚类成实体关系模式类。根据上述对实体关系模式进行聚类的方法,其中,提取的步骤包括:对中语境中的词与关系词本体中的词进行匹配,从而保留中语境中与关系词本体中的词相同或语义相似的词及其在原始句子中的原始位置,并且去除不相关的词。根据上述对实体关系模式进行聚类的方法,还包括:根据实体关系模式类中所包含的实体关系模式的数目来计算实体关系模式类的置信度。根据本发明的另一实施例,提供了一种对实体关系模式进行聚类的设备,包括:第一预处理装置,用于对原始句子进行预处理,以识别原始句子中表示实体的实体词;第一拆分装置,用于根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;第一提取装置,用于提取拆分后的子句的实体关系模式,其中,子句的实体关系模式用实体词及实体词之间的中语境组成的关系元组来表示;第一相似度计算装置,用于计算所提取的子句的实体关系模式之间的第一相似度;以及聚类装置,根据所计算的子句的实体关系模式之间的第一相似度,将子句的实体关系模式聚类成实体关系模式类。根据上述对实体关系模式进行聚类的设备,其中,第一提取装置包括:匹配装置,用于对中语境中的词与关系词本体中的词进行匹配,从而保留中语境中与关系词本体中的词相同或语义相似的词及其在原始句子中的原始位置,并且去除不相关的词。根据上述对实体关系模式进行聚类的设备,还包括:置信度计算装置,用于根据实体关系模式类中所包含的实体关系模式的数目来计算实体关系模式类的置信度。根据本发明的又一实施例,提供了一种对实体关系模式进行提取的方法,包括:对原始句子进行预处理,以识别原始句子中表示实体的实体词;根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;提取拆分后的子句的实体关系模式,其中,子句的实体关系模式用实体词及实体词之间的中语境组成的关系元组来表示;分别计算子句的实体关系模式与根据上述对实体关系模式进行聚类的方法所得到的实体关系模式类之间的第二相似度;以及根据第二相似度,将子句的实体关系模式分类到实体关系模式类中与子句的实体关系模式相似的实体关系模式类中。根据上述对实体关系模式进行提取的方法,其中,分类的步骤包括:根据第二相似度和与第二相似度对应的实体关系模式类的置信度,来确定与子句的实体关系模式相似的实体关系模式类。根据上述对实体关系模式进行提取的方法,还包括:计算实体之间的实体关系的强度;以及根据实体之间的实体关系的强度过滤假阳性实体关系。根据本发明的再一实施例,提供了一种对实体关系模式进行提取的设备,包括:第二预处理装置,用于对原始句子进行预处理,以识别原始句子中表示实体的实体词;第二拆分装置,根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;第二提取装置,用于提取拆分后的子句的实体关系模式,其中,子句的实体关系模式用实体词及实体词之间的中语境组成的关系元组来表示;第二相似度计算装置,用于分别计算子句的实体关系模式与根据上述对实体关系模式进行聚类的设备所得到的实体关系模式类之间的第二相似度;以及分类装置,用于根据第二相似度,将子句的实体关系模式分类到实体关系模式类中与子句的实体关系模式相似的实体关系模式类中。根据上述对实体关系模式进行提取的设备,其中,分类装置包括:实体关系模式类确定装置,用于根据第二相似度和与第二相似度对应的实体关系模式类的置信度,来确定与子句的实体关系模式相似的实体关系模式类。根据上述对实体关系模式进行提取的设备,还包括:强度计算装置,用于计算实体之间的实体关系的强度;以及过滤装置,用于根据实体之间的实体关系的强度过滤假阳性实体关系。根据本发明,通过根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列将预处理后的句子拆分成子句,将复杂的句子拆分成简单的子句,可以提高实体及其之间的实体关系模式的提取的准确性,并且可以有效缓解数据稀疏性带来的问题。另外,本申请不需要对原始句子进行句法分析,从而防止句法分析错误的引入。而且,本发明可以适用于从非标注语料中提取实体及其之间的实体关系模式,因此应用领域广泛。附图说明本发明可以通过参考下文中结合附图所给出的描述而得到更好的理解,其中在所有附图中使用了相同或相似的附图标记来表示相同或者相似的部件。所述附图连同下面的详细说明一起包含在本说明书中并且形成本说明书的一部分,而且用来进一步举例说明本发明的优选实施例和解释本发明的原理和优点。在附图中:图1是示出根据本发明的实施例的对实体关系模式进行聚类的方法的示意性流程图;图2是示出根据本发明的实施例的提取拆分后的子句的实体关系模式的示意性流程图;图3是示出根据本发明的实施例的计算子句的实体关系模式之间的第一相似度的示意性流程图;图4是示出根据本发明的实施例的计算子句的实体关系模式之间的第一字符串相似度的示意性流程图;图5是示出根据本发明的实施例的计算子句的实体关系模式之间的第一语义相似度的示意性流程图;图6是示出根据本发明的另一实施例的对实体关系模式进行聚类的方法的示意性流程图;图7是示出根据本发明的实施例的对实体关系模式进行聚类的设备的示意性框图;图8是示出根据本发明的实施例的对实体关系模式进行聚类的设备中的第一提取装置的示意性框图;图9是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第一相似度计算装置的示意性框图;图10是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第一字符串相似度计算装置的示意性框图;图11是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第一语义相似度计算装置的示意性框图;图12是示出根据本发明的另一实施例的对实体关系模式进行聚类的设备的示意性框图;图13是示出根据本发明的实施例的对实体关系模式进行提取的方法的示意性流程图;图14是示出根据本发明的实施例的计算子句的实体关系模式与实体关系模式类之间的第二相似度的示意性流程图;图15是示出出根据本发明的实施例的将子句的实体关系模式分类到与其相似的实体关系模式类中的示意性流程图;图16是示出根据本发明的实施例的生成和输出实体关系模式的处理的示意性流程图;图17是示出根据本发明的另一实施例的生成和输出实体关系模式的处理的示意性流程图;图18是示出根据本发明的实施例的计算实体关系模式强度的处理的示意性流程图;图19是示出根据本发明的实施例的对实体关系模式进行提取的设备的示意性框图;图20是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第二相似度计算装置的示意性框图;图21示出根据本发明的实施例的对实体关系模式进行提取的设备中的分类装置的示意性框图;图22是示出根据本发明的另一实施例的对实体关系模式进行提取的设备的示意性框图;图23是示出根据本发明的又一实施例的对实体关系模式进行提取的设备的示意性框图;图24是示出根据本发明的再一实施例的对实体关系模式进行提取的设备的示意性框图;以及图25是示出可用于作为实施根据本发明的实施例的信息处理设备的示意性框图。具体实施方式在下文中将结合附图对本发明的示范性实施例进行描述。为了清楚和简明起见,在说明书中并未描述实际实施方式的所有特征。然而,应该了解,在开发任何这种实际实施方式的过程中可以做出很多特定于实施方式的决定,以便实现开发人员的具体目标,并且这些决定可能会随着实施方式的不同而有所改变。在此,还需要说明的一点是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的装置结构,而省略了与本发明关系不大的其他细节。下面将结合图1来描述根据本发明的实施例的对实体关系模式进行聚类的方法。图1是示出根据本发明的实施例的对实体关系模式进行聚类的方法的示意性流程图。如图1所示,该处理在S100开始。接着,该处理前进到S102。在S102,对原始句子进行预处理,以识别原始句子中表示实体的实体词。可以对文本信息中的原始句子进行各种预处理,例如分句、分词、词性标注和命名实体识别等。命名实体识别可以识别文本信息中的原始句子中表示实体的实体词。例如,在生物医学领域的文本信息中存在“食物(Food)”和“疾病(Disease)”等实体,其中表示实体“食物”的实体词例如可以为“<Food>绿茶</Food>”,而表示实体“疾病”的实体词例如可以为“<Disease>肿瘤</Disease>”。因此,通过上述预处理,可以得到包含有实体标签的原始句子,从而可以识别出原始句子中表示实体的实体词。例如,通过对文本信息中的原始句子“结果表示绿茶对乌拉坦诱发昆明种小鼠肺腺癌的发病率影响不大,但肿瘤指数I和肿瘤指数II显著下降,提示福建绿茶有一定的防癌作用”进行上述预处理,可以得到下面的包含有实体标签的原始句子“结果表示<Food>绿茶</Food>对乌拉坦诱发昆明种<Disease>小鼠肺腺癌</Disease>的发病率影响不大,但肿瘤指数I和肿瘤指数II显著下降,提示福建<Food>绿茶</Food>有一定的防<Disease>癌</Disease>作用”,从而识别出原始句子中表示实体“食物”的实体词“绿茶”、以及表示实体“疾病”的实体词“小鼠肺腺癌”和“癌”。本领域技术人员应当理解,上述命名实体识别等预处理仅是示例性的而非限制性的,还可以采用采用其它的预处理,只要其能够识别原始句子中表示实体的实体词即可。在S102之后,该处理前进到S104。在S104,根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句。原始句子一般为非结构性的,原始句子中的各个实体之间具有各种各样的实体关系。如果直接对原始句子进行处理,则效率低下,甚至无法进行。因此,需要对原始句子进行简化,例如将复杂的句子拆分为简单的句子等。针对具有不同实体关系的原始句子,可以分别采用相应的拆分方式来将复杂的句子拆分为简单的句子。下面针对几种具有典型实体关系的原始句子,分别说明其相应的拆分方式。(1.基于独立子句的拆分)独立实体关系表示一个实体与另一个实体之间的一对一关系。如果预处理后的原始句子包含多个表示独立实体关系的独立子句,则可将该原始句子直接拆分为多个独立子句。还是以“食物”和“疾病”两个实体为例,假设预处理后的原始句子为{食物,疾病,…,食物,疾病,食物,疾病},因为其包含多个表示独立实体关系{食物,疾病}的独立子句,因此可将预处理后的原始句子{食物,疾病,…,食物,疾病,食物,疾病}直接拆分为多个独立子句:{食物,疾病},…,{食物,疾病},{食物,疾病}。更具体地,例如对于预处理后的原始句子“结果表示<Food>绿茶</Food>对乌拉坦诱发昆明种<Disease>小鼠肺腺癌</Disease>的发病率影响不大,但肿瘤指数I和肿瘤指数II显著下降,提示福建<Food>绿茶</Food>有一定的防<Disease>癌</Disease>作用”,其具有如下独立实体关系{<Food>绿茶</Food>,<Disease>小鼠肺腺癌</Disease>}、{<Food>绿茶</Food>,<Disease>癌</Disease>},因此经过独立子句拆分之后可以得到两个独立子句,分别为“结果表示<Food>绿茶</Food>对乌拉坦诱发昆明种<Disease>小鼠肺腺癌</Disease>的发病率影响不大”和“但肿瘤指数I和肿瘤指数II显著下降,提示福建<Food>绿茶</Food>有一定的防<Disease>癌</Disease>作用”。在上述示例中,在进行独立子句拆分时,还考虑了原始句子中的连接词,例如“但”等,并且将连接词前后的部分拆分到不同的独立子句中。(2.基于实体关系的拆分)可以根据实体词和关系词本体中的关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系。关系词本体可以预先设定和存储,关系词本体中包含了表示各种实体的实体词和表示各种实体之间的实体关系的关系词。通过参考关系词本体,可以识别预处理后的原始句子中的实体词之间的实体关系,例如可以识别预处理后的原始句子中各个实体词和关系词的特定出现序列。在识别出预处理后的原始句子中的实体词之间的实体关系之后,可以根据所确定的实体关系将预处理后的句子拆分成子句。下面详细说明几种典型的实体关系及其相应的拆分方式。(2.1多对多实体关系a)还是以“食物”和“疾病”两个实体为例。多对多关系a为具有如下形式的实体词和关系词的特定出现序列:{食物1,食物2,…,食物m,关系词,疾病1,疾病2,…,疾病n},其中,m和n都是大于或等于2的自然数。注意,例如,上述关系词可以从关系词本体中获得,但是这仅是示例性的而非限制性的,还可以采用其它方式获得上述关系词。对于多对多关系a,可以将关系词之前的多个连续的实体“食物1”、“食物2”、…、“食物m”合并为一个复合实体“食物1-m”,并且将关系词之后的多个连续的实体合并为一个复合实体“疾病1-n”。因此,可以将上述多对多关系a:{食物1,食物2,…,食物m,关系词,疾病1,疾病2,…,疾病n}拆分为{食物1-m,关系词,疾病1-n}。更具体地,对于预处理后的原始句子“抗肿瘤作用表明,<Food>富硒绿茶</Food>中<Food>茶多酚</Food>及水提物、普通<Food>绿茶</Food>中<Food>茶多酚</Food>及水提物对<Disease>人肺癌细胞A549</Disease>和<Disease>人肝癌细胞HepG2</Disease>均有明显的生长抑制作用,并呈剂量效应关系”,其具有如下形式的实体词和关系词的特定出现序列:{<Food>富硒绿茶</Food>,<Food>茶多酚</Food>,<Food>绿茶</Food>,<Food>茶多酚</Food>,对…具有抑制作用,<Disease>人肺癌细胞A549</Disease>,<Disease>人肝癌细胞HepG2</Disease>},因此将上述原始句子“抗肿瘤作用表明,<Food>富硒绿茶</Food>中<Food>茶多酚</Food>及水提物、普通<Food>绿茶</Food>中<Food>茶多酚</Food>及水提物对<Disease>人肺癌细胞A549</Disease>和<Disease>人肝癌细胞HepG2</Disease>均有明显的生长抑制作用,并呈剂量效应关系”作为一个子句。(2.2多对多实体关系b)还是以“食物”和“疾病”两个实体为例。多对多实体关系b为具有如下形式的实体词和关系词的特定出现序列:{食物1,食物2,…,食物m,关系词1,疾病1,关系词2,疾病2,…,关系词n,疾病n},其中,m和n都是大于或等于2的自然数。注意,例如,上述关系词可以从关系词本体中获得,但是这仅是示例性的而非限制性的,还可以采用其它方式获得上述关系词。对于多对多实体关系b,可以将关系词之前的多个连续的实体“食物1”、“食物2”、…、“食物m”合并为一个复合实体“食物1-m”。因此,可以将上述多对多关系b:{食物1,食物2,…,食物m,关系词1,疾病1,关系词2,疾病2,…,关系词n,疾病n}拆分为多个子句:{食物1-m,关系词1,疾病1},{食物1-m,关系词2,疾病2},…,{食物1-m,关系词n,疾病n}。更具体地,对于预处理后的原始句子“<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>是一种由<Food>绿茶</Food>中提取的具有生物活性的<Food>多酯类物质</Food>,它具有抗<Disease>氧化</Disease>、抗<Disease>衰老</Disease>、抗<Disease>肿瘤</Disease>、抗<Disease>炎症</Disease>和杀<Disease>菌<Disease>等多种生物学效应”,其具有如下形式的实体词和关系词的特定出现序列:{<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>,<Food>绿茶</Food>,<Food>多酯类物质</Food>,抗,<Disease>氧化</Disease>,抗,<Disease>衰老</Disease>,抗,<Disease>肿瘤</Disease>,抗,<Disease>炎症</Disease>,杀,<Disease>菌<Disease>},因此将上述预处理后的原始句子“<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>是一种由<Food>绿茶</Food>中提取的具有生物活性的<Food>多酯类物质</Food>,它具有抗<Disease>氧化</Disease>、抗<Disease>衰老</Disease>、抗<Disease>肿瘤</Disease>、抗<Disease>炎症</Disease>和杀<Disease>菌<Disease>等多种生物学效应”拆分为以下多个子句:“<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>是一种由<Food>绿茶</Food>中提取的具有生物活性的<Food>多酯类物质</Food>,它具有抗<Disease>氧化</Disease>”、“<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>是一种由<Food>绿茶</Food>中提取的具有生物活性的<Food>多酯类物质</Food>,它具有抗<Disease>衰老</Disease>”、“<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>是一种由<Food>绿茶</Food>中提取的具有生物活性的<Food>多酯类物质</Food>,它具有抗<Disease>肿瘤</Disease>”、“<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>是一种由<Food>绿茶</Food>中提取的具有生物活性的<Food>多酯类物质</Food>,它具有抗<Disease>炎症</Disease>”以及“<Food>表没食子酸儿茶素没食子酸酯EGCG</Food>是一种由<Food>绿茶</Food>中提取的具有生物活性的<Food>多酯类物质</Food>,它具有杀<Disease>菌<Disease>等多种生物学效应”。(2.3多对一实体关系)还是以“食物”和“疾病”两个实体为例。多对一实体关系为具有如下形式的实体词和关系词的特定出现序列:{食物1,食物2,…,食物m,关系词,疾病},其中,m是大于或等于2的自然数。注意,例如,上述关系词可以从关系词本体中获得,但是这仅是示例性的而非限制性的,还可以采用其它方式获得上述关系词。对于多对一实体关系,可以将关系词之前的多个连续的实体“食物1”、“食物2”、…、“食物m”合并为一个复合实体“食物1-m”。因此,可以将上述多对一关系:{食物1,食物2,…,食物m,关系词,疾病}拆分为{食物1-m,关系词,疾病}。更具体地,对于预处理后的原始句子“采用武汉市职工医学院从湖北<Food>绿茶</Food>中提取的<Food>绿茶素(TP-91)</Food>及湖北大学生命科学院从<Food>蚕蛹</Food>中提取的<Food>壳多糖</Food>进行抗<Disease>肿瘤</Disease>试验研究”,其具有如下形式的实体词和关系词的特定出现序列:{<Food>绿茶</Food>,<Food>绿茶素(TP-91)</Food>,<Food>蚕蛹</Food>,<Food>壳多糖</Food>,抗,<Disease>肿瘤</Disease>},因此将上述原始句子“采用武汉市职工医学院从湖北<Food>绿茶</Food>中提取的<Food>绿茶素(TP-91)</Food>及湖北大学生命科学院从<Food>蚕蛹</Food>中提取的<Food>壳多糖</Food>进行抗<Disease>肿瘤</Disease>试验研究”作为一个子句。(2.4一对多实体关系a)还是以“食物”和“疾病”两个实体为例。一对多实体关系a为具有如下形式的实体词和关系词的特定出现序列:{食物,关系词,疾病1,疾病2,…,疾病n},其中,n是大于或等于2的自然数。注意,例如,上述关系词可以从关系词本体中获得,但是这仅是示例性的而非限制性的,还可以采用其它方式获得上述关系词。对于一对多实体关系a,可以将关系词之后的多个连续的实体“疾病1”、“疾病2”、…、“疾病n”合并为一个复合实体“疾病1-n”。因此,可以将上述一对多关系a:{食物,关系词,疾病1,疾病2,…,疾病n}拆分为{食物,关系词,疾病1-n}。更具体地,对于预处理后的原始句子“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>和<Disease>肿瘤</Disease>作用”,其具有如下形式的实体词和关系词的特定出现序列:{<Food>富硒绿茶</Food>,抗,<Disease>炎症</Disease>,<Disease>肿瘤</Disease>},因此将上述原始句子“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>和<Disease>肿瘤</Disease>作用”作为一个子句。(2.5一对多实体关系b)还是以“食物”和“疾病”两个实体为例。一对多实体关系b为具有如下形式的实体词和关系词的特定出现序列:{食物,关系词1,疾病1,关系词2,疾病2,…,关系词n,疾病n},其中,n是大于或等于2的自然数。注意,例如,上述关系词可以从关系词本体中获得,但是这仅是示例性的而非限制性的,还可以采用其它方式获得上述关系词。对于一对多实体关系b,可以将上述一对多关系b:{食物,关系词1,疾病1,关系词2,疾病2,…,关系词n,疾病n}拆分为以下多个子句:{食物,关系词1,疾病1}、{食物,关系词2,疾病2}、…、{食物,关系词n,疾病n}。更具体地,对于预处理后的原始句子“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症、抑制</Disease>和<Disease>肿瘤</Disease>作用”,其具有如下形式的实体词和关系词的特定出现序列:{<Food>富硒绿茶</Food>,抗,<Disease>炎症,抑制,</Disease>和<Disease>肿瘤},因此将上述原始句子“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症、抑制</Disease>和<Disease>肿瘤</Disease>作用”拆分为以下多个子句:“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症”、“<Food>富硒绿茶</Food>具有抑制</Disease>和<Disease>肿瘤</Disease>作用”。经过上述拆分处理,可以简化原始句子结构,同时还可以增加学习样本数量,缓解由数据稀疏性带来的问题。本领域技术人员应当理解,实体不限于“食物”或“疾病”,还可以是其它实体。另外,上述说明的各种拆分方式仅是示例性的而非限制性的,还可以采用其它适当的拆分方式。在S104之后,该处理前进到S106。在S106,提取拆分后的子句的实体关系模式,其中,子句的实体关系模式用实体词及实体词之间的中语境组成的关系元组来表示。在通过S104将原始句子拆分成子句之后,可以提取拆分后的子句的实体关系模式。可以将子句的实体关系模式表示为下面的关系元组的形式:{prefix,entity1,infix,entity2,suffix},其中,“entity1”表示实体1,“entity2”表示实体2,“prefix”表示entity1的前语境,“infix”表示entity1和entity2之间的中语境,而“suffix”表示entity2的后语境。当前语境、中语境或后语境不存在时,用空(NULL)表示。另外,一般而言,前语境和后语境没有实体之间的中语境重要,因此也可以在关系元组中省略前语境和后语境,而仅保留实体之间的中语境,从而将关系元组表示为如下形式:{entity1,infix,entity2}。例如,在原始句子“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症、抑制</Disease>和<Disease>肿瘤</Disease>作用”被拆分为以下两个子句:“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>”、“<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>作用”之后,可以提取子句“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>”的实体关系模式为“NULL<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>NULL”,即实体1“<Food>富硒绿茶</Food>”的前语境为“NULL”,实体2“<Disease>炎症</Disease>”的后语境为“NULL”,而实体1“<Food>富硒绿茶</Food>”与实体2“<Disease>炎症</Disease>”之间的中语境为“具有显著的抗”;同理,可以提取子句“<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>作用”的实体关系模式为“NULL<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>作用”,即实体1“<Food>富硒绿茶</Food>”的前语境为“NULL”,实体2“<Disease>炎症</Disease>”的后语境为“作用”,而实体1“<Food>富硒绿茶</Food>”与实体2“<Disease>炎症</Disease>”之间的中语境为“抑制”。另外,也可以省略前语境和后语境,而仅保留实体之间的中语境。例如,可以提取子句“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>”的实体关系模式为“<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>”;同理,可以提取子句“<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>作用”的实体关系模式为“<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>”。下文中,对关系元组{prefix,entity1,infix,entity2,suffix}的处理同样适用于对关系元组{entity1,infix,entity2}另外,可以根据关系词本体对上述提取的子句的实体关系模式进行泛化,以去除其他无关词。下面结合图2来详细说明根据关系词本体对上述提取的子句的实体关系模式进行泛化的处理。如图2所示,该处理开始于S200。在S200之后,该处理前进到S202。在S202,对中语境中的词与关系词本体中的词进行匹配,从而保留中语境中与关系词本体中的词相同或语义相似的词及其在原始句子中的原始位置,并且去除不相关的词。另外,也可以对前语境和/或后语境中的词与关系词本体中的词进行匹配从而保留前语境和/或后语境中与关系词本体中的词相同或语义相似的词及其在原始句子中的原始位置,并且去除不相关的词。还是以上述提取的子句的实体关系模式“NULL<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>NULL”和“NULL<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>作用”为例。对于实体关系模式“NULL<Food>富硒绿茶</Food>具有显著的抗<Disease>炎症</Disease>NULL”,例如按照最长匹配策略,将前语境“NULL”、中语境“具有显著的抗”和后语境“NULL”分别与关系词本体进行匹配,并且将前语境保留为“NULL”,将中语境保留为“抗”并去除了无关词“具有显著的”,以及将后语境保留为“NULL”,最终得到泛化后的实体关系模式“NULL<Food>富硒绿茶</Food>抗<Disease>炎症</Disease>NULL”。对于实体关系模式“NULL<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>作用”可以按照同样的方式进行泛化,从而得到泛化后的实体关系模式“NULL<Food>富硒绿茶</Food>抑制</Disease>和<Disease>肿瘤</Disease>作用”。该处理在S208结束。该处理可以根据关系词本体去除前语境、中语境和后语境中的无关词,从而减少了对后续处理的干扰,可以提高后续处理的效率和准确度。本领域技术人员应当理解,上述根据关系词本体对提取的实体关系模式进行泛化的处理仅是示例性的而非限制性的,并且是可选的,即也可以不对提取的实体关系模式进行泛化。接着返回参考图1。在S106之后,该处理前进到S108。在S108,计算所提取的子句的实体关系模式之间的第一相似度。在经过S106提取子句的实体关系模式之后,可以计算不同的子句的实体关系模式之间的第一相似度。可以计算不同的子句的实体关系模式之间的字符串相似度,也可以计算不同的子句的实体关系模式之间的语义相似度,或者可以计算不同的子句的实体关系模式之间的字符串相似度和语义相似度两者。另外,在计算不同的子句的实体关系模式之间的第一相似度时,可以计算不同的子句的实体关系模式中的前语境、中语境和后语境中的至少之一之间的相似度,例如可以计算不同的子句的实体关系模式中的中语境之间的相似度。稍后将参考图3至图5详细描述如何计算所提取的子句的实体关系模式之间的第一相似度。本领域技术人员应当理解,上述采用字符串相似度和/或语义相似度来计算不同的子句的实体关系模式之间的第一相似度仅是示例性的而非限制性的,还可以采用其它的相似度计算的方式。在S108之后,该处理前进到S110。在S110,根据所计算的子句的实体关系模式之间的第一相似度,将子句的实体关系模式聚类成实体关系模式类。在经过S108计算出不同的子句的实体关系模式之间的第一相似度之后,可以根据所计算的第一相似度,采用聚类算法对子句的实体关系模式进行聚类。聚类算法的示例为KNN(K最邻近结点算法),EM(最大期望算法)等。由于这些聚类算法都是本领域比较公知的算法,其具体细节在此不再赘述。本领域技术人员应当理解,聚类算法不限于上述的KNN和EM,还可以采用其它的聚类算法。最后,该处理在S112处结束。根据本实施例,可以将从原始句子中提取的子句的实体关系模式聚类成实体关系模式类。可以采用聚类所得到的实体关系模式类来提取新的子句的实体关系模式,从而提高子句的实体关系模式的提取的效率和准确度。下面结合图3至图5详细描述如何计算所提取的子句的实体关系模式之间的第一相似度。图3是示出根据本发明的实施例的计算子句的实体关系模式之间的第一相似度的示意性流程图。图4是示出根据本发明的实施例的计算子句的实体关系模式之间的第一字符串相似度的示意性流程图。图5是示出根据本发明的实施例的计算子句的实体关系模式之间的第一语义相似度的示意性流程图。如图3所示,该处理开始于S300。在S300之后,该处理前进到S302。在S302,计算子句的实体关系模式之间的第一字符串相似度。如上所述,子句的实体关系模式可以用关系元组{prefix,entity1,infix,entity2,suffix}、或者{entity1,infix,entity2}来表示。因此,可以通过计算不同的子句的实体关系模式中的前语境、中语境和后语境中的至少之一之间的字符串相似度,例如可以通过计算不同的子句的实体关系模式中的中语境之间的字符串相似度,来计算子句的实体关系模式之间的第一字符串相似度。假设子句1的实体关系模式为p1,子句2的实体关系模式为p2,则实体关系模式p1与实体关系模式p2之间的第一字符串相似度可以用StringSimilarity(p1,p2)来表示。稍后将参考图4详细描述如何计算子句的实体关系模式之间的第一字符串相似度。在S302之后,该处理前进到S304。在S304,计算子句的实体关系模式之间的第一语义相似度。如上所述,子句的实体关系模式可以用关系元组{prefix,entity1,infix,entity2,suffix}、或{entity1,infix,entity2}来表示。因此,可以通过计算不同的子句的实体关系模式中的前语境、中语境和后语境中的至少之一之间的语义相似度,例如可以通过计算不同的子句的实体关系模式中的中语境之间的语义相似度,来计算子句的实体关系模式之间的第一语义相似度。假设子句1的实体关系模式为p1,子句2的实体关系模式为p2,则实体关系模式p1与实体关系模式p2之间的第一语义相似度可以用SemanticSimilarity(p1,p2)来表示。稍后将参考图5详细描述如何计算子句的实体关系模式之间的第一语义相似度。在S304之后,该处理前进到S306。在S306,将第一字符串相似度和第一语义相似度加权后的结果作为第一相似度。如上所述,如果实体关系模式p1与实体关系模式p2之间的第一字符串相似度用StringSimilarity(p1,p2)来表示,而实体关系模式p1与实体关系模式p2之间的第一语义相似度用SemanticSimilarity(p1,p2)来表示,则第一相似度(即最终相似度FinalSimilarity(p1,p2))可以用以下公式来通过加权组合而得到。FinalSimilarity(p1,p2)=θ×SemanticSimilarity(p1,p2)+(1-θ)StringSimilarity(p1,p2)其中,θ为经验值,可以用来均衡字符串相似度和语义相似度的权重。θ的取值范围为0≤θ≤1。θ可以预先设定,或者可以通过试验来确定。下面将结合图4详细描述如何计算子句的实体关系模式之间的第一字符串相似度。如图4所示,该处理开始于S400。在S400之后,该处理前进到S402。在S402,分别计算子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二字符串相似度。如上所述,子句的实体关系模式可以用关系元组{prefix,entity1,infix,entity2,suffix}来表示。对前语境prefix可以进行最长公共后匹配(longest-common-back-matching),即从前语境的后面进行严格匹配,若匹配则为1,否者为0。对中语境infix可以进行最长公共前匹配(longest-common-forth-matching),即从中语境infix的前面进行严格匹配,若匹配则为1,否则为0。对后语境suffix进行最长公共后匹配(longest-common-back-matching),即从后语境suffix的后面进行严格匹配,若匹配则为1,否者为0。在S402之后,该处理前进到S404。在S404,将第二字符串相似度加权后的结果作为第一字符串相似度。假设子句1的实体关系模式为p1,子句2的实体关系模式为p2,则可以根据以下公式来计算子句1的实体关系模式中的前语境、中语境和后语境与子句2的实体关系模式中的前语境、中语境和后语境之间的第二字符串相似度的加权和。StringSimilarity(p1,p2)=α×match(prefix(p1),prefix(p2))+β×match(infix(p1),infix(p2))+γ×match(suffix(p1),suffix(p2))其中,match(prefix(p1),prefix(p2))表示实体关系模式p1的前语境与实体关系模式p2的前语境之间的字符串相似度,match(infix(p1),infix(p2))表示实体关系模式p1的中语境与实体关系模式p2的中语境之间的字符串相似度,而match(suffix(p1),suffix(p2)表示实体关系模式p1的后语境与实体关系模式p2的后语境之间的字符串相似度,并且α+β+γ=1。由于实体的前语境、中语境和后语境对实体关系模式相似度计算的影响程度不同,所以α、β和γ可以采用不同的权重。本发明中,α、β和γ的值可以使用MLE(最大似然估计)算法从开发集中估计得到。例如,可以统计开发集中关系词出现在前语境、中语境和后语境位置的概率,并使用该概率来表示α、β和γ的值。本领域技术人员应该理解,上述确定α、β和γ的值的方法仅是示例性的而非限制的,还可以采用其它方式来确定α、β和γ的值,例如可以预先设定或者根据试验来确定α、β和γ的值。该处理在S406结束。另外,对于省略了前语境和后语境的关系元组{prefix,entity1,infix,entity2,suffix},可以仅计算子句的实体关系模式中的中语境与其它子句的实体关系模式中的中语境之间的第二字符串相似度,并且将计算出的第二字符串相似度作为第一字符串相似度。下面结合图5来详细描述如何计算子句的实体关系模式之间的第一语义相似度。如图5所示,该处理开始于S500。在S500之后,该处理前进到S502。在S502,分别计算子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二语义相似度。如上所述,子句的实体关系模式可以用关系元组{prefix,entity1,infix,entity2,suffix}来表示。可以参考关系词本体来判断子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境在语义上是否相似。在S502之后,该处理前进到S504。在S504,将第二语义相似度加权后的结果作为第一语义相似度。假设子句1的实体关系模式为p1,子句2的实体关系模式为p2,则可以根据以下公式来计算子句1的实体关系模式中的前语境、中语境和后语境与子句2的实体关系模式中的前语境、中语境和后语境之间的第二语义相似度的加权和。SemanticSimilarity(p1,p2)=α×sim(prefix(p1),prefix(p2))+β×sim(infix(p1),infix(p2))+γ×sim(suffix(p1),suffix(p2))其中,sim(prefix(p1),prefix(p2))表示实体关系模式p1的前语境与实体关系模式p2的前语境之间的语义相似度,sim(infix(p1),infix(p2))表示实体关系模式p1的中语境与实体关系模式p2的中语境之间的语义相似度,而sim(suffix(p1),suffix(p2)表示实体关系模式p1的后语境与实体关系模式p2的后语境之间的字符串相似度,并且α+β+γ=1。由于实体的前语境、中语境和后语境对实体关系模式相似度计算的影响程度不同,所以α、β和γ可以采用不同的权重。本发明中,α、β和γ的值可以使用MLE算法从开发集中估计得到。例如,可以统计开发集中关系词出现在前语境、中语境和后语境位置的概率,并使用该概率来表示α、β和γ的值。本领域技术人员应该理解,上述确定α、β和γ的值的方法仅是示例性的而非限制的,还可以采用其它方式来确定α、β和γ的值,例如可以预先设定或者根据试验来确定α、β和γ的值。该处理在S506结束。另外,对于省略了前语境和后语境的关系元组{prefix,entity1,infix,entity2,suffix},可以仅计算子句的实体关系模式中的中语境与其它子句的实体关系模式中的中语境之间的第二语义相似度,并且将计算出的第二语义相似度作为第一语义相似度。下面结合图6来描述根据本发明的另一实施例的对实体关系模式进行聚类的方法。图6是示出根据本发明的另一实施例的对实体关系模式进行聚类的方法的示意性流程图。图6中所示的S102至S110的处理与图1中所示的S102至S110的处理相同,其细节在此不再赘述。图6所示的处理与图1所示的处理的不同之处在于,图6所示的处理在S110聚类得到实体关系模式类之后前进到S111。在S111,根据实体关系模式类中所包含的实体关系模式的数目来计算实体关系模式类的置信度。假设经过S110聚类得到了总共k个实体关系模式类,其中k为大于或等于1的自然数。用Pi表示k个实体关系模式类中的任一个实体关系模式类,其中,i为自然数并且1≤i≤k。可以根据下面的公式来计算实体关系模式类的置信度conf(Pi):其中,Num(Pi)表示实体关系模式类Pi中的实体关系模式的数目,而表示k个实体关系模式类中的全部实体关系模式的数目。由以上公式可见,实体关系模式类Pi的置信度可以用实体关系模式类Pi中的实体关系模式的数目与全部实体关系模式类中的实体关系模式总和之比来表示。实体关系模式类中的每个实体关系模式的置信度与该实体关系模式类的置信度相同。可以动态地更新实体关系模式类的置信度。稍后将详细说明动态地更新实体关系模式类的置信度的处理。下面结合图7至图12来说明根据本发明的实施例的对实体关系模式进行聚类的设备。图7是示出根据本发明的实施例的对实体关系模式进行聚类的设备的示意性框图。如图7所示,对实体关系模式进行聚类的设备700包括:第一预处理装置702,用于对原始句子进行预处理,以识别原始句子中表示实体的实体词;第一拆分装置704,用于根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;第一提取装置706,用于提取拆分后的子句的实体关系模式,其中,子句的实体关系模式用实体词及实体词之间的中语境组成的关系元组来表示;第一相似度计算装置708,用于计算所提取的子句的实体关系模式之间的第一相似度;以及聚类装置710,根据所计算的子句的实体关系模式之间的第一相似度,将子句的实体关系模式聚类成实体关系模式类。需要指出的是,在与设备有关的实施例中所涉及的相关术语或表述与以上对根据本发明的实施例的方法的实施例阐述中所使用的术语或表述对应,在此不再赘述。图8是示出根据本发明的实施例的对实体关系模式进行聚类的设备中的第一提取装置的示意性框图。如图8所示,第一提取装置706包括:匹配装置801,用于对中语境中的词与关系词本体中的词进行匹配,从而保留中语境中与关系词本体中的词相同或语义相似的词及其在原始句子中的原始位置,并且去除不相关的词。另外,也可以对前语境和/或后语境中的词与关系词本体中的词进行匹配从而保留前语境和/或后语境中与关系词本体中的词相同或语义相似的词及其在原始句子中的原始位置,并且去除不相关的词。图9是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第一相似度计算装置的示意性框图。如图9所示,第一相似度计算装置708包括:第一字符串相似度计算装置901,用于计算子句的实体关系模式之间的第一字符串相似度;第一语义相似度计算装置902,用于计算子句的实体关系模式之间的第一语义相似度;以及第一加权装置903,用于将第一字符串相似度和第一语义相似度加权后的结果作为第一相似度。图10是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第一字符串相似度计算装置的示意性框图。如图10所示,第一字符串相似度计算装置901包括:第二字符串相似度计算装置1001,用于分别计算子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二字符串相似度;以及第二加权装置1003,用于将第二字符串相似度加权后的结果作为第一字符串相似度。另外,对于省略了前语境和后语境的关系元组{prefix,entity1,infix,entity2,suffix},可以仅计算子句的实体关系模式中的中语境与其它子句的实体关系模式中的中语境之间的第二字符串相似度,并且将计算出的第二字符串相似度作为第一字符串相似度。图11是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第一语义相似度计算装置的示意性框图。如图11所示,第一语义相似度计算装置902包括:第二语义相似度计算装置1101,用于分别计算子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二语义相似度;以及第三加权装置1103,用于将第二语义相似度加权后的结果作为第一语义相似度。另外,对于省略了前语境和后语境的关系元组{prefix,entity1,infix,entity2,suffix},可以仅计算子句的实体关系模式中的中语境与其它子句的实体关系模式中的中语境之间的第二语义相似度,并且将计算出的第二语义相似度作为第一语义相似度。图12是示出根据本发明的另一实施例的对实体关系模式进行聚类的设备的示意性框图。如图12所示,对实体关系模式进行聚类的设备1200包括第一预处理装置702、第一拆分装置704、第一提取装置706、第一相似度计算装置708、聚类装置710和置信度计算装置1201。对实体关系模式进行聚类的设备1200中的第一预处理装置702、第一拆分装置704、第一提取装置706、第一相似度计算装置708和聚类装置710与图7所示的对实体关系模式进行聚类的设备700中的第一预处理装置702、第一拆分装置704、第一提取装置706、第一相似度计算装置708和聚类装置710相同,其细节在此不再赘述。另外,对实体关系模式进行聚类的设备1200中的置信度计算装置1201用于根据实体关系模式类中所包含的实体关系模式的数目来计算实体关系模式类的置信度。上述图7至图12中的各个设备和/或装置例如可以被配置成按照相应方法中的相应步骤的工作方式来操作。细节参见上述针对根据本申请的实施例的方法所阐述的实施例。在此不再赘述。下面结合图13至图18描述根据本发明的另一实施例的对实体关系模式进行提取的方法。图13是示出根据本发明的实施例的对实体关系模式进行提取的方法的示意性流程图。图13中所示的S1302至S1306的处理与图1中所示的S102至S106的处理相同,其细节在此不再赘述。如图13所示,在S1306之后,该方法前进到S1308。在S1308,分别计算子句的实体关系模式与根据上述对实体关系模式进行聚类的方法所得到的实体关系模式类之间的第二相似度。在经过S1306之后,可以得到候选的子句的实体关系模式T。假设经过上述对实体关系进行聚类的方法之后得到了k个实体关系模式类{P1,P2,…,Pi,…,Pk-1,Pk},其中,i和k均为自然数,并且1≤i≤k。可以计算候选的子句的实体关系模式T与k个实体关系模式类{P1,P2,…,Pi,…,Pk-1,Pk}中的每个实体关系模式类Pi之间的第二相似度Similarity(Pi,T)。稍后将结合图14详细说明如何计算候选的子句的实体关系模式T与k个实体关系模式类{P1,P2,…,Pi,…,Pk-1,Pk}中的每个实体关系模式类Pi之间的第二相似度Similarity(Pi,T)。在S1308之后,该方法前进到S1310。在S1310,根据第二相似度,将子句的实体关系模式分类到实体关系模式类中与子句的实体关系模式相似的实体关系模式类中。在经过S1308计算出候选的子句的实体关系模式T与k个实体关系模式类{P1,P2,…,Pi,…,Pk-1,Pk}中的每个实体关系模式类Pi之间的第二相似度Similarity(Pi,T)之后,可以将所计算的第二相似度Similarity(Pi,T)与预定的阈值进行比较,并且根据比较的结果将候选的子句的实体关系模式T分类到相应的实体关系模式类中。如果所计算的第二相似度Similarity(Pi,T)大于预定的阈值,则将候选的子句的实体关系模式T分类到该第二相似度Similarity(Pi,T)所对应的实体关系模式类Pi中。最后,该方法在S1312结束。下面结合图14详细说明计算子句的实体关系模式与实体关系模式类之间的第二相似度的处理。图14是示出根据本发明的实施例的计算子句的实体关系模式与实体关系模式类之间的第二相似度的示意性流程图。如图14所示,该处理开始于S1400。在S1400之后,该处理前进到S1402。在S1402,分别计算子句的实体关系模式与实体关系模式类中的每个实体关系模式之间的第三相似度。如上所述,对于k个实体关系模式类{P1,P2,…,Pi,…,Pk-1,Pk}中的任一个实体关系模式类Pi,假设实体关系模式类Pi中存在n个实体关系模式{pi,1,pi,2,…,pi,t,…,pi,n-1,pi,n},其中,i,k,t和n均为自然数,并且,1≤i≤k,1≤t≤n。注意,不同的实体关系模式类Pi可以具有不同数目的实体关系模式,即n对于不同的实体关系模式类Pi可以具有不同的数值。可以计算候选的子句的实体关系模式T与实体关系模式类Pi中的实体关系模式pi,t之间的第三相似度FinalSimilarity(pi,t,T)。注意,计算候选的子句的实体关系模式T与实体关系模式类Pi中的实体关系模式pi,t之间的第三相似度FinalSimilarity(pi,t,T)的方法与之前参考图3至图5描述的计算子句的实体关系模式之间的第一相似度的方法相同,其具体细节在此不再赘述。在S1402之后,该方法前进到S1404。在S1404,选择具有最大值的第三相似度作为第二相似度。在经过S1402计算出候选的子句的实体关系模式T与实体关系模式类Pi中的实体关系模式pi,t之间的第三相似度FinalSimilarity(pi,t,T)之后,可以选择具有最大值的第三相似度FinalSimilarity(pi,t,T)作为候选的子句的实体关系模式T与实体关系模式类Pi之间的第二相似度Siminlarity(Pi,T)。即,可以根据下面的公式来计算第二相似度Siminlarity(Pi,T):Siminlarity(Pi,T)=Max(FinalSimilarity(pi,t,T)),pi,t∈Pi。本领域技术人员应当理解,上述选择具有最大值的第三相似度FinalSimilarity(pi,t,T)作为候选的子句的实体关系模式T与实体关系模式类Pi之间的第二相似度Siminlarity(Pi,T)仅是示例性的而非限制性的,还可以采用其它的方法来计算候选的子句的实体关系模式T与实体关系模式类Pi之间的第二相似度Siminlarity(Pi,T),例如可以计算候选的子句的实体关系模式T与实体关系模式类Pi中的实体关系模式pi,t之间的第三相似度FinalSimilarity(pi,t,T)的平均值作为上述第二相似度Siminlarity(Pi,T)。下面结合图15说明将子句的实体关系模式分类到与其相似的实体关系模式类的处理。图15是示出出根据本发明的实施例的将子句的实体关系模式分类到与其相似的实体关系模式类中的示意性流程图。如图15所述,该处理开始于S1500。在S1500之后,该处理前进到S1502。在S1502,根据第二相似度和与第二相似度对应的实体关系模式类的置信度,来确定与子句的实体关系模式相似的实体关系模式类。为了确定候选的子句的实体关系模式T属于哪个实体关系模式类Pi,除了考虑候选的子句的实体关系模式T与实体关系模式类Pi之间的相似度FinalSimilarity(Pi,T)之外,还考虑实体关系模式类Pi的置信度conf(Pi)。例如,可以根据下面的公式来计算候选的子句的实体关系模式T与实体关系模式类Pi之间的模式排序Rank(Pi,T):Rank(Pi,T)=conf(Pi)×Similarity(Pi,T)在计算出候选的子句的实体关系模式T与实体关系模式类Pi之间的模式排序Rank(Pi,T)之后,可以将所计算的模式排序Rank(Pi,T)与预定的阈值进行比较,并且根据比较的结果将候选的子句的实体关系模式T分类到相应的实体关系模式类中。如果所计算的模式排序Rank(Pi,T)大于预定的阈值,则将候选的子句的实体关系模式T分类到该模式排序Rank(Pi,T)所对应的实体关系模式类Pi中。该处理在S1504结束。下面结合图16说明根据本发明的实施例的生成和输出实体关系模式的处理。图16是示出根据本发明的实施例的生成和输出实体关系模式的处理的示意性流程图。如图16所示,该处理开始于S1600。在S1600之后,该处理前进到S1602。在S1602,将第二相似度与预定阈值进行比较。在S1602之后,该处理前进到S1604。在S1604,在第二相似度大于预定阈值时,将子句的实体关系模式加入与第二相似度对应的实体关系模式类中并且更新与第二相似度对应的实体关系模式类的置信度,以及将子句的关系元组加入实体关系库中,并且将子句中的关系词加入关系词本体。如上所述,可以根据上述公式来计算实体关系模式类Pi的置信度conf(Pi)。当将候选的子句的实体关系模式T加入到实体关系模式类Pi中之后,可以根据上述计算置信度conf(Pi)的公式重新计算实体关系模式类Pi的置信度,从而可以动态更新实体关系模式类Pi的置信度。该处理在S1606结束。下面,结合图17说明根据本发明的另一实施例的生成和输出实体关系模式的处理。图17是示出根据本发明的另一实施例的生成和输出实体关系模式的处理的示意性流程图。如图17所示,该处理开始于S1700。在S1700之后,该处理前进到S1702。在S1702,将第二相似度和与第二相似度对应的实体关系模式类的置信度的乘积与预定阈值进行比较。如上所述,可以根据公式Rank(Pi,T)=conf(Pi)×Similarity(Pi,T)来计算候选的子句的实体关系模式T与实体关系模式类Pi之间的模式排序Rank(Pi,T),该模式排序同时体现了候选的子句的实体关系模式与实体关系模式类之间的第二相似度、以及与第二相似度对应的实体关系模式类的置信度。在S1702之后,该处理前进到S1704。在S1704,在第二相似度和与第二相似度对应的实体关系模式类的置信度的乘积(即模式排序Rank(Pi,T))大于预定阈值时,将子句的实体关系模式加入与第二相似度对应的实体关系模式类中并且更新与第二相似度对应的实体关系模式类的置信度,以及将子句的关系元组加入实体关系库中,并且将子句中的关系词加入关系词本体。如上所述,可以根据上述公式来计算实体关系模式类Pi的置信度conf(Pi)。当将候选的子句的实体关系模式T加入到实体关系模式类Pi中之后,可以根据上述计算置信度conf(Pi)的公式重新计算实体关系模式类Pi的置信度,从而可以动态更新实体关系模式类Pi的置信度。最后,该处理在S1706结束。下面,结合图18来说明根据本发明的实施例的计算实体关系模式强度的处理。图18是示出根据本发明的实施例的计算实体关系模式强度的处理的示意性流程图。如图8所示,该处理开始于S1800。在S1800之后,该处理前进到S1802。在S1802,计算实体之间的实体关系的强度。假设Ei和Ej分别表示两个实体,LinkNum(Ei,Ej)表示实体Ei和Ej在关系库中出现的次数,表示Ei与其它所有相关实体在关系库中出现的次数,则可以根据下面的公式来计算实体Ei和实体Ej之间的实体关系的强度Strength(Ei,Ej):其中,i,j,k和q均为自然数,并且,1≤i≤q,1≤j≤q,1≤k≤q。本领域技术人员应当理解,上述计算实体之间的实体关系的强度的方法仅是示例性的而非限制性的。还可以采用其它的方法来计算实体之间的实体关系的强度,例如可以采用最大似然估计MLE来计算实体之间的实体关系的强度等。在S1802之后,该处理前进到S1804。在S1804,根据实体之间的实体关系的强度过滤假阳性实体关系。在经过S1802得到实体Ei和实体Ej之间的实体关系的强度Strength(Ei,Ej)之后,可以将实体关系的强度Strength(Ei,Ej)与预定阈值进行比较。当实体关系的强度Strength(Ei,Ej)小于预定阈值时,则表示实体Ei和实体Ej之间的实体关系为假阳性(FalsePositive)的实体关系,因此可以将实体Ei和实体Ej之间的假阳性的实体关系过滤掉。最后,该处理在S1806结束。下面结合图19至图24来说明根据本发明的实施例的对实体关系模式进行提取的设备。图19是示出根据本发明的实施例的对实体关系模式进行提取的设备的示意性框图。如图19所示,对实体关系模式进行提取的设备1900包括:第二预处理装置1902,用于对原始句子进行预处理,以识别原始句子中表示实体的实体词;第二拆分装置1904,根据实体词和关系词本体中的关系词以及实体词和关系词在预处理后的句子中的特定出现序列确定预处理后的句子中的实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;第二提取装置1906,用于提取拆分后的子句的实体关系模式,其中,子句的实体关系模式用实体词及实体词之间的中语境组成的关系元组来表示;第二相似度计算装置1908,用于分别计算子句的实体关系模式与根据上述对实体关系模式进行聚类的设备所得到的实体关系模式类之间的第二相似度;以及分类装置1910,用于根据第二相似度,将子句的实体关系模式分类到实体关系模式类中与子句的实体关系模式相似的实体关系模式类中。需要指出的是,在与设备有关的实施例中所涉及的相关术语或表述与以上对根据本发明的实施例的方法的实施例阐述中所使用的术语或表述对应,在此不再赘述。图20是示出根据本发明的实施例的对实体关系模式进行提取的设备中的第二相似度计算装置的示意性框图。如图20所示,第二相似度计算装置1908包括:第三相似度计算装置2001,用于分别计算子句的实体关系模式与实体关系模式类中的每个实体关系模式之间的第三相似度;以及选择装置2002,用于选择具有最大值的第三相似度作为第二相似度。图21示出根据本发明的实施例的对实体关系模式进行提取的设备中的分类装置的示意性框图。如图21所示,分类装置1910包括:实体关系模式类确定装置2101,用于根据第二相似度和与第二相似度对应的实体关系模式类的置信度,来确定与子句的实体关系模式相似的实体关系模式类。图22是示出根据本发明的另一实施例的对实体关系模式进行提取的设备的示意性框图。如图22所示,对实体关系模式进行提取的设备2200包括第二预处理装置1902、第二拆分装置1904、第二提取装置1906、第二相似度计算装置1908、分类装置1910、第一比较装置2201和第一更新装置2203。对实体关系模式进行提取的设备2200中的第二预处理装置1902、第二拆分装置1904、第二提取装置1906、第二相似度计算装置1908、分类装置1910与图19所示的对实体关系模式进行提取的设备1900中的相应装置的功能相同,其具体细节在此不再赘述。对实体关系模式进行提取的设备2200中的第一比较装置2201用于将第二相似度与预定阈值进行比较。对实体关系模式进行提取的设备2200中的第一更新装置2203用于在第二相似度大于预定阈值时,将子句的实体关系模式加入与第二相似度对应的实体关系模式类中并且更新与第二相似度对应的实体关系模式类的置信度,以及将子句的关系元组加入实体关系库中,并且将子句中的关系词加入关系词本体。图23是示出根据本发明的又一实施例的对实体关系模式进行提取的设备的示意性框图。如图23所示,对实体关系模式进行提取的设备2300包括第二预处理装置1902、第二拆分装置1904、第二提取装置1906、第二相似度计算装置1908、分类装置1910、第二比较装置2301和第二更新装置2303。对实体关系模式进行提取的设备2300中的第二预处理装置1902、第二拆分装置1904、第二提取装置1906、第二相似度计算装置1908、分类装置1910与图19所示的对实体关系模式进行提取的设备1900中的相应装置的功能相同,其具体细节在此不再赘述。对实体关系模式进行提取的设备2300中的第二比较装置2301用于将第二相似度和与第二相似度对应的实体关系模式类的置信度的乘积与预定阈值进行比较。对实体关系模式进行提取的设备2300中的第二更新装置2303用于在第二相似度和与第二相似度对应的实体关系模式类的置信度的乘积大于预定阈值时,将子句的实体关系模式加入与第二相似度对应的实体关系模式类中并且更新与第二相似度对应的实体关系模式类的置信度,以及将子句的关系元组加入实体关系库中,并且将子句中的关系词加入关系词本体。图24是示出根据本发明的再一实施例的对实体关系模式进行提取的设备的示意性框图。如图24所示,对实体关系模式进行提取的设备2400包括第二预处理装置1902、第二拆分装置1904、第二提取装置1906、第二相似度计算装置1908、分类装置1910、强度计算装置2401和过滤装置2403。对实体关系模式进行提取的设备2400中的第二预处理装置1902、第二拆分装置1904、第二提取装置1906、第二相似度计算装置1908、分类装置1910与图19所示的对实体关系模式进行提取的设备1900中的相应装置的功能相同,其具体细节在此不再赘述。对实体关系模式进行提取的设备2400中的强度计算装置2401用于计算实体之间的实体关系的强度。对实体关系模式进行提取的设备2400中的过滤装置2403用于根据实体之间的实体关系的强度过滤假阳性实体关系。上述图19至图24中的各个设备和/或装置例如可以被配置成按照相应方法中的相应步骤的工作方式来操作。细节参见上述针对根据本申请的实施例的方法所阐述的实施例。在此不再赘述。本领域技术人员理解,在上面描述的根据本发明各实施例的对实体关系模式进行聚类、提取的方法中的各步骤或者对实体关系模式进行聚类、提取的设备中的各功能装置,可以根据实际需要进行任意的组合,即,一个对实体关系模式进行聚类、提取的方法实施例中的处理步骤可以与其它对实体关系模式进行聚类、提取的方法实施例中的处理步骤进行组合,或者,一个对实体关系模式进行聚类、提取的设备实施例中的功能装置可以与其它对实体关系模式进行聚类、提取的设备实施例中的功能装置进行组合,以便实现所期望的技术目的。此外,本申请的实施例还提出了一种程序产品,该程序产品承载机器可执行的指令,当在信息处理设备上执行指令时,指令使得信息处理设备执行根据上述本发明的实施例的对实体关系模式进行聚类的方法。此外,本申请的实施例还提出了一种程序产品,该程序产品承载机器可执行的指令,当在信息处理设备上执行指令时,指令使得信息处理设备执行根据上述本发明的实施例的对实体关系模式进行提取的方法。此外,本申请的实施例还提出了一种存储介质,该存储介质包括机器可读的程序代码,当在信息处理设备上执行程序代码时,程序代码使得信息处理设备执行根据上述本发明的实施例的对实体关系模式进行聚类的方法。此外,本申请的实施例还提出了一种存储介质,该存储介质包括机器可读的程序代码,当在信息处理设备上执行程序代码时,程序代码使得信息处理设备执行根据上述本发明的实施例的对实体关系模式进行提取的方法。相应地,用于承载上述存储有机器可读取的指令代码的程序产品的存储介质也包括在本发明的公开中。存储介质包括但不限于软盘、光盘、磁光盘、存储卡、存储棒等等。根据本发明的实施例的对实体关系模式进行聚类的设备及其各个组成部件以及根据本发明的实施例的对实体关系模式进行提取的设备及其各个组成部件可通过软件、固件、硬件或其组合的方式进行配置。配置可使用的具体手段或方式为本领域技术人员所熟知,在此不再赘述。在通过软件或固件实现的情况下,从存储介质或网络向具有专用硬件结构的信息处理设备(例如图25所示的通用计算机2500)安装构成该软件的程序,该计算机在安装有各种程序时,能够执行各种功能等。在图25中,中央处理单元(CPU)2501根据只读存储器(ROM)2502中存储的程序或从存储部分2508加载到随机存取存储器(RAM)2503的程序执行各种处理。在RAM2503中,也根据需要存储当CPU2501执行各种处理等等时所需的数据。CPU2501、ROM2502和RAM2503经由总线2504彼此连接。输入/输出接口2505也连接到总线2504。下述部件连接到输入/输出接口2505:输入部分2506(包括键盘、鼠标等等)、输出部分2507(包括显示器,比如阴极射线管(CRT)、液晶显示器(LCD)等,和扬声器等)、存储部分2508(包括硬盘等)、通信部分2509(包括网络接口卡比如LAN卡、调制解调器等)。通信部分2509经由网络比如因特网执行通信处理。根据需要,驱动器2510也可连接到输入/输出接口2505。可拆卸介质2511比如磁盘、光盘、磁光盘、半导体存储器等等根据需要被安装在驱动器2510上,使得从中读出的计算机程序根据需要被安装到存储部分2508中。在通过软件实现上述系列处理的情况下,从网络比如因特网或存储介质比如可拆卸介质2511安装构成软件的程序。本领域的技术人员应当理解,这种存储介质不局限于图25所示的其中存储有程序、与设备相分离地分发以向用户提供程序的可拆卸介质2511。可拆卸介质2511的例子包含磁盘(包含软盘(注册商标))、光盘(包含光盘只读存储器(CD-ROM)和数字通用盘(DVD))、磁光盘(包含迷你盘(MD)(注册商标))和半导体存储器。或者,存储介质可以是ROM2502、存储部分2508中包含的硬盘等等,其中存有程序,并且与包含它们的设备一起被分发给用户。指令代码由机器读取并执行时,可执行上述根据本发明实施例的方法。最后,还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。此外,在没有更多限制的情况下,由语句“包括一个......”限定的要素,并不排除在包括要素的过程、方法、物品或者设备中还存在另外的相同要素。再者,由措辞“第一”,“第二”,“第三”等等限定的技术特征或者参数,并不因为这些措辞的使用而具有特定的顺序或者优先级或者重要性程度。换句话说,这些措辞的使用只是为了区分或识别这些技术特征或者参数而没有任何其他的限定含义。通过以上的描述不难看出,本发明的实施例提供的技术方案包括但不限于:附记1.一种对实体关系模式进行聚类的方法,包括:对原始句子进行预处理,以识别所述原始句子中表示实体的实体词;根据实体词和关系词本体中的关系词以及所述实体词和所述关系词在预处理后的句子中的特定出现序列确定所述预处理后的句子中的所述实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;提取拆分后的子句的实体关系模式,其中,所述子句的实体关系模式用所述实体词及所述实体词之间的中语境组成的关系元组来表示;计算所提取的所述子句的实体关系模式之间的第一相似度;以及根据所计算的所述子句的实体关系模式之间的所述第一相似度,将所述子句的实体关系模式聚类成实体关系模式类。附记2.根据附记1所述的对实体关系模式进行聚类的方法,所述提取的步骤包括:对所述中语境中的词与关系词本体中的词进行匹配,从而保留所述中语境中与所述关系词本体中的词相同或语义相似的词及其在所述原始句子中的原始位置,并且去除不相关的词。附记3.根据附记1所述的对实体关系模式进行聚类的方法,其中,计算第一相似度的步骤包括:计算所述子句的实体关系模式之间的第一字符串相似度;计算所述子句的实体关系模式之间的第一语义相似度;以及将所述第一字符串相似度和所述第一语义相似度加权后的结果作为所述第一相似度。附记4.根据附记3所述的对实体关系模式进行聚类的方法,其中,所述计算所述子句的实体关系模式之间的第一字符串相似度包括:分别计算所述子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二字符串相似度;以及将所述第二字符串相似度加权后的结果作为所述第一字符串相似度。附记5.根据附记3所述的对实体关系模式进行聚类的方法,其中,所述计算所述子句的实体关系模式之间的第一语义相似度包括:分别计算所述子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二语义相似度;以及将所述第二语义相似度加权后的结果作为所述第一语义相似度。附记6.根据附记1所述的对实体关系模式进行聚类的方法,还包括:根据所述实体关系模式类中所包含的实体关系模式的数目来计算所述实体关系模式类的置信度。附记7.一种对实体关系模式进行聚类的设备,包括:第一预处理装置,用于对原始句子进行预处理,以识别所述原始句子中表示实体的实体词;第一拆分装置,用于根据实体词和关系词本体中的关系词以及所述实体词和所述关系词在预处理后的句子中的特定出现序列确定所述预处理后的句子中的所述实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;第一提取装置,用于提取拆分后的子句的实体关系模式,其中,所述子句的实体关系模式用所述实体词及所述实体词之间的中语境组成的关系元组来表示;第一相似度计算装置,用于计算所提取的所述子句的实体关系模式之间的第一相似度;以及聚类装置,根据所计算的所述子句的实体关系模式之间的所述第一相似度,将所述子句的实体关系模式聚类成实体关系模式类。附记8.根据附记7所述的对实体关系模式进行聚类的设备,所述第一提取装置包括:匹配装置,用于对所述中语境中的词与关系词本体中的词进行匹配,从而保留所述中语境中与所述关系词本体中的词相同或语义相似的词及其在所述原始句子中的原始位置,并且去除不相关的词。附记9.根据附记7所述的对实体关系模式进行聚类的设备,其中,所述第一相似度计算装置包括:第一字符串相似度计算装置,用于计算所述子句的实体关系模式之间的第一字符串相似度;第一语义相似度计算装置,用于计算所述子句的实体关系模式之间的第一语义相似度;以及第一加权装置,用于将所述第一字符串相似度和所述第一语义相似度加权后的结果作为所述第一相似度。附记10.根据附记9所述的对实体关系模式进行聚类的设备,其中,所述第一字符串相似度计算装置包括:第二字符串相似度计算装置,用于分别计算所述子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二字符串相似度;以及第二加权装置,用于将所述第二字符串相似度加权后的结果作为所述第一字符串相似度。附记11.根据附记9所述的对实体关系模式进行聚类的设备,其中,所述第一语义相似度计算装置包括:第二语义相似度计算装置,用于分别计算所述子句的实体关系模式中的前语境、中语境和后语境与其它子句的实体关系模式中的前语境、中语境和后语境之间的第二语义相似度;以及第三加权装置,用于将所述第二语义相似度加权后的结果作为所述第一语义相似度。附记12.根据附记7所述的对实体关系模式进行聚类的设备,还包括:置信度计算装置,用于根据所述实体关系模式类中所包含的实体关系模式的数目来计算所述实体关系模式类的置信度。附记13.一种对实体关系模式进行提取的方法,包括:对原始句子进行预处理,以识别所述原始句子中表示实体的实体词;根据实体词和关系词本体中的关系词以及所述实体词和所述关系词在预处理后的句子中的特定出现序列确定所述预处理后的句子中的所述实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;提取拆分后的子句的实体关系模式,其中,所述子句的实体关系模式用所述实体词及所述实体词之间的中语境组成的关系元组来表示;分别计算所述子句的实体关系模式与根据附记1-6中任一项所述的对实体关系模式进行聚类的方法所得到的实体关系模式类之间的第二相似度;以及根据所述第二相似度,将所述子句的实体关系模式分类到所述实体关系模式类中与所述子句的实体关系模式相似的实体关系模式类中。附记14.根据附记13所述的对实体关系模式进行提取的方法,其中,计算第二相似度的步骤包括:分别计算所述子句的实体关系模式与实体关系模式类中的每个实体关系模式之间的第三相似度;以及选择具有最大值的所述第三相似度作为所述第二相似度。附记15.根据附记13所述的对实体关系模式进行提取的方法,其中,所述分类的步骤包括:根据所述第二相似度和与所述第二相似度对应的所述实体关系模式类的置信度,来确定所述与所述子句的实体关系模式相似的实体关系模式类。附记16.根据附记13所述的对实体关系模式进行提取的方法,包括:将所述第二相似度与预定阈值进行比较;以及在所述第二相似度大于预定阈值时,将所述子句的实体关系模式加入与所述第二相似度对应的实体关系模式类中并且更新所述与所述第二相似度对应的实体关系模式类的置信度,以及将所述子句的所述关系元组加入实体关系库中,并且将所述子句中的所述关系词加入关系词本体。附记17.根据附记15所述的方法,包括:将所述第二相似度和与所述第二相似度对应的所述实体关系模式类的置信度的乘积与预定阈值进行比较;以及在所述第二相似度和与所述第二相似度对应的所述实体关系模式类的置信度的乘积大于预定阈值时,将所述子句的实体关系模式加入与所述第二相似度对应的实体关系模式类中并且更新所述与所述第二相似度对应的实体关系模式类的置信度,以及将所述子句的所述关系元组加入实体关系库中,并且将所述子句中的所述关系词加入关系词本体。附记18.根据附记13所述的对实体关系模式进行提取的方法,还包括:计算所述实体之间的实体关系的强度;以及根据所述实体之间的实体关系的强度过滤假阳性实体关系。附记19.一种对实体关系模式进行提取的设备,包括:第二预处理装置,用于对原始句子进行预处理,以识别所述原始句子中表示实体的实体词;第二拆分装置,根据实体词和关系词本体中的关系词以及所述实体词和所述关系词在预处理后的句子中的特定出现序列确定所述预处理后的句子中的所述实体词之间的实体关系,并且根据所确定的实体关系将预处理后的句子拆分成子句;第二提取装置,用于提取拆分后的子句的实体关系模式,其中,所述子句的实体关系模式用所述实体词及所述实体词之间的中语境组成的关系元组来表示;第二相似度计算装置,用于分别计算所述子句的实体关系模式与根据附记7-12中任一项所述的对实体关系模式进行聚类的设备所得到的实体关系模式类之间的第二相似度;以及分类装置,用于根据所述第二相似度,将所述子句的实体关系模式分类到所述实体关系模式类中与所述子句的实体关系模式相似的实体关系模式类中。附记20.根据附记19所述的对实体关系模式进行提取的设备,所述第二相似度计算装置包括:第三相似度计算装置,用于分别计算所述子句的实体关系模式与实体关系模式类中的每个实体关系模式之间的第三相似度;以及选择装置,用于选择具有最大值的所述第三相似度作为所述第二相似度。附记21.根据附记19所述的对实体关系模式进行提取的设备,其中,所述分类装置包括:实体关系模式类确定装置,用于根据所述第二相似度和与所述第二相似度对应的所述实体关系模式类的置信度,来确定所述与所述子句的实体关系模式相似的实体关系模式类。附记22.根据附记19所述的对实体关系模式进行提取的设备,包括:第一比较装置,用于将所述第二相似度与预定阈值进行比较;以及第一更新装置,用于在所述第二相似度大于预定阈值时,将所述子句的实体关系模式加入与所述第二相似度对应的实体关系模式类中并且更新所述与所述第二相似度对应的实体关系模式类的置信度,以及将所述子句的所述关系元组加入实体关系库中,并且将所述子句中的所述关系词加入关系词本体。附记23.根据附记21所述的对实体关系模式进行提取的设备,包括:第二比较装置,用于将所述第二相似度和与所述第二相似度对应的所述实体关系模式类的置信度的乘积与预定阈值进行比较;以及第二更新装置,用于在所述第二相似度和与所述第二相似度对应的所述实体关系模式类的置信度的乘积大于预定阈值时,将所述子句的实体关系模式加入与所述第二相似度对应的实体关系模式类中并且更新所述与所述第二相似度对应的实体关系模式类的置信度,以及将所述子句的所述关系元组加入实体关系库中,并且将所述子句中的所述关系词加入关系词本体。附记24.根据附记19所述的对实体关系模式进行提取的设备,还包括:强度计算装置,用于计算所述实体之间的实体关系的强度;以及过滤装置,用于根据所述实体之间的实体关系的强度过滤假阳性实体关系。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1