通过使用可置换的剔除程序提高图形性能的方法和装置与流程
通过使用可置换的剔除程序提高图形性能的方法和装置本申请是申请日为2008年1月23日,申请号为200880001484.4的发明专利申请的分案申请。技术领域本发明整体涉及数字表示图形,尤其涉及提高生成数字表示图形的性能。
背景技术:
数字表示图形(digitallyrepresentedgraphics),例如计算机图形,在性能上一直持续不断地得到改进。在二十世纪八十年代和九十年代,出现了具有图形加速器的用于计算机和游戏控制台的显示适配器,这减轻了在图形生成时中央处理单元(CPU)的负担。起初,显示适配器提供2D图形加速,但是它们最终还包括了对3D图形加速的支持。如今显示适配器使用了通常被叫做图形处理单元(GPU)的处理单元。。由于3D图形的复杂性,当前的GPU在执行与3D图形相关的计算时使用了其大量的处理能力。显示适配器持续出现的问题是性能问题。始终会存在需要更高帧速率(每秒钟所渲染的屏幕图像)、更高分辨率和更高图像质量的新的应用和游戏,这就导致了对于在尽可能短的时间内渲染每一个屏幕图像的需求。换句话说,提高性能始终是非常重要的。一种通常的提高性能的方法就是通过提供更高的时钟速度、流水线化或者利用并行计算来提高GPU的处理能力。然而,这样通常会产生更多的热量,导致更多的电力消耗,以及为了冷却GPU产生的更高的风扇噪音。而且,每一个GPU的时钟速度也是有限制的。因此,在改进数字表示图形的性能方面仍然存在能力不足的问题。
技术实现要素:
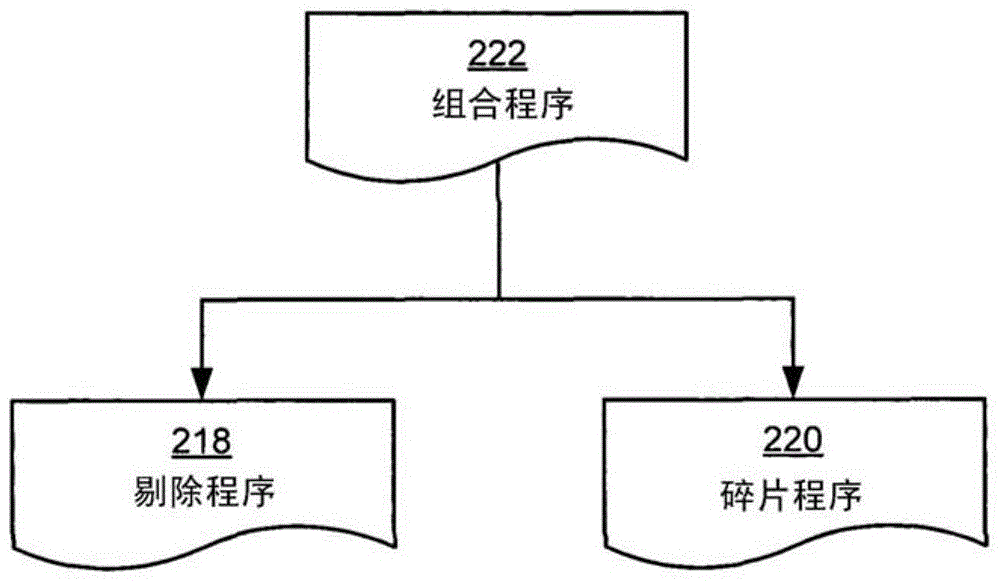
鉴于上述原因,本发明的一个目的就是为了解决或者至少减少上述的问题。通常,通过附带的独立专利权利要求来实现上述目的。根据本发明的第一方面,提供了一种用于提高数字表示图形的生成性能的方法,包括以下步骤:选择要处理的包含碎片(fragment)的瓦片(tile);对该瓦片执行剔除程序,该剔除程序是可置换的;并且对所述碎片的多个子集中的每一个子集执行一指令集,所述指令集是基于所述剔除程序的输出值而从多个指令集中选出的。因此有可能创建处理瓦片的剔除程序,并且执行这些剔除程序来提高性能。在对所述瓦片执行剔除程序的步骤中,可以对所述剔除程序的至少一部分指令使用表示整个瓦片的算法。这使得在每一次都可以处理多个碎片,从而提高了性能。在执行剔除程序的步骤中,对所述剔除程序的至少一部分指令使用区间(interval)算法。区间算法允许表示多个碎片并且实现起来相对容易。在执行剔除程序的步骤中,对所述剔除程序的至少一部分指令使用仿射算法。仿射算法可以获得对多个碎片的相对准确的表示。上述方法可以进一步包括以下步骤:向所述剔除程序提供表示所述碎片中的多个碎片的至少一个属性的值。所述瓦片的碎片的每一个子集都可以包括一个碎片。换句话说,可以针对每一个碎片执行处理。执行指令集的步骤可以包括:当所述输出值满足剔除条件时,对于所述碎片的多个子集中的每一个子集执行第一指令集,而当所述输出值不满足所述剔除条件时,对于碎片的所述多个子集中的每一个子集执行第二指令集。第一指令集可以比第二指令集包含更少的指令。第一指令集可以包含零个指令。换句话说,如果所述剔除条件为“真”,则不执行指令,这样就提高了性能。在执行指令集的步骤中,所述剔除条件可以对应于:所述瓦片的碎片对最终渲染的图像没有贡献。这是本发明中性能提高的根源。在执行指令集的步骤中,所述剔除条件可以对应于:所述瓦片的碎片对最终渲染的图像的贡献小于一阈值。这样可以在与图像质量的降低之间具有某种折衷的情况下进一步提高性能。可以根据所需要的在性能与图像质量之间的平衡来任意地设定所述阈值。在提供值的步骤中,使用区间算法,并使用所述瓦片的多个碎片作为输入,来计算所述值。在提供值的步骤中,使用仿射算法,并使用所述瓦片的多个碎片作为输入,来计算所述值。在提供值的步骤中,作为所述剔除程序请求对所述值进行访问的结果,来计算所述值。换句话说,可以使用一种“拉(pull)”的机制向剔除程序提供值。在提供值的步骤中,在执行所述剔除程序之前计算所述值。换句话说,可以使用一种“推(push)”的机制向剔除程序提供值。选择要处理的包含碎片的瓦片的步骤包括:选择至少部分地被正在处理的多边形所覆盖的瓦片。换句话说,选择多边形对其具有贡献的瓦片。所述碎片可以是与所述多边形关联的碎片。因此,只处理瓦片中的多边形的碎片。重复所述选择瓦片的步骤、执行剔除程序的步骤以及执行指令集的步骤,直到处理完所有的至少部分地被特定多边形覆盖的瓦片为止。当处理完一个多边形时,可以类似地处理下一个多边形,并以此类推,直到处理完图像的所有多边形为止。在执行指令集的步骤中,在所述选择的指令集中或在由后续使用的处理单元进行的处理中,可以使用由所述剔除程序计算的至少一个值。例如,这些值可以在随后的阶段中执行的分层深度剔除中使用。本发明的第二方面是适用于生成数字表示图形的显示适配器,包括:用于选择要处理的包含碎片的瓦片的模块;用于对所述瓦片执行剔除程序的模块,所述剔除程序是可置换的;以及用于对所述碎片的多个子集中的每一个子集执行指令集的模块,所述指令集是基于所述剔除程序的输出值而从多个指令集中选出的。应当明白,本发明的第二方面可以以与本发明第一方面的任意特征相对应的特征的任意组合一起来实现。本发明的第三方面是一种包含软件指令的计算机程序产品,所述软件指令当在控制器中执行时,执行根据本发明的第一方面的方法。本发明的其它目的、特征和优点将会从下面的详细描述中、附带的从属权利要求中以及从附图中看到。通常,在权利要求中使用的所有术语都可以根据该技术领域中的通常含义进行解释,除非本文中另有明确定义。所有的“一个【元件、设备、组件、装置、步骤等等】”都可以开放性地解释为是元件、设备、组件、装置和步骤的至少一个实例,除非文中另有明确声明。本文中公开的任意方法中的步骤都并非必然以公开的顺序执行,除非有明确地声明。附图说明现在结合附图对本发明的各个实施例进行更详细描述,其中:图1是一个方块图,示出了本发明的一个实施例的一个显示适配器中不同的实体之间如何互相作用。图2是一个示意性方块图,示出了图1的显示适配器中使用的不同的程序之间的关系。图3示出了在图1的显示适配器中使用区间算法剔除瓦片的一个实例。图4a和4b示出了剔除处理的流程图,其可以在图1的显示适配器中执行。图5示出了包含图1的显示适配器的计算机的概览架构。图6a是一个显示图,示出了图1的显示适配器中的一种输入值异常情况。图6b是图6a的情况中输入值的图表。图7a和7b是图1的显示适配器中使用的纹理的说明性透视图。图8a-d是图1的显示适配器中使用的纹理的说明图。具体实施方式下文结合附图对本发明进行更完整描述,其中示出了本发明的一些实施例。然而,本发明可以以许多不同的形式体现,而不应当限于在文中列举出的实施例;而且,通过实例化方式提供这些实施例以便使得本公开内容更加透彻和完整,并且可以将本发明的范围传达给本领域技术人员。文中相同的数字表示相同的元件。图1是一个方块图,示出了本发明的一个实施例中的显示适配器100中不同实体之间的相互作用。多边形设置块102用于按照连接的CPU570的指令(图5)来设置多边形。虽然可以使用任意多边形,但是一般使用三角形。对于每一个多边形,瓦片光栅化器104都对该多边形进行分割,以便将其渲染到一个或多个瓦片中,其中每一个瓦片都由该多边形至少部分地覆盖。通常,瓦片是一组碎片。在一个实施例中,瓦片是包含多个碎片的二维矩形。这些碎片中的每一个都对应于一个像素,并且包含对于渲染该像素并且测试该像素是否应当渲染在显示屏上而言所必需的数据。虽然本发明的范围可以包含任意的瓦片尺寸,但是瓦片通常的尺寸是8×8个碎片。分层深度剔除块106执行分层深度剔除(hierarchicaldepthculling),其基于深度缓冲进行剔除。这里,可以执行保守的测试来证明该瓦片是否被深度缓冲器中的内容所覆盖。换句话说,从浏览者的角度看,测试是否存在另一个完全覆盖该瓦片中的多边形的渲染对象。如果是这种情况,就可以剔除整个瓦片,也就是,将瓦片挑选出来以便实现更少的处理,例如将该瓦片跳过。从而可以获得性能的提高。应当明白,该分层深度剔除可以在可编程剔除单元108的剔除之前或之后执行。该单元是一个固定的功能,这意味着其并不是执行一个可置换的程序。在可编程剔除单元108中,根据可置换剔除程序118来执行剔除,可置换剔除程序118也称为可置换剔除模块。下面结合附图4a详细解释该剔除程序118的细节和效果。在碎片光栅化器110中,由可编程剔除单元108处理的瓦片被细分成覆盖多边形的多个碎片。这些碎片中每一个都对应于一个像素并且包含对于渲染像素并且测试该像素是否应当渲染在显示屏上而言所必需的数据。碎片数据包括光栅位置、深度、颜色、纹理坐标、模板(stancile)、阿尔法(alpha)(用于混合)等。对于每一个像素,都可能存在多个碎片样本。在碎片程序单元112中,使用碎片程序120处理从碎片光栅化器输出的碎片。这个单元的目的是执行诸如将先前计算的颜色与纹理进行组合之类的任务,并且添加诸如雾之类的效果,以及如果有可能的话,识别不需要渲染的碎片,即碎片剔除。纹理单元114用于纹理查找,例如使用一维、二维、三维、四维和立方图cubemap纹理进行纹理查找,并且按照需要将它们提供给可编程剔除单元108和碎片程序单元112。混合/深度/阿尔法单元116使用由碎片程序单元112提供的碎片在将碎片写入目标缓冲器之前执行深度测试、阿尔法测试和混合。图2是一个示意性方块图,示出了在图1的显示适配器100中使用的不同程序之间的关系。原理是组合程序222可以用于自动生成在可编程剔除单元108中所使用的剔除程序218以及在碎片程序单元112中所使用的碎片程序220。可选的,程序员可以分别编写剔除和碎片程序218和220。作为一个实例,考虑组合程序222的伪代码片段(1),其最初目的是被编写为碎片程序:DP3d,n,l(1)KILd<0TEX2Dc,t0,r1MULout.col,d,c这段程序通过使用DP3指令计算光(l)和法线(n)矢量之间的点积结果(d),来执行基本扩散照明。n和l向量对于每一个碎片都是变化的。KIL指令终止表面法线并不面向光的所有碎片,这通过使d小于0来指示。TEX2D指令在c中执行二维纹理查找。最后,将结果(d)乘以扩散材料系数(c)。在本文中提到的新方式中,对于剔除由碎片构成的整个瓦片来说,KIL指令是一个机会。但是为了完成它,应该保守地证明对于该整个瓦片而言满足用于KIL指令的条件。紧跟着,在该实例中,还必须能够保守地计算DP3指令的值,因为KlL指令依赖于该指令的结果。另外,必须能够获得对于整个瓦片的输入(在这种情况中是法线n的向量和光l的向量)的保守边界,因为DP3指令进而依赖于这些值。为了实现这个保守计算链,可编程剔除单元是基于与碎片程序单元相同的指令集的。而且,并非如同在处理碎片时通常的情况下一样使用浮点变量作为指令的源和目标寄存器,而是使用了区间,并且使用区间算法的原理来实现该指令。作为一个简单的实例,考虑一个标准的ADD指令:对于相应的可编程剔除单元区间指令,用区间来置换操作数,其中,一个区间(例如)被如下定义:从而可编程剔除单元ADD指令如下:其中,区间加法运算被实现为:可以看到,该区间加法的结果包括所有可能的“普通”加法的结果,或者更加正式的,其可以满足其中因此,其保守来说是正确的。采用类似的方式来重新定义碎片程序指令集中的每一个指令的行为。所得到的增强指令的全部详细情况如下所示。表1:实施例中的指令的运算和条件表达除了使用区间指令之外,输入也必须被定义为区间。因此,必须能够为在由碎片构成的整个瓦片上的内插的量来计算保守的边界。这在下面详细地解释。应当注意,虽然这里使用了区间算法,但是也可使用表示整个瓦片的任意适当的算法。例如,在本发明的范围内也同样可以使用仿射算法。在上面的情况中,剔除程序218可以从组合程序(1)中自动获得。下面是获得的剔除程序:另外,这里的碎片程序220是从组合程序(1)中获得的,其与组合程序220相同。下面是碎片程序:DP3d,n,l(7)KILd<0TEX2Dc,t0,r1MULout.col,d,c图3示出了在图1的显示适配器100中能够使用区间算法来剔除瓦片的实例。对于由碎片构成的整个瓦片来说,假设确定了其法线330的输入区间334是并且其光向量332的区间336是如图3所示。假设z坐标为0,这样可以简化说明的实例。这些区间表示之间的点积得到了(参见表1中DP3指令)。因此可以得出结论,最多为由于该值严格地小于0,在上面结合图2解释的剔除程序中,可以剔除该整个瓦片而不用对每一个碎片执行碎片程序,下面将结合图4a进行更进一步的描述。这就是在本发明中性能提高的根源。图4a示出了可以在图1的显示适配器100中执行的剔除处理的流程图。当该流程开始时,已经选择了要渲染的多边形。在选择要处理的瓦片的步骤440中,选择一个瓦片,其中所选择的瓦片至少部分地由多边形覆盖。然后在执行剔除程序的步骤452中执行剔除程序。在这个实施例中,当剔除程序请求输入值时,该流程前进到为剔除程序步骤454a提供输入值。所述输入值是与以某种方式表示瓦片中所有碎片的特征相关的值。例如,输入值可以是法线、位置坐标、光向量、颜色、纹理坐标等等。在这个实施例中,使用区间算法计算所请求的输入值。换句话说,根据“拉”机制,只有当需要时才计算输入值,这与与下文中参考图4b解释的“推”机制相反。剔除程序的结果就是当前处理的瓦片是否应当被剔除。这可以很严格地确定,从而只有当前多边形在该瓦片的区域中不会对最终渲染的图像产生贡献时才剔除该瓦片。可替代的,可以执行有损剔除,从而如果在当前瓦片的区域中当前多边形对最终渲染的图像的贡献落在某一阈值之下时,则剔除该瓦片。当剔除程序完成处理时,流程继续到判断剔除条件是否为“真(true)”的步骤456。在这个步骤中,根据剔除程序的输出来判断是否对当前处理的瓦片执行剔除。如果要执行剔除,则流程继续到执行指令集A的步骤458。反之,则流程继续到执行指令集B的步骤460。在一个实施例中,如果剔除条件为“假(false)”,则将该瓦片打碎成多个更小的瓦片,并且流程返回到选择要处理的瓦片的步骤440。对于越来越小的瓦片连续地执行以上步骤,从而实现分层、多级剔除处理。应当注意,除了剔除条件之外,剔除程序还可以输出其它结果。这些结果可以向下发送到图形流水线以便进行进一步的处理。这样的实施例的一个实例包括反转分层深度剔除单元106(图1)和可编程剔除单元108(图1)的顺序。可编程剔除单元计算在一个瓦片中深度值的边界或者区间,然后将这个区间发送到分层深度剔除单元。分层深度剔除单元然后基于由程序计算的深度值来执行剔除。在执行指令集A的步骤458中,针对瓦片的子集(通常是碎片)执行指令集A。这些碎片通常共同覆盖该瓦片的所有像素,该瓦片覆盖被处理的三角形。在执行指令集B的步骤460中,针对瓦片的子集(通常是碎片)执行指令集B。这通常是在瓦片级之后的一个对碎片进行渲染的传统处理。指令集A通常比指令集B具有更低的要求,从而导致当剔除条件被确定为“真”时,对于瓦片所处理的指令数量较少,从而获得性能上的提高。在一个实施例中,指令集A为空,从而可以大大地减少处理量,也就是提高了性能。图4b示出了与参考图4a描述的流程基本上相同的流程。选择要处理的瓦片的步骤440、执行剔除程序的步骤452、判断剔除条件是否为“真”的步骤456、执行指令集A的步骤458、执行指令集B的步骤460、判断是否有更多瓦片的步骤462全部都等同于图4a的相应步骤。然而,在这里向剔除程序步骤454b提供输入值是在执行剔除程序之前执行的。在这个步骤中,计算所有相关的输入值(在这个实施例中使用区间算法进行计算)并提供这些值,从而使得剔除程序可以访问这些值。这样对于输入值计算来说实现了一个“推”机制。图5示出了包含图1的显示适配器100的通用计算机583的概览框架图。该计算机具有控制器570,例如CPU,其能够执行软件指令。控制器570连接到易失性存储器571(例如随机存取存储器(RAM))和显示适配器500、100。显示适配器500、100进而连接到显示器576,例如CRT监视器、LCD监视器等等。控制器570还连接到持久性存储器573(例如硬盘驱动器或者闪存存储器)和光存储器574(例如诸如CD、DVD、HD-DVD或者蓝光光盘之类的光介质的读取器和/或者写入器)。网络接口581还连接到控制器570以便提供对网络582的接入,网络582例如为局域网、广域网(例如,因特网)、无线局域网或者无线城域网。通过周边接口577,例如通用串行总线、无线通用串行总线、火线、RS232串行、中心并行(Centronicsparallel)、PS/2、CPU570类型的接口,可以与鼠标578、键盘579或者任意其它外部设备580(包括游戏杆、打印机、扫描仪)等等进行通信。应当注意,虽然上面描述的通用计算机实现了本发明,但是本发明还可以包含在使用数字图形,尤其是3D图形,例如游戏控制台、移动电话、MP3播放器等等的任意环境中。现在描述如何使用区间算法计算输入值,假设了如上所述那样实现指令集。随后可以对由多个碎片构成的整个瓦片执行剔除程序。而且,为了如此执行,还需要计算对于可变(或者内插的)输入的边界区间。首先,使用内插在瓦片的所有四个角内计算可变属性的值。然后计算这四个值的边界区间,并且将其称为还计算在三角形顶点处的可变属性的边界区间,并且将其称为在整个瓦片上的可变属性的最终边界区间可以如下计算应当注意,还有其它方法可以计算区间,例如通过考虑覆盖瓦片的所有碎片来进行计算。最后,必须处理异常情况,如图6a中所示。这里,以棋盘纹理686的形式示出了三角形685上的透视矫正内插(perspectivecorrectinterpolation)。如所见到的,该纹理关于投影线687镜像,该投影线687是三角形685的水平线在其无限大时所投影的线。该镜像效果是由透视矫正内插中使用的划分所引起的反投影的形式。现在,假设需要在覆盖了该投影线的瓦片688上计算某种可变属性的边界区间。图6b示出了透视矫正内插函数690,以及当内插瓦片688的四个角时获得的值691a-d。注意,这些角的边界区间692明显不正确,因为该区域没有包含在这个区间内该函数690的所有值,这是因为该函数690在该投影线上接近无限大。通过设置为作为用于覆盖该投影线的瓦片的边界区间,来处理这种异常情况。人们可能会争论这个区间是过度保守的,但是这些有问题的瓦片很少以至于很难引发更复杂的计算。在这个实施例中,只穿过了实际覆盖该三角形的瓦片,并且使用透视矫正重心坐标(barycentriccoordinate)来进行内插。在GraphicHardware第65-72页中的MCCOOL,M.D.,WALES,C.和MOULE,K.2002,“IncrementalandHierarchicalHilbertOrderEdgeEquationPolygonRasterization”公开了所述重心坐标。当对于瓦片的角计算透视矫正重心坐标时,可以很容易地检测到这些有问题的瓦片。透视矫正重心坐标被表达为有理函数,并且如果对于任意的瓦片角来说分母小于0,那么该瓦片跨过投影线。下面将公开如何执行N维纹理查找。用于执行N维纹理查找的区间指令对于用于置换映射细分(replacementmapsubdivision)的已知方法而言是一种改进。通常的方式是提供这样的一种快速有效的手段:即,在给定的区域上计算纹理数据的边界区间。这个实例的剩余部分将仅仅考虑二维纹理,但是其具有明显的普遍性。首先,我们对于经过了基于区间的纹理查找的每一个纹理计算两个Mipmap金字塔。如图7a和7b所示,每一个元素(例如Mipmap中的元素793)都都计算为该金字塔中在其下紧邻的四个对应纹理像素(例如元素794a-d)中按成分(component)计的最小值(如图7a所示)或者按成分计的最小值(如图7b所示)。最终结果可以被看作是边界区间的Mipmap金字塔。可以由驱动器很容易地处理该预先计算的类型,这类似于如何自动产生标准Mipmap。当执行纹理查找时,我们希望在轴对齐的边界框(其是纹理坐标区间)上计算纹理数据的边界区间。首先,我们计算适当的Mipmap等级如下:其中是未归一化的整数纹理坐标的二维区间(也就是,它们包括纹理的大小)。它们都被适当地进行了舍入,以使得对于i∈{x,y},ti是向下舍入(floored),是向上舍入(ceiled)。当转换到该Mipmap等级时,在任意维度上都不会大于一个纹理像素宽度,其最宽的维度将会是纹理像素宽度的至少1/2。这样,我们得到了四种可能的纹理坐标区间的情况,如在图8a-d中所示的。在用于普通线性内插的存取方案中,我们始终从纹理像素796中采样2×2纹理像素的正方形,其左下角在(tx,ty)处。然后将实际覆盖纹理坐标区间的纹理像素的颜色的边界计算为纹理查找的结果。也就是,我们放弃了由图8a-c中标记795所指示的用阴影表示的纹理像素。由于转换成的Mipmap将被舍入为最接近的整数坐标,因此通过仅比较最后一个比特就可以非常有效地实现这种覆盖测试。我们的纹理查找流程与标准的“三线性”滤波纹理查找的计算开销基本相同。最大的不同在于,我们需要能够从两种不同的Mipmap金字塔的相同等级中采样而不是从两个相邻的等级中,以及我们将最终的结果计算为边界,而不是使用线性内插。读者还应当注意,这种策略实质上支持所有不同类型的环绕模式(wrappingmode),例如夹紧(clamp),重复和镜像重复。在Mipmap等级计算之后,可以将适当的环绕模式很简单地应用到区间坐标上,从而得到期望的结果。还可以示出,对于滤波纹理查找来说,只要滤波纹理查找使用有限的差值来计算导数以及只要纹理滤波器不向所述导数所跨越的区域外部延伸,这种纹理查找流程就是保守的。如果有更多的纹理化单元可用,就可以改善区间纹理查找的边界。标准的纹理查找假设我们可以每次都能读出2×2个纹理像素的块。如果我们具有足够的硬件资源读取4×4个纹理像素的块,那么我们可以在Mipmap层次结构中向下移动一个等级并且能获得更精确的结果。另外一个重要的观察就是,我们仅仅需要创造在剔除程序中实际使用的Mipmap等级。这种优化对于在屏幕空间中发生的算法来说尤其重要,例如不受顺序约束的透明度。在这种情况中,我们预先知道我们仅仅需要在其基本等级上的纹理,以及对应于屏幕上瓦片的Mipmap等级。注意,这种瓦片信息在当今的硬件中是可以得到的,并且可以自由读取。最小和最大深度值例如可以在分层深度剔除单元中得到。还有可能(但是可能性较小)已经为了压缩目的而计算了最小和最大颜色,否则的话我们就需要计算它们。对于纹理的底层和瓦片Mipmap等级的渲染的扩展会大大地加速屏幕空间算法。我们可以使用与二维纹理相同的方法来为立方图计算最小/最大Mipmap金字塔。然而,在接近立方体的边缘和角的位置处,必须进行特别的处理。对于边缘,我们将在边缘的两侧上的四个纹理像素的最小值或最大值计算为Mipmap颜色,对于角,我们将在从那个角发出的三条边上的四个纹理像素的最小值或最大值计算为Mipmap颜色。在边缘的相对两端上的纹理像素将因此共用在较高Mipmap等级上的相同颜色。类似的,在一个角内的三个纹理像素也将共用一个相同的颜色。应当注意,最高等级的Mipmap将包含在整个立方体上的最小和最大值,如所期望的那样。我们现在可以使用该Mipmap金字塔来进行保守的立方体图查找,并且仅对立方体的一侧进行访问。首先,我们计算等效地基于主轴的区间。给定一个纹理坐标区间我们将主轴i定义这样的轴:即ti和在其上具有相同符号并且min在其上是最大的。如果ti和在所有轴上具有不同符号,那么我们就不能找到主轴。然而,只有在原点位于纹理坐标区域内时才发生这种情况。在这种情况中,纹理坐标区间将投影到整个立方体图上。我们可以通过选择最高的Mipmap等级并且对任意的立方图表面进行采样来处理这种情况。一旦我们找到主轴,我们就保守地将纹理坐标区间投影在立方图的相应侧上。通过分别投影两个剩余轴中每一个的边界来实现该投影。我们考虑一种实例,在该实例中,x是主轴,y是我们想要为其投影边界的轴。那么对于纹理坐标区间(注意,由于x轴在这种情况中不是主轴,导致没有区间可以跨越y轴)和我们必须进行投影来计算边界的极值点来说有六种可能的情况。幸运的是,很容易确定哪些是这些极值点。这足以看到纹理坐标区间的符号,并且通过表查找来得到极值点。我们对于剩余的两个轴来的极值点进行投影以形成二维投影坐标区间。该区间用于计算Mipmap等级以及执行二维纹理查找,这与上面针对二维情况所描述的方法相同。由于在Mipmap生成期间的信息丢失(bleeding),可能会显示出这种算法是保守的。另外,其计算量不大。找到主轴,并且投影的计算开销会两倍于正常的立方体映射实现,考虑到我们使用了区间,这种情况是合理的。另外,我们需要表格函数来根据符号求解极值点,但是这已经是计算量非常小的情况了。以上已经主要结合几个实施例对本发明进行了描述。然而,本领域技术人员都很容易理解,除了以上公开的实施例之外的其它实施例在本发明的范围内都是可行的,本发明的范围由附带的发明权利要求定义。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1