一种对乱序数据流排序的方法与流程
本发明涉及数据流排序方法,尤其涉及在内存受限系统中对乱序数据流进行高性能高可用性排序的方法。
背景技术:
数据处理系统中,数据源会向外产生大量数据,相同类型的数据构成一串数据流。所谓的无序数据流,即是该数据流中的各个数据到达的先后顺序并非与数据产生的顺序相同。而在数据处理系统的下游,通常要求输入数据是按其产生顺序(序号)到达的,因此需要一个中间的排序环节进行数据排序。由于数据乱序的先天特性,序号较小(表示先生成)的数据可能较晚才会到达,在不可改变上游系统下发数据顺序的情况下,排序模块需要缓存所有数据,直到序号正确的数据到达。专利《一种实现多引擎并行处理器中数据包的方法》(专利号200510093220)将上游数据进行标记所属通道,通过在不同引擎上构建排队缓存,每次由数据选中的通道输出数据办法来实现排序,可是该方法在内存受限的情况下使用受局限。专利《数据排序系统以及可携式装置中的数据排序方法》(专利号200910261953)统计含某些属性数据的频率值,计算数据的排序值,并由专门的排序单元生成排序结果。该方法利用统计信息预测输入数据的模式,对于到达数据顺序随机的情况并无更多优点。专利《重排序数据分组的方法和设备》(专利号01125541)将输入数据分组,以桶的方式对桶内数据做排序,当桶内数据顺序完成时,发送数据。此方式以桶为单位发送数据,发送效率不高,且受内存制约。传统的排序方法要求指定长度的输入规模,且对于缺号断号的情况只能等待。而在高性能高可用性领域内,由于数据缺号后等待而引起的数据阻塞甚至是丢弃数据是危险的,而全面缓存数据的办法在内存受限的系统中无法施行。
技术实现要素:
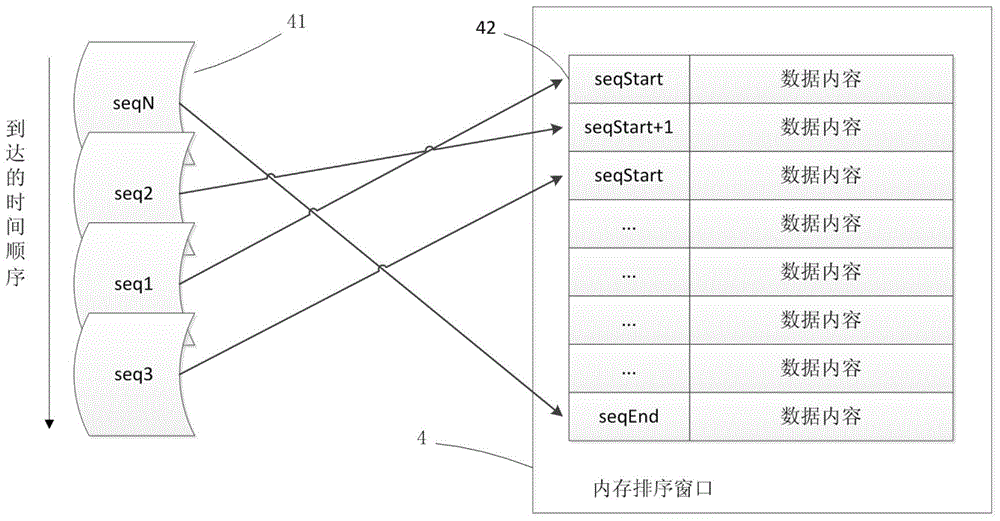
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种能够在内存受限的情况下对高速乱序数据流进行高性能、高可用性地排序的方法,用于解决传统的排序方法要求指定长度的输入规模,且对于缺号断号的情况只能等待,在高性能高可用性领域内,由于数据缺号后等待可能引起的数据阻塞甚至是丢弃数据,而全面缓存数据的办法在内存受限的系统中无法施行的等问题。为解决上述问题,本发明提供一种对乱序数据流排序的方法,应用于数据处理设备中,其特征在于,所述数据处理设备至少包括第一缓存及第二缓存,且所述第一缓存大小固定,所述方法包括:读取到达数据,并依据到达数据的数据序号将该到达数据插入到第一缓存中预设位置,如果无法插入所述第一缓存,则将到达数据插入到第二缓存中预设位置;从第一缓存中依序读取数据,判断读取位置上是否有有效数据,若是,则发送给下游,若否,则等待,直至该位置存有有效数据时读取并发送给下游;将第二缓存中的数据回载到第一缓存中。优选地,上述本发明的排序方法中,第二缓存可以是一个或者多个文件。由于本发明的排序方法中,第一缓存的大小固定,所以本发明的方法对于一级缓存,例如内存,受限制的情况下,能够很好地工作,并且第二缓存的组织形式多样,因此方法适用范围广。本发明的优选实施例使用文件作为第二缓存,提高了缓存容量、扩展性好并能随机读取,所以减小数据缺号后的等待,减小数据阻塞,避免数据丢弃。附图说明图1显示根据本发明的对乱序数据流排序方法的数据流图。图2显示图1中插入操作11的原理图。图3显示图1中插入操作12的流程图。图4显示图1中发送操作2的流程图。图5显示图1中回载操作3的流程图。图6-图15显示利用本发明对乱序数据流排序方法的一个实施例对数据流排序过程的示意图。具体实施方式以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。现在参看附图,需要说明的是,各附图中,相同的操作或者组件,如无特别说明,则都使用相同的标记。先看图1,图1显示根据本发明的对乱序数据流排序方法的数据流图。图1中的上游数据表示乱序的数据流,操作1表示插入操作,插入操作过程中对数据完成排序。图上可以看到,插入操作1可以分为子操作11和12,其中子操作11表示将数据插入第一缓存4中,子操作12表示将数据插入到第二缓存5中。上游数据到达后,被按一定的规则分别插入第一缓存4和第二缓存5,插入的过程就完成排序。发送操作3再按一定的规则,将第一缓存4中的数据向下游发送,就得到了有序的下游数据。下面结合图2-图5详细介绍本发明对乱序数据流排序方法实施例的各部分操作。参看图2,图2显示了图1中插入操作11的原理图。下面对图2中的标记及插入操作11中的重要参数做详细介绍:标记4对应图1中的第一缓存,在本实施例中,第一缓存设置在内存中,称为内存排序窗口。标记41指向的一系列方块表示上游到达的数据流,各方块代表数据流中的数据,从上到下的排列顺序代表到达顺序,seqN、seq1……表示数据在源头的产生顺序,简称为数据序号。图中可以看出,数据的到达顺序与数据的产生顺序并不一致,所以标记41是乱序数据流,经排序后,数据顺序应当变成seq1、seq2……seqN。标记42表示排序窗口4的头部位置,seqStart表示内存排序窗口4头部位置42中数据的数据序号。WindowSize表示内存排序窗口大小。lastSendSeq表示已经排序完成且已经发送到下游的最大数据序号。当数据流41到达时,首先根据数据序号,通过公式:lastSendSeq≤SeqN≤lastSendSeq+WindowSize(1)判断该数据是否处于排序窗口4所能容纳的数据范围中。当数据序号满足公式(1)时,表示该数据处于排序窗口4所能容纳的数据范围中,可将数据插入排序窗口。如果不满足公式(1),表示该数据不处于排序窗口4所能容纳的数据范围,则需要执行插入操作12,插入操作12将在下文中结合图3做详细介绍。本例中插入操作11的规则是先按公式:Index=seqNmodWindowSize(2)计算出数据在排序窗口4中的位置。公式(2)中,seqN表示数据序号,WindowSize表示排序窗口4的大小。mod为求模运算(求模结果为0时,本领域技术人员可以根据需要对Index进行修正)。通过公式(2)求得的Index表示数据序号为seqN的数据应当存放于排序窗口4中第Index个位置。此种方式天然地将数据放置到排序后它应该存在的位置,从而实现排序功能。需要说明的是,本领域技术人员可以修改上述将数据插入第一缓存的策略,例如但不限于,采用不同于公式(2)的方式计算数据在排序窗口4中的位置,或者采用映射的方式将数据序号映射到排序窗口4内的某个位置,同时将该位置映射至内存中该数据内容的存储单元等等,这些修改均未超过本发明的构思。如果收取到的数据不能插入第一缓存4,即本例中收到的数据不处于排序窗口4所能容纳的数据范围,则需要执行插入操作12,将数据存插入第二缓存5。本实施例中,第二缓存5采用了缓存文件的实现方式。每一个缓存文件中的每一条数据大小有其上限,固定其为静态值。缓存文件中的条目数也是确定的,因此每个缓存文件大小总是固定的。缓存文件可以有多个。每个缓存文件有如下属性:beginPos:该文件中起始位置数据的数据序号;endPos:该文件中结束位置数据的数据序号;FileSize:该缓存文件的大小,该值是一个静态值;lastReadPos:该缓存文件最后一次读取的数据的数据序号;标记位:该缓存文件中每条数据的对应一个标记位,表示该条数据的有效性,即表示该条数据是否已经被回载过。本例中,为了说明方便,各缓存文件采用相同的大小,且各缓存文件的FileSize、endPos、beginPos与排序窗口4的大小WindowSize有如下的关系:endPos-beginPos=N*WindowSize=FileSize(3)下面参看图3,图3中显示了图1中插入操作12的流程图。插入操作12中,首先遍历每一个缓存文件,如果到达数据的数据序号落在当前缓存文件的beginPos与endPos之间,则将到达数据插入当前缓存文件中。如果遍历完所有的缓存文件,未能找到一个文件使得当前到达数据的数据序号落入其beginPos与endPos之间,则再次遍历缓存文件以寻找失效文件。所谓失效的文件,是指该文件中的endPos小于已经排序完成且已经发送到下游的最大数据序号lastSendSeq。找到失效文件后,则按下述公式(4)刷新该文件的beginPos与endPos,其中round函数表示向下取整:beginPos=round[(seqN-WindowSize)/FileSize]*FileSize+WindowSize(4)endPos=beginPos+FileSize-1并删除该文件中原有的所有数据,然后再将到达数据插入该文件。如果遍历完缓存文件后,未能找到失效文件,则生成新缓存文件,再将到达数据插入该新缓存文件中。下面介绍将数据插入缓存文件的一种方法,先用公式(5)计算数据插入位置insertPos及偏移offset:insertPos=seqN-beginPos+1(5)offset=insertPos*dataSize其中,dataSize表示数据的大小,根据计算出的插入位置insertPos即可将数据插入缓存文件,并在插入数据后,置文件中该数据的有标志位置为有效。至此,插入操作12完成。需要说明的是,本领域技术人员可以对本例中的插入操作12作出变化,例如但不限于:使用内存数据库或者其它方式实现第二缓存,或者缓存文件的大小可以不同,或者缓存文件属性与排序窗口满足公式(4)之外的其它关系,或者将数据插入文件时采用其它的策略等等,所以这些变化均未超出本发明的构思。下面参看图4,图4显示了图1中发送操作2的流程图。当排序窗口4中被插入了数据,即完成了部分数据的排序后,就可以将排序窗口4中的数据按一定的方法向下游发送以得到有序的下游数据流。本例中,发送操作2是依次并循环地从排序窗口4的头部位置扫描至尾部位置。如果扫描到数据且数据序号是连续的,则将该数据向下游发送,并将lastSendReq增加,否则等待。本例中,数据序号连续是指该数据的数据序号大于lastSendReq值且与lastSendReq值相邻。需要说明的是,发送操作2的发送策略需要与插入操作11对应,本例中,由于插入操作11采用了公式(2)计算数据在排序窗口4中的位置后将数据插入,所以发送操作2采用了依次循环扫描排序窗口4的方式。如果插入操作11采用了其它插入的方式,则发送操作2也相应地需要改变策略,这些改变对于本领域技术人员来说很容易想到,并且均未超出本发明的构思。下面参看图5,图5显示了图1中回载操作3的流程图。回载操作3是将第二缓存中的数据回载到排序窗口4中经发送操作2扫描并发送过的位置,以供发送操作2扫描并发送给下游。如图5所示,回载操作3循环地扫描缓存文件,对于当前文件,首先判断该文件数据是否有效。此处判断是指判断当前文件的lastReadPos是否超过了当前文件的endPos,如果超过说明当前文件中的数据已经全部被回载完成,不需要再回载。如果未超过,则继续判断位于lastReadPos的数据是否有效且是否处于排序窗口4所能容纳的数据范围中,如果数据有效且该数据处于排序窗口4所能容纳的数据范围,则读出该数据插入排序窗口,然后将该数据的标志位改为无效,并将lastReadPos加1。以上对本发明的对乱序数据流排序方法的各操作做了详细介绍,本发明可以对一路乱序数据流排序,也可以对多路乱序数据流排序。为使本发明的原理更清楚,下面结合图6-15介绍如何用本发明一个实施例对两路乱序数据流进行排序。图6显示了两个上游数据的输入流、内存排序窗口4、缓存文件5的初始状态。输入队列中,每个方块表示一个数据,队列中至下向上表示数据到达的顺序,方块内数字的含义表示数据的实际生成的顺序,数字越小表示数据越早生成。图中可以看到,两个输入流中是乱序数据,需要将其合并成为一个有序流。为了说明方便,对图6的标记和参数约定如下:排序窗口大小WindowSize为4,缓存文件个数1,以标记51表示,每个缓存文件的大小FileSize为2,AN表示当前描述的数据是来自A队列数据序号为N的数据,SN表示当前描述的数据是位于排序窗口中数据序号为N的数据,BUFn_N位于缓存文件n中的全局序号为N的数据。InsertA/B:表示两个第一缓存插入线程,分别读取输入队列A/B的数据后插入排序窗口4。其中InsertA/B两个线程的处理是独立的,且为说明简便,这里并不完整覆盖两个队列的数据在全局时钟下的16种到达顺序,仅描述其中一种到达顺序。Read:表示发送线程,用于读取排序窗口4中的数据并向下游发送。Store:表示第二缓存插入线程,用于将数据缓存进第二缓存5中。Load:表示回载线程,用于将数据从第二缓存5中读回至排序窗口4。后续的图7-14中,如无特别说明,相同的标记也遵守上述约定。初始状态下,seqStart为1,lastSendSeq及两个缓存文件的beginPos和endPos都为0。排序开始,首先InsertA/B分别从队列A/B中读取了A3、B1、B4,由于根据公式(1)得:lastSendSeq=0<1,3,4≤4=lastSendSeq+WindowSize所以三个数据序号范围都处于排序窗口4之内,所以根据公式(2)计算出三个数据在排序窗口4中的位置分别为1、3、4(本例中,求模运算的值为0时修正为4,本领域技术人员可以根据需要采用其它修正策略),将这些数据插入排序窗口4,插入后状态如图7所示。Read线程可与InsertA/B线程同时工作。它循环扫描排序窗口4,将数据1发送给下游,并将lastSendSeq更新为1。发送后的状态如图8所示。随后Read线程顺序地读取排序窗口4的位置2,但在排序窗口位置2处发现没有数据,所以Read线程在此阻塞,等待数据。Read线程工作的同时,InsertA/B线程分别从队列A/B中读取了A5、A2,对于A5,按公式(1)得:lastSendSeq=1≤5≤lastSendSeq+WindowSize=1+4=5所以其位于排序窗口4的数据范围内,再根据公式(2)计算其在排序窗口的位置为:5mod4=1所以A5放在排序窗口4中位置1的地方,同理A2是放在排序窗口中位置2的地方。A5、A2插入后的状态如图9所示。InsertA/B继续读取到数据B7,根据公式(1)发现B7不属于排序窗口4所容纳的数据范围,所以需要Store线程将其插入第二缓存。又因为初始时,缓存文件51的biginPos=0,endPos=0,根据上述图3中所示流程,B7也能插入缓存文件51。所以Store线程再寻找失效文件,发现缓存文件51为失效文件,于是根据公式(4),刷新缓存文件51的beginPos=6,endPos=7,再根据公式(5)计算出B7在缓存文件51中的插入位置为2,于是Store线程将B7插入缓存文件1的位置2处,插入后的状态如图10所示。InsertA/B继续读取到数据B8,根据公式(1)发现B8同样不属于排序窗口4所容纳的数据范围,所以也需要Store线程将其插入第二缓存5。由于B8不应存在缓存文件51中(8>7),并且此时也没有失效文件,所以新建一个缓存文件52,计算缓存文件52的beginPos=8,endPos=9,再根据公式(5)计算出B8在缓存文件51中的插入位置为1,所以将B8插入缓存文件52的位置1处。插入后的状态如图11所示。InsertA/B继续读取到数据A6,根据公式(1)发现A6同样不属于排序窗口4所容纳的数据范围,所以也需要Store线程将其插入第二缓存5。经计算发现A6应当插入缓存文件51中(beginPos=6≤6≤7=endPos),再根据公式(5)计算出应将A6插入缓存文件51的位置1处。插入后的状态如图12所示。Store、InsertA/B线程工作的同时,Read线程仍在工作,当Read线程发现排序窗口4的位置2处有数据S2(因Insert线程插入了A2)后,结束等待,将S2向下游发送,并继续依次扫描、发送,扫描到排序窗口4的尾部位置并发送完数据S4后,循环到排序窗口4的头部位置,更新排序窗口4的seqStart值为5,并继续依次扫描、发送,发送完头部位置的数据S5后,更新lastSendSeq为5,继续扫描到排序窗口4的位置2处时发现没有数据了,则等待,如图13所示。Load线程可与Store、InsertA/B、Read线程同时工作,其逐一扫描每个缓存文件,发现缓存文件中的数据属于排序窗口4所容纳的数据范围后就将文件中有效的数据依次回载入排序窗口4。回载完成后的状态如图14所示。Read线程发现排序窗口4的位置2处有了数据S6后,结束等待,将S6向下游发送,并继续扫描、发送直到所有数据处理完毕,处理完成后的状态如图15所示。经过上述过程,上游的乱序数据流被排序并被发往下游。上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。本领域技术人员可以根据需要对上述实施例进行修饰或改变。例如但不限于:修改插入、发送、回载的策略,采用非文件方式作为第二缓存等等。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1