基于文本流网络的实时个性化视频推荐方法与流程
本发明涉及互联个性化推荐技术领域,尤其涉及一种基于文本流网络的实时个性化视频推荐方法。
背景技术:
随着互联网技术的发展,特别是WEB2.0时代的到来,在线视频的传播已经达到了前所未有的水平。虽然如此海量的视频数据能满足几乎所有用户的需求,但同时也使得搜寻和查找到用户真正感兴趣的视频成为了一件非常烦琐的事情。因此,个性化视频推荐对于信息过载的当今是非常必要的。传统的个性化视频推荐方法是基于静态用户模型,该模型利用用户注册信息,历史行为来理解用户的长期兴趣。然而,当今信息的更新越来越频繁。用户每天都面对着大量新信息,导致用户的短期兴趣随着当前热点事件在不断的飘移。例如,当一名用户读到美国总统就职典礼的新闻时,他很可能会去搜索相关视频去进一步了解该事件。也许从长期兴趣的角度来看,这名用户对政治并不是非常感兴趣,但是他的短期兴趣却被当前热点事件影响了。在这种情况下,传统的个性化视频推荐方法无法应对的,因为他们无法捕捉用户兴趣的漂移。图1为现有技术进行个性化视频推荐的流程图。如图1所示,现有技术进行个性化视频推荐的流程包括:步骤S101,利用用户在某一个网络平台的信息(如注册信息,历史行为)建立用户长期兴趣模型,通常为特征向量,每一维表示用户的某一偏好;步骤S102,利用视频信息(如视频标注,上下文信息以及视频内容)为每个视频建立特征向量;步骤S103,利用用户特例向量与视频特征向量的内积对视频进行排序,将得分高(如前10)的视频推荐给用户。发明人发现上述个性化视频推荐的方法存在如下技术缺陷:1)注重用户的长期兴趣,无法实时捕捉用户的短期兴趣偏好;2)只利用单一网络平台信息学习用户兴趣,往往存在冷启动(cold-start)和数据稀疏性(datasparsity)问题。
技术实现要素:
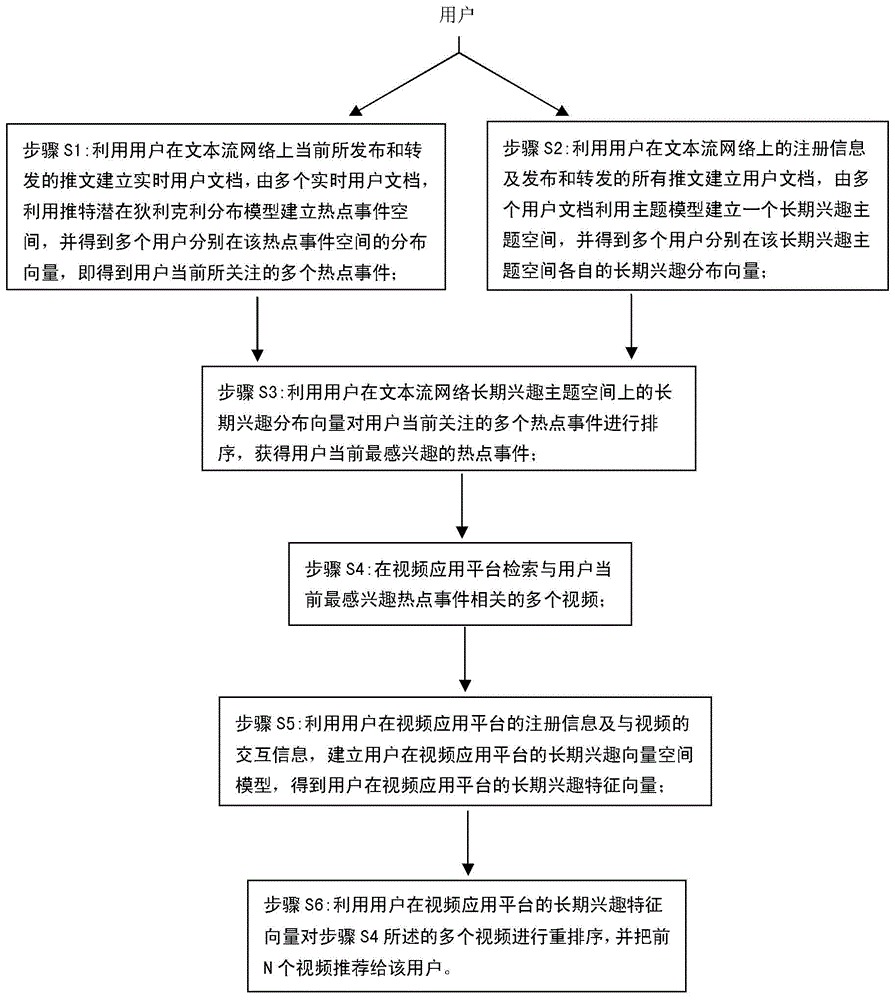
(一)要解决的技术问题为解决上述的问题,本发明提供了一种基于文本流网络的实时个性化视频推荐方法,以提高个性化视频推荐的准确性。(二)技术方案本发明提供基于文本流网络的实时个性化视频推荐方法,所述个性化视频推荐的步骤包括:步骤S1:利用用户在文本流网络上当前所发布和转发的推文建立实时用户文档,利用推特潜在狄利克利分布模型对多个实时用户文档建立热点事件空间,并得到多个用户分别在该热点事件空间的分布向量,即得到用户当前所关注的多个热点事件;步骤S2:利用用户在文本流网络上的注册信息及发布和转发的所有推文建立用户文档,利用主题模型对多个用户文档建立一个长期兴趣主题空间,并得到多个用户分别在该长期兴趣主题空间各自的长期兴趣分布向量;步骤S3:利用用户在文本流网络长期兴趣主题空间上的长期兴趣分布向量对用户当前关注的多个热点事件进行排序,获得用户当前最感兴趣的热点事件;步骤S4:在视频应用平台检索与用户当前最感兴趣热点事件相关的多个视频;步骤S5:利用用户在视频应用平台的注册信息及与视频的交互信息,建立用户在视频应用平台的长期兴趣向量空间模型,得到用户在视频应用平台的长期兴趣特征向量;步骤S6:利用用户在视频应用平台的长期兴趣特征向量对步骤S4所述的多个视频进行重排序,并把前N个视频推荐给该用户。(三)有益效果从上述技术方案可以看出,本发明基于文本流网络的实时个性化视频推荐方法具有以下有益效果:(1)利用文本流网络热点事件出现和传播的快速性,实时检测用户所关注的热点事件,有效地捕捉了用户的短期兴趣,从而提高了个性化视频推荐的准确性;(2)利用了用户在不同平台的信息学习用户兴趣,有效地缓解了冷启动和数据稀疏性问题。附图说明图1为现有技术利用传统方法进行个性化视频推荐的流程图;图2为本发明实施例基于文本流网络的实时个性化视频推荐方法的流程图。具体实施方式需要说明的是,在附图或说明书描述中,相似或相同的部分都使用相同的图号。且在附图中,以简化或是方便标示。再者,附图中未绘示或描述的实现方式,为所属技术领域中普通技术人员所知的形式。另外,虽然本文可提供包含特定值的参数的示范,但应了解,参数无需确切等于相应的值,而是可在可接受的误差容限或设计约束内近似于相应的值。本发明的目的是实现实时个性化视频推荐。该问题存在如下挑战。首先,我们很难准确捕获用户的短期兴趣;另外,用户在单一平台的可用信息往往有限,难以准确把握用户的长期兴趣;最后,如何融合用户的短期兴趣和长期兴趣也是一个难点。需要说明的是,本领域技术人员应当了解,上述的视频也可以是音频、图片等,在下文中主要以视频为例进行说明,但本发明并不局限于此。另外,上述文本流网络在下文中以推特(Twitter)为例进行说明,视频应用平台以优突博(YouTube)为例进行说明,但本发明并不局限于此。在本发明的一个示例性实施例中,提出了一种基于文本流网络的实时个性化视频推荐的方法。如图2所示,本实施例基于文本流网络的实时个性化视频推荐方法包括:步骤S1:利用用户在文本流网络上当前所发布或转发的推文建立实时用户文档,利用推特潜在狄利克利分布模型对多个实时用户文档建立热点事件空间,并得到多个用户分别在该热点事件空间的分布向量,即得到用户当前所关注的多个热点事件;用户在推特平台发布或转发推文(tweet),而这些行为是受当前热点事件,用户好友及用户本身兴趣共同作用的结果,是用户短期兴趣的一种体现。由于推文的短文本特性,每篇推文都主要表达一个事件,因此,我们采用推特潜在狄利克利分布模型(TwitterLDA)从多个用户当前发布或转发的多个推文建立热点事件空间,每个热点事件是由一些语义词汇构成的向量,向量的每一维表示某一语义词汇在该事件中出现的概率。但是由于推文和注册信息中含有大量噪声,如无意义的词汇及误输入。因此我们采用词网进行过滤。基于上述描述,步骤S1中所述利用用户在文本流网络上当前所发布或转发的推文建立实时用户文档的具体步骤如下:步骤S1a:从网络中收集多个用户当前分别发布和转发的推文;步骤S1b:利用词网过滤上述推文中的噪声,得到过滤后的推文;步骤S1c:对于多个用户中的每一个,利用其过滤后的推文分别建立实时用户文档。步骤S1中所述每个用户的分布向量中具有非零元素,所述非零元素对应的热点事件即为用户当前所关注的热点事件,因此我们得到了用户当前所关注的多个热点事件。上述“当前”可以为“一小时内”,“一天内”,任意能体现实时性的时间范围均可。步骤S2:利用用户在文本流网络上的注册信息及发布和转发的所有推文建立用户文档,利用主题模型对多个用户文档建立一个长期兴趣主题空间,并得到多个用户分别在该长期兴趣主题空间各自的长期兴趣分布向量;用户在推特上的注册信息反应了用户的长期兴趣;同时,用户所发布和转发的所有推文可以反应用户的长期兴趣。因此我们利用用户的注册信息及用户发布和转发的推文来建立用户文档。但是该文档含有大量噪声,如无意义的词汇及误输入。这里我们同样采用词网进行过滤。基于上述描述,步骤S2利用用户在文本流网络上的信息建立用户文档的步骤如下:步骤S2a:从网络中收集多个用户分别发布和转发的推文及其注册信息;步骤S2b:利用词网过滤上述推文和注册信息中的噪声,滤掉除推文和注册信息中的名词成分之外的成分,得到过滤后的推文及注册信息;步骤S2c:对于多个用户中的每一个用户,利用每一个用户发布和转发的推文及注册信息中的名词成分分别建立每一个用户文档。步骤S2:中所述主题模型可以选择潜在狄利克利分布模型(LDA),当然也可以选择本领域公知的其他模型,例如:概率潜在主义分析模型(PLSA)或涡轮主题模型(TurboTopic)。步骤S3:利用用户在文本流网络长期兴趣主题空间上的长期兴趣分布向量对用户当前关注的多个热点事件进行排序,获得用户当前最感兴趣的热点事件;用户当前可能关注了多个热点事件,我们通过用户的长期兴趣分布向量来推测用户最感兴趣的热点事件。对所述多个热点事件进行排序,首先,我们通过相对熵(RelativeEntropy)计算用户当前所关注的每个热点事件与用户长期兴趣主题空间中各主题的相似度,然后再结合用户在长期兴趣主题空间的长期兴趣分布向量计算用户在当前所关注的每个事件上的兴趣分值,分值最大的事件即为用户当前最感兴趣的热点事件;所述用户当前所关注的每个热点事件与用户长期兴趣主题空间中各主题的相似度,所述所述平均相对熵D(z||x)表示如下:其中z为长期兴趣主题空间中的主题向量,x为当前热点事件空间热点事件向量,D(z||x)表示主题向量z和热点事件向量x之间的平均相对熵,z(i)和x(i)表示主题向量z和热点事件向量x在第i个语义词汇上的概率值,K为词汇空间的维度,i=1,2,...K。平均相对熵的倒数即为主题向量z和热点事件向量x的相似度。所述用户在当前所关注的每个事件上的兴趣分值p(x|u,λ)表示如下:其中x为用户u当前所关注的某一热点事件向量;λ为用户u在长期兴趣主题空间上的分布向量;Φ为长期兴趣主题空间;λZ表示用户u在长期兴趣主题空间Φ中主题向量z上的概率值;p(x|u,λ)表示在给定用户u及其在长期兴趣主题空间Φ上的分布向量λ下,热点事件向量x的得分;为用户u分别计算当前所关注的多个热点事件的得分后,我们再把得分最高的热点事件作为用户当前最感兴趣的热点事件。经过步骤S3,我们实现了利用文本流网络热点事件出现和传播的快速性,实时检测用户当前最感兴趣的热点事件,有效地捕捉了用户的短期兴趣。步骤S4:在视频应用平台检索与用户当前最感兴趣热点事件相关的多个视频;如步骤S2所述,热点事件由一些语义词汇构成的向量,向量的每一位表示某一语义词汇在该事件出现的概率。因此,我们选择用户当前最感兴趣的热点事件中出现概率最大的三个语义词汇作为查询词,在视频应用平台检索相关视频,并选择前20到前100个视频,实施例中选取前20或前50或前100个视频。步骤S5:利用用户在视频应用平台的注册信息及与视频的交互信息,建立用户在视频应用平台的长期兴趣向量空间模型,得到用户在视频应用平台的长期兴趣特征向量;用户在视频应用平台的注册信息反应了用户的长期兴趣,同时,用户对视频的主动行为(如上传或收藏)反映了用户的长期兴趣爱好。因此我们利用用户的注册信息,以及用户上传或收藏视频的语义标签,类别及描述来建立用户在视频应用平台的长期兴趣向量空间模型。步骤S5中所述利用用户在视频应用平台的注册信息及与视频的交互信息的具体步骤如下:步骤S5a:收集用户注册信息及上传或收藏的视频的语义标签、类别和描述;步骤S5b:利用词网过滤上述注册信息及语义标签、类别和描述中的噪声,滤除所述注册信息及语义标签、类别和描述中除名词成分之外的成分;步骤S5中所述建立用户在视频应用平台的长期兴趣向量空间模型是:利用所述注册信息及语义标签、类别和描述中的名词成分建立每个用户长期兴趣向量空间模型,得到用户在视频应用平台的长期兴趣特征向量。步骤S6:利用用户在视频应用平台的长期兴趣特征向量对步骤S4所述的多个视频进行重排序,并把前N个视频推荐给该用户。首先,我们利用视频的语义标签、类别和描述为每个视频建立特征向量,然后我们根据该特征向量与用户在该视频应用平台的长期兴趣特征向量的匹配程度对视频进行排序,具体包括,给定一个视频υ,用户在视频应用平台的长期兴趣特征向量θ,该视频υ的得分表示为:其中M表示向量空间的维度,i=1,2,…M;p(υ|θ)表示在给定用户在视频应用平台的长期兴趣特征向量θ下,视频υ的得分;υi表示是视频特征向量在第i维上的权重,θi表示用户长期兴趣特征向量在第i维上的权重。为每个视频计算得分后,我们再根据这些得分对与用户当前最感兴趣的热点事件相关的前20至前100个视频进行重排序,然后把前5至前20个最相关视频推荐给用户。实施例中并选取前20或前50或前100个视频进行重排序,然后把前5或前10或前20个最相关视频推荐给用户。上述N个视频中的N可以为任意合理数,例如5到20,只需小于步骤S4中所选取的多个视频的数目。所述视频应用平台是优酷(YouKu)、优突博(YouTube)等视频应用平台,实施例中以优突博(YouTube)为例进行说明。所述相关视频是前10个或任意合理数最相关视频推荐给该用户。以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1