一种基于网络编码的分布式存储方法及其装置与流程
本发明属于计算机存储技术领域,具体涉及一种基于网络编码的分布式存储方法及其装置。
背景技术:
随着社会信息化的程度不断提高,信息的产生呈现爆炸式的增长,人们对信息的存储需求也不断在变高。在商业领域,公司的业务数据量翻倍地增长,包含多媒体数据,电子商务数据,网页搜索数据等等。越来越庞大的数据存储对存储技术的要求也越来越高。分布式存储系统相对于传统的文件系统具有以下优势:可扩展性、可靠性、高吞吐率和系统成本低,当今大型互联网公司内部的分布式存储系统的集群规模在急剧扩张,存储成本也在不断上升。随着集群中节点数的增加,节点故障的概率也在不断地增加。为了保证数据的高可用性,现有的分布式存储系统中通常采用完全数据冗余的方式来进行容错处理。如GFS(GoogleFileSystem)和HDFS(HadoopDistributedFileSystem)都采用三副本策略,即每一份文件都在存储节点上保存3份副本。三副本策略实现简单,也可以保证数据有较高的可用性,但是副本策略会给系统带来相当大的空间消耗,存储效率低下。当文件系统中存储的数据量达到PB级后,为保证数据的可用性,每增加一份副本都意味着会增加百万级别的存储成本。纠删码是副本的推广,在海量数据面前,在保证与副本策略相同的容错能力下,纠删码可以大大减少存储成本。将大小为M的文件D等分为k个数据块:d1,d2...dk,每个数据块大小为M1,编码之后产生n个编码数据块:C1,C2...Cn,每个数据块大小为M1,将这n个数据块存储到n个不同的数据节点:D1,D2...Dn,当一个数据节点Di损坏时,要从k个可用的数据节点(Di1,Di2...Dik)里下载k个数据块(Ci1,Ci2...Cik),来恢复丢失的数据块Ci。谷歌的第二代GFS(即Colossus)系统中就使用了RS类纠删码来实现低成本的可靠存储,见"Google’sglobally-distributeddatabase"Proceedingsofthe10thUSENIXconferenceonOperatingSystemsDesignandImplementation.USENIXAssociation,2012.251-264。微软公司在其开发的Azure平台中也使用了纠删码技术。见"Erasurecodinginwindowsazurestorage"Proceedingsofthe2012USENIXconferenceonAnnualTechnicalConference.USENIXAssociation,2012.2。但是纠删码在修复损坏的数据节点时存在一个问题:修复M1大小的数据块需要通过网络连接从k个不同的节点上总共下载k×M1大小的数据块,这样修复带宽是昂贵的。针对纠删码的修复带宽的问题,网络编码可以有效地减少数据节点损坏时的修复带宽,但会造成数据节点内部的磁盘IO量变大。见"NetworkCodingforDistributedStorageSystems"Proc.ofIEEEINFOCOM2007.
技术实现要素:
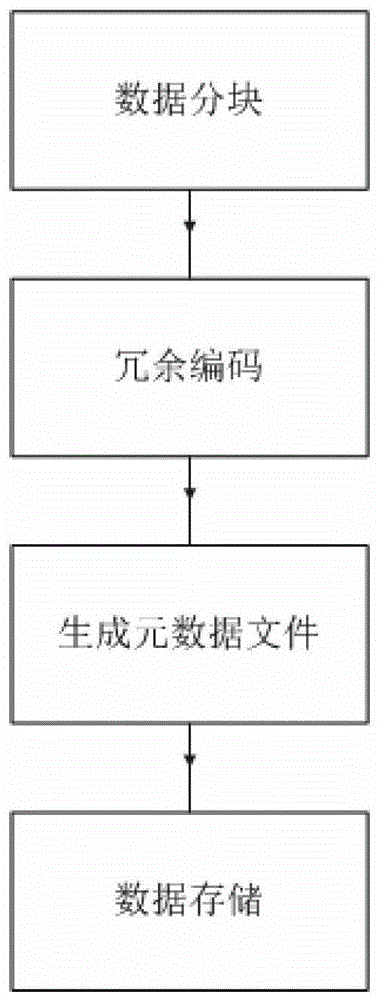
本发明提供一种基于网络编码的分布式存储方法,同时提供其装置,解决现有基于网络编码的分布式存储方法所存在的存储节点的磁盘IO过大的问题,在数据节点损坏时,通过网络连接d(d≥k)个数据节点,下载不多于原始文件D大小的数据,修复损坏的数据,有效地减小修复带宽。而且从d个数据节点中下载随机选择的γ个编码数据块(Ce1,Ce2,...Ceγ),数据块在数据节点内没有进行线性运算,直接从数据节点中读出,可以有效地提高数据节点的磁盘IO效率。本发明所提供的一种基于网络编码的分布式存储方法,适用于分布式存储系统,包括数据编码步骤、数据解码步骤和数据修复步骤,分布式存储系统由一个名字节点NS和P个存储节点{DS1,DS2,DS3...DSP}构成,P≥3,其中用于存储文件分块的存储节点称为数据节点,为n个,3≤n≤P;其特征在于:(1)数据编码步骤,包括下述子步骤:(1.1)数据分块:将原始文件D分割为c块等大小的原始数据块Dg,g=0,1...c-1,对于不足一块原始数据块大小的剩余原始数据DB,先记下DB的大小LB,再将其使用零填充补足为原始数据块大小,作为原始数据块Dc;c=k×(d+1+i-k)-(i+1)×i/2,其中,k为恢复出原文件所需最少数据节点数目,2≤k<n;d为修复一个损坏节点时可用数据节点的数目,k≤d<n;i为编码冗余参数,0≤i≤k-1;(1.2)冗余编码:将c个原始数据块Dg与编码矩阵Me进行有限域2q内的运算,编码为r个编码数据块Cb,q=4、8、16、32或64;b=0,1,...r-1;r=(d+1+i-k)×n;其中,编码矩阵Me中的矩阵元素ab,g为属于有限域2q的整数,0≤ab,g≤2q-1,编码矩阵Me为一个r行c列的范德蒙矩阵;每个Cb都是c个原始数据块Dg的线性组合,其中g=0,1...c-1,线性组合系数对应为编码矩阵Me第b行的行向量Vb,即每个Cb对应编码矩阵Me第b行的行向量Vb;(1.3)生成元数据文件Dmeta:将编码矩阵Me以及参数n、k、d、i、q和LB保存在元数据文件Dmeta中;(1.4)数据存储:将r个编码数据块Cb存放在n个数据节点df上,f=0,1,...n-1,每个数据节点存储α=d+1+i-k个编码数据块,并存储一份Dmeta的副本;数据节点df存储的数据块为Ct,t=f×α,f×α+1,...(f+1)α-1;(2)数据解码步骤,包括下述子步骤:(2.1)获取文件元数据信息:下载原始文件D的元数据文件Dmeta,得到编码矩阵Me以及参数n、k、d、i、q和LB;(2.2)下载可用数据块:判断n个数据节点中可用数据节点数是否小于k个,是则数据读取失败,退出;否则任意选择k个可用数据节点,k个可用数据节点中包含rk=k×α=k×(d+1+i-k)个编码数据块,共对应编码矩阵Me中rk个行向量:从编码矩阵Me这rk个行向量中选择c个行向量,要求这c个行向量组成的方阵Me1可逆,然后下载这c个行向量所对应的c个编码数据块:Cb0,Cb1...Cb(c-1);(2.3)冗余解码:对所述方阵Me1矩阵求逆,得到其逆矩阵Me1-1,逆矩阵Me1-1中元素记为bgj,其中行数g=0,1,...c-1,列数j=0,1,...c-1;将逆矩阵Me1-1与下载的c个编码数据块做有限域2q内的运算,得到c个原始数据块Dg,其中g=0,1...c-1;Dg为c个编码数据块Cb0,Cb1...Cb(c-1)的线性组合,线性组合的系数为逆矩阵Me1-1对应的行向量Vdg;(2.4)恢复数据:将冗余解码后得到的c个原始数据块Dg按其下标的顺序D0,D1...Dc-1依次写入到恢复文件DO中,最后一块原始数据块Dc-1只写其前LB个字节到恢复文件DO中,形成恢复文件DO;(3)数据修复步骤,当一个数据节点dv损坏时,v为0、1、...或n-1,其存储的编码数据块的修复包括下述子步骤:(3.1)获取文件元数据信息:下载原始文件D的元数据文件Dmeta,得到编码矩阵Me以及参数n、k、d、i、q和LB;设置下载数据块数目变量γ的初值:γ=(2×c×d)/((2×k-i-1)×i+2×k×(d-k+1));(3.2)计算数据块修复信息,包括下述过程:(3.2.1)置循环次数变量N1=0,判断n个数据节点中可用数据节点数是否小于d个,是则数据修复失败,退出;否则进行过程(3.2.2);(3.2.2)从d个可用数据节点中随机选择γ个编码数据块,将它们对应的编码矩阵Me的γ个行向量Vh组合为γ行c列矩阵Vs,h=1,2...γ;置N1=N1+1;(3.2.3)生成一个(d+1+i-k)行γ列的修复矩阵Mr=[mp,h],其中每个元素mp,h从有限域2q内随机取值,p=1,2,...(d+1+i-k),h=1,2,...γ;(3.2.4)建立r行c列的新编码矩阵Me’,Me’由原有行向量和新行向量Vp'构成,原有行向量为可用数据节点所包括的编码数据块对应的编码矩阵Me中的行向量,按其在Me中原有位置存在于Me’中,做有限域2q内的矩阵Mr与矩阵Vs乘法运算,得到新行向量Vz':用新行向量Vp'代替编码矩阵Me中损坏的数据节点dv所存储的α个编码数据块对应的行向量Vz,其中z=v×α,v×α+1,...(v+1)×α-1;(3.2.5)检查所述新编码矩阵Me’是否满足MDS性质,是则进行子步骤(3.3),否则进行过程(3.2.6);所述MDS性质中文为最大距离可分性质,即n个节点中任意k个节点的数据可以恢复出原文件的数据;(3.2.6)判断是否N1≤L,是则转过程(3.2.2);否则置N1=0,置γ=γ+1,然后转过程(3.2.2),最大循环次数L=1000~3000;(3.3)更新元数据文件:将元数据文件Dmeta中的编码矩阵Me替换为新编码矩阵Me’,形成更新后的元数据文件Dmeta’,将其拷贝到各个数据节点;(3.4)修复数据块:下载过程(3.2.2)中所随机选择的γ个编码数据块Ce1,Ce2,...Ceγ,做有限域2q内矩阵Mr与γ个编码数据块Ce1,Ce2,...Ceγ的运算,得到修复的数据块Cp’:Cp’为γ个编码数据块Ce1,Ce2,...Ceγ的线性组合,线性组合的系数为修复矩阵Mr对应的行向量Vrp;(3.5)存储数据块:将修复的数据块Cp’存储到一个新的可用数据节点上。本发明中,数据编码步骤是基础,数据解码步骤和数据修复步骤是互相独立的;用户需要对原始文件进行编码存储时,对文件进行编码操作,进行数据编码步骤;用户需要下载原始文件时,对文件进行解码操作,进行数据解码步骤;当一个数据节点损坏时,对该数据节点上的数据块进行修复操作,进行数据修复步骤。所述子步骤(1.1)中,根据编码冗余参数i的不同取值,编码的效果不同。当i=0时,每一个数据节点存储的数据量αR最小,αR=M/k;修复损坏数据节点时,d个可用数据节点中,从每个数据节点下载的数据量为γR,γR=(M×d)/(k×(d-k+1)),其中M为原始文件的大小。当i=(k-1)时,每一个数据节点存储的数据量αR为:αR=(2×M×d)/(2×k×d-k2+k);修复损坏数据节点时,d个可用数据节点中,从每个数据节点下载的数据量γR最小,γR=(2×M×d)/(2×k×d-k2+k)。当0<i<(k-1)时,每个节点存储的数据量αR为:M/k<αR<(2×M×d)/(2×k×d-k2+k)。修复损坏数据节点时,d个可用数据节点中,从每个数据节点下载的数据量γR为:(2×M×d)/(2×k×d-k2+k)<γR<(M×d)/(k×(d-k+1))。所述子步骤(1.2)中编码矩阵Me为一个r行c列的范德蒙矩阵,满足最大距离可分(MDS)性质,即n个节点中任意k个节点的数据可以恢复出原文件的数据;所述子步骤(3.4)中从d个数据节点中下载随机选择的γ个Vi对应的编码数据块(Ce1,Ce2,...Ceγ),数据块在d个数据节点内没有进行线性运算,直接从数据节点中读出,可以有效地提高数据节点的磁盘IO效率。本发明所提供的一种基于网络编码的分布式存储装置,适用于分布式存储系统,包括数据编码模块、数据解码模块和数据修复模块;分布式存储系统由一个名字节点NS和P个存储节点{DS1,DS2,DS3...DSP}构成,P≥3,其中用于存储文件分块的存储节点称为数据节点,为n个,3≤n≤P;其特征在于:(1)数据编码模块,包括下述子模块:(1.1)数据分块子模块:将原始文件D分割为c块等大小的原始数据块Dg,g=0,1...c-1,对于不足一块原始数据块大小的剩余原始数据DB,先记下DB的大小LB,再将其使用零填充补足为原始数据块大小,作为原始数据块Dc-1;c=k×(d+1+i-k)-(i+1)×i/2,其中,k为恢复出原文件所需最少数据节点数目,2≤k<n;d为修复一个损坏节点时可用数据节点的数目,k≤d<n;i为编码冗余参数,0≤i≤k-1;(1.2)冗余编码子模块:将c个原始数据块Dg与编码矩阵Me进行有限域2q内的运算,编码为r个编码数据块Cb,q=4、8、16、32或64;b=0,1,...r-1;r=(d+1+i-k)×n;其中,编码矩阵Me中的矩阵元素ab,g为属于有限域2q的整数,0≤ab,g≤2q-1,编码矩阵Me为一个r行c列的范德蒙矩阵;每个Cb都是c个原始数据块Dg的线性组合,其中g=0,1...c-1,线性组合系数对应为编码矩阵Me第b行的行向量Vb,即每个Cb对应编码矩阵Me第b行的行向量Vb;(1.3)生成元数据文件Dmeta子模块:将编码矩阵Me以及参数n、k、d、i、q和LB保存在元数据文件Dmeta中;(1.4)数据存储子模块:将r个编码数据块Cb存放在n个数据节点df上,f=0,1,...n-1,每个数据节点存储α=d+1+i-k个编码数据块,并存储一份Dmeta的副本;数据节点df存储的数据块为Ct,t=f×α,f×α+1,...(f+1)α-1;(2)数据解码模块,包括下述子模块:(2.1)获取文件元数据信息子模块:下载原始文件D的元数据文件Dmeta,得到编码矩阵Me以及参数n、k、d、i、q和LB;(2.2)下载可用数据块子模块:判断n个数据节点中可用数据节点数是否小于k个,是则数据读取失败,退出;否则任意选择k个可用数据节点,k个可用数据节点中包含rk=k×α=k×(d+1+i-k)个编码数据块,共对应编码矩阵Me中rk个行向量:从编码矩阵Me这rk个行向量中选择c个行向量,要求这c个行向量组成的方阵Me1可逆,然后下载这c个行向量所对应的c个编码数据块:Cb0,Cb1...Cb(c-1);(2.3)冗余解码子模块:对所述方阵Me1矩阵求逆,得到其逆矩阵Me1-1,逆矩阵Me1-1中元素记为bgj,其中行数g=0,1,...c-1,列数j=0,1,...c-1;将逆矩阵Me1-1与下载的c个编码数据块做有限域2q内的乘法运算,得到c个原始数据块Dg,其中g=0,1...c-1;Dg为c个编码数据块Cb0,Cb1...Cb(c-1)的线性组合,线性组合的系数为逆矩阵Me1-1对应的行向量Vdg;(2.4)恢复数据子模块:将冗余解码后得到的c个原始数据块Dg按其下标的顺序D0,D1...Dc-1依次写入到恢复文件DO中,最后一块原始数据块Dc-1只写其前LB个字节到恢复文件DO中,形成恢复文件DO;(3)数据修复模块,当一个数据节点dv损坏时,v为0、1、...或n-1,其存储的编码数据块的修复包括下述子模块:(3.1)获取文件元数据信息子模块:下载原始文件D的元数据文件Dmeta,得到编码矩阵Me以及参数n、k、d、i、q和LB;设置下载数据块数目变量γ的初值:γ=(2×c×d)/((2×k-i-1)×i+2×k×(d-k+1));(3.2)计算数据块修复信息子模块,包括下述单元:第一单元,置循环次数变量N1=0,判断n个数据节点中可用数据节点数是否小于d个,是则数据修复失败,退出;否则转第二单元;第二单元,从d个可用数据节点中随机选择γ个编码数据块,将它们对应的编码矩阵Me的γ个行向量Vh组合为γ行c列矩阵Vs,h=1,2...γ;置N1=N1+1;第三单元,生成一个(d+1+i-k)行γ列的修复矩阵Mr=[mp,h],其中每个元素mp,h从有限域2q内随机取值,p=1,2,...(d+1+i-k),h=1,2,...γ;第四单元,建立r行c列的新编码矩阵Me’,Me’由原有行向量和新行向量Vp'构成,原有行向量为可用数据节点所包括的编码数据块对应的编码矩阵Me中的行向量,按其在Me中原有位置存在于Me’中,做有限域2q内的矩阵Mr与矩阵Vs乘法运算,得到新行向量Vp':用新行向量Vp'代替编码矩阵Me中损坏的数据节点dv所存储的α个编码数据块对应的行向量Vz,其中z=v×α,v×α+1,...(v+1)×α-1;第五单元,检查所述新编码矩阵Me’是否满足MDS性质,是则转更新元数据文件子模块,否则转第六单元;所述MDS性质中文为最大距离可分性质,即n个节点中任意k个节点的数据可以恢复出原文件的数据;第六单元,判断是否N1≤L,是则转第二单元;否则置N1=0,置γ=γ+1,然后转第二单元,最大循环次数L=1000~3000;(3.3)更新元数据文件子模块:将元数据文件Dmeta中的编码矩阵Me替换为新编码矩阵Me’,形成更新后的元数据文件Dmeta’,将其拷贝到各个数据节点;(3.4)修复数据块子模块:下载所述第二单元中所随机选择的γ个编码数据块Ce1,Ce2,...Ceγ,做有限域2q内矩阵Mr与γ个编码数据块Ce1,Ce2,...Ceγ的运算,得到修复的数据块Cp’:Cp’为γ个编码数据块Ce1,Ce2,...Ceγ的线性组合,线性组合的系数为修复矩阵Mr对应的行向量Vrp;(3.5)存储数据块子模块:将修复的数据块Cp’存储到一个新的可用数据节点上。与现有的技术相比较,本发明具有以下优点:(1)保证数据高可用性的前提下能够解决现有的分布式存储系统中使用副本策略所带来的巨大的空间消耗和存储成本的增加。(2)在一个数据节点损坏时,通过网络连接d(d≥k)个数据节点,下载不多于原始文件M大小的数据,修复损坏的数据,有效地减小修复带宽。(3)修复一个损坏的数据节点时,从d个数据节点中下载随机选择的γ个编码数据块(Ce1,Ce2,...Ceγ),数据块在数据节点内没有进行线性运算,直接从数据节点中读出,可以有效地提高数据节点的磁盘IO效率。附图说明图1为本发明实施例的结构示意图;图2为本发明的实施例数据编码步骤流程示意图;图3为本发明的实施例数据解码步骤流程示意图;图4为本发明的实施例数据修复步骤流程示意图。具体实施方式以下结合附图和实施例对本发明进一步说明。如图1所示,本发明实施例,包括数据编码步骤、数据解码步骤和数据修复步骤,适用于由一个名字节点NS和5个存储节点{DS1,DS2,DS3...DS5}构成的分布式存储系统,其中用于存储文件分块的n=4个存储节点称为数据节点,为d0、d1、d2、d3;(1)数据编码步骤,如图2所示,包括下述子步骤:(1.1)数据分块:将大小为64M的原始数据D分割为c=k×(d+1+i-k)-(i+1)×i/2=4块等大小的原始数据块Dg,g=0,1...3,k=2,d=3,编码冗余参数i=0;其中D0、D1、D2、D3的大小为16M;原始数据D的大小是c的整数倍,所以LB=0;(1.2)数据编码:将4个原始数据块Dg与编码矩阵Me进行有限域28内的运算,编码为r=(d+i+i-k)×n=8个编码数据块Cb,b=0,1,...7;其中,编码矩阵Me中的矩阵元素ab,g为属于有限域28的整数,0≤ab,g≤28-1,编码矩阵Me为一个8行4列的范德蒙矩阵;每个Cb都是4个原始数据块Dg的线性组合,其中g=0,1...3,线性组合系数对应为编码矩阵Me第b行的行向量Vb,即每个Cb对应编码矩阵Me第b行的行向量Vb;(1.3)生成元数据文件:将编码矩阵Me以及参数n=4,k=2,d=3,i=0和LB=0保存在元数据文件Dmeta中;(1.4)数据存储:将8个编码数据块C0,C1,C2...C7存放在4个数据节点d0,d1...d3上,每个数据节点存储α=2个编码数据块,数据节点du存储的数据块为Cu×α,Cu×α+1;每一个数据节点上都存储一份Dmeta的副本;(2)数据解码步骤,如图3所示,包括下述子步骤:(2.1)获取文件元数据信息:下载原始文件D的元数据文件Dmeta,得到编码矩阵Me以及参数n=4,k=2,d=3,i=0和LB=0;(2.2)下载可用数据块:判断4个数据节点中是否可用数据节点数小于2个,是则数据读取失败,退出;否则任意选择2个可用数据节点:d2、d3,d2、d3这2个可用数据节点中包含的编码数据块为:C4、C5、C6、C7,共对应编码矩阵Me中4个行向量:V4、V5、V6、V7。这4个行向量按V4、V5、V6、V7的顺序组成方阵Me1;编码Me满足MDS性质,所以方阵Me1可逆,然后下载这4个行向量所对应的4个编码数据块:C4、C5、C6、C7;(2.3)冗余解码:对所述方阵Me1矩阵求逆,得到其逆矩阵Me1-1,逆矩阵Me1-1中元素记为bgj,其中行数g=0,1,...3,列数j=0,1,...3;将逆矩阵Me1-1与下载的4个编码数据块C4、C5、C6、C7做有限域28内的运算,得到4个原始数据块Dg,其中g=0,1...3;Dg为4个编码数据块Cb0,Cb1...Cb(c-1)的线性组合,线性组合的系数为逆矩阵Me1-1对应的行向量Vdg;(2.4)读取数据:先将冗余解码后得到的原始数据块D0、D1、D2、D3按其下标的顺序D0、D1、D2、D3依次写入到恢复文件DO中,由于LB=0,最后一块原始数据块D3全部写到恢复文件DO中;然后形成恢复文件DO;(3)数据修复步骤,当一个数据节点d0损坏时,其存储的编码数据块的修复包括下述子步骤,如图4所示:(3.1)获取文件元数据信息:下载原始文件D的元数据文件Dmeta,得到编码矩阵Me以及参数n=4,k=2,d=3,i=0和LB=0;(3.2)计算数据块修复信息,包括下述过程:(3.2.1)置循环次数变量N1=0,判断4个数据节点中可用数据节点数是否小于3个,是则数据修复失败,退出;否则进行过程(3.2.2),数据节点d1、d2、和d3都可用,所以进行过程(3.2.2);(3.2.2)从3个可用数据节点d1、d2、和d3中随机选择3个编码数据块,将它们对应的编码矩阵Me的3个行向量Vh组合为3行4列矩阵Vs,h=1,2...3;置N1=N1+1;(3.2.3)生成一个(d+1+i-k)=2行3列的修复矩阵Mr=[mp,h],其中每个元素mp,h从有限域28内随机取值,p=1,2,h=1,2,3;(3.2.4)建立8行4列的新编码矩阵Me’,Me’由原有行向量和新行向量Vp'构成,原有行向量为可用数据节点所包括的编码数据块对应的编码矩阵Me中的行向量,按其在Me中原有位置存在于Me’中,做有限域2q内的矩阵Mr与矩阵Vs乘法运算,得到新行向量Vp'为:其中p=v×α,v×α+1,...(v+1)×α-1;用新行向量Vp'代替编码矩阵Me中损坏的数据节点dv所存储的α个编码数据块对应的行向量Vz,其中z=v×α,v×α+1,...(v+1)×α-1:(3.2.5)检查所述新编码矩阵Me’是否满足MDS性质,是则进行子步骤(3.3),否则进行过程(3.2.6)。检查结果为Me’满足MDS性质,所以,进行子步骤(3.3);(3.2.6)判断是否N1≤L,是则转过程(3.2.2);否则置N1=0,置γ=γ+1,然后转过程(3.2.2),最大循环次数L=2000;(3.3)更新元数据文件:将元数据文件Dmeta中的编码矩阵Me替换为新编码矩阵Me’,形成更新后的元数据文件Dmeta’,将其拷贝到各个数据节点;(3.4)修复数据块:下载过程(3.2.2)中所随机选择的3个编码数据块Ce1,Ce2,Ce3,做有限域28内矩阵Mr与3个编码数据块Ce1,Ce2,Ce3的运算,将损坏的数据节点d0中所存储的数据块修复为Cp’:其中p=v×α,v×α+1,...(v+1)×α-1;Cp’为3个编码数据块Ce1,Ce2,Ce3的线性组合,线性组合的系数为修复矩阵Mr对应的行向量Vrp;(3.5)存储数据块:将修复的数据块Cvp存储到一个新的可用数据节点d5上。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1