一种基于一维线性空间实现Trie树的词典检索方法与流程
本发明涉及一种词典检索方法,尤其涉及一种基于一维线性空间实现Trie树的词典检索方法。
背景技术:
在信息检索和自然语言处理领域,特别是基于词典的技术应用中,词典的规模一般都非常大,拥有成千上万甚至上亿条记录,尤其是搜索引擎中倒排索引词的规模最为庞大。对海量数据词典的查找,当前通常采用索引的数据结构来实现。常用的索引结构包括线性索引表、倒排表、散列(hash)表和搜索树等。对于一个记录的关键字(key)长度为n,词典的规模为N的情况下(其中N>>n)各索引结构检索的时间复杂度分析如下:线性索引结构或倒排表一般采用顺序结构存储词典中的记录,对词典中记录的查找一般采用顺序遍历每一个记录,因此,每一次查找的时间复杂度为O(N)×l(n)(其中l(n)为两条记录的关键字因比较所花费的时间)。此种方法的改进是让词典的每一条记录按关键字(key)有序,在检索的时候用折半查找,其时间复杂度为O(logN)×l(n)。在基于词典的自然语言处理应用,如基于词典的中文分词、基于词典的字音转换(汉字转换成拼音)、基于词典的命名实体识别、基于词典的标注(包括词性标注和语义标注等),其中的核心部分是要进行大量的查询操作。为了满足此类应用的要求,就需要一种高效的词典检索方法。现今也有基于二维数组的Trie树的词典查询方法,但是基于二维数组的这种查询方法在Trie树的构建过程中会存在因插入新状态而引起的冲突,导致要移动大量存在冲突的数据问题。
技术实现要素:
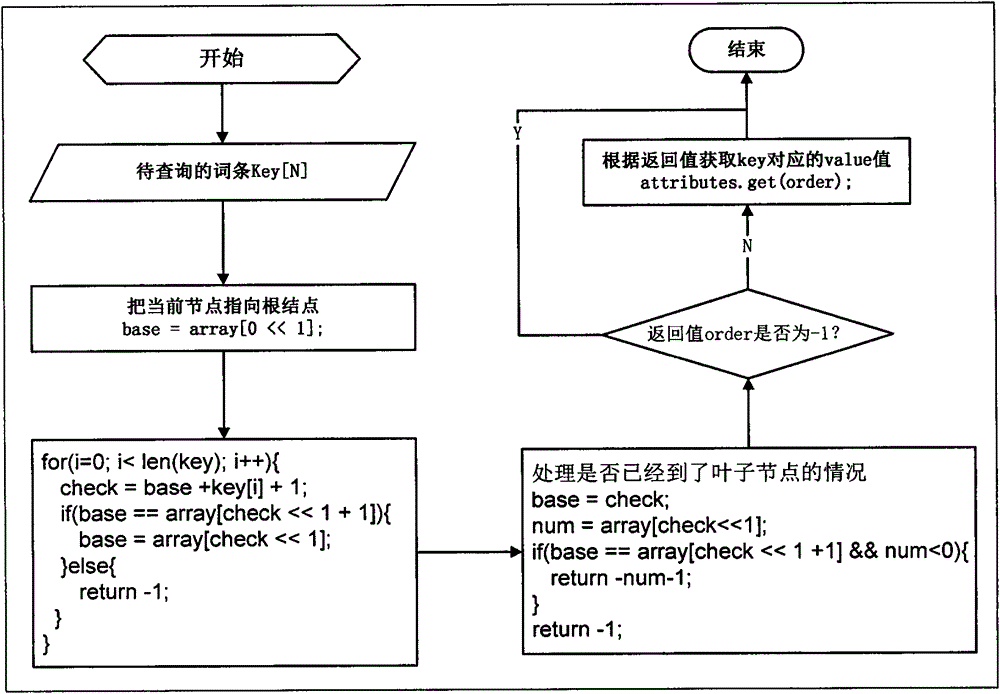
本发明旨在解决上述缺陷之一。因此,本发明提供一种基于一维线性空间实现Trie树的词典检索方法,通过生成一维线性空间的Trie树词典数据;根据用户输入确定待查询词条key;根据词条key的当前状态实现查询。在一维线性空间下构建Trie树的词典数据下,提高了词典加载和检索速度,并且能够快速检索到词条的所有前缀词,另外,基于一维线性空间实现Trie树的词典检索能够解决传统Trie树词典数据检索在Tire树的构建过程中存在的因插入新状态而引起的冲突问题,并能避免该冲突导致的大量词典数据的移动问题。为此,本发明公开了一种基于一维线性空间实现Trie树的词典检索方法,该方法包括以下步骤:生成一维线性空间Trie树的词典数据;根据用户输入确定待查询词条key;根据词条key的当前状态实现查询。优选地,词典数据的key转化为节点后存储在一维数组中,所述一维数组的值用来标识base值是否唯一。优选地,所述一维线性空间的Trie树中将所有终端结点变为非终端结点,在所述终端结点后面增加一个叶子节点,并将叶子节点的check值赋上其存储位置。优选地,所述叶子节点还包括:叶子节点的base值用以标识其是否为终端结点。优选地,所述查询包括以下步骤:把当前结点指向根节点;根据当前输入的字符做出状态转移,获取其直接后继状态的位置;校验当前状态的前驱,确定当前状态由哪一状态转移而来;获取词条key对应的value值。优选地,所述查询包括:词条key的查询可以获得其所有前缀词的结果。本发明提供的一种基于一维线性空间实现Trie树的词典检索方法,通过生成一维线性空间的Trie树词典数据;根据用户输入确定待查询词条key;根据词条key的当前状态实现查询。在一维线性空间下构建Trie树的词典数据下,提高了词典加载和检索速度,并且能够快速检索到词条的所有前缀词。同时,在Trie树的构建过程中通过调整base值,使得其所有直接后继均不会发生冲突,因此避免了数据移动或存储空间分配的回溯问题。应当理解,以上总体说明和以下详细说明都是说明性和实例性的,旨在提供对所要求的本发明的进一步说明。附图说明图1是本发明实施例一种基于一维线性空间实现Trie树的词典检索方法的流程图。图2是本发明实施例根据词条key的当前状态实现查询的流程框架图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。本发明实施例提供的一种基于一维线性空间实现Trie树的词典检索方法。如图1所示,是本发明实施例一种基于一维线性空间实现Trie树的词典检索方法的流程图。步骤S110:生成一维线性空间Trie树的词典数据。获取词典数据,要生成一维线性空间Trie树的词典数据包括以下具体步骤:步骤S111:将所有词条和属性信息以key为中心按词典顺序排序,合并拥有相同key值的values,要保证key不存在重复。遍历_Keys和_values中存储的元素,按词典顺序将Keys和_values以key为中心排序,并合并相同key的value值,将有序的key序列和value序列存储到List<String>keys和Collection<String>attributes中;该步骤的伪代码如下:步骤S112:定义起始状态,编号为0,其包含的信息值为[code=0,depth=0,start=0,end=N],其中N为词典的规模,即key的数量。步骤S113:将起始状态放入双数组第0位置,将其base[0]=1(array[2*0]=array[0]=1),并标识base为1的值已经被占用(保证所有状态的base值唯—),check[0]=0(array[2*0+1]=array[1]=0)步骤S114:以起始状态作为当前状态。步骤S115:获取当前状态的所有直接后继状态的信息,若直接后继结点列表为空,即当前结点为终端结点“$”,表示从起始结点到当前结点构成的key恰好是词典中的一个完整词条,将当前结点(终端结点)的base值赋上当前key词典顺序序号的相反数,该路径上执行完毕;否则执行步骤S116。该步骤的伪代码如下:步骤S116:为当前结点寻找一个合适的base值,使得base值唯一,且不会导致所有直接后继结点与现有Trie树存储的结点冲突。依次将当前结点的直接后继结点插入Trie树中,并将其check值赋上当前结点的base值,再依次把当前结点的直接后继结点作为当前结点,跳转到步骤S115。该步骤的伪代码如下:所述一维线性空间的Trie树中将所有终端结点变为非终端结点,在所述终端结点后面增加一个叶子节点,并将叶子节点的check值赋上其存储位置。将所有的终端结点变为非终端结点,并在其后面增加一个叶子结点,叶子结点的check值赋上自己的存储位置,叶子结点的base值赋上从初始结点(0结点)到当前叶子结点路径上的输入字符组成的完整词条在整个有序词条集合中位置的相反数(即叶子结点所处的key中在所有按词典排序的词条集中序号的相反数),因此结点的base值的符号用于标识是否是终端结点(叶子结点,其base值小于0)。步骤S120:根据用户输入待查询词条key。Trie树构建好之后,接下来就是查询用户输入的词条是否存在Trie树,即是否是从根结点到叶子结点的一条完整路径。步骤S130:根据词条key的当前状态实现查询。如图2所示,是根据词条key的当前状态实现查询的流程框架图,具体步骤如下:步骤S131:把当前结点指向根节点。步骤S132:根据当前输入的字符做出状态转移,获取其直接后继状态的位置。步骤S133:校验当前状态的前驱,确定当前状态由哪一状态转移而来。步骤S134:获取词条key对应的value值。在当前状态为s,输入的字符为c,下一状态为t的条件下,其本方法的查询过程的约束条件修改为:check[base[s]+c]=base[s];base[s]+c=t;每个状态的base[s]值唯一。若当前状态s可以转移到叶子结点t中,则其约束条件为:base[s]=t;t=check[t]。base[t]<0且base[t]的值为DFA的初始结点0到当前叶子结点经过的字符组成的词条在所有按词典顺序排序的词条集中位置的相反数。本发明实施例中可以获取词条key的所有前缀词,并可以将检索到的每条结果信息保存在一个对象TrieResult中,该表存储的变量作如下描述:Length表示当前key的长度;Index当前key在词典中的存储序号-1,即当前key对应属性的存储位置。本发明实施例一种基于一维线性空间实现Trie树的词典检索方法的查询速度18.3MB/s。因此,本发明提供一种基于一维线性空间实现Trie树的词典检索方法,通过生成一维线性空间的Trie树词典数据;根据用户输入确定待查询词条key;根据词条key的当前状态实现查询。在一维线性空间下构建Trie树的词典数据下,提高了词典加载和检索速度,并且能够快速检索到词条的所有前缀词,同时,在Trie树的构建过程中通过调整base值,使得其所有直接后继均不会发生冲突,因此避免了数据移动或存储空间分配的回溯问题。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1