一种基于改进贝叶斯分类的短信智能分类及搜索方法与流程
本发明涉及一种分类方法及搜索方法,尤其涉及一种基于改进贝叶斯分类的短信智能分类及搜索方法,属于计算机软件技术领域。
背景技术:
在信息化高度发达的今天,人们的交流也变得愈加快捷和频繁,在移动通信领域,短信凭借着它独特的优势,在人们的生活中占据着重要的位置。可以说,短信记录了人们生活的点点滴滴,一次约会,一次聊天,一次活动的通知,一则生日的祝福,都被一条条的短信记录下来。对于忙碌的现代人,他们已经没有时间像往常一样通过日记来记录下生活的琐事,而短信,就是他们信息化时代下新的日记本。然而,如今的手机短信管理软件看似琳琅满目,实际上则大同小异,基本都是对短信进行以联系人为特征分类,以时间为顺序显示的简单非智能化的管理,这样就导致了人们的短信成为了时间线而不是日记本,因为谁都不会将自己的工作日记和情感日记写到一起。对短信的智能管理,核心是能够对短信进行准确的分类,但是,对正常用户短信的分类困难重重,主要体现在文本太短:由于短信文本很短,这就导致特征值会多而散,非常的不明显,很多的分类算法面对这种情况很难达到预想的效果。当前,国内外的商业公司越来越多的将目光聚焦于移动平台,虽然关于自然语言处理和文本分类的研究已经相对成熟,但是将其运用于短信智能管理上还极不成熟,这种困难性是由短信的先天特质而决定的。
技术实现要素:
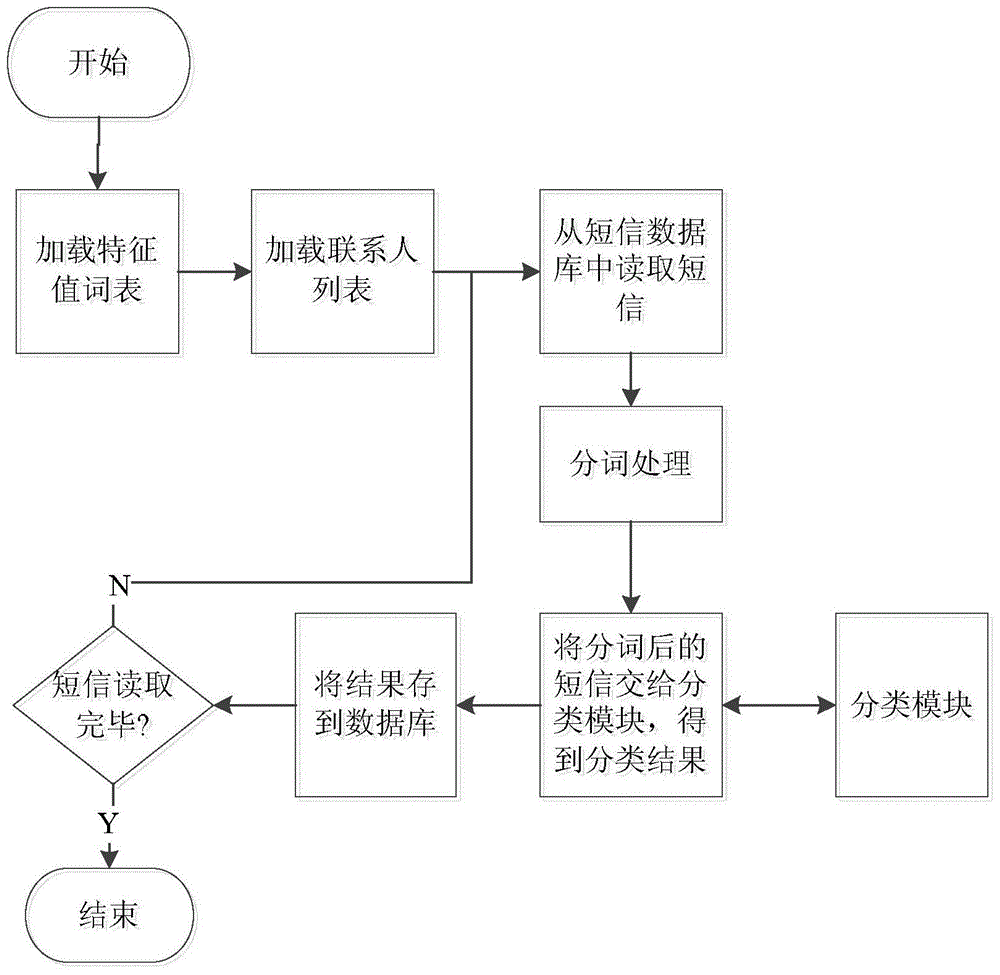
本发明的目的在于提出一种自动对短信进行分类及搜索的算法。本发明主要应用在Android智能手机上,每当用户接收到一条短信,就利用该算法将此条短信划入系统预先定义好的某个类别中,方便用户对短信进行查看和管理。本发明是基于改进贝叶斯分类的智能短信分类及搜索算法,能够通过对短信特点的分析,综合用户习惯,结合国内外现有短文本分类研究成果,解决短信的智能分类问题,从而提出一个高效可行的智能短信分类搜索方案。针对中文短信展开研究,分词是基础。本系统根据研究平台的特点选择了两款最适合的分词工具。1)中科院汉语分词系统:NLPIR(又名ICTCLAS2013)采用了层叠隐马尔科夫模型(HierarchicalHiddenMarkovModel),可同时进行分词和词性标注,支持用户词典,支持多种编码,在准确率上非常优秀。本系统采用NLPIR系统在PC端对训练集进行切词和词性标注。但是经过实验证明,NLPIR在手机端切词并不合适,原因是NLPIR发行包很大,打包到手机应用中会极大的影响用户体验。2)Jcseg:Jcseg是使用Java开发的一个中文分词器,使用流行的mmseg算法实现。根据Jsceg官方wiki公布,其分词准确率达到了98.41%。开源、轻量级的Jcseg是手机端切词的很好选择,由于Jcseg官方版本并不支持安卓系统,通过对Jcseg的部分代码重写(替换一些在Android中不支持的函数,比如将Java常用的System.out输出信息改为Android中的Log等;修改字典的读取路径,将字典文件放入Android应用的assets文件夹中),得到了一个安卓版本的Jcseg,实验证明,该分词系统在安卓手机上有很好的分词效果。为达成上述目的,本发明的技术方案步骤包括:1)对训练集中的短信,在PC端利用中科院汉语分词系统得到词条的集合;中科院分词系统对词语的词性进行了详细的分类(如名词、时间词、处所词、方位词、动词、形容词等),而其中有一些高频词是没有意义的,比如“的”“了”“吧”等。本发明出于效率和准确率的折中考虑,仅保留名词、动词和形容词三类;2)在PC端利用一种适用于短信内容的特征值提取方法计算词条的重要性值并排序,将前N个词条的集合作为系统的特征值集合;每个特征词及其在各个类别中的权重值(重要性值)保存在一个文件中,在系统进行手机端的初始化操作时直接导入;3)对于用户手机上已存在的每一条短信,根据改进的贝叶斯分类算法计算该短信属于每个类别的概率,并将具有最大概率的类别作为该短信的分类结果,保存在手机的短信类别数据库表中;4)监听用户的手机短信,对于每一条收到的短信,利用3)所述流程对该短信进行分类。5)利用搜索模块可以向数据管理模块发送搜索请求,对数据库中已有的短信进行搜索,并将得到的搜索结果发送到界面模块展示给用户。与现有技术相比,本发明的积极效果为:本发明综合了短信文本的词条频率、文本平均长度和总词条数等因素,在现有的特征值提取方法基础上进行改进,提出了一种适用于短信内容的特征值提取方法;本发明对朴素贝叶斯分类器进行了改进,加入了特征词的重要性值以及文本长度的因素,使之对短信文本的特征描述更加准确,得到了更好的分类效果。对手机短信进行准确的分类,有利于用户更便捷地从中发现生活主题、追踪生活轨迹,更高效地进行信息查询。分类之后的短信列表长度明显缩短,为用户进行信息检索提供了一种新的方式,提高了信息查询的效率。附图说明图1示出了本发明基于改进贝叶斯分类的智能短信分类算法流程图;图2示出了本发明实施例中初始化模块的流程图。具体实施方式本发明根据已有的短信文本训练集对改进的朴素贝叶斯分类器进行训练,得到特征词集合及其元素在各个预定义类别中的权重值,然后对用户的手机中已有的短信进行分类,保存分类结果,每当短信收信箱中有新短信到来时,自动对新短信进行分类。本发明的方法流程如图1所示,可以通过以下方式实施:1)利用PC端的训练模块根据已有的训练集进行训练,得到特征词集合及其元素在各个预定义类别中的权重值,并将这些数据发送到初始化模块;2)利用初始化模块将训练模块得到的数据和手机中已有的短信发送给分类模块进行分类;3)利用短信监听模块对新收到的短信进行监听,将捕获的短信数据发送给分类模块进行分类;4)利用分类模块,根据改进的贝叶斯分类算法对短信进行分类,将分类结果发送到数据管理模块,保存在数据库中,并发送到界面模块将结果展示给用户;5)利用搜索模块可以向数据管理模块发送搜索请求,对数据库中已有的短信进行搜索,并将得到的搜索结果发送到界面模块展示给用户;6)数据管理模块负责提供一个数据存储的接口,让其他模块能够统一的从该模块对数据库进行操作。7)利用界面模块,用户可以对短信进行查看和管理。PC端的训练模块的工作方法为:1)利用中科院分词系统对训练集中的文本进行分词,得到每个文档(即短信文本)及其词条的集合;训练集可以为从互联网获得的祝福短信库和新加坡国立大学2004年收集的短信语料库。2)对于每个词条,利用一种适用于短信内容的特征值提取方法计算它在整个训练集中的重要性值;3)将词条按重要性值降序排列,取前N个词条组成特征词集合;4)将每个特征词及其在每个类别中的重要性值输出到一个文件中。其中,适用于短信内容的特征值提取方法是本发明的一个重点内容,其重要性值的计算公式推导过程如下:词条t在类别C中的重要性用I(t,C)来表示。首先,显然如果一个词条在这个类别中出现的概率越高,则重要性越大,即:其中,F(C)表示类别C中的短信总数,F(t,C)表示属于类别C的短信中出现词条t的短信个数。其次,如果一个类别中的平均文档越长,则说明一个词条对文档类别的重要性会越小:其中,avgLen(C)表示类别C中短信的平均文本长度。最后,如果一个类别中的词条数越多,则一个词条对文档的重要性会越小:其中,termNum(C)表示类别C中的总词条数。综合以上分析,我们得到一个词条在一个类别中的重要性推导公式:为了避免I(t,C)等于0,我们采用拉普拉斯概率估计:最终的重要性用对数来表示:一个词条在整个训练集中的重要性为:根据此处I(t)的公式,取最大的前Q个词条作为特征值,这个值可以根据类别的多少灵活调整。如图2所示,手机端的初始化模块的工作方法为:1)加载特征值词表;2)从短信数据库中读取一条短信;3)利用安卓版本的Jcseg对短信进行分词处理;4)将分词后的短信发送至分类模块进行分类,利用贝叶斯分类算法根据特征词表对短信进行分类;5)将分类结果发送至数据管理模块,保存到数据库中;6)重复2)到5)的过程,直至将系统中所有短信完成分类。短信监听模块用来检测新短信的到来,如果有新的短信到来,该模块首先对该短信进行分词处理,然后将结果交由分类模块分类,并且将分类的结果和短信的内容以Notification的形式来提醒用户。分类模块利用改进的贝叶斯分类算法将短信归入系统预定义的某个类别当中,该算法是本发明的另一个重要内容。首先,训练集中的短信分为m类,对于手机上的每条短信d,其属于类别Ci(i=1…m)的概率是P(Ci|d),这样,具有最大P(Ci|d)的类别Ci就是该短信d最终的分类结果。具体的P(Ci|d)的计算如下:根据贝叶斯定理其中,P(Ci)表示类别Ci出现的概率,P(d)表示短信d出现的概率,P(d|Ci)是短信d属于类别Ci的“先验概率”。由于P(d)对于所有的类别Ci(i=1…m)均相等,所以有:P(Ci|d)∝P(d|Ci)·P(Ci)P(Ci)使用拉普拉斯概率估计:N是样本短信总数,m是类别总数,F(Ci)表示类别Ci中的短信总数,短信样本d可以表示为其提取的特征词{t1,t2,…,tk},由于不同的特征值对于给定的类别的影响是相互独立的,有:对于上式中tj在类别Ci中出现的概率P(tj|Ci)的计算,传统上有文档型计算公式和词频型计算公式。在本方法中,为了更精确地描述一个词条对于某个分类的重要性,我们用到了在训练模块中得到的特征词的权重,即P(tj|Ci)=I(tj,Ci)。另外,短信具有一个很重要的特征——长度。下面我们引入一个长度评估因子L(d,C),评估因子越大,表明长度特征越吻合,P(Ci|d)越大。P(Ci|d)∝L(d,Ci)假设类别C的文档平均长度为avgLen(C),待分类样本d的长度为Len(d),参数k代表了长度特征对类别的影响度,称之为长度影响因子,k越大,则长度特征对最终的结果影响越大。综合以上推导,得到改进的贝叶斯分类算法,对于类别Ci(i=1…m),待分类短信为d,则d属于类别Ci的概率为:分类模块根据此公式计算每条待分类短信属于每个类别的概率,概率最大的类别即为该短信所属的类别。本发明在分类过程中充分利用了特征值的选取和权重,进一步的加入了文本长度的因素,使分类结果更准确。数据管理模块主要提供一个数据存储的接口,让其他模块能够统一的从该模块对数据库进行操作。搜索模块接收用户输入关键词,在短信数据库中进行搜索,返回搜素结果到搜索列表界面并且显示。界面模块主要提供人机交互的作用,主要有1)联系人列表界面:类似手机默认的短信管理工具按联系人对短信进行组织,以列表的形式将联系人名字、短信数、最近短信时间等信息展示出来;2)短信列表界面:显示与某个联系人的短信对话详情,以短信气泡的形式显示每一条短信,并提供删除短信、发新短信等功能;3)分类列表界面:用圆角矩形按钮显示系统预定义的短信类别名称(如“祝福”“学习”等),打开可查看属于此类别的短信详情;4)搜索界面:显示按关键词搜索短信的结果列表,列表中提供信息内容预览,并以时间顺序排列;5)系统信息界面:显示该应用软件的用户反馈入口、使用帮助、作者信息等内容;6)新短信通知界面:当新短信到来时,在通知栏上显示短信预览,短信正文前加上分类结果作为前缀,并以该应用软件的图标表示这是该软件分类的结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1