基于集合选择的分布式信息检索方法与流程
本发明涉及分布式信息检索领域,尤其涉及一种基于集合选择的分布式信息检索方法。
背景技术:
在大数据时代,随着信息量的飞速增长,传统的集中式信息检索系统在面对海量数据时往往不堪重负,系统的负载随着数据量的增大将遇到瓶颈,无法快速的服务用户的查询请求。分布式信息检索系统可以提供一种整合各种不同信息资源的全面的信息服务。分布式信息检索系统将地理位置上分布广泛的异构数据联合起来,形成一个逻辑整体,为用户提供强大的统一的信息检索能力,通常被用来解决海量数据的索引检索问题。在具体的检索中,用户通常只关心排名靠前的检索结果,而每次查询的网站数目却数以亿计。这数亿的页面中,与查询相关的只有很少一部分,搜索部分而非全部的页面可以得到类似乃至于更好的检索结果。可以大概的估算下,若只搜索全部页面的5%乃至不到5%就可以获得类似搜索全部页面的检索效果,那么检索数据所需要的机器数量将会减少到约为原来的5%,节省下来的资源可以提供更多的服务,这对实际的系统而言有着巨大的意义。在每次的检索中,并不是全部的信息集合都包含了用户需要的信息,检索全部的信息集,不但将占用大量的网络带宽以及计算开销,同时也会因为受到大量不相关文档的干扰,影响检索的效果。因此集合选择,即在海量的信息资源中准确的定位到包含与用户查询相关的文档所属的信息集合,对于降低分布式信息检索系统的网络带宽消耗和计算开销,加快响应用户的检索请求,以及提高检索效果有着重要作用。近十年来在分布式信息检索集合选择领域出现了许多研究,主要包括以下几类:1)将集合中包含的文档看成一个逻辑整体,一个集合即是一个超大“文档”(bigdocument),将计算查询与集合的相关度就转化为计算查询与文档相关度,按相关度的高低对各集合排序。以上方法将各个集合中的所有文档看成一个逻辑上的统一整体,从而将分布式的集合选择问题转化为传统的查询词对文档的检索问题,能够直观的应用传统的检索方法进行检索。然而由于虚拟文档与真实的文档之间实际上存在着很大的不同,如文档长度,主题等,以上方法倾向于选择小的,主题较少的集合,而不是大的,主题复杂,包含相关文档更多的集合,不适用于集合大小不均匀的环境。2)估算集合中包含的与查询相关的文档数目,以相关文档数目的多少对各集合排序,从而选择排名较高的集合检索。以上方法通过估计各个集合包含的与查询相关的文档数,按包含文档数目从高到低对集合排序,能够有效定位到包含相关文档数目更多的集合。然而,对于返回topN个结果的检索请求,与查询最相关的文档未必包含在相关文档数目最多的集合。3)通过历史查询的检索结果来指导当前查询的集合选择,如基于历史点击数据的分布式信息检索集合选择方法,通过计算历史查询与当前查询的相关度,以及从历史查询的检索结果的用户点击情况推测出的历史查询与各集合的相关度,得到当前查询与各集合的相关度。然而由于查询词通常较短,词的二义性的存在,以及用户对每个查询结果的点击量通常较小,会降低检索的效果。集合选择是分布式信息检索研究的重要问题。集合选择的目的是对于给定的若干个信息集合,选出和用户查询最相关的部分信息集合进行检索。集合选择能够在海量的信息资源中准确的定位到包含与用户查询相关的文档所属的信息集合,对于降低分布式信息检索系统的网络带宽消耗和计算开销,加快响应用户的检索请求,以及提高检索效果有着重要作用。在分布式信息检索领域,集合选择又叫资源选择或数据库选择。公开号为101582085的专利文献公开了一种基于分布式信息检索系统的集合选择方法,该方法包括:计算需要检索的数据对待选数据库的覆盖程度,根据覆盖程度的大小,确定选择数据库集合的先后顺序。本发明方法大大提高了计算机在进行分布式信息检索时系统计算的时间和空间开销,保证了提问结果的查全率和查准率,增强了分布式信息检索的效率和效果。公开号为102521350A的专利文献公开了一种基于历史点击数据的分布式信息检索集合选择方法,实施步骤如下:1)检索代理服务器对查询日志进行预处理提取历史查询及其点击数据;2)检索代理服务器根据点击数据计算历史查询和各个信息集合之间的相关度;3)检索代理服务器计算新查询和各个历史查询之间的综合相关度;4)检索代理服务器根据综合相关度选择多个最相似的历史查询,根据选择的历史查询及其与各个信息集合之间相关度计算出新查询与各个信息集合的相关度;5)检索代理服务器选择多个信息集合,发出检索请求并将信息检索服务器返回的结果合并后输出给发出新查询的用户。本发明具有检索结果准确度高、网络带宽消耗低、响应速度快、检索经济高效的优点。
技术实现要素:
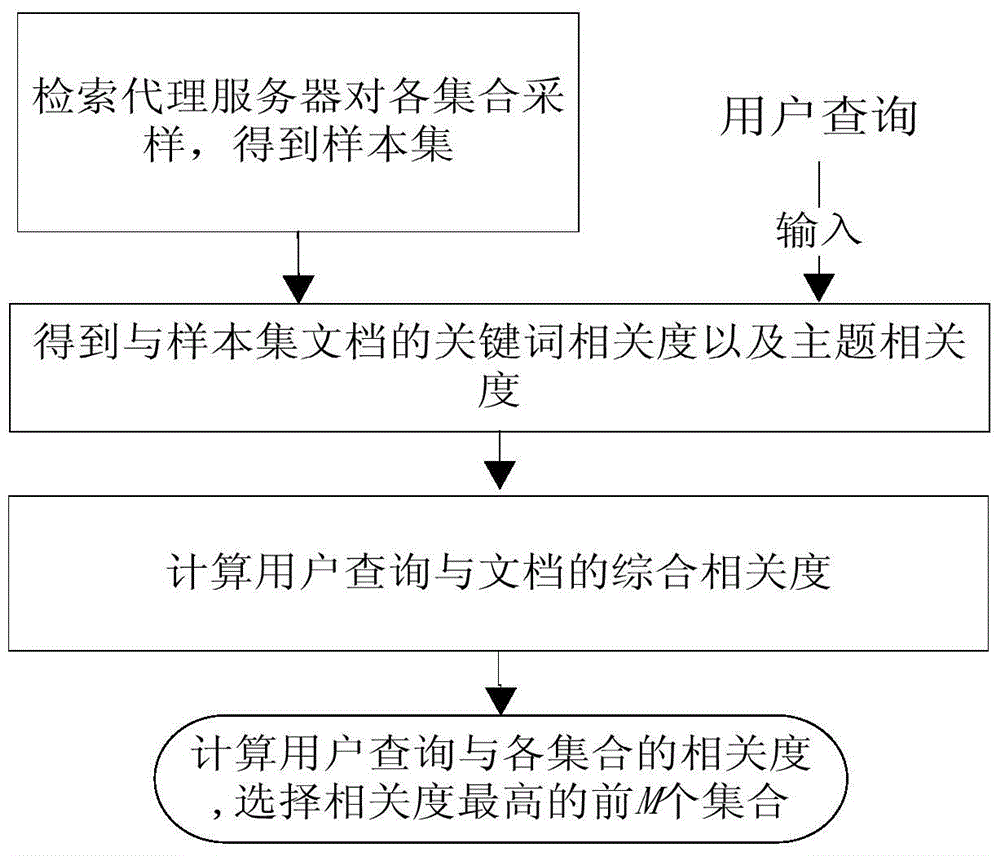
本发明要解决的技术问题是提供一种集合排序与选择方法。对于给定的用户查询,设计有效的集合选择方法,在保证检索的查准率和查全率的情况下,考虑查询和集合的语义关系,选择与查询最相关的若干个集合进行检索,从而降低分布式检索系统的网络带宽消耗以及计算和通信开销,提高系统的整体性能。一种基于集合选择的分布式信息检索方法,用于对存储于各检索服务器上的集合进行检索,包括:步骤1,从各个集合获取样本集,并根据其中的样本集文档建立LDA主题模型;步骤2,接收用户查询,计算用户查询和样本集文档的关键词相关度和主题相关度;步骤3,利用主题相关度和关键词相关度计算用户查询和样本集文档的综合相关度;步骤4,根据用户查询和样本集文档的综合相关度以及样本集文档所属集合的信息,计算用户查询与各集合的相关度,并按相关度的高低选择相应的集合进行检索。分布式信息检索包含一组客户端,一个检索代理服务器和一组检索服务器,其中检索服务器中存放着各自的集合,各检索服务器独立地检索自己的集合。用户通过在客户端输入用户查询,将用户查询发送到检索代理服务器;检索代理服务器不负责实际的检索工作,它通过本发明方法选择出与用户查询相关度较高的部分集合,并将分别发送至对应的检索服务器;各检索服务器单独地在自己的集合中检索,然后把查询结果返回给代理服务器;检索代理服务器收到各检索服务器的查询结果后,通过基于综合相关度的合并策略对得到的查询结果合并,并进行全局的排序,最后检索代理服务器将排序后的检索结果返回到查询客户端,呈现给用户。利用基于查询的采样方法对所有集合进行采样,构建样本集。基于查询的采样方法根据JamieCallan,MargaretCollell.Query-BasedSamplingofTextDatabases[J]ACMTransactionsonInformationSystems,2001,19(2):97-13所提供的方法进行。利用基于查询的采样方法对所有集合进行采样方法如下:步骤a,选择一个查询词;步骤b,利用所选查询词对所有的集合进行查询;步骤c,将每个集合获取查询结果中的前n篇文档加入样本集中,其中n为正整数;步骤d,从返回的所有文档中提取词和词频,根据词和词频的特征学习和更新文档所属的集合的描述信息;步骤e,对于每个集合判断样本集中文档数目是否达到所有集合文档总数目的预设百分比:是,结束查询;否则,从步骤d提取的词中随机选取新的查询词,返回步骤b。作为优选,步骤e中预设百分比为3%。其中利用样本集建立的LDA主题模型包括文档-主题概率分布及主题-词概率分布,建立方法如下:步骤1-1,从样本集中选取一篇未读的样本集文档;步骤1-2,基于狄利克雷参数α,从文档-主题的概率分布θ中选取一个与样本集文档相关的主题;步骤1-3,对于所选取主题,基于参数β,从主题-词的概率分布中选取一个与主题相关的词;步骤1-4,重复步骤1-2及1-3直到生成了样本集文档中的所有词,将样本集文档标记为已读;步骤1-5,返回步骤1-1,直到遍历完样本集中的所有样本集文档。其中狄利克雷参数α及参数β为预设值,例如可以选择α=50/k,β=0.01,其中k为主题数目。在步骤2中,计算用户查询和样本集文档的关键词相关度方法为:计算得到得分rel(q|di),计算公式如下:其中,Wti,q为用户查询的第i个词ti所对应的权重,Wti,d为样本集文档的第i个词ti所对应的权重,用户查询或样本集文档中的词ti权重所对应的Wti的计算公式如下:Wti=tfi×idfi;其中,tfi为用户查询q或样本集中第i个文档di中词ti出现的频率,逆向查询频率idfi的计算公式如下:其中,dfi为包含ti的样本集文档个数,|S|为样本集文档总数;从而得到用户查询与样本集文档的关键词相关度Scorekeyword(di,q):其中relmax(q|di)表示所有得分中最高的得分。用户查询与样本集文档的关键词相关度为归一化后的关键词相关度。在步骤3中,计算用户查询与样本集文档的主题相关度方法为,利用如下公式得到用户查询与样本集文档的主题相关度Scorelda(di,q):其中,P(q'|di)表示扩展查询q'与样本集中第i个文档di的主题相关度,Pmax(q'|di)表示P(q'|di)中最大的取值,计算公式如下:其中,eff(tj)为词tj对扩展查询q'的影响度,P(tj|di)表示扩展查询q'中的词tj与样本集中第i个文档di在LDA模型中的主题{z1,z2,…,zk}的主题相关度;k为主题的个数;eff(tj)的计算公式为:eff(tj)=sim(q|pi),tj∈q'且tj∈pi,其中sim(q|pi)为计算查询pi与查询q相似度的函数计算公式如下:其中result(q)表示用户查询所得文档,result(pi)为历史查询所得文档;P(tj|di)计算公式如下:其中,为通过主题-词概率分布所得到的查询q'中的词tj与主题zx相关的概率,P(zx|di,θ)为通过文档-主题概率分布θ所得样本集文档di与主题zx相关的概率,其中x=1,2,…,k。N(result(q)∩result(pi))表示用户查询q所得文档和历史查询pi所得文档中相同文档的个数,N(result(q)∪result(pi))表示用户查询q所得文档和历史查询pi所得文档中的文档总数。其中,主题{z1,z2,…,zk}为样本集中第i个文档di在LDA主题模型中文档-主题概率分布所包括的所有主题的集合。在步骤3中,用户查询与样本集文档的综合相关度Score(di,q)计算公式为:Score(di,q)=λ×Scorelda(di,q)+(1-λ)×Scorekeyword(di,q);其中,λ为用户查询与样本集文档的主题相关度在总和相关度中的权重,取值范围在[0,1]。其中,λ越大表示主题相关度得分在综合相关度得分中的影响越大。用户查询q与第i个集合Ci的相关度计算方式如下:其中,|Ci|为集合Ci包含的文档总数,为样本集中采样自集合Ci的文档,为样本集中采样自Ci的文档总数,R(dk|q)表示样本集文档dk对所在集合与用户查询q的相关度影响;其中,dk为与用户查询的综合相关度排名为k的样本集文档,Score(dk,q)为样本集文档dk与查询q的综合相关度,γ为样本集中与用户查询相关的文档数量阈值,γ的计算公式如下:γ=ratio×|S||S|为样本集文档的总数,参数ratio为预设比例。其中在得到用户查询与样本集文档的综合相关度之后,按照综合相关度进行排序,综合相关度越高,次序越靠前。参数ratio表示样本集中相关文档数占样本集文档总数的比例。ratio过大将会引入许多不相关的样本集文档,ratio过小可能会过滤掉许多相关的样本集文档,因此作为优选,参数ratio取值为0.003。本发明方法与现有的检索方法相比,优点在于:(1)LDA主题模型提供了一种有效的基于主题的文档集建模方式,本方法充分考虑查询与样本集文档潜藏的语义关系,采用基于关键词相关度和基于主题相关度结合的方法来估计查询与样本集中各文档的综合相关度,能更准确的估计查询与文档的相关度。(2)利用历史查询扩展当前查询,能有效的解决因为查询词通常较短而造成的主题估计的误差,能更有效的估计当前查询的主题,同时历史查询与当前的用户查询的相似度采用基于检索结果的方法,避免了查询词较短和二义性存在造成的影响,更准确地估计了查询间的相似度,进而更好的计算查询与文档的主题相关度。(3)在计算用户查询与集合相关度时,充分考虑了样本集文档与用户查询的综合相关度,样本集文档综合相关度排名,样本集文档所属集合的大小以及该集合被采样的文档大小四方面的因素,提供了更有效的通过样本集估计用户查询与集合相关度的方法。附图说明图1为本发明所采用的分布式信息检索架构图;图2为本发明方法的步骤流程图。具体实施方式分布式信息检索的架构如图1所示,包含一组客户端,一个检索代理服务器和一组检索服务器,其中检索服务器中存放着各自的集合,各检索服务器独立的检索自己的集合。一个具体的查询过程可以描述如下:用户通过查询客户端,将查询请求发送到检索代理服务器;检索代理服务器不负责实际的检索工作,它通过集合选择算法选择出与该查询相关的部分集合,并将检索请求分别发送至选择的检索服务器;各检索服务器单独的在自己的信息集合中检索,然后把检索结果返回给代理服务器;检索代理服务器收到各检索服务器的检索结果后,通过合并策略对得到的检索结果合并,并进行全局的排序;最后检索代理服务器将排序后的检索结果返回到查询客户端,呈现给用户。本发明方法总体流程如图2所示,分为在线和离线两部分,离线部分主要是对样本集的预处理:首先代理服务器使用基于查询的采样方法对各集合采样,其次代理服务器对样本集预处理,构建倒排索引,同时对样本集建立LDA主题模型,推导出主题-词概率分布以及文档-主题概率分布θ。在线部分包括:1)查询检索倒排索引,计算查询与各文档关键词相关度;2)通过历史查询得到新查询的扩展查询,同时利用扩展查询和LDA推断出的分布计算查询与各文档主题相关度;3)得到查询与样本集中各文档的综合相关度;4)计算查询与各个集合的相关度并排序,选择排序结果最靠前的M个集合,将检索请求发送到这些集合。步骤1,从各个集合获取样本集,并根据其中的样本集文档建立LDA主题模型。步骤1阶段通过数据预处理来获取样本集,数据预处理包括集合选择前数据的准备和处理。首先通过基于查询的采样方法对存储在各个检索服务器上的集合进行采样并在检索代理服务器中构建样本集。基于查询的采样方法对各个检索服务器上的集合进行采样的具体步骤如下:步骤a,选择一个查询词;步骤b,利用所选查询词对所有的集合进行查询;步骤c,针对每个集合获取查询结果中的前n篇文档,其中n为正整数;步骤d,从返回的所有文档中提取词和词频,根据词和词频的特征学习和更新各个集合的描述信息;步骤e,对于每个集合判断文档数目是否达到样本集所设定数目的预设百分比:是,结束查询;否则,选取新的查询词,返回步骤b。然后,根据样本集构建LDA主题模型和倒排索引。其中LDA主题模型的建立方法如下:步骤1-1,从样本集中选取一篇未读的样本集文档;步骤1-2,基于狄利克雷参数α,从文档-主题的概率分布θ中选取一个与样本集文档相关的主题;步骤1-3,对于所选取主题,基于参数β,从主题-词的概率分布中选取一个与主题相关的词;步骤1-4,重复步骤1-2及1-3直到生成了样本集文档中的所有词,将样本集文档标记为已读;步骤1-5,返回步骤1-1,直到遍历完样本集中的所有样本集文档。在本发明当前实施例中,狄利克雷参数α取值为50/k,参数β的取值为0.01,其中k为样LDA主题模型中主题的数目。另外,从存储在检索代理服务器的查询日志中提取历史查询,以方便实时地查询计算与样本集文档的主题相关度。步骤2,接收用户查询,计算用户查询和样本集文档的关键词相关度和主题相关度。将查询看成由查询词构成的短文本,用户查询q和样本集文档均可表示为向量(<t1,Wt1>,<t2,Wt2>,…,<tn,Wtn>),在用户查询中ti表示用户查询的第i个词,在样本集文档中,ti表示样本集文档的第i个词,Wti为用户查询中或样本集文档对应词ti的权重。查询与文档的关键词相关度采用空间向量模型的余弦相似度计算,权重使用tf-idf的方法计算,并将结果归一化:其中,Wti,q为用户查询的第i个词ti所对应的权重,Wti,d为样本集文档的第i个词ti所对应的权重,用户查询或样本集文档中的词ti权重所对应的Wti计算公式如下:Wti=tfi×idfi(2)其中,tfi为用户查询q或样本集中第i个文档di中词ti出现的频率,逆向查询频率idfi的计算公式如下:在得到rel(q|di)之后,计算用户查询与样本集文档的相似度:式中tfi为查询q或文档di中词ti出现的频率,idfi为逆向查询频率,dfi为包含ti的文档数,|S|为样本集文档总数。设用户查询q={t1,t2,...,tm},历史查询集合为p={p1,p2,...,pn},其中历史查询集合中第i个历史查询pi表示为一组词的形式则用户查询q基于历史查询集合{p1,p2,...,pn}的扩展查询扩展查询q'中的每个词的影响度为该词所属的历史查询pi和用户查询q的相关度,即对于词t∈q'且t∈pi,词t在扩展查询q'中的影响度efft=sim(q|pi),其中sim(q|pi)为计算查询pi与查询q相关度的函数。则查询p与查询q的相似度计算如下:其中result(q)表示用户查询所得文档,result(pi)为历史查询所得文档。N(result(q)∩result(pi))表示用户查询q所得文档和历史查询pi所得文档中相同文档的个数,N(result(q)∪result(pi))表示用户查询q所得文档和历史查询pi所得文档中的文档总数。扩展查询q'中的词tj与文档di在LDA模型中得出的主题{z1,z2,…,zk}上的主题相关度计算如下:其中为通过主题-词概率分布可以得到用户查询q中的词tj与主题zx相关的概率。而另一个P(zx|di,θ)为通过文档-主题概率分布θ得到的样本集中的i个文档di与主题zx相关的概率。通过扩展查询q'中各个词与文档的主题相关度,可以得到扩展查询q'与样本集中第i个文档di的主题相关度,计算如下:其中eff(tj)为词tj对扩展查询q'的影响度。将之归一化得到用户查询q与样本集中第i个文档di的主题相关度:步骤3,利用主题相关度和关键词相关度计算用户查询和样本集文档的综合相关度。样本集文档与用户查询的综合相关度由两部分线性组成,一部分是基于LDA主题模型的样本集文档和用户查询的主题相关度,另一部分是用户查询与样本集文档的关键词相关度,样本集当中的样本集中第i个文档di与用户查询q的综合相关度Scorelda(di,q)计算如下:Score(di,q)=λ×Scorelda(di,q)+(1-λ)×Scorekeyword(di,q)(9)其中λ取值在[0,1],为主题相关度得分在综合相关度得分的权重,λ越大表示主题相关度得分在综合相关度得分中影响越大。步骤4,根据用户查询和样本集文档的综合相关度以及样本集文档所属集合的信息,计算用户查询与各集合的相关度,并按相关度的高低选择相应的集合进行检索。考虑样本集文档与查询的综合相关度及其排名,每个文档对其所在集合与查询q的相关度影响计算如下:γ=ratio×|S|(11)其中dk为样本集中与查询的综合相关度排名为k的文档,Score(dk,q)为文档dk与查询q的综合相关度,|S|为样本集的文档总数,γ为样本集中与查询相关文档的阈值,表示与查询相关的有效文档数量,参数ratio表示检索结果的相关文档数占样本集文档总数的比例。考虑集合大小及其被采样文档大小的影响,第i个集合Ci与用户查询q的相关度计算如下:其中|Ci|为第i个集合Ci包含的文档总数,为样本集中采样自第i个Ci的文档,为样本集中采样自Ci的文档总数。按照各集合与查询的相关度对各集合排序,选择排名靠前的M个集合检索,其中M为正整数。本发明在保证检索结果的召回率和准确率的情况下,能够有效减少检索时的网络带宽消耗和计算开销,增强了分布式信息检索系统的效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1