自主型思考模型生成机的制作方法
本发明涉及学习人的思考模型、并针对某个状况生成与人所思索的一系列思考模型相同的思考模型的智能机械。进而,还涉及通过评价并记录所输入的信息的价值来自主地扩大知识的智能机械。
背景技术:
以往的自动机械、机器人等智能机械依照预先编程的步骤进行行动来对应某个状况。程序需要由人设计并输入到搭载于机械中的计算机,机械自身无法设计并更新程序。
专利文献:日本专利公开平11-126197(人工知能システム)
技术实现要素:
发明所要解决的技术问题
以往的自动机械、机器人等智能机械依照预先编程的步骤进行行动来应对某个状况。程序需要由人设计并输入到搭载于机械中的计算机,存在在开发中需要大量时间等缺点。
[现有技术](对应于技术方案1)
在通过图像信息、声音信息以及从人得到的信息来使机械进行动作的情况下,通过在搭载于机械的计算机中嵌入预先利用程序语言制作的程序并执行来实现。以当检测到预先设定的条件时执行对应的动作的方式来制作程序。如果条件的检测以及对应的动作不适合,则修正在计算机中安装的程序。将条件以及对应的动作设定为与人的思考对应的模型、通过从模型向模型的变化来执行动作的机械在以往是没有的。
[现有技术](对应于技术方案2)
分析所输入的信息的价值、记录判断为有益的信息并自主地扩大判断为有用的信息的机械在以往是没有的。
[现有技术](对应于技术方案3)
分析所输入的语句的单词的词类、识别语句的主语部分、谓语部分、主语、谓语、修饰语等、并针对“何时(いつ)”、“何地(どこで)”、“谁(誰が)”、“将什么(何を)”、“如何(どのように)”、“为何(なぜ)”、“进行了吗(したのか)”进行识别/整理的机械在以往是没有的。
[现有技术](对应于技术方案4)
为了使机械输出从所输入的多个条件导出或者联想的结果,需要在搭载于机械的计算机中预先设定为程序。以当检测到预先设定的条件时输出对应的结果的方式来制作程序。对条件进行模型化、并通过模型之间的连接的组合而输出导出或者联想的结果的机械在以往是没有的。
[现有技术](对应于技术方案5)
以往,通过获取与输入信号的相关度来进行模型的辨别,不具有主动地避免错误辨别的功能。
[现有技术](对应于技术方案6)
以往,相对于输入信号,单独地检测相关度,不具有通过多根线同时并行处理相关度的功能。
[发明所要解决的技术问题](对应于技术方案1)
以往,在使机械进行动作的情况下,需要在计算机中预先设定程序。需要制作根据图像信息以及声音信息判断状况的程序、根据各个条件使机械动作的程序,并在搭载于机械的计算机上安装执行。需要通过专用的程序语言制作程序,存在在开发中需要大量时间等缺点。
另外,如果条件的检测以及对应的动作不适合,则人需要修正安装于计算机中的程序,存在在修正中需要大量时间等缺点。
[发明所要解决的技术问题](对应于技术方案2)
当在机械中记录信息的情况下,人需要依次判断信息的价值,将判断为有用的信息输入并记录到机械,存在需要大量时间等缺点。
[发明所要解决的技术问题](对应于技术方案3)
在从记录于计算机等的信息中查找所需的信息的情况下,人需要将关键字等输入到计算机并检索关联的数据来搜索所需的信息,存在需要大量时间等缺点。
[发明所要解决的技术问题](对应于技术方案4)
为了使机械输出从所输入的多个条件导出或者联想的结果,人需要在搭载于机械的计算机中预先设定为程序,存在在程序制作中需要大量时间等缺点。
[发明所要解决的技术问题](对应于技术方案5)
以往,在进行模型辨别的情况下,随着模型学习推进,检测增益等增大,存在大量发生错误辨别等缺点。
[发明所要解决的技术问题](对应于技术方案6)
以往,相对于输入信号,单独地检测相关度的依次处理,无法同时并行处理相关度检测。
解决技术问题的技术手段
[解决技术问题的技术手段](对应于技术方案1)
本发明中的思考模型生成机将图像信息、声音信息及语言变换为模型。通过图像检测器检测图像信息,变换为与对象物对应的模型。通过声音检测器检测声音信息,变换为与声音对应的模型。语言也被变换为由词、单词构成的模型。模型是通过检测器识别的信号的组合来表现对应的现象的特征而得到的。
根据图像、声音以及语言生成的模型被记录到模型记录器。关于记录于模型记录器的模型,能够在与其他模型之间设定关系。例如,将某个现象A表现为模型A,将其他现象B表现为模型B。在如果发生现象A则也发生现象B的情况下,对应的模型A与模型B存在关系。以当激活模型A后接着激活模型B的方式,通过模型控制器设定结合关系。
作为具体的例子,作为图像信息,如果输入《狗》,则生成狗的图像模型,在模型记录器中记录为狗的图像模型。另一方面,作为语言信息,将《いぬ》输入到作为5的语言输入器,变换为经整理的型。接下来,在作为6的语言模型变换中变换为语言模型,记录到模型记录器。该图像模型和语言模型表示同一对象(在该例子中是狗),所以当通过模型控制器设定结合关系后,当狗的图像模型激活时,接着作为语言信息,表示《いぬ》的语言模型激活。如果这样使思考模型生成机看到狗的图像,并作为语言信息学习到是《いぬ》(在此表示设定模型之间的关系),则在下次看到狗时能够辨别出是《いぬ》。
以上叙述了图像模型与语言模型的结合关系,但声音模型与语言模型的结合关系也能够同样地设定。
接下来,说明在机械中生成思考模型的手段。人使用语言来思考。在看到某个现象时,人辨别它是什么。进而,关于针对辨别出的结果的感想、应对等,也使用语言。作为例子,设为在人行横道上看到红绿灯。在红绿灯是红灯的情况下,人辨别出红绿灯是红灯,想起接下来的语言。人想起“在人行横道上红绿灯是红灯的情况下要站住”这样的语言,同时对自己的身体输出指令以停住。由此,人在人行横道之前停住。接下来设为红绿灯变为绿灯。人辨别出红绿灯变为绿灯,想起接下来的语言。人想起“在人行横道上红绿灯是绿灯的情况下注意车辆并通过”这样的语言,同时对自己的身体输出指令,以注意车辆并横过人行横道。由此,人一边注意车辆一边过人行横道。说明了在机械中也能够生成与人的思考模型相同的模型并行动。在图像检测中检测出的红灯的图像模型被辨别为红灯的图像。它向图像检测器输入红灯,将红灯的图像模型记录到模型记录器。同时,将“红灯”这样的语言模型记录到模型记录器。在学习模型之间的关系的情况下,使用模型控制器。首先,将红灯输入到图像检测器。由于红灯的图像模型已经被记录到模型记录器,所以红灯的图像模型激活。接下来,使“红灯”这样的语言模型激活。模型控制器当在所激活的模型之后其他模型激活了时,从先激活的模型向接下来激活的模型地生成结合关系。当一旦生成结合关系后,当最初的模型激活时,接下来的模型激活。在上述例子中,在红灯的图像模型激活之后,激活“红灯”这样的语言模型,所以生成从红灯的图像模型向“红灯”这样的语言模型的结合关系。在生成结合关系之后,当输入红灯的图像模型时,“红灯”这样的语言模型激活。
通过相同的步骤,也能够实现绿灯的辨别。
接下来,在语言模型与语言模型之间生成结合关系。
如果使“红灯”这样的语言模型激活,并接着它激活“站住!”这样的语言模型,则生成如下结合关系。“红灯”→“站住!”
同样地,能够生成“绿灯”→“注意车辆并过马路!”这样的结合关系。
接下来,“站住!”这样的语言模型被送到控制信号生成器,针对致动器生成命令“站住”的控制信号。同样地“注意车辆并过马路!”这样的语言模型被展开为“检测确认周围没有车!”和“过马路!”这样的语言模型,当检测到周围没有车时,“过马路!”这样的语言模型被送到控制信号生成器,针对致动器生成命令“过马路”的控制信号。
如上所述,通过按照人的思考模型,使思考模型生成机生成模型并动作,能够针对机械使用《使用语言》的模型来实现与人相同的控制。
[解决技术问题的技术手段](对应于技术方案2)
本发明中的思考模型生成机分析所输入的信息的价值。能够针对例如如下项目实施分析。作为分析的结果,关于判断为有用的信息,在识别出的领域中追加分析结果,记录到模型记录器。
①分析是从谁得到的信息。
②分析是与哪个领域有关的信息。
③分析是否为关注的领域的信息。
④分析与所记录的信息的关系(匹配、不匹配、新颖性、依据的妥当性)。
⑤分析信息的种类(真实、事实、推测、传闻、询问语句、命令语句、感叹语句等)。
最初,说明①分析是从谁得到的信息。
信息分析器识别所输入的信息以及信息的发送源(书、电视机、人··等)是什么。这能够通过确认所输入的信息的传递路径来实现。例如,在书中记载的图像信息能够识别为是来自书的信息。来自电视机的信息能够根据图像信息以及声音信息识别为是来自电视机的信息。关于来自人的信息,能够根据图像信息识别周围存在的人是谁,并且识别是来自谁的声音信息。
说明②分析是与哪个领域有关的信息。
一般来说,在所输入的信息中,包括作为是与哪个领域有关的信息的线索的单词以及语句等。即使在最近的信息中不包括作为线索的单词以及语句等,只要暂且监视一会儿,就能够检测出作为线索的单词以及语句等。
将信息输入到模型变换器,将信息变换为语言模型。在人观察该信息而判断出是与哪个领域有关的信息时,将与领域有关的语言模型记录到模型记录器,设定从与输入信息对应的语言模型向表示领域的语言模型的结合关系。能够经过结合系数,实施语言模型与语言模型的结合。在判断为所输入的信息1与领域1对应的情况下,生成从与信息1对应的语言模型经过结合系数向与领域1对应的语言模型的结合。在与信息1对应的语言模型激活时,针对领域1的结合以与结合系数成比例的强度强化。关于领域1的语言模型是否激活,通过经过结合系数而输入的结合的强度相对于事先设定的阈值的大小关系来决定。通过针对所输入的信息反复进行上述识别,学习所输入的信息的领域分析。在针对所输入的信息的领域分析的结果错误的情况下,以减弱针对输入模型的结合的方式,修正结合系数。
通过反复进行这样的学习,能够正确地实施所输入的信息的领域分析。
说明③分析是否为关注的领域的信息。
这能够通过与在②中叙述的方法相同的方法来实现。通过分析在所输入的信息中是否包括关注的领域的单词以及语句等,能够识别所输入的信息是否为关注的领域的信息。
说明④分析与所记录的信息的关系(新颖性、匹配、不匹配)。
针对所输入的信息,实施在上面叙述的领域分析,与记录于模型记录器的模型进行对照。如果检测到有关联的模型,则针对与所输入的信息的关系进行分析。能够在记录于模型记录器的语言模型与语言模型之间,定义匹配、不匹配的关系。例如,在表示“上”的语言模型与表示“下”的语言模型之间,定义表示相反的意义的结合关系。另外,在表示“美丽”的语言模型与表示“漂亮”的语言模型之间定义表示类似的意义的结合关系。这样,能够在语言模型与语言模型之间,设定识别相反的意义、类似的意义的结合关系。例如,设为在所输入的语言模型中包括表示“上”的语言模型。设为在模型记录器中检测到与所输入的信息关联的信息,在该关联信息的语言模型中包括表示“下”的语言模型。此时,所输入的语言模型将“上”这样的语言模型激活,关联信息的语言模型将“下”激活。语言模型“上”和“下”为表示相反的结合,所以能够辨别出在所输入的信息与所记录的关联信息之间存在不匹配。同样地,在激活了如“美丽”和“漂亮”的关系那样表示类似的语言模型的情况下,能够辨别出在所输入的信息与所记录的关联信息之间存在匹配。人在接触到新的信息时,通过想起并比较关联的信息,确认匹配以及不匹配。在机械中也能够进行相同的动作。
接下来,说明分析在所输入的信息中是否有新颖性的方法。
生成包括构成所输入的信息的语言模型的下位的语言模型(对于语句而言是单词)和等价的语言模型的语言模型。该语言模型不对所输入的信息的新颖性造成影响,成为具有同一意义的语言模型的集合。
同样地,生成包括构成与所输入的信息关联的信息的语言模型的下位的语言模型和等价的语言模型的语言模型。该语言模型也不对所包括的信息量造成影响,成为具有同一意义的语言模型的集合。能够解释为该语言模型的集合在由单词构成的意义空间中,关于语言表示的意义占据最大限度的区域。
在关于在所输入的信息中是否有新颖性的判断中,在对所记录的关联信息表示的语言模型的集合与新信息表示的语言模型的集合进行比较时,当在关联信息表示的语言模型以外的部位存在新信息的语言模型时,能够判断为有新颖性。其原因为,这表示在所输入的信息中包括在关联信息中没有的信息。
接下来,说明依据的妥当性。
在将所输入的信息变换为语言模型并记录时,尽可能将依据也变换为语言模型并记录。例如,在输入了“A是B。”这样的信息的情况下,关于“这是由于A是C”这样的依据,也设为语言模型来记录。通过反复进行这样的记录,组成构成依据的语言模型的集合。通过基于真实、事实或者常识来累积依据的记录,能够使表示依据的语言模型具有妥当性。在假设在所输入的信息与所记录的关联信息之间检测到不匹配时,比较其依据。
通过将所输入的信息以及关联信息的依据与构成在上述中所生成的依据的语言模型的集合进行对照,能够针对哪一个作为依据较为妥当进行比较。在与构成依据的语言模型进行了对照时,在未检测到所对照的对象的情况下,则在过去未说明该依据。即,在与构成依据的语言模型的集合进行对照时,对照越多,则依据的妥当性越高,对照越少,则依据的妥当性越低。
说明⑤分析信息的种类(陈述语句(真实、事实、推测、传闻)、疑问语句、命令语句、感叹语句等)的方法。
关于所输入的信息的语言模型,分析信息的种类。一般来说,在语言模型中,包括识别语句的种类(陈述语句、疑问语句、命令语句、感叹语句等)的模型。
陈述语句是“です”、“ます”、“である”、“だ”等
疑问语句是“ですか”、“ますか”、“だろうか”等
命令语句是“せよ”、“しろ”、“して下さい”等
感叹语句是“なんて··だろう”、“なんて··でしょう”等
推测是“だろう”、“でしょう”等
传闻是“らしい”等
通过检测这些模型,能够识别信息的种类。
通过除了语言模型以外还引入图像模型、声音模型的信息,能够实施真实以及事实的识别。在将在图像模型中实际发生的现象记录为语言模型的情况下,能够识别为事实。另外,在信息的源泉是可靠的人、书籍等的情况下,能够识别为事实、真实并记录。
通过以上的①至⑤的分析来分析所输入的信息,评价作为信息的价值。来自可靠的发送源的关注的领域的信息被判断为价值高,来自不可靠的发送源的不关注的领域的信息被判断为价值低。将价值高的信息作为语言模型记录到模型记录器,不记录价值低的记录。
由此,依次累积有用的信息,在模型记录器中构成庞大的知识。
[解决技术问题的技术手段](对应于技术方案3)
本发明中的思考模型生成机分析所输入的语句的单词的词类,识别语句的主语部分、谓语部分、主语、谓语、修饰语等,针对“何时”、“何地”、“谁”、“将什么”、“如何”、“为何”、“进行了吗”进行识别/整理并记录。在希望从所记录的信息提取所需的信息的情况下,通过输入希望获知与什么有关的什么,输出所需的信息。
构成思考模型生成器的语句构成分析器分析所输入的信息的语言模型的单词的词类。各单词的词类是确定的,所以针对每个单词,将词类对应起来。接下来,语句构成分析器分析词类及其组合。例如,如下所述,能够识别主语、谓语、修饰语等。
→(情形1:“他动词”的主语是“名词2”)
“名词1”+“助词(を)”+“他动词”是“名词2”的修饰语
→(情形2:“他动词”的主语是“名词3”)
“名词1”+“助词(を)”+“他动词”是“名词3”的修饰语
·“名词(日期时间)”→意味着(何时)
·“名词(场所)”+“助词(で)”→意味着(何地)
·“语句(···する方向で)”→意味着(如何)
·“语句(···だからである)”→意味着(为何)
等
进而,语句构成分析器将识别出的主语、谓语、修饰语配置于分别对应的位置来生成语言模型。通过这样配置,(何时)、(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么(何した))变得明确。
如果使用这样整理并配置了的语言模型,则容易针对各种提问生成回答。具体而言,作为检索用的语言模型,使用下述语言模型。
检索用的语言模型:
(何时)+(何地)+(谁)+(将什么)+(如何)+(为何)+(做了什么)
例如,即便部分地获知(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么),仍想要获知(何时)。在该情况下,在(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么)中,按已知的语言模型来生成检索用的语言模型。使用该检索用的语言模型,在上面叙述的整理并配置了的语言模型中进行对照。如果根据对照在(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么)中存在符合的语言模型,则能够作为包括回答的候补而选出。在该候补中,在针对(何时)这样的项目而包括表现(何时)的语言模型的情况下,成为针对提问的回答。
不论提问是(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么)中的哪一个,都能够同样地得到回答。使用想要提问的项目以外的项目来生成检索用的语言模型,对模型记录器对照该检索用的语言模型,如果从针对对照而反应了的候补中选出在想要提问的项目中包括具体内容的语言模型,则能够得到针对提问的回答。
在这样在模型记录器中包括针对提问的回答的情况下,能够直接地得到回答。
[解决技术问题的技术手段](对应于技术方案4)
本发明中的思考模型生成机生成从所输入的多个模型导出的模型以及联想的模型。将所输入的多个模型设为“模型A”、“模型B1”、“模型B1”、··“模型BN”,将导出或者联想的模型设为“模型C1”、“模型C1”、··“模型CN”。设为在所输入的模型和导出或者联想的模型之间存在如下关系。
·“模型A”+“模型B1”→“模型C1”
·“模型A”+“模型B2”→“模型C2”
· ··
· ··
·“模型A”+“模型BN”→“模型CN”
这使用先前说明的模型控制器。
使“模型A”和“模型Bi”(i=1~N)激活,之后,使“模型Ci”激活。此时,通过模型控制器,从“模型A”、“模型Bi”向“模型Ci”(i=1~N)地生成结合。当生成该结合后,当“模型A”和“模型Bi”激活时,“模型Ci”激活。如上所述,通过变更所输入的模型的组合,能够输出与组合对应的模型。
[解决技术问题的技术手段](对应于技术方案5)
本发明中的模型记录器具备检测模型的模型检测部以及对无法检测的错误模型进行检测的错误模型检测部,从而在错误地检测到无法检测的信号的情况下,通过错误模型检测部检测出是错误模型,能够抑制错误的检测。
[解决技术问题的技术手段](对应于技术方案6)
本发明中的模型记录器具备多根输入线和多根输出线,针对每根线检测与输入信号的相关度,针对每根线输出检测结果,所以不会发生干扰,能够同时并行处理相关度检测。
具体实施方式
[发明的实施方式1](对应于技术方案1)
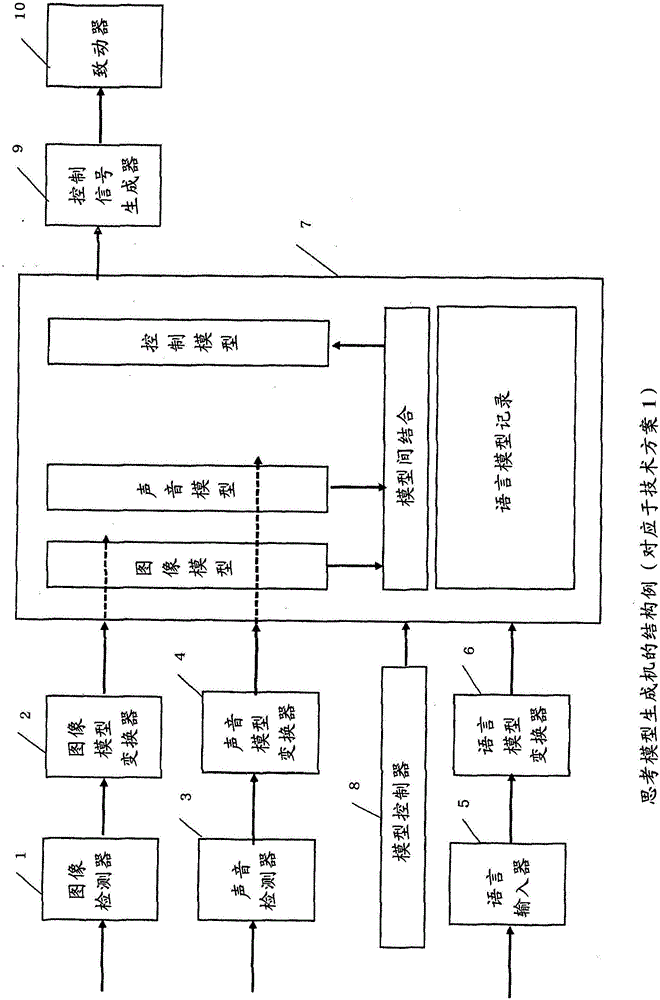
图1是示出本发明的一个实施例中的思考模型生成机的结构的图。
在图1中,1是检测图像信息的图像检测器。2是将图像检测器的输出变换为图像模型的图像模型变换器。3是检测声音信息的声音检测器。4是将声音检测器的输出变换为声音模型的声音模型变换器。5是输入语言的语言输入器。6是将语言输入器的输出变换为语言模型的语言模型变换器。7是记录图像模型、声音模型以及语言模型的模型记录器。8是实施模型的设定、变更以及模型与模型的结合关系的生成的模型控制器。9是将模型变换为控制信号的控制信号生成器。10是通过控制信号生成器的输出来驱动的致动器。
接下来,说明动作。
作为1的图像检测器生成与对象物对应的信号。将与该对象物对应的信号输入到作为2的图像模型变换器,生成图像模型。同样地作为3的声音检测器将与声音对应的信号输入到作为4的声音模型变换器,生成声音模型。作为5的语言输入器输入语言。语言是指词、单词以及语句。语言输入器将所输入的语句变换为按主语、谓语、修饰语等整理而成的型。作为6的语言模型变换器将作为5的语言输入器的输出变换为语言模型。图2、图3、图4示出图像模型、声音模型以及语言模型的例子。在此,将把图像、声音以及语言的信息分别变换为所识别的信号的组合而得到的结果称为模型。在此,用“ON”、“OFF”或者“1”、“0”来表现模型的要素。虽然也可以用其他表现,但根据相关处理的简便性,采用本表现。将所生成的模型记录于作为7的模型记录。作为8的模型控制器实施模型的设定、变更以及模型与模型的结合关系的生成。
图5示出模型记录器的结构。
说明模型与模型的结合关系的例子。将某个现象A表现为模型A,将其他现象B表现为模型B。在如果发生现象A则还发生现象B的情况下,对应的模型A和模型B存在关系。能够以当模型A激活后接着模型B激活的方式,通过模型控制器设定结合关系。
作为具体的动作例,作为图像信息,当输入《狗》时,生成狗的图像模型,在模型记录器中记录为狗的图像模型。另一方面,作为语言信息,将《いぬ》输入到作为5的语言输入器,变换为经整理的型。接下来,在作为6的语言模型变换中变换为语言模型,并记录到模型记录器。当通过作为8的模型控制器设定结合关系后,当狗的图像模型激活时,接着作为语言信息,表示《いぬ》的语言模型激活。如果这样使思考模型生成机看到狗的图像,并将作为语言信息是《いぬ》这一情形关联起来,则在下次看到狗时能够辨别出是《いぬ》。
图6示出模型记录器的动作例。
也能够同样地生成声音模型与语言模型的结合关系。
作为具体的动作例,通过声音发声为“あ”,输入到声音检测器。作为3的声音检测器根据声音的频率模型,生成与“あ”对应的声音信号,并输出到作为4的声音模型变换器。声音模型变换器将与“あ”对应的声音信号生成为声音模型。
接下来,向作为5的语言输入器输入《あ》,通过作为6的语言模型变换器变换为与《あ》对应的语言模型。当通过作为8的模型控制器设定结合关系后,当“あ”这样的声音模型激活时,接着作为语言信息,与《あ》对应的语言模型激活。
同样地,预先将“い”、“う”、“え”、“お”、“か”···“ん”这样的声音模型记录于作为7的模型记录器。
语言模型变换器进而根据词与词的组合将单词生成为语言模型,根据单词与单词的组合将语句生成为语言模型。将所生成的语言模型记录于作为7的模型记录器。
根据以上所述,能够根据声音模型,生成对应的语言模型。
此外,声音模型根据说话的人也有微妙的不同,所以如果针对各人分别记录声音模型,则还能够检测出谁在说话。
接下来,说明语言模型与语言模型的结合关系和动作。
在产生某个状况时,图像模型或者声音模型激活,对应的语言模型激活。此时,人观察该语言模型,将接下来想到的语言或者联想的语言输入到作为5的语言输入器,通过作为6的语言模型变换器,变换为语言模型。进而,通过作为8的模型控制器,设定语言模型与语言模型的关系。作为8的模型控制器当在激活的模型之后其他模型激活时,从先激活的模型向后激活的模型地生成结合关系。由此,当某个语言模型激活时,与其关联的语言模型被依次激活。还能够如在人意识到某个想法时接着想起关联的想法那样,使思考模型生成机也根据语言模型来激活语言模型。人意识到某个想法对应于思考模型生成机激活了语言模型。图7示出语言模型与语言模型的结合关系的动作例。
作为模型与模型的结合的例子,可以举出下述的例子。
·图像模型→在图像中识别出的对象的名称
·声音模型→在声音中识别出的词、单词、文章
·声音模型→发出声音的对象是谁?(是人还是动物?、谁?等)
·语言模型(某个现象)→语言模型(根据现象归结的现象)
(例子(科学的事实):使氧与氢反应。→生成水。)
·语言模型(某个现象)→语言模型(根据现象归结的行动)
(例子(习惯、习俗等):碰到○○君。→向○○君打招呼。)
·语言模型(某个现象)→语言模型(根据现象归结的行动指南)
(例子(规则等):红灯→停住。)
·语言模型(某个现象)→语言模型(根据现象联想的现象)
(例子(预想):出现了乌云。→要下雨吧。)
·语言模型(提问)→语言模型(针对提问的回答)
·语言模型(问题)→语言模型(想起问题的解决方法)
···等
所激活的模型还能够依次激活关联的模型,并且与记录于模型记录器的模型进行对照,得到想要检索的信息。
例如,在人让本思考模型生成机回答今天的推荐的娱乐是什么比较好的情况下,能够通过下述的步骤来进行。
1.以如下方式设定语言模型:当提问今天的推荐的娱乐时,如果是晴天则回答郊游比较好,如果是下雨则回答电影比较好。
2.当获得与今天的天气有关的信息后,记录到模型记录器。
3.当提问今天的推荐的娱乐时,从模型记录器检索与今天的天气有关的信息,根据该信息的内容来生成回答。
如上所述,通过按照人的思考模型,让思考模型生成机生成模型并进行动作,能够使机械实施与人相同的思考以及动作。
[发明的实施方式2](对应于技术方案2)
图8是示出本发明的一个实施例中的思考模型生成机的结构的图。
在图8中,1是检测图像信息的图像检测器。2是将图像检测器的输出变换为图像模型的图像模型变换器。3是检测声音信息的声音检测器。4是将声音检测器的输出变换为声音模型的声音模型变换器。5是输入语言的语言输入器。6是将语言输入器的输出变换为语言模型的语言模型变换器。7是记录图像模型、声音模型以及语言模型的模型记录器。8是实施模型的设定、变更以及模型与模型的结合关系的生成的模型控制器。9是将模型变换为控制信号的控制信号生成器。10是通过控制信号生成器的输出来驱动的致动器。11是分析所输入的信息的价值的信息分析器。
接下来,说明动作。
作为1的图像检测器生成与对象物对应的信号。将与该对象物对应的信号输入到作为2的图像模型变换器,生成图像模型。同样地作为3的声音检测器将与声音对应的信号输入到作为4的声音模型变换器,生成声音模型。作为5的语言输入器输入语言。作为6的语言模型变换器将作为5的语言输入器的输出变换为语言模型。将所生成的模型记录于作为7的模型记录。作为8的模型控制器实施模型的设定、变更以及模型与模型的结合关系的生成。
作为11的信息分析器分析所输入的信息的价值。在分析中,作为一个例子,实施①至⑤的项目。通过①至⑤的分析来分析所输入的信息,评价作为信息的价值。来自可靠的发送源的关注的领域的信息被判断为价值高,来自不可靠的发送源的不关注的领域的信息被判断为价值低。将价值高的信息作为语言模型记录到模型记录器,不记录价值低的记录。
由此,依次累积有用的信息,在模型记录器中构成庞大的知识。
①分析是从谁得到的信息。
②分析是与哪个领域有关的信息。
③分析是否为关注的领域的信息。
④分析与所记录的信息的关系(匹配、不匹配、新颖性、依据的妥当性)。
⑤分析信息的种类(真实、事实、推测、传闻、询问语句、命令语句、感叹语句等)。
说明①分析是从谁得到的信息。
信息分析器识别所输入的信息以及信息的发送源(书、电视机、人···等)是什么。这通过确认所输入的信息的传递路径来实施。在书中记载的图像信息能够识别为是来自书的信息。来自电视机的信息能够根据图像信息以及声音信息识别为是来自电视机的信息。关于来自人的信息,根据图像信息识别周围存在的人是谁,并且识别是来自谁的声音信息。
说明②分析是与哪个领域有关的信息。
在所输入的信息中,包括作为是与哪个领域有关的信息的线索的单词以及语句等。即使在最近的信息中不包括作为线索的单词以及语句等,只要暂且监视一会儿,就能够检测出作为线索的单词以及语句等。
将信息输入到模型变换器,将信息变换为语言模型。在人观察该信息而判断出是与哪个领域有关的信息时,将与领域有关的语言模型记录到模型记录器,设定从与输入信息对应的语言模型向表示领域的语言模型的结合关系。语言模型与语言模型的结合经过结合系数来实施。在判断为所输入的信息1与领域1对应的情况下,生成从与信息1对应的语言模型经过结合系数向与领域1对应的语言模型的结合。在与信息1对应的语言模型激活了时,针对领域1的结合以与结合系数成比例的强度而强化。关于领域1的语言模型是否激活,根据经过结合系数输入的结合的强度相对于事先设定的阈值的大小关系来决定。通过针对所输入的信息反复进行领域的识别,学习所输入的信息的领域分析。在针对所输入的信息的领域分析的结果错误了的情况下,以减弱针对输入模型的结合的方式,修正结合系数。
通过反复进行这样的学习,能够正确地实施所输入的信息的领域分析。图9示出针对是与哪个领域有关的信息进行分析的信息分析器的动作例。
说明③分析是否为关注的领域的信息。
这能够通过与在②中叙述的方法相同的方法来实现。通过分析在所输入的信息中是否包括关注的领域的单词以及语句等,识别所输入的信息是否为关注的领域的信息。
说明④分析所记录的信息的关系(新颖性、匹配、不匹配)。
针对所输入的信息实施上述领域分析,与记录于模型记录器的模型进行对照。当检测到关联的模型时,针对与所输入的信息的关系实施分析。记录于模型记录器的语言模型与语言模型之间,定义匹配、不匹配的关系。例如,在表示“上”的语言模型和表示“下”的语言模型之间,定义表示相反的意义的结合关系。另外,在表示“美丽”的语言模型和表示“漂亮”的语言模型之间定义表示类似的意义的结合关系。这样在语言模型与语言模型之间,设定识别相反的意义、类似的意义的结合关系。例如,设为在所输入的语言模型中包括表示“上”的语言模型。设为在模型记录器中检测出与所输入的信息关联的信息,在该关联信息的语言模型中包括表示“下”的语言模型。此时,所输入的语言模型将“上”这样的语言模型激活,关联信息的语言模型将“下”激活。语言模型“上”和“下”是表示相反的结合关系,所以能够辨别出在所输入的信息与所记录的关联信息之间存在不匹配。同样地,在激活了如“美丽”与“漂亮”的关系那样表示类似的语言模型的情况下,能够辨别出在所输入的信息与所记录的关联信息之间存在匹配。人在接触到新的信息时,通过想起并比较关联的信息,确认匹配以及不匹配。在思考模型生成机中也能够进行相同的动作。
图10示出与匹配/不匹配有关的信息分析器的动作例。
接下来,说明分析在所输入的信息中是否有新颖性的方法。
生成包括构成所输入的信息的语言模型的下位的语言模型(对于语句而言是单词)和等价的语言模型的语言模型。图11以及图12是示出同义词的分析例的图。该语言模型不对所输入的信息的新颖性造成影响,成为具有同一意义的语言模型的集合。
同样地,生成包括构成与所输入的信息关联的信息的语言模型的下位的语言模型和等价的语言模型的语言模型。该语言模型也不对所包括的信息量造成影响,成为具有同一意义的语言模型的集合。能够解释为该语言模型的集合在由单词构成的意义空间中,关于语言表示的意义占据最大限度的区域。图13示出由同义词构成的集合体的结构。
在关于在所输入的信息中是否有新颖性的判断中,在对所记录的关联信息表示的语言模型的集合和新信息表示的语言模型的集合进行比较时,当在关联信息表示的语言模型以外的部位存在新信息的语言模型时,能够判断为有新颖性。其原因为,这表示在所输入的信息中包括在关联信息中没有的信息。
图14示出与新颖性检测有关的信息分析器的动作例。
接下来,说明依据的妥当性。
在将所输入的信息变换为语言模型并记录时,尽可能将依据也变换为语言模型并记录。例如,在输入了“A是B。”这样的信息的情况下,关于“这是由于A是C”这样的依据,也设为语言模型来记录。通过反复进行与这样的依据有关的记录,组成构成依据的语言模型的集合。通过基于真实、事实或者常识来累积依据的记录,能够使表示依据的语言模型具有妥当性。在假设在所输入的信息与所记录的关联信息之间检测到不匹配时,比较其依据。
通过将所输入的信息以及关联信息的依据与构成在上述中所生成的依据的语言模型的集合进行对照,能够针对哪一个作为依据较为妥当进行比较。在与构成依据的语言模型进行了对照时,在未检测到所对照的对象的情况下,则在过去未说明该依据。即,在与构成依据的语言模型的集合进行对照时,对照越多,则依据的妥当性越高,对照越少,则依据的妥当性越低。
说明⑥分析信息的种类(陈述语句(真实、事实、推测、传闻)、疑问语句、命令语句、感叹语句等)的方法。
关于所输入的信息的语言模型,分析信息的种类。一般来说,在语言模型中,包括识别语句的种类(陈述语句、疑问语句、命令语句、感叹语句等)的模型。
陈述语句是“です”、“ます”、“である”、“だ”等
疑问语句是“ですか”、“ますか”、“だろうか”等
命令语句是“せよ”、“しろ”、“して下さい”等
感叹语句是“なんて··だろう”、“なんて··でしょう”等
推测是“だろう”、“でしょう”等
传闻是“らしい”等
通过检测这些模型,识别信息的种类。
通过除了语言模型以外还引入图像模型、声音模型的信息,实施真实以及事实的识别。在检测在图像模型中实际发生的现象并记录为语言模型的情况下,识别为事实。另外,在信息的源泉是可靠的人、书籍等的情况下,识别并记录为确信的信息。
通过以上的①至⑤的分析来分析所输入的信息,评价作为信息的价值。来自可靠的发送源的关注的领域的信息被判断为价值高,来自不可靠的发送源的不关注的领域的信息被判断为价值低。将价值高的信息作为语言模型记录到模型记录器,不记录价值低的记录。
由此,依次累积有用的信息,在模型记录器中构成庞大的知识。
图15示出有用的信息的检测以及记录的动作例。
[发明的实施方式3](对应于技术方案3)
图16是示出本发明的一个实施例中的思考模型生成机的结构的图。
在图16中,1是检测图像信息的图像检测器。2是将图像检测器的输出变换为图像模型的图像模型变换器。3是检测声音信息的声音检测器。4是将声音检测器的输出变换为声音模型的声音模型变换器。5是输入语言的语言输入器。6是将语言输入器的输出变换为语言模型的语言模型变换器。7是记录图像模型、声音模型以及语言模型的模型记录器。8是实施模型的设定、变更以及模型与模型的结合关系的生成的模型控制器。9是将模型变换为控制信号的控制信号生成器。10是通过控制信号生成器的输出来驱动的致动器。12是分析所输入的语句的单词的词类,识别语句的主语部分、谓语部分、主语、谓语、修饰语等,针对“何时”、“何地”、“谁”、“将什么”、“如何”、“为何”、“进行了吗”进行识别/整理的语句构成分析器。13是从记录于模型记录器的信息提取想要检索的信息的信息提取器。
接下来,说明动作。
本发明中的思考模型生成机分析所输入的语句的单词的词类,识别语句的主语部分、谓语部分、主语、谓语、修饰语等,针对“何时”、“何地”、“谁”、“将什么”、“如何”、“为何”、“进行了吗”进行识别/整理并记录。在希望从所记录的信息提取所需的信息的情况下,通过输入希望获知与什么有关的什么,输出所需的信息。
构成思考模型生成器的语句构成分析器分析所输入的信息的语言模型的单词的词类。各单词的词类是确定的,所以针对每个单词,将词类对应起来。接下来,语句构成分析器分析词类及其组合。例如,如下所述,能够识别主语、谓语、修饰语等。
→(情形1:“他动词”的主语是“名词2”)
“名词1”+“助词(を)”+“他动词”是“名词2”的修饰语
→(情形2:“他动词”的主语是“名词3”)
“名词1”+“助词(を)”+“他动词”是“名词3”的修饰语
·“名词(日期时间)”→意味着(何时)
·“名词(场所)”+“助词(で)”→意味着(何地)
·“语句(···する方向で)”→意味着(如何)
·“语句(···だからである)”→意味着(为何)
等
进而,语句构成分析器将识别出的主语、谓语、修饰语配置于分别对应的位置来生成语言模型。通过这样配置,(何时)、(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么)变得明确。
图17示出按照主语、谓语、修饰语整理并配置了的语言模型的一个例子。
如果使用这样整理并配置了的语言模型,则容易针对各种提问生成回答。具体而言,作为检索用的语言模型,使用下述语言模型。
在作为13的信息提取器中生成接下来的检索用的语言模型。
检索用的语言模型:
(何时)+(何地)+(谁)+(将什么)+(如何)+(为何)+(做了什么)
例如,即便部分地获知(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么),仍想要获知(何时)。在该情况下,在(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么)中,按已知的语言模型来生成检索用的语言模型。使用该检索用的语言模型,在上面叙述的整理并配置了的语言模型中进行对照。如果根据对照在(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么)中存在符合的语言模型,则能够作为包括回答的候补而选出。在该候补中,在针对(何时)这样的项目而包括表现(何时)的语言模型的情况下,成为针对提问的回答。
不论提问是(何地)、(谁)、(将什么)、(如何)、(为何)、(做了什么)中的哪一个,都能够同样地得到回答。在信息提取器中使用想要提问的项目以外的项目来生成检索用的语言模型,对模型记录器对照该检索用的语言模型,如果从针对对照而反应了的候补中选出在想要提问的项目中包括具体内容的语言模型时,能够得到针对提问的回答。
在这样在模型记录器中包括针对提问的回答的情况下,能够直接地提取回答。
[发明的实施方式4](对应于技术方案4)
图18是示出本发明的一个实施例中的思考模型生成机的结构的图。
在图18中,1是检测图像信息的图像检测器。2是将图像检测器的输出变换为图像模型的图像模型变换器。3是检测声音信息的声音检测器。4是将声音检测器的输出变换为声音模型的声音模型变换器。5是输入语言的语言输入器。6是将语言输入器的输出变换为语言模型的语言模型变换器。7是记录语言模型的模型记录器。8是实施模型的设定、变更以及模型与模型的结合关系的生成的模型控制器。
9是将模型变换为控制信号的控制信号生成器。10是通过控制信号生成器的输出来驱动的致动器。11是分析所输入的信息的价值的信息分析器。
本发明中的思考模型生成机生成从所输入的多个模型导出的模型以及联想的模型。将所输入的多个模型设为“模型A”、“模型B1”、“模型B1”、··、“模型BN”,将导出或者联想的模型设为“模型C1”、“模型C1”、··、“模型CN”。设为在所输入的模型和导出或者联想的模型之间存在如下关系。
·“模型A”+“模型B1”→“模型C1”
·“模型A”+“模型B2”→“模型C2”
···
·“模型A”+“模型Bi”→“模型Ci”
···
·“模型A”+“模型BN”→“模型CN”
这使用先前说明的作为8的模型控制器。
使“模型A”和“模型Bi”(i=1~N)激活,之后,使“模型Ci”激活。此时,通过模型控制器,从“模型A”、“模型Bi”向“模型Ci”(i=1~N)地生成结合。当生成该结合后,当“模型A”和“模型Bi”激活时,“模型Ci”激活。如上所述,通过变更所输入的模型的组合,能够输出与组合对应的模型。图19示出与模型对应的模型的输出例。
[发明的实施方式5](对应于技术方案5)
图20是示出本发明的一个实施例中的避免错误识别的模型记录器的结构例的图。在图20中,14是模型。15是检测模型的活性侧模型检测部。16是活性侧阈值。17是在由检测部生成的信号超过阈值的情况下表示记录模块的活化的模块活性部。18是生成模块之间的结合的活性侧模块间结合部。19是保存使模块活化了的模型的活性侧模型保存部。
20是对误检测出的模型进行检测的抑制侧模型检测部。21是抑制侧阈值。22是抑制由于误检测导致的错误的记录模块的活化的误检测抑制部。23是生成模块之间的结合的抑制侧模块间结合部。24是保存活性侧模型检测部错误地活化了的错误模型的抑制侧模型保存部。
接下来,说明动作。
在通过作为15的活性侧模型检测部检测作为14的模型的情况下,以使与作为14的信号模型的相关度超过活性侧阈值的方式,自动地设定活性侧模型检测部的结合系数。当在设定结合系数之后输入了该模型的情况下,示出活性侧模型检测部的信号超过活性侧阈值,作为17的模块活性部激活,本模块活化。
假设为由于无法使本模块活化的输入模型,活性侧模型检测的信号超过活性侧阈值。在该情况下实现检测,所以通过控制信号通知是误检测。此时,以使与输入模型的相关度超过抑制侧阈值的方式,自动地设定抑制侧模型检测部的结合系数。由此,作为22的误检测抑制部进行动作,能够避免误检测。在活性侧模型保存部和抑制侧模型保存部中,分别记录在本模块中检测出的模型以及通过活性侧模型检测部错误地检测出的模型。在变更活性侧检测部的结合系数以及抑制侧检测部的结合系数时、在确认到过去实施的检测或者抑制被维持时,使用所保存的模型。
[发明的实施方式6](对应于技术方案6)
图21是示出本发明的一个实施例中的对于多个输入不发生干扰的模型记录器的结构例的图。在图21中,25是输入模型A。26是输入模型B。27是向模型记录器的输入线。28是模型记录器的输出线。
在本图中,在实施例中,将线设为2根,但根据需要也会设置多根。
针对每根输入线,计算模型检测部中的相关度。将模型A传输到某根输入线,通过模型检测部实施相关度计算。将模型B也传输到其他输入线,通过模型检测部,与上述独立地实施相关度计算。因此,根据传输到输入线的模型,在同一模块中,激活的情况和未激活的情况混合存在。在发生了模块的激活的情况下,模块的模型被输出到输出线。
这样,能够针对多个输入,不发生干扰地实施相关度计算,并且也能够不发生干扰地输出所激活的模块的信息。
[发明效果1](对应于技术方案1)
根据第1发明,在使机械进行动作的情况下,人无需在搭载于机械的计算机中依次设定程序。
通过将图像信息、声音信息及语言变换为对应的模型的模型变换器、记录模型的模型记录器、实施模型的设定、变更以及模型与模型的结合关系的生成的模型控制器以及将模型变换为控制信号的控制信号生成器,能够将人的思考作为模型来依次学习,按照所学习的那样执行与状况对应的动作。
[发明效果2](对应于技术方案2)
根据第2发明,在对机械记录信息的情况下,人无需实施依次判断信息的价值并将判断为有用的信息依次输入并记录于机械等的作业。
通过将图像信息、声音信息及语言变换为对应的模型的模型变换器、记录模型的模型记录器、实施模型的设定、变更以及模型与模型的结合关系的生成的模型控制器以及分析所输入的信息的价值的信息分析器,能够自主地记录判断为有用的信息。
[发明效果3](对应于技术方案3)
根据第3发明,在从在计算机等中记录有的信息查找所需的信息的情况下,人无需将关键字等输入到计算机并检索关联的数据而搜索所需的信息。
通过针对“何时”、“何地”、“谁”、“将什么”、“如何”、“为何”、“进行了吗”进行识别/整理的语句构成分析器、记录由语句构成分析器整理了的语句的模型记录器以及从记录于模型记录器的信息提取想要检索的信息的信息提取器,能够针对提问由机械生成直接的回答。
[发明效果4](对应于技术方案4)
根据第4发明,在使机械输出从所输入的多个条件导出或者联想的结果的情况下,人无需在搭载于机械的计算机中依次设定为程序。
通过记录所输入的模型的模型记录器以及生成从所输入的多个模型导出或者联想的模型的模型控制器,改变所输入的模型的组合,从而能够使机械输出与组合对应的模型。
[发明效果5](对应于技术方案5)
根据第5发明,在进行模型识别中的模型学习时,主动地抑制被设想为伴随学习推进而增加的错误辨别,所以能够正确地实施模型识别。
[发明效果6](对应于技术方案6)
根据第6发明,即使输入多个输入模型也不会发生干扰,所以能够并行地实施模型处理。能够针对某根输入线设定某个模型,针对其他线依次设定其他模型,使模型的转变独立地进行动作。在通常的计算机等中,难以进行并行处理,但根据本发明,能够进行并行处理。
附图说明
图1是思考模型生成机的结构例(对应于技术方案1)。
图2是图像模型变换器的结构例。
图3是声音模型变换器的结构例。
图4是语言模型变换器的结构例。
图5是模型记录器的结构例。
图6是模型记录器的动作例。
图7是语言模型与语言模型的结合关系的动作例。
图8是思考模型生成机的结构例(对应于技术方案2)。
图9是信息分析器的动作例(分析是与哪个领域有关的信息)。
图10是信息分析器的动作例(匹配/不匹配的分析)。
图11是信息分析器的动作例(同义词的分析)(1/2)。
图12是信息分析器的动作例(同义词的分析)(2/2)。
图13是信息分析器的动作例(同义词的集合体的结构)。
图14是信息分析器的动作例(新颖性的检测)。
图15是有用的信息的检测以及记录的动作例。
图16是思考模型生成机的结构例(对应于技术方案3)。
图17是语句构成器输出的语言模型例。
图18是思考模型生成机(对应于技术方案4)。
图19是与组合对应的模型的输出例。
图20是避免错误识别的模型记录器的结构例。
图21是对于多个输入不发生干扰的记录器的结构例。
(符号说明)
1:图像检测器;2:图像模型变换器;3:声音检测器;4:声音模型变换器;5:语言输入器;6:语言模型变换器;7:模型记录器;8:模型控制器;9:控制信号生成器;10:致动器;11:信息分析器;12:语句构成分析器;13:信息提取器;14:模型;15:活性侧检测部;16:活性侧阈值;17:模块活性部;18:活性侧模块间结合部;19:活性侧模型保存部;20:抑制侧模型检测部;21:抑制侧阈值;22:误检测抑制部;23:抑制侧模块间结合部;24:抑制侧模型保存部;25:模型A;26:模型B;27:输入线;28:输出线。
- 还没有人留言评论。精彩留言会获得点赞!