一种通用文本挖掘方法和系统与流程
本发明属于文字检索
技术领域:
,具体地,本发明属于文本挖掘和自然语言处理
技术领域:
。本发明涉及一种通用的文本挖掘方法,可以为不同领域的文本挖掘需求中的挖掘目标、挖掘范围、分析算法以及分析结果过滤规则提供形式化的描述手段。
背景技术:
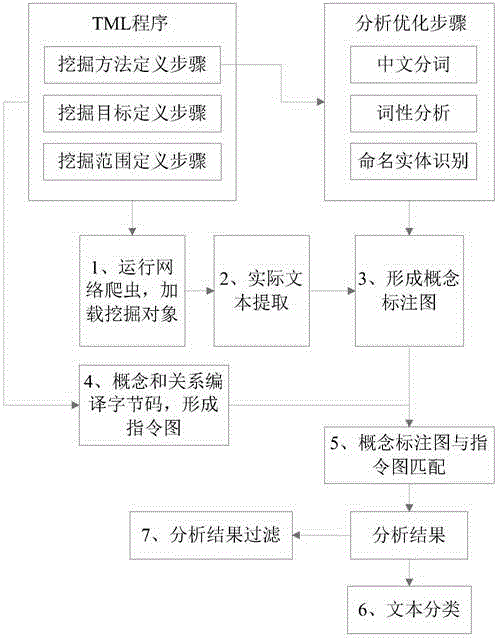
:上世纪九十年代以来,信息抽取在学术界和工业界得到持续关注,有大量的相关研究工作。随着互联网信息数量的快速增长,对非结构化文本的挖掘已成为研究热点。文本挖掘在舆情监控、情报分析、商务智能等诸多领域得到越来越广泛的应用。现有抽取技术一般应用于具体的领域,即在预先设计的特定领域中使用,例如与网页信息的大量抽取相关的,尤其是与其中Wrapper生成相关的工作仅针对利用网页的结构抽取有用的信息。另一些情况例如DBLife系统,则使用Datalog语言让用户定制抽取目标,并提高抽取效率,但这种方法只能在文献分析领域中使用。本发明的发明人意识到,在现有的信息抽取技术手段中,并没有一种能够在多个领域中使用的通用办法,无法为使用者在实际应用的情况下提供多个领域的信息抽取技术支持。而且,现有的信息抽取手段存在技术缺陷,也无法达到通用文本挖掘的效果。一方面,现有抽取技术使用关键词布尔逻辑来描述匹配目标,这限制了对目标的刻画能力。另一方面,这些技术手段不具备通用性,换一个行业或场景后往往就需要重新实现。技术实现要素:本发明的一个目的是提供一种通用的文本挖掘方法。本发明人认为, 可以基于规则的抽取技术,开发与应用无关的规则语言以达到领域的通用性,让使用者采取声明式抽取的方式,在不同领域内定制抽取目标。为满足这类需求,通用性文本挖掘系统要解决以下3个方面的主要问题:1)如何提供一种形式化方法来刻画文本挖掘模式;2)如何满足挖掘目标包含复杂语义结构的需求;3)如何解决大规模语义抽取的效率问题。本发明方法提出了一种形式化定义手段,能够对文本挖掘的挖掘目标、挖掘范围和分析算法进行描述;并且采用分层式的方法给出分析结果,进一步还提供对分析结果的过滤规则。另一方面,本发明还提供了一种可以实现上述文本挖掘方法的系统。本发明提供的通用文本挖掘方法包括:步骤1,运行网络爬虫,加载挖掘范围内的挖掘对象;步骤2,对所述挖掘对象进行实际文本提取,得到实际文本;步骤3,将所述实际文本形成概念标注图;步骤4,根据与挖掘目标对应的所述概念和概念之间的关系,将所述概念和关系编译形成字节码,进而形成指令图;步骤5,将所述概念标注图和所述指令图进行匹配,将所述概念标注图中符合指令图的概念和关系的内容形成分析结果。在步骤3之后,可以包括用于优化所述概念标注图的分析优化步骤,所述分析优化步骤中的挖掘方法包括分词、词性分析、命名实体识别。在所述分析优化步骤之前,还可以包括用于选定所述挖掘方法的挖掘方法定义步骤。在所述步骤4之前,还可以包括定义与所述挖掘目标对应的所述概念以及定义所述概念之间的所述关系的挖掘目标定义步骤,所述挖掘目标是所述概念和关系的具体值。在所述步骤1之前可以包括定义所述挖掘范围的挖掘范围定义步骤。在所述步骤5之后,还可以包括根据概念和关系的匹配结果,对所述文本进行分类的步骤。所述概念间的所述关系包括:“SENT”:作用域内的所有概念必须出现在一条语句中;“DIST_n”:作用域内的任何两个相邻概念之间的距离不能大于n;“ORD”:作用域内的所有概念顺序出现;“CONT”:作用域内的所有概念相邻。本发明所述的方法还包括步骤6,对所述所述实际文本进行主题分类,另外还可以包括步骤7,对所述分析结果进行结果过滤,根据所述实际文本中匹配到的概念和关系的出现频率对所述分析结果进行限定。本发明提供的通用文本挖掘系统包括:加载模块,用于使用网络爬虫加载挖掘范围内的挖掘对象文本;文本提取模块,用于提取所述挖掘对象中的实际文本;标注图生成模块,用于将所述实际文本形成概念标注图;编译模块,用于根据与挖掘目标对应的所述概念之间的关系,将所述概念和关系编译形成字节码,进而形成指令图;匹配模块,将所述概念标注图和所述指令图进行匹配,将所述概念标注图中符合指令图的概念和关系的内容形成分析结果。所述系统可以包括分析优化模块,用于优化所述概念标注图。所述系统还可以包括挖掘方法定义模块,用于选定所述分析优化模块中使用的挖掘方法。进一步的,所述系统还可以包括用于存储所述挖掘方法的方法模型库,所述挖掘方法定义模块从所述方法模型库中选定挖掘方法。所述方法模型库的挖掘方法包括:分词模块、词性分析模块、命名实体识别模块等。所述系统还可以包括挖掘目标定义模块,用于定义与所述挖掘目标对应的所述概念,并定义所述概念之间的所述关系,所述挖掘目标作为所述概念的具体值。所述概念之间的所述关系可以包括:“SENT”:作用域内的所有概念必须出现在一条语句中;“DIST_n”:作用域内的任何两个相邻概念之间的距离不能大于n;“ORD”:作用域内的所有概念顺序出现;“CONT”:作用域内的所有概念相邻。本发明所述系统还可以包括挖掘范围定义模块,用于定义所述挖掘范 围。本发明的系统还包括文本分类模块,用于根据在所述文本中概念和关系的匹配结果以及文本涉及的领域,对实际文本进行主题分类。另外,本发明的系统还包括结果过滤模块,用于根据所述文本中匹配到的所述概念和关系的出现频率对所述分析结果进行限定。本发明提出了一种能够对文本挖掘中的挖掘目标、范围和挖掘方法进行形式化描述并获得挖掘结果的通用文本挖掘方法。本发明用一个对应的上下文有关语言来同时支持对任意概念和关系的抽取,同时提供了对挖掘范围和相关挖掘方法的定制手段。用户只需要使用本发明的规则定义概念和概念之间的关系,将具体的搜索目标赋值个所述概念,就能实现对其文本挖掘需求的描述,并进一步得到文本挖掘的分析结果。根据本发明所述的挖掘方法,使用者可以对所需的概念进行定义和赋值,并对概念之间的关系进行定义,然后选定挖掘范围和挖掘方法。本发明提供的方法能够利用挖掘方法对检索范围内的文本进行标注,生成概念标注图。另一方面,本发明能够将使用者定义的概念和关系编译成字节码,生成指令图。进一步的,本发明将概念标注图和指令图进行匹配,从而分析出挖掘范围内符合使用者定义的概念和关系的文本内容,形成分析结果。本发明的发明人发现,在本领域技术中,并没有技术人员试图提供一种类似的通用文本挖掘方法或模板,本领域技术人员还未意识到真正意义上的通用文本挖掘方法的重要性。因此,本发明所要实现的技术任务或者所要解决的技术问题是本领域技术人员从未想到的或者没有预期到的,故本发明是一种新的技术方案。通过以下参照附图对本发明的示例性实施例的详细描述,本发明的其它特征及其优点将会变得清楚。附图说明被结合在说明书中并构成说明书的一部分的附图示出了本发明的实施例,并且连同其说明一起用于解释本发明的原理。图1是本发明的通用文本挖掘方法的步骤图;图2是本发明具体实施方式中通用文本挖掘方法的步骤图;图3是本发明所述方法对应的TML语言的精简语法;图4是本发明具体实施例中的概念标注图示例;图5是本发明具体实施例中TML语言程序的关系定义语句示例;图6是本发明具体实施例中TML语言程序的关系语句的字节码示例;图7是本发明提供的具体实施例中通用文本挖掘系统的结构框图;图8是本发明具体实施例中TML语言程序的概念与关系层次图。具体实施方式现在将参照附图来详细描述本发明的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本发明的范围。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。在这里示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。本发明提供了一通用文本挖掘方法,图1是本发明所述方法的步骤框架图,本发明的文本挖掘方法实现了网络爬虫、实际文本提取、文本标注图生成、分词、词性标注、命名实体识别和文本分类等技术,并将它们形成一个流水线分析。如图1所示,其中包括以下步骤:1、运行网络爬虫,加载挖掘范围内的挖掘对象;2、对所述挖掘对象提取实际文本;3、将所述实际文本形成概念标注图;4、将所述概念和关系编译成字节码、形成指令图;5、将所述概念标注图和指令图进行匹配,得到分析结果。在本发明的所述的方法中,所述挖掘发内可以是任何文本的载体,例如网页、书籍、 文件等形式的载体。在本发明提供的文本挖掘方法中,可以以TML语言为基础,如图3所示,通过正则表达式定义语句、概念定义语句、赋值语句、关系定义语句、挖掘范围定义语句、分析算法定义语句,以及输出语句、加载语句等语句编写程序,实现本发明所述的挖掘方法。图3示出的是本发明提供的与所述通用文本挖掘方法相对应的TML程序框架,本方法的使用者可以通过这套程序框架对任何领域、任何客观的挖掘范围进行文本挖掘分析。所述正则表达式用于对概念以及相对具体值的格式进行定义。在步骤1中,所述文本挖掘方法首先运行网络爬虫,加载选定的挖掘范围内的挖掘对象。在所述步骤1之前,如图2所示,可以先执行挖掘范围定义步骤。通过如图3第17-19行所示的挖掘范围定义语句定义、选定所述挖掘范围。所述挖掘范围定义语句包括保留字“PAGES”、变量名<string>和挖掘范围属性列表<pagerestricts>形成的复合语句组成。第18行的挖掘范围属性列表可以包括多个挖掘范围属性<pagerestrict>。在第19行中,挖掘范围属性由属性和属性值组成,属性定义如表1所示。表1挖掘范围属性定义在步骤2中,由于所述挖掘范围有多种形式,所述其中的挖掘对象也可能包括了无意义的对象,例如网页中的格式字符、书籍中的格式字符等。所以,所述流水线分析中可以包括实际文本提取步骤。所述实际文本提取步骤用于去除挖掘对象中对挖掘检索无意义的部分,得到真正需要进行挖 掘分析的实际文本。在所述步骤3中,本发明将所述实际文本生成概念标注图。在所述概念标注图中,在符合挖掘目标的字句上,即符合概念的具体值的字句上,标注有与之相应的所述概念。在具体实施例中,所述概念标注图如图4所示。在步骤3及其之后的步骤中,本发明所述方法可以对概念标注图进行优化。特别的,由于可能包括多种挖掘方法,所以本发明中将分析过程形成了程序化的标注图分析优化步骤。如图2所示,例如,所述分析优化步骤可以依次执行中文分词步骤、词性标注步骤和命名实体抽取步骤。所述中文分词步骤是针对挖掘范围内的中文文本,将一个汉字序列切分成一个一个单独的词。所述词性标注步骤是对实际文本中的词性进行标注,例如形容词、名词、动词等,用来描述一个词在上下文中的作用。所述命名实体抽取步骤识别文本中具有特定意义的实体,,主要包括人名、地名、机构名等实体名称。如图2所示,在本发明的特定实施例中,所述标注图优化步骤可以依次包括多项分析步骤和方法,本领域技术人员可以根据实际使用的需要,选择/取舍不同的挖掘方法。在所述分析优化步骤之前,还可以包括用于选定所述挖掘方法的挖掘方法定义步骤。可以通过如图3第20-23行所述的挖掘方法定义语句来装载、选定现有的挖掘方法和方法模型库,包括事先定义好的分词步骤、词性标注步骤、分类步骤等,以执行挖掘方法定义步骤。如图3第20行所示,所述挖掘方法定义语句包括保留字“USE”、工具名和工具所在的路径。特别的,在所述步骤4之前,如图2所示,还可以包括定义所述概念和关系的挖掘目标定义步骤。在本发明中,可通过如图3第4-7行所示的概念定义语句、关系定义语句和赋值语句对所述概念和关系进行定义。赋值语句可以是:<assignstatement>::=<string>“:=”<string>“;”|<string>“:=”“OR”“(”<stmtargs>“)”“;”其中将“:=”符号的右值<string>赋给左值<string>,还可以用“OR”操作符为一个概念定义多个并列值。概念定义语句可以是:<conceptstatement>::=“CONCEPT”<stmtvars>“;”|“CONCEPT”<string>“(”<stmtarg>“)”“{”<stmtlimits>“}”其中包括保留字“CONCEPT”和语句变量列表<stmtvars>,所述概念可以在定义的同时赋值。特别的,所述挖掘目标是所述概念的具体值,使用所述赋值语句或在定义概念的同时,可以将所述挖掘目标赋值给所述概念。关系定义语句可以是:<predicatestatement>::=“PREDICATE”<string>“(”<stmtargs>“)”“{”<stmtlimits>“}”其中包括保留字“PREDICATE”、语句参数列表<stmtargs>和表示概念间的约束关系复合语句<stmtlimits>。其中概念间的约束关系计算符分为两类,即布尔计算符和上下文计算符,计算符定义分别如表2和表3所示。所述概念之间的所述关系可以包括多种类型,在本发明中可以通过上下文计算符和布尔计算符表示,例如:“SENT”:作用域内的所有概念必须出现在一条语句中;“DIST_n”:作用域内的任何两个相邻概念之间的距离不能大于n;“ORD”:作用域内的所有概念顺序出现;“CONT”:作用域内的所有概念相邻;作用域指计算符后括号内的内容。操作符定义ANDAND作用域中的所有字句必须同时在输入文本中出现OROR作用域中的所有字句至少有有一个在输入文本中出现NOTNOT作用域中的字句不能出现,否则输入文本不匹配表2布尔关系计算符定义表3上下文操作符定义如图2所述,所述挖掘目标定义步骤可以在TML程序中实现。另外,还可以对TML程序进行优化,将复杂的、存在逻辑矛盾的关系进行调整,形成正确无误的逻辑关系。在所述步骤4中,本发明根据与所述挖掘目标对应的所述概念之间的关系,将所述概念和关系编译形成字节码,进而形成指令图。所述步骤4的过程在具体实施例中如图5所示,图5中将department和title两个概念出现在同一句话中定义为关系position,然后用position等关系和概念定义概念manager,其中关系position编译后生成的字节码如图6所示,即针对SENT操作符添加了START_SENT,START_MATCH,END_MATCH,END_SENT等运行虚拟机指令。在执行字节码时,运行虚拟机针对这些指令执行对应的匹配逻辑。采取类似方法,可以将所有的所述概念和关系转化为字节码。将所述概念和关系转化为字节码后,可以根据字节码中的目标依赖关系生成指令图。所述步骤5将所述概念标注图和所述指令图进行匹配,将所述概念标注图中符合指令图的概念和关系的内容形成分析结果。在指令图与标注图的匹配过程中,需要记录每一步的相关信息,为了保证匹配规则执行的效率和正确性,本发明还可以解决下列问题:(1)规则的并发执行问题对于没有依赖关系的概念和关系,在匹配可以并发执行,例如SENT(person,“接受采访”)和SENT(person,“接见记者”)这两行语句只有“受采访”和“见记者”不同,因此“SENT(person,“接”这部分可以并发匹配,只是要解决指令图中的相关顶点被若干字节码片段共享所带来的问题。(2)匹配概念与概念之间的依赖问题程序中的多个概念彼此之间可能具有复杂的依赖关系,要在编译阶 段,即执行步骤4时计算好它们的先后顺序。例如图5中必须先匹配“title”和“department”才能匹配“position”。(3)上下文关系的匹配问题对于简单布尔逻辑关系计算符AND,OR和NOT,可以直接将概念标注图与指令图本身进行高效率匹配后再执行逻辑关系;但对于SENT和DIST_n等上下文关系,除了匹配文本自身外,本发明还要将匹配文本的上下文逻辑关系(4)所述关系的嵌套问题规则的所述关系经常相互嵌套,例如DIST_3(SENT(OR(“inc”,“corp”),OR(“acquire”,“buy”))))描述了一个简单的“公司收购”关系,对它的字节码的执行以及指令图和概念标注图的匹配过程中,需要考虑到DIST_n操作符里面嵌套的SENT和OR,在执行过程中需要解决这种嵌套问题。在所述步骤5之后,还可以包括步骤6,文本分类步骤,可以在挖掘方法的程序中指定对文本的分类属性,以执行步骤6。如图3第21行所示的分类方法语句中包括保留字“CLASS”、变量名和分类属性列表,而分类属性列表可以由多个分类属性组成,也可以为空。第23行示出了分类属性用来指定方法模型库、方法步骤等,其中各项的语义如表4所示。表4抽取手段属性定义特别的,在所述步骤5之后,还包括步骤7,对所述分析结果进行结果过滤,根据所述实际文本匹配到的所述概念和关系的出现频率对所述分析结果进行限定。在本发明中,可以根据图3第24-29行所示的结果过滤语句对步骤7的过滤方法进行定义。第24-29行的结果过滤语句来根据文档的类别和概念及其关系的出现频率对文本挖掘的分析结果做更进一步的限定。如第24行所示,所述结果过滤语句包含保留字“SELECT”,以及可选的“FROM”分句和“WHERE”分句。选择对象<selectobjects>可以为由”,”分隔的若干概念,如第25行所示。选择源<selectsources>可以由多个表示分析源的字符串组成,例如网页或者分类结果,如第26行所示。选择条件列表<selecetconditions>行由若干个选择条件组成,如第27行所示。选择条件<selecetcondition>由比较运算符链接的选择分句组成,如第28行所示,比较运算符如表5所示。选择分句<selectconditionclause>可以为以概念名作为参数的“FREQ”操作,如第29行所示。得到分析结果后,可以根据上述操作,执行分析结果过滤步骤。表5比较运算符定义表本发明所述方法将经过处理后的实际文本形成概念标注图,它与由TML语言所写的概念和关系编译而成的字节码流相匹配,输出注释结果。另一方面,本发明提供了一种通用文本挖掘系统,能够实现上述通用文本挖掘方法。如图7所示,所述系统包括:加载模块100,用于使用网络爬虫加载挖掘范围内的挖掘对象;实际文本提取模块200,用于提取挖掘范围内的实际文本;标注图生成模块300,用于将所述实际文本形成概念标注图;标注图优化模块400,用于根据挖掘方法定义模块710和方法模型库720,对标注图生成模块300生成的标注图进行优化,所述标注图优化模块400使用所述方法模型库720中的挖掘方法进行优化,所述方法模型库720中可以包括分词模块410,词性标注模块420和命名实体识别模块430。编译模块500,用于根据所述概念和概念之间的关系,将所述概念和关系编译形成字节码,进而形成指令图;匹配模块600,将所述概念标注图和所述指令图进行匹配,将所述概念标注图中符合指令图的概念和关系的内容形成分析结果。所述系统还包括定义模块700,所述定义模块700中包括:挖掘方法定义模块710,用于从所述方法模型库720中选定所述优化分析模块中使用的挖掘方法;相应的,所述系统还包括用于存储挖掘方法的方法模型库720,所述挖掘方法定义模块710从所述方法模型库720中选定挖掘方法。所述方法库720的挖掘方法可以包括词性标注方法、命名实体抽取方法、文本分类方法以及关键词抽取方法等。所述定义模块700还可以包括挖掘范围定义模块730,用于定义所述挖掘范围。所述定义模块700还可以包括挖掘目标定义模块740,用于定义与所述挖掘目标对应的所述概念,并定义所述概念之间的所述关系,所述挖掘目标作为所述概念的具体值。优选的,所述系统中使用的概念间的所述关系包括:“SENT”:作用域内的所有概念必须出现在一条语句中;“DIST_n”:作用域内的任何两个相邻概念之间的距离不能大于n;“ORD”:作用域内的所有概念顺序出现;“CONT”:作用域内的所有概念相邻。优选的,所述系统还可以包括文本分类模块900和结果过滤模块800。所述文本分类模块900用于对实际文本进行主题分类,所述结果过滤模块800用于根据所述概念标注图中所述概念和关系的出现频率对所述分析结果进行限定。上述两个模块的以分别独立的对挖掘结果进行处理,也可以依次进行处理,本发明不限制文本分类与结果过滤的先后顺序。在本发明的一个实施例中,以下以所述方法对应的TML语言解决从指定的种子节点中找到知名企业市场部门负责人的方法。首先,本发明定义挖掘目标,挖掘目标中需要包含知名企业、市场部门、负责人等概念,以及由这些概念形成的关系,例如市场部门负责人和知名企业市场部门负责人等。对应TML语言的程序片段如下:其中所述概念和所述关系之间的层次关系如附图8所示。其次,本发明所述方法在该实施例中要定义挖掘范围。挖掘范围中制定抓取的种子节点为http://finance.sina.com.cn和http://it.sohu.com,抓取深度为3。对应TML语言的程序片段如下:第三,本发明的方法在本实施例中需定义挖掘方法,至少加载一个中文分词器。假设分词器名为chn_tkzo_mini.bin,在当前路径下。对应TML语言的程序片段如下:USE(tokenizer:"./chn_tkzo_mini.bin");第四,本发明的方法在本实施例中可以定义结果过滤规则。过滤规则为从至少包含一个人名实体的待分析文档中找到匹配comppos关系。对应TML语言的程序片段如下:SELECTcompposFROMsample1WHEREFREQ(PERSON)>0;本实施例完整的程序如下:USE(tokenizer:"./chn_tkzo_mini.bin");1.CONCEPTbrand,company;2.brand:="IBM";3.brand:="通用汽车";…4.company:="中国石油化工集团公司";5.company:="国家电网公司";….6.CONCEPTdepartment,title;7.department:=OR("市场","品牌","营销","公关");8.title:=OR("经理","高级经理","总监","专员","部门负责人");9.PREDICATEmanager(departmentd,titlet){CONT(d,t);}10.PREDICATEcomppos(managerper,companycomp){11.OR(SENT(per,comp),DIST_15(per,comp));}12.PREDICATEcomppos(managerper,brandprod){13.OR(SENT(per,prod),DIST_15(per,prod));}14.PAGESsample1{15.SEED("http://finance.sina.com.cn");16.SEED("http://it.sohu.com");17.DEPTH(“3”);18.}19.SELECTcompposFROMsample1WHEREFREQ(PERSON)>0;在本发明的另一个实施例中,本文以购买意愿分析为例来说明本发明所述方法和系统的使用。从用户言论中挖掘潜在购买意愿的基本途径是,从社交网络下载用户言论之后,用所述TML程序编写制定该领域常见的购买模式,此外还编写了汽车、房地产、旅游、保险、化妆品等行业的知识库,包括产品、产品属性、功效、品牌、公司等,然后用它们定义不同行业下的特定购买意愿模式。以下是与化妆品行业相关的一些程序片段:1.COSMETIC-PRODUCT:=OR("肌底液","双眼皮胶","洗涤用品","化妆品收纳",……,"身体防晒");2.ATTRIBUTE(COSMETIC-PRODUCT,classname):="化妆品";3.CONCEPTCOSMETIC-ASPECTS:=OR("保湿","滋润","补水","美白","深层清洁",……);…#预算相关4.CONCEPTBUDGET:=OR("预算","付得起","买的起","买得起","刚够","钱不够",……);5.PREDICATEcosmetics-intending(BUDGETbd,COSMETIC-PRODUCTproduct){AND(SENT(DIST_5(bd,product),NOT(NOT-PUR-DIST)),NOT(AD));}表6给出购买意愿分析的TML程序的情况,其中平均匹配速度为虚拟机下载文档和执行程序的速度,在典型的单CPU/2GB内存环境下约为1MBps;但当文本含有大量购买意愿而使得每一条指令都可能被执行时,匹配速度下降为约20KBps,在使用TML分析购买意愿的7个行业中,每日识别出数万条购买意愿的有效精度在40%-50%之间。TML程序运行的时间代价与程序长度没有直接关系,能够求解非常大规模的问题。表6本发明具体实施例购买意愿分析虽然已经通过例子对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上例子仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员应该理解,可在不脱离本发明的范围和精神的情况下,对以上实施例进行修改。本发明的范围由所附权利要求来限定。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1