基于概念代数的微博文本特征扩展方法与流程
本发明属于自然语言处理领域,涉及一种基于概念代数的微博文本特征扩展方法。
背景技术:
随着社交网络的出现,微博作为一种新的文化渗透到网络中来。微博传播迅速,极大的方便了人们的交流,同时特对自然语言处理提出了新的挑战。微博文本与传统文本相比,一方面,微博文本篇幅较短,包含的词语个数较少,进而词切分带来的错误对微博文本处理的影响变得更为明显。另一方面,微博文本特征词少导致了微博文本的表示能力较弱,微博文本在使用向量空间模型(VSM)做文本表示时的高维度高稀疏性使得传统文本处理的性能下降。因此,对微博进行特征扩展,增加微博文本表示的语义具有十分重要的意义。
技术实现要素:
为了解决微博文本特征稀疏的问题,并且找到一种特征扩展后的微博文本表示方法,本发明提出了一种基于概念代数的微博文本特征扩展方法。
本发明主要利用了概念代数和维基百科进行微博文本特征扩展方法的设计。
概念代数可以表示为一个5元组:
C@(O,A,Rc,Ri,Ro)
其中,O为对象集,A为属性集,Rc为O与A的关系集,Ri为A的输出关系,Ro为A的输出关系。根据Wang等人的研究,相比于传统的文本表示,概念代数是基于关键词的语义表示,能够充分的表示同一关键词在不同语境中所表达的不同的含义,是一种有效的知识表示方法。在本发明中,将微博文本原特征看做概念代数的对象集O,微博文本特征的扩展信息作为概念代数的属性集A、输入关系Ri和输出关系Ro。
维基百科在本发明中起到辅助作用,作为微博文本特征的外部知识库,根据盛志超,汪洋等人的研究,维基百科中的页面网络和类别网络包含丰富的语义信息,可以利用这些语义信息生成微博文本特征的扩展特征。由于维基百科中的页面网络中存在入度节点和出度节点,联想到上述概念代数的结构特性,维基百科作为知识库可以有效的与概念代数相结合,有利于概念代数中的属性集A、输入关系Ri和输出关系Ro的构建。
本发明为了实现上述目的采用的技术方案如下:
1)构建维基百科的页面网络和类别网络信息存储到数据库中,主要包括数据信息为:页面信息(Page)、页面网络(pagelink)、类别网络(category)和重定向页面(redirect)。
2)微博文本预处理,主要为微博文本内容扩充和词义纠正。其中文本内容扩充利用微博的评论信息,采用了简单词共现方法挑选有价值的微博评论信息;词义纠正利用维基百科的重定向页面(redirect)对微博中的缩写进行扩展,生成维基百科对应的概念词条。
3)基于概念代数的微博文本特征的属性集(A)构建,利用维基百科的类别网络计算微博文本特征与维基百科解释页面对应每个概念的相关度,选择相关度较大的解释页面中的概念作为微博文本特征的属性集A,相关度计算公式为:
在此公式中主要考虑:在a,b在维基百科类别网络上的所有公共祖先节点的数目,为公式的第一部分;概念a和概念b在维基百科类别网络所有公共路劲的长度,在维基百科类别网络上的距离,距离越大则表示其相关程度越低;概念a和概念b是否在维基百科类别网的同一层上。若差值等于0,则表示概念a和概念b在维基百科类别网络的同一层上,那么其相关度相对不在同一层上的概念较 高。
4)构建概念代数的微博文本特征的输入关系Ri和输出关系Ro,利用维基百科页面网络(pagelink)中的入度节点和出度节点,对每个微博文本特征和其对应的属性集生成输入关系Ri和输出关系Ro
5)生成基于概念代数的微博文本特征扩展后的微博文本特征表示形式。
本发明的积极进步效果在于:提出了一种基于概念代数的微博文本特征扩展方法,引入维基百科作为知识库,使得微博文本的特征扩展具有有效知识库的支持,实现了微博文本特征的语义扩展,同时以概念代数作为微博文本表示特征扩展后的形式克服了传统向量空间模型(VSM)文本表示缺乏层次性的不足。
附图说明
图1为基于概念代数微博文本特征扩展方法的实现框架
图2为基于概念代数微博文本特征扩展方法的数据流程图
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
在实施例中主要的微博文本来源为新浪微博,通过新浪微博提供的API下载微博原文和微博原文的评论信息。
如图1所示,本发明的基于概念代数的微博文本特征扩展方法主要包括以下几个步骤:
步骤1、维基百科知识库信息预处理,将维基百科中的相关信息存储到数据库表格中,方便以后信息查询。
步骤2、微博文本预处理,对微博文本内容进行扩充,以及分词操作,进行必要的词以纠正操作。
步骤3、基于概念代数的微博文本特征的属性集构建,利用维基百科的类别网信息,进行文本特征与维基百科的解释信息的相关度计算,选择相关度较大的解释信息作为微博文本特征的属性集。
步骤4、基于概念代数的微博文本特征的输入关系和输出关系构建,利用维基百科的页面网信息,查询文本特征及其属性集在页面网中的出度节点和入度节点作为微博文本特征的输入关系和输出关系。
步骤5、生成微博文本的概念代数表示形式,将步骤3和步骤4产生的属性集、输入关系和输出关系进行组织表示,以XML文件存储。
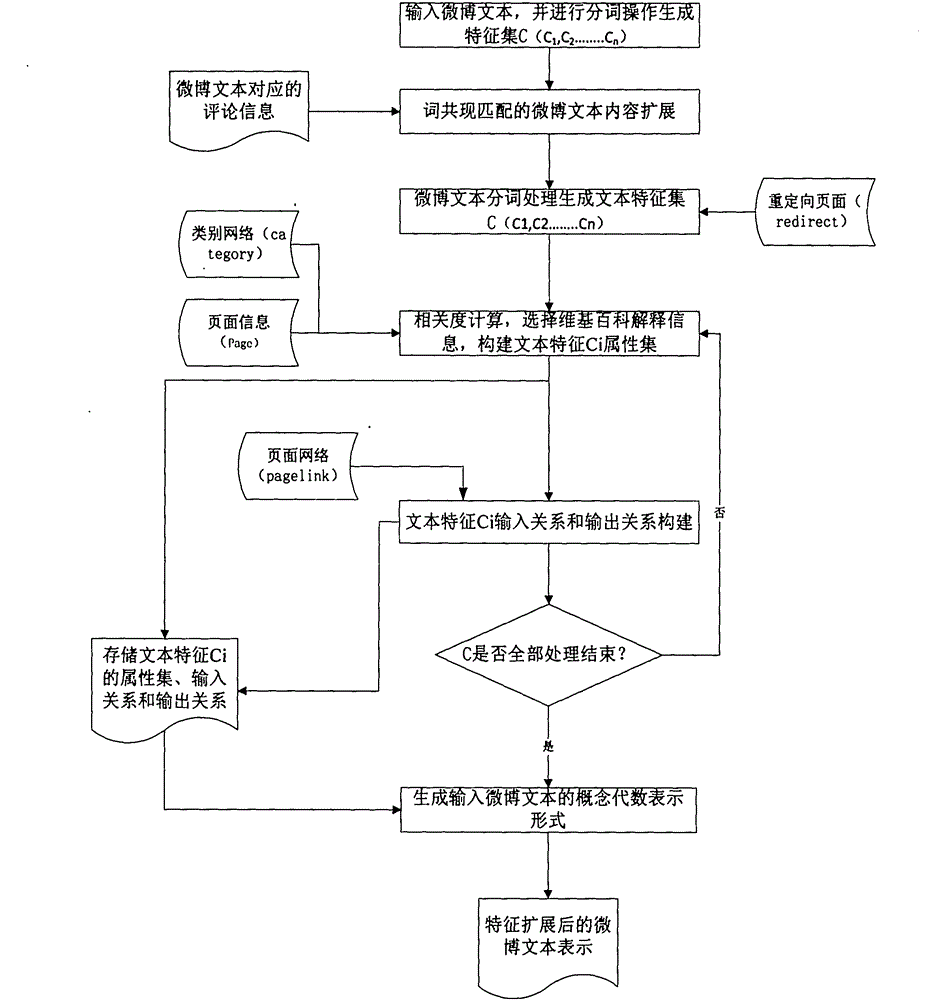
本发明的具体算法流程如图2所示:
1)输入微博文本,并进行分词操作生成特征集C(C1,C2........Cn)。
2)采用词共现方法逐条判断微博文本的评论信息是否存在于微博文本相同的词语,若存在,则评论信息添加到微博文本特征集C中。否则,处理下一条评论信息。若评论信息已经处理完,则跳转到步骤3
3)对每个微博文本特征Ci查询维基百科page信息,找到其对应的解释信息,并利用维基百科的类别网络(category)逐个相关度计算,选择维基百科解释信息,构建文本特征Ci属性集,并将生成的属性集存储在中间文件中。
4)对文本特征Ci对应的属性集中的每个属性A查询维基百科的页面网络(pagelink)中的入度节点和出度节点作为输入关系和输出关系,并存储到步骤3的中间文件中。
5)判断微博文本特征集C是否处理结束,若是,则转到步骤6,否则,转到步骤3
6)生成特征扩展后的微博文本的概念代数表示形式,并且以XML的形式保存。
通过上述算法便完成了对一篇微博文本的特征扩展,并且实现了微博文本的新的表示形式,丰富了微博文本的语义信息,这样有利于对微博文本的后续处理,如文本分类、舆情分析和情感分析等。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更或修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!