一种单机的大规模数据集的聚类挖掘方法与流程
本发明涉及一种单机的大规模数据集的聚类挖掘方法,属于数据挖掘技术领域。
背景技术:
近几年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百GB甚至数十至数百TB规模的行业/企业大数据已远远超出了现有传统的计算技术和信息系统的处理能力。
大数据给传统的计算技术带来了很多新的挑战。大数据使得很多在小数据集上有效的传统的串行化算法在面对大数据处理时难以在可接受的时间内完成计算;同时大数据含有较多噪音、样本稀疏、样本不平衡等特点使得现有的很多机器学习算法有效性降低。大数据在带来巨大技术挑战的同时,也带来巨大的技术创新与商业机遇。因此,寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。
如今的大数据处理技术,大多基于网络集群来实现分布式数据挖掘,对资源与条件要求较高,且实现起来难度较高。在仅有一台物理机的情况下,若想完成大规模数据集的挖掘工作,需要一套较为成熟的方案。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种单机的大规模数据集的聚类挖掘方法。
本发明提供的方法基于虚拟内存、分块处理的机制有效地解决了单台物理机内存严重不足的问题,基于共享内存机制、内存映射文件机制与单机多核并行处理机制成功地提高了大规模数据集的挖掘效率,并且基于R语言构建聚类的挖掘模型,完成子数据集的挖掘工作后将结果进行合并,从而实现单机上的大规模数据集的聚类挖掘工作。
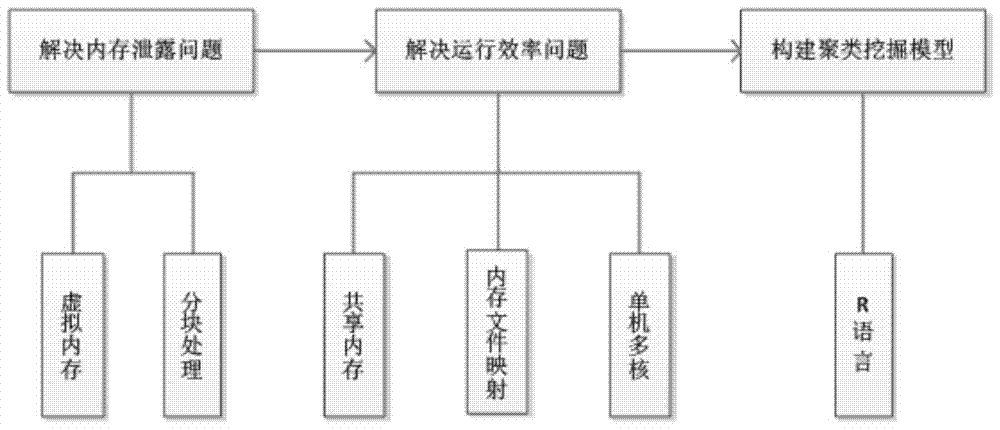
技术方案:一种单机的大规模数据集的聚类挖掘方法,采用多种机制来解决单机大数据聚类挖掘所遇到的内存泄露与运行效率问题,主要包括:
A、解决内存泄漏问题:主要通过改进传统的数据存储和读取方式来完成。采用虚拟内存、分块处理的机制,即将大数据按照固定大小分块,每次读取一到两个数据块并加载至内存中,处理完成后及时释放内存与临时空间,如此分时地利用物理机内存。
B、解决运行效率问题:充分利用单机上的硬件优势与“分而治之”的思想是提高大数据挖掘的运行效率的关键。采用共享内存机制、内存映射文件机制与单机多核并行处理机制,通过共享内存实现多个进程共享一块内存区域,以方便实现并行算法;通过内存映射文件使得处理磁盘上的文件不必执行I/O操作,节省运行时间;单机多核机制则将不同数据块的挖掘任务分配到处理器不同的核上并行处理。
C、聚类挖掘方面:基于R语言构建聚类挖掘模型,首先自行定制模型参数,完成所有子任务的聚类挖掘工作后将子任务的挖掘结果进行合并,即把得到的每簇的中心点重新组织作为挖掘模型的输入,如此迭代下去,直至结果满足预设的聚类簇数。
本发明采用上述技术方案,具有以下有益效果:本发明提供的单机的大规模数据集的聚类挖掘方法,基于共享内存机制、内存映射文件机制与单机多核并行处理机制等有效地解决了单机上大数据聚类挖掘时存在的内存泄露与运行效率问题,充分利用了单台物理机有限的内存空间与处理器资源,在不依赖网络集群或搭建网络集群条件受限的情况下,为大规模数据集的聚类挖掘工作提供了一套可用的单机解决方案。
附图说明
图1为本发明实施例的设计流程图;
图2为本发明实施例的实现步骤示意图;
图3为本发明实施例中虚拟内存、分块处理机制的设计原理图;
图4为本发明实施例中单机多核处理的分解过程;
图5为本发明实施例中单机多核处理的汇总过程。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本发明所提供的方法将单机上大规模数据集的聚类挖掘大致分为三大步,如图1所示,首先构建聚类挖掘模型,然后分别解决内存泄露问题和运行效率问题;如图2所述,本发明方法的实现步骤分别是:内存泄漏问题的解决,即基于虚拟内存、分块处理机制将大数据分块读入内存;运行效率问题的解决,即基于共享内存机制、内存文件映射机制与单机多核并行处理机制,通过减少进程切换时间、节省文件I/O操作的时间、充分利用处理器的多核进行并行计算等方法大幅提高运行效率;聚类挖掘模型的构建与挖掘结果的合并,即基于R语言构建模型,完成子任务的挖掘工作后合并得到最终结果的过程。
本发明实施例中单机的大规模数据集的聚类挖掘方法包括以下步骤:
步骤1:解决内存泄露问题。首先根据数据集的规模从物理机的硬盘上动态划分出一片存储区域作为虚拟内存,用来以二进制文件的形式来存储大数据的临时数据;然后将大数据按照10~20M的大小进行分块,存储在上述临时文件中,并为每个数据块建立映射索引。在进行处理时,每次从外存中读取一至两个数据块到内存中,然后对数据块进行修正,即用R语言中数据框的形式保存该数据块中的数据,使其可以作为步骤3中挖掘模型的输入数据。处理完成后,及时释放内存空间和虚拟内存空间。虚拟内存、分块处理的机制如图3所示。
步骤2:解决运行效率问题。首先实现共享内存机制,具体就是让多个进程共享一块物理内存,共享该内存中的数据块。如此便使得不同的进程可以通过共享内存通信,而且数据块可被多个进程共享,为后面的单机多核机制实现并行算法提供方便;然后实现内存文件映射机制,保留一个地址空间的区域,同时将物理存储器(已经存在于磁盘上的文件)提交给此区域,而且对该文件与相应内存区域建立映射,如此处理存储在磁盘上的文件时,不必再对文件执行I/O操作;接着在底层利用C语言的数据类型对步骤1中得到的数据块进行处理,将其中的数据用矩阵存储,并将矩阵分配到共享内存或内存映射文件中,然后用一个指针对象指向存储的数据块,实现文件缓存的机制,提高后续工作的效率;最终实现单机多核并行处理机制,首先根据处理器的具体情况,选择一个核作为master,其他的核作为worker。master接受到一个任务之后,会将其分解为n-1个子任务(n为处理器核数),分配给每个worker,分解过程如图4。接着每个worker基于共享内存/内存文件映射机制单独处理自己的小任务(基于步骤3的聚类挖掘模型),处理完毕后每个worker将中间结果返回给master,最终由master将结果汇总后输出,汇总过程如图5所示。
步骤3:挖掘模型的构建与挖掘结果的合并。用Java封装R语言的cluster程序包中的clara()函数,如此便构建起聚类挖掘模型,并部署在处理器的每个核上,设置好相关参数(可自行定制参数,例如聚类的簇数等)后,按照步骤2的单机多核机制完成每个数据块的聚类挖掘。所有worker上的数据块挖掘任务完成以后,将这些数据块的挖掘结果中划分的所有簇中心点重新整合,作为一个新的聚类任务进行挖掘,如此的挖掘结果便覆盖了这些数据块。按照此类方式进行迭代,直至挖掘结果覆盖最初的大规模数据集。
- 还没有人留言评论。精彩留言会获得点赞!