将微博话题词分类到具体领域的方法和设备与流程
本发明一般地涉及信息处理领域。具体而言,本发明涉及一种能够准确地将微博话题词分类到已有分类体系下的具体领域的方法和设备。
背景技术:
近年来,微博(microblog)得到了迅猛的发展,成为非常流行的网络信息发布和获取平台。然而,海量的微博内容也带来了筛选感兴趣微博内容的难度。
“话题词”(hashtag)在某种程度上解决了这个问题。微博平台可以推出一些话题词,用户也可以自定义一些话题词。话题词通常代表一个讨论的热点,比如最近的一个新闻事件等。话题词的表现形式是“#话题词#”。微博作者只需将“#话题词#”插入到自己要发表的微博内容中,然后发表该微博。这样,微博用户就能够通过话题词的应用查看到包含该话题词的微博内容了。
例如,微博内容“#鲁甸地震_灾后重建#又一次来到龙头山镇灰街子安置点,群众们已经住进了加棉的帐篷里,集体厨房里也井井有条!”。其中,“#鲁甸地震_灾后重建#”是一个话题词,其代表了与鲁甸地震这一重大自然灾害事件相关的灾后重建问题相关的内容。再比如,微博内容“#奔跑吧兄弟##决胜济州岛#周五快到我碗里来!”,其包括话题词“#奔跑吧兄弟#”,代表当下最为热门的电视综艺节目之一,并且还包括话题词“#决胜济州岛#”,这是与话题词“#奔跑吧兄弟#”相关的话题词。
可见,话题词有助于微博用户浏览感兴趣的话题相关的微博内容,提高微博平台的用户友好性和使用便利性。但是,话题词涉及的内容十分广 泛,目前没有针对话题词合理分类的手段,导致确定感兴趣的话题词,如按类别查看、选择话题词时存在困难。
因此,期望一种将微博话题词分类到具体领域的方法和设备,对话题词进行归类,以便于微博用户按类别查看、选择话题词,帮助微博用户找到自己感兴趣的特定话题词。
技术实现要素:
在下文中给出了关于本发明的简要概述,以便提供关于本发明的某些方面的基本理解。应当理解,这个概述并不是关于本发明的穷举性概述。它并不是意图确定本发明的关键或重要部分,也不是意图限定本发明的范围。其目的仅仅是以简化的形式给出某些概念,以此作为稍后论述的更详细描述的前序。
本发明的目的是针对现有技术的上述问题,提出了一种能够准确地将微博话题词分类到已有分类体系下的具体领域的方法和设备。
为了实现上述目的,根据本发明的一个方面,提供了一种将微博话题词分类到具体领域的方法,该方法包括:获取代表微博话题词的表意文本;以及利用针对具体分类体系的分类模型,对所述表意文本进行分类;其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果。
根据本发明的另一个方面,提供了一种将微博话题词分类到具体领域的设备,该设备包括:表意文本获取装置,被配置为:获取代表微博话题词的表意文本;以及针对具体分类体系的分类模型,用于对所述表意文本进行分类;其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果。
另外,根据本发明的另一方面,还提供了一种存储介质。所述存储介质包括机器可读的程序代码,当在信息处理设备上执行所述程序代码时,所述程序代码使得所述信息处理设备执行根据本发明的上述方法。
此外,根据本发明的再一方面,还提供了一种程序产品。所述程序产 品包括机器可执行的指令,当在信息处理设备上执行所述指令时,所述指令使得所述信息处理设备执行根据本发明的上述方法。
附图说明
参照下面结合附图对本发明的实施例的说明,会更加容易地理解本发明的以上和其它目的、特点和优点。附图中的部件只是为了示出本发明的原理。在附图中,相同的或类似的技术特征或部件将采用相同或类似的附图标记来表示。附图中:
图1示出了根据本发明的一个实施例的将微博话题词分类到具体领域的方法的流程图;
图2示出了步骤S1的一种实现方式的流程图;
图3示出了根据本发明的另一实施例的将微博话题词分类到具体领域的方法的流程图;
图4示出了根据本发明的一个实施例的将微博话题词分类到具体领域的设备的结构方框图;
图5示出了根据本发明的另一实施例的将微博话题词分类到具体领域的设备的结构方框图;以及
图6示出了可用于实施根据本发明的实施例的方法和设备的计算机的示意性框图。
具体实施方式
在下文中将结合附图对本发明的示范性实施例进行详细描述。为了清楚和简明起见,在说明书中并未描述实际实施方式的所有特征。然而,应该了解,在开发任何这种实际实施方式的过程中必须做出很多特定于实施方式的决定,以便实现开发人员的具体目标,例如,符合与系统及业务相关的那些限制条件,并且这些限制条件可能会随着实施方式的不同而有所 改变。此外,还应该了解,虽然开发工作有可能是非常复杂和费时的,但对得益于本公开内容的本领域技术人员来说,这种开发工作仅仅是例行的任务。
在此,还需要说明的一点是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的装置结构和/或处理步骤,而省略了与本发明关系不大的其他细节。另外,还需要指出的是,在本发明的一个附图或一种实施方式中描述的元素和特征可以与一个或更多个其它附图或实施方式中示出的元素和特征相结合。
本发明的基本思想是利用已有的专业分类体系作为参照,将微博话题词分类到分类体系中的类别之中,以便于微博用户按类别查看、选择感兴趣的话题词。另外,在类别内对话题词进行热度排序,帮助微博用户了解具体领域(类别)内的话题词热度情况。
下面将参照图1描述根据本发明的一个实施例的将微博话题词分类到具体领域的方法的流程。
图1示出了根据本发明的一个实施例的将微博话题词分类到具体领域的方法的流程图。如图1所示,根据本发明的一个实施例的分类方法包括如下步骤:获取代表微博话题词的表意文本(步骤S1);以及利用针对具体分类体系的分类模型,对所述表意文本进行分类(步骤S2),其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果。
在步骤S1中,获取代表微博话题词的表意文本。
这是因为话题词本身只是短语,其提供的语义信息较为有限,不利于准确地对话题词进行分类。考虑到话题词本身代表了其所在的微博内容的话题,所以可以选取能够较好地表征话题词所代表话题的微博内容来体现话题词的意义。
然而,由于包含话题词的微博内容并不一定都是与该话题词密切相关的,可能是借助于话题词对自身推广的广告等,所以需要对包含话题词的微博内容进行筛选,选出真正有意义的代表性微博内容。在本文中,将能 够代表话题词的微博内容称为表意文本。
获取话题词的表意文本的方法显然有多种,下文中给出一种示例的实现方式,本发明不限于此。
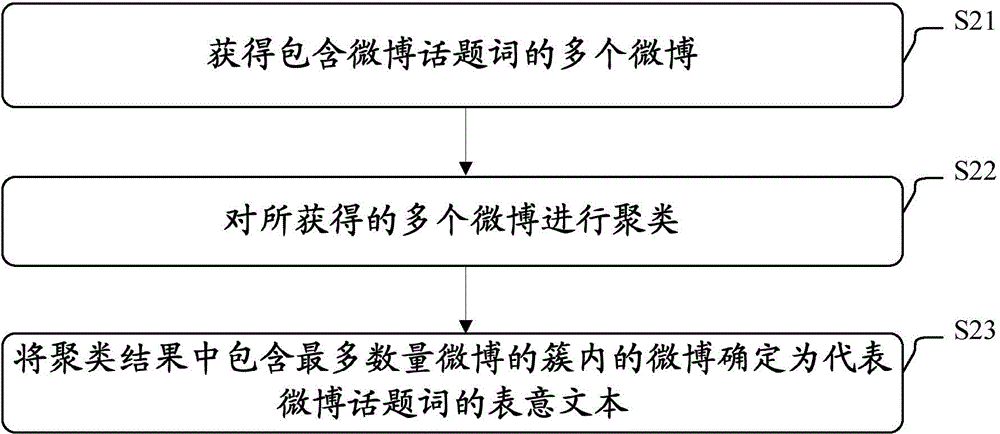
图2示出了步骤S1的一种实现方式的流程图。
如图2所示,获取话题词的表意文本的方法包括:获得包含微博话题词的多个微博(步骤S21);对所获得的多个微博进行聚类(步骤S22);将聚类结果中包含最多数量微博的簇内的微博确定为代表微博话题词的表意文本(步骤S23)。
在步骤S21中,获得包含微博话题词的多个微博。例如,获得包含话题词的最近一段时间内发表的多个微博。最近一段时间例如是最近一周、最近一个月。
所获得的每一个微博要进行分词、去重等预处理操作,以形成一个词向量。词向量的维度和每个维度对应的词,与下文所述的已分类文本数据(如新闻文本)的词向量的维度和每个维度对应的词保持一致。
在步骤S22中,对所获得的多个微博进行聚类。也即,对多个词向量进行聚类。
聚类的目的是为了去除广告等无关信息。正如前文所述,理想状况是话题词代表话题词所在微博内容的话题,包含话题词的微博内容与话题词相适应。但由于例如广告借助于热门话题词进行推广,导致包含话题词的微博内容与话题词不相适应,这样的微博内容不适于作为话题词的表意文本。然而,应理解大多数的包含同一话题词的微博内容应该是与该话题词内容相适应的,所以通过聚类操作,能够去除无关信息,帮助找出表意文本。当然,聚类方法不受限制。
在此,给出一种优选的聚类方法。在该优选聚类方法中,采用自适应阈值作为聚类的标准。
具体地,假设要聚类的多个词向量有x个,则x个词向量两两组成一 对,共对。计算特征空间中每对词向量之间的欧氏距离/相似度,计算平均欧式距离/平均相似度,并乘以预定的权值参数,即可得到自适应于这x个词向量的聚类阈值。
基于欧氏距离的聚类阈值T的公式表示如下。
其中,w为权值参数,大于0且小于或等于1,优选取值为0.9。x为词向量个数。S(mi)和S(mj)分别表示微博内容mi和mj对应的词向量,Ed(S(mi),S(mj))表示词向量S(mi)和S(mj)之间的欧式距离。
自适应聚类阈值还可以是x个词向量两两之间的相似度的平均值与大于或等于1的权值参数的乘积。
确定了自适应聚类阈值之后,可以采用如下方法基于自适应聚类阈值对词向量进行聚类。下面以基于欧氏距离的自适应聚类阈值为例进行说明,基于相似度的自适应聚类阈值的聚类类似。
(1)随机选择一个词向量,作为一个新簇;
(2)随机选择一个未聚类的词向量,计算其与每一个已有簇的中心向量之间的欧式距离;
(3)将欧式距离小于自适应聚类阈值的词向量,加入到对应的簇中;
(4)将欧式距离均大于或等于自适应聚类阈值的词向量,作为一个新簇;
重复上述步骤(2)-(4)直至所有词向量均被聚类。
经过步骤S22,与一个话题词相关的多个微博(其向量)被聚类,以得到多个簇。
在步骤S23中,将聚类结果中包含最多数量微博的簇内的微博确定为代表微博话题词的表意文本。
认为包含最多数量微博的簇,也就是最大类中的微博是体现话题词的微博内容,因为认为话题词的大部分微博内容是针对话题词发出的,广告等无关微博占比较小。
在一个实施例中,将聚类结果中包含最多数量微博的簇内的所有微博作为代表微博话题词的表意文本。
在另一个实施例中,将聚类结果中包含最多数量微博的簇内的距离簇中心最近的一个或多个微博作为代表微博话题词的表意文本。
至此,在步骤S1中,获得了话题词的表意文本。表意文本的形式是词向量。如果表意文本包括多个微博的词向量,则将多个微博的词向量合并为一个总的词向量。
在步骤S2中,利用针对具体分类体系的分类模型,对所述表意文本进行分类;其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果。
与简单地将话题词分组不同,本发明对话题词的分类实际上是将话题词归类到已有的专业分类体系中。例如,新闻分类体系就是非常专业权威的分类体系,并且适合微博话题词的分类。所以,以新闻分类体系为例,可以通过将表意文本分类到新闻分类体系下的具体领域中来将对应的微博话题词进行分类。
为了实现上述分类,可以预先训练一个针对具体分类体系的分类模型,然后将表意文本(词向量)输入训练好的分类模型,以获得表意文本的分类结果,作为话题词的分类结果。
为了训练分类模型,首先收集已分类文本数据及其分类信息。
例如,分类文本数据是新闻文本,新闻文本已经由专业编辑按新闻分类体系分类。在新闻网站或者综合网站的新闻版块中,有很多新闻文本可以获取。新闻文本的类别例如是“体育”、“社会”、“娱乐”等等。针对每个类别,例如收集不少于10000条新闻文本。然后,对每个新闻文本进行分词、去重等操作,以获得词向量。词向量的维度,是大量新闻文本中包 含的所有词语数量,每个维度对应的词是大量新闻文本中包含的所有词语之一,词向量的每个维度的值可以是1或0,代表该维度对应的词存在于或不存在于该词向量对应的文本,也可以是该维度对应的词在该词向量对应的文本中出现的次数。
然后,利用所收集的已分类文本数据及其分类信息,训练分类模型。分类模型例如是但不限于SVM分类器、贝叶斯分类器和决策树分类器等等。
利用已训练好的分类模型对代表话题词的表意文本进行分类,所获得的分类体系下的具体领域信息就是话题词的分类结果。比如,话题词1、3、6、9被分类到“娱乐”,话题词2、4、5、8被分类到“军事”。微博用户如果仅对娱乐感兴趣,而对军事毫无兴趣,就可以查看分类为“娱乐”领域的话题词,从中进一步找到自己感兴趣的话题词3,然后利用话题词应用,查看话题词3相关的微博内容。显然,根据本发明的方法,可以准确地将话题词按已有的专业分类体系分类到具体领域中,方便微博用户利用话题词。
除了提供话题词的分类信息之外,根据本发明的另一个实施例,还可以提供话题词在某一具体领域中的热度信息,更加便于微博用户利用话题词查看微博内容。
图3示出了根据本发明的另一实施例的将微博话题词分类到具体领域的方法的流程图。如图3所示,根据本发明的实施例的分类方法包括如下步骤:获取代表微博话题词的表意文本(步骤S31);利用针对具体分类体系的分类模型,对所述表意文本进行分类(步骤S32),其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果;以及针对给定类别,对被分类到该类别内的微博话题词进行热度排序(步骤S33)。
步骤S31、S32与上面实施例中的步骤S1、S2相同,在此不再赘述。
在步骤S33中,对于属于同一具体领域的话题词进行热度排序。其目的是提供热度信息,帮助微博用户了解话题词。
因为微博是一个时效性比较强的事物,微博用户容易在短时间内集中关注近期较热的话题,话题在时间久了后会逐渐失去对微博用户的吸引力,所以话题词涉及的话题的热度是影响微博用户兴趣的重要因素。根据热度对属于同一具体领域内的话题词进行排序,显然有助于微博用户了解和选择具体的感兴趣的话题词。
热度可以通过热度评价值体现。热度评价值例如可以与下列三个因素中的至少一个因素相关:包含微博话题词的微博的数量、发表时间、以及微博话题词属于该给定类别的概率。
包含微博话题词的微博的数量越多,话题词越热,热度评价值越高。
包含微博话题词的微博的发表时间越近,话题词越热,热度评价值越高。
上述分类模型对话题词进行分类实际上是确定话题词属于各个具体领域的概率,然后将话题词分类到概率最大的那个具体领域中。因此,可获得话题词属于作为分类结果的类别的概率值,利用其计算话题词的热度。概率值越高,热度评价值越高。
话题词的热度评价值的示例公式如下。
其中,H(hi)代表微博话题词hi的热度值,Di是指hi被分类模型划分到的领域,p(hi,Di)是指hi属于Di的概率。Ni表示hi对应的微博数量,tp表示当前的时间,tj表示hi对应的第j条微博的发表时间,其中(1≤j≤Ni),γ是衰减内核参数,表示兴趣衰减的快慢,举例来说,其设定为7(天),exp()是以自然常数e为底的指数函数。
可按照热度值对属于同一具体领域的话题词排序,并按照排序结果,将话题词呈现给微博用户。这样,微博用户不仅了解到话题词的分类信息还能了解到话题词的热度信息,从而更容易地选择到自己感兴趣的话题词。
下面,将参照图4描述根据本发明的一个实施例的将微博话题词分类到具体领域的设备。
图4示出了根据本发明的一个实施例的将微博话题词分类到具体领域的设备的结构方框图。如图4所示,根据本发明的分类设备400包括:表意文本获取装置41,被配置为:获取代表微博话题词的表意文本;以及针对具体分类体系的分类模型42,用于对所述表意文本进行分类;其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果。
在一个实施例中,表意文本获取装置41包括:获得单元,被配置为:获得包含微博话题词的多个微博;聚类单元,被配置为:对所获得的多个微博进行聚类;确定单元,被配置为:将聚类结果中包含最多数量微博的簇内的微博确定为代表微博话题词的表意文本。
在一个实施例中,确定单元被进一步配置为:将聚类结果中包含最多数量微博的簇内的所有微博作为代表微博话题词的表意文本。
在一个实施例中,确定单元被进一步配置为:将聚类结果中包含最多数量微博的簇内的距离簇中心最近的一个或多个微博作为代表微博话题词的表意文本。
在一个实施例中,分类设备400还包括训练装置,用于训练所述分类模型,所述训练装置被配置为:收集已分类文本数据及其分类信息;利用所收集的已分类文本数据及其分类信息,训练所述分类模型。
在一个实施例中,已分类文本数据包括新闻文本,分类信息包括新闻文本的分类信息。
下面,将参照图5描述根据本发明的另一实施例的将微博话题词分类到具体领域的设备。
图5示出了根据本发明的另一实施例的将微博话题词分类到具体领域的设备的结构方框图。如图5所示,根据本发明的分类设备500包括:表意文本获取装置51,被配置为:获取代表微博话题词的表意文本;以及针对具体分类体系的分类模型52,用于对所述表意文本进行分类;其 中,对所述表意文本的分类结果作为对所述微博话题词的分类结果;热度排序装置53,被配置为:针对给定类别,对被分类到该类别内的微博话题词进行热度排序。
表意文本获取装置51、针对具体分类体系的分类模型52分别与上述表意文本获取装置41、针对具体分类体系的分类模型42相同。
在一个实施例中,热度排序装置53包括:评价值计算单元,被配置为:根据包含微博话题词的微博的数量、发表时间、以及微博话题词属于该给定类别的概率中的至少一个,计算该微博话题词在该给定类别内的热度评价值;排序单元,被配置为:根据该给定类别内的所有微博话题词的热度评价值,对微博话题词进行热度排序。
由于在根据本发明的分类设备400、分类设备500中所包括的各个装置和单元中的处理分别与上面描述的分类方法中所包括的各个步骤中的处理类似,因此为了简洁起见,在此省略这些装置和单元的详细描述。
此外,这里尚需指出的是,上述设备中各个组成装置、单元可以通过软件、固件、硬件或其组合的方式进行配置。配置可使用的具体手段或方式为本领域技术人员所熟知,在此不再赘述。在通过软件或固件实现的情况下,从存储介质或网络向具有专用硬件结构的计算机(例如图6所示的通用计算机600)安装构成该软件的程序,该计算机在安装有各种程序时,能够执行各种功能等。
图6示出了可用于实施根据本发明的实施例的方法和设备的计算机的示意性框图。
在图6中,中央处理单元(CPU)601根据只读存储器(ROM)602中存储的程序或从存储部分608加载到随机存取存储器(RAM)603的程序执行各种处理。在RAM 603中,还根据需要存储当CPU 601执行各种处理等等时所需的数据。CPU 601、ROM 602和RAM 603经由总线604彼此连接。输入/输出接口605也连接到总线604。
下述部件连接到输入/输出接口605:输入部分606(包括键盘、鼠标等等)、输出部分607(包括显示器,比如阴极射线管(CRT)、液晶显示器 (LCD)等,和扬声器等)、存储部分608(包括硬盘等)、通信部分609(包括网络接口卡比如LAN卡、调制解调器等)。通信部分609经由网络比如因特网执行通信处理。根据需要,驱动器610也可连接到输入/输出接口605。可拆卸介质611比如磁盘、光盘、磁光盘、半导体存储器等等可以根据需要被安装在驱动器610上,使得从中读出的计算机程序根据需要被安装到存储部分608中。
在通过软件实现上述系列处理的情况下,从网络比如因特网或存储介质比如可拆卸介质611安装构成软件的程序。
本领域的技术人员应当理解,这种存储介质不局限于图6所示的其中存储有程序、与设备相分离地分发以向用户提供程序的可拆卸介质611。可拆卸介质611的例子包含磁盘(包含软盘(注册商标))、光盘(包含光盘只读存储器(CD-ROM)和数字通用盘(DVD))、磁光盘(包含迷你盘(MD)(注册商标))和半导体存储器。或者,存储介质可以是ROM 602、存储部分608中包含的硬盘等等,其中存有程序,并且与包含它们的设备一起被分发给用户。
本发明还提出一种存储有机器可读取的指令代码的程序产品。所述指令代码由机器读取并执行时,可执行上述根据本发明的实施例的方法。
相应地,用于承载上述存储有机器可读取的指令代码的程序产品的存储介质也包括在本发明的公开中。所述存储介质包括但不限于软盘、光盘、磁光盘、存储卡、存储棒等等。
在上面对本发明具体实施例的描述中,针对一种实施方式描述和/或示出的特征可以以相同或类似的方式在一个或更多个其它实施方式中使用,与其它实施方式中的特征相组合,或替代其它实施方式中的特征。
应该强调,术语“包括/包含”在本文使用时指特征、要素、步骤或组件的存在,但并不排除一个或更多个其它特征、要素、步骤或组件的存在或附加。
此外,本发明的方法不限于按照说明书中描述的时间顺序来执行,也 可以按照其他的时间顺序地、并行地或独立地执行。因此,本说明书中描述的方法的执行顺序不对本发明的技术范围构成限制。
尽管上面已经通过对本发明的具体实施例的描述对本发明进行了披露,但是,应该理解,上述的所有实施例和示例均是示例性的,而非限制性的。本领域的技术人员可在所附权利要求的精神和范围内设计对本发明的各种修改、改进或者等同物。这些修改、改进或者等同物也应当被认为包括在本发明的保护范围内。
附记
1.一种将微博话题词分类到具体领域的方法,包括:
获取代表微博话题词的表意文本;以及
利用针对具体分类体系的分类模型,对所述表意文本进行分类;
其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果。
2.如附记1所述的方法,其中,所述获取代表微博话题词的表意文本包括:
获得包含微博话题词的多个微博;
对所获得的多个微博进行聚类;
将聚类结果中包含最多数量微博的簇内的微博确定为代表微博话题词的表意文本。
3.如附记2所述的方法,其中,将聚类结果中包含最多数量微博的簇内的所有微博作为代表微博话题词的表意文本。
4.如附记2所述的方法,其中,将聚类结果中包含最多数量微博的簇内的距离簇中心最近的一个或多个微博作为代表微博话题词的表意文本。
5.如附记2所述的方法,其中,所述对所获得的多个微博进行聚类包括:
计算多个微博所对应的多个词向量中两两之间的欧式距离的平均值与大于0且小于或等于1的权值参数的乘积,作为用于聚类的自适应阈值;
利用所确定的自适应阈值,对多个词向量进行聚类。
6.如附记2所述的方法,其中,所述对所获得的多个微博进行聚类包括:
计算多个微博所对应的多个词向量中两两之间的相似度的平均值与大于或等于1的权值参数的乘积,作为用于聚类的自适应阈值;
利用所确定的自适应阈值,对多个词向量进行聚类。
7.如附记1所述的方法,其中,所述分类模型通过如下步骤训练得到:
收集已分类文本数据及其分类信息;
利用所收集的已分类文本数据及其分类信息,训练所述分类模型。
8.如附记7所述的方法,其中,所述已分类文本数据包括新闻文本,所述分类信息包括新闻文本的分类信息。
9.如附记1所述的方法,还包括:针对给定类别,对被分类到该类别内的微博话题词进行热度排序。
10.如附记9所述的方法,其中所述针对给定类别,对被分类到该类别内的微博话题词进行热度排序包括:
根据包含微博话题词的微博的数量、发表时间、以及微博话题词属于该给定类别的概率中的至少一个,计算该微博话题词在该给定类别内的热度评价值;
根据该给定类别内的所有微博话题词的热度评价值,对微博话题词进行热度排序。
11.一种将微博话题词分类到具体领域的设备,包括:
表意文本获取装置,被配置为:获取代表微博话题词的表意文本;以及
针对具体分类体系的分类模型,用于对所述表意文本进行分类;
其中,对所述表意文本的分类结果作为对所述微博话题词的分类结果。
12.如附记11所述的设备,其中,所述表意文本获取装置包括:
获得单元,被配置为:获得包含微博话题词的多个微博;
聚类单元,被配置为:对所获得的多个微博进行聚类;
确定单元,被配置为:将聚类结果中包含最多数量微博的簇内的微博确定为代表微博话题词的表意文本。
13.如附记12所述的设备,其中,所述确定单元被进一步配置为:将聚类结果中包含最多数量微博的簇内的所有微博作为代表微博话题词的表意文本。
14.如附记12所述的设备,其中,所述确定单元被进一步配置为:将聚类结果中包含最多数量微博的簇内的距离簇中心最近的一个或多个微博作为代表微博话题词的表意文本。
15.如附记12所述的方法,其中,所述聚类单元包括:
自适应阈值确定子单元,被配置为:计算多个微博所对应的多个词向量中两两之间的欧式距离的平均值与大于0且小于或等于1的权值参数的乘积,作为用于聚类的自适应阈值;
聚类子单元,被配置为:利用所确定的自适应阈值,对多个词向量进行聚类。
16.如附记12所述的方法,其中,所述聚类单元包括:
自适应阈值确定子单元,被配置为:计算多个微博所对应的多个词向量中两两之间的相似度的平均值与大于或等于1的权值参数的乘积,作为用于聚类的自适应阈值;
聚类子单元,被配置为:利用所确定的自适应阈值,对多个词向量进行聚类。
17.如附记11所述的设备,还包括训练装置,用于训练所述分类模型,所述训练装置被配置为:
收集已分类文本数据及其分类信息;
利用所收集的已分类文本数据及其分类信息,训练所述分类模型。
18.如附记17所述的设备,其中,所述已分类文本数据包括新闻文本,所述分类信息包括新闻文本的分类信息。
19.如附记11所述的设备,还包括:热度排序装置,被配置为:针 对给定类别,对被分类到该类别内的微博话题词进行热度排序。
20.如附记19所述的设备,其中所述热度排序装置包括:
评价值计算单元,被配置为:根据包含微博话题词的微博的数量、发表时间、以及微博话题词属于该给定类别的概率中的至少一个,计算该微博话题词在该给定类别内的热度评价值;
排序单元,被配置为:根据该给定类别内的所有微博话题词的热度评价值,对微博话题词进行热度排序。
- 还没有人留言评论。精彩留言会获得点赞!