一种CPU与协处理器的通信方法及系统与流程
本发明属于石油勘探、矿产勘探等地质勘测中的人工地震反射波成像领域,涉及一种CPU与协处理器的通信方法及系统。
背景技术:
目前地震波成像方法以逆时偏移为精度最高的算法,但其特点为:计算量大、存储量大、内存需求大等,这些实用性瓶颈制约了应用范围。目前解决这些瓶颈的现有技术要点概括起来包括:多节点并行提高计算效率、GPU实现波场有限差分延拓提高部分代码的计算效率、优化检查点方法减少存储量、利用压缩算法减少内存需求等。尽管现有技术已经可以应用于实际资料,但是其依然是应用周期最长的一种算法,需要进一步提高效率。
逆时偏移算法采用CPU处理器加配高性能协处理器(如GPU、MAC、FPGA等)实现是近年来的研究热点,现有技术中存在的问题包括:协处理器的内存容量无法满足逆时偏移算法的要求,通常需要多个协处理器完成一炮数据的处理,但是协处理器之间的数据通信是通过PCI-E的传输总线进行传输的,其传输效率相比CPU与内存之间的传输要低很多,因此通信效率的瓶颈一直存在于常规算法中。
2013年刘守伟、唐祥功等在文献【1】(刘守伟、王华忠、陈生昌等.三维逆时偏移GPU/CPU机群实现方案研究.地球物理学报,2013,56(10):3487-3496.)和文献【2】(唐祥功、匡斌、杜继修等.多GPU协同三维叠前逆时偏移方法研究与应用.石油地球物理勘探,2013,48(6):910-914)中,利用波场重构的方式进行了GPU-RTM在大规模集群环境下的算法设计, 其核心思想是利用波场传播的可逆性把震源波场进行两轮模拟,对比于常规的CPU上的算法该方法不需要波场存储,解决了RTM存储量大的问题,但是多了一次震源波场的模拟,因此计算量增大了30%,GPU的内存需求量同样增加了一倍,通行量也增加了一倍。在实际应用中可以预见,GPU内存远远不能满足这类算法的需求,当规模增大扩大一定程度后依然存在诸多计算与通信效率的问题。另外,波场重构的方式若采用PML吸收边界时需要大量的分支计算,会大幅度降低GPU的计算效率。2013年刘守伟在文献【1】中提到利用统一波动方程的方式避免边界条件的判断,但是边界统一波动方程相比于常规的波动方程计算量增大不止一倍,内存量需求也同样增加一倍以上,这也是波场重构的致命弱点。
现有技术中,常规逆时偏移算法流程如图1所示,协处理器用于计算CPU负责数据传输,每次传播一个时间步长都需要串行执行,即T时刻协处理器计算波场完成后进行CPU处理器的数据传输,等传输完毕再进行T+1时刻的协处理器的波场计算。必须这样实现的原因是算法实现过程中由于内存容量的限制,只能申请T和T-1时刻的波场存储单元,把T和T-1时刻的波场作为输入,从而计算实现T+1时刻的波场计算并且存储在T-1时刻对应的波场内存空间。依次类推实现不同时刻的波场传播模拟。值得注意的是某一时间最多只有连续2个时刻的波场存在,其余时刻的波场无法存储在内存中。因此CPU处理器传输和协处理器的波场计算只能串行执行。
技术实现要素:
本发明所要解决的技术问题是,为了适应不同种类的协处理器,波场重构方式并非理想方式,应从CPU-RTM算法的源头进行重新考虑,提供一种逆时偏移算法中的CPU与协处理器的通信方法及系统,针对异构硬件环境,通过分析CPU-RTM现有算法的问题和弊端,提出全新的实现流程,在算法 源头设计CPU与协处理器的并行解耦算法,提高协处理与CPU处理器的通信效率。此方法可以适用于任何协处理器的应用。
本发明解决上述技术问题的技术方案如下:一种CPU与协处理器的通信方法,具体包括以下步骤:
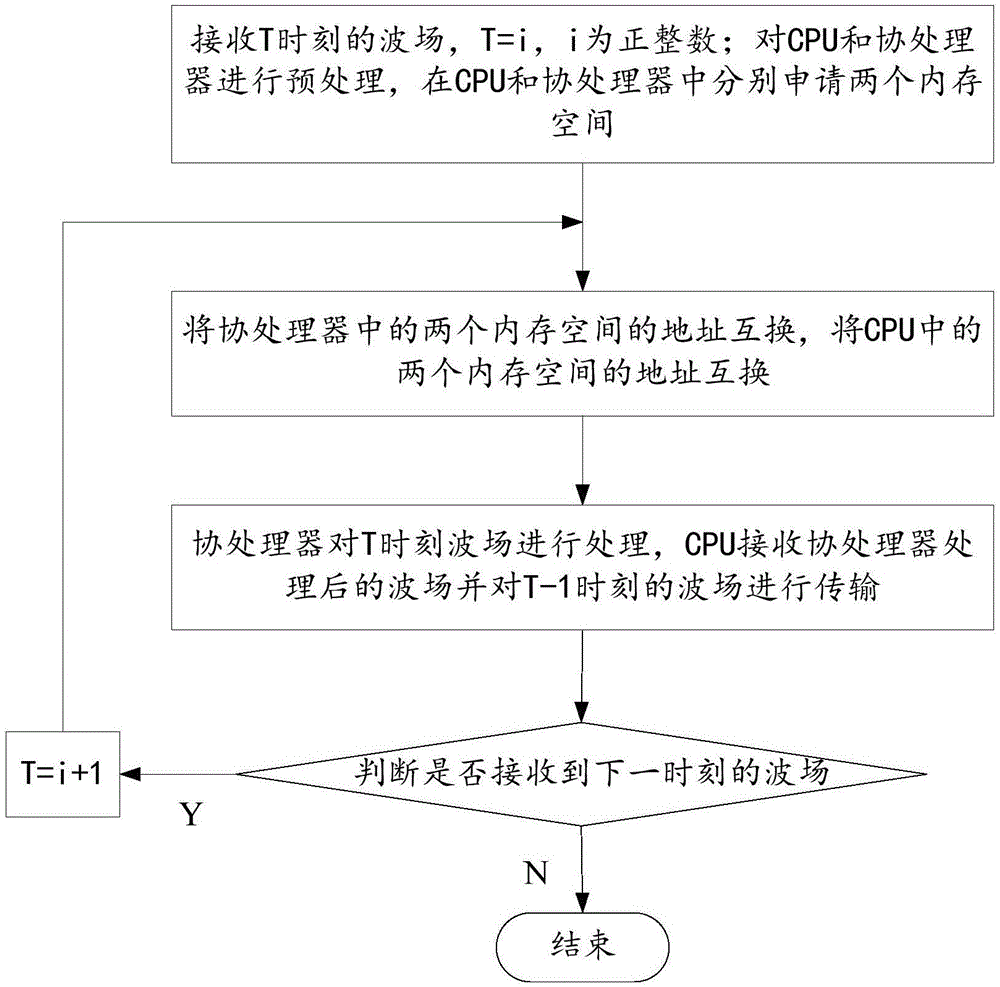
a.接收T时刻的波场,T=i,i为正整数;对CPU和协处理器进行预处理,在CPU和协处理器中分别申请两个内存空间;
b.将协处理器中的两个内存空间的地址互换,将CPU中的两个内存空间的地址互换;
c.协处理器对T时刻波场进行处理,CPU接收协处理器处理后的波场并对T-1时刻的波场进行传输;
d.判断是否接收到下一时刻的波场,如果是,协处理器对下一时刻的波场进行处理,T=i+1,i为正整数,执行步骤b;否则,结束。
本发明的有益效果是:本发明提供了高效的并行算法,其效率与常规的逆时偏移算法相比节省了40%的运行时间和机时费,是减少服务成本,提高勘探效率的有利方法。计算的结果与常规方法比较计算结果完全一样,若应用于石油勘探领域的实际资料的地震波成像,常规方法通常完成整个逆时偏移需要按月来估算,本发明可以节省大量的时间和机时费,是减少服务成本,提高勘探效率的有利方法。
在上述技术方案的基础上,本发明还可以做如下改进。
进一步,所述步骤a具体包括:
在CPU中申请两个波场内存空间:第一内存空间u1和第二内存空间u2,在协处理器中申请两个波场内存空间:第一内存空间x1和第二内存空间x2。
进一步,所述步骤c的具体过程包括:
协处理器处理T时刻的边界波场,将T-1时刻的中间波场和得到的T时刻的边界波场并分别存储;协处理器将T时刻的边界波场和T-1时刻的中间 波场分别传输到CPU中的不同内存空间,CPU开始传输T-1时刻的边界波场和T-2时刻的中间波场,并存储T-1时刻的完整波场或对T-1时刻的完整波场进行成像。
进一步,所述步骤c包括以下步骤:
协处理器处理T时刻的边界波场,并将存入第二内存空间x2的T时刻的边界波场传输到CPU中的第二内存空间u2;
CPU中第二内存空间u2接收T时刻的边界波场,并传输T-1时刻的边界波场;
协处理器将存入第一内存空间x1的T-1时刻的中间波场传输到CPU中的第一内存空间u1;
CPU中第一内存空间u1接收T-1时刻的中间波场,并传输T-2时刻的中间波场,CPU存储第二内存空间u2中的波场到磁盘缓存或进行成像;
协处理器计算T时刻的中间波场并存入第二内存空间x2,其中T=i,i为正整数。
进一步,当i=1时,CPU仅接收波场不做其他处理。
进一步,当i=2时,CPU存储第二内存空间u2中存有T-1时刻的完整波场,CPU将完整波场存到磁盘缓存或进行成像;
此时CPU中第一内存空间u1中存有T时刻的边界波场和T-1时刻的中间波场。
进一步,所述CPU中第一内存空间u1用于存储是当前时刻的边界波场和前两个时刻的中间波场,第二内存空间u2每个时刻存储的都是前一时刻的完整波场。
本发明所述的CPU与协处理器通信方法,在协处理器计算T时刻的波场的同时CPU传输T-1时刻的波场;
CPU采用两个波场内存空间:第一内存空间u1和第二内存空间u2,所 述第二内存空间u2用于接收边界波场,第一内存空间u1用于接收中间波场或者用于相关成像或波场磁盘存储的输入数据。
所述方法中协处理器与CPU的通信只有两次数据传输过程。
所述协处理器与CPU的通信采用异步方式实现,即传输仅仅是发送一个传输开始的指令,无需等待传输完毕即继续下面的协处理器的波场延拓计算。
本发明是协处理器与CPU处理器的协同并行方案,其中包含了:波场数据存储方案、CPU与协处理器并行算法设计、CPU与协处理器的数据传输方法。
本发明解决上述技术问题的技术方案如下:一种CPU与协处理器的通信系统,包括预处理模块、地址互换模块、处理传输模块和判断接收模块;
所述预处理模块用于接收T时刻的波场,T=i,i为正整数;对CPU和协处理器进行预处理,在CPU和协处理器中分别申请两个内存空间;
所述地址互换模块用于将协处理器中的两个内存空间的地址互换,将CPU中的两个内存空间的地址互换;
所述处理传输模块用于控制协处理器对T时刻波场进行处理,CPU接收协处理器处理后的波场并对T-1时刻的波场进行传输;
所述判断接收模块用于判断是否接收到下一时刻的波场,如果是,协处理器对下一时刻的波场进行处理,T=i+1,i为正整数,执行步骤b;否则,结束。
本发明的有益效果是:本发明提供了高效的并行算法,其效率与常规的逆时偏移算法相比节省了40%的运行时间和机时费,是减少服务成本,提高勘探效率的有利方法。计算的结果与常规方法比较计算结果完全一样,若应用于石油勘探领域的实际资料的地震波成像,常规方法通常完成整个逆时偏移需要按月来估算,本发明可以节省大量的时间和机时费,是减少服务成本, 提高勘探效率的有利方法。
在上述技术方案的基础上,本发明还可以做如下改进。
进一步,所述预处理模块具体的在CPU中申请两个波场内存空间:第一内存空间u1和第二内存空间u2,在协处理器中申请两个波场内存空间:第一内存空间x1和第二内存空间x2。
进一步,所述处理传输模块具体用于控制协处理器处理T时刻的边界波场,得到T时刻的边界波场和T-1时刻的中间波场并分别存储;协处理器将T时刻的边界波场和T-1时刻的中间波场分别传输到CPU中的不同内存空间,CPU开始传输T-1时刻的边界波场和T-2时刻的中间波场,并存储T-1时刻的完整波场或进行成像。
进一步,所述CPU中第一内存空间u1用于存储是当前时刻的边界波场和前两个时刻的中间波场,第二内存空间u2每个时刻存储的都是前一时刻的完整波场。
附图说明
图1为现有技术中常规逆时偏移算法流程图;
图2为本发明所述的一种CPU与协处理器的通信方法流程图;
图3为本发明所述的一种CPU与协处理器的通信系统结构框图;
图4为本发明具体实施例流程图;
图5为本发明CPU与协处理器的并行算法流程图;
图6为本发明的流程多节点并行实施方案流程图;
图7a为本发明实施例的速度模型示意图;
图7b为常规逆时偏移方法计算结果示意图;
图7c为采用本发明的计算结果示意图;
图8为本发明实施例的计算效率与常规方法对比图。
附图中,各标号所代表的部件列表如下:
1、预处理模块,2、地址互换模块,3、处理传输模块,4、判断接收模块。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图2所示,为本发明所述的一种CPU与协处理器的通信方法,具体包括以下步骤:
a.接收T时刻的波场,T=i,i为正整数;对CPU和协处理器进行预处理,在CPU和协处理器中分别申请两个内存空间;
b.将协处理器中的两个内存空间的地址互换,将CPU中的两个内存空间的地址互换;
c.协处理器对T时刻波场进行处理,CPU接收协处理器处理后的波场并对T-1时刻的波场进行传输;
d.判断是否接收到下一时刻的波场,如果是,协处理器对下一时刻的波场进行处理,T=i+1,i为正整数,执行步骤b;否则,结束。
所述步骤a具体包括:
在CPU中申请两个波场内存空间:第一内存空间u1和第二内存空间u2,在协处理器中申请两个波场内存空间:第一内存空间x1和第二内存空间x2。
所述步骤c的具体过程包括:
协处理器处理T时刻的边界波场,将T-1时刻的中间波场和得到的T时刻的边界波场并分别存储;协处理器将T时刻的边界波场和T-1时刻的中间波场分别传输到CPU中的不同内存空间,CPU开始传输T-1时刻的边界波场和T-2时刻的中间波场,并存储T-1时刻的完整波场或对T-1时刻的完整 波场进行成像。
所述步骤c包括以下步骤:
协处理器处理T时刻的边界波场,并将存入第二内存空间x2的T时刻的边界波场传输到CPU中的第二内存空间u2;
CPU中第二内存空间u2接收T时刻的边界波场,并传输T-1时刻的边界波场;
协处理器将存入第一内存空间x1的T-1时刻的中间波场传输到CPU中的第一内存空间u1;
CPU中第一内存空间u1接收T-1时刻的中间波场,并传输T-2时刻的中间波场,CPU存储第二内存空间u2中的波场到磁盘缓存或进行成像;
协处理器计算T时刻的中间波场并存入第二内存空间x2,其中T=i,i为正整数。
当i=1时,CPU仅接收波场不做其他处理。
当i=2时,CPU存储第二内存空间u2中存有T-1时刻的完整波场,CPU将完整波场存到磁盘缓存或进行成像;
此时CPU中第一内存空间u1中存有T时刻的边界波场和T-1时刻的中间波场。
所述CPU中第一内存空间u1用于存储是当前时刻的边界波场和前两个时刻的中间波场,第二内存空间u2每个时刻存储的都是前一时刻的完整波场。
如图2所示,为本发明所述的一种CPU与协处理器的通信系统,包括预处理模块1、地址互换模块2、处理传输模块3和判断接收模块4;
所述预处理模块1用于接收T时刻的波场,T=i,i为正整数;对CPU和协处理器进行预处理,在CPU和协处理器中分别申请两个内存空间;
所述地址互换模块2用于将协处理器中的两个内存空间的地址互换,将 CPU中的两个内存空间的地址互换;
所述处理传输模块3用于控制协处理器对T时刻波场进行处理,CPU接收协处理器处理后的波场并对T-1时刻的波场进行传输;
所述判断接收模块4用于判断是否接收到下一时刻的波场,如果是,协处理器对下一时刻的波场进行处理,T=i+1,i为正整数,执行步骤b;否则,结束。
所述预处理模块1具体的在CPU中申请两个波场内存空间:第一内存空间u1和第二内存空间u2,在协处理器中申请两个波场内存空间:第一内存空间x1和第二内存空间x2。
所述处理传输模块3具体用于控制协处理器处理T时刻的边界波场,得到T时刻的边界波场和T-1时刻的中间波场并分别存储;协处理器将T时刻的边界波场和T-1时刻的中间波场分别传输到CPU中的不同内存空间,CPU开始传输T-1时刻的边界波场和T-2时刻的中间波场,并存储T-1时刻的完整波场或进行成像。
所述CPU中第一内存空间u1用于存储是当前时刻的边界波场和前两个时刻的中间波场,第二内存空间u2每个时刻存储的都是前一时刻的完整波场。
本发明实施例的算法改进流程如图4所示:通过错时传输技术可以实现CPU传输与协处理器计算波场的并行化执行,即协处理器计算T时刻的波场的同时CPU处理器传输T-1时刻的波场,可以大幅度提高整体性能。本发明的创新点就是逆时偏移CPU与协处理器的并行算法设计方案。具体内容如下:
要实现CPU与协处理器的完全并行,就要降低CPU与协处理器算法中的相关性。解耦算法的设计如图5所示:每个CPU分别需要申请两个波场内存空间u1和u2,u2用于接收边界波场,u1用于接收中间波场,另外u1 亦可用于相关成像或波场磁盘存储的输入数据。图5中协处理器与CPU的通信仅仅是两次数据传输过程,其余部分完全并行,然而传输过程可以采用异步方式实现,即传输仅仅是发送一个传输开始的指令,无需等待传输完毕就可以继续下面的协处理器的波场延拓计算,这样可以实现计算与传输的完全并行。目前支持的协处理器可以支持异步传输的有GPU、MAC、FPGA等。
表1 本发明存储器分配与存储内容随时间的变化表
表1给出了采用本发明的算法流程在波场延拓到不同时刻CPU内存u1和u2中存储的内容和协处理器内存x1和x2中存储的内容,从表中可见,协处理器x1和x2沿着时间的推移波场不断增加,CPU内存中的u2每个时刻存储的都是前一时刻的完整波场,而CPU内存u1中则是当前时刻的边界波场和前两个时刻的中间波场,因此CPU内存u2的波场可以用于成像,但是CPU内存u1中的波场是不正确的波场,仅仅是为下一时刻的u2波场完整性做准备。引入CPU内存u1正是本发明的关键点,这点与常规算法仅仅申请一个CPU内存u2不同在于无需等待传输的完成就可以继续协处理器的下一步运算。
本发明引入CPU内存u1和u2两个缓存空间、并采用交替传输边界波场和中间波场的方式实现了协处理器与CPU处理器的完全并行化,可以充分利用硬件资源和提高计算效率。
本发明采用如图6的方式进行程序编制即可实现逆时偏移并行算法,图5包含了多个节点的并行计算的设计,并且采用了万兆以太网络实现传输过程。为了方便与现有技术对比,同样采用GPU作为协处理器进行试验。节 点之间的数据传输采用文献【1】中的GPU-P2P方式实现;协处理器计算函数采用2010年文献【3】(刘红伟、李博、刘洪等.地震叠前逆时偏移高阶有限差分算法及GPU实现.地球物理学报,2010,53(7):1725-1733)中描述的方法:利用运用矩阵分片的思想,借助GPU共享存储器(share memory)机制实现;节点内的CPU与GPU的并行算法采用本发明的方案执行。具体算法测试选择一个模型数据如图7a所示的速度模型,观测系统为地表宽方位采集整个网格同时接收反射地震波,网格维度为(901,901,501),网格面元(15m,15m,10m)的三维采集方式,单炮的设计为(30m,30m)的网格点加入人工震源,可以计算出单炮数为450x450=202500炮数据,总数据体为3TB。利用逆时偏移算法对其进行偏移成像,计算结果如图7b、图7c所示。常规方法的计算结果与本发明的计算结果完全一致,证明本发明的并行算法满足计算精度。另外,计算效率的对比如图8所示,其中以常规算法的计算时间为基准分别统计了协处理器的计算时间、CPU与协处理器的通信时间、磁盘数据IO时间等。本实施例的常规方法运行时间为249小时约10.2天,利用本发明的并行方案花费149小时约6.25天。图8中亦可见本发明的并行方案基本消除了通信时间所占比重,提高整体效率达到40%左右。因为本发明的实施例仅使用了人工模型数据测试,规模较小。若应用于石油勘探领域的实际资料的地震波成像,常规方法通常完成整个逆时偏移需要按月来估算,本发明可以节省大量的时间和机时费,是减少服务成本,提高勘探效率的有利方法。
逆时偏移算法是精度最高的反射波成像算法,可以应用于石油勘探、煤气田开发、矿产资源的探测等资源领域。近年来逆时偏移算法成为广泛采用的成像手段,并且利用GPU、MAC、FPGA等高速的协处理器进行提高计算效率缩短周期。研究重点往往集中在如何提高协处理器的计算效率,而忽视了协处理器与CPU的并行处理方案。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!