一种Hadoop分布式文件系统的存储方法及装置与流程
本发明涉及数据处理控制技术领域,尤其涉及一种Hadoop分布式文件系统的存储方法及装置。
背景技术:
Hadoop具有可扩展、可伸缩、可容错等特性,近年来得到广泛应用。如何高效可靠合理地存储海量数据特别重要。HDFS(Hadoop Distributed File System)是Hadoop的分布式文件系统,HDFS云存储系统作为Hadoop的核心子项目,负责数据的存储与管理,成为云存储研究热点之一。
HDFS采用主从结构模型,HDFS集群由一个元数据节点和若干个数据节点组成。其中:元数据节点作为主服务器,管理文件系统的命名空间和客户端对文件的访问。数据节点管理存储的数据,负责处理文件系统客户端的文件读写请求,并在元数据节点的统一调度下进行数据块的创建、删除和复制工作。
HDFS采用心跳机制对数据节点的健康状况进行检测,如发现问题采取数据备份的方式来保证数据的安全性。数据节点周期性向元数据节点汇报状态信息,包括比特容量(capacityBytes)、剩余比特容量(remainingBytes)、最新更新时间(lastUpdate)等信息。
但是现有的HDFS仍存在不足,主要体现在:
(1)提供心跳机制来检测数据节点是否出现故障,但未对收集的信息进行可靠性分析。
(2)数据节点状态信息不能完全表现数据节点的状态,元数据节点在进行负载均衡和数据存储策略时考虑的因素有限,可能导致负载不均。
技术实现要素:
本发明实施例的目的在于提供一种Hadoop分布式文件系统的存储方法及 装置,可以采集更多的节点状态信息,获得健康性评估值,同时增加了可靠性评价机制,为数据存储提供更好的可靠性保证,采用简单易行的基于多因素的存储选择策略及选择算法,提高了数据节点的选择效率,带来更好的用户体验。
本发明实施例提供一种Hadoop分布式文件系统的存储方法,包括:
元数据节点接收数据节点反馈的节点状态信息,根据各个数据节点的节点状态信息计算数据节点的健康状态,获得各个数据节点的健康性评估值;
根据宕机次数以及每次宕机恢复后的存活时间,计算各个数据节点的可靠性,获得各个数据节点的可靠性评估值,其中数据节点的可靠性评估值随宕机次数的增加而降低,且随所述存活时间的增加而增加;
按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以及,根据预设存储策略选择出第三预设数量的第三组数据节点;
根据第一组数据节点、第二组数据节点以及第三组数据节点,筛选出用于当前数据存储的N个目标数据节点,其中,所述N个目标数据节点是根据数据节点在第一组数据节点、第二组数据节点以及第三组数据节点中出现次数的高低排序,选择出的前N个数据节点。
其中,所述根据各个数据节点的节点状态信息计算数据节点的健康状态,获得各个数据节点的健康性评估值,包括:
针对每个数据节点,计算该数据节点的节点状态信息与对应权值的乘积的和值,得到该数据节点的健康性评估值。
其中,所述各个数据节点的节点状态信息至少包括以下信息中的两种:磁盘容量、磁盘剩余量、磁盘IO性能、内存大小、空闲内存、CPU空闲率、网络性能以及空闲带宽。
其中,所述根据宕机次数以及每次宕机恢复后的存活时间,计算各个数据节点的可靠性,包括:
根据数据节点每次宕机恢复后的存活时间,数据节点初次加入系统的时间,系统当前时间SystemTime以及第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,根据以下公式计算出各个数据节点i的可靠性:
其中:k(i)表示第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,j表示第j次宕机事件,AliveTime(j)表示数据节点第j次宕机恢复后的存活时间,EnterTime(i)表示第i个数据节点初次加入系统的时间,A表示存活时间的权重,(1—A)表示宕机次数的权重。
其中,所述根据第一组数据节点、第二组数据节点以及第三组数据节点,筛选出用于当前数据存储的N个目标数据节点,包括:
计算第一组数据节点、第二组数据节点和第三组数据节点的交集得到第一交集结果,当所述第一交集结果中的数据节点的个数大于等于预设值N时,选择N个数据节点作为所述目标数据节点进行数据存储;
当所述第一交集结果中的数据节点的个数小于N时,计算第一组数据节点与第二组数据节点的交集得到第二交集结果,计算所述第一交集结果与所述第二交集结果的并集,得到第一并集结果,当所述第一并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
当所述第一并集结果中的数据节点的个数小于N时,计算第一组数据节点与第三组数据节点的交集得到第三交集结果;计算所述第一并集结果和所述第三交集结果的并集得到第二并集结果,当所述第二并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
当所述第二并集结果中的数据节点的个数小于N时,计算第二组数据节点与第三组数据节点的交集得到第四交集结果;计算所述第二并集结果与所述第四交集结果的并集得到第三并集结果,当所述第三并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
当所述第三并集结果中的数据节点的个数小于N时,则在增加所述第一预设数量、第二预设数量、第三预设数量后,返回所述按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以 及,根据预设存储策略选择出第三预设数量的第三组数据节点的步骤。
本发明实施例提供一种Hadoop分布式文件系统的存储装置,包括:
处理模块,用于接收数据节点反馈的节点状态信息,根据各个数据节点的节点状态信息计算数据节点的健康状态,获得各个数据节点的健康性评估值;
计算模块,用于根据宕机次数以及每次宕机恢复后的存活时间,计算各个数据节点的可靠性,获得各个数据节点的可靠性评估值,其中数据节点的可靠性评估值随宕机次数的增加而降低,且随所述存活时间的增加而增加;
第一选择模块,用于按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以及,根据预设存储策略选择出第三预设数量的第三组数据节点;
第二选择模块,用于根据第一组数据节点、第二组数据节点以及第三组数据节点,筛选出用于当前数据存储的N个目标数据节点,其中,所述N个目标数据节点是根据数据节点在第一组数据节点、第二组数据节点以及第三组数据节点中出现次数的高低排序,选择出的前N个数据节点。
其中,所述处理模块进一步用于
针对每个数据节点,计算该数据节点的节点状态信息与对应权值的乘积的和值,得到该数据节点的健康性评估值。
其中,所述处理模块中各个数据节点的节点状态信息至少包括以下信息中的两种:磁盘容量、磁盘剩余量、磁盘IO性能、内存大小、空闲内存、CPU空闲率、网络性能以及空闲带宽。
其中,所述计算模块进一步用于
根据数据节点每次宕机恢复后的存活时间,数据节点初次加入系统的时间,系统当前时间SystemTime以及第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,根据以下公式计算出各个数据节点i的可靠性:
其中:k(i)表示第i个数据节点从最初加入系统至当前时间共发生的宕机 事件次数,j表示第j次宕机事件,AliveTime(j)表示数据节点第j次宕机恢复后的存活时间,EnterTime(i)表示第i个数据节点初次加入系统的时间,A表示存活时间的权重,(1—A)表示宕机次数的权重。
其中,所述第二选择模块包括:
第一子单元,用于计算第一组数据节点、第二组数据节点和第三组数据节点的交集得到第一交集结果,当所述第一交集结果中的数据节点的个数大于等于预设值N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第二子单元,用于当所述第一交集结果中的数据节点的个数小于N时,计算第一组数据节点与第二组数据节点的交集得到第二交集结果,计算所述第一交集结果与所述第二交集结果的并集,得到第一并集结果,当所述第一并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第三子单元,用于当所述第一并集结果中的数据节点的个数小于N时,计算第一组数据节点与第三组数据节点的交集得到第三交集结果;计算所述第一并集结果和所述第三交集结果的并集得到第二并集结果,当所述第二并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第四子单元,用于当所述第二并集结果中的数据节点的个数小于N时,计算第二组数据节点与第三组数据节点的交集得到第四交集结果;计算所述第二并集结果与所述第四交集结果的并集得到第三并集结果,当所述第三并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第五子单元,用于当所述第三并集结果中的数据节点的个数小于N时,则在增加所述第一预设数量、第二预设数量、第三预设数量后,触发所述第一选择模块按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以及,根据预设存储策略选择出第三预设数量的第三组数据节点。
本发明实施例的有益效果是:通过采集更多的节点状态信息,计算得到健 康性评估值,提高数据存储效率;同时增加了可靠性评价机制,对数据节点的可靠性实时进行评估,为数据存储提供更好的可靠性保证。采用简单易行的基于多因素的存储选择策略及选择算法,提高了数据节点的选择效率,带来更好的用户体验。
附图说明
图1表示本发明实施例Hadoop分布式文件系统的存储方法步骤示意图一;
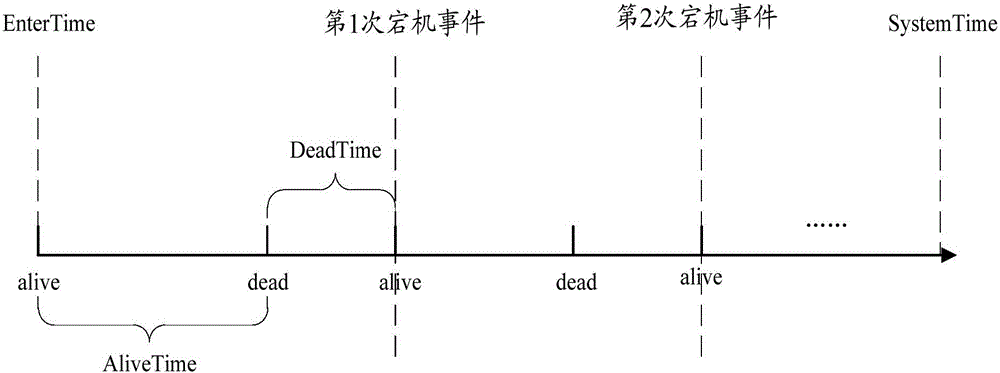
图2表示本发明实施例Hadoop分布式文件系统的存储方法中数据节点的宕机示意图;
图3表示本发明实施例Hadoop分布式文件系统的存储方法步骤示意图二;
图4表示本发明实施例Hadoop分布式文件系统的存储方法整体流程示意图;
图5表示本发明实施例Hadoop分布式文件系统的存储装置示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图及具体实施例对本发明进行详细描述。
本发明实施例提供一种Hadoop分布式文件系统的存储方法,如图1所示,包括:
步骤S100、元数据节点接收数据节点反馈的节点状态信息,根据各个数据节点的节点状态信息计算数据节点的健康状态,获得各个数据节点的健康性评估值;
步骤S200、根据宕机次数以及每次宕机恢复后的存活时间,计算各个数据节点的可靠性,获得各个数据节点的可靠性评估值,其中数据节点的可靠性评估值随宕机次数的增加而降低,且随所述存活时间的增加而增加;
步骤S300、按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以及,根据预设存储策略选择出第三预设数量的第三组数据节点;
步骤S400、根据第一组数据节点、第二组数据节点以及第三组数据节点,筛选出用于当前数据存储的N个目标数据节点,其中,所述N个目标数据节点是根据数据节点在第一组数据节点、第二组数据节点以及第三组数据节点中出现次数的高低排序,选择出的前N个数据节点。
本发明实施例采用简单易行的基于多因素的存储选择策略及选择算法,提高了数据节点的选择效率,带来更好的用户体验。
具体的,接收数据节点反馈的节点状态信息,依据各个数据节点的节点状态信息计算各个数据节点的健康性评估值。依据健康性评估值的高低顺序对各个数据节点进行排序,获得排序后的各个数据节点。然后在经过排序后的各个数据节点里选择靠前的第一预设数量的数据节点,作为第一组数据节点。数据节点将节点状态信息通过心跳协议发送给元数据节点,元数据节点获得数据节点的健康状态,在进行数据节点的选择时考虑数据节点的健康状态因素,较现有HDFS存储方法,本方法可以提高存储效率。
获取各个数据节点的宕机次数以及每次宕机恢复后的存活时间,依据可靠性评价机制,计算得到各个数据节点的可靠性评估值,依据可靠性评估值的高低顺序对各个数据节点进行排序,获得排序后的各个数据节点。然后在经过排序后的各个数据节点里选择靠前的第二预设数量的数据节点,作为第二组数据节点。需要说明的是,数据节点的可靠性评估值随宕机次数的增加而降低,且随存活时间的增加而增加,这里是指当存活时间不变,宕机次数增加时,数据节点的可靠性评估值会降低;当宕机次数不变,存活时间增加时,数据节点的可靠性评估值会增加。
根据预设的存储策略选择出第三组数据节点。然后根据获得的第一组数据节点、第二组数据节点和第三组数据节点选择出用于当前数据存储的目标数据节点。
需要说明的是,预设存储策略是用户预先设定的存储策略,例如,该策略可以是基于各个数据节点的剩余容量参数,选择出剩余容量满足存储需求的数据节点,具体的,可以按照剩余容量的大小顺序,从剩余容量满足存储需求的数据节点中,选择剩余容量较大的数据节点,或者是从剩余容量满足存储需求的数据节点中,随机选择数据节点。也可以是基于各个数据节点的内存参数, 选择出内存满足存储需求的数据节点,具体的,可以按照内存的大小顺序,从内存满足存储需求的数据节点中,选择内存较大的数据节点,或者是从内存满足存储需求的数据节点中,随机选择数据节点。除了上述举例的策略外,还可以按照采用现有技术的各种存储策略,作为预设策略,本发明对此不作具体限定。
需要说明的是,第一组数据节点、第二组数据节点和第三组数据节点的选取,并无严格的时间上的限制。可以先获取第一组数据节点,也可以先获取第二组数据节点或第三组数据节点。且第一预设数量、第二预设数量和第三预设数量可以根据需求自行设定,并不要求第一预设数量、第二预设数量和第三预设数量相等。
元数据节点收集数据节点的状态信息,对数据节点的健康状态进行评价;引入可靠性评价机制对数据节点的稳定性、可靠性进行评价;得到数据节点的健康性评估值和可靠性评估值,然后对各个数据节点进行排序和选择。综合预设的存储策略选择出用于当前数据存储的目标数据节点。
元数据节点在接收数据节点反馈的节点状态信息之前,需要进行初始化,具体包括:初始化远程过程调用协议通信功能,创建远程过程调用协议服务进程,同时加载元数据信息至内存,初始化元数据节点协议(NameNodeProtocol),创建元数据节点之间的通信。然后等待数据节点的注册和通信,接收数据节点返回的节点状态信息。
数据节点向元数据节点反馈节点状态信息之前,需要进行初始化操作,包括:初始化远程过程调用协议通信功能,为客户端和其它数据节点提供服务;同时启动数据传输功能,进行客户端和数据节点之间的数据传输;启动数据存储功能,负责存储,保存数据信息。创建状态监听进程,实时收集节点状态信息,然后通过心跳协议周期性发送给元数据节点。
在本发明上述实施例中,步骤S100中,根据各个数据节点的节点状态信息计算数据节点的健康状态,获得各个数据节点的健康性评估值,包括:
针对每个数据节点,计算该数据节点的节点状态信息与对应权值的乘积的和值,得到该数据节点的健康性评估值。
本发明对数据节点的节点状态信息进行了扩展与优化,以便于元数据节点 更好地了解数据节点的状态,更好地实现存储调度。各个数据节点的节点状态信息至少包括以下信息中的两种:S1:磁盘容量、S2:磁盘剩余量、S3:磁盘IO性能、S4:内存大小、S5:空闲内存、S6:CPU空闲率、S7:网络性能以及S8:空闲带宽。
具体的,根据需要,配置节点状态信息S1、S2、…、S8状态的权重W1、W2、…、W8,满足公式1:
若Wj=0(j=1、2、…、8),表示不考虑Sj状态。
采用公式2,计算数据节点的健康状态:
Note_Health(i)表示第i个DataNode的健康性评估值,该值越大,则表示数据节点状态越好。
在本发明上述实施例中,步骤S200中根据宕机次数以及每次宕机恢复后的存活时间,计算各个数据节点的可靠性,包括:
根据数据节点每次宕机恢复后的存活时间,数据节点初次加入系统的时间,系统当前时间SystemTime以及第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,根据以下公式计算出各个数据节点i的可靠性:
其中:k(i)表示第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,j表示第j次宕机事件,AliveTime(j)表示数据节点第j次宕机恢复后的存活时间,EnterTime(i)表示第i个数据节点初次加入系统的时间,A表示存活时间的权重,(1—A)表示宕机次数的权重。
具体的,基于HDFS心跳机制对数据节点可靠性进行统计分析,数据节点刚接入系统时处于激活状态(alive),元数据节点在一定时间段内收不到某数据节点发送的心跳信息,就将其标记为失效(dead),直到重新检测到该数据节点 的心跳信息为止,如图2所示,数据节点的alive-dead-alive过程为一次宕机事件。
在一次宕机事件过程中,用AliveTime表示数据节点存活时间,DeadTime表示数据节点失效时间,EnterTime表示数据节点初次加入系统的时间,SystemTime表示系统当前时间。根据各数据节点心跳信息的历史数据进行统计分析,按照公式3计算出各数据节点i的可靠性评估值,用Node_Relability表示。
(公式3)
其中:k(i)表示第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,j表示第j次宕机事件,AliveTime(j)表示数据节点第j次宕机恢复后的存活时间,EnterTime(i)表示第i个数据节点初次加入系统的时间,A表示存活时间的权重,(1-A)表示宕机次数的权重。具体的,数据节点的可靠性由两部分决定,第一部分为基于存活时间变化的第一参数,随存活时间的增大而增大,第一参数的权重为A;第二部分为基于宕机次数变化的第二参数,随着宕机次数的增大而减小,第二参数的权重为(1—A)。第一参数为:
第二参数为:
第一参数中包含第j次宕机事件的影响因子:
其中在第一参数里引入第j次宕机事件的影响因子,j越大,影响因子值越大,以体现宕机事件影响随时间衰减特性。
在本发明上述实施例中,如图3所示,步骤S400包括:
步骤S401、计算第一组数据节点、第二组数据节点和第三组数据节点的交集得到第一交集结果,当所述第一交集结果中的数据节点的个数大于等于预 设值N时,选择N个数据节点作为所述目标数据节点进行数据存储;
步骤S402、当所述第一交集结果中的数据节点的个数小于N时,计算第一组数据节点与第二组数据节点的交集得到第二交集结果,计算所述第一交集结果与所述第二交集结果的并集,得到第一并集结果,当所述第一并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
步骤S403、当所述第一并集结果中的数据节点的个数小于N时,计算第一组数据节点与第三组数据节点的交集得到第三交集结果;计算所述第一并集结果和所述第三交集结果的并集得到第二并集结果,当所述第二并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
步骤S404、当所述第二并集结果中的数据节点的个数小于N时,计算第二组数据节点与第三组数据节点的交集得到第四交集结果;计算所述第二并集结果与所述第四交集结果的并集得到第三并集结果,当所述第三并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
步骤S405、当所述第三并集结果中的数据节点的个数小于N时,则在增加所述第一预设数量、第二预设数量、第三预设数量后,返回步骤S300。
具体的,计算第一组数据节点、第二组数据节点和第三组数据节点的交集得到第一交集结果,其中第一组数据节点、第二组数据节点和第三组数据节点中数据节点的数量均可以大于等于N个,对第一交集结果中的数据节点的个数进行判断,当判断结果为:第一交集结果中的数据节点的个数大于等于预设值N时,则在第一交集结果中选择N个数据节点作为目标数据节点进行数据存储,流程结束。
当第一交集结果中的数据节点的个数小于预设值N时,则需要计算第一组数据节点与第二组数据节点的交集得到第二交集结果,然后计算第一交集结果与第二交集结果的并集,得到第一并集结果,判断第一并集结果中的数据节点的个数是否大于等于N,当判断结果为第一并集结果中的数据节点的个数大于等于N时,则需要在第一并集结果中选择N个数据节点作为目标数据节点 进行数据存储,流程结束。
当判断结果为第一并集结果中的数据节点的个数小于N时,计算第一组数据节点与第三组数据节点的交集得到第三交集结果;计算第一并集结果和第三交集结果的并集得到第二并集结果,判断第二并集结果中的数据节点的个数是否大于等于N,当判断结果为第二并集结果中的数据节点的个数大于等于N时,在第二并集结果中选择N个数据节点作为目标数据节点进行数据存储,流程结束。
当判断结果为第二并集结果中的数据节点的个数小于N时,计算第二组数据节点与第三组数据节点的交集得到第四交集结果;计算第二并集结果与第四交集结果的并集得到第三并集结果,判断第三并集结果中的数据节点的个数是否大于等于N,当判断结果为第三并集结果中的数据节点的个数大于等于N时,在第三并集结果中选择N个数据节点作为目标数据节点进行数据存储,流程结束。
当判断结果为第三并集结果中的数据节点的个数小于N时,则需要增加第一预设数量、第二预设数量、第三预设数量,然后返回按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以及,根据预设存储策略选择出第三预设数量的第三组数据节点的步骤。需要说明的是,当第一交集结果中的数据节点的个数小于预设值N,需要继续计算时,可以先选择第一组数据节点和第三数据节点的交集,也可以先选择第二组数据节点和第三组数据节点的交集。此过程可根据实际情况来处理,本实施例先选择第一组数据节点和第二数据节点的交集仅为其中的一种处理方式。
如图4所示,为本发明实施例的整体流程图:
步骤S101、计算各个数据节点的健康性评估值,按照优劣顺序,选择出排序靠前的第一预设数量的第一组数据节点。
步骤S102、计算各个数据节点的可靠性评估值,按照优劣顺序,选择出排序靠前的第二预设数量的第二组数据节点。
步骤S103、根据预设存储策略选择出第三预设数量的第三组数据节点。
步骤S104、计算第一组数据节点、第二组数据节点和第三组数据节点的 交集,得到第一交集结果,判断第一交集结果中数据节点的个数是否大于等于N,当判断结果大于等于N时,执行步骤S108,否则执行步骤S105。
步骤S105、计算第一组数据节点、第二组数据节点的交集,得到第二交集结果,计算第二交集结果和第一交集结果的并集,得到第一并集结果,判断第一并集结果中数据节点的个数是否大于等于N,当判断结果大于等于N时,执行步骤S108,否则执行步骤S106。
步骤S106、计算第一组数据节点、第三组数据节点的交集,得到第三交集结果,计算第三交集结果和第一并集结果的并集,得到第二并集结果,判断第二并集结果中数据节点的个数是否大于等于N,当判断结果大于等于N时,执行步骤S108,否则执行步骤S107。
步骤S107、计算第二组数据节点、第三组数据节点的交集,得到第四交集结果,计算第四交集结果和第二并集结果的并集,得到第三并集结果,判断第三并集结果中数据节点的个数是否大于等于N,当判断结果大于等于N时,执行步骤S108,否则执行步骤S109。
步骤S108、选出N个目标数据节点,执行步骤S111。
步骤S109、增加第一预设数量、第二预设数量和第三预设数量,执行步骤S110。
步骤S110、选择第一预设数量的第一组数据节点、第二预设数量的第二组数据节点以及第三预设数量的第三组数据节点,继续执行步骤S104。
步骤S111、结束流程。
本实施例的描述方式仅为处理过程中一种处理方式,本发明所提供的方法并不局限于本实施例描述的处理流程,本领域人员在具体实施过程中可选用不同的处理方式。
本发明实施例提供一种Hadoop分布式文件系统的存储装置,如图5所示,包括:
处理模块10,用于接收数据节点反馈的节点状态信息,根据各个数据节点的节点状态信息计算数据节点的健康状态,获得各个数据节点的健康性评估值;
计算模块20,用于根据宕机次数以及每次宕机恢复后的存活时间,计算 各个数据节点的可靠性,获得各个数据节点的可靠性评估值,其中数据节点的可靠性评估值随宕机次数的增加而降低,且随所述存活时间的增加而增加;
第一选择模块30,用于按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以及,根据预设存储策略选择出第三预设数量的第三组数据节点;
第二选择模块40,用于根据第一组数据节点、第二组数据节点以及第三组数据节点,筛选出用于当前数据存储的N个目标数据节点,其中,所述N个目标数据节点是根据数据节点在第一组数据节点、第二组数据节点以及第三组数据节点中出现次数的高低排序,选择出的前N个数据节点。
在本发明上述实施例中,所述处理模块10进一步用于
针对每个数据节点,计算该数据节点的节点状态信息与对应权值的乘积的和值,得到该数据节点的健康性评估值。
在本发明上述实施例中,所述处理模块10中各个数据节点的节点状态信息至少包括以下信息中的两种:磁盘容量、磁盘剩余量、磁盘IO性能、内存大小、空闲内存、CPU空闲率、网络性能以及空闲带宽。
在本发明上述实施例中,所述计算模块20进一步用于
根据数据节点每次宕机恢复后的存活时间,数据节点初次加入系统的时间,系统当前时间SystemTime以及第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,根据以下公式计算出各个数据节点i的可靠性:
其中:k(i)表示第i个数据节点从最初加入系统至当前时间共发生的宕机事件次数,j表示第j次宕机事件,AliveTime(j)表示数据节点第j次宕机恢复后的存活时间,EnterTime(i)表示第i个数据节点初次加入系统的时间,A表示存活时间的权重,(1—A)表示宕机次数的权重。
在本发明上述实施例中,所述第二选择模块40包括:
第一子单元41,用于计算第一组数据节点、第二组数据节点和第三组数 据节点的交集得到第一交集结果,当所述第一交集结果中的数据节点的个数大于等于预设值N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第二子单元42,用于当所述第一交集结果中的数据节点的个数小于N时,计算第一组数据节点与第二组数据节点的交集得到第二交集结果,计算所述第一交集结果与所述第二交集结果的并集,得到第一并集结果,当所述第一并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第三子单元43,用于当所述第一并集结果中的数据节点的个数小于N时,计算第一组数据节点与第三组数据节点的交集得到第三交集结果;计算所述第一并集结果和所述第三交集结果的并集得到第二并集结果,当所述第二并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第四子单元44,用于当所述第二并集结果中的数据节点的个数小于N时,计算第二组数据节点与第三组数据节点的交集得到第四交集结果;计算所述第二并集结果与所述第四交集结果的并集得到第三并集结果,当所述第三并集结果中的数据节点的个数大于等于N时,选择N个数据节点作为所述目标数据节点进行数据存储;
第五子单元45,用于当所述第三并集结果中的数据节点的个数小于N时,则在增加所述第一预设数量、第二预设数量、第三预设数量后,触发所述第一选择模块按照健康性评估值的优劣的先后顺序,选择出排序靠前的第一预设数量的第一组数据节点;按照可靠性评估值的高低顺序,选择出排序靠前的第二预设数量的第二组数据节点;以及,根据预设存储策略选择出第三预设数量的第三组数据节点。
本发明实施例一种Hadoop分布式文件系统的存储方法,通过采集更多的节点状态信息,计算得到健康性评估值,提高数据存储效率;同时增加了可靠性评价机制,对数据节点的可靠性实时进行评估,为数据存储提供更好的可靠性保证。采用简单易行的基于多因素的存储选择策略及选择算法,提高了数据节点的选择效率,带来更好的用户体验。
需要说明的是,本发明提供的Hadoop分布式文件系统的存储装置是应用 上述方法的装置,则上述方法的所有实施例均适用于该装置,且均能达到相同或相似的有益效果。
以上所述的是本发明的优选实施方式,应当指出对于本技术领域的普通人员来说,在不脱离本发明所述的原理前提下还可以作出若干改进和润饰,这些改进和润饰也在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!