一种基于用户历史行为的商品信息推荐方法及系统与流程
本发明涉及电子商务领域中的商品信息推荐方法及系统,具体来说,涉及一种基于用户历史行为的商品信息推荐方法及系统。
背景技术:
利用电子商务用户行为进行商品推荐的方法有:基于用户行为的排行榜(例如销售排行榜),基于相同行为的推荐(例如大家同时看了A商品,还看了什么商品),基于相同主题的推荐(例如儿童手机推荐),基于用户反馈的推荐(例如大家都喜欢的商品)等。通过提问,顾客回答问题,直接了解顾客的喜好,推荐合适的商品。此外还有关联规则等式的商品推荐方法。
上述方法没有深入挖掘用户行为和用户行为对用户价值的影响,上述方法直接简单利用用户行为直接进行推荐或者直接挖掘用户行为的关联关系进行推荐,没有挖掘用户的个性化的信息,推荐方式缺乏个性化,推荐效果不佳。
另外,现有用户购买概率的预测主要方法有:使用用户的购买行为预测购买概率;使用用户的忠诚度等信息预测用户购买概率。这些方法都是针对用户或者用户对品类的购买概率预测,不能预测未购买的商品或者单品的购买概率。
技术实现要素:
技术问题:本发明所要解决的技术问题是:提供一种基于用户历史行为的商品信息推荐方法及系统,该方法和系统基于用户历史行为数据,精准分析用户的行为数据,为用户提供个性化的商品推荐列表,且商品推荐更加精准。
技术方案:为了解决上述问题,本发明实施例采用以下的技术方案:
第一方面,本实施例提供一种基于用户历史行为的商品信息推荐方法,该方法包括以下步骤:
S11采集用户在电子商务网站历史行为数据,历史行为数据包括用户信息和商品信息;
S12根据历史行为数据,建立用户商品概率预测特征向量;
S13根据用户商品概率预测特征向量,训练模型,得到用户推荐商品预测模型;
S14将待预测的用户数据输入用户推荐商品预测模型中,测算行为商品的预测购买概率;
S15根据行为商品的预测购买概率,计算关联商品的预测购买概率,合并行为商品和关联商品,得到商品推荐列表。
结合第一方面,作为第一种可能实现的方式,所述的S11中,历史行为数据来源于PC端、WAP端、APP端、线下数据;用户信息包括用户的标识ID、用户的性别、年龄、访问偏好;商品信息包括商品的标识编码、商品流量特征、商品行为特征和商品决策成本。
结合第一方面,作为第二种可能实现的方式,所述的S12中,建立用户商品概率预测特征向量具体包括:
S201进行数据清洗:将异常数据和不符合用户浏览习惯的数据,进行清洗;
S202进行特征处理,得到用户特征值:将清洗后的各终端用户历史行为特征,按天统计,分别构造用户历史行为特征统计函数,对统计天数划分为M个区间段,对每个区间段按照时间衰减函数,测算区间段的特征值,累加各区间段的特征值,得到用户特征值:
S203建立用户商品概率预测特征向量:用户商品概率预测特征向量的表示形式为:各终端的指纹ID+商品ID+用户特征向量值;其中,指纹ID表示用户的标识ID,商品ID表示商品的标识编码。
结合第一方面,作为第三种可能实现的方式,所述的S15具体包括:
S301确定关联商品:根据用户历史行为数据中的访问历史数据和购买历史数据,采用关联规则或者协同过滤算法,计算该行为商品的关联商品的关联度,取关联度最高的前b个商品,作为该行为商品的关联商品集合;
S302根据式(1)计算关联商品的购买概率:
Score_i=Master_Pos*SKU_Score_i/max(SKU_Score_i)式(1)
其中,Score_i表示关联商品的购买概率;Master_Pos表示行为商品购买概率;max(SKU_Score_i)表示关联商品集合中关联度最高 值,SKU_Score_i表示关联商品SKU_i与行为商品的关联度;
S303合并行为商品和关联商品,生成商品推荐列表:若行为商品在步骤S301得到的关联商品集合中,则按照行为商品和关联商品的预测购买概率大小排序,得到商品推荐列表;若行为商品不在步骤S301得到的关联商品集合中,且行为商品的预测购买概率小于概率阈值,则将行为商品预测购买概率乘以惩罚系数作为该行为商品最终的预测购买概率;将关联商品和行为商品按照商品预测购买概率大小排序,得到商品推荐列表。
结合第一方面,作为第四种可能实现的方式,所述的基于用户历史行为的商品信息推荐方法,还包括步骤S16:对S15得到的商品推荐列表,进行过滤和输出逻辑处理,生成最终的商品推荐列表。
结合第一方面的第四种可能实现的方式,作为第五种可能实现的方式,所述的步骤S16具体包括:取用户最近H天之内的订单商品,将订单商品所属商品组作为用户过滤商品组,过滤S16得到的商品推荐列表中属于过滤商品组的商品;根据商品预测购买概率,将过滤后的商品推荐列表中的商品重新进行排序,生成最终的商品推荐列表。
第二方面,本实施例提供一种基于用户历史行为的商品信息推荐系统,该系统包括:
采集模块:用于采集用户在电子商务网站历史行为数据;
特征向量建立模块:用于根据采集模块采集历史行为数据,建立用户商品概率预测特征向量;
模型建立模块;用于根据特征向量建立模块建立的用户商品概率 预测特征向量,训练模型,得到用户推荐商品预测模型;
测算模块:用于将数据输入用户推荐商品预测模型中,测算行为商品的预测购买概率;
第一生成模块:用于根据测算模块测算的行为商品的预测购买概率,计算关联商品的预测购买概率,合并行为商品和关联商品,得到商品推荐列表。
结合第二方面,作为第一种可能实现的方式,所述的采集模块采集的历史行为数据来源于PC端、WAP端、APP端、线下数据。
结合第二方面,作为第二种可能实现的方式,所述的特征向量建立模块包括:
清洗子模块:用于将异常数据和不符合用户浏览习惯的数据,进行清洗;
测算子模块:用于将清洗后的各终端用户历史行为特征,按天统计,分别构造用户历史行为特征统计函数,对统计天数划分为M个区间段,对每个区间段按照时间衰减函数,测算区间段的特征值,累加各区间段的特征值,得到用户特征值:
建立子模块:用于建立用户商品概率预测特征向量,用户商品概率预测特征向量的表示形式为:各终端的指纹ID+用户ID+商品ID+用户特征值;其中,指纹ID表示用户的标识ID,用户ID表示用户的指纹标识,商品ID表示商品的标识编码。
结合第二方面,作为第三种可能实现的方式,所述的第一生成模块包括:
确定子模块:用于根据用户历史行为数据中的访问历史数据和购买历史数据,采用关联规则或者协同过滤算法,计算该行为商品的关联商品的关联度,取关联度最高的前b个商品,作为该行为商品的关联商品集合;
计算子模块:用于计算关联商品的购买概率;
第一生成子模块:用于合并行为商品和关联商品,生成商品推荐列表:若行为商品在确定子模块建立的关联商品集合中,则按照行为商品和关联商品的预测购买概率大小排序,得到商品推荐列表;若行为商品不在确定子模块建立的关联商品集合中,且行为商品的预测购买概率小于概率阈值,则将行为商品预测购买概率乘以惩罚系数作为该行为商品最终的预测购买概率;将关联商品和行为商品按照商品预测购买概率大小排序,得到商品推荐列表。
结合第二方面,作为第四种可能实现的方式,所述的基于用户历史行为的商品信息推荐系统,还包括第二生成模块:用于对第一生成模块得到的商品推荐列表,进行过滤和输出逻辑处理,生成最终的商品推荐列表。
结合第二方面第四种可能实现的方式,作为第五种可能实现的方式,所述的第二生成模块包括:
过滤商品组建立子模块:用于取用户最近H天之内的订单商品,将订单商品所属商品组作为用户过滤商品组;
过滤子模块:用于过滤第一生成模块生成的商品推荐列表中属于过滤商品组的商品;
第二生成子模块:根据商品预测购买概率,将过滤子模块过滤后的商品推荐列表中的商品重新进行排序,生成最终的商品推荐列表。
有益效果:与现有技术相比,本发明实施例提供的基于用户历史行为的商品信息推荐方法及系统,能够为用户提供个性化的商品推荐,且推荐更加精准,符合用户需求。本实施例的基于用户历史行为的商品信息推荐方法基于用户的历史行为数据进行分析,构建用户推荐商品预测模型,并且将与行为商品相关的关联商品也纳入推荐商品列表中,综合比较行为商品和关联商品的购买概率后,生成商品推荐列表。
附图说明
图1是本发明推荐方法的实施例的流程框图。
图2是本发明推荐方法的实施例中步骤S13的流程框图。
图3是本发明推荐方法的实施例中步骤S16的流程框图。
图4是本发明推荐方法的另一实施例的流程框图。
图5是本发明推荐系统的实施例的结构框图。
图6是本发明推荐系统实施例中特征向量建立模块的结构框图。
图7是本发明推荐系统实施例中第一生成模块的结构框图。
图8是本发明推荐系统的另一实施例的结构框图。
图9是本发明推荐系统另一实施例中第二生成模块的结构框图。
具体实施方式
下面结合附图,对本发明实施例的技术方案进行详细的解释。
如图1所示,本实施例的一种基于用户历史行为的商品信息推荐方法,包括以下步骤:
S11收集用户在电子商务网站历史行为数据,历史行为数据包括用户信息和商品信息;
S12根据用户的属性、商品特征和用户的历史行为特征,建立用户商品概率预测特征向量;
S13根据用户商品概率预测特征向量,训练模型,得出用户推荐商品预测模型;
S14将数据输入用户推荐商品预测模型中,得出行为商品的预测购买概率;
S15根据行为商品的预测购买概率,计算关联商品的预测购买概率,合并行为商品和关联商品,得到商品推荐列表。
上述推荐方法中,利用用户在电子商务网站的历史行为数据,测算行为商品的预测购买概率,并将行为商品和关联商品进行结合,生成商品推荐列表。由于不同用户的行为是不同的,所以基于不同用户的历史行为,测算行为商品的预测购买概率,使得最终生成的商品推荐列表具有个性化,针对不同用户生成不同的商品推荐列表。
为使得推荐的商品列表更符合用户的需求,步骤S11中,历史行为数据来源于PC端、WAP端、APP端和线下数据。多终端的数据来源,有利于扩大用户的历史行为数据采集范围,使得采集的历史行为数据更加准确的反应用户的历史需求,为后续商品推荐列表的生成提供更 准确的历史数据基础。采集的历史行为数据种类可以根据实际需要确定,包括用户信息和商品信息。例如,用户标签信息、用户访问信息、用户点击信息、用户浏览的时长、用户搜索信息、用户收藏夹、购物车信息、预售信息、订单销售信息等。用户信息包括用户标识ID、用户属性信息等。商品信息包括商品标识编码、商品特征信息等。用户属性信息包括用户的性别、年龄、访问偏好。其中,访问偏好反应用户的喜好,例如颜色、款式等等。确定用户的属性可根据历史行为数据,运用统计分析和机器学习等方法对其进行建模识别得出。商品特征包括商品流量特征、商品行为特征和商品决策成本。商品流量特征是指:PV、UV、转化率、销量、订单数量、销量增长率、订单增长率等。商品行为特征是指:促销、降价、新品、预售预约、爆款商品、促销力度、价格等。商品决策成本是指:购买商品的决策时间、浏览次数、浏览天数等。构建用户的历史行为特征是指:对用户的历史行为数据进行分析,得出影响用户购买的因子,根据因子分别提取因子特征值,组成因子数值向量,得到用户的历史行为特征。
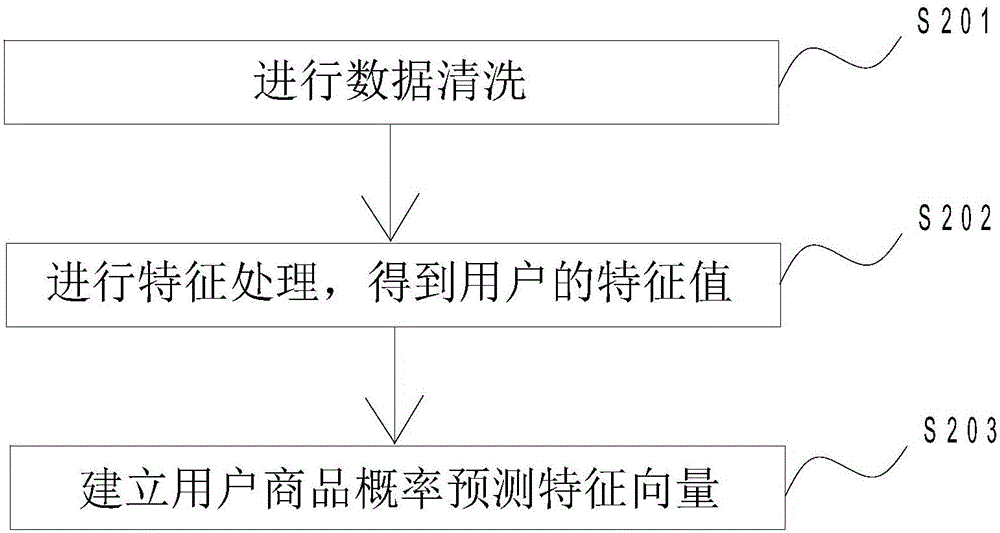
作为优选,如图2所示,所述的S12中,建立用户商品概率预测特征向量具体包括:
S201进行数据清洗:对异常数据进行清洗。
所谓异常数据是指与其他数据相比,该数据是显著相异的、异常的或者不一致的数据。例如以下需要过滤的数据,都属于异常数据:过滤同一用户加入购物车商品类别数>商品类别阈值Na的用户;过滤浏览时间小于浏览时间阈值Nbs的商品详情页浏览记录;过滤浏览时 间大于浏览时间阈值Ncs的商品详情页浏览记录;如果一个会话内用户四级页面浏览数量大于四级页面浏览数量阈值Nd,那么过滤该会话;用户当天访问pv小于pv阈值Ne,过滤该用户。
除了异常数据,还可以对不符合用户浏览习惯的数据进行清洗,即:将异常数据和不符合用户浏览习惯的数据进行清洗。所谓不符合用户浏览习惯的数据是指与正常购物用户的行为差别很大的数据,例如爬虫用户或者刷单用户的浏览行为。
S202进行特征处理:根据各终端用户历史行为特征的分布,按天统计,分别构造如式(2)所示的函数:
式(2)
其中,f(X)表示用户历史行为特征统计函数,X表示特征变量,a表示各特征阈值,x表示特征变量X的统计数。
设统计天数为N天,对统计天数划分为M个区间段,每个区间段按照式(3)所示的时间衰减函数,测算该区间段的特征值;
式(3)
其中,K表示衰减函数的半衰期,t表示距离本次测算的天数,如计算前一天的特征值时,t=1,计算前两天的特征值时,t=2;
按照式(3)衰减每个区间段的特征值,累加得出最终的用户的特征值:
式(4)
其中,N表示历史行为数据的统计天数,Nt表示1:N/M的整数序列;
S203建立用户商品概率预测特征向量:用户商品概率预测特征向量的表示形式为:各终端的指纹ID+商品ID+用户特征向量值。
指纹ID表示用户的标识ID。例如cookieid、MEMI、会员编码等。商品ID表示商品的标识编码。
用用户商品概率预测特征向量根据各终端用户的不同,而分别建立,具体来说:
(1)PC用户:指纹ID(PC)+商品ID+行为特征;
(2)WAP用户:指纹ID(WAP)+商品ID+行为特征;
(3)APP用户:指纹ID+商品ID+行为特征;
(4)跨屏用户:指纹ID1(PC)+指纹ID2(WAP)+指纹ID3+商品ID+行为特征。
其中,指纹ID(PC)表示PC用户标识ID;指纹ID(WAP)表示WAP用户标识ID;指纹ID表示APP用户标识ID。
在步骤S13中,根据用户商品概率预测特征向量,训练模型,得出用户推荐商品预测模型。
训练的模型是依据逻辑回归、lasso回归、random forests中的任意一种或多种方法而建立。训练时,PC端、WAP端、APP端等多端数据,分别进行训练模型。取购物车中已经转化为订单的商品的用户商品概率预测特征向量,作为训练集正样本数据。取行为中没有转化为订单的SKU的用户商品概率预测特征向量,作为训练集反样本数据。本实施例中涉及的模型训练,采用学习分类模型计算每个商品的购买概率,包括逻辑回归,lasso回归、random forests等。
逻辑回归模型:在分类的情形下,经过学习之后的LR分类器得到一组权值,权值按照与训练数据线性加和的方式,求出一个加权值,之后按照sigmoid函数的形式计算出其概率,即得到购买概率。
lasso回归模型:Lasso(Least absolute shrinkage and selection operator,Tibshirani)方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。Lasso的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,得到可以解释的模型。使得预测概率更加准确。
random forests模型:随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。根据输出类别计算得出用户的购买概率。
在步骤S14中,将待预测的用户数据载入用户商品预测模型中,得出行为商品的预测购买概率。
作为优选,S15具体包括以下步骤:
S301确定关联商品:根据用户历史行为数据中的访问历史数据和购买历史数据,采用关联规则或者协同过滤算法,计算该行为商品的关联商品的关联度,取关联度最高的前b个商品,作为该行为商品的关联商品集合,b为整数,且b>1。
S302根据式(1)计算关联商品的购买概率:
Score_i=Master_Pos*SKU_Score_i/max(SKU_Score_i)式(1)
其中,Score_i表示关联商品的购买概率;Master_Pos表示行为商品购买概率;max(SKU_Score_i)表示关联商品集合中关联度最高值,SKU_Score_i表示关联商品SKU_i与行为商品的关联度;
S303合并行为商品和关联商品,得到商品的推荐列表:
若行为商品在步骤S301得到的关联商品集合中,则按照行为商品和关联商品的预测购买概率大小排序,得出商品推荐列表;若行为商品不在步骤S301得到的关联商品集合中,且行为商品的预测购买概率小于概率阈值,则将行为商品预测购买概率乘以惩罚系数作为行为商品最终的预测购买概率,将关联商品和行为商品,按照商品预测购买概率大小重新排序,得到商品推荐列表。
步骤S303中,概率阈值和惩罚系数按照综合评价指标(F-Measure)的最优标准进行选择,取当F-Measure最大时的概率阈值和惩罚系数。
其中:命中率=正确识别的个体总数/识别出的个体总数;
召回率=正确识别的个体总数/测试集中存在的个体总数;
在命中率和召回率指标出现矛盾的情况下,采用综合评价指标(F-Measure,又称为F-Score)综合考虑它们,选取最优值。F-Measure是命中率和召回率加权调和平均。
F-Measure=(1+a2)*命中率*召回率/a2*(命中率+召回率);
当参数a=1时,就是最常见的F1,也即F1=2*命中率*召回率/(命 中率+召回率)。
可知,F1综合了命中率和召回率的结果。当F1较高时,则说明方法比较有效。F1主要作用是调整排序。
如图4所示,本实施例提供的推荐方法在上述实施例的基础上,增加了步骤S16:根据S15得到的商品推荐列表,按照行为过滤逻辑进行过滤和输出逻辑处理,输出最终的商品推荐列表。
按照行为过滤逻辑进行过滤和输出逻辑处理的具体过程是:取用户最近H天之内的订单商品,将订单商品所属商品组作为用户过滤商品组,过滤S16得到的商品推荐列表中属于过滤商品组的商品;根据商品预测购买概率,将过滤后的商品推荐列表中的商品重新进行排序,作为最终的商品推荐列表。基于用户在最近H天之内下了订单的商品,用户近期就不会再次购买,因此,采用行为过滤逻辑处理,使得最终的商品推荐列表中不再出现最近H天之内已经下了订单的商品。排除了这些商品后的商品推荐列表,更能准确反映用户的需求。
上述实施例的推荐方法,综合考虑了用户行为和商品特征与二者的交叉特征,提高了预测的准确度,进一步提高了推荐的准确度。交叉特征是指特征属性的线性或者非线性组合。交叉特征对用户行为的刻画更加丰富,增加的特征变量的维度,进一步增加了模型的精准度。
进行精度测试:对比例和本实施例,两者的测试数据均是采用本实施例中训练数据的获取方式,在新的时间窗口计算得到。对比例采用逻辑回归模型,本实施例采用步骤S13建立的模型。在计算时,对比例采用的用户特征为用户的浏览行为,本实施例采用的用户特征为 用户行为特征、商品特征。对比例和本实施例经过模型测试输出推荐列表。根据两者的预测结果,对比例的预测精度AUC为0.70,本实施例的预测精度AUC为0.83。
综合维度对推荐结果进行排序,针对推荐的核心评价指标召回率与命中率会发生矛盾的情况,本实施例采用综合加权调和平均的统计方法进行衡量,最后使用其最优值优化推荐排序结果,即按照综合评价指标最大值对应的结果进行排序,提高了推荐排序的准确度,
采用了多层次衰减的方法,建立用户的历史行为特征。将用户的历史行为划分成M个区间段,在区间段和时间两个维度进行衰减。使用该方法保留了用户的连续浏览习惯,该方法认为在同一区间段的用户行为是连续行为,并且考虑了时间对用户的购买需求的影响。多层次衰减的方法影响排序的商品得分,衰减的速度和区间会造成最终特征向量值不同,导致用户得分不同。由于用户的商品排序是按照得分大小排列的,故得分不同影响排序的结果(即推荐排序结果)。
本实施例方法预测用户对电子商务商品进行购买概率预测,预测结果作为电子商务网站进行精准营销、个性化推荐等基础预测数据。
另外,如图5所示,还提供一种基于用户历史行为的商品信息推荐系统,该系统包括:
采集模块:用于采集用户在电子商务网站历史行为数据;
特征向量建立模块:用于根据采集模块采集历史行为数据,建立用户商品概率预测特征向量;
模型建立模块;用于根据特征向量建立模块建立的用户商品概率 预测特征向量,训练模型,得到用户推荐商品预测模型;
测算模块:用于将数据输入用户推荐商品预测模型中,测算行为商品的预测购买概率;
第一生成模块:用于根据测算模块测算的行为商品的预测购买概率,计算关联商品的预测购买概率,合并行为商品和关联商品,得到商品推荐列表。
上述系统中,利用用户在电子商务网站的历史行为数据,测算行为商品的预测购买概率,并将行为商品和关联商品进行结合,生成商品推荐列表。由于不同用户的行为是不同的,所以基于不同用户的历史行为,测算行为商品的预测购买概率,使得最终生成的商品推荐列表具有个性化,针对不同用户生成不同的商品推荐列表。
采集模块采集的历史行为数据来源于PC端、WAP端、APP端和线下数据。多终端的数据来源,有利于扩大用户的历史行为数据采集范围,使得采集的历史行为数据更加准确的反应用户的历史需求,为后续商品推荐列表的生成提供更准确的历史数据基础。历史行为数据包括用户信息和商品信息。用户信息包括用户的标识ID、用户属性信息等。商品信息包括商品的标识编码、商品特征信息等。用户属性包括用户的性别、年龄、访问偏好。商品特征包括商品流量特征、商品行为特征和商品决策成本。
作为优选方案,如图6所示,所述的特征向量建立模块包括:
清洗子模块:用于将异常数据和不符合用户浏览习惯的数据,进行清洗;
测算子模块:用于将清洗后的各终端用户历史行为特征,按天统计,分别构造用户历史行为特征统计函数,对统计天数划分为M个区间段,对每个区间段按照时间衰减函数,测算区间段的特征值,累加各区间段的特征值,得到用户特征值:
建立子模块:用于建立用户商品概率预测特征向量,用户商品概率预测特征向量的表示形式为:各终端的指纹ID++商品ID+用户特征值;其中,指纹ID表示用户的标识ID,商品ID表示商品的标识编码。
特征向量建立模块中,利用清洗子模块清洗异常数据和不不符合用户浏览习惯的数据,然后利用测算子模块测算用户特征值,最后利用建立子模块建立用户商品概率预测特征向量。其中,测算子模块对每个区间段按照时间衰减函数,测算区间段的特征值,然后累加各区间段的特征值。多层次衰减的方法影响排序的商品得分,衰减的速度和区间会造成最终特征向量值不同,导致用户得分不同,由于用户的商品排序是按照得分大小排列的,故得分不同影响排序的结果(即推荐排序结果)。
清洗子模块中,异常数据是指与其他数据相比,该数据是显著相异的、异常的或者不一致的数据。例如以下需要过滤的数据,都属于异常数据:过滤同一用户加入购物车商品类别数>商品类别阈值Na的用户;过滤浏览时间小于浏览时间阈值Nbs的商品详情页浏览记录;过滤浏览时间大于浏览时间阈值Ncs的商品详情页浏览记录;如果一个会话内用户四级页面浏览数量大于四级页面浏览数量阈值Nd,那 么过滤该会话;用户当天访问pv小于pv阈值Ne,过滤该用户。
所谓不符合用户浏览习惯的数据是指与正常购物用户的行为差别很大的数据,例如爬虫用户或者刷单用户的浏览行为。
作为优选方案,如图7所示,所述的第一生成模块包括:
确定子模块:用于根据用户历史行为数据中的访问历史数据和购买历史数据,采用关联规则或者协同过滤算法,计算该行为商品的关联商品的关联度,取关联度最高的前b个商品,作为该行为商品的关联商品集合;
计算子模块:用于根据式(1)计算关联商品的购买概率:
Score_i=Master_Pos*SKU_Score_i/max(SKU_Score_i)式(1)
其中,Score_i表示关联商品的购买概率;Master_Pos表示行为商品购买概率;max(SKU_Score_i)表示关联商品集合中关联度最高值,SKU_Score_i表示关联商品SKU_i与行为商品的关联度;
第一生成子模块:用于合并行为商品和关联商品,生成商品推荐列表:若行为商品在确定子模块建立的关联商品集合中,则按照行为商品和关联商品的预测购买概率大小排序,得到商品推荐列表;若行为商品不在确定子模块建立的关联商品集合中,且行为商品的预测购买概率小于概率阈值,则将行为商品预测购买概率乘以惩罚系数作为该行为商品最终的预测购买概率;将关联商品和行为商品按照商品预测购买概率大小排序,得到商品推荐列表。
第一生成子模块中,概率阈值和惩罚系数按照综合评价指标 (F-Measure)的最优标准进行选择,取当F-Measure最大时的概率阈值和惩罚系数。
第一生成子模块不仅考虑了行为商品,还考虑了关联商品,将关联商品与行为商品一起作为待推荐的商品。在选择推荐商品时,根据行为商品是否已存在关联商品集合中,对行为商品的预测购买概率进行不同的处理,将关联商品和处理后的行为商品,重新按照购买概率进行排序,使得行为商品在推荐列表中的位置更符合用户的需求。
如图8所示,所述的基于用户历史行为的商品信息推荐系统,还包括第二生成模块:用于对第一生成模块得到的商品推荐列表,进行过滤和输出逻辑处理,生成最终的商品推荐列表。由于用户近期购买的商品,通常不会再次购买,所以对第一生成模块生成的商品推荐列表进行过滤和输出逻辑处理,使得最终的商品推荐列表中没有用户近期购买的商品,从而使得商品推荐列表更符合用户的真正需求。
如图9所示,所述的第二生成模块包括:
过滤商品组建立子模块:用于取用户最近H天之内的订单商品,将订单商品所属商品组作为用户过滤商品组。H为整数,且H>3。
过滤子模块:用于过滤第一生成模块生成的商品推荐列表中属于过滤商品组的商品。
第二生成子模块:根据商品预测购买概率,将过滤子模块过滤后的商品推荐列表中的商品重新进行排序,生成最终的商品推荐列表。
通过过滤商品组建立子模块选取过滤商品组。过滤商品组为用户近期购买的商品。过滤子模块将第一生成模块生成的商品推荐列表中 属于过滤商品组的商品过滤。第二生成子模块将过滤后的商品推荐列表中的商品,按照商品预测购买概率,重新进行排序,生成最终的商品推荐列表。通过上述三个子模块,将第一生成模块生成的商品推荐列表中,与用户近期购买的商品属于同类的商品过滤掉,以使得最终的商品推荐列表中排列的商品符合用户的真正需求。
本领域技术人员应该知晓,实现上述实施例的方法或者系统,可以通过计算机程序指令来实现。该计算机程序指令装载到可编程数据处理设备上,例如计算机,从而在可编程数据处理设备上执行相应的指令,用于实现上述实施例的方法或者系统实现的功能。
本领域技术人员依据上述实施例,可以对本申请进行非创造性的技术改进,而不脱离本发明的精神实质。这些改进仍应视为在本申请权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!