存储空间的写入加速方法、装置和系统与流程
本发明涉及多核处理器,尤其涉及一种存储空间的写入加速方法、装置和系统。
背景技术:
现代计算机的系统架构中普遍配置了图形处理器(Graphic Processing Unit,简称GPU)、GPU存储空间及存在大容量存储空间的I/O设备,访问GPU存储空间及I/O设备的存储空间会发生大量的数据拷贝操作。
现有技术中,访问和配置GPU存储空间、I/O设备的存储空间时,通常通过硬件维护数据一致性的数据总线进行数据交互,在普通的无缓存(uncache)访问方式下,如果对一段连续的存储空间进行写访问,则每条提交队列中的存储(store)指令都需要等收到写操作完成的写完成(commit)信号后才能提交。例如,第二存储指令必须等到收到第一存储指令的写操作完成的写完成信号后才能执行,即,连续的存储指令操作开销等于一条存储指令的开销乘以存储指令数,很明显连续的无缓存写入开销会很大,因而速度较慢,访问性能较低。
技术实现要素:
本发明提供一种存储空间的写入加速方法、装置和系统,用以解决连续存储指令需等待写完成信号,而造成的写入速度慢及访问性能低的问题。
本发明实施例第一方面提供一种存储空间的写入加速方法,包括:
连续接收存储指令对应的数据,将各所述存储指令对应的数据存储至第一无缓存加速缓冲接口UABE中,直至所述第一UABE存满后,将所述第一UABE中的数据存储至存储空间;
将未存储至所述第一UABE中的各所述存储指令对应的数据存储至第二UABE中,直至所述第二UABE存满后,将所述第二UABE中的数据存储至 所述存储空间;
重复执行上述两个过程,直至所有存储指令对应的数据写入所述存储空间。
本发明实施例第二方面提供一种存储空间的写入加速方法,包括:
步骤一、连续接收存储指令对应的数据,将各所述存储指令对应的数据存储至第一UABE中,直至所述第一UABE存满;
步骤二、将所述第一UABE中的数据存储至所述存储空间;
步骤三、将未存储至所述第一UABE中的各所述存储指令对应的数据存储至第n UABE中,直至所述第n UABE存满;
步骤四、将所述第n UABE中的数据存储至所述存储空间;
步骤五、将未存储至所述第n UABE中的各所述存储指令对应的数据存储至第n+1 UABE中,直至所述第n+1 UABE存满;
步骤六、将所述第n+1 UABE中的数据存储至所述存储空间;
步骤七、重复执行步骤五和步骤六,且在重复执行的步骤五之前将n的取值加1,直至N个UABE均存储过数据,n的初始值为2;N为大于等于3的正整数;重复执行步骤一至步骤七,直至所有存储指令对应的数据写入所述存储空间。
本发明实施例第三方面提供一种存储空间的写入加速装置,包括:
第一接收模块,用于连续接收存储指令对应的数据,将各所述存储指令对应的数据存储至第一UABE中,直至第一UABE存满;
第一发送模块,用于将所述第一UABE中的数据存储至所述存储空间;
第二接收模块,用于将未存储至所述第一UABE中的各所述存储指令对应的数据存储至第二UABE中,直至所述第二UABE存满;
第二发送模块,用于将所述第二UABE中的数据存储至所述存储空间;
所述第一接收模块、第一发送模块、第二接收模块和第二发送模块重复工作,直至所有存储指令对应的数据写入所述存储空间。
本发明实施例第四方面提供一种存储空间的写入加速装置,包括:
第一接收模块,用于连续接收存储指令对应的数据,将各所述存储指令对应的数据存储至第一UABE中,直至第一UABE存满;
第一发送模块,用于将所述第一UABE中的数据存储至所述存储空间;
第n接收模块,用于将未存储至所述第一UABE中的各所述存储指令对应的数据存储至第n UABE中,直至所述第n UABE存满;
第n发送模块,用于将所述第n UABE中的数据存储至所述存储空间;
其中,n为大于2且小于N的所有正整数;N为大于等于3的正整数;
所述第一接收模块、第一发送模块至第N接收模块和第N发送模块重复工作,直至所有存储指令对应的数据写入所述存储空间。
本发明实施例第五方面提供一种存储空间的写入加速系统,包括存储空间的写入加速装置、存储空间、第一UABE和第二UABE;
所述存储空间的写入加速装置,用于连续接收存储指令对应的数据,将各所述存储指令对应的数据存储至所述第一UABE或所述第二UABE中;
当所述第一UABE或所述第二UABE存满时,将所述第一UABE或第二UABE中的数据存储至所述存储空间。
本发明实施例提供的存储空间的写入加速方法、装置和系统,将连续存储指令对应的数据先后轮流存储至两个UABE中,当一个UABE存满时,将其中的数据统一发送至存储空间,并开始存另一个UABE,当另一个UABE存满时,可再次利用已经将数据发送至存储空间的空的UABE进行数据存储,通过轮流将数据存储在两个UABE中,可避免因等待存储空间返回的写完成信号而导致的写入速度慢、开销大的问题,达到提高存储空间的写入速度的目的。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明存储空间的写入加速系统实施例一的结构示意图;
图2为本发明存储空间的写入加速方法实施例一的流程图;
图3为本发明存储空间的写入加速方法实施例二的流程图;
图4为本发明存储空间的写入加速方法实施例二的应用场景示意图;
图5为本发明存储空间的写入加速方法实施例三的流程图;
图6为本发明存储空间的写入加速方法实施例四的流程图;
图7为本发明存储空间的写入加速装置实施例的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明存储空间的写入加速系统实施例一的结构示意图。如图1所示,本发明提供的系统包括:能够实现加速存储空间写入速度的装置、存储空间、第一UABE和第二UABE。
该能够实现加速存储空间写入速度的装置连续接收存储指令对应的数据,将各存储指令对应的数据存储至第一UABE或第二UABE中;当第一UABE或第二UABE存满时,该装置将第一UABE或第二UABE中的数据存储至存储空间。
其中,该加速空间写入速度的装置可以安装到GPU上。图1所示的结构示意图仅为该装置逻辑关系的示意图。
可选的,如图1所示,上述系统还包括FIFO,当第一UABE或第二UABE存满时,该装置向FIFO发送第一UABE或第二UABE写入存储空间的第一写入请求或第二写入请求。
本实施例提供的存储空间的写入加速系统,可以用于执行下述各实施例中的存储空间的写入加速方法实施例的技术方案。
本发明实施例中的存储空间可以为GPU存储空间或其他任意具有大量存储空间的I/O设备,而第一UABE、第二UABE及FIFO则是为提高上述存储空间的写入速度所增加的数据缓存空间,下述各实施例中仅以GPU存储空间为例,而非对存储空间的限定。且上述装置可以嵌入到执行存储操作的设备中,下述各实施例中的存储空间的写入加速方法的执行主体为该装置。
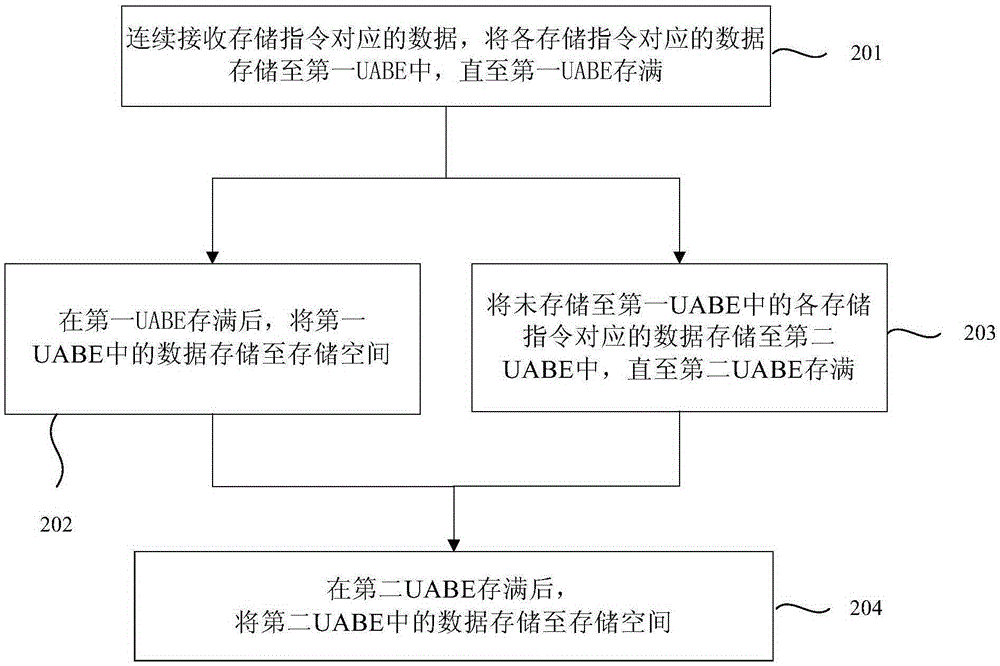
图2为本发明存储空间的写入加速方法实施例一的流程图。如图2所示,本发明提供的方法包括:
步骤一(201)、连续接收存储指令对应的数据,将各存储指令对应的数据存储至第一UABE中,直至第一UABE存满;
步骤二(202)、在第一UABE存满后,将第一UABE中的数据存储至存储空间;
步骤三(203)、将未存储至第一UABE中的各存储指令对应的数据存储至第二UABE中,直至第二UABE存满;
步骤四(204)、在第二UABE存满后,将第二UABE中的数据存储至存储空间;
重复执行上述过程,即步骤一至步骤四,直至所有存储指令对应的数据写入存储空间。并且上述方法可以部署在GPU中来执行。在本发明实施例中,步骤的划分并不是对发明执行顺序的限定,可以拆成更多的步骤,也可以对各步骤进行合并,减少步骤。
可选的,在重复执行时,将UABE中的数据存储至存储空间的步骤与将未存储至UABE中的各存储指令对应的数据存储至其它UABE的步骤并行执行。
当CPU访问GPU存储空间或其他I/O设备的存储空间,进行大量的数据拷贝或写入时,CPU发送连续存储指令,存储空间接收各存储指令对应的数据,并在数据写入存储空间后向CPU返回写完成指令。
对于上述实施例一,当CPU发送连续存储指令时,执行步骤一,上述实施例中的装置连续接收存储指令对应的数据,将各存储指令对应的数据存储至第一UABE中,直至第一UABE存满。当第一UABE存满时,执行步骤二,将所有存储在第一UABE中的数据一起发送至存储空间。与单独发送每个存储指令对应的数据相比两个存储指令之间无需等待写完成指令,通过增加UABE将连续的存储指令对应的数据连续的先存储在UABE中,避免了下一个存储指令需等待上一个存储指令的写完成信号,才能进行存储,提高了存储空间的写入速度。
执行步骤三,将没有存储至第一UABE中的存储指令对应的数据存储至第二UABE中,直至第二UABE存满。当第二UABE存满时,与步骤二相似,执行步骤四,将第二UABE中的数据存储至存储空间。
当存储指令较多,则再次重复执行步骤一,由于第一UABE中的数据已 经存储至存储空间中,因而将没有存储至第二UABE中的存储指令对应的数据再次存储至第一UABE中,直至第一UABE存满。
重复执行步骤一至步骤四,直至所有存储指令对应的数据写入到存储空间。可选的,步骤二中的将第一UABE中的数据存储至存储空间的操作与步骤三中的将未存储至第一UABE中的各存储指令对应的数据存储至第二UABE的操作并行执行,步骤四中的将第二UABE中的数据存储至存储空间的操作与重复执行的步骤一中的将未存储至第二UABE中的各存储指令对应的数据存储至第一UABE的步骤并行执行。即,步骤二和步骤三同时执行,步骤四和重复的步骤一同时执行,直至所有存储指令对应的数据写入到存储空间。
当连续的存储指令结束时,若最后用于存储数据的第一UABE或第二UABE未存满,仍将第一UABE或第二UABE中存储的数据存储至存储空间。且需等待所有的数据都存储至存储空间再执行后续操作,以保证数据一致性。
本发明实施例提供的存储空间的写入加速方法,将连续存储指令对应的数据先后轮流存储至两个UABE中,当一个UABE存满时,将其中的数据统一发送至存储空间,并开始存另一个UABE,当另一个UABE存满时,可再次利用已经将数据发送至存储空间的空的UABE进行数据存储,通过轮流将数据存储在两个UABE中,可避免因等待存储空间返回的写完成信号而导致的写入速度慢、开销大的问题,达到提高存储空间的写入速度的目的。
在上述实施例一的基础上,图3为本发明存储空间的写入加速方法实施例二的流程图。图4为本发明存储空间的写入加速方法实施例二的应用场景示意图。结合图3和图4,对本发明提供的方法进行详细说明。如图3所示,在执行上述实施例中的步骤二,将第一UABE中的数据存储至存储空间之前,该方法还包括:
步骤2001、向FIFO发送第一UABE写入存储空间的第一写入请求,以使FIFO将第一写入请求记录至空的指示位。
在执行上述实施例中的步骤四,将第二UABE中的数据存储至存储空间之前,该方法还包括:
步骤4001、向FIFO发送第二UABE写入存储空间的第二写入请求,以 使FIFO将第二写入请求记录至空的指示位。
其中步骤2001可以在每次执行步骤二之前执行,也可与步骤二同时执行,或在步骤二之后、步骤三之前执行,本发明对此不做严格限定。
其中步骤4001可以在每次执行步骤四之前执行,也可与步骤四同时执行,或在步骤四之后、重复执行的步骤一之前执行,本发明对此不做严格限定。
如图4所示,当CPU连续发送存储指令时,连续的存储指令会在存储指令队列中排队等待,存储指令队列中的各存储指令对应的数据均需存储至存储空间,首先执行步骤一,按指令队列将各存储指令对应的数据连续存储至UABE0中,直至UABE0存满。然后执行步骤二与步骤201,向FIFO发送第一写入请求,FIFO将第一写入请求记录至空的指示位0中,同时将UABE0中的数据存储至GPU存储空间。该第一写入请求用于指示FIFO将UABE0中的数据写入GPU存储空间,FIFO为先入先出队列,具有8个指示位,即指示位0至指示位7,可用于存储第一写入请求。
在执行步骤二和步骤2001的同时,执行步骤三,将指令队列中没有存储至UABE0中的存储指令对应的数据存储至UABE1中,直至UABE1存满。当UABE1存满时,与步骤二相似,执行步骤四和步骤4001,向FIFO发送第二写入请求,FIFO将第二写入请求记录至空的指示位1中,同时将UABE1中的数据存储至GPU存储空间。由于UABE0和UABE1交替存储个存储指令对应的数据,因此FIFO中的指示位交替存储第一写入请求和第二写入请求。并在数据写入GPU存储空间后,GPU存储空间向FIFO返回写完成指令,收到写完成指令后,FIFO清空对应的指示位。
在上述实施例二的基础上,如图5所示,是本发明提供的存储空间的写入加速方法实施例三的流程图。在实施例二中的步骤2001和步骤4001之前,本方法还包括:
步骤501、判断FIFO中的指示位是否写满;若判定未写满,则执行步骤502;若判定写满,则执行步骤503;
步骤502、确定执行向FIFO发送第一UABE或第二UABE写入存储空间的第一写入请求或第二写入请求的步骤;
步骤503、等待FIFO中有空的指示位,其中,在存储空间向FIFO返回 第一UABE或第二UABE写完成信号后,FIFO将第一UABE或第二UABE对应的第一写入请求或第二写入请求所占的指示位设置为空。
当存储空间的写入速度较慢,返回写完成信号较慢时,在上述实施例一中可能会导致第二UABE存满时,第一UABE发送给存储空间的数据仍未完全写入存储空间中。或上述实施例二中,会导致8组的第一UABE和第二UABE中发出的数据处于等待被写入存储空间的状态中,当第五次重复执行的UABE0写满时,指示位0仍不为空,为保证等待中的第一UABE和第二UABE发出的数据不超过数据总线的承载能力,在执行上述实施例二中的2001和4001之前,增加判断FIFO中的指示位是否写满的步骤。
每当第一UABE或第二UABE存满后,则将第一UABE或第二UABE中的数据存储至存储空间,但有可能存在存储空间写入速度过慢导致数据总线中有多个已发送的UABE数据仍在等待的情况,此时需先确认有多少已发送的第一UABE或第二UABE中的数据在等待。而在将第一UABE或第二UABE中的数据存储至存储空间时,同时向FIFO发送了对应的第一写入请求或第二写入请求,每个第一写入请求或第二写入请求占用了一个FIFO的指示位;因此,只需合理设置FIFO的大小,判断FIFO是否写满即可。
当FIFO中的指示位未写满时,则执行步骤502,即执行实施例二中的步骤二和步骤2001,或执行实施例二中的步骤四和步骤4001。当FIFO中的指示位写满时,执行步骤503,等待FIFO中有空的指示位。
当存储空间完成第一UABE或第二UABE发送的数据的存储时,存储空间向FIFO返回该第一UABE或第二UABE对应的写完成信号,FIFO接收到存储空间返回的写完成信号后,FIFO释放该第一写入请求或第二写入请求占用的指示位,将该指示位置为空。
可选的,在实际使用中,为简化设计、便于实现,可使FIFO中的指示位包括数量相同的第一UABE使用的第一指示位和第二UABE使用的第二指示位,第一指示位和第二指示位交替排列,指示位至少为四位。可选的,也可将FIFO中的指示位设置为奇数个,指示位至少为三个。
在上述实施例的基础上,针对现有的不同的操作系统的内核所工作的unmapped地址空间和MMAP地址空间,在连续接收存储指令对应的数据之后,还包括:
确定存储指令对应的地址的标志位有效;或
确定存储指令对应的地址在处理器的传输后备缓冲器模块对应的标识位有效。
具体的,对于unmapped地址空间,各存储指令所对应的地址为物理地址,可直接在物理地址中增加一标识位,该标识位用于表示该存储指令是否采用上述实施例所提供的存储空间的写入加速方法。当标识位有效时,存储指令采用加速方法进行数据的存储,当标识位无效时,则不通过加速的方法进行数据存储,可以采用现有技术进行数据存储。可选的,标识位的有效与否可采用高低电平来指示。
具体的,对于MMAP地址空间,由于存在虚拟地址和物理地址的转换,因此,在处理器中设置有传输后备缓冲器(Translation Lookaside Buffer,简称TLB)模块用于记录各虚拟地址和物理地址的对应关系,因此,可在TLB模块中增加标识位,该标识位用于表示该存储指令是否采用上述实施例所提供的存储空间的写入加速方法。当接收到存储指令时,确定存储指令对应的地址在TLB模块中对应的标识位即可,无需在存储指令对应的地址上增加标识位。
图6为本发明存储空间的写入加速方法实施例四的流程图。如图6所示,本发明提供的方法包括:
步骤一(601)、连续接收存储指令对应的数据,将各存储指令对应的数据存储至第一UABE中,直至第一UABE存满;
步骤二(602)、将第一UABE中的数据存储至存储空间;
步骤三(603)、将未存储至第一UABE中的各存储指令对应的数据存储至第n UABE中,直至第n UABE存满;
步骤四(604)、将第n UABE中的数据存储至存储空间;
步骤五(605)、将未存储至第n UABE中的各存储指令对应的数据存储至第n+1 UABE中,直至第n+1 UABE存满;
步骤六(606)、将第n+1 UABE中的数据存储至存储空间;
步骤七(607)、重复执行步骤五和步骤六,且在重复执行的步骤五之前将n的取值加1,直至N个UABE均存储过数据,n的初始值为2;N为大于等于3的正整数;
重复执行步骤一至步骤七,直至所有存储指令对应的数据写入存储空间;
其中,将UABE中的数据存储至存储空间的步骤与将未存储至UABE中的各存储指令对应的数据存储至其它UABE的步骤并行执行。
当采用多个UABE交替存储连续存储指令对应的数据时,可实现避免等待返回的写完成信号,而提高写入速度。可选的,也可在上述实施例四的基础上,设置FIFO,其具体实现方式与上述实施二或实施例三类似,即将实施例四与上述任一实施例或多个实施例相结合,本发明对此不做限定。
本发明实施例还提供一种存储空间的写入加速装置。本发明下文所提供的存储空间的写入加速装置可用于执行如上所述的实施例。图7为本发明存储空间的写入加速装置实施例一的示意图。如图7所示,本发明提供的装置包括:
第一接收模块701,用于连续接收存储指令对应的数据,将各存储指令对应的数据存储至第一UABE中,直至第一UABE存满;
第一发送模块702,用于将第一UABE中的数据存储至存储空间;
第二接收模块703,用于将未存储至第一UABE中的各存储指令对应的数据存储至第二UABE中,直至第二UABE存满;
第二发送模块704,用于将第二UABE中的数据存储至存储空间;
第一接收模块701、第一发送模块702、第二接收模块703和第二发送模块704重复工作,直至所有存储指令对应的数据写入存储空间;
可选的,第一发送模块702与第二接收模块703并行工作,第二发送模块704与重复工作的第一发送模块701并行工作。
可选的,在上述实施例的基础上,第一发送模块702还用于向FIFO发送第一UABE写入存储空间的第一写入请求,以使FIFO将第一写入请求记录至空的指示位;
第二发送模块704还用于向FIFO发送第二UABE写入存储空间的第二写入请求,以使FIFO将第二写入请求记录至空的指示位。
可选的,本发明提供的存储空间的写入加速装置还包括:FIFO判断模块,用于判断FIFO中的指示位是否写满;
若判定未写满,则确定执行向FIFO发送第一UABE或第二UABE写入 存储空间的第一写入请求或第二写入请求的步骤;
若判定写满,则等待FIFO中有空的指示位,其中,在存储空间向FIFO返回第一UABE或第二UABE写完成信号后,FIFO将第一UABE或第二UABE对应的第一写入请求或第二写入请求所占的指示位置为空。
可选的,FIFO中的指示位包括数量相同的第一UABE使用的第一指示位和第二UABE使用的第二指示位,第一指示位和第二指示位交替排列,指示位至少为四位。
可选的,本发明提供的存储空间的写入加速装置还包括:第一标识位确定模块,用于确定存储指令对应的地址的标识位有效。
可选的,本发明提供的存储空间的写入加速装置还包括:第二标识位确定模块,用于确定存储指令对应的地址在处理器的传输后备缓冲器模块对应的标识位有效。
本发明实施例还提供一种存储空间的写入加速装置,包括:
接收模块,用于连续接收存储指令对应的数据,将各存储指令对应的数据存储至第一UABE中,直至第一UABE存满;
发送模块,用于将第一UABE中的数据存储至存储空间;
接收模块,还用于将未存储至第一UABE中的各存储指令对应的数据存储至第n UABE中,直至第n UABE存满;
发送模块,还用于将第n UABE中的数据存储至存储空间;
其中,n为大于2且小于N的所有正整数;N为大于等于3的正整数;
接收模块和发送模块重复工作,直至所有存储指令对应的数据写入存储空间。
本发明实施例还提供一种存储空间的写入加速系统。图1为本发明存储空间的写入加速系统实施例的结构示意图。如图1所示,本发明提供的系统包括:存储空间的写入加速装置、存储空间、第一UABE和第二UABE;
装置连续接收存储指令对应的数据,将各存储指令对应的数据存储至第一UABE或第二UABE中;
当第一UABE或第二UABE存满时,装置将第一UABE或第二UABE中的数据存储至存储空间。
可选的,存储空间的写入加速装置可以如上述实施例所述。
可选的,如图1所示,上述系统还包括FIFO;当第一UABE或第二UABE存满时,装置向FIFO发送第一UABE或第二UABE写入存储空间的第一写入请求或第二写入请求。
以上各实施例所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!