最近邻分类装置及方法与流程
本发明涉及信息技术领域,尤其涉及一种最近邻分类装置及方法。
背景技术:
随着信息技术的不断发展,模式识别的应用日益普遍。而最近邻分类是模式识别领域中被普遍使用的分类策略。单纯的最近邻分类指的是,对于需要分类的物体,根据一些距离规则来选择K个最近邻的训练样本,而该物体的类别被确定为该K个最近邻的训练样本中最普遍的类别,当K为1时,该物体的类别则被确定为该单一的最近邻样本的类别。
单纯的最近邻分类策略的鲁棒性较差且对噪声较为敏感,为了解决该问题,目前进行了很多改进。例如,可采用加权最近邻分类法,其中,根据各个最近邻样本的贡献分配权重,距离测试样本较近的贡献较大。例如,一种普遍使用的加权最近邻分类法采用1/d作为各个最近邻样本的权重,d为各个最近邻样本距离测试样本的距离。
应该注意,上面对技术背景的介绍只是为了方便对本发明的技术方案进行清楚、完整的说明,并方便本领域技术人员的理解而阐述的。不能仅仅因为这些方案在本发明的背景技术部分进行了阐述而认为上述技术方案为本领域技术人员所公知。
技术实现要素:
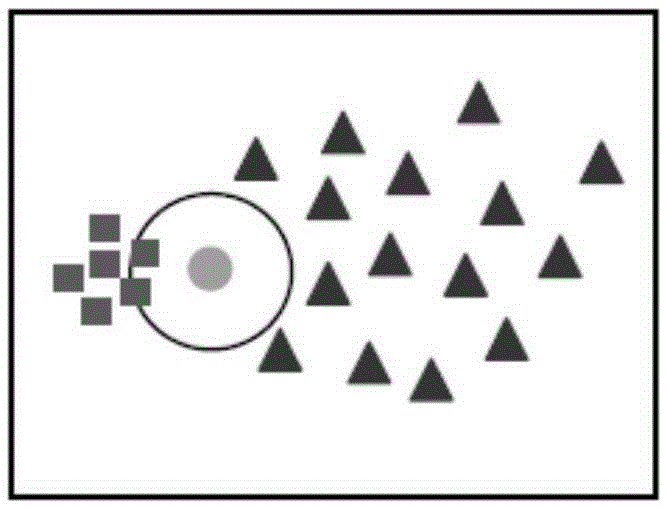
本发明的发明人发现,现有的加权最近邻分类法的分类结果依赖于数据的局部结构,从而可能导致分类错误。图1是一种示例的数据分布图,如图1所示,圆圈内的圆点表示测试样本,当使用现有的加权最近邻分类法时,由于采用1/d作为各个最近邻的权重,该测试样本被错误的划分为正方形的类别。
另外,现有的最近邻分类法依赖于最近邻样本的数量,即依赖于K值。图2是另一种示例的数据分布图,如图2所示,圆点表示测试样本,当K=3时,选取的最近邻样本为实线圆圈内的样本,该测试样本被划分为三角形的类别,当K=5时,选 取的最近邻样本为虚线圆圈内的样本,该测试样本被划分为正方形的类别,因此,K值的不同将导致分类结果的不同,使得分类结果不可靠。
本发明实施例提供一种最近邻分类装置及方法,由于在对测试样本进行分类时,同时考虑了各个类别的权重和先验概率这两个因素,能够有效提高分类结果的准确性,并具有较强的鲁棒性。
根据本发明实施例的第一方面,提供一种最近邻分类装置,包括:获取单元,所述获取单元用于获得测试样本的K个最近邻样本,K为正整数;分组单元,所述分组单元用于根据所述K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;第一计算单元,所述第一计算单元用于计算每个组的权重;第二计算单元,所述第二计算单元用于计算每个组的概率密度分布,并根据每个组的概率密度分布计算所述测试样本对于每个组的先验概率;第三计算单元,所述第三计算单元用于根据每个组的权重和所述测试样本对于每个组的先验概率,计算每个组对应的类别的得分;分类单元,所述分类单元用于将所有类别中得分最高的类别确定为所述测试样本的类别。
根据本发明实施例的第二方面,提供一种最近邻分类方法,包括:获得测试样本的K个最近邻样本,K为正整数;根据所述K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;计算每个组的权重;计算每个组的概率密度分布,并根据每个组的概率密度分布计算所述测试样本对于每个组的先验概率;根据每个组的权重和所述测试样本对于每个组的先验概率,计算每个组对应的类别的得分;将所有类别中得分最高的类别确定为所述测试样本的类别。
本发明的有益效果在于:由于在对测试样本进行分类时,同时考虑了各个类别的权重和先验概率这两个因素,能够有效提高分类结果的准确性,并具有较强的鲁棒性。
参照后文的说明和附图,详细公开了本发明的特定实施方式,指明了本发明的原理可以被采用的方式。应该理解,本发明的实施方式在范围上并不因而受到限制。在所附权利要求的精神和条款的范围内,本发明的实施方式包括许多改变、修改和等同。
针对一种实施方式描述和/或示出的特征可以以相同或类似的方式在一个或更多个其它实施方式中使用,与其它实施方式中的特征相组合,或替代其它实施方式中的特征。
应该强调,术语“包括/包含”在本文使用时指特征、整件、步骤或组件的存在,但并不排除一个或更多个其它特征、整件、步骤或组件的存在或附加。
附图说明
所包括的附图用来提供对本发明实施例的进一步的理解,其构成了说明书的一部分,用于例示本发明的实施方式,并与文字描述一起来阐释本发明的原理。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。在附图中:
图1是一种示例的数据分布图;
图2是另一种示例的数据分布图;
图3是本发明实施例1的最近邻分类装置的组成示意图;
图4是本发明实施例1的第二计算单元304的组成示意图;
图5是本发明实施例2的电子设备的组成示意图;
图6是本发明实施例2的电子设备的系统构成的一示意框图;
图7是本发明实施例3的最近邻分类方法流程图;
图8是本发明实施例4的最近邻分类方法流程图。
具体实施方式
参照附图,通过下面的说明书,本发明的前述以及其它特征将变得明显。在说明书和附图中,具体公开了本发明的特定实施方式,其表明了其中可以采用本发明的原则的部分实施方式,应了解的是,本发明不限于所描述的实施方式,相反,本发明包括落入所附权利要求的范围内的全部修改、变型以及等同物。
实施例1
图3是本发明实施例1的最近邻分类装置的组成示意图。如图3所示,装置300包括:
获取单元301,用于获得测试样本的K个最近邻样本,K为正整数;
分组单元302,用于根据该K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;
第一计算单元303,用于计算每个组的权重;
第二计算单元304,用于计算每个组的概率密度分布,并根据每个组的概率密度分布计算该测试样本对于每个组的先验概率;
第三计算单元305,用于根据每个组的权重和该测试样本对于每个组的先验概率,计算每个组对应的类别的得分;
分类单元306,用于将所有类别中得分最高的类别确定为该测试样本的类别。
由上述实施例可知,由于在对测试样本进行分类时,同时考虑了各个类别的权重和先验概率这两个因素,能够有效提高分类结果的准确性,并具有较强的鲁棒性。
在本实施例中,获取单元301可采用现有方法获得测试样本的K个最近邻样本。例如,可以根据实际需要设定K的数值,从而获得K个最近邻样本;也可以确定与测试样本的距离,将该距离内的所有样本作为测试样本的最近邻样本。
在本实施例中,分组单元302根据该K个最近邻样本的类别进行分组,其中,每个组对应于每个类别。
例如,K个最近邻样本一共具有T个类别,表示为C={C1,C2,…,CT}。那么,可按照K个最近邻样本中各个样本的类别将这些样本分为T个组,同一类别的样本被分在同一组,T个组分别表示为G1,G2,…,GT,各个组的样本数量分别表示为M1,M2,…,MT。
在本实施例中,第一计算单元303可使用现有方法计算每个组的权重。例如,可使用以下的公式(1)计算每个组的权重:
Wi=Mi/K (1)
其中,Wi表示第i组的权重,Mi表示第i组的样本数量,i=1,…,T,T表示K个最近邻样本的类别总数,也就是组的数量,T和i为正整数。
在本实施例中,第二计算单元304用于计算每个组的概率密度分布,并根据每个组的概率密度分布计算该测试样本对于每个组的先验概率,其中,可使用现有的方法计算概率密度分布和先验概率。
以下对本实施例的第二计算单元304的结构以及计算概率密度分布和先验概率的方法进行示例性的说明。
图4是本发明实施例1的第二计算单元304的组成示意图。如图4所示,第二计算单元304包括:
第四计算单元401,用于使用高斯分布计算每个组的均值向量和协方差矩阵;
第五计算单元402,用于根据每个组的均值向量和协方差矩阵,计算该测试样本对于每个组的先验概率。
在本实施例中,第四计算单元401可使用高斯分布计算每个组的均值向量和协方差矩阵,例如,可使用以下的公式(2)和(3)计算每个组的均值向量和协方差矩阵:
其中,Meani表示第i组的均值向量,Mi表示第i组的样本数量,xg_i表示属于第i组的样本,covi表示第i组的协方差矩阵,i=1,…,T,T表示组的数量,T和i为正整数。
第五计算单元402根据计算出的每个组的均值向量和协方差矩阵,计算该测试样本对于每个组的先验概率,例如,可使用以下的公式(4)计算该测试样本对于每个组的先验概率:
其中,Fi表示该测试样本对于第i组的先验概率,Meani表示第i组的均值向量,covi表示第i组的协方差矩阵,y表示该测试样本的向量,d表示向量的维数,i=1,…,T,T表示组的数量,T和i为正整数。
在本实施例中,第三计算单元305用于根据每个组的权重和该测试样本对于每个组的先验概率,计算每个组对应的类别的得分。其中,可使用多种方法计算每个组对应的类别的得分,只要考虑了每个组的权重和该测试样本对于每个组的先验概率这两个因素即可。
例如,将每个组的权重与所述测试样本对于每个组的先验概率的乘积、或者每个组的权重与所述测试样本对于每个组的先验概率之和、或者每个组的权重与所述测试样本对于每个组的先验概率的加权和,作为每个组对应的类别的得分。
例如,可根据以下的公式(5)计算每个组对应的类别的得分:
Zi=Wi*Fi (5)
其中,Zi表示第i组对应的类别的得分,Wi表示第i组的权重,Fi表示该测试样本对于第i组的先验概率,i=1,…,T,T表示组的数量,T和i为正整数。
例如,也可以根据以下的公式(6)计算每个组对应的类别的得分:
Zi=a*Wi+b*Fi (6)
其中,Zi表示第i组对应的类别的得分,Wi表示第i组的权重,Fi表示该测试样本对于第i组的先验概率,a表示权重的权重,b表示先验概率的权重,a+b=1,i=1,…,T, T表示组的数量,T和i为正整数。
在本实施例中,在第三计算单元305计算出每个组对应的类别的得分后,分类单元306用于将所有类别中得分最高的类别确定为该测试样本的类别。
在本实施例中,当分组单元302确定K个最近邻样本属于同一个类别时,则第一计算单元303、第二计算单元304以及第三计算单元305不工作,分类单元306直接将该K个最近邻样本属于的该类别确定为该测试样本的类别。
在本实施例中,该装置还可以包括:
设定单元307,用于设定K的取值,其中,当根据当前的K值计算出的所有类别的得分中的最高得分Z1与第二高得分Z2之比小于预定阈值t时,设定单元307将当前的K值加上预定的步长,该K值的初始值为预定范围的最小值A;
此时,分类单元306用于当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比大于或等于该预定阈值t时,将所有类别中得分最高的类别确定为该测试样本的类别。
在本实施例中,设定单元307为可选部件,在图3中用虚线框表示。
这样,根据最高得分与第二高得分之比自适应的设定K的取值,能够使得分类结果更加可靠。
在本实施例中,该预定范围的最小值A和最大值B以及该预定的步长Kstep可根据实际需要而设置。
例如,该预定范围[A,B]的最小值A可以为样本总量的十分之一,当样本总量较小时,该预定范围的最小值A可以为大于等于5的整数;该预定范围的最大值B可以为样本总量的五分之一;该预定的步长Kstep可以为2。
在本实施例中,该预定阈值t的数值可根据实际需要而设置,例如,该预定阈值t可以为1.1或1.2。
在本实施例中,分类单元306还用于在当前的K值大于或等于该预定范围的最大值B、且当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比小于该预定阈值t的情况下,将该测试样本的类别确定为:根据当前的K值以及之前的K值分别计算出的所有类别的得分中最高得分Z1与第二高得分Z2之比最大时具有该最高得分Z1的类别。也就是说,在上述情况下,根据当前的K值以及之前的各个K值分别计算出多个Z1/Z2,选取多个Z1/Z2中比值最大的Z1/Z2中具有最高得 分Z1的类别作为该测试样本的类别。
例如,假设预定阈值t=1.1,预定范围的最小值A=6,最大值B=10,当前的K值为K1=10,之前的K值包括K1和K2,K2=6,K3=8,其中,根据K1计算出的Z1/Z2=1.02,根据K2计算出的Z1/Z2=1.06,根据K3计算出的Z1/Z2=1.01,由于当前的K值已达到预定范围的最大值B,并且根据K1、K2和K3计算出的Z1/Z2均小于预定阈值t,其中,根据K2计算出的Z1/Z2最大,那么将具有根据K2计算出的最高得分Z1的类别作为该测试样本的类别。
这样,即使在K值增加至达到或超过该预定范围的最大值时仍然没有满足最高得分与第二高得分之比大于或等于该预定阈值的情况下,能够在当前的K值以及之前的所有K值中选择使得最高得分与第二高得分之比最大的K值,从而保证分类结果的可靠性。
由上述实施例可知,由于在对测试样本进行分类时,同时考虑了各个类别的权重和先验概率这两个因素,能够有效提高分类结果的准确性,并具有较强的鲁棒性。
另外,根据最高得分与第二高得分之比自适应的设定K的取值,能够使得分类结果更加可靠。
实施例2
本发明实施例还提供了一种电子设备,图5是本发明实施例2的电子设备的组成示意图。如图5所示,电子设备500包括最近邻分类装置501,其中,最近邻分类装置501的结构和功能与实施例1中的记载相同,此处不再赘述。
图6是本发明实施例2的电子设备的系统构成的一示意框图。如图6所示,电子设备600可以包括中央处理器601和存储器602;存储器602耦合到中央处理器601。该图是示例性的;还可以使用其它类型的结构,来补充或代替该结构,以实现电信功能或其它功能。
如图6所示,该电子设备600还可以包括:输入单元603、显示器604、电源605。
在一个实施方式中,实施例1所述的最近邻分类装置的功能可以被集成到中央处理器601中。其中,中央处理器601可以被配置为:获得测试样本的K个最近邻样本,K为正整数;根据所述K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;计算每个组的权重;计算每个组的概率密度分布,并根据每个组的概率密度分布计算所述测试样本对于每个组的先验概率;根据每个组的权重和所述测试样本 对于每个组的先验概率,计算每个组对应的类别的得分;将所有类别中得分最高的类别确定为所述测试样本的类别。
其中,所述计算每个组的概率密度分布,并根据每个组的概率密度分布计算所述测试样本对于每个组的先验概率,包括:使用高斯分布计算每个组的均值向量和协方差矩阵;根据每个组的均值向量和协方差矩阵,计算所述测试样本对于每个组的先验概率。
其中,中央处理器601还可以被配置为:设定K的取值,其中,当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比小于预定阈值时,所述设定单元将当前的K值加上预定的步长,所述K值的初始值为预定范围的最小值;所述将所有类别中得分最高的类别确定为所述测试样本的类别,包括:当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比大于或等于所述预定阈值时,将所有类别中得分最高的类别确定为所述测试样本的类别。
其中,中央处理器601还可以被配置为:在当前的K值大于或等于所述预定范围的最大值、且根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比小于所述预定阈值的情况下,将所述测试样本的类别确定为:根据当前的K值以及之前的K值分别计算出的所有类别的得分中最高得分与第二高得分之比最大时具有所述最高得分的类别。
其中,中央处理器601还可以被配置为:当所述K个最近邻样本属于同一个类别时,将所述K个最近邻样本属于的所述类别确定为所述测试样本的类别。
其中,所述根据每个组的权重和所述测试样本对于每个组的先验概率,计算每个组对应的类别的得分,包括:将每个组的权重与所述测试样本对于每个组的先验概率的乘积、或者每个组的权重与所述测试样本对于每个组的先验概率之和、或者每个组的权重与所述测试样本对于每个组的先验概率的加权和,作为每个组对应的类别的得分。
在另一个实施方式中,实施例1所述的最近邻分类装置可以与中央处理器601分开配置,例如可以将最近邻分类装置配置为与中央处理器601连接的芯片,通过中央处理器601的控制来实现最近邻分类装置的功能。
在本实施例中电子设备600也并不是必须要包括图6中所示的所有部件。
如图6所示,中央处理器601有时也称为控制器或操作控件,可以包括微处理器 或其它处理器装置和/或逻辑装置,中央处理器601接收输入并控制电子设备600的各个部件的操作。
存储器602,例如可以是缓存器、闪存、硬驱、可移动介质、易失性存储器、非易失性存储器或其它合适装置中的一种或更多种。并且中央处理器601可执行该存储器602存储的该程序,以实现信息存储或处理等。其它部件的功能与现有类似,此处不再赘述。电子设备600的各部件可以通过专用硬件、固件、软件或其结合来实现,而不偏离本发明的范围。
由上述实施例可知,由于在对测试样本进行分类时,同时考虑了各个类别的权重和先验概率这两个因素,能够有效提高分类结果的准确性,并具有较强的鲁棒性。
另外,根据最高得分与第二高得分之比自适应的设定K的取值,能够使得分类结果更加可靠。
实施例3
本发明实施例还提供一种最近邻分类方法,其对应于实施例1的最近邻分类装置。图7是本发明实施例3的最近邻分类方法流程图。如图7所示,该方法包括:
步骤701:获得测试样本的K个最近邻样本,K为正整数;
步骤702:根据该K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;
步骤703:计算每个组的权重;
步骤704:计算每个组的概率密度分布,并根据每个组的概率密度分布计算该测试样本对于每个组的先验概率;
步骤705:根据每个组的权重和该测试样本对于每个组的先验概率,计算每个组对应的类别的得分;
步骤706:将所有类别中得分最高的类别确定为该测试样本的类别。
在本实施例中,获得K个最近邻样本的方法、对K个最近邻样本进行分组的方法、计算每个组的权重、概率密度分布以及该测试样本对于每个组的先验概率的方法、计算每个组对应的类别的得分的方法与实施例1中的记载相同,此处不再赘述。
由上述实施例可知,由于在对测试样本进行分类时,同时考虑了各个类别的权重和先验概率这两个因素,能够有效提高分类结果的准确性,并具有较强的鲁棒性。
另外,根据最高得分与第二高得分之比自适应的设定K的取值,能够使得分类 结果更加可靠。
实施例4
本发明实施例还提供一种最近邻分类方法,其对应于实施例1的最近邻分类装置。图8是本发明实施例4的最近邻分类方法流程图。如图8所示,该方法包括:
步骤801:将K值的初始值设为预定范围[A,B]的最小值A,K为正整数;
步骤802:获得测试样本的K个最近邻样本;
步骤803:根据该K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;
步骤804:计算每个组的权重;
步骤805:计算每个组的概率密度分布,并根据每个组的概率密度分布计算该测试样本对于每个组的先验概率;
步骤806:根据每个组的权重和该测试样本对于每个组的先验概率,计算每个组对应的类别的得分;
步骤807:判断所有类别的得分中的最高得分Z1与第二高得分Z2之比是否大于或等于预定阈值t,当判断结果为“否”时,进入步骤808,当判断结果为“是”时,进入步骤811;
步骤808:判断当前的K值是否小于该预定范围[A,B]的最大值B,当判断结果为“是”时,进入步骤809,当判断结果为“否”时,进入步骤810;
步骤809:将当前的K值加上预定的步长Kstep;
步骤810:将该测试样本的类别确定为:根据当前的K值以及之前的K值分别计算出的所有类别的得分中最高得分Z1与第二高得分Z2之比最大时具有该最高得分Z1的类别;
步骤811:将所有类别中得分最高的类别确定为该测试样本的类别。
在本实施例中,获得K个最近邻样本的方法、对K个最近邻样本进行分组的方法、计算每个组的权重、概率密度分布以及该测试样本对于每个组的先验概率的方法、计算每个组对应的类别的得分的方法与实施例1中的记载相同,此处不再赘述。
由上述实施例可知,由于在对测试样本进行分类时,同时考虑了各个类别的权重和先验概率这两个因素,能够有效提高分类结果的准确性,并具有较强的鲁棒性。
另外,根据最高得分与第二高得分之比自适应的设定K的取值,能够使得分类 结果更加可靠。
本发明实施例还提供一种计算机可读程序,其中当在最近邻分类装置或电子设备中执行所述程序时,所述程序使得计算机在所述最近邻分类装置或电子设备中执行实施例3或实施例4所述的最近邻分类方法。
本发明实施例还提供一种存储有计算机可读程序的存储介质,其中所述计算机可读程序使得计算机在最近邻分类装置或电子设备中执行实施例3或实施例4所述的最近邻分类方法。
本发明以上的装置和方法可以由硬件实现,也可以由硬件结合软件实现。本发明涉及这样的计算机可读程序,当该程序被逻辑部件所执行时,能够使该逻辑部件实现上文所述的装置或构成部件,或使该逻辑部件实现上文所述的各种方法或步骤。本发明还涉及用于存储以上程序的存储介质,如硬盘、磁盘、光盘、DVD、flash存储器等。
以上结合具体的实施方式对本发明进行了描述,但本领域技术人员应该清楚,这些描述都是示例性的,并不是对本发明保护范围的限制。本领域技术人员可以根据本发明的精神和原理对本发明做出各种变型和修改,这些变型和修改也在本发明的范围内。
关于包括以上实施例的实施方式,还公开下述的附记:
附记1、一种最近邻分类装置,包括:
获取单元,所述获取单元用于获得测试样本的K个最近邻样本,K为正整数;
分组单元,所述分组单元用于根据所述K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;
第一计算单元,所述第一计算单元用于计算每个组的权重;
第二计算单元,所述第二计算单元用于计算每个组的概率密度分布,并根据每个组的概率密度分布计算所述测试样本对于每个组的先验概率;
第三计算单元,所述第三计算单元用于根据每个组的权重和所述测试样本对于每个组的先验概率,计算每个组对应的类别的得分;
分类单元,所述分类单元用于将所有类别中得分最高的类别确定为所述测试样本的类别。
附记2、根据附记1所述的装置,其中,所述第二计算单元包括:
第四计算单元,所述第四计算单元用于使用高斯分布计算每个组的均值向量和协方差矩阵;
第五计算单元,所述第五计算单元用于根据每个组的均值向量和协方差矩阵,计算所述测试样本对于每个组的先验概率。
附记3、根据附记1所述的装置,其中,所述装置还包括:
设定单元,所述设定单元用于设定K的取值,其中,当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比小于预定阈值时,所述设定单元将当前的K值加上预定的步长,所述K值的初始值为预定范围的最小值;
所述分类单元用于当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比大于或等于所述预定阈值时,将所有类别中得分最高的类别确定为所述测试样本的类别。
附记4、根据附记3所述的装置,其中,
所述分类单元还用于在当前的K值大于或等于所述预定范围的最大值、且当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比小于所述预定阈值的情况下,将所述测试样本的类别确定为:根据当前的K值以及之前的K值分别计算出的所有类别的得分中最高得分与第二高得分之比最大时具有所述最高得分的类别。
附记5、根据附记1所述的装置,其中,
所述分类单元还用于当所述分组单元确定所述K个最近邻样本属于同一个类别时,将所述K个最近邻样本属于的所述类别确定为所述测试样本的类别。
附记6、根据附记1所述的装置,其中,
所述第三计算单元用于将每个组的权重与所述测试样本对于每个组的先验概率的乘积、或者每个组的权重与所述测试样本对于每个组的先验概率之和、或者每个组的权重与所述测试样本对于每个组的先验概率的加权和,作为每个组对应的类别的得分。
附记7、一种最近邻分类方法,包括:
获得测试样本的K个最近邻样本,K为正整数;
根据所述K个最近邻样本的类别进行分组,其中,每个组对应于每个类别;
计算每个组的权重;
计算每个组的概率密度分布,并根据每个组的概率密度分布计算所述测试样本对于每个组的先验概率;
根据每个组的权重和所述测试样本对于每个组的先验概率,计算每个组对应的类别的得分;
将所有类别中得分最高的类别确定为所述测试样本的类别。
附记8、根据附记7所述的方法,其中,所述计算每个组的概率密度分布,并根据每个组的概率密度分布计算所述测试样本对于每个组的先验概率,包括:
使用高斯分布计算每个组的均值向量和协方差矩阵;
根据每个组的均值向量和协方差矩阵,计算所述测试样本对于每个组的先验概率。
附记9、根据附记7所述的方法,其中,所述方法还包括:
设定K的取值,其中,当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比小于预定阈值时,所述设定单元将当前的K值加上预定的步长,所述K值的初始值为预定范围的最小值;
所述将所有类别中得分最高的类别确定为所述测试样本的类别,包括:当根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比大于或等于所述预定阈值时,将所有类别中得分最高的类别确定为所述测试样本的类别。
附记10、根据附记9所述的方法,其中,所述方法还包括:
在当前的K值大于或等于所述预定范围的最大值、且根据当前的K值计算出的所有类别的得分中的最高得分与第二高得分之比小于所述预定阈值的情况下,将所述测试样本的类别确定为:根据当前的K值以及之前的K值分别计算出的所有类别的得分中最高得分与第二高得分之比最大时具有所述最高得分的类别。
附记11、根据附记7所述的方法,其中,所述方法还包括:
当所述K个最近邻样本属于同一个类别时,将所述K个最近邻样本属于的所述类别确定为所述测试样本的类别。
附记12、根据附记7所述的方法,其中,
所述根据每个组的权重和所述测试样本对于每个组的先验概率,计算每个组对应的类别的得分,包括:将每个组的权重与所述测试样本对于每个组的先验概率的乘积、或者每个组的权重与所述测试样本对于每个组的先验概率之和、或者每个组的权重与所述测试样本对于每个组的先验概率的加权和,作为每个组对应的类别的得分。
- 还没有人留言评论。精彩留言会获得点赞!