容量扩展方法及装置与流程
本发明涉及通信领域,具体而言,涉及一种容量扩展方法及装置。
背景技术:
云计算(Cloud Computing)是网格计算(Grid Computing)、分布式计算(Distributed Computing)、并行计算(Parallel Computing)、效用计算(Utility Computing)网络存储(Network Storage Technologies)、虚拟化(Virtualization)、负载均衡(Load Balance)等传统计算机技术和网络技术发展融合的产物。它旨在通过网络把多个成本相对较低的计算实体整合成一个具有强大计算能力的系统。分布式存储是云计算范畴中的一个领域,其作用是提供海量数据的分布式存储服务以及高速读写访问的能力。
分布式存储系统是由若干服务器节点(以下简称“节点”)和客户端互相连接构成的。所述数据由键(Key)和值(Value)构成,Key相当于数据的索引,Value是Key所代表的数据内容。逻辑上Key和Value是一对一的关系。为方便管理数据,将数据按不同应用划分为不同的空间,每个空间划分为多个分片,然后将数据按分片放入节点进行存储和管理,节点和分片是一对多的关系。为实现分片间数据的均衡分布,将key通过一定算法(MD5等)生成key的Hash值,通过一定的算法计算该hash值对应的分片ID(如对hash值按分片总数取模),从而将数据均匀分布在空间的各个分片上,这样只要按节点存储能力调整其上分片的个数即可充分利用系统资源。
在分布式存储系统中,一个常见的问题是随着应用规模的扩大原有存储系统无法承担更多的应用数据,最简单的方法就是向分布式存储系统中增加节点,而问题的关键在于如何在不影响系统正常工作的前提下让新增加的节点承担起数据存储服务。如果系统中分片的数量远大于节点个数则可以将部分分片通过迁移的方式调整到新的节点上使新节点承担起数据存储服务,而如果分片数较少呢?在分片数仅比节点多一些的情况下,迁移分片至新节点虽然能让新节点承担起数据存储服务,但很难根据节点能力调整节点负荷,容易导致节点间负荷不均;更严重的情况是分片数小于系统当前节点数,同一个分片只能在一个节点上,这样就导致部分节点没有分片,严重浪费资源。
针对上述问题,相关技术方案中,数据迁移一般采用以下解决方法:
通过预估将来系统的规模,按将来的规模对初始分片数进行配置;当前系统可能只有三个节点,但是预计将来可能扩容为1000个节点的大型分布式系统,故现在就将分片数配置为10000个或者更多,从而使新节点的加入只需要通过迁移分片就可以简单完成。这种方案的问题在于分片本身是有额外开销的,节点每多一个分片就会多一份开销,原来1G数据存储的额外开销可能是10M,而现在因为单个节点分片多了则可能变成100M 甚至更多,需要等到预估的将来才能降至10M;原来新增加一个节点可能只需要迁移10个分片,而现在则是1000个甚至更多,虽然数据量上来看可能相差不多,但流程上增加了100倍,出问题的概率也增加了100倍。
随着技术的发展,目前方案1还出现了一种演进版本,即轻量级的分片。分片的开销低了,同样规模的分布式系统就可以有更多的分片,但分片的开销并不会凭空消失,如原来需要分片管理的资源分配现在分片不管理了交给了节点,因为范围扩大了,分配资源可能遭遇更大的锁冲突。
针对相关技术中,在系统运行初期预先设置大量分片,导致分片开销太大的问题,尚未提出有效地解决方案。
技术实现要素:
本发明提供了一种容量扩展方法及装置,以至少解决相关技术中在扩容过程中,需要预先设置大量分片,导致分片开销太大的问题。
根据本发明的一个方面,提供了一种容量扩展方法,包括:获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,所述当前分布式数据存储系统中包括新增服务器节点和初始服务器节点;根据所述服务器节点的节点数量对所述当前分布式数据存储系统中所述初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;在所述当前分布式数据存储系统中重新分布所述扩展后的分片数据,以使所述新增服务器节点和所述初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。
可选地,根据所述服务器节点的节点数量对所述当前分布式数据存储系统中所述初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据包括:判断所述初始服务器节点上的分片数据的分片数量是否大于所述服务器节点的节点数量;若所述初始服务器节点上的分片数据的分片数量小于所述服务器节点的节点数量,则在所述初始服务器节点中按照所述初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展,以得到所述扩展后的分片数据。
可选地,所述在所述初始服务器节点中按照所述初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展包括:对所述初始服务器节点中分片号为i的分片数据按照预定倍数X进行分裂扩展,以得到扩展后的分片号集合(i*X,i*X+X-1),其中,所述i为0到所述初始服务器节点中的分片数据的分片总量之间的任意一个自然数;建立与扩展后的所述分片号集合中每一个分片号对应的过滤器和指针,以得到用于访问扩展后的每一个分片号对应的分片数据的连接。
可选地,在所述当前分布式数据存储系统中重新分布所述扩展后的分片数据包括:根据最小迁移路径生成迁移列表,其中,所述迁移列表中至少包括待迁移的分片数据, 以及所述待迁移的分片数据在迁移前的源服务器节点地址和在迁移后的目标服务器节点地址;将所述待迁移的分片数据按照所述迁移列表由所述源服务器节点复制迁移至所述目标服务器节点。
可选地,在将所述待迁移的分片数据按照所述迁移列表由所述源服务器节点复制迁移至所述目标服务器节点时,还包括:接收客户端发送的操作请求,其中,所述操作请求用于对所述待迁移的分片数据执行预定操作;响应所述操作请求对所述初始服务器中的分片数据执行所述预定操作,并将所述预定操作的操作记录保存到Redo日志中,其中,所述操作记录用于对迁移后的所述服务器节点中的分片数据执行所述预定操作。
可选地,在将所述待迁移的分片数据按照所述迁移列表由所述源服务器节点复制迁移至所述目标服务器节点时,还包括:若已完成所述迁移的分片数据的分片数量大于等于预定阈值,则锁定所述初始服务器节点中的分片数据,其中,在锁定所述初始服务器节点中的分片数据之后,所述初始服务器节点中的分片数据将拒绝执行所述操作。
根据本发明的另一方面,提供了一种容量扩展装置,包括:获取模块,用于获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,所述当前分布式数据存储系统中包括新增服务器节点和初始服务器节点;第一处理模块,用于根据所述服务器节点的节点数量对所述当前分布式数据存储系统中所述初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;第二处理模块,用于在所述当前分布式数据存储系统中重新分布所述扩展后的分片数据,以使所述新增服务器节点和所述初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。
可选地,所述第一处理模块包括:判断单元,用于判断所述初始服务器节点上的分片数据的分片数量是否大于所述服务器节点的节点数量;处理单元,用于在所述初始服务器节点上的分片数据的分片数量小于所述服务器节点的节点数量时,在所述初始服务器节点中按照所述初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展,以得到所述扩展后的分片数据。
可选地,所述处理单元包括:第一处理子单元,用于对所述初始服务器节点中分片号为i的分片数据按照预定倍数X进行分裂扩展,以得到扩展后的分片号集合(i*X,i*X+X-1),其中,所述i为0到所述初始服务器节点中的分片数据的分片总量之间的任意一个自然数;创建子单元,用于建立与扩展后的所述分片号集合中每一个分片号对应的过滤器和指针,以得到用于访问扩展后的每一个分片号对应的分片数据的连接。
可选地,所述第二处理模块包括:获取单元,用于根据最小迁移路径生成迁移列表,其中,所述迁移列表中至少包括待迁移的分片数据,以及所述待迁移的分片数据在迁移前的源服务器节点地址和在迁移后的目标服务器节点地址;迁移单元,用于将所述待迁移的分片数据按照所述迁移列表由所述源服务器节点复制迁移至所述目标服务器节点。
可选地,所述迁移单元包括:接收子单元,用于接收客户端发送的操作请求,其中, 所述操作请求用于对所述待迁移的分片数据执行预定操作;第二处理子单元,用于响应所述操作请求对所述初始服务器中的分片数据执行所述预定操作,并将所述预定操作的操作记录保存到Redo日志中,其中,所述操作记录用于对迁移后的所述服务器节点中的分片数据执行所述预定操作。
可选地,所述迁移单元还用于在已完成所述迁移的分片数据的分片数量大于等于预定阈值时,锁定所述初始服务器节点中的分片数据,其中,在锁定所述初始服务器节点中的分片数据之后,所述初始服务器节点中的分片数据将拒绝执行所述操作。
通过本发明,获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,该当前分布式数据存储系统中包括新增服务器节点和初始服务器节点;根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;在当前分布式数据存储系统中重新分布扩展后的分片数据,以使该新增服务器节点和该初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。也就是说,可以根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据,并在当前分布式数据存储系统中重新分布扩展后的分片数据,以满足服务器节点的扩容需求,解决了相关技术在系统运行初期预先设置大量分片,导致分片开销太大的问题,进而达到了减小分片开销的效果,
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是根据本发明实施例的容量扩展方法的流程图;
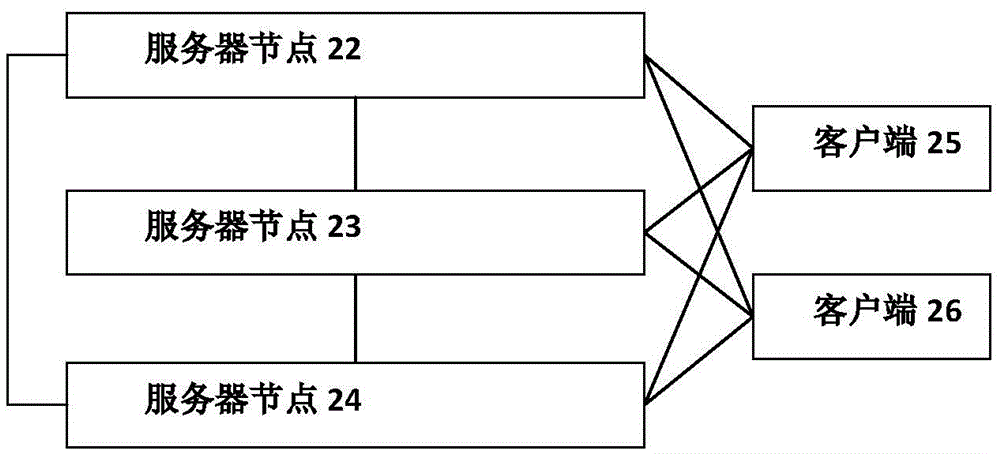
图2是根据本发明实施例的由服务器节点和客户端构成的分布式存储系统架构示意图;
图3是根据本发明实施例的存储系统扩容操作流程图;
图4是根据本发明实施例的容量扩展装置的结构框图;
图5是根据本发明实施例的容量扩展装置的结构框图(一);
图6是根据本发明实施例的容量扩展装置的结构框图(二);
图7是根据本发明实施例的容量扩展装置的结构框图(三);
图8是根据本发明实施例的容量扩展装置的结构框图(四)。
具体实施方式
下文中将参考附图并结合实施例来详细说明本发明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
实施例1
在本实施例中提供了一种容量扩展方法,图1是根据本发明实施例的容量扩展方法的流程图,如图1所示,该流程包括如下步骤:
步骤S102,获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,当前分布式数据存储系统中包括新增服务器节点和初始服务器节点;
步骤S104,根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;
步骤S106,在当前分布式数据存储系统中重新分布扩展后的分片数据,以使该新增服务器节点和该初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。
可选地,在本实施例中,上述容量扩展方法包括但并不限于应用于云计算分布式存储系统中进行系统扩容的过程中。在该应用场景下,获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,当前分布式数据存储系统中包括新增服务器节点和初始服务器节点;根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;在当前分布式数据存储系统中重新分布扩展后的分片数据,以使该新增服务器节点和该初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。也就是说,可以根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据,并在当前分布式数据存储系统中重新分布扩展后的分片数据,以满足服务器节点的扩容需求,解决了相关技术在系统运行初期预先设置大量分片,导致分片开销太大的问题,进而达到了减小分片开销的效果。
需要说明的是,根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据。其中,分裂扩展可以包括但不限于:将初始服务器节点中的原有分片按照预定倍数进行分裂扩展,得到扩展后的分片数据。以使扩展后的分片数据的分片数量满足包含新增服务器节点的服务器节点的扩容需要。
可选地,在本实施例中,在初始服务器节点中按照初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展的方法包括但并不限于:对初始服务器中分片号为i的分片数据按照预定倍数X进行分裂扩展,以得到扩展后的分片号集合。例如,假设原有8个分片数据,则可以按照预定倍数X进行分裂,则扩展后的分片数据为8X,使分裂 后的分片数量满足系统扩容需要。在此,假设将上述8个分片数据中分片号i=1的分片数据,按照预定倍数8倍(即X=8)进行分裂扩展,那么原分片号为0的分片数据在分裂扩展后,所得到的扩展后的分片号集合中的分片号为(0~7),原分片号为1的分片数据在分裂扩展后,所得到的扩展后的分片号集合中的分片号为(8~15),依次类推,将得到与8个分片数据分别对应的扩展后的分片号集合。
需要说明的是,本实施例中涉及的预定条件包括但并不限于:每一服务器节点的分片负载是否均衡。
可选地,本实施例中,在当前分布式数据存储系统中重新分布该扩展后的分片数据的方法包括但并不限于:根据最小迁移路径生成迁移列表,将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至该目标服务器节点。
下面结合具体示例,对本实施例作举例说明。
本发明主要包括以下步骤,其中,需要说明的是,在以下示例中,新增服务器节点以新节点为例,初始服务器节点以原有节点为例:
前置步骤:客户端与分布式存储系统中多个服务器节点(假设服务器节点A用节点A表示、服务器节点B用节点B表示、服务器节点C用节点C表示)建立连接,服务器节点间互相建立连接并且运行正常,客户端连续不断地发起不同的请求至服务器节点;为应对应用规模的增大,现新增N个服务器节点(假设服务器节点X用节点X表示、服务器节点Y用节点Y表示、服务器节点Z用节点Z表示),新节点已完成和原有节点、客户端的建链工作,而数据目前仍然在原节点上。
步骤S11:判断当前系统中分片数是否满足扩容的需要(由特定算法实现,保证重分布后各节点上分片数达到合理数量),如分片数不足则执行步骤S12,否则执行步骤S14;
步骤S12:将分片总数按倍数进行分裂(如原先有8个分片则分裂为16、24……8X),使分裂后的总数满足系统扩容需要。假设分裂为8X个分片,分裂前的路由用R1表示仅含有8个分片的路由信息,分裂后的路由R2则含有8X个分片的路由信息,原分片i对应新的分片(iX)~(iX+X-1),原分片均匀分散在8X中;该步骤不执行数据分裂,仅相对于对原有分片生成了X个连接,每个连接创建一个过滤器使其仅连接原分片的1/X数据。
步骤S13:在步骤S12中将路由R1分裂为了路由R2,但是因为系统是分布式环境,节点和客户端之间路由同步需要一定的时间,为了保证在该过程中保证服务仍然可用,将服务端原有路由R1仍然保留,因为步骤S12中的分裂并非真正的分裂,数据仍然还是旧的分布方式。故通过路由R1仍然可以访问到正确的存储地址,所以在允许R1正常使用的情况下,步骤S12的分裂对系统可用性是没有影响的,在当前步骤中监控路由R2 的同步情况,当R2在分布式系统中完成同步时使路由R1不可用,完成新旧路由的切换;
步骤S14:现在分片数足以满足系统扩容需要,按分片重新计算节点间的数据分布产生迁移列表,使分片数据从原节点上迁移至新节点上。按以下步骤分别执行迁移列表中的迁移任务:
步骤S15:执行迁移任务,将分片数据从源节点迁移至目的节点,迁移过程中记录Redo日志,当迁移快结束时使分片不可用,完成迁移后恢复,在分片数据不可用的短暂时间内服务端收到服务请求后退回客户端重试(分布式系统多副本机制也可以容忍单点故障),因不可用时间在毫秒ms级故通过重试即可完成服务对应用没有影响。
上述步骤S11至步骤S15为系统节点间数据迁移的场景。
进一步地,上述步骤中涉及到的Redo日志是用于记录对数据进行的操作,用于重做相关的操作,本实施例中用于记录迁移过程中外部请求对数据的操作,方便在迁移结束后根据记录重新操作相应数据,从而保证数据的一致性。
上述步骤S13、S15体现了本发明实施例中数据迁移对系统正常工作的无影响。相对于相关技术中预先设置大量分片实现扩容的方式,本发明实施例中分片数在合理范围内开销很小,体现了本发明实施例的技术优势;相对于现有技术中通过扩展Hash范围,然后通过查表的方式获取分片数据路由,导致了路由时间复杂度大的问题。而实施例中路由仍然可以通过简单计算获取,时间复杂度在O(1),体现了本实施例的性能优势。
进一步地,步骤S15中,虽然节点在迁移的最后阶段停止了对客户端关于被迁移数据的服务,但因为系统是分布式的设计时就考虑了某个节点不工作的情况(多副本机制、请求重试机制等),且停止服务的时间很短故系统的正常工作不会受到影响。对客户端来说本次迁移完全是透明的。
通过本实施例,提出了一种高可用而可靠的分布式存储系统中扩容的方案,解决了相关技术在扩容过程中,需要预先设置大量分片,导致分片开销太大的问题,进一步解决了相关技术中通过扩展Hash范围,然后通过查表的方式获取分片数据路由,导致路由时间复杂度大的问题。
在一个可选的实施方式中,根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据包括以下步骤:
步骤S21,判断初始服务器节点上的分片数据的分片数量是否大于服务器节点的节点数量;
步骤S22,若初始服务器节点上的分片数据的分片数量小于服务器节点的节点数量,则在初始服务器节点中按照初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展,以得到扩展后的分片数据。
可选地,在本实施例中,判断初始服务器节点上的分片数据的分片数量是否大于服务器节点的节点数量的方法包括但并不限于:用初始服务器节点中的分片数据的分片总量除以服务器节点总量(其中服务器节点总量包括新增服务器节点和初始服务器节点),若得到的计算结果过小,则需对初始服务器节点中的分片数据的分片数量进行分裂扩展,以满足各个服务器节点都有分片数据,进而克服现有技术中只有部分服务器节点中有分片数据,部分服务器节点中没有分片数据,所造成的分片数据分布不均衡的问题。此外,若得到的计算结果大于预定阈值,则可直接对初始服务器节点中的分片数据进行容量扩展,以使新增服务器节点与初始服务器节点上的分片数据分布均衡。
通过上述步骤,根据判断初始服务器节点上的分片数据的分片数量是否大于服务器节点的节点数量,如果否,则在初始服务器节点中按照初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展,以得到扩展后的分片数据,进一步解决了在系统运行初期预先设置大量分片,导致分片开销太大的问题。
在一个可选的实施方式中,在初始服务器节点中按照初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展可以通过以下步骤实现:
步骤S31,对初始服务器节点中分片号为i的分片数据按照预定倍数X进行分裂扩展,以得到扩展后的分片号集合(i*X,i*X+X-1);
步骤S32,建立与扩展后的该分片号集合中每一个分片号对应的过滤器和指针,以得到用于访问扩展后的每一个分片号对应的分片数据的连接。
可选地,在本实施例中,具体是通过在扩容过程中,对初始服务器中分片号为i的分片数据按照该预定倍数X进行分裂扩展,以得到扩展后的分片号集合,并通过建立与扩展后的分片号集合中的每一个分片号对应的过滤器和指针,以得到与扩展后的每一个分片号对应的分片数据的连接。而不同于相关技术中,通过预先设置大量分片,导致分片开销太大的问题,而是根据服务器节点和分片总量之间的关系,分裂当前分片数据得到扩展后的分片数据集合。
需要说明的是,上述步骤S21中涉及到的i为0到初始服务器节点中的分片数据的分片总量之间的任意一个自然数。
例如,假设i为1,预定倍数X为8,那么对初始服务器中分片号为1的分片数据按照预定倍数8进行分裂扩展,以得到扩展后的分片号集合(8,15)。进一步地,在本实施例中,并不是执行真正意义上的数据分裂,仅相对于对原有分片生成了多个连接,每个连接创建一个过滤器和指针,使其仅连接原分片的1/8数据。
通过上述步骤,建立扩展后的每一个分片号对应的分片数据的连接,而不是执行数据分裂,进而使得在迁移过程中,数据可以仍然使用原有路由,避免数据中断。
在一个可选的实施方式中,在当前分布式数据存储系统中重新分布扩展后的分片数 据包括以下步骤:
步骤S41,根据最小迁移路径生成迁移列表;
步骤S42,将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至目标服务器节点。
可选地,在本实施例中,具体是根据最小迁移路径生成的迁移列表,将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至目标服务器节点。
需要说明的是,上述步骤中涉及到的迁移列表中至少包括待迁移的分片数据,以及待迁移的分片数据在迁移前的源服务器节点地址和在迁移后的目标服务器节点地址。
通过上述步骤,根据最小迁移路径生成的迁移列表,将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至目标服务器节点,进一步解决了相关技术在扩容过程中,需要预先设置大量分片,导致分片开销太大的问题。
在一个可选的实施方式中,在将待迁移的分片数据按照迁移列表由该源服务器节点复制迁移至该目标服务器节点时,还包括以下步骤:
步骤S51,接收客户端发送的操作请求,其中,操作请求用于对待迁移的分片数据执行预定操作;
步骤S52,响应操作请求对初始服务器中的分片数据执行操作该预定操作,并将预定操作的操作记录保存到Redo日志中,其中,操作记录用于对迁移后的服务器节点中的分片数据执行该预定操作。
通过上述步骤,将操作记录保存到重做(Redo)日志中,方便在迁移结束后根据记录重新操作相应数据,从而保证了数据的一致性。
在一个可选的实施方式中,在将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至该目标服务器节点时,还包括以下步骤:
步骤S61,若已完成迁移的分片数据的分片数量大于等于预定阈值,则锁定该初始服务器节点中的分片数据,其中,在锁定该初始服务器节点中的分片数据之后,该初始服务器节点中的分片数据将拒绝执行该操作。
需要说明的是,在本实施例中,上述预定阈值可以是已完成迁移的分片数据的分片数量占总分片数量的比值大于等于80%。可以根据实际迁移过程设置,并不做限定。
可选地,在本实施例中,首先得判断已完成迁移的分片数据的分片数量是否大于等于预定阈值,如果大于,则锁定该初始服务器节点中的分片数据,使得初始服务器中的分片数据为不可用状态;如果小于预定阈值,则可以继续访问初始服务器节点中的分片数据。
通过上述步骤,解决了相关技术中在扩容时,造成数据访问中断的问题,使得系统扩容对整个系统的持续稳定工作无影响,对客户端完全透明,达到了扩容速度快、效率高、开销小的效果。
下面结合具体示例,对本实施例作举例说明。
本实施例可以是在云计算领域分布式存储系统中,解决系统扩容问题。具体地,本发明提出了一系列措施,使得系统扩容对整个系统的持续稳定工作无影响,进而达到对客户端完全透明,且扩容速度快、效率高、开销小的效果。
图2是根据本发明实施例的由服务器节点和客户端构成的分布式存储系统架构示意图。如图2所示,包括服务器节点22至服务器节点24,和客户端25和客户端26。其中,扩容包括新增服务器节点需要完成和原服务器节点及客户端之间的连接、数据重分布两个部分,连接建立过程相对简单,本发明不做详细描述。节点间的数据分布以分片为最小分布单元,扩容后需要将一部分分片迁移至新节点以保证系统中各节点负荷均衡。
在图2所示系统架构下,下面结合图3对本实施例作进一步说明。图3是根据本发明实施例的存储系统扩容操作流程图。其中,需要说明的是,在以下示例中,初始服务器节点以原节点为例,新增服务器节点以新节点为例,Redo日志即为重做日志。其中,包括如下步骤:
前置步骤:客户端31持续发起请求,整个存储系统32正常工作中,新节点34已完成和原节点33、客户端31的链路连接。
步骤S301,计算当前的存储系统32中分片数量是否满足扩容需要,是否能保证扩容后各个节点有足够的分片以保证负载均衡,如分片数量不足则执行步骤S302,分裂分片;如分片数量足够则直接跳至步骤S306;
步骤S302,计算分片分裂倍数,计算需要将分片数量分裂为多少倍才能满足扩容需要,假设为X倍(X>1);
步骤S303,将原有路由R1分裂为R2,使分片数扩大X倍,其中原有分片i分裂为分片iX~(iX+X-1),分裂后新分片对应的存储位置不变,新分片在节点中由过滤器及指向原有分片的指针组成,相当于原分片部分数据(1/X)的连接,分片的大多数服务由原分片处理。
步骤S304,同步路由至客户端;
步骤S305,检查新路由是否同步完成,在分裂及同步过程中因数据存储位置等没有改变,原路由仍然可用,客户端31仍然可以通过原路由R1访问服务执行读写请求,存储系统32可用性不受影响;
步骤S306,当分裂和同步执行完成后,使旧路由R1对客户端31不可用,客户端 31只能通过新路由R2访问服务执行读写请求,因客户端31已完成路由R2的同步,故存储系统32可用性也不受影响;
步骤S307,计算生成迁移列表,列表中的每一项表示一个分片的迁移路径,在图3中具体是从原节点33迁移至新节点34,使存储系统32通过执行迁移列表中的迁移任务完成整个存储系统32的数据重分布;
步骤S308,执行迁移任务,原节点33将该分片中的数据发送至新节点34(通过过滤器可以将非本分片的数据过滤掉);
步骤S309,新节点34保存数据。在迁移数据过程中因原节点33仍然在提供数据读写服务,故在原节点33分片上记录Redo日志;
步骤S310,原节点33在发送完数据后发送Redo日志;
步骤S311,新节点34收到Redo日志后执行数据重建;在这一过程中需要保证新节点34数据重建的速度高于源节点数据变更速度;
步骤S312,在原节点33传输Redo日志快结束时停止原节点33分片的服务,发送最后的Redo日志。新节点34收到日志后数据重建完成后由新节点34恢复服务;该分片停止服务的时间内由多副本机制及请求重试机制保证系统的可用性;
步骤S313,完成迁移列表中所有迁移任务,至此整个存储系统32扩容完成;
步骤S314,启动服务。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
实施例2
在本实施例中还提供了一种容量扩展装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
图4是根据本发明实施例的容量扩展装置的结构框图,如图4所示,该装置包括:
1)获取模块42,用于获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,该当前分布式数据存储系统中包括新增服务器节点和初始服 务器节点;
2)第一处理模块44,用于根据该服务器节点的节点数量对该当前分布式数据存储系统中该初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;
3)第二处理模块46,用于在该当前分布式数据存储系统中重新分布该扩展后的分片数据,以使该新增服务器节点和该初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。
可选地,在本实施例中,上述容量扩展方法包括但并不限于应用于云计算分布式存储系统中进行系统扩容的过程中。在该应用场景下,获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,当前分布式数据存储系统中包括新增服务器节点和初始服务器节点;根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;在当前分布式数据存储系统中重新分布扩展后的分片数据,以使该新增服务器节点和该初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。也就是说,可以根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据,并在当前分布式数据存储系统中重新分布扩展后的分片数据,以满足服务器节点的扩容需求,解决了相关技术在系统运行初期预先设置大量分片,导致分片开销太大的问题,进而达到了减小分片开销的效果。
需要说明的是,根据服务器节点的节点数量对当前分布式数据存储系统中初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据。其中,分裂扩展可以包括但不限于:将初始服务器节点中的原有分片按照预定倍数进行分裂扩展,得到扩展后的分片数据。以使扩展后的分片数据的分片数量满足包含新增服务器节点的服务器节点的扩容需要。
可选地,在本实施例中,在初始服务器节点中按照初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展的方法包括但并不限于:对初始服务器中分片号为i的分片数据按照预定倍数X进行分裂扩展,以得到扩展后的分片号集合。例如,假设原有8个分片数据,则可以按照预定倍数X进行分裂,则扩展后的分片数据为8X,使分裂后的分片数量满足系统扩容需要。在此,假设将上述8个分片数据中分片号i=1的分片数据,按照预定倍数8倍(即X=8)进行分裂扩展,那么原分片号为0的分片数据在分裂扩展后,所得到的扩展后的分片号集合中的分片号为(0~7),原分片号为1的分片数据在分裂扩展后,所得到的扩展后的分片号集合中的分片号为(8~15),依次类推,将得到与8个分片数据分别对应的扩展后的分片号集合。
需要说明的是,本实施例中涉及的预定条件包括但并不限于:每一服务器节点的分片负载是否均衡。
可选地,本实施例中,在当前分布式数据存储系统中重新分布该扩展后的分片数据 的方法包括但并不限于:根据最小迁移路径生成迁移列表,将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至该目标服务器节点。
在一个可选地实施方式中,图5是根据本发明实施例的容量扩展装置的结构框图(一),如图5所示,第一处理模块44包括:
1)判断单元52,用于判断该初始服务器节点上的分片数据的分片数量是否大于该服务器节点的节点数量;
2)处理单元54,用于在该初始服务器节点上的分片数据的分片数量小于该服务器节点的节点数量时,在该初始服务器节点中按照该初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展,以得到该扩展后的分片数据。
可选地,在本实施例中,判断初始服务器节点上的分片数据的分片数量是否大于服务器节点的节点数量的方法包括但并不限于:用初始服务器节点中的分片数据的分片总量除以服务器节点总量(其中服务器节点总量包括新增服务器节点和初始服务器节点),若得到的计算结果过小,则需对初始服务器节点中的分片数据的分片数量进行分裂扩展,以满足各个服务器节点都有分片数据,进而克服现有技术中只有部分服务器节点中有分片数据,部分服务器节点中没有分片数据,所造成的分片数据分布不均衡的问题。此外,若得到的计算结果大于预定阈值,则可直接对初始服务器节点中的分片数据进行容量扩展,以使新增服务器节点与初始服务器节点上的分片数据分布均衡。
通过上述装置,根据判断初始服务器节点上的分片数据的分片数量是否大于服务器节点的节点数量,如果否,则在初始服务器节点中按照初始服务器节点中的分片数据的分片数量的预定倍数进行分裂扩展,以得到扩展后的分片数据,进一步解决了在系统运行初期预先设置大量分片,导致分片开销太大的问题。
在一个可选地实施方式中,图6是根据本发明实施例的容量扩展装置的结构框图(二),如图6所示,处理单元54包括:
1)第一处理子单元62,用于对该初始服务器节点中分片号为i的分片数据按照预定倍数X进行分裂扩展,以得到扩展后的分片号集合(i*X,i*X+X-1),其中,该i为0到该初始服务器节点中的分片数据的分片总量之间的任意一个自然数;
2)创建子单元64,用于建立与扩展后的该分片号集合中每一个分片号对应的过滤器和指针,以得到用于访问扩展后的每一个分片号对应的分片数据的连接。
可选地,在本实施例中,具体是通过在扩容过程中,对初始服务器中分片号为i的分片数据按照该预定倍数X进行分裂扩展,以得到扩展后的分片号集合,并通过建立与扩展后的分片号集合中的每一个分片号对应的过滤器和指针,以得到与扩展后的每一个分片号对应的分片数据的连接。而不同于相关技术中,通过预先设置大量分片,导致分片开销太大的问题,而是根据服务器节点和分片总量之间的关系,分裂当前分片数据得 到扩展后的分片数据集合。
需要说明的是,上述步骤S21中涉及到的i为0到初始服务器节点中的分片数据的分片总量之间的任意一个自然数。
例如,假设i为1,预定倍数X为8,那么对初始服务器中分片号为1的分片数据按照预定倍数8进行分裂扩展,以得到扩展后的分片号集合(8,15)。进一步地,在本实施例中,并不是执行真正意义上的数据分裂,仅相对于对原有分片生成了多个连接,每个连接创建一个过滤器和指针,使其仅连接原分片的1/8数据。
通过上述装置,建立扩展后的每一个分片号对应的分片数据的连接,而不是执行数据分裂,进而使得在迁移过程中,数据可以仍然使用原有路由,避免数据中断。
在一个可选地实施方式中,图7是根据本发明实施例的容量扩展装置的结构框图(三),如图7所示,第二处理模块46包括:
1)获取单元72,用于根据最小迁移路径生成迁移列表,其中,该迁移列表中至少包括待迁移的分片数据,以及该待迁移的分片数据在迁移前的源服务器节点地址和在迁移后的目标服务器节点地址;
2)迁移单元74,用于将该待迁移的分片数据按照该迁移列表由该源服务器节点复制迁移至该目标服务器节点。
可选地,在本实施例中,具体是根据最小迁移路径生成的迁移列表,将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至目标服务器节点。
需要说明的是,上述步骤中涉及到的迁移列表中至少包括待迁移的分片数据,以及待迁移的分片数据在迁移前的源服务器节点地址和在迁移后的目标服务器节点地址。
通过上述装置,根据最小迁移路径生成的迁移列表,将待迁移的分片数据按照迁移列表由源服务器节点复制迁移至目标服务器节点,进一步解决了相关技术在扩容过程中,需要预先设置大量分片,导致分片开销太大的问题。
在一个可选地实施方式中,图8是根据本发明实施例的容量扩展装置的结构框图(四),如图8所示,迁移单元74包括:
1)接收子单元82,用于接收客户端发送的操作请求,其中,该操作请求用于对该待迁移的分片数据执行预定操作;
2)第二处理子单元84,用于响应该操作请求对该初始服务器中的分片数据执行该预定操作,并将该预定操作的操作记录保存到Redo日志中,其中,该操作记录用于对迁移后的该服务器节点中的分片数据执行该预定操作。
通过上述装置,将操作记录保存到Redo日志中,方便在迁移结束后根据记录重新 操作相应数据,从而保证了数据的一致性。
可选地,在本实施例中,迁移单元74还用于在已完成该迁移的分片数据的分片数量大于等于预定阈值时,锁定该初始服务器节点中的分片数据,其中,在锁定该初始服务器节点中的分片数据之后,该初始服务器节点中的分片数据将拒绝执行该操作。
需要说明的是,在本实施例中,上述预定阈值可以是已完成迁移的分片数据的分片数量占总分片数量的比值大于等于80%。可以根据实际迁移过程设置,并不做限定。
可选地,在本实施例中,首先得判断已完成迁移的分片数据的分片数量是否大于等于预定阈值,如果大于,则锁定该初始服务器节点中的分片数据,使得初始服务器中的分片数据为不可用状态;如果小于预定阈值,则可以继续访问初始服务器节点中的分片数据。
通过上述装置,解决了相关技术中在扩容时,造成数据访问中断的问题,使得系统扩容对整个系统的持续稳定工作无影响,对客户端完全透明,达到了扩容速度快、效率高、开销小的效果。
需要说明的是,上述各个模块是可以通过软件或硬件来实现的,对于后者,可以通过以下方式实现,但不限于此:上述模块均位于同一处理器中;或者,上述模块分别位于多个处理器中。
实施例3
本发明的实施例还提供了一种存储介质。本实施例的具体应用场景可以参考上述实施例1和实施例2,在此不赘述。可选地,在本实施例中,上述存储介质可以被设置为存储用于执行以下步骤的程序代码:
S1,获取在增加服务器节点后的当前分布式数据存储系统中服务器节点的节点数量,其中,该当前分布式数据存储系统中包括新增服务器节点和初始服务器节点;
S2,根据该服务器节点的节点数量对该当前分布式数据存储系统中该初始服务器节点上的分片数据进行分裂扩展,以得到扩展后的分片数据;
S3,在该当前分布式数据存储系统中重新分布该扩展后的分片数据,以使该新增服务器节点和该初始服务器节点中每一个节点上的分片数据的分片数量满足预定条件。
可选地,在本实施例中,上述存储介质可以包括但不限于:U盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
可选地,在本实施例中,处理器根据存储介质中已存储的程序代码执行上述步骤S1、S2以及S3。
可选地,本实施例中的具体示例可以参考上述实施例及可选实施方式中所描述的示例,本实施例在此不再赘述。
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!