一种分布式系统的制作方法
本发明涉及数据库领域,特别是涉及一种分布式系统。
背景技术:
数据库(Database)是一组结构化的数据,是我们对于现实世界建模的结果。关系数据库(Relational Database)是以表格形式表达数据的数据库。分布式数据库系统(Distributed Database System,DDBS)是一群分布在计算机网络上,逻辑上相互关联的数据库。结构化查询语言(Structured Query Language,SQL)是一种用于存取数据以及查询、更新和管理关系数据库系统的数据库查询和程序设计语言。透明是指将系统的高层语义和底层的实现问题相分离,一个透明的系统向用户“隐藏”了系统实现的细节。中间件是指一类独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。
在关系数据库中,随着表数据量的增加,单数据库难以支撑对数据的存储和查询请求,需要引入表的拆分,将一张数据表的记录分散存储在多个数据库中,各个分库存放的数据无交集,用以提升数据库系统性能、可用性以及可靠性。将表拆分存储以后,引入了分布式的问题,前端应用在执行查询请求时面对的是一个分布式的数据库系统。每个前端应用需要查询后端的多个分片来获得完整的数据结果集。
参照图1,给出了本申请现有技术所述应用查询架构。
在上述查询架构中,如果有m个应用程序,n个数据库,需要的最小连接数为:m×n个,其中m、n为正整数。每增加s个应用程序,最少需要增加的连接数为:n×s个,其中n、s为正整数。在上述架构中,如果后端任意一个数据库不可用,则整个数据库系统都不可用。
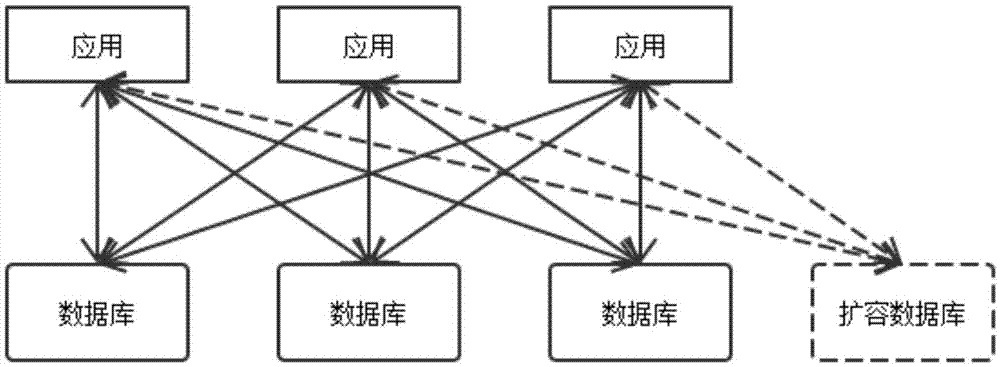
参照图2,给出了本申请现有技术所述架构扩容方案。
在上述扩容方案中,每增加t个数据库,最少需要增加的连接数为:m×t个,其中m、t为正整数。在本申请现有技术方案情况下,分布式数据库系统存在着不透明、连接数过多,可用性较差,伸缩性较弱等问题。
技术实现要素:
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种分布式系统,用于解决现有技术中不透明、连接数过多,可用性较差,伸缩性较弱等的问题。
为实现上述目的及其他相关目的,本发明提供一种分布式系统,包括:前端应用、中间件、以及数据库;其中,所述前端应用通过所述中间件与所述数据库进行通信。
于本发明的一具体实施例中,还包括扩容数据库,所述前端应用还通过所述中间件与所述扩容数据库通信。
于本发明的一具体实施例中,还具有与所述数据库对应的备用数据库,且当一数据库不可用时,所述中间件将所述不可用的数据库切换至相应的备用数据库。
于本发明的一具体实施例中,所述中间件包括:协议层、连接池、SQL处理层、SQL执行层、结果集处理层、和可用性维护层。
于本发明的一具体实施例中,所述SQL处理层执行的操作包括以下中的一种或多种:对SQL进行语法解析、对SQL进行格式化和改写、对SQL的信息进行记录、根据所述记录模块记录的所述SQL的信息判断目标的数据库、以及对SQL语句进行拦截。
于本发明的一具体实施例中,所述SQL执行层用以根据接收的所述前端应用发送的请求指令执行相应的操作。
于本发明的一具体实施例中,所述结果集处理层执行的操作包括以下中的一种多种:对数据库返回的错误信息进行处理、对数据库发生的连接异常进行处理、对数据库返回的数据进行收集、对全部数据库返回完成的数据进行处理、以及将最终的处理结果返回给前端应用。
于本发明的一具体实施例中,所述可用性维护层包括:HA检测模块,用以保证分布式数据库服务可用;事务协调模块,用以保证分布式事务正确执行;监控管理模块,用以执行监控和管理。
于本发明的一具体实施例中,所述HA检测模块还包括:定时单元,用于定时执行心跳检测任务;执行单元,用于执行心跳检测任务,判断数据库可用性;切换单元,用于将不可用的数据库切换至可用的数据库。
于本发明的一具体实施例中,所述监控管理模块用以执行以下中的一种或多种:前端应用连接状态监控;数据库连接状态以及可用性监控;中间件自身状态监控及管理。
于本发明的一具体实施例中,所述中间件自身状态监控及管理,包括以下中的一种或多种:中间件资源占用情况的监控;中间件配置信息的热加载和回滚;中间件后端可用数据库的切换;中间件心跳检测的管理控制;经由中间件的SQL语句的执行统计。
如上所述,本发明的分布式系统,包括:前端应用、中间件、以及数据库;其中,所述前端应用通过所述中间件与所述数据库进行通信。本发明应用透明的分布式系统,将系统的高层语义和底层的实现问题相分离,保障运行的稳定性和安全性,且中间件的采用,可在一数据库出现问题的时候,将其移入相应的备用文件中,不影响系统的稳定运行,系统伸缩性好,可用性高,且中间件的加入,还大大减少了连接数。
附图说明
图1显示为现有技术中一分布式系统的结构示意图。
图2显示为现有技术中一分布式系统的结构示意图。
图3显示为本发明一具体实施例中的分布式系统的结构示意图。
图4显示为本发明一具体实施例中的分布式系统的结构示意图。
图5显示为本发明一具体实施例中的中间件运行的系统架构示意图。
图6显示为本发明一具体实施例中的HA检测模块的模块示意图。
图7显示为应用本发明一具体实施例中的中间件进行查询的流程示意图。
图8显示为本发明一具体实施例中的分布式系统的结构示意图。
元件标号说明
101~106 步骤
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图示中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
请参阅图3,显示为本发明的一种分布式系统在一具体实施例中的结构示意图。所述分布式系统,包括:
应用、中间件、以及数据库;其中,所述应用通过所述中间件与所述数据库进行通信。前端应用查询时,仅需连接所述的中间件,便可以直接进行数据的查询,所述的中间件系统将接收到的数据包解析处理后转发至后端一个或多个数据库中,并将获得的结果集进行处理后返回给前端应用。对于前端应用来说,中间件就是一个完整的数据库服务系统。在图3所述系统中,如果有m个应用程序,n个数据库,需要的最小连接数为:m+n个,其中m、n为正整数。每增加s个应用程序,最少需要增加的连接数为:s个,其中s为正整数。
在本发明的另一具体实施例中,还包括扩容数据库,所述应用还通过所述中间件与所述扩容数据库通信。具体的,请参照图4,在所述扩容方案中,每增加t个数据库,最少需要增加的连接数为:t个,其中t为正整数。
本发明的中间件的系统架构图具体参阅图5,所述的透明的分布式数据库中间件包括协议层、连接池、SQL处理层、执行层、结果集处理层和可用性维护层。
其中,所述协议层包括应用和中间件之间的通信协议以及中间件与分布式数据库之间的通信协议实现。
进一步,所述应用和中间件之间的通信协议实现,包括:应用网络请求的应答;应用与中间件之间的网络包的解码和打包;应用的权限控制。
进一步,所述中间件与分布式数据库之间的通信协议实现,包括:数据库网络请求的应答;数据库与中间件之间网络包的解码和打包。
所述连接池,包括应用和中间件之间的连接池以及中间件与分布式数据库之间的连接池。负责将接收到的语句或者数据转发至对应的处理逻辑。进一步,所述连接池,包括:对应用和数据库连接进行缓存;对应用和数据库连接进行管理。进一步,所述对应用和数据库连接进行管理,包括:维护连接池的正常状态;处理逻辑提供可用的数据库连接。优选的,所述维护连接池的正常状态,包括:关闭不再可用的连接;保持连接池内的连接可用;维护连接池内连接的数量在合理的范围之内。
所述SQL处理层,用于对前端应用发送到中间件的数据包或SQL语句进行相应的处理,其中包括SQL的解析、优化和路由。于本发明一具体实施例中,所述SQL的解析,包括:对SQL进行词法和语法分析;判断SQL语句语法的正确性;获取SQL语句的具体信息。进一步,所述SQL的优化,包括:对SQL语句进行格式化;对SQL语句进行改写。进一步,所述对SQL语句进行格式化,包括对SQL语句的空格、字母大小写、缩进、标点符号、分行等进行标准化操作。进一步,所述SQL的路由,包括:对SQL语句将要转发到哪几个数据库上进行判断;对SQL语句进行拦截。所述对SQL语句将要转发到哪几个数据库上进行判断,包括:根据SQL包含的信息以及用户事先配置的转发规则,确定后端的数据库,或:信息不足时,根据SQL包含的信息以及用户事先配置的逻辑数据库和逻辑数据表信息确定后端的数据库。
进一步,所述逻辑数据库和逻辑数据表是指所述中间件对应用提供的虚拟的数据库和数据表信息,是后端数据库信息的一个聚合。
优选的,所述执行层,负责将处理后的SQL语句发送到后端的数据库中,包括SQL语句的具体执行和连接变量的维护。进一步,所述SQL语句的具体执行,包括:将SQL查询语句转发到后端的数据库中;将自身的状态信息反馈给前端应用;将伪造的结果集返回给前端应用。进一步,所述连接变量的维护,包括:用户连接变量信息的保存和获取;后端数据库连接信息的保存和获取;中间件自身连接信息的保存和获取。
所述结果集处理层,负责处理由后端数据库返回的数据包或者错误信息,包括:对数据库返回的错误信息进行处理;对数据库发生的连接异常进行处理;对数据库返回的数据进行收集;对全部数据库返回完成的数据进行处理;将最终的处理结果返回给前端应用。进一步,所述对数据库返回的错误信息进行处理,包括:对后端数据库返回的错误信息返回给前端应用;根据具体的错误信息执行相应的恢复措施;对后端数据库返回的错误信息进行屏蔽。进一步,所述对数据库返回的数据进行收集,包括:缓存解析后的数据集,或改写解析后的数据集,或丢弃解析后的数据集。进一步,所述对全部数据库返回完成的数据进行处理,包括:根据原始SQL信息对结果集进行排序、分页、聚合操作;根据SQL改写的记录对结果集进行数据的再处理;进一步,所述将最终的处理结果返回给前端应用,包括:将查询流程中发生的错误信息返回给前端应用;将结果集直接转发给前端应用;将处理后的结果集返回给前端应用。
所述可用性维护层,负责保证整个分布式数据库服务处于可用的状态,包括:HA检测模块;事务协调模块;监控管理模块。进一步,所述HA检测模块执行的检测包括:后端数据库的可用性检测;检测到后端数据库不可用时,切换到可用的备用数据库上;为数据库同步复制提供延时监测。进一步,所述事务协调模块,包括:实现分布式事务的原子性,一致性,隔离性和持久性;故障恢复后事务状态的还原;后端部分数据库事务失败时的调度和处理。进一步,所述监控管理模块,包括:前端应用连接状态监控;后端数据库连接状态以及可用性监控;中间件自身状态监控及管理。进一步,所述中间件自身状态监控及管理,包括:中间件资源占用情况的监控;中间件配置信息的热加载和回滚;中间件后端可用数据库的切换;中间件心跳检测的管理控制;经由中间件的SQL语句的执行统计。参阅图6,显示为本发明的HA检测模块在一具体实施例中的模块示意图。在本申请实施例所述的HA检测模块中,包括定时单元,检测单元和切换单元,其中:定时单元用于定时执行心跳检测任务;检测单元用于执行心跳检测任务;进一步,所述执行心跳检测任务,是指向后端数据节点发送SQL语句,根据数据节点返回的信息和返回结果的时间判断数据节点的可用性。切换单元用于将不可用的数据节点切换至可用的备份数据节点上。
参照图7,显示为应用本发明的透明的分布式数据库中间件进行查询的流程图。包括步骤101~106。
所述步骤101,启动分布式数据库中间件,读取相关配置,初始化数据库连接池。本实施例启动时需要获取后端数据节点的具体信息来初始化数据库连接池,此外还需要初始化不同数据表的拆分规则,这些信息可以存储于文件系统中也可以存储于数据库中。
所述步骤102,前端应用向中间件发出正常的连接和查询请求。由于本实施例已经伪装成了一个数据库服务,前端应用只需要像访问单机数据库一样访问本实施例就好了,查询语句无需做任何修改。
所述步骤103,中间件对SQL请求进行解析、处理和路由。本实施例接收到前端应用发出的数据包后,根据数据库的通信协议将数据包解码,获得应用的查询语句。
参照图8,显示为本发明的分布式系统在一具体实施例中的结构示意图。且,包括两个数据库,分别为1号数据库和2号数据库。优选的,于本实施例中,所述1号数据库和2号数据库分别具有对应的数据库备库,即备用数据库,在本实施例中,如果后端任意一个数据库不可用,中间件将该不可用的数据库切换到备用的数据库上,以保障整体数据库服务的可用性。
以图8的系统结构为例,假设前端应用发出的SQL语句为SELECT user_id,user_level,user_type FROM t_user WHERE user_level>12AND user_type=3。假设中间件配置中表t_user的拆分规则为:user_type为奇数的记录存放于1号数据节点中,user_type为偶数的记录存放于2号数据节点中。根据所述的前提,本实施例将解析前端应用所发出的SQL语句,首先解析出数据表名t_user,然后根据表名确认该表的拆分规则,发现该表根据user_type的值来决定具体的数据节点,于是本实施例继续解析该查询给出的条件信息,解析出user_type的值为3,是奇数,确认了该SQL语句应该发往1号数据节点中。假设SQL语句中没有user_type的信息时,本实施例则将根据数据表名t_user的配置,将该SQL发往所有存储有t_user表的数据节点中。进一步,对于一些特殊的SQL语句,本实施例将对其进行改写。例如,SQL语句中包含AVG函数需要查询结果的平均值,本实施例则需要将其改写成SUM和COUNT以供后续计算平均值。进一步,对于一些特殊的SQL语句,本实施例将对其信息特征进行记录,例如,SQL语句中包含SUM、COUNT、MAX、MIN、GROUP BY、ORDER BY、LIMIT、HAVING等查询条件时,本实施例需要记录相应的信息以便步骤105中对数据节点返回的结果集进行收集和处理。进一步,当SQL的语法错误时,本实施例将语法错误信息返回给前端应用,并不实际执行错误的SQL语句。
所述步骤104,中间件从数据库连接池中获取连接,对请求进行分发执行。本实施例在完成步骤103后,确认了执行该条SQL语句的具体发送数据节点,则将从各个数据节点的连接池中获取空闲的连接,并执行相应的SQL语句。
所述步骤105,中间件对数据节点返回的结果集进行收集和处理。本实施例执行相应的SQL语句后,可能从后端的数据节点收到不同的响应,本实施例需要对该响应进行收集和处理,包括:收集执行结果,汇总后返回给前端应用;收集执行结果,改造后返回给前端应用;收集执行结果,过滤后返回给前端应用。进一步,所述执行结果,包括:后端数据节点返回的查询结果集包;后端数据节点返回的错误信息包;后端网络连接返回的错误信息。进一步,所述汇总,包括:后端数据节点返回的OK包信息的合并;后端数据节点返回的Error包信息的合并;后端数据节点返回的行数据包的合并。进一步,所述改造,包括后端数据节点行数据包头、包尾以及包数据的改写。进一步,所述过滤,包括后端数据节点返回的结果集的丢弃或跳过。例如LIMIT分页查询时,需要丢弃前OFFSET个数据包;而在含有ORDER BY的LIMIT排序分页查询中,需要跳过排完序后的前OFFSET个数据包。
所述步骤106,中间件将处理好的结果集发送给前端应用。本实施例在获取完所有数据节点返回的数据后,将用完的数据库连接释放回数据库连接池,然后将最终处理好的结果集根据通信协议进行打包,然后返回给前端应用。前端应用收到结果集包后,查询流程结束。
本发明通过将自身伪装成数据库服务,屏蔽了后端的数据库分布,使得分布对于用户变得透明,并通过数据库连接池、可用性维护层等组件保障了分布情况下服务的高性能和高可用。
综上所述,本发明的分布式系统,包括:前端应用、中间件、以及数据库;其中,所述前端应用通过所述中间件与所述数据库进行通信。本发明应用透明的分布式系统,将系统的高层语义和底层的实现问题相分离,保障运行的稳定性和安全性,且中间件的采用,可在一数据库出现问题的时候,将其移入相应的备用文件中,不影响系统的稳定运行,系统伸缩性好,可用性高,且中间件的加入,还大大减少了连接数。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!