处理大型数据储存库中的数据集的制作方法
本公开涉及处理大型数据储存库中的数据的领域。
背景技术:
在信息管理程序(如数据仓库、主数据管理(MDM)或大型数据分析程序)中使用数据之前,需要很多步骤以将来自多个内部和外部源的原始数据按照能够由端用户以有意义的方式来消耗的格式集成到统一的数据储存库中。首先,需要识别包含特定任务所需要的全部信息的数据源。因此,用户需要知道可用数据集的语义内容,例如通过手动检查或者通过在可用数据集上手动触发语义数据剖析工具的执行。用户可以开始数据剖析工程并且合并他认为相关的源。然而,上述步骤已经需要用户知道应当分析哪些源。可能丢弃有趣的数据源。另外,用户必须花费时间和精力来习惯可用的数据集和工具,因为他或她需要知道哪种分析工具需要哪种数据格式。
数据整合也可能由于以下事实而进一步变得复杂:一些数据集可以包括不应当被呈现给端用户或者端用户的一些组的机密信息。确保并且增加可用数据集的数据质量可能也是问题:数据可以冗余地存储在原始数据集中,可以包括关于一些数据记录的不一致的信息,或者可以用不同的数据格式和标准来呈现。
在现有技术中,存在多个产品和方法,它们可以满足以上要求中的一些要求,但是上述工具依赖于用户的手动控制和配置,或者依赖于预定义的和固定的工作流方案。用户或工作流方案必须明确地规定这些工具中的哪个工具必须在哪个时刻应用于这些数据集中的哪个数据集以便解决特定问题。手动数据预处理和剖析方法可以仅在要整合的数据的量很少并且具有相对低的复杂性的情况下使用。预定义的基于工作流的数据处理方法需要处理固定的数据集序列,从而上述数据集的语法和内容事先已知。这样的数据通常称为结构化数据,这二者均结合基于工作流的数据处理等。
然而,在大型数据环境中,需要整合和处理大量数据,并且事先不知道要整合的数据的内容、语法、序列或文件格式。不限于其中语法和内容事先知道的数据集的这样的数据通常称为非结构化数据。可能不能够预见特定数据集是否可用以及何时可用。不能应用手动方法,因为人类不能应付所涉及的数据处理任务的复杂性和动态性。依赖于预定工作流的方法也不适用,因为其不能够预见整合和处理动态提供的新的数据所必须的所有数据处理、剖析和分析步骤的种类和序列。因此,手动方法或基于工作流的方法都不能应付要由大型数据环境来处理的数据的量、结构和语义异质性和不可预期性。
US006381556B1例如公开了用于准备源自于制造环境的原始数据以便出于报告目的而加载上述数据的方法。所呈现的方法类似于ETL作业是相当静态的。US006643635B2描述了自动方式的用于商业分析的数据的变换用于基于静态数据处理方案读取和准备来自不同的数据源的数据。
技术实现要素:
本发明的实施例的目的是提供一种用于处理大型数据环境中的数据的改进的方法。改进因此可以涉及人类用户在计划、触发和监督要被传送到大型数据储存库中或者已经包含在大型数据储存库中的数据的处理上花费的时间和精力的减少。改进还可以涉及遗留数据处理程序到增加的质量的分析数据处理和到增加的安全性的机密数据的无缝整合。也可以增加大型数据储存库充分且灵活地对付和处理其可用性、内容和结构动态变化并且不能事先预见的数据的能力。
上述目的通过独立权利要求的主题来解决。从属权利要求中描述有利的实施例。
本文中使用的数据储存库或“大型数据”储存库是用于存储和管理结构化和非结构化数据集的数据容器。要被整合到大型数据储存库中的数据集可以是语义和/或语法上异质的。要整合或处理的数据集的顺序、语义内容、源和/或语法形式可以是不可预期的。可能有必要连续地整合新的数据集并且处理现有数据集。大型数据储存库可管理的数据量可以很大,例如在包括数十亿到数万亿记录的拍字节(1024太字节)或艾字节(1024拍字节)的范围内。要存储在大型数据储存库中的数据的量可能是传统数据库和软件技术不可处理的。数据可以至少部分不完整、机密、冗余、不一致或语法上不适合数据分析。
“注释”是描述其他数据并且与其他数据相关联的元数据(例如内容、解释、一个或多个标签或标记的集合、属性值对等)。注释可以是针对特定数据集收集的并且与上述数据集相关联地存储的元数据。元数据可以包括结构元数据(关于数据结构的设计和规定)和/或描述元数据(关于数据内容)。
术语“数据处理”可以指代对数据集的任何种类的预处理或处理。例如,数据处理可以指代数据集的任何种类的语义、统计或语法数据分析、格式化、变换、屏蔽、校正、分割和组合等。
“条件”是可以被满足或者不被满足的关于例如要处理的数据集的特定实体的句子。
“程序引擎”是任何种类的可执行程序逻辑,例如应用程序、脚本、(web)服务、程序模块或数据库例程等。
“代理”是已经被指派一个或多个条件并且其执行在上述条件满足时自动触发的任何种类的可执行程序逻辑,例如应用程序、脚本、(web)服务、程序模块或数据库例程等。上述条件中的至少一些条件涉及要由上述代理来处理的数据集(包括上述数据集的注释)。代理可以直接或在本文中称为“程序引擎”的其他程序的帮助下间接地处理数据集。
一方面,本发明涉及一种用于处理大型数据储存库中的多个数据集的计算机实现的方法。提供代理的集合。每个代理可操作以触发数据集中的一个或多个数据集的处理。上述代理中的每个代理的执行在向上述代理指派的一个或多个条件满足的情况下自动触发。代理中的每个代理的条件中的至少一个条件涉及其处理能够由上述代理来触发的数据集的存在、结构、内容和/或注释。例如,大型数据储存库中的新的数据集的创建或者到大型数据储存库中的外部数据集的导入可以表示触发已经被指派以下条件的代理的执行:上述创建的或者导入的数据集“存在”于大型数据储存库中。
该方法包括执行代理中的第一代理。上述执行由关于数据集中的第一数据集的第一代理的条件满足来触发。第一代理的执行触发第一数据集的处理。然后,由第一代理来更新第一数据集的注释。从而在上述注释中包括第一数据集的处理的结果。产生上述结果的第一数据集的处理由第一代理来触发。特定数据集的注释的“更新”可以包括上述数据集的现有注释的修改和/或补充或者上述数据集的注释的初始创建。上述新的或已更新注释可以包括对上述数据集的处理的结果。
该方法还包括执行代理中的第二代理。上述第二代理的执行由第一数据集的已更新注释满足第二代理的条件来触发。第二代理的执行触发第一数据集的进一步处理。第二代理还通过从上述进一步处理获得的结果来更新所述第一数据集的注释。
根据实施例,代理的集合中的每个代理能够仅通过要由上述代理来处理的数据集中的一个数据集的注释的更新和/或通过数据储存库中新的数据集的检测来触发,上述检测可以由大型数据储存库的储存库管理器来执行。上述代理的执行导致已处理数据集的注释的更新。更新可以包括初始创建已处理数据集的注释。
根据一些实施例,代理的集合包括多个代理的子集,多个代理的子集可以仅通过要由上述代理来处理的数据集中的一个数据集的注释的更新来触发。多个代理可操作以自动处理和准备数据集以便向用户输出已处理数据集或者上述处理的一些结果。上述代理的执行序列仅取决于数据集相关的条件的满足并且因此遵循完全数据驱动的、动态和自动确定的处理任务序列。
根据一些实施例,数据集的处理由代理直接执行。根据另外的实施例,大型数据储存库由多个程序引擎可访问。每个程序引擎可操作以处理数据集中的至少一个数据集。代理中的至少一些代理已经分别被指派程序引擎中的一个程序引擎并且分别包括到其的所指派的程序引擎的接口。代理通过经由其接口初始化其相应地被指派的程序引擎的执行来触发数据集中的一个或多个数据集的处理。上述特征可以使得能够根据第一程序语言或框架(例如Java、EJB或.NET等)来实现所有程序代理,而实际处理可以由也可以是遗留程序的不同框架的程序引擎来进行。
所谓的程序引擎可以向调用代理返回处理的结果。调用代理可以使用上述结果(直接或在一些附加处理步骤之后)并且将上述结果或其衍生物添加到上述数据集的注释。另外地或者备选地,代理可以使用上述结果用于创建衍生数据集。
根据实施例,该方法还包括向程序引擎中的每个程序引擎提供任务队列。代理中的一个代理对引擎中的一个引擎的执行的触发包括向上述程序引擎的任务队列添加由上述一个程序引擎来处理数据集中的一个或多个数据集的任务。上述任务到任务队列的添加由上述代理来执行。因此,上述一个程序引擎根据上述程序引擎的任务队列的顺序来处理一个或多个数据集。因此,任务队列可以使得能够组织和管理其执行由多个不同代理触发的处理任务。
根据实施例,大型数据储存库操作地耦合至工作量管理器。代理中的至少一些代理可操作以触发等同程序引擎的集合的执行。本文中使用的“等同程序引擎”是可操作以根据数据集中的给定数据集生成相同的处理结果的程序引擎。因此,等同程序引擎可以在功能上彼此代替。工作量管理器从程序引擎中的每个程序引擎重复地接收工作量信息,例如,以预定义的时间间隔(例如每毫秒、秒或分钟)。工作量信息可以表示上述程序引擎的能力利用率。特定处理引擎的能力利用率例如可以用上述处理引擎的序列中的任务的数目来规定。另外地或者备选地,程序引擎的能力利用率可以包括托管上述程序引擎的计算机系统的能力利用率,例如表示资源的消耗(诸如CPU、存储装置、存储器或网络业务等)的参数。
工作量管理器通过使用所接收的工作量信息作为输入,针对向代理中的一个代理指派的等同程序引擎的至少一个集合,重复地并且自动地确定具有最低能力消耗的程序引擎。然后,工作量管理器向等同程序引擎的上述集合被指派给其的代理提供上述确定的程序引擎的指示。在已经接收到上述指示之后,上述代理选择性地触发所指示的程序引擎的执行而非触发向上述代理指派的其他等同程序引擎中的任何等同程序引擎的执行。
根据实施例,程序引擎中的任何一个程序引擎的工作量信息包括当前存储在上述程序引擎的任务队列中的任务的数目。
根据实施例,代理中的至少一些代理已经被指派优先级号码。大型数据储存库操作地耦合至连续地监视所有代理的实例化和/或执行并且获取一些监视信息的代理管理器。代理管理器基于这一信息来自动确定代理中的至少两个代理尝试处理数据集中的相同的数据集。另外地或者备选地,代理管理器确定代理中的至少两个代理需要不能同时向两个代理提供的计算资源(例如CPU、存储器或存储能力或者未占用的程序引擎)。代理管理器评估至少两个代理的优先级号码并且选择性地使得能够执行具有最高优先级号码的代理。代理管理器可以永久地阻挡所有其他评估的引擎或者至少直到具有最高优先级号码的代理的执行完成。代理的优先级可以向数据处理系统提供对不同情况的灵活反映。例如,两个代理(或者其相应处理引擎)可能要求访问特定数据集。然而,一次仅可以向一个代理(或处理引擎)授予对上述数据集的访问以阻止不一致的数据记录的创建。
根据一些实施例,数据集中的至少一些数据集已经被指派优先级号码。大型数据储存库操作地耦合至代理管理器。代理管理器连续地监视所有代理的实例化和/或执行。代理管理器基于监视信息自动确定代理中的一个代理被发起用于触发数据集中的两个或更多个不同数据集的处理。然后,代理管理器评估上述两个或更多个不同的数据集的优先级号码。代理管理器基于上述评估引起上述代理触发已经被指派较高优先级号码的数据集的处理。代理管理器例如可以阻挡具有较低优先级号码的所有其他评估的数据集合被上述代理处理至少直到具有最高优先级号码的评估的数据集的处理完成。备选地,在多个等同处理引擎可用并且被指派给上述代理的情况下,代理管理器同样可以引起上述代理触发由第一处理引擎进行的具有最高优先级的数据集的执行并且触发由等同于第一处理引擎的第二处理引擎进行的具有较低优先级的数据集的执行。
根据一些实施例,处理引擎中的至少一些处理引擎可以可操作以并行地处理N个数据集,N是大于“1”的整数。在这些情况下,代理管理器可以选择具有最高优先级号码的N个数据集并且可以引起由处理引擎进行上述所选择的N个数据集的并行处理。
不同数据集的执行的优先化可以通过代理管理器将具有较高优先级号码的数据集的处理任务移动到要执行上述处理的程序引擎的队列的顶部来实现。具有较低优先级的其他数据集将由上述处理引擎在程序引擎的能力允许的情况下来处理。这可以允许一些数据集优先于其他数据集。在代理以及数据集可以已经被指派优先级号码的情况下,两个优先级号码由代理管理器例如基于一些规则来评估。
根据一些实施例,大型数据储存库或者与大型数据储存库可互操作的应用程序或模块向用户提供图形用户界面(GUI)。大型数据储存库经由GUI从用户接收配置数据并且根据所接收的配置数据修改代理中的一个或多个代理的条件。另外地或者备选地,大型数据储存库修改代理中的一个或多个代理的优先级号码和/或修改向数据集中的一个或多个数据集指派的优先级号码。上述修改根据所接收的配置数据来执行。
根据实施例,第一代理或由第一代理触发的程序引擎创建第二数据集。第二数据集是第一数据集的衍生物。衍生数据集可以是错误、冗余和/或机密数据被去除或者变为合适的数据格式的清洁的数据集。更新第一数据集的注释包括使用链接补充第一数据集的注释,该链接指向所生成的第二数据集的存储位置。第二代理的执行可以包括使用所生成的第二数据集作为第一数据集,第一数据集然后由第二代理或者由第二代理调用的程序引擎来进一步处理。这可以使得能够自动和完全透明切换至已处理或以其他方式改进的数据集作为进一步处理步骤的基础,从而“透明”表示用户甚至可能没有认识到他或她作业的数据集实际上已经变化。例如,第二数据集可以是通过解析操作根据包括CSV文件的第一数据集得到的关系数据库表格。对于很多分析和其他程序引擎,与使用CVS文件作业相比,更容易使用关系数据库表格作业。衍生数据集的其他示例可以是不包括任何机密数据的屏蔽数据集。
根据实施例,多个程序引擎包括以下类型的程序引擎中的至少两个程序引擎的任何组合:
·可操作以执行文件格式识别任务或文件语法识别任务的程序引擎。上述程序引擎可以使用文件格式信息或语法信息来注释数据集。
·可操作以执行提取变换加载(ETL)任务用于变换数据集以符合其他程序引擎的操作需求的程序引擎。要变换的数据集可以已经由大型数据储存库导入或者可以已经在大型数据储存库中创建。通常,语义剖析工具和/或用户要求以特定语法形式来呈现数据,诸如CSV、RDF、二进制或XML文件或者关系或列数据库表格。在上述情况下,可用数据集必须被变换成能够由数据剖析工具来解释的格式。
·可操作以执行数据质量检查用于从已处理数据集中自动去除低质量的数据记录的程序引擎,例如错误、冗余、模糊、过期或不一致的数据记录。另外地或者备选地,上述程序引擎可以可操作以使用自动确定的质量水平的上述数据集来补充已处理数据集的注释。
·可操作以执行数据屏蔽操作用于从已处理数据集自动去除机密数据值或机密数据记录和/或用于使用任何机密数据从上述数据集成功去除这一信息来补充已处理数据集的注释的程序引擎。
·可操作以执行主数据管理(MDM)操作用于根据技术要求和/或商业要求自动校正、标准化或处理已处理数据集中的数据记录的程序引擎。MDM操作可以包括收集、聚合、匹配、联合、质量保证、坚持和/或使数据遍布组织分布。上述程序引擎另外地或者备选地可以能够使用关于上述MDM操作的结果的信息来补充已处理数据集的注释。
·可操作以执行已处理数据集的数据分析和/或使用上述数据分析的结果来补充已处理数据集的注释的程序引擎。上述分析可以包括例如文本分析和统计分析。
上述程序引擎中的至少一些程序引擎也可以能够生成给用户的通知用于已处理数据集的预览。
根据实施例,向大型数据储存库的用户提供搜索索引数据结构。搜索索引数据结构使得用户能够执行搜索以检索匹配搜索准则的完整数据集(例如检索包含已经被指派最小质量水平的个人信息的数据集)和/或在上述索引数据结构上执行搜索所选择的数据集的数据记录。由已经触发数据处理的代理连续地并且自动地向搜索索引数据结构添加由代理中的任何一个代理针对数据集中的任何一个数据集创建的注释。注释可以包括可以尚未被包含在原始加载到大型数据储存库中的数据集中的附加元数据和分析结果。
根据实施例,代理中的一个代理可以使用第二指针自动(并且优先地对用户透明)代替上述搜索索引数据结构的第一指针。上述代替在上述生成的第二数据集是数据集中的第一数据集的衍生物的情况下执行。第一指针指向第一数据集,第二指针指向第二数据集。上述特征可以使得能够在进行基于索引的搜索时完全自动和透明地切换到新的数据集。查询可以是或者包括关键字搜索,但是也可以是更加复杂的查询。例如,对其代理已经得到第二衍生数据集的第一数据集的查询从第二数据集而非第一数据集透明地返回数据集。搜索可以是例如:“搜索包含类型人姓名和地址的数据并且其数据质量索引高于80%的所有数据集”。数据质量代理可以产生包含度量的注释(不包括80%的行有效)。搜索准则因此可以包括这种数字度量。因此,通过由代理的级联自动创建附加注释(元数据),并且通过将上述注释自动整合到搜索索引中,自动增加了搜索的质量。
根据实施例,代理中的至少一些代理被托管在经由网络连接至彼此的不同的计算机系统上。由相应代理触发的程序引擎中的至少一些程序引擎是被托管在与触发代理相同的计算机系统上的遗留应用。
取决于实施例,大型数据储存库可以基于分布式文件系统(诸如Hadoop)、非分布式文件系统、关系或列数据库、内容管理系统或另一等同系统或框架来实现。
另一方面,本发明涉及一种计算机可读存储介质,其包括用于由处理器来执行的机器可执行指令。指令的执行引起处理器执行根据以上实施例中的任一项的方法。
另一方面,本发明涉及一种包括处理器和计算机可读存储介质的计算机系统。计算机可读存储介质包括大型数据储存库。大型数据储存库包括用于由处理器来执行的多个数据集和机器可执行指令。指令的执行引起处理器执行根据以上实施例中的任一项的方法。
本领域技术人员应当理解,以上提及的实施例的特征可以彼此组合。本发明的各个方面可以实施为系统、方法或计算机程序产品。因此,本发明的各个方面可以采用完全硬件实施例、完全软件实施例(包括固件、驻留软件、微代码等)、或者组合软件和硬件方面的实施例的形式,所有这些实施例在本文中通常可以称为“电路”、“模块”或“系统”。另外,本发明的各个方面可以采用在其上实施有计算机可读程序代码的一个或多个计算机可读介质中实施的计算机程序产品的形式。
附图说明
本发明的以上和其他项目、特征和优点在结合附图阅读本发明的实施例的以下更具体的描述时将能更好地理解,在附图中:
图1是包括大型数据储存库的计算机系统的框图,
图2描绘上述计算机系统的分布式变型,以及
图3是用于处理多个数据集的方法的流程图。
具体实施方式
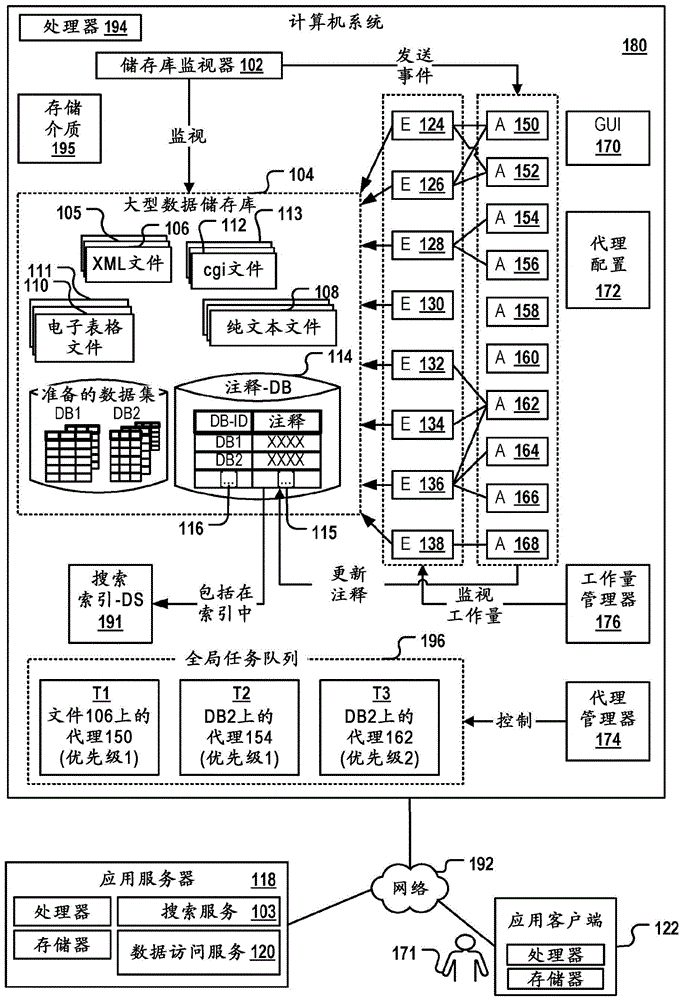
图1描绘包括处理器194和计算机可读存储介质195的计算机系统180。存储介质可以是单个存储介质,或者包括多个连接的存储介质。另外,处理器可以包括彼此操作地耦合的多个处理器。多个存储介质和处理器可以由例如云环境来提供和管理。计算机系统托管大型数据储存库104,大型数据储存库104可以基于分布式文件系统,诸如Hadoop。其可以包括由多个不同的代理150-168创建和/或处理的多个数据集105、106、110-113、108、DB1、DB2。代理可以调用非常不同类型的程序引擎124-138用于处理数据集并且用于执行任务,诸如文件格式识别、列分析、ETL操作和数据剖析等。
代理是其在数据集中的一个数据集上的执行由与上述代理相关联的所有条件均满足的事件来触发的部件。上述条件可以完全或者至少部分涉及要处理的数据集的特征,包括上述数据集的注释。例如,用于在数据集上开始列分析的条件可以是新的注释到上述数据集的添加,从而上述注释表示数据集已经被解析并且已经创建具有关系表格形式的衍生数据集(其是用于执行列数据分析的合适的格式)。代理可以使用内部程序逻辑或调用外部程序逻辑用于处理数据集。上述程序逻辑可以提供由代理用于创建或更新已处理数据集的注释和/或用于创建衍生数据集的处理结果。例如,用于识别文件格式的代理可以产生表示所识别的文件格式的注释。用于借助于数据格式变换作业来创建衍生数据集的代理可以创建指向衍生数据集并且包括关于其格式的元信息的注释。每个代理可以被指派优先级号码以表示数据处理任务在触发相应代理的条件满足时应当有多紧急需要开始。
寄存的代理的列表以及相应地触发其激活的条件存储在代理配置数据库172中。代理管理器174是可以从储存库监视器102接收事件并且可以基于代理配置数据库172中存储的代理的配置来决定哪个代理应当在哪个数据集上运行的程序逻辑(在多个代理的条件关于特别的最近更新的数据集满足的情况下)。一旦代理管理器检测到用于在数据集上激活代理的条件满足,则其将代理执行任务放置在全局任务队列196中。全局任务队列可以包括要由相应代理150、154、162在数据集106、DB2中的一个上来执行的多个任务T1-T3。代理的任务在这一队列中的位置将取决于代理的优先级号码和/或其用于执行的任务已经在队列中的这些代理的优先级号码和/或对任务排队的时间。队列中的任务的顺序也可以由用户在运行时间修改,例如经由图形用户界面170,以使得用户能够修改向代理指派的条件和优先级号码并且修改向数据集中的至少一些数据集指派的优先级号码。
工作量管理器176监视全局任务队列以及程序引擎的队列,如图2中描绘的。工作量管理器在多个等同程序引擎可用于由代理之一来执行数据处理任务的情况下向其作业队列相当空和/或在具有空闲CPU/存储器/存储能力的计算机系统上执行的等同处理引擎指派上述代理的上述处理任务。在已经完成数据处理任务之后,已经执行上述任务并且已经创建或更新一些注释的代理或程序引擎可以在搜索索引数据结构191中自动包括所创建或已更新注释。搜索索引数据结构使得应用客户端122的任何用户171能够经由网络192快速地搜索大型数据储存库的内容。上述搜索可以是关键词搜索或者是也评估数据集的注释中包含的元数据的更加复杂的搜索(例如:搜索包含其完整性和质量>90%的个人数据的所有数据集)。
当用户171选择检索特定数据集时,实际上被检索的数据集的版本可以是上述特定数据集的衍生物,例如DB1或DB2,其可以已经被创建作为清洁或变换操作的结果。取代以其原始、非解析/非标准化平面文件格式108返回特定数据集,衍生数据集或其数据记录中的一些数据记录被返回作为搜索结果。用户也可以具有手动更新注释并且添加或删除注释的特权,从而搜索索引数据结构通过更新被自动补充,例如借助于使索引数据结构永久性地同步注释数据库114中存储的注释的背景作业。搜索功能可以在应用服务器118的帮助下提供,应用服务器118在搜索索引数据结构191上提供搜索服务103。用户171可以经由数据访问服务120手动编辑大型数据储存库104的数据集的注释115。
注释可以存储在与其相应数据集的标识符116相关联的注释数据库114中。注释数据库114可以驻留在大型数据储存库中或者驻留在其外部。数据集注释还可以包括可以规定在什么情况下必须屏蔽、校正、质量检查和剪裁数据等的策略和规则。储存库监视器102监视注释数据库中的注释115的任何变化以及大型数据储存库104中包含的文件的数目和类型的任何变化。储存库监视器在检测到任何变化的情况下抛出事件。上述事件可以引起已经被注册作为上述种类的事件的监听器的所有代理或者至少一些代理评估其相应被指派的条件并且在其所有条件满足的情况下自动触发其相应被指派的(多个)数据集的处理。
例如,储存库监视器可以检测随后的平面文件形式(clients.txt)的新的数据集已经被导入到大型数据储存库104中。数据集可以尚没有注释。储存库监视器仅知道其位置以及其是命名为“clients.txt”的文件这一事实。上述文件可以包括:
“1576”,“Cliff Langlais”,“35Livery Street,Birmingham”,“28451”,“单身”,“闲散”
“1277”,“Patrice Merkel”,“Daimler Straβe 3Wiernsheim”,“75444”,“离异”,“雇员”
“1287”,“Catherine Coon”,“Shcilllenbergweg 10Sundern”,“59846”,“已婚”,“闲散”
[…]
首先,可以执行专用于检测平面文件格式的代理:上述代理可以已经被指派条件“不存在属性‘格式’的注释”。每次在大型数据储存库中检测到在其注释中尚未指派属性“格式”的值的新的数据集时,上述代理自动执行。代理可以执行文本分析例程,文本分析例程用于检查行、重复分隔符等的存在。代理可以检测新的文件有可能是通过特定定界符分离的逗号分离的值文件(CSV文件)。如果格式没有被识别出,则代理将“格式=未知”的注释与上述数据集相关联地存储在注释数据库114中用于防止相同的代理第二次处理上述数据集。另外,上述注释可以防止其他代理进一步处理该数据集,从而防止错误的衍生数据集的创建。如果格式被识别出,则针对上述数据集创建包括关键值对“格式=‘CSV’”的注释。
当数据集的格式已经被另一代理识别为“原始文本”或“CSV”或“XML”时,另一代理可以在上述数据集中搜索正则表达式。正则表达式可以用于从clients.txt文件中提取例如人的姓名、地址和职业。上述代理可以已经被指派条件“格式=‘CSV或XML或纯文本’”并且只要上述clients.txt文件的注释包括属性值对“格式=CSV”,就可以被自动触发以处理clients.txt文件。由上述其他代理生成的用于更新已处理clients.txt数据集的注释的输出可以包括实体类型,诸如“地址”和“职业”,其在上述文件中被识别:“实体类型=‘人的姓名;地址;职业’”。
处理clients.txt文件的第三代理“A3”可以是专用于通过从文件中提取上述数据并且将所提取的数据存储在关系数据库表格中来解析包括人的姓名和地址的结构化CSV文件的代理。上述第三代理的条件可以看起来像“格式=纯文本或CSV”和“实体类型=人的姓名或地址”以及“代理-A3=尚未执行”。在后的条件表明代理“A3”尚未运行(对于clients.txt数据集尚未存在以关系表格形式的衍生数据集)。在代理A3的成功执行之后,可以将clients.txt数据集的注释更新为“代理-A3=执行”。另外,可以向原始clients.txt文件的注释添加衍生数据集的链接或标识符,例如“衍生数据集=clients-DB”。其他代理可以可操作以处理clients.txt文件,而不管其是否包含人的姓名或其他命名的实体。上述代理的执行可以仅由要解析的文件的格式来触发,并且进行解析作业而不管各个列的语义内容。
第四和第六代理可以在注释属性“衍生数据集”已经指派值的情况下来执行,所指派的值是例如衍生关系数据库的标识符。第四和第六代理可以执行标准化步骤用于标准化客户端的地址和/或诸如邮政编码的各种参数的统计分析或聚类算法。标准化任务的结果可以是新的衍生结构化表格,其将取代先前的结构化表格。例如,先前的表格可以被包含作为单个列“地址”,其包含所有地址数据,而新的衍生结构化表格可以包括用于“街道”、“房屋号码”和“邮政编码”单独的列。在已经执行标准化代理之后,将向标准化数据集添加注释“标准化=是”以防止在这一数据集上再次运行相同的代理。
代理的集合也可以包括用户特定的代理。取决于用户的特权,可以触发不同的用户特定的代理用于创建衍生数据集。例如,在第一用户被允许检查一些机密数据,而第二用户不被允许的情况下,特定用于第一用户的第一代理可以产生衍生数据集,该衍生数据集仍然包括原始数据集的一些机密数据,而由不同的用户特定的代理针对第二用户生成的衍生数据集可以已经变为清除任何机密数据。
本发明的实施例的特征可以是有益的,因为它们可以允许任何种类的数据整合、预处理或处理任务的高度灵活、完全自动的执行而没有用户的任何手动干预并且没有预定义的、静态工作流的编程者的提供。所有步骤可以按照数据驱动的方式完全自动执行:在创建新的数据集或者上述数据集的新的注释和/或更新现有的注释的情况下,可操作以处理上述数据集的一个或多个代理的条件可以满足。在上述条件满足时,可以完全自动触发已经被指派上述条件的相应代理的执行。上述代理的执行触发上述数据集的处理。因此,在很多情况下,特定代理的编程者仅需要知道的关于可用数据的信息涉及上述代理或者由上述代理触发以实际处理上述数据集的另一程序的语义和语法输入要求。编程者不需要知道“全局工作流”或所有其他潜在的成百上千的代理的要求以便使用新的完全功能代理来补充运行的大型数据储存库,该代理能够预处理其他代理的数据集而甚至不知道上述其他代理存在。这可以使得复杂的大型数据储存库的创建和维护变得简单,以支持多个不同的相互依赖的导入、预处理、分析和导出数据处理任务。
例如,注释可以使用表示特定预处理或处理步骤(成功或未成功)在上述数据集上被执行的状态信息来更新。数据集的注释的更新可以表明数据集现在是用于进一步处理上述数据集的另一代理要求的正确的文件格式或者语法。数据集的处理可以由代理直接或借助于被上述代理调用的附加应用程序(本文中称为程序引擎)来执行。
一些代理的条件可以完全或至少部分涉及一个或多个数据集的注释。它们也可以涉及具有特定文件名或文件类型(例如用特定文件扩展名来表示)的文件的存在或者涉及上述数据集的任何注释的存在或不存在。例如,代理可以由来自外部数据源的尚未注释的XML文件的成功导入来触发。
上述代理执行的序列可以仅取决于数据集相关的条件的满足,并且因此可以遵循处理任务的完全数据驱动的、动态并且自动确定的序列。上述特征可以是有益的,因为编程者创建和维护复杂的大型数据储存库所需要的时间和精力可以显著减少。编程者不需要修改和重新编译现有代理的任何可执行源代码,因为没有代理被任何其他代理直接调用。代理的动态行为仅取决于其相应被指派的条件以及上述条件涉及的动态更新的注释。优选地,条件由用户在大型数据储存库的运行时可编辑,从而上述条件的修改不需要代理或其他程序模块的重新编译以便变得有效。
代理可以通过以上描述的接口触发数据集中的一个或多个的处理可以使得能够根据第一程序语言或框架(例如Java、EJB或.NET等)实现所有程序代理,而实际处理可以由也可以是遗留程序的不同框架的程序引擎来进行。因此,遗留数据预处理和处理程序可以很容易整合而没有借助于可操作以调用上述遗留程序作为用于处理特定数据集的程序引擎的附加代理的代码的重新编译或重写。
代理可以选择性地触发所指示的程序引擎而非多个其他等同程序引擎中的任何一个的执行可以是有益的,因为在当多个等同程序引擎能够执行特定数据处理任务的情况下,上述任务可以被指派给具有最低能力消耗的程序引擎。因此,可以避免瓶颈,并且可以更加有效地使用可用的硬件资源。
程序引擎中的任何一个的工作量信息可以包括当前存储在上述程序引擎的任务队列中的任务的数目可以是有益的,因为任务队列可以使得用户或大型数据储存库的系统部件能够收集关于处理引擎的负载的信息并且选择具有空闲能力的处理引擎用于处理特定数据集。
通过优先化触发更相关并且对用户更重要的数据集的处理的代理之一,大型数据储存库可以更快地选择性地提供与用户高度相关的信息。
一些数据集与其他数据集相比的优先化可以增加大型数据储存库的灵活性、准确性和性能。在代理的优先级号码以及数据集的优先级号码由代理管理器来评估的情况下,代理可以取决于已处理数据的重要性以及要执行的处理的类型动态、高度灵活并且完全自动地处理数据集。实现系统的复杂且灵活地适配的行为不需要复杂的预定义的工作流。
例如,代理管理器可以可操作以确定可操作以触发数据集Z的处理的代理x,上述数据集在要由代理x处理的所有数据集中具有最高优先级号码。代理管理器例如通过评估上述确定的代理x的所有条件自动确定必须在上述代理x之前执行的其他代理,使得上述代理的所有条件满足。这一步骤可以针对其他确定的代理的所有条件重复以用于识别需要执行的依赖性链中的所有代理,使得代理x的所有条件满足。代理管理器然后可以将依赖性链的所有代理放置到全局任务队列中,从而上述队列中的任务的顺序确保了上述依赖性链的所有代理按照正确的序列顺序被执行。这可以是有益的,因为用户可以例如经由GUI通过向数据集Z指派关于代理x的最高优先级号码来规定数据集Z应当由代理x尽可能快地处理。代理管理器可以自动确定需要在代理x能够执行之前执行的代理x的依赖性链中的所有其他代理。代理管理器然后将所有识别的代理放置在全局任务队列的顶部,例如通过自动增加向上述代理指派的优先级号码。因此,用户不需要知道在代理x能够开始之前必须执行的代理的依赖性链。
大型数据储存库可以从用户接收配置数据并且可以根据上述配置数据修改代理的条件、代理中的一个或多个代理的优先级号码和/或向数据集中的一个或多个数据集指派的优先级号码,这可以是有益的,因为用户可以通过编辑配置数据来很容易适配数据处理的行为而没有源代码的任何重新编译。用户也不被要求知道或规定复杂的数据处理工作流。他可以完全或单独专注于几个方面的配置,例如特定输入文件的处理或者在特定处理任务/代理可以开始之前应当满足的条件。
注释到搜索索引数据结构中的自动整合可以加速或改善搜索的准确性,因为注释可以包括附加元信息和分析结果,其可以尚未被包含在原始加载到大型数据储存库中的数据集中。
数据集、大型数据储存库、代理和程序引擎可以存储在计算机可读存储介质195上。可以使用一个或多个计算机可读介质的任意组合。计算机可读介质可以是计算机可读信号介质或计算机可读存储介质。计算机可读存储介质可以是例如但不限于电子、磁性、光学、电磁、红外或半导体系统、装置或设备、或上述的任意合适的组合。计算机可读存储介质的更具体的示例(非排他性列表)将包括以下:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(EPROM或闪存存储器)、光纤、便携式光盘只读存储器(CD-ROM)、光学存储设备、磁性存储设备、或者上述的任意合适的组合。在本文档的上下文中,计算机可读存储介质可以是能够包含或存储用于由或结合指令执行系统、装置或设备来使用的程序的任何有形介质。
计算机可读信号介质可以包括其中实施有计算机可读程序代码的传播数据信号,例如在载波的基带中或者作为载波的部分。这样的传播信号可以采用各种形式中的任何形式,包括但不限于电磁、光、或其任意合适的组合。计算机可读信号介质可以是不作为计算机可读存储介质并且能够通信、传播或传送程序用于由或结合指令执行系统、装置或设备来使用的程序的任何计算机可读介质。在计算机可读介质中实施的程序代码可以使用任何适当的介质来传输,包括但不限于无线、有线、光纤线缆、RF等,或者使用上述的任意合适的组合来传输。
用于执行本发明的各个方面的操作的计算机程序代码可以用一个或多个编程语言的任意组合来书写,包括面向对象的编程语言(诸如Java、Smalltalk或C++等)和传统的过程编程语言(诸如“C”编程语言或类似的编程语言)。程序代码可以完全在用户的计算机上、部分在用户的计算机上、作为独立的软件包、部分在用户的计算机上并且部分在远程计算机上、或者完全在远程计算机或服务器上来执行。在后面的场景中,远程计算机可以通过任何类型的网络(包括局域网(LAN)或广域网(WAN))连接至用户的计算机,或者可以做出到外部计算机的连接(例如使用因特网服务提供商通过因特网)。
参考根据本公开的实施例的方法、装置(系统)、和计算机程序产品的流程图图示和/或框图来描述本公开的各个方面。应当理解,流程图图示和/或框图的每个块以及流程图图示和/或框图中的块的组合可以用计算机程序指令来实现。这些计算机程序指令可以被提供给通用计算机、专用计算机、或其他可编程数据处理装置的处理器以产生机器,使得经由计算机或其他可编程数据处理装置的处理器来执行的指令创建用于实现流程图和/或框图块中规定的功能/任务的装置。这些计算机程序指令也可以存储在计算机可读介质中,计算机可读介质可以指示计算机、其他可编程数据处理装置或其他设备按照特定方式工作,使得存储在计算机可读介质中的指令产生包括实现流程图和/或框图块中规定的功能/动作的指令的制造品。
计算机程序指令也可以加载到计算机、其他可编程数据处理装置、或其他设备上以引起在计算机、其他可编程装置、或其他设备上执行一系列操作步骤从而产生计算机实现的过程,使得在计算机或其他可编程装置上执行的指令提供用于实现流程图和/或框图块中规定的功能/动作的过程。附图中的框图图示根据本公开的各种实施例的系统、方法和计算机程序产品的可能实现的架构、功能和操作。在这一点上,框图中的每个块可以表示模块、分段或代码部分,其包括用于实现(多个)规定的逻辑功能的一个或多个可执行指令。还应当注意,在一些备选实现中,上文中讨论的功能可以不按照所公开的顺序来发生。例如,依次教示的两个功能实际上可以基本上同时执行,或者功能有时可以按照相反顺序执行,这取决于所涉及的功能。还应当注意,框图的每个块以及框图中的块的组合可以用专用的基于硬件的系统来实现,该系统执行规定的功能或动作、或者专用硬件和计算机指令的组合。本文中使用的术语仅出于描述特定实施例的目的,而非意图限制本发明。如本文中使用的,单数形式的“一”、“一个”和“该”意图也包括复数形式,除非上下文另外清楚地指明。还应当理解,术语“包括”和/或“包含”当在本说明书中使用时规定所指出的特征、整体、步骤、操作、元素和/或部件的存在,但是不排除一个或多个其他特征、整体、步骤、操作、元素、部件和/或其组的存在或添加。所附权利要求中的所有装置或步骤加上功能元件的对应的结构、材料、动作和等同物意图包括用于结合具体要求保护的其他要求保护的元件执行该功能的任何结构、材料或动作。已经出于说明和描述的目的呈现了本发明的描述,但是并非意图排他或将本发明限于所公开的形式。很多修改和变型对本领域普通技术人员将是清楚的,而没有偏离本发明的精神和范围。实施例被选择和描述以便最佳地解释本发明的原理和实际应用,并且使得本领域普通技术人员能够理解适合预期的特定用途的具有各种修改的本发明的各种实施例。
图2描绘在图1中描述的计算机系统的分布式变型。代理162-168、206以及对应程序引擎134-138、208中的至少一些由另一计算机系统204而非在计算机系统202上运行的其他代理和程序引擎来托管。代理管理器可以基于通信框架(诸如web服务、EJB或.Net等)经由网络与远程代理交互。这一架构可以允许(远程)遗留系统的集成。数据集可以已经被指派优先级号码D.1-D.5,其表示由代理150-168、206中的特定代理处理上述数据集的紧急性。另外,每个代理可以已经被指派优先级号码P.1-P.7,其可以确定在两个或更多个代理竞争特定资源的情况下哪个代理首先执行。工作量管理器176可以从每个程序引擎124-136、208中重复地接收工作量信息,工作量信息表示相应程序引擎或者托管上述程序引擎的计算机系统的能力利用率。工作量管理器向上述程序引擎被指派给其的每个代理提供上述工作量。这一信息使得已经被指派多个等同处理引擎的代理能够选择性地触发当前具有最低能力消耗的程序引擎(例如具有最空队列Q1-Q9的等同处理引擎的集合中的一个处理引擎)的执行。
使用全局任务队列196结合处理引擎特定的队列Q1-Q9可以通过避免处理引擎中的空闲时间来帮助改善性能:取代在使代理触发上述作业引擎的执行之前定期检查特定处理引擎的可用性,甚至在当前由程序引擎执行的任务实际上被进行之前,工作量管理器可以简单地将包含在全局作业队列中的任务(用于在特定数据集上执行特定代理)推送到多个处理引擎特定的队列中的合适的队列中。因此,程序引擎可以开始下一任务而没有延迟。
图3描绘用于处理如以上已经描述的大型数据储存库104的数据集的方法的流程图。在第一步骤302,提供代理的集合150-168。每个代理可操作以触发数据集105、106、110-113、108、DB1、DB2中的一个或多个的处理。上述代理中的每个的执行在向上述代理指派的一个或多个条件满足的情况下自动触发。在步骤304,可以执行代理中的第一代理。第一代理的执行触发第一数据集的处理,例如已经被导入到大型数据储存库104中的平面文件。在由第一代理已经处理第一数据集之后,第一代理在步骤306更新第一数据集的注释,从而在上述注释中包括上述处理的结果。在步骤308,由第一数据集的已更新注释满足第二代理的条件的事件来触发第二代理的执行。第二代理的执行导致第一数据集的进一步处理,并且导致由第二代理进行的第一数据集的注释的进一步更新。
- 还没有人留言评论。精彩留言会获得点赞!