使用RDMA来扫描内存用于删除重复的制作方法
本发明大体上涉及计算系统,并且具体涉及用于在计算节点中资源共享的方法和系统。
发明背景
机器虚拟化常用在各种计算环境中,诸如在数据中心和云计算中。在本领域中已知各种的虚拟化解决方案。例如,VMware公司(帕罗奥多,加州)提供用于诸如数据中心、云计算、个人桌面和移动计算的环境的虚拟化软件。
在一些计算环境中,计算节点可以使用远程直接内存访问(RDMA)技术来直接访问其他计算节点的内存。例如,RDMA协议是在2007年10月的请求注解(RFC)5040的“A Remote Direct Memory Access Protocol Specification”中由Internet工程任务组的网络工作组指定,该文件通过引用并入本文。例如,在2003年4月的“RDMA Protocol Verbs Specification”版本1.0中对支持RDMA的网络接口卡(NIC)进行描述,该文件通过引用并入本文。
发明概述
本文描述的本发明的实施例提供用于存储的方法,该方法包括将多个内存页存储在第一计算节点的内存中。使用经由通信网络与第一计算节点进行通信的第二计算节点,通过直接访问第一计算节点的内存来识别在第一计算节点的内存中存储的内存页中的重复的内存页。将所识别的重复的内存页的一个或多个从第一计算节点中逐出。在实施例中,直接访问第一计算节点的内存包括使用远程直接内存访问(RDMA)协议来访问第一计算节点的内存。
在一些实施例中,逐出重复的内存页包括对重复的内存页中的一个或多个删除重复,或者将重复的内存页中的一个或多个从第一计算节点转移到另一个计算节点。在其他实施例中,该方法包括计算内存页上相应的哈希值,以及识别重复的内存页包括直接从第一计算节点的内存读取哈希值并且识别具有相同的哈希值的内存页。在另外其他实施例中,计算哈希值包括使用网络接口卡(NIC)中的硬件来生成哈希值,该网络接口卡(NIC)将第一计算节点连接到通信网络。
在实施例中,计算哈希值包括预计算第一计算节点中的哈希值并且将与相应的内存页相关的预计算的哈希值存储在第一计算节点中,以及读取哈希值包括直接从第一计算节点的内存中读取预计算的哈希值。在另一个实施例中,计算哈希值包括直接从第一计算节点的内存中读取相应的内存页的内容,并且在第二计算节点中计算关于该相应的内存页的内容的哈希值。
在一些实施例中,逐出重复的内存页包括向第一计算节点提供候选内存页的逐出信息,该逐出信息指示第一计算节点中哪些内存页是用于逐出的候选。在其他实施例中,逐出重复的内存页包括重新计算候选内存页的哈希值,并且避免逐出自被第二计算节点扫描后已改变的内存页。在另外其他实施例中,逐出重复的内存页包括将写时复制保护应用于至少候选内存页,使得对于已改变的给定的候选内存页,第一计算节点将给定的候选内存页的相应的修改的版本存储在不同于给定的候选内存页的位置的位置中,并且不管候选内存页是否已经改变,逐出该候选内存页。
在实施例中,该方法包括将逐出信息存储在一个或多个计算节点中,并且直接在一个或多个计算节点的相应的内存中访问该逐出信息。在另一个实施例中,逐出重复的内存页包括从第一计算节点接收实际被逐出的内存页的响应报告,并且根据该响应报告更新逐出信息。在又一个实施例中,该方法包括直接在第一计算节点和第二计算节点的内存之间共享响应报告。
在一些实施例中,逐出重复的内存页包括共享关于第一计算节点中的页使用统计的信息,并且基于该页使用统计,决定用于逐出的候选内存页。在其他实施例中,该方法包括在第二计算节点中维护所逐出的内存页的访问信息,并且允许第一计算节点通过直接从第二计算节点的内存中读取访问信息来访问逐出的内存页。
根据本发明的实施例,本发明另外提供了包括第一计算节点和第二计算节点的装置。第一计算节点包括内存并且被配置为在内存中存储多个内存页。第二计算节点被配置为经由通信网络与第一计算节点进行通信,通过直接访问第一计算节点的内存来识别在第一计算节点的内存中存储的内存页中重复的内存页,并且通知第一计算节点所识别的重复的内存页,以便促使第一计算节点将所识别的重复的内存页的一个或多个从第一计算节点中逐出。
根据本发明的实施例,本发明另外提供了一种计算机软件产品,该计算机软件产品包括其中存储程序指令的非暂时性计算机可读介质,当指令被经由通信网络与存储多个内存页的第一计算节点进行通信的第二计算节点的处理器读取时,促使处理器通过直接访问第一计算节点的内存来识别在第一计算节点的内存中存储的内存页中重复的内存页,并且通知第一计算节点将所识别的重复的内存页的一个或多个从第一计算节点中逐出。
根据结合附图进行的本发明的实施例的以下详细描述,本发明将被更完全地理解,其中:
附图简述
图1是根据本发明的实施例示意性示出计算系统的框图;以及
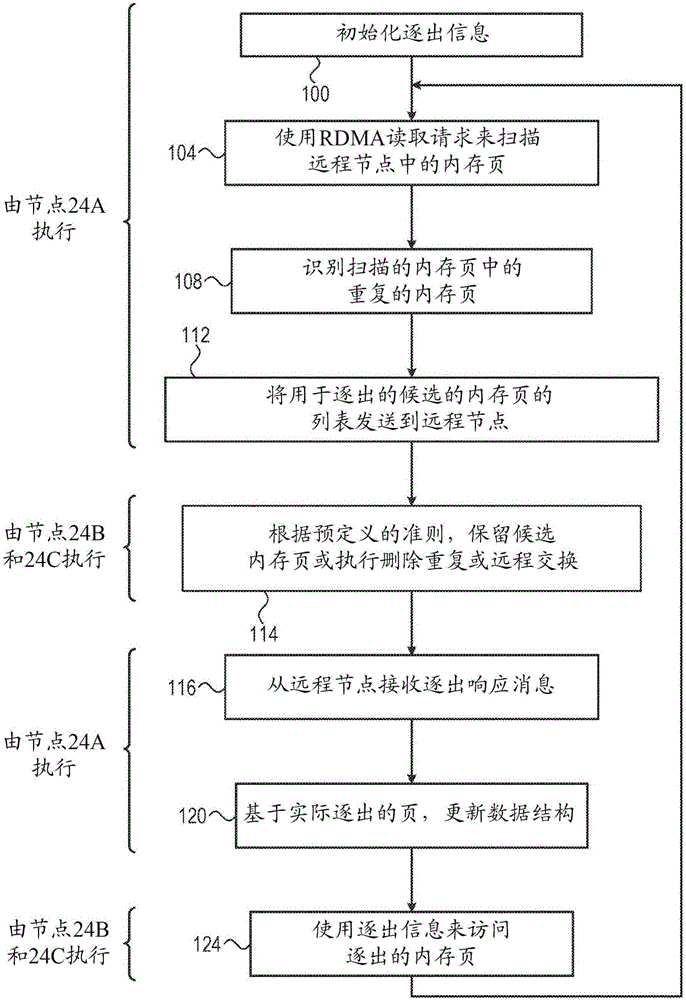
图2是根据本发明的实施例示意性示出用于删除重复内存页的方法的流程图,该方法包括使用RDMA扫描其他计算节点中重复的内存页。
具体实施方式
概述
各种计算系统(诸如,数据中心、云计算系统和高性能计算(HPC)系统)在由通信网络连接的计算节点的集群上运行虚拟机(VM)。为简洁起见,计算节点还被简称为“节点”。在许多的实际情况下,限制VM性能的主要瓶颈是缺乏可用内存。例如,有限的内存资源可以限制计算节点能同时托管的VM的数量。增加可用内存的一种可能的方式是对重复的内存页的删除重复。
本文描述的本发明的实施例提供用于内存页删除重复的改进的方法和系统。在下面的描述中,虽然我们假设基本存储单元被称为内存页,但是所公开的技术适合于其他种类的基本存储单元。本文描述的方法和系统使得给定的计算节点能够使用直接内存访问技术来扫描另一个节点上或甚至跨整个节点集群的重复的内存页。
在本发明的上下文中以及在权利要求中,诸如“对计算节点的内存的直接访问”和“直接从计算节点的内存读取”的术语指的是一种并不加载或以其他方式涉及该节点的CPU的内存访问。在一些实施例中,执行直接内存访问的示例协议包括RDMA协议,该RDMA协议例如,在计算节点的NIC上被实现为例如,一组RDMA协议原语。虽然我们主要将RDMA称为直接访问协议,但是也可以使用用于直接访问远程内存的任何其他合适的方法。
内存资源使用效率低下的一个主要原因是单独的计算节点内和/或跨节点集群的某些内存页的复制副本的存储。例如,运行在一个或多个计算节点中的多个VM可以执行诸如例如操作系统(OS)的公用程序的重复的实例。用于通过将一个节点配置为使用RDMA来扫描另一个节点的内存页同时搜索要合并的重复的内存页来提高内存利用率的几个技术将在下面详细地进行描述。
一种执行删除重复的方式是执行两个阶段。首先,应该识别重复的内存页,并且然后应该丢弃或以其他方式处理至少一些重复的页。通常,节点中的超级管理器将CPU资源分配给VM和分配给删除重复过程两者。由于重复的内存页的识别需要大量的CPU资源,CPU忙碌(例如,运行VM)的节点可能没有足够的CPU资源用于内存删除重复。因此,减少该节点中的重复的内存页可能是差的或被延迟。因为将扫描的内存页加载到CPU缓存中(还被称为缓存污染影响),另外,由本地CPU识别重复的内存页往往会降低VM性能。
在所公开的技术中,在搜索重复的内存页中扫描给定的计算节点的内存页的任务被委派给一些其他节点,通常是具有空闲的CPU资源的节点。执行扫描的节点在本文中还被称为远程节点,以及内存页正在被远程地扫描的节点在本文中还被称为本地节点。由于这种任务委派,甚至可以在非常忙碌的节点上实现有效的删除重复。扫描过程通常使用RDMA来执行,即,通过直接访问扫描的节点的内存而没有涉及扫描的节点的CPU。从而,有效地从重复的页扫描任务中卸载扫描的节点。
扫描节点可以搜索单个扫描的节点上或多个扫描的节点上的重复的内存页。通过扫描多个扫描节点中的内存页而不是分别地扫描每节点中的内存页,驻留在不同的节点中的重复的内存页可以被识别并且处理,由此提高集群范围的内存利用率。
在本地节点和远程节点之间的删除重复任务的划分导致节点间的一些通信开销。为了减少这样开销,在一些实施例中,本地节点将扫描的内存页的哈希值而不是内存页的(更加大得多的)内容转移到远程节点。在一些实施例中,在存储内存页时或者在运行时使用本地节点的NIC中的硬件执行哈希值的计算。这种特征从计算哈希值中卸载本地节点的CPU。
在一些实施例中,作为扫描过程的一部分,远程节点生成逐出信息,该逐出信息识别要从本地节点逐出的内存页。远程节点然后向本地节点通知要被逐出的内存页。
本地节点可以以各种方式逐出本地内存页。例如,如果集群范围内或者至少局部地在节点中存在足够数量的页的副本,该页可以从本地节点中删除。页删除的这种过程被称为删除重复。如果页的副本的数量不允许删除重复,该页可以被导出到另一个节点,例如,被导出到其中内存压力较低的节点。可替换地,重复的页可能已经在另一个节点上存在,以及因此该节点可以本地删除该页并且维护对远程重复的页的访问信息。删除被导出的(或者已具有远程副本的)本地页的后者过程被称为远程交换。在本专利申请的上下文中以及在权利要求中,内存页的术语“逐出”指的是删除重复、远程交换(根据要被本地删除的内存页是否分别具有本地或远程副本)或减少重复的内存页的任何其他方式。
在实施例中,基于例如,对内存页的访问模式,从远程节点接收逐出信息的本地节点将删除重复或远程交换应用到要被逐出的内存页。本地节点然后向远程节点报告实际上逐出哪些内存页(例如,自被传递到远程节点后已经改变的内存页不应该被逐出),并且远程节点相应地更新逐出信息。在实施例中,当本地节点访问之前已被逐出的内存页时,本地节点首先使用RDMA来访问远程节点中的逐出信息。
集群中的节点可以被配置为以各种方式使用RDMA用于共享内存资源。例如,在实施例中,远程节点将部分的逐出信息或所有的逐出信息存储在一个或多个其它节点中。在这样的实施例中,当本地不可用时,远程节点和本地节点使用RDMA来访问逐出信息。
作为另一个示例,用于识别重复的内存页的扫描内存页的任务可以由两个或更多节点的组执行。在这样的实施例中,在该组中的每个节点使用RDMA来扫描其他节点(可能包括该组中的其他成员节点)中的内存页。作为又一个示例,节点可以通过允许使用RDMA对该信息进行访问来与其他节点共享诸如页访问模式的本地信息。
系统描述
图1是根据本发明的实施例示意性示出计算系统20的框图,该计算系统20包括计算节点24的集群。系统20可以包括,例如,数据中心、云计算系统、高性能计算(HPC)系统、存储系统或任何其他合适的系统。
计算节点24(为简洁起见简称为“节点”)通常包括服务器,但可替换地包括任何其他合适类型的计算节点。图1中的节点集群包括三个计算节点24A、24B和24C。可替换地,系统20可以包括相同类型或不同类型的任何其他合适数量的节点24。
节点24是通过用于集群内通信的通信网络28(通常是局域网(LAN))进行连接的。网络28可以根据任何合适的网络协议(诸如,以太网或InfiniBand)操作。
每个节点24包括中央处理单元(CPU)32。根据计算节点的类型,CPU 32可以包括多个处理核心和/或多个集成电路(IC)。不管具体的节点配置,节点的处理电路在本文中总体上被认为是节点CPU。每个节点24还包括存储多个内存页42的内存36(通常是诸如动态随机存取存储器-DRAM的易失性存储器)以及用于经由通信网络28与其他计算节点进行通信的网络接口卡(NIC)44。在InfiniBand术语中,NIC 44还被称为主机通道适配器(HCA)。
节点24B和24C(以及可能节点24A)通常运行虚拟机(VM)52,该虚拟机52反过来运行客户应用程序。超级管理器58管理诸如CPU时间的计算资源、输入/输出(I/O)带宽和内存资源的向VM 52的提供。在其他任务中,超级管理器58使得VM52能够访问本地驻留的以及其他计算节点中的内存页42。在一些实施例中,超级管理器58另外管理计算节点24中内存资源的共享。
在下面的描述中,我们假设NIC 44包括支持RDMA的网络适配器。换言之,NIC 44将RDMA协议实现为,例如,一组RDMA协议原语(例如,如在上面引用的“RDMA Protocol Verbs Specification”中描述的)。使用RDMA使得一个节点(例如,本示例中的节点24A)能够直接访问(例如,读取、写入或两者)存储在另一个节点中的内存页42(例如,42B和42C),而没有涉及运行在其他节点上的CPU或操作系统(OS)。
在一些实施例中,在内存页的内容上计算的哈希值被用作识别集群范围的内存页(以及其相同的副本)的唯一标识符。哈希值还被称为全球唯一内容ID(GUCID)。注意,哈希只是可用于将页内容进行索引的签名或索引的示例形式。可替换地或另外,可使用任何其他合适的签名或索引方案。例如,在一些实施例中,当在内存页上计算的相应的循环冗余码(CRC)被发现是不同时,内存页被识别为非重复的。
NIC 44包括哈希引擎60,该哈希引擎60可被配置为计算NIC 44访问的内存页的哈希值。在一些实施例中,哈希引擎60计算内存页的内容上的哈希值,将用于识别重复的内存页。可替换地,为了非匹配内存页的快速拒收,哈希引擎60首先计算快速得到的(但对于唯一页识别太弱)CRC或一些其他校验和,并且只有在内存页的CRC匹配时才计算哈希值。
除存储内存页42外,内存36存储逐出信息64,该逐出信息64包括用于执行页逐出过程(即,删除重复和远程交换)的信息并且使得计算节点24能够访问之前已经被逐出的内存页。内存36另外存储内存页表66,该内存页表66保存对逐出的页的访问信息并且更新后面的删除重复或远程交换。内存页表66和逐出信息64可包括内存页的元数据,诸如,例如,该内存页的存储位置和关于该内存页内容计算的哈希值。在一些实施例中,逐出信息64和内存页表66被实现为统一的数据结构。
在一些实施例中,给定的计算节点被配置为搜索集群中其他计算节点中的重复的内存页。下面的描述包括示例,在该示例中,节点24A分别扫描节点24B的内存页42B和24C的内存页42C。在我们的术语中,节点24A用作远程节点,而节点24B和24C用作本地节点。节点24A通常执行扫描软件模块70,以执行其他节点中的页扫描以及管理用于逐出的候选内存页的选择。扫描软件模块70的执行可以根据节点24A的硬件配置。例如,在一个实施例中,节点24A包括超级管理器58A和一个或多个VM52,并且超级管理器或者VM中的一个VM执行扫描软件70。在另一个实施例中,CPU32A执行扫描软件70。在另外其他实施例中,节点24A包括执行扫描软件70的硬件加速器单元(未在图中示出)。
在一些实施例中,代替传递扫描的内存页的内容,NIC 44B和44C使用哈希引擎60来计算运行的被扫描的内存页的哈希值,并且将哈希值(而不是内存页的内容)传递到NIC 44A,该NIC 44A将哈希值存储在内存36A中。因为内存页的大小通常比其相应的哈希值的大小大得多,所以这种特征大大地减少网络28上的通信带宽。另外,这种特征从计算哈希值中卸载远程节点和本地节点的CPU。
在替换的实施例中,代替NIC 44B和44C或者结合NIC 44B和44C,节点24B和24C中的CPU 32B和32C或其他模块计算内存页的哈希值。另外可替换地,哈希值可以关联于相应的内存页进行计算和存储(例如,当最初存储内存页时),以及在扫描内存页时哈希值可被检索。因此,当节点24A扫描内存页42B和42C时,代替计算运行中的哈希值,节点24A使用RDMA来读取由本地节点预计算并且存储的哈希值。
使用哈希引擎(例如,60B和60C)来计算运行中的哈希值使CPU 32免于计算这些哈希值,从而提高CPU资源的利用率。在替换的实施例中,NIC 44B和44C将内存页42B和44C的内容传递到NIC 44A,该NIC 44A在内存36A中进行存储之前计算相应的哈希值。
节点24A中的扫描软件模块70分析从节点24B和24C检索的哈希值并且生成相应的逐出信息64A,该逐出信息64A包括对要逐出的内存页42B和42C的访问信息。逐出后,节点24B和24C读取逐出信息64A,以检索对之前被逐出的内存页42B和42C的访问信息。节点42B和24C另外更新它们相应的页内存表66。
在一些实施例中,节点24A包括硬件加速器,诸如,例如,加密或压缩加速器(未在图中示出)。在这样的实施例中,代替CPU 32A或除CPU 32A外,可以使用加速器,用于例如,通过执行扫描软件模块70来扫描内存页42B和42C。可替换地,可使用任何其他合适的硬件加速器。
计算节点的集群上的VM的资源共享的其它方面是在美国专利申请14/181,791和14/260,304中被解决了,该两个专利申请被转让给本专利申请的受让人并且其公开内容通过引用并入本文。
在图1中示出的系统和计算节点配置是示例配置,仅仅为了概念上阐述的清晰起见而被选择。在替换的实施例中,可使用任何其他合适的系统和/或节点配置。系统20的各种元件,尤其是节点24的元件,可以使用诸如在一个或多个专用集成电路(ASIC)或现场可编程门阵列(FPGA)中的硬件/固件来实施。可替换地,一些系统或节点元件(例如,CPU 32)可以在软件中或使用硬件/固件和软件元件的组合来实施。
在一些实施例中,CPU 32包括在软件中被编程以执行本文描述的功能的通用处理器。可经由网络以电子形式将软件下载到处理器,例如,或者所述软件可以可选地或附加地被提供和/或存储在非暂时性有形媒介上,诸如磁存储器、光学存储器或电子存储器。
在上面的图1中,计算节点24使用NIC设备来互相进行通信,该NIC设备能够经由网络进行通信并且例如,使用RDMA来直接访问其他计算节点的内存。在替换的实施例中,还可以使用其他设备,不管底层通信介质和/或使用除RDMA外的直接访问协议,该其他设备使得计算节点能够互相进行通信。这样的设备的示例包括能进行RDMA的NIC、能进行非RDMA的以太网NIC和InfiniBand HCA。
在一些实施例中,通信发生在访问内存的主机和相同服务器中的另一个主机之间。在这样的实施例中,直接内存访问可以使用执行直接内存访问的任何合适的总线控制设备(诸如,经由“PCIe网络”或经由任何其他合适的专有总线类型或其他总线类型进行通信的设备)来完成。
在一些实施例中,计算节点之间的通信方案包括通信设备(例如,NIC)和内存访问设备(例如,使用PCIe网络来访问内存的设备)。
实现通信设备、直接内存访问设备或两者的硬件,可包括例如,能进行RDMA的NIC、FPGA或通用计算图形处理单元(GPGPU)。
通过使用RDMA扫描远程节点中的内存页来识别重复的内存页
图2是根据本发明的实施例示意性示出用于删除重复内存页的方法的流程图,该方法包括使用RDMA扫描其他计算节点中重复的内存页。在本示例中,以及参考以上图1中描述的系统20,计算节点24A管理内存页42B和42C中副本的逐出。重复的内存页可包括内存页42A中的本地页。在替换的实施例中,系统20可包括任何合适数量的计算节点(除三个外),计算节点的任何合适的子组被配置为对集群范围的内存页删除重复。
在实施例中,与扫描软件模块70相关的部分是由节点24A执行的并且其他部分是由节点24B和24C执行的。在本示例中,节点24A包括超级管理器58A,该超级管理器58A执行与扫描软件模块70相关的方法部分。可替换地,节点24A的另一个元件(诸如,CPU32A或硬件加速器)可以执行扫描软件模块70。
该方法开始于初始化步骤100,通过超级管理器58A初始化逐出信息64A。在一些实施例中,超级管理器58A将逐出信息64A进行初始化到空的数据结构。可替换地,超级管理器58A扫描本地内存页24A,识别扫描的内存页中的副本(例如,使用将在下面描述的方法),并且相应地初始化逐出信息64A。
在扫描步骤104处,超级管理器58A使用RDMA来扫描内存页42B和42C。为了扫描内存页,如本文描述的,超级管理器58A读取内存页42B和42C的到内存36A中的内容或其哈希值。在一些实施例中,NIC 44B和44C被配置为计算(例如,分别使用哈希引擎60B和60C)相应的内存页42B和42C的哈希值(即,没有涉及CPU 32B和32C),并且通过NIC 44A将计算的哈希值传递到内存36A。可替换地,如上所述,哈希值可以由本地节点预计算并且存储。
另外可替换地,NIC 44B和44C使用RDMA来检索相应的内存页42B和42C的内容,并且将检索的内存页的内容传递到内存36A。在实施例中,当接收内存页42B和42C的内容时,NIC 44A计算内存页的相应的哈希值并且将该哈希值存储在内存36A中。
在聚类步骤108处,通过分析内存36A中的检索的哈希值,超级管理器58A识别用于逐出的候选内存页。换言之,超级管理器58A将对应于相同的哈希值的内存页42B和42C分类为重复的内存页。在其中步骤104处内存36A存储内存页42B和42C的检索的内容的实施例中,超级管理器58A通过将内存页的内容进行比较来识别重复的内存页。在一些实施例中,由超级管理器58A对副本的识别包括内存页24A。
在发送步骤112处,超级管理器58A向超级管理器58B和58C中的每一个发送用于逐出的候选内存页的相应的列表。如将在下面描述的,基于候选列表和页访问模式,超级管理器58B和58C通过应用删除重复或远程交换来执行相应的内存页的本地逐出。虽然描述主要指的是超级管理器58B,但是超级管理器58C的行为类似于超级管理器58B。
在候选列表中的页的内容可以在当节点24A接收/计算哈希值并且将给定的页放在列表中时的事件和当本地节点接收用于逐出的该候选列表(包括给定的页)时的事件之间变化。在超级管理器58B从节点24A接收候选列表后,超级管理器58B在逐出步骤114处,重新计算候选内存页的哈希值,并且如上所述,对哈希值(并且因此内容)已改变的内存页排除逐出。
在替换的实施例中,本地节点24B和24C将写时复制保护应用到本地内存页。在这样的实施例中,当给定的页改变时,超级管理器保持原来未修改的给定的页,并且将该页的修改的版本写入在不同的位置。通过使用写时复制,本地节点不需要检查给定的候选页是否如上所述已经改变。
进一步地,在步骤114处,超级管理器58B根据预定义的准则,决定是否执行删除重复或者是否远程交换到未改变的候选内存页。预定义的准则可以例如,与由节点24B的VM对内存页的使用或访问配置文件相关。可替换地,可使用任何其他合适的准则。逐出后,超级管理器58B向超级管理器58A报告实际上从节点24B逐出的内存页。
在访问步骤124处,超级管理器58B和58C使用逐出信息64A来访问之前已经被逐出的相应的内存页42B和42A。超级管理器58A然后循环回到步骤104,以重新扫描节点24B和24C的内存页。注意,当访问在另一个节点上存在的给定的内存页时,以及对于本地节点没有本地副本(例如,由于对给定的页的远程交换),本地节点使用逐出信息64来定位页并且检索页返回(还被称为页调入操作)。
上面描述的实施例是通过示例的方式呈现,并且还可以使用其他合适的实施例。例如,虽然在上面图2的示例中单个节点(24A)扫描其他节点(24B和24C)的内存页,但是在替换的实施例中,两个或更多节点可被配置为扫描其他节点的内存页。
作为另一个示例,如上所述,节点24A通过分析其扫描的内存页或哈希值生成的逐出信息64A可以驻留在两个或更多节点中并且使用RMDA进行访问(当本地不可用时)。
在一些实施例中,如以上在步骤114处描述的,当给定的节点(例如,24B)向远程节点(例如,24A)报告实际被逐出的内存页时,给定的节点将该报告放置在公共内存区域(例如,在内存36B或36C),并且节点24A使用RDMA来访问该报告。
在上面图2的示例中,节点24B和24C收集由本地VM访问的页的统计,并且使用这种信息来决定逐出类型(删除重复或远程交换)。在替换的实施例中,该节点使用RDMA来与其他节点共享关于页访问统计的信息(或任何其他合适的本地信息)。
将要理解的是,以上描述的实施例是通过示例的方式引用的,并且本发明不限于上文中已经特别示出和描述的那些情况。而是,本发明的范围包括上文所描述的各种特征的组合和子组合,以及本领域技术人员在阅读以上描述之后将想到的且未在现有技术中公开的变型和修改。通过引用结合在本专利申请中的文档被视为本申请的组成部分,除了在这些结合的文档中的任何术语以与本说明书中明确地或隐含地作出的定义冲突方式定义时,仅应考虑本说明书中的定义。
- 还没有人留言评论。精彩留言会获得点赞!