基于来自多个数据中心的信息的虚拟机放置的制作方法
本发明大体上涉及虚拟化计算,并且具体地涉及用于虚拟机(VM)放置的方法和系统。
发明背景
机器虚拟化常用在各种计算环境中,诸如在数据中心和云计算中。在本领域中已知各种虚拟化解决方案。例如,VMware公司(帕罗奥多,加州)提供用于诸如数据中心和云计算的环境的虚拟化软件。虚拟化计算系统常常运行用于选择哪个物理主机要运行给定的VM的VM放置过程。
发明概述
本文描述的本发明的实施例提供了一种方法,该方法包括收集在第一计算机网络中的第一主机上运行的第一工作负载的性能特性。从第一工作负载的性能特性得到用于将工作负载分配到主机的一个或多个放置指令。根据放置指令,第二工作负载被分配到第二计算系统中的第二主机,该第二计算系统独立于第一计算系统。
在一些实施例中,第一计算机网络和第二计算机网络包括虚拟化数据中心,以及第一工作负载和第二工作负载包括虚拟机(VM)。在实施例中,导出放置指令包括根据性能特性将第一工作负载分类为多个类,并且根据所述类指定放置指令。在另一个实施例中,将第二工作负载分配到第二主机包括基于从第一工作负载得到的放置指令,预测第二工作负载的资源使用模式,并且基于预测的资源使用模式,将第二工作负载分配到第二主机。
在公开的实施例中,性能特性的收集和放置指令的应用是通过第一计算机系统和第二计算机系统中的本地放置单元执行的,以及放置指令的导出是通过第一计算机网络和第二计算机网络外部的全局放置单元来执行的。在另一个实施例中,收集性能特性包括收集第一工作负载的时间资源使用模式。
在又一个实施例中,收集性能特性包括收集第一工作负载中的两个或多个第一工作负载之间的通信交互。在再一个实施例中,该方法包括估计第一主机的可用资源,以及导出放置指令包括基于所估计的可用资源来指定放置指令。
在实施例中,收集性能特性包括收集第一计算机网络和第二计算机网络两者中的第一工作负载和第二工作负载上的性能特性,以及导出放置指令包括基于在第一计算机网络和第二计算机网络上收集的性能特性,来指定放置指令。在一些实施例中,该方法可以包括基于所收集的性能特性,将第二计算系统中的第二主机中的一个或多个的一个或多个物理资源分配到第二工作负载中的一个或多个。
根据本发明的实施例,本发明另外提供了一种系统,所述系统包括第一本地放置单元和第二本地放置单元以及全局放置单元。第一本地放置单元被配置为收集在第一计算机网络中的第一主机上运行的第一工作负载的性能特性。全局放置单元被配置为从第一工作负载的性能特性导出用于将工作负载分配到主机的一个或多个放置指令。第二本地放置单元被配置为根据放置指令,将第二工作负载分配到第二计算系统中的第二主机,该第二计算系统独立于第一计算系统。
根据本发明的实施例,本发明还提供了一种装置,所述装置包括接口和处理器。接口被配置为与独立的第一计算机网络和第二计算机网络进行通信。处理器被配置为经由接口接收在第一计算机网络中的第一主机上运行的第一工作负载的性能特性,以从第一工作负载的性能特性导出用于将工作负载分配到主机的一个或多个放置指令,并且经由接口将指令发送到第二计算系统,用于将第二工作负载分配到第二计算系统中的第二主机。
根据以下结合附图进行的对本发明的实施例的详细描述,本发明将被更完全地理解,其中:
附图简述
图1是根据本发明的实施例示意性示出VM放置系统的框图;以及
图2是根据本发明的实施例示意性示出用于VM放置的方法的流程图。
具体实施方式
概述
本文所描述的本发明的实施例提供用于计算机网络中工作负载的放置的改进的方法和系统。在本上下文中,术语“放置”意味着工作负载到物理主机的分配,其包括哪个工作负载将要在哪个主机上运行的决定。给定工作负载的放置可以在提供且运行工作负载之前或之后执行。后者过程常常被称为迁移。
本文描述的实施例主要指的是虚拟化数据中心中的虚拟机(VM)的放置。然而,所公开的技术可以与各种其他类型的工作负载一起使用并且可以在各种其他类型的计算机网络中使用。
在所公开的实施例中,向多个独立的数据中心提供被称为本地放置单元的相应的软件组件。另外,全局放置单元与各种本地放置单元(例如,云服务)进行通信。每个本地放置单元收集在其相应的数据中心中运行的VM的性能特性。全局放置单元累积跨多个数据中心收集的性能特性,并且从累积的性能特性中导出VM放置指令。放置指令被发回到本地放置单元,该本地放置单元反过来在它们相应的数据中心应用放置指令。
例如,可以定义几类VM,例如,短寿命的VM、突发性VM或倾向于广泛地相互进行通信的一对VM。放置指令可以指定如何将VM分类为多个类中的一个类,以及如何放置该类中的VM。以这种方式,本地放置单元能够预测VM的资源使用模式,并且相应地将它们分配到主机。
当使用所公开的技术时,在一个数据中心中的VM放置可以使用在另一个数据中心中收集的信息进行优化。这样的技术例如,在小或新的数据中心中是有利的,该小或新的数据中心能受益于在更大或更成熟的数据中心中收集的信息。此外,所公开的技术使得全局放置单元能够超过任何单独的数据中心的规模,指定、测试并且细化关于大量的VM和主机的放置指令。由此,放置指令通常更准确并且使得每个单独的数据中心能够更好地利用它的可用资源。
此外,当使用所公开的技术时,给定的数据中心中的本地放置单元可以使用在另一个数据中心中收集的工作负载性能特性,以用于将物理主机资源(例如,CPU、内存或网络资源)分配给本地数据中心中的VM。
系统描述
图1是根据本发明的实施例示意性示出VM放置系统20的框图。系统20跨多个数据中心操作。为清楚起见,图1的示例只示出两个数据中心24A和24B。可替换地,然而,系统20可以在任何期望的数量的数据中心上操作。数据中心24通常是相互独立的并且可由不同方操作。
每个数据中心包括物理主机28,该物理主机28通过通信网络36连接。每个主机运行一个或多个虚拟机(VM)32。VM消耗主机的物理资源,例如,内存、CPU和网络资源。主机28可以包括例如,服务器、工作站或任何其他合适的计算平台。网络36可以包括例如,以太网或Infiniband局域网(LAN)。
在一些实施例中,每个数据中心24包括相应的本地放置单元40,该本地放置单元40执行与该数据中心中的VM的放置有关的各种任务。另外,系统20包括全局放置单元52,基于跨多个数据中心收集的信息,该全局放置单元52指定VM放置指令。下面更详细地描述了本地放置单元40和全局放置单元52的功能。
本地放置单元40经由广域网56(诸如,因特网)与全局放置单元52进行通信。每个本地放置单元40包括网络接口44,其用于经由网络36与其相应的数据中心的主机28进行通信,并且用于经由网络56与全局放置单元52进行通信。每个本地放置单元还包括处理器48,该处理器48执行本地放置单元的各种的处理任务。全局放置单元52包括网络接口60以及处理器64,该网络接口60用于经由网络56与本地放置单元40进行通信,处理器64执行全局放置单元的各种的处理任务。
图1中示出的系统配置是示例配置,其仅仅被选择用于概念清晰的目的。在替换的实施例中,可使用任何其他合适的系统配置。例如,虽然本文描述的实施例主要指的是VM的放置,但是所公开的技术可以用于任何其他合适类型的工作负载的放置,诸如应用程序和/或操作系统进程或容器。虽然本文描述的实施例主要指的是虚拟化数据中心,但是所公开的技术可以用于在任何其他合适类型的计算机系统中的工作负载的放置。
系统20的各种元件,尤其是放置单元40和/或52的元件,可以使用诸如在一个或多个专用集成电路(ASIC)或现场可编程门阵列(FPGA)中的硬件/固件来实施。可替换地,一些系统元件(例如,处理器48和/或64)可以在软件中或使用硬件/固件和软件元件的组合来实施。在一些实施例中,处理器48和/或64包括在软件中编程以执行本文描述的功能的通用处理器。可经由网络以电子形式将软件下载到处理器,例如,或者所述软件可以可选地或附加地被提供和/或存储在非暂时性有形介质上,诸如磁存储器、光学存储器或电子存储器。
基于在多个数据中心上收集的性能特性的放置指令
作为每个数据中心24的正在进行的操作的部分,每个本地放置单元40作出放置决定并且相应地将VM 32分配给主机28。放置决定是基于例如VM的性能特性并且基于主机的可用的物理资源(例如,CPU、内存和网络资源)。放置决定的目的通常是预测VM的未来资源消耗,并且将VM分配给主机以便最佳地提供所需的资源。
每个本地放置单元40通常通过应用一组放置指令来将VM 32分配给主机28。在一些实施例中,基于跨多个数据中心24收集的信息,由全局放置单元52指定放置指令。
本地放置单元40通常收集VM 32的各种性能特性。给定VM的性能特性可以包括例如创建VM的图像的大小、存储器的配置文件和随着时间推移的CPU和网络资源的使用、VM时间使用模式(例如,启动时间、停止时间、使用持续时间)。本地放置单元40向全局放置单元52报告这些性能特性,该全局放置单元52使用这些性能特性来指定放置指令。
在一些实施例中,本地放置单元40将VM32分类为几类,并且还根据该类定义放置指令。通过将给定的VM进行分类,本地放置单元40能够预测VM的预期资源使用模式,并且将其分配给将能够提供预期的资源的主机。
例如,放置指令可以指定如何识别并且放置短寿命的VM,例如,开始的VM在短的时间段内执行大量的计算,保存结果并且停止。例如,假设大多数短寿命的VM是从一定大小的图像中创建的。因此,放置指令可以指定具有这样的图像大小的VM应该被放置在将能够在下一个规定的时间段内提供某些指定的内存/CPU/网络资源的主机上。
实际上,短寿命的VM的行为可以很好地在一个数据中心中定义和分类,例如,因为它是大的数据中心或者因为它已经运行了很长一段时间了。另一个数据中心(其可以是新的或小的)可以受益于根据前者数据中心的VM导出的放置指令。
作为另一个示例,一些VM可以被分类为“突发性”VM,即,除了在其中资源消耗峰值达到大的数值的短时间段内,在大多数时间内消耗很少或不消耗资源的VM。如果突发性VM在一个数据中心中是常见的但在另一个数据中心中是罕见的,有可能使用来自第一数据中心的信息,以便指定如何识别并且放置突发性VM。这种放置指令然后可以有效地在第二数据中心中被应用。
作为又一个示例,基于第一数据中心中的分析,已知具有某个性能特性的一对VM可以广泛地相互进行通信。使用这种信息,全局放置单元52可以定义用于将这样的VM放置在相同的主机上的指令。该指令可以由第二数据中心的本地放置单元应用,即使第二数据中心并不具有用于导出这样的指令的充分统计量。
以上描述的放置指令仅仅通过示例的方式描绘。在替换的实施例中,系统20可以基于任何其他合适的VM性能特性来定义并且应用任何其他合适的放置指令。在一些实施例中,本地放置单元40还向全局放置单元52报告各个主机的可用资源。全局放置单元可以在导出放置指令方面考虑所报告的资源。
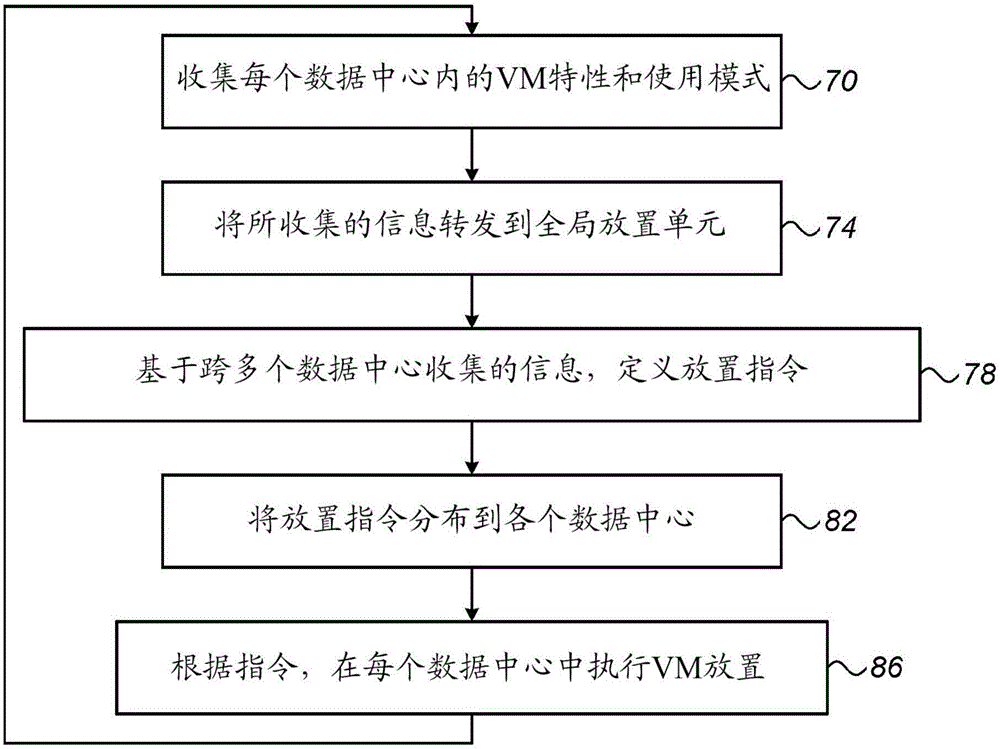
图2是根据本发明的实施例示意性示出用于VM放置的方法的流程图。该方法在收集步骤70处以本地放置单元40收集VM性能特性(例如,使用模式)为开始。每个本地放置单元收集在其相应的数据中心中的VM上的信息。在转发步骤74处,本地放置单元40将所收集的信息转发到全局放置单元52。
在指令导出步骤78处,全局放置单元52从跨多个数据中心收集的信息导出一个或多个VM放置指令。例如,如上所述,指令可以指定如何识别VM属于给定的类,以及如何放置该类的VM。
在指令分布步骤82处,全局放置单元52将放置指令分布给在各种数据中心中的本地放置单元40。在每个数据中心中,在放置步骤86处,本地放置单元40基于指令将VM分配给主机。图2的过程通常是持续的,即,随着时间推移而重复并且更新。
虽然本文描述的实施例主要解决VM或其他工作负载的放置,但是本文描述的方法和系统还可以用于其他应用。例如,给定的数据中心中的本地放置单元40可以使用在另一个数据中心中收集的工作负载性能特性,以用于将物理主机资源(例如,CPU、内存或网络资源)分配给工作负载。
因此,应理解上述实施例是通过实例引用的,本发明并不限于上文已具体示出和描述的内容。而是,本发明的范围包括上文描述的各种特征的组合和子组合,以及本领域的技术人员在阅读上述描述后想到的和在现有技术中没有公开的其变型和修改。通过引用并入在本专利申请中的文档将被认为是本申请的组成部分,当在某种程度上任何术语是以与在本说明书中显式或隐式做出的定义冲突的方式在这些并入的文档定义时,仅以本说明书中的定义应该被考虑。
- 还没有人留言评论。精彩留言会获得点赞!