通过知识库促进的用户兴趣的制作方法
随着计算系统在社会上变得普及,数字内容已经激增。随着大量的数字内容现在可供使用,识别以及呈现与用户相关的数字内容变得日益重要。例如,用户可以将搜索查询输入到搜索引擎中以定位相关的网站或其它数字内容。搜索引擎可以分析大量的数字内容从而识别出相关的数字内容。这样做时,搜索引擎可以评估搜索查询以确定用户意图从而提供相关的搜索结果。
技术实现要素:
本公开部分地涉及确定通过知识库所促进的用户兴趣,基本上如至少一个附图所示和/或结合至少一个附图所描述的,以及如权利要求中更完整阐述的。根据本公开的实现,用户兴趣能够通过知识库的促进而确定、发现和更新。可处理用户活动,从而确定用户已经与哪些数字内容交互。可以对用户已经与其交互的数字内容进行评估,从而确定数字内容的主题。该主题可从知识库的实体中选出并且可映射到数字内容。
通过利用知识库分析主题,可以对用户兴趣做出推断。例如,可以分析主题之间的关系以发现用户的新兴趣或者重新评估兴趣的现有级别的量化。因此,可以从否则可能未被发现的数字内容中发现新的相关兴趣。此外,随着关于用户或用户兴趣变化的更多信息可用,随时间推移可以更新用户兴趣。因此,知识库允许对用户已经与其交互的数字内容进行深入理解。而且,呈现给用户的附加数字内容可以利用知识库按用户兴趣进行定制。
提供该发明内容以便以简化的形式来引入下面的具体实施方式中进一步描述的概念的选择。该发明内容不旨在识别所要求保护的主题的关键特征或主要特征,也不旨在作为单独地用于确定所要求保护的主题的范围的辅助。
附图说明
下文参考随附的附图详细描述本公开的实现,其中:
图1是适合用于本公开的实现的示例性计算环境的框图;
图2示出了根据本公开的实现来确定用户兴趣的示例性系统;
图3描绘了根据本公开的实现用于确定用户兴趣的示例性方法的流程图;
图4描绘了根据本公开的实现用于确定用户兴趣的示例性方法的流程图;
图5示出了根据本公开的实现的示例性系统;以及
图6描绘出根据本公开的实现的知识库的示例性内容。
具体实施方式
本文具体描述本发明的实施例的主题以满足规定的要求。然而,说明书本身不旨在限制该专利的范围。相反,发明人已经设想,所要求保护的主题可以通过其它方式与其它当前或未来的技术相结合来具体实施,以包括不同的步骤或类似于该文档中所描述的步骤的组合。而且,虽然术语“步骤”和/或“块”在本文中用来暗示所具体实施的方法的不同要素,但是该术语不应解释为暗指本文公开的各步骤当中或之间的任何特定的次序,除非以及除了当单个步骤的次序被明确描述之外。
本公开部分地涉及确定知识库促进的用户兴趣,基本上如至少一个附图所示和/或结合至少一个附图所描述的,以及如权利要求中更完整阐述的。根据本公开的实现,用户兴趣可通过知识库的促进而确定、发现和更新。可以处理用户活动从而确定用户已经与哪些数字内容交互。用户已经与其交互的数字内容可被评估从而确定数字内容的主题。该主题可从知识库的实体选出并且可以映射到数字内容。
通过利用知识库分析主题,可以对用户兴趣做出推断。例如,能够分析主题之间的关系以发现用户的新兴趣或者重新评估兴趣的现有级别的量化。因此,能够从可能否则已经未被发现的数字内容中发现新的相关兴趣。此外,随着关于用户或用户兴趣变化的更多信息可用,随时间推移可以更新用户兴趣。因此,知识库允许对用户已经与其交互的数字内容进行深入理解。而且,呈现给用户的附加数字内容可以利用知识库按用户兴趣进行定制。
图1是适合用于本公开的实现的示例性计算环境的框图。特别地,示例性计算环境被示出并且一般表示为计算设备100。计算设备100仅是适合的计算环境的一个示例,并且不旨在暗示对本发明的使用或功能的范围的任何限制。计算设备100不应解释为具有与图示的任何一个组件或组件组合相关的任何依赖或要求。
本公开的实现可以在计算机代码或机器可用指令的一般上下文进行描述,所述计算机代码或机器可用指令包括诸如程序组件的计算机可执行指令,其由诸如个人数字助理或其它手持式设备的计算机或其它机器执行。一般地,包括例程、程序、对象、组件、数据结构等在内的程序组件是指执行特定任务或实现特定抽象数据类型的代码。本公开的实现可以通过各种系统配置来实现,包括手持式设备、消费电子设备、通用计算机、专用计算设备等。本公开的实现还可以实施于分布式计算环境,其中任务通过经通信网链接的远程处理设备来执行。
继续参考图1,计算设备100包括与以下设备直接或间接耦合的总线102:存储器104、一个或多个处理器106、一个或多个呈现组件108、输入/输出(I/O)端口110、I/O组件112和电源114。总线102表示一个或多个总线是什么(诸如地址总线、数据总线或其组合)。虽然为了清晰起见,用线显示出图1的设备,但是实际上,勾勒各个组件不是如此清楚,并且比喻地说,线将更精确地为灰色或模糊的。例如,可以考虑诸如显示设备的呈现组件作为I/O组件112中的一个。而且,诸如一个或多个处理器106的处理器具有存储器。本公开认识到这是本领域的本质,并且再次重申图1仅是能够与本公开的一个或多个实现相结合使用的示例性计算环境的示例说明。不对如“工作站”、“服务器”、“膝上型设备”、“手持式设备”等类别之间做出区分,因为这些都在图1的范围内构思并且是指“计算机”或“计算设备”。
计算设备100通常包括各种计算机可读介质。计算机可读介质可以是能够由计算设备100访问的任何可用介质,并且包括易失性和非易失性的介质、可移除和非移除的介质。通过示例而不是限制的方式,计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以任何用于存储诸如计算机可读指令、数据结构、程序模块或其它数据的信息的方法或技术实现的易失性和非易失性的、可移除和非可移除的介质。
计算机存储介质包括RAM、ROM、EEPROM、闪速存储器或其它存储器技术、CD-ROM、数字多功能盘(DVD)或其它光盘存储、磁盒、磁带、磁盘存储或其它磁存储设备。计算机存储介质不包括传播的数据信号。
通信介质典型地具体实施为计算机可读指令、数据结构、程序模块或诸如载波或其它传输机制的调制数据信号中的其它数据并且包括任何信息输送介质。术语“调制数据信号”可以是指使其一个或多个特性以将信息编码在信号中的方式来设定或改变的信号。通过示例而不是限制的方式,通信介质包括有线网或直接接线连接的有线介质以及诸如声波、RF、红外的无线介质和其它无线介质。上述任意的组合也应当包括在计算机可读介质的范围内。
存储器104包括易失性和/或非易失性存储器形式的计算机存储介质。存储器104可以是可移除的、非可移除的或者其组合。示例性存储器包括固态存储器、硬盘、光盘驱动器等。计算设备100包括一个或多个处理器106,其从诸如总线102、存储器104或I/O组件112的各种实体读取数据。一个或多个呈现组件108向人或其它设备呈现数据指示。示例性一个或多个呈现组件108包括显示设备、扬声器、打印组件、振动组件等。I/O端口110允许计算设备110与包括I/O组件112的其它设备逻辑耦合,所述其它设备中的一些可内置于计算设备100内。示例性的I/O组件112包括麦克风、操纵杆、游戏板、卫星盘、扫描仪、打印机、无线设备等。
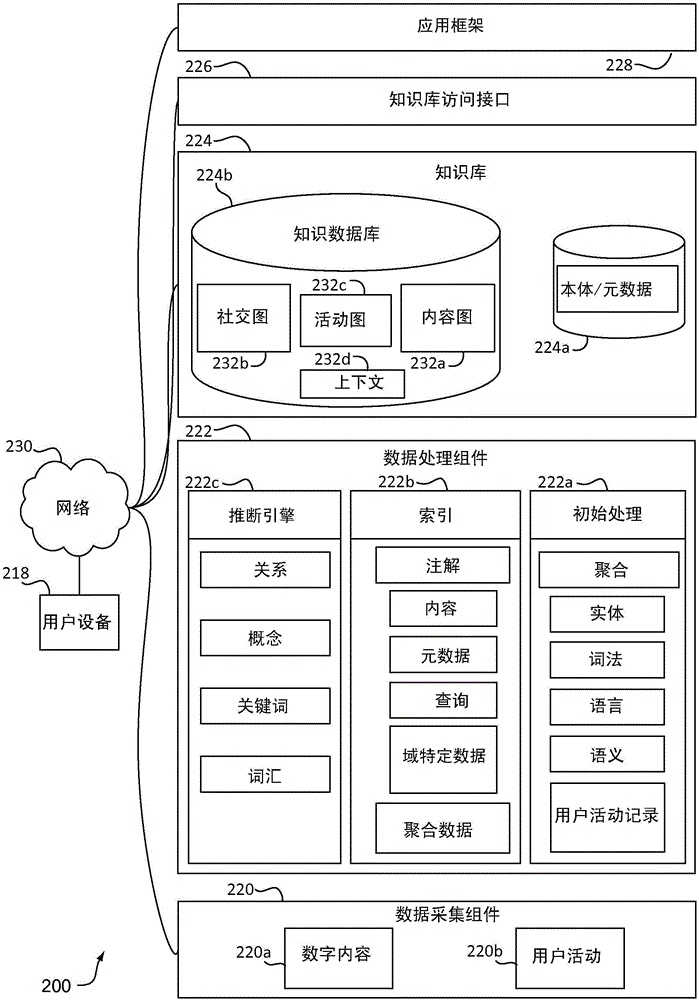
现在参考图2,提供了根据本公开的实现的示例性系统的描绘。特别地,图2示出了根据本公开的实现的系统200,其适合确定知识库所促进的用户兴趣。系统200包括用户设备218、数据采集组件220、数据处理组件222、知识库224、知识库访问接口226以及应用框架228,全部都能够彼此通信,例如经由网络230通信。
网络230可以是有线的、无线的或两者。网络230可以包括多个网络、或网络的联网,但是在图2中以简化的形式示出从而不混淆本公开的其它方面。通过示例的方式,网络230可以包括一个或多个广域网(WAN)、一个或多个局域网(LAN)、一个或多个公共网,诸如因特网,和/或一个或多个私有网。在网络230包括无线通信网的情况下,诸如基站、通信塔、或者甚至接入点(以及其它组件)的组件可以提供无线连接。虽然为清晰起见示出了单个组件,但是网络230可以实现任意数量的设备之间的通信,这些设备可以包括用户设备218。网络环境常见于办公室、企业广域计算机网、内联网、以及因特网。因此,网络230不进行重点说明。
在各个实现中,用户设备218是任何能够访问诸如万维网的因特网的计算设备,例如图1的计算设备100。因此,用户设备218可能呈现多种形式,诸如个人计算机(PC)、膝上型计算机、移动电话、平板式计算机、可穿戴计算机、个人数字助理(PDA)、服务器、CD播放器、MP3播放器、全球定位系统(GPS)设备、视频播放器、手持式通信设备、工作站、这些所述设备的任意组合、或者任何其它能够实现网络访问能力的设备。在一些实现中,用户设备218是使用无线远程通信网来通过网络230通信的移动设备。
数据采集组件220、数据处理组件222、知识库224、知识库访问接口226和应用架构228(本文还称为“组件220、222、224、226、和228”)可以与一个或多个计算设备(例如,服务器或服务器群)相关联地存在。根据图1的计算设备100可以实现一个或多个计算设备中的任一个或全部。虽然组件220、222、224、226、和228图示为不同的组件,但是组件220、222、224、226、和228中的一个或多个实际上可以组合或者本身可由多个组件构成。系统200仅是一个示例性配置并且不旨在限于此。
数据采集组件220被配置为获得用于系统200的数据。该数据可以包括非结构化数据、结构化数据和半结构化数据的任意组合。非结构化数据可以包括处理一系列文本行的文档。包括在非结构化数据类别中的文档可以具有极少元数据或者没有元数据。另一方面,结构化数据可以包括其中信息被结构化并且被引用的传统数据库。半结构化数据可以包括诸如研究论文或安全与交换委员会归档的文档,其中文档的部分包括文本行,而文档的部分包括用于图示的表格和图形。在半结构化数据的情况下,可以将文档的结构化组件分析为结构化数据,并且可以将文档的非结构化组件分析为非结构化数据。
数据采集组件220能够以多种方式来获得数据,包括通过使用数字内容馈送220a和用户活动馈送220b,如图2所示。数据内容馈送220a为系统200提供对数字内容的访问权。例如,索引子组件222b能够使用数字内容馈送220a来将数字内容处理成一个或多个索引,诸如下文详细说明的图5的索引574。一个或多个索引也可以包括在知识库224中。数字内容能够呈现各种形式,并且可以并入一个或多个文档或文件中,但是无需进行如此结构化。数字内容的示例包括网页、社交网络上的贴文、电子邮件、移动文本、广告、文字处理文档、音乐文件、视频文件、音频书籍、电子表格、电子书、新闻文章、博客贴文、游戏、应用,诸如此类。
数字内容馈送220a能够使得数字内容源自各种数据库。在一些实现中,数据库为数字内容馈送220a提供了对能够在因特网和/或内联网上访问的任何数字内容的访问权。在一个实现中,数字内容包括web文档,通过从web文档的爬网(crawling)中请求(pull)数据而将web文档源送到数字内容馈送220a。数字内容可以被推送到系统200。数据推送可源起于诸如结构化数据源的一个或多个源。在一些实现中,数字内容周期性地提供给系统200。例如,数字内容能够由提供供销售的数字内容的公司操作的诸如数字媒体库的系统来提供。
此外,数字内容馈送220a的数字内容所源自的数据库中的一个可以是用户设备218的本地设备,诸如硬盘。作为另一示例,另一数据库可以是例如通过用户识别符和/或用户账户与用户设备218的用户相关联的基于云的存储。然而,可设想的是,用户能够准许或拒绝对任何数据库中的数字内容的访问,对任何数据库中的数字内容的访问会有破坏用户的隐私和匿名性的风险。
用户活动馈送220b为系统200提供对用户活动数据的访问权。用户活动数据可以包括用户历史或者可以是实时地被提供为流的用户活动。用户活动馈送220b可以通过数据处理组件222来处理和/或分析从而将用户活动数据提供给系统200。例如,用户活动馈送220b可以被初始处理子组件222a跟踪、记录和聚合从而生成用户历史数据。
用户活动数据可以描述用户与数字内容之间的交互,数字内容诸如为数字内容馈送220a所能访问的任意数字内容。用户活动馈送220b的示例包括用户输入、用户已经查看数字内容的次数、点击、点击流、打开数字内容、访问数字内容、查看数字内容、下载数字内容、购买数字内容、注解数字内容、搜索查询和/或在将数字内容与和用户的交互相关联的计算环境中的其它用户行为的任意组合。在处理用户活动数据时严格地强制施行用户隐私和匿名。
用户活动馈送220b的具体示例包括将搜索查询输入到搜索引擎中。例如,搜索引擎能够响应于搜索查询而返回文档,其中文档能够对应于用户活动数据的数字内容。用户活动馈送220b的另一示例包括将web文档在web浏览器中标记为喜欢的或者书签,其中web文档可以对应于用户活动数据的数字内容。在一些实现中,用户活动馈送220b包括来自用户的反馈。例如,反馈可以确认知识库224的实体是用户感兴趣的。作为一个示例,反馈可以响应于查询,在由数据处理组件222生成之后呈现在用户设备218上以确认用户兴趣。用户活动馈送220b的另外的示例可以包括由用户在用户设备218上输入的任何其它信息。
使用数据采集组件220从一个或多个源接收到的数据,诸如上文所列的那些,由数据处理组件222分析以提取相关信息。也即,数据处理组件222被配置为分析数据并且从其中提取信息。在各个实现中,一旦数据由数据采集组件220接收,则数据可由数据处理组件222的一个或多个数据处理子组件来处理。图2所示的数据处理组件222包括用于处理数据的初始处理子组件222a、索引子组件222b(例如,维度索引子组件)以及推断引擎222c。
在各个实现中,初始处理子组件222a被配置为分析来自数据采集组件220的数据并且利用一个或多个数据处理方法从数据提取信息。在这方面,初始处理子组件222a可用于分析该数据并且从非结构化数据、结构化数据和半结构化数据中的任一者提取信息。
在一些实现中,通过初始处理子组件222a对数据的初始处理包括数据的词法分析、语言分析、语义分析和实体提取分析中的一项或多项。在初始分析时或者初始分析之后,可在接收到的数据的各方面之间做出推断。因此,来自表面上不相干的源的数据可以整合,并且可通过从数据中提取诸如含义和语义的属性来推断新关系。利用所处理的文档或数据以及已经存储在知识库224中的数据,通过实体关系提取,来创建推断。在一些实现中,数据来自数字内容馈送220a和/或用户活动馈送220b,并且用户活动数据是基于推断而生成的。
在各个实现中,随着数据装载到系统200中,可以形成推断。该推断可以在新信息与已经存储在系统200中的信息之间进行辨别,例如与知识库224相关联(如下文更全面描述的)。此外,当新的条目已经输入到系统200中时,尤其当新的条目添加到系统200的知识库224时,可以分析存储在系统200中的数据以便进行推断。因此,系统200可以被视为学习系统,其采用一个或多个机器学习算法。一旦已经从数据给出推断,则那些推断可以聚合成数据库,诸如知识库224的知识数据库224b。
索引子组件222b被配置为创建一个或多个索引,诸如多维索引或表格。一个或多个索引能够引用知识库224的组件,诸如知识库224内的各实体中的任一个。一个或多个索引还可以任选地引用数字内容,诸如从数字内容馈送220a提供的数字内容。在一些实现中,索引子组件222b也被配置为基于关系架构和本体来抽象数据并且统一数据而使其被暴露为知识图。本体可以对应于知识库224的本体/元数据组件224a,如图2所示。因此,索引子组件222b可以是指存储在知识库224中的本体。
索引子组件222b因此实现数据的映射和本体。例如,数字内容能够映射到本体的实体。另外,索引子组件222b使得映射诸如元数据、内容、注解、查询、域特定数据和聚合数据的子区域。利用索引子组件222b映射的知识数据库224b的实体包括实例实体和概念实体。值得注意的是,本公开不限于特定的本体。
推断引擎222c被配置为通过分析可能存在于添加到知识库224的数据之间的推断以及已经存储在系统200的知识库224中的推断来做出第二程度推断。因此,推断引擎222c的一个方面可以是分析知识库224以搜索当数据添加到知识库224中时可能做出的新推断。而且,推断引擎222c可以响应于利用知识库访问接口226接收到对知识库224做出的信息请求而搜索新推断。
示例性知识库224包括本体/元数据组件224a和知识数据库224b。虽然图示为单个数据库,但是知识数据库224b实际上可以是一个或多个数据库的集合,其中一个或多个数据库可以与服务器(未示出)、网络(未示出)、其它系统组件(例如,用户设备218)或其它计算设备(未示出)相关联地存储。本体/元数据组件224a和知识数据库224b的内容能够以包括在线或离线的各种方式存储并且能够位于例如分布式文件系统或云中。因此,值得注意的是内容无需存储在数据库中。
示例性知识数据库224b包括至少一个图,诸如内容图232a、社交图232b以及用户活动图232c,以及上下文数据232d,因为其与知识数据库224b中的全部或一些图相关。在一些实现中,内容图232a、社交图232b和/或用户活动图232c被并入到单个复合图中。在系统200中使用的图可以基于灵活的、可扩展的数据存储架构(例如,星形或雪花形架构)来构造。星形或雪花形架构能够用来管理知识数据库224内的实体之间的连接或关系。此外,在系统200中使用的图可以使用能够基于需要定制的其它数据存储架构来构造。
知识库224的本体/元数据组件224a可以充当基于本体和元数据的索引,其中可以从知识数据库224b的至少一个图(诸如,内容图232a、社交图232b和用户活动图232c)中提取实体。本体/元数据组件224a是例如通过索引子组件222b来使能的,并且例如通过推断引擎222c来修正。
本体/元数据组件224a能够用于利用共同引用架构从知识数据库224b的每个图中引用数据。共同引用架构可以为上述星形架构的形式。通过使用星形架构,一组数据可以存储在数据表中。从该初始数据表,通过雪花状进入其它表格,可以引用额外的数据。共同引用架构的使用允许一种实体有效地引用针对知识数据库224b采集并且存储在不同图中的数据的不相干的方面的手段。
包括在知识库224中的实体可以例如是概念实体,其能够代表可以是诸如web文档的数字内容的主题的概念、多组实体、实体的类型、实体的种类和/或实体的集合。包括在知识库224内的实体还可以是例如实例实体,其能够代表一个或多个概念实体的个体,诸如人、地方、事件或事物。实例实体可以是通过本体/元数据组件224a所具体实施的本体的“底层(ground level)”实体。实例实体的示例包括游戏中的特定人物(例如,“Romeo”)、特定的数学定理(例如,“Pythagorean Theorem”)或特定的地理位置(例如,“Alexandria”)。对应的概念实体的示例则可以包括“Characters of Shakespeare”、“Mathematical Theorems”和“Cities in Virginia”。
在一些实现中,知识库224中的每个实体包括至少一个属性。属性包括与实体相关联的数据,诸如特性或事实。例如,与概念实体相关联的属性可以包括由概念实体表示的概念的共同定义、已经使用搜索引擎搜索该概念的人数以及已经在该概念上写作的作者的姓名。与表示游戏中的人物的实例实体相关联的示例性属性包括特定人物的兴趣爱好、人物的地理原籍、游戏的作者以及人物的普便认可的品质。与代表数学定理的实例实体相关联的示例性属性包括发现定理的人的姓名、发现该数学定理的日期以及与数学定理的发展和/或接受有关的历史事实。与代表地理位置的实例实体相关联的示例性属性包括地理位置的历史、在地理位置通常所讲的语言以及地理位置的经度和纬度参考点。
在各实现中,知识数据库224b的社交图232b包括与关于用户简档、与其它用户的用户关系和用户偏好的数据相关联的实体。社交图232b还可以包括与社交网络的参与者相关联的用户简档信息。例如,社交图232b可以包括在区域内的全部“朋友”列表,或者其可以包括与哪些用户是用户朋友的朋友相关的信息(“朋友的朋友”数据)。与社交网站上的用户相关联的数据可以包括用户人口统计信息、用户心理记录信息和用户行为数据。用户行为数据的示例包括社交网上的贴文的追随和喜爱。
用户活动图232c可以由与用户活动(例如,注册用户的活动)相关联的信息来构造。在一些实现中,通过使用安全措施,诸如口令或者认证用户身份的另一形式,例如通过用户设备(例如,用户设备218)的起源地址,用户可以被核验为注册用户。仅为示例的方式,用户活动可以包括用户活动馈送220b所指示的各种用户活动中的任一个。
知识数据库224b的内容图232a可以包括实体的一个或多个属性,所述属性包括关键词、元数据、含义、关联、性质、内容、查询、查询结果、注解和表义数据实体。内容图232a中的实体可以包括关于数字内容的信息,以及数字内容本身。数据采集组件220和数据处理组件222能够分析该信息并且将其存储在系统200中,例如,与知识库224相关联。
知识数据库224b可进一步包括具有被配置为管理元数据注解的本体/元数据管理组件的注解组件(未示出)。知识数据库224b还可以包括被配置为将表义数据存储在关系表或图形表中的表义数据组件(未示出)。表义数据可通过索引子组件222b和/或其它关系数据库管理器(未示出)来管理。
知识数据库224b的上下文数据232d可以包括适合将知识数据库224b的内容(包括用户活动在内)置于上下文理解的各种类型的数据。示例包括时间数据、地点数据、用户设备数据和/或能够用于上下文的其它数据。时间数据可以包括与包括在图中的数据的时间本质(也即,时间的或者与时间相关的)相关的信息或者使用数字内容馈送220a和/或用户活动馈送220b获得的其它数据。而且,时间索引可以包括上下文数据232d的时间元素的聚合。例如,时间元素可以跟踪在,诸如过去30天的一段时间内的用户活动,或者可以指示用户与数字内容交互的具体时间。上下文数据232d可由推断引擎222c使用来做出有关在一天、一周或一年的不同时间段内的用户兴趣的推断。
位置数据可以包括与用户和/或用户设备218的位置相关的信息。例如,位置数据可以包括地理信息并且可由集成到用户设备218中的GPS来提供。在一些实现中,地点数据从用户与其交互的数字内容中提取。例如,位置数据可以从数字内容的文本中提取。数字内容可包括嵌入有地理数据的数字照片。作为另一示例,位置数据可通过分析数字内容来确定。例如,数字照片的位置可根据图像分析来确定或者对于数字书籍可通过基于文本的分析来确定。
用户设备数据可以包括用户设备218的设备信息。例如,用户设备数据可以指示用户设备218的各种状态或能力中的任一种。几个示例包括用户设备218的型号、用户设备218的可用或已用存储空间、用户设备218的可用或已用随机存取存储器(RAM)、运行于用户设备218上的操作系统的类型的版本、与用户设备218所能访问的数字内容的数量、量和或类型相关的信息、指示用户设备218所能访问的任何数字照相机的存在和/或类型的信息、包括可用分辨率和显示量的显示信息以及许多其它信息。
系统200的知识库访问接口226允许一个或多个应用访问知识库224的组件。一个或多个应用可以被托管在应用架构228上从而通过知识库访问接口226与知识库224交互。应用架构228可通过提交由数据处理组件222所处理的信息请求而允许一个或多个应用访问和查询知识库224。另外,API可用于允许开发者编写使用知识库224的应用。一个或多个应用中的一些应用可以至少部分地运行于用户设备218上。其它应用可运行于用户设备218之外。
根据本公开的实现,系统200允许处理用户活动,从而确定用户与哪些数字内容交互。用户与其交互的数字内容随后可进行评估从而确定数字内容的主题。主题可从知识库224的实体中选出并且映射到数字内容。通过使用知识库来分析主题,可以对用户的兴趣做出推断。例如,可以分析主题之间的关系以发现用户的新兴趣或者重新评估兴趣的现有级别的量化。
现在参考图3,提供了根据本公开的实现的示例性方法的流程图。特别地,图3描绘了根据本公开的实现的方法300的流程图。仅为了示例说明的目的,下文参考图5和图6来描述方法300。图5示出了根据本公开的实现的示例性系统。特别地,图5示出了系统500,其对应于图2的系统200。因此,系统500包括用户设备518、数据采集组件520、数据处理组件522、知识库524、应用架构528以及网络530,它们分别对应于系统200中的用户设备218、数据采集组件220、数据处理组件222、知识库224、应用架构228和网络230。值得注意的是,图5不旨在捕获与数据的相对位置相关的具体时间,而是旨在示出了与系统500可用的数据的处置和数据的类型相关的方面。
方法300包括接收描述用户与数字内容之间的交互的用户活动数据(图3中的340)。例如,如图5所指示的,用户活动数据500被接收并且描述了用户562与数字内容564A之间的交互。
通过数据处理组件522可以从数据采集组件520接收用户活动数据560。用户活动数据560可以对应于如上文结合图2所描述的用户活动数据。因此,用户活动数据560已经由数据处理组件522通过处理和/或分析图2的用户活动馈送220b来生成。
作为一个示例,用户562可以将用户输入562a经由用户设备518提供给被托管在应用架构528上的应用528a。应用528a可以是web浏览器、操作系统、媒体库、文字处理器、移动操作系统、操作系统扩展、游戏、电子书阅读器或能够接收用户输入562a以处理用户562与数字内容564a之间的用户交互的其它应用。那些交互中的任意交互可并入用户活动数据560中。
在一些实现中,利用知识库524从用户活动馈送220b生成用户活动数据560。例如,数据处理组件522能够使用用户活动图232c、任选地结合上下文数据232d来处理和分析用户活动馈送220b。然而,在其它实现中,数据处理组件522能够不使用知识库224而生成用户活动数据560。换言之,本公开不限于基于图的方法来生成用户活动数据560。
用户562与数字内容564A之间的交互可以描述于用户活动数据560中,例如,利用来自用户活动图232c的内容和/或上下文数据232d,例如,包括在其中的实例和/或概念实体的任意组合,作为示例,与用户识别符(ID)和/或数字内容ID相关联。
方法300还包括:生成对用户与作为数字内容的主题的实体之间的兴趣级别进行量化的第一兴趣级别数据,其中实体属于包括在知识库内的多个实体,所述知识库包括指示多个实体之间的关系的本体(图3中的342)。例如,如图5所指示的,兴趣级别数据566a被生成并且对用户562与作为数字内容564a的主题的实体568a之间的兴趣级别进行量化。实体568a是包括在知识库524内的实体568中的,其中知识库524包括指示实体568之间的关系572的本体570。
可以在用户活动数据560中识别出数字内容564a,例如,通过用户活动数据50中的数字内容ID。数据处理组件222随后可以确定实体568a以及可能其它实体是数字内容564a的主题。数据处理组件222可以接着针对实体568a以及被确定为数字内容564a的主题的任何其它实体生成兴趣级别数据。
在一些实现中,通过分析来自图2的数字内容馈送220a的数字内容564a以及根据传输中的数字内容564a生成实体,实体568a和/或其它实体被确定为数字内容564a的主题。实体568a和/或其它实体也可以预先生成并且通过映射数据识别出实体与数字内容564a匹配而被确定为数字内容564a的主题。例如,实体568a可以通过映射数据576与数字内容564a匹配。映射数据576可以是多个映射数据中的,其可以在索引574中。多个映射数据可以将知识库524内所包括的任意或全部实体568匹配于对应的数字内容(其包括数字内容564a)。
初始处理子组件222a能够使用推断来通过基于数字内容564a和已经存储在知识库224中的数据而进行的实体关系提取而生成数字内容的主题。在示例性实现中,基于分析数字内容564a来生成推断。例如,可以采用语义理解算法,其比较数字内容564a和与知识库524内的实体568相关联的已知内容的相似度。作为一个示例,可以比较数字内容564a中所包括的词语和包括在与实体568相关联的已知内容中的词语的相似度。与实体568相关联的已知内容可能已经由系统200从在将实体568并入知识库524中所使用的数字内容中提取,或者已经通过其它方式提供。
可以生成相似度得分,其量化了与任意实体568相关联的已知内容与使用语义理解算法的数字内容564a之间的相似度。通过该方法,实体568中的一个,包括实体568a,能够基于例如超过预定阈值的相似度得分而被确定为数字内容564a的主题。作为另一示例,某些数量的实体568,包括实体568a,能够基于具有实体568的最高相似度得分而被确定为数字内容564a的主题(例如,前十个实体可被确定为实体568a的主题)。将意识到,在确定数字内容564a的主题中可以采用许多其它的方法。如上所指示的,在各实现中,在接收到用户活动数据560之前生成主题(例如通过将与预先生成的实体相关联的映射数据存储在索引574中),并且在其它实现中,在接收到用户活动数据560之后和/或响应于接收到用户活动数据560而生成主题。
数据处理组件222可以针对实体568a以及被确定为数字内容564a的主题的任何其它实体生成兴趣级别数据,例如通过存储指示用户562与实体之间的兴趣级别的数据。兴趣级别数据可以存储在用户设备518上或者在外部,例如在云中。兴趣级别数据的示例是相对于图5中的兴趣级别数据566a来示出的。
如图所示,兴趣级别数据566a包括实体ID 580b,其能够由系统500使用来识别知识库524中的实体568a。兴趣级别数据566a还包括用户ID 580a。用户ID 580a能够对应于用户52,并且可由系统500使用来从多个其它用户账户中识别用户562的用户账户。用户ID 580a能够链接到兴趣级别数据566a中的实体ID 580b,从而指示用户562与实体568a之间的兴趣。因此,在一些实现方式中,兴趣级别数据可被视为用户兴趣简档,其跟踪各个实体与用户之间的兴趣级别数据。
同样如图5所示,兴趣级别数据可以包括实体串,诸如实体串580e。实体串580e包括对应于由知识库524中的实体568a所表示的实体的字符串。例如,在实体568a代表了莎士比亚的Romeo and Juliet中的人物罗密欧的情况下,字符串可以是“Romeo”。实体串580e反而可以根据需要从知识库524中得到。
同样如图5所示,兴趣级别数据可以包括置信得分,诸如置信得分580d。置信得分580d可以是代表用户562与实体568a之间的兴趣级别的值。在一些实现方式中,在生成兴趣级别数据时,上文关于实体568a所描述的相似度得分能够存储为置信得分580d。然而,置信得分580d可以通过其它方式由数据处理组件522计算或者能够被赋予默认值。
兴趣级别数据还可以包括频率数据,诸如频率数据580c。频率数据580c可以指示实体568a已经是用户562与其交互的例如在各种用户活动数据中所描述的各种数字内容的主题的频率或次数。在初始地生成兴趣级别数据566a时,实体568a已经作为在数字内容中的主题出现的次数能够是一次。然而,频率数据580c可以随着实体568a出现在另外的数字内容中而随时间更新。例如,在某点,用户562可以与数字内容564a或564c交互,其中实体568a已经被确定为其主题。因此,在用户已经与数字内容564b或564c交互之后,数据处理组件522能够更新频率数据580c。通过该方法,用户562与作为数字内容564a的主题的实体568a之间的兴趣级别能够基于实体568a是数字内容的主题的频率来更新。随着实体568a的频率增加,因此用户562与实体568a之间的兴趣级别也增加。
图5还示出了兴趣级别数据可以包括新近性数据诸如新近性数据580f。新近性数据580f可以指示在多近期的时间或者在什么时间实体568a已经作为用户562与其交互的例如在用户活动数据中所描述的数字内容的主题出现。数字内容包括数字内容564a。新近性数据580f可以仅与实体568a已经作为用户562与其交互的数字内容中的主题出现的最近期时间相关。在其它实现中,新近性数据580f可以包括每次实体568a作为用户562与其交互的数字内容中的主题出现的条目。将意识到,在该实现方式中,频率数据580c能够并入新近性数据580f中。例如,新近性数据580f中的条目的数量可以对应于频率数据580c。每个条目可以为例如时间戳。通过该方法,用户562与作为数字内容564a的主题的实体568a之间的兴趣级别能够基于实体568a作为数字内容的主题的近期性来更新。
在各实现方式中,频率数据580c和/或新近性数据580f能够用来初始地计算置信得分580d和/或随时间而更新置信得分580d。而且,在一些实现方式中,置信得分580d根据需要由系统200来计算。例如,通过随时间而更新频率数据580c和/或新近性数据580f,置信得分580d能够被计算以对用户562与实体568a之间的同期兴趣级别进行量化。
而且,能够使用频率数据和/或新近性数据来修整来自兴趣级别数据的实体。例如,如果新近性数据580f指示实体568a过于陈旧,则可从系统500中去除兴趣级别数据566a。作为一个示例,可使用新近性数据580f来随时间降低置信得分580d。这可通过将新近性数据580f与系统时钟比较来确定自实体568a已经是用户562与其交互的数字内容的主题起已经经过了多少时间以及随着该时间增加而成比例地减少置信得分580d来实现。当置信得分580d降至预定阈值以下时,兴趣级别数据566a可以从系统500中剪除。前述内容仅是频率数据和/或新近性数据如何能够在系统500中使用的一个具体示例,其它许多方法是可能的。
方法300另外地包括:基于候选实体与知识库内的实体具有一种关系来识别(图3中的344)所述候选实体。例如,如图5所指示,基于实体568b与知识库524内的实体568a具有一种关系572来识别实体568b。
下面参考图6来描述前述内容的示例。图6描绘了根据本公开的实现的知识库的示例性内容。特别地,知识库可以对应于图5中的知识库524。如图6所示,知识库600包括多个实体,多个实体能够对应于图5中的实体568。为了公开清楚起见,在图6中没有示出知识库600中的多个实体的全部。注意的是,一些没有示出的实体可能与所示的实体相关。
知识库600包括实例实体,诸如实例实体682a、682b、682c、682d、682e和682f(本文也统称为“实例实体682”)。知识库600还包括概念实体,诸如概念实体684a、684b、684c、和684d(本文也统称为“实例实体684”)。知识库600包括属性,这些属性可以与各个实体相关联,诸如属性686a,686b,686c,686d,686e,686f和686g(本文也统称为“实例实体686”)。属性686a,686b,686c,686d和686e是实例实体682a的,并且属性686f和686g是实例实体682b的。知识库600还包括关系,该关系用来指示多个实体之间的关系。所示的关系包括关系688a,688b,688c,688d和688e(本文也统称为“实例实体688”)。
如上所述,能够基于实体568b与知识库524内的实体568a具有一种关系572来识别实体568b。每个关系572均可以包括一个或多个关联,例如一些关系572可以包括关联688。在一个示例中,实体568a和568b可以各自是本体570的实例实体。例如,实体568a可以是图6中的实例实体682a,并且实体568b可以是图6中的实例实体682b。在图6所示的示例中,实例实体682a代表了“James Camero”并且实例实体682b代表了“Kathryn Bigelow”。在该点,实例实体682a可以不明确地与系统500中的用户562相关联。例如,系统500可能不包括将用户562与实例实体682b链接的兴趣级别数据。
根据一些实现方式,系统500可以基于实例实体682ab与知识库600内的实例实体682a具有一种或多种关系来识别实例实体682b。在所示的示例中,关联688a和688b指示实例实体682a与实例实体682b之间的关系。该关系包括实例实体682a和682b均是概念实体684a的实例实体。换言之,实例实体682b与实例实体682a共享至少一个共同概念实体。在当前的示例中,概念实体684a代表了结婚。因此,关系668a和668b指示“James Cameron”和“Kathryn Bigelow”已经结婚。作为另一示例,实例实体568a可以代表Seattle Mariners,并且实例实体568b可以代表Houston Astros。知识库524中的共享概念实体则可能是棒球。
一般的,实体568a和568b可以是概念实体或实例实体,并且两者可以是相同的实体类型。例如,实体568a可以是图6中的概念实体684a(例如,结婚),或者实体568b可以是上述示例中的概念实体684a(例如,结婚)。虽然本示例仅引用实体568a,其由于具有兴趣级别数据566a而是系统600的已知实体,但是其它已知实体能够与实体568a相结合使用从而识别实体568b和/或知识库600内的其它相关实体。那些其它已知的实体可以按照与实体568a相同或相似的方式从数字内容中得到。因此,可以基于与除了实体568a之外的其它已知实体中的一些或全部具有一种或多种关系来识别实体568b。在图6所示的示例中,那些其它已知实体的示例可以是实例实体682d(例如,“1989”)和682c(“1991”),其定义了“James Cameron”和“Kathryn Bigelow”结婚的时间范围(即,1989-1991)。
进一步值得注意的是,能够识别多个候选实体。可以使用从多个候选中选择的各种方法。例如,能够利用要求候选实体与多个已知实体相关来缩窄被识别出的候选实体的数量。为了说明上文,可以基于与可以是已知实体的实例实体682a(例如,“James Cameron”)、682b(例如,“Kathryn Bigelow”)、682c(例如,“1991”)和682d(例如,“1989”)中的每一个具有关系来识别出概念实体684a(例如,结婚)。相反,基于仅与实例实体682a(例如,“James Cameron”)相关而不识别出实例实体682f(例如,“Ghosts of the Abyss”)。
因此,如上所述,根据各个实现方式,通过分析知识库524,系统500可以识别出用户562感兴趣、但是不一定作为用户562与其交互的数字内容的主题出现的新实体。因此,系统500能够生成并且维护更精确且具体地捕获用户562的兴趣的鲁棒的用户兴趣简档。
方法300还包括基于候选实体与知识库内的实体的一种关系的分析来生成对用户与候选实体之间的兴趣级别进行量化的第二兴趣级别数据(图3中的346)。例如,如图5所指示,基于实体568b与知识库524内的实体568a的一种关系572的分析,兴趣级别数据566b被生成并且对用户562与实体568b之间的兴趣级别进行量化。
下文提供了示例,由此能够生成第二兴趣级别数据,并且能够分析知识库524内的实体之间的关系。然而,那些示例不旨在限制,并且仅示出了生成第二兴趣级别数据的可能的方法。另外,所给出的示例为了清晰而进行了简化,但是可以明显更复杂并且并入额外的变量。进一步注意的是,对于具有不同本体的知识库,可以采用不同的方法。
返回图6,其中上文识别出实例682b,通过分析实体568a与知识库524内的实体568b的关系,能够生成兴趣级别数据566b。在这样做时,系统500可以生成兴趣级别得分588,其对用户562与实例实体682b之间的兴趣级别进行量化。此外,系统500可以基于由兴趣级别数据566a所量化的用户562与实体568a之间的兴趣级别来生成兴趣级别数据566b。作为一个示例,兴趣级别得分588可以基于例如置信得分580d来计算。
兴趣级别得分588可以对应于置信得分580d,其按实例实体682b与682a之间的关系数量而递减。例如,因为在知识库600中仅关系688a和688b链接实例实体682b和682a,所以兴趣级别得分588可以仍指示相对强的兴趣。如果实例实体682b距离实例实体682a更远,则兴趣级别得分588可以指示相对应的较低的兴趣级别。
兴趣级别得分588还可以基于比较实例实体682b与实例实体682a之间的属性。例如,属性686a与686f之间的比较可以指示,那些属性相同或相似,其可使得兴趣级别得分588递增。
与实例实体682b相关的其它置信得分和/或其它实体的属性也可以考虑进兴趣级别得分588。例如,兴趣级别得分588可以以其它置信得分为因素并且聚合其它置信得分。作为一个示例,当对识别出的实体进行分析时,考虑概念实体686a。实例实体682a和682b可以已经为系统500所知并且具有关联的置信得分。那些置信得分可以考虑进兴趣级别得分588,以及考虑进概念实体684a与实例实体682a和682b之间的关系的数量(即,分离程度)。
如果兴趣级别得分588所指示的兴趣级别足够强,例如,如果兴趣级别得分588超过预定阈值,或者其它方式指示强的兴趣,则系统500可以生成兴趣级别数据566b。兴趣级别数据566b可以将兴趣级别得分588并入作为置信得分,类似于兴趣级别数据566a。在一些实现方式中,置信得分是根据兴趣级别得分588或者基于兴趣级别得分588来计算的。然而,系统500可以确定,兴趣级别得分588不足够强,从而不生成兴趣级别数据566b(例如,如果兴趣级别得分588不超过预定阈值)。
因此,系统500可以响应于对实例实体682b与实例实体682a和/或知识库524中的其它已知实体的关系的分析而有条件地生成兴趣级别数据566b。通过该方法,不是全部识别出的实体都为系统500已知。然而,系统500仍可以针对实例实体682b生成兴趣级别数据566b,其中兴趣级别得分588没有指示实体682b作为用户562的强烈兴趣。例如,系统500可以当前具有实体568的不足的兴趣级别数据从而确定实例实体682b与任何其它那些各种实体之间的强的关系。
通过分析共同出现数据,可以生成兴趣级别数据566b。共同出现数据描述了主题如何频繁地出现在来自文档语料库的单个文档内。共同出现分析可以通过确定候选实体和具有已知兴趣级别的实体如何频繁地是单个文档的主题来将兴趣级别赋予没有接收到用户交互的候选实体。两个实体一起出现在单个文档中越频繁,两个实体之间的关系越强。较强的关系会导致被赋予候选实体的更高级别的兴趣级别。共同出现分析的结果可以记录在知识库中,作为实体之间的关系强度的指示。
在一个方面,实体之间的关系强度可以是单向的。在其它工作中,A与B的关系可以不同于B与A的关系。单向关系强度可以反映人们如何在相关实体中形成兴趣。例如,对第一实体感兴趣的人可能以第一置信度对第二相关实体感兴趣,而对第二实体感兴趣的人可能以不同于第一置信度的第二置信度对第一实体感兴趣。例如,对Seattle Mariners(实体A)感兴趣的人可能以高的置信度对Major League Baseball(实体2)感兴趣。另一方面,对Major League Baseball感兴趣的人可能以较低的置信度对Seattle Mariners感兴趣,因为Mariners仅是棒球迷可能感兴趣的32个队中的1个。
在一个方面,实体A与实体B之间的关系强度可以基于实体A和B的总的共同出现率除以分析的文档的语料库内的A的总出现率。类似地,实体B与实体A之间的关系强度可以基于实体A和B的总共同出现率除以分析文档的语料库内的B的总出现率。
可利用机器学习机制来生成兴趣级别数据566b,机器学习机制评估实体并且确定指示对第一实体感兴趣的人有多大可能可能对第二实体感兴趣的置信得分。包括用户反馈在内的训练数据可用于训练机器学习机制来评估已知对第一实体感兴趣的用户可能对第二相关实体具有的兴趣级别。训练数据可以包括调节两个或更多个实体之间的关系强度的编辑指令或规则。例如,按规则,用户可被赋予对不多于两个棒球队的兴趣。棒球队可能在文档中具有大量的共同出现,但是用户不一定可能对多个队感兴趣。然而,训练数据可能指示,用户通常对不多于两个或三个不同的队感兴趣。给定该数据,当试图将兴趣级别赋予用户时,可能使得棒球队之间的关系强度打折扣,而当用户已经表达了对具体队感兴趣时,可能使得一个或多个队之间的关系强度打折扣。
如上文所指示,系统500的兴趣级别数据可以随时间而变化,例如,在用户562查看另外的数字内容并且在知识库524中生成新的推断时。因此,能够周期性地重新评估用户562与实例实体682b之间的兴趣级别。例如,基于实例实体682b与知识库524中的其它实体之间的关系的后续分析,可以更新兴趣级别数据566b的置信得分从而增加或减小值。通过该方式,系统500能够随时间推移而形成有关用户562的兴趣的深入理解,这会随着来自用户562的更多信息可用而适应。方法400部分地涉及本公开的一些实现方式,这些能够用来随时间而适应系统500的用户兴趣数据。
现在参考图4,图4描绘了根据本公开的实现方式的示例性方法的流程图。特别地,图4描绘了根据本公开的实现方式的方法400的流程图。下文结合图5和图6描述方法400,这仅为了示例说明。
方法400包括生成对用户与作为第一数字内容的主题的第一实体之间的第一兴趣级别进行量化的第一兴趣级别数据,其中第一实体是包括在知识库内的多个实体中的一个,知识库包括指示多个实体之间的关系的本体(图4中的448)。例如,如图5所指示,兴趣级别数据566a被生成并且对用户562与作为数字内容564a的主题的实体568a之间的兴趣级别进行量化。实体568a属于包括在知识库524内的实体568,其中知识库524包括指示实体568之间的关系572的本体570。
兴趣级别数据566a能够被生成并且对用户562与作为数字内容564a的主题的实体568a之间的兴趣级别进行量化,类似于上文结合方法300所描述的。因此,生成兴趣级别数据566a可以在接收描述用户562与数字内容564a之间的交互的用户活动数据560之前进行。
方法400另外包括生成对用户与作为第二数字内容的主题的第二实体之间的第二兴趣级别进行量化的第二兴趣级别数据,其中第二实体是知识库内包括的多个实体中的一个(图4中的450)。例如,如图5所指示,兴趣级别数据566b被生成并且对用户562与作为数字内容564b的主题的实体568b之间的兴趣级别进行量化。实体568b是知识库524内所包括的实体568中的。
兴趣级别数据566b能够被生成并且对用户562与作为数字内容564b的主题的实体568b之间的兴趣级别进行量化,类似于上文关于方法300和兴趣级别数据566a所描述的。因此,生成兴趣级别数据566b可以在接收描述用户562与数字内容564b之间的交互的用户活动数据(未示出)之前进行。
方法400还包括通过基于在知识库的一种关系中第二实体与第一实体紧密相关来增加用户与第一实体之间的兴趣的第一级别,从而更新第一兴趣级别数据(图4中的452)。例如,通过基于在知识库524的关系572的一种中实体568b与实体568a紧密相关来增加用户562与实体568a之间的兴趣级别,从而更新兴趣级别数据566a。
更新兴趣级别数据566a可以包括确定在知识库524的关系572的一种中实体568b与实体568a紧密相关,这可以包括对实体568a与568b之间的关系数量进行计数。在一些实现方式中,如果关系数量不超过预定阈值,则实体568b可视为与实体568a紧密相关。此外,实体568b与实体568a越紧密相关,用户562与实体568a之间的兴趣级别增加的量可以越大。更新兴趣级别数据566a还可以并入其它因素,诸如置信得分580d,和/或兴趣级别数据566b的置信得分。此外,关于系统500的其它已知实体(即,具有兴趣级别数据的实体),可以考虑类似的因素。
作为一个示例,更新兴趣级别数据566a可以包括针对实体568a生成兴趣级别得分588。然后,可以将兴趣级别数据566a的置信得分580d更新为兴趣级别得分588。兴趣级别得分588可以基于兴趣级别数据566a的置信得分580d。例如,可以根据置信得分580d来计算兴趣级别得分588。然而,兴趣级别得分588不一定基于兴趣级别数据566b的置信得分580d。
通过更新兴趣级别数据566a,方法400使得系统500能够将其对用户兴趣的理解同期化。虽然上面的示例描述了实体568a和568b均是数字内容(即,分别是数字内容564a和564b)的主题,但是在各个实现方式中,实体568a和568b中的任一个还可以是候选实体,具有根据方法300生成的兴趣级别数据。另外,可以基于其它因素诸如来自数字内容的更新频率和/或新近性数据来更新兴趣级别数据566a。虽然兴趣级别数据566a已经描述为被更新,但是兴趣级别数据566b还可以基于知识库524中实体568a与568b之间的关系572的一种的分析来进行更新。
使用根据本公开的实现方式的方法,系统500能够识别并且确定用户562可能感兴趣的、但是不一定出现作为用户562与其交互的数字内容的主题的新实体的兴趣级别。此外,系统500能够识别并且确定确实出现作为用户562与其交互的数字内容的主题的实体的兴趣级别。另外,方法500可以随时间更新对任意实体的兴趣级别。
兴趣级别是通过兴趣级别数据来量化的,其可用于识别并且呈现与用户562相关的数字内容。例如,在一些实现方式中,基于实体568a或568b是另外的数字内容的主题,在用户设备518上向用户562呈现另外的数字内容。另外的数字可以呈现给用户562,而不使用用户活动数据。例如,系统500能够使用类似上文关于数字内容564a所描述的手段来判定实体568a或568b是否是另外的数字内容的主题。通过该方式,系统500能够为用户562呈现用户562不一定与其交互,但是用户562可能感兴趣的另外的数字内容。
因此,例如,系统500可以获知,用户562是Seattle Mariners(例如,实体568a)的迷恋着并且为用户562呈现关于Seattle Mariners的网络文章。将意识到,可采用各种算法来确定应将哪些另外的内容呈现给用户562以及在何时呈现。例如,系统500可以基于确定诸如与用户562具有相似兴趣的用户的其它用户已经与另外的数字内容交互来将另外的内容呈现给用户562。作为另一示例,系统500可以基于另外的内容在多近期已经变得可用来将另外的内容呈现给用户562。基于网络文章的时间和/或流行度,用户562可被呈现关于Seattle Mariners赢得世界大赛的网络文章。
作为另一示例,系统500能够针对用户562生成利用其中的任何兴趣级别数据进行相关度排级的搜索结果。因此,搜索结果可针对特定用户定制。例如,用户可以将搜索查询“棒球票”提供给搜索引擎。系统500可以基于用户562对Seattle Mariners感兴趣而将关于Seattle Mariners的票的网络文档排级为高于关于Houston Astros的票的网络文档。然而,基于不同用户对Houston Astros感兴趣,来自不同用户的相同的搜索查询可以将关于Seattle Mariners的票的网络文档排级为低于关于Houston Astros的票的网络文档。
系统500还可以基于来自用户562的反馈数据来更新用户562与实体之间的兴趣级别。在上述的示例中,例如,用户562选择不与作为另外的数字内容呈现的网络文章交互。用户562可以关闭窗口或者以其它方式生成可构成负面反馈数据的用户输入。负面反馈数据能够用于将用户562与实体之间的兴趣级别递减。另一方面,正面反馈数据能够用于使得用户562与实体之间的兴趣级别递增。
在一些实现方式中,基于分析与实体相关联的兴趣级别数据,系统500能够为用户562呈现查询。用户562可以在用户设备518上提供用户输入以对查询进行响应,其中用户的回应构成了反馈数据。作为一个示例,数字助理可以为用户562呈现查询“你对Seattle Mariners感兴趣”,其中SeattleMariners是实体。在该情况下,正面反馈可以指示由于查询的直接性而有强的兴趣级别。因此,系统500可以存储实体是用户562的明确兴趣的指示。类似地,负面反馈可以使得系统500存储实体明确地不是用户562的兴趣的指示,或者可以引起对实体的存储的兴趣级别数据的修剪。
示例
在一个方面,提供了用于确定用户兴趣的计算机实现的方法。该方法包括:接收描述用户与数字内容之间的交互的用户活动数据;生成对所述用户与作为所述数字内容的主题的实体之间的兴趣的第一级别进行量化的第一兴趣级别数据,其中所述实体是包括在知识库内的多个实体中的一个,所述知识库包括指示所述多个实体之间的关系的本体;基于候选实体具有与所述知识库内的所述实体的所述关系中的一种而识别出所述候选实体;以及基于对所述候选实体与所述知识库内的所述实体的所述关系中的一种的分析而生成第二兴趣级别数据,所述第二兴趣级别数据对所述用户与所述候选实体之间的第二兴趣级别进行量化。
在另一方面,提供了用于确定用户兴趣的计算机实现的方法。该方法包括:生成对用户与作为第一数字内容的主题的第一实体之间的兴趣的第一级别进行量化的第一兴趣级别数据,其中所述第一实体是知识库内包括的多个实体中的一个,所述知识库包括指示所述多个实体之间的关系的本体;生成对所述用户与作为第二数字内容的主题的第二实体之间的兴趣的第二级别进行量化的第二兴趣级别数据,其中所述第二实体是包括在所述知识库内的所述多个实体中的一个;以及通过基于在所述知识库的一种所述关系中所述第二实体与所述第一实体紧密相关来增加所述用户与所述第一实体之间的所述兴趣的第一级别而更新所述第一兴趣级别数据。
在另一方面,提供了存储有计算机可用指令的一个或多个计算机存储介质,当通过计算设备执行时,所述计算机可用指令执行用于确定用户兴趣的方法。该方法包括:在描述用户与数字内容之间的交互的用户活动数据中识别出所述数字内容;通过映射数据识别出与所述数字内容匹配的实体,所述实体是所述数字内容的主题,其中所述实体属于包括在知识库内的多个实体,所述知识库包括指示所述多个实体之间的关系的本体;生成对所述用户与所述实体之间的兴趣的第一级别进行量化的第一兴趣级别数据;基于候选实体具有与所述知识库内的所述实体的所述关系中的一种而识别出所述候选实体;以及生成第二兴趣级别数据,其基于对所述候选实体与所述知识库内的所述实体的所述关系中的一种的分析而对所述用户与所述候选实体之间的兴趣的第二级别进行量化。
因此,根据本公开的实现方式,能够在知识库的促促进下确定、发现和更新用户兴趣。知识库能够允许对用户与其交互的数字内容进行深入理解。因此,从否则可能会未被发现的数字内容中发现新的相关兴趣。此外,随着关于用户的更多信息可用或者用户兴趣变化,而随时间更新用户兴趣。而且,呈现给用户的另外的数字内容能够针对用户兴趣来定制。
本发明的实施例已经被描述为示例而不是限制。将理解的是,一些特征和子组合具有实用性并且可以在不参照其它特征和子组合的情况下采用。这也由权利要求进行设想并且在权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!