流处理的制作方法
本说明书涉及流处理。
背景技术:
流处理是指用于实时地连续地处理数据对象如事件的无界序列的系统和技术,无界序列即不限于数据对象的预定数目或数据对象的到达速率,这样的序列被称为流(stream)。例如,对象的流可以表示由web站点接收的页面请求、来自传感器的遥测事件或由用户发布的微博消息。流处理系统能够执行各种任务,包括随着数据对象被找到而提供立即搜索结果并且随着它们被接收而连续地处理新数据对象。
技术实现要素:
本说明书描述了能够被单独地或相结合地用来在流处理的场境中实现用于快速数据分析的可伸缩框架的许多新颖技术。在流处理中,通过数种类型的期望变换来推送数据的流。这种范型能够导致快速数据处理,因为分裂的流能够由数个计算节点并行地变换,每个计算节点在数据流的一小部分上实现变换流水线。在流处理中,每个计算节点看见可能不代表整体的数据的一小部分。
一种技术是允许快速数据计算密集处理(例如,机器学习)的框架。这通过分解每个计算算法来实现:算法被分成(i)高度并行的部分、(ii)数据的聚合以及(iii)计算密集但数据轻的部分。数据的聚合是两阶段过程;它被分成(ii.1)计算节点内的聚合以及(ii.2)计算节点之间的聚合。
在该框架中,算法是以将被称为“本地建模器”(lm)和“中心建模器”(cm)的操作组件的一个或多个对(pair)的形式实现的。lm实现部分(i)和(ii.1),然而cm实现部分(ii.2)和(iii)。
这样得到的体系结构是混合装置,其中:
·lm被布置在流水线中并且实现流处理范型:数据被碎片化并且每个碎片通过流水线的数个相同的拷贝中的一个来传递。以这种方式,能够处理数据密集部分。
·lm通过分散-聚集与cm进行通信:lm通过在仅它们看见的数据上聚合来部分地计算聚合;它们然后将它们的数据通信到共享cm,该共享cm这时能够执行聚合的第二阶段并且因此在整个数据上计算聚合结果。
·cm使用聚合结果以及像它一样的其它结果作为计算的计算密集但数据轻的部分的输入。然后能够将与lm相关的聚合结果或任何其它计算结果通信回到lm。cm能够以系统开发者期望的任何方式与彼此进行通信,因为cm不是数据密集的。实际上,它们能够实现网格处理范型。
另一技术是能够基于此框架的在线机器学习算法的实时建模和评分的实施方式。基本上,聚合功能性被使用以使得在通过lm并行地流式传输的数据上学习各种所需统计量。统计量最终在cm中被计算。cm然后能够使用这些统计量为期望的机器学习模型而优化参数。模型参数然后被通信回到lm。这些进而能够通过使用所通信的模型来执行传入数据事件的评分,例如以用于预测。
机器学习算法是基于作为输入给予该算法的证据从模型族中确定特定模型的算法。模型族是算法固有的并且是参数族。输出模型通过其参数集来指定。机器学习算法可以具有附加输出,例如,算法在模型中的置信度。
基本底层构思是模型被以最佳地拟合可用数据的方式选择的。确切相同的机制能够被用来取得新证据并且对照现有模型来对其拟合进行比较。这被称为评分。
根据传入数据联机地构建模型的过程通常是计算密集的。为此,如上所述在体系结构上把创建模型的算法分裂成如上所述并且在本说明书中被称为中心建模器和本地建模器的数个组件是有利的。
在该框架的一些实施方式中,机器学习模型被离线开发并且直接或者通过一个或多个cm注入到lm中。
另一技术处理对事件执行的分析需要事件外部的数据的情形。例如,确定来自特定移动号码的呼叫是否实际上是该移动设备的合法所有者发起,仅有有关该呼叫的细节是不够的,还必须具有与设备的所有者有关的细节。通常,在快速数据分析中,尤其在需要低延迟响应时,不能利用这样的外部数据,因为将数据发送到相关算法(通常是lm)执行的计算节点花费太长时间。这个技术通过使用允许利用用户定义键完成数据碎片化的框架来解决该问题。对刚刚给出的例子,能够基于例如呼叫的移动号码将呼叫信息路由到lm。相同移动号码将总是被路由到相同lm,而不管有多少此lm的拷贝存在于系统的别处。因此,能够在相同节点中存储与此移动号码相关的任何外部信息,如与其所有者有关的相关细节。这个体系结构允许使用外部数据完成评分,但是不需要实时地在lm节点之间通信任何外部数据。
这个技术的一方面处理其中分析需要在相同计算的过程中处理数个不同类型的外部数据的情形。例如,能够进一步通过考虑被叫设备的所有者的细节来增强以上示例。该体系结构通过不仅允许一个碎片化进程而且在流水线中在lm之间路由来适应这个。例如,系统能够按始发号码路由呼叫,在lm中基于始发号码处理诈骗的任何指示,然后按被叫号码再路由并且在另一lm中基于被叫号码处理诈骗的任何指示。最终,本系统能够在无需计算节点之间的大规模数据移动的情况下基于两个指示符来确定呼叫的合法性。
另一技术允许系统执行在线数据建模,其中现实在不断变迁并且迟反应是高开销的。该技术把低估较旧数据的学习速率参数引入到以上所描述的框架中。在一些实施方式中,这通过随着任何新事件通过系统用管道输送时间戳而完成。较旧数据能够作为已经在lm中的聚合进程的一部分被低估。通过更改学习速率参数,系统开发者能够将机器学习模型设定为更稳定的(即怀疑可能有噪声的最近数据)或更灵活的(即怀疑可能过时的较旧数据)。这使得通过适应关于底层现实改变的速率的看法或通过考虑稳定性和灵活性需要来调谐算法。
另一技术允许系统在发生突然变动时触发警报。例如,系统可能需要标记社交媒体中的趋势单词,并且越早标记能够做得越好。这通过使两个相同的算法同时基于传入事件对数据进行建模而实现,其中两个算法之间的唯一差异是它们被给予不同的学习速率参数。通过对两个算法的输出进行比较并且测量这两个模型之间的“概念漂移”,能够检测趋势和趋势改变。在任何给定时间点t,算法基于它们已看见的数据对系统进行建模,即,算法捕获系统在时间t-δ的状态。改变学习速率导致不同的δ,对于稳定模型来说较大,对于灵活模型来说较小。对两个结果进行比较类似于取导数,并且因此类似于测量变化的速率。开发者可以实现相同的系统但是利用基本算法的更多拷贝以测量更高阶的导数。例如,二阶导数是用于检测突然跳跃并且使它们与逐渐改变分开的有用度量。
另一技术允许cm根据哪个数据被碎片到其算法的lm来实时地确定键(key)。因此,各种lm能够在计算中具有不对称的角色。数据的数据驱动再分割允许单独的lm基于具有不同特性的数据的部分来训练子模型。数据驱动再分割允许在不丢失框架的好处中的任一个的情况下实现整体算法,例如,打包、助推、交叉验证或粒子系统。
利用另一技术,该框架能够被用来实现与cm进行通信的lm的多对多关系。这允许系统不仅在任何给定时间计算一个聚合,而且并行地计算多个聚合。
能够实现本说明书中所描述的主题的特定实施例,以便实现以下优点中的一个或多个。系统能够将流处理系统的好处(例如,事件流并行的快速连续处理)与计算密集处理系统的好处(例如,执行复杂操作)组合。该计算密集处理系统能够与其它计算密集处理系统组合以形成能够优选地实时地训练事件流中的底层进程的复杂机器学习模型的分布式处理系统。应用所述模型,该系统能够执行事件流的在线评分,并且继续确定机器学习模型的实时更新。
此外或替选地,系统能够通过将场境(context)数据分割到流处理系统的本地建模器的操作存储器中来减少用于访问事件的场境数据的延迟。该系统进一步能够通过在与将场境数据维护在操作存储器中的进程相同的操作系统进程中执行流处理操作来减少延迟。以这种方式,该流处理系统能够例如通过不需要对外部数据库的调用来减少检索场境数据的延迟。附加地,该流处理系统能够减少由于数据锁定问题和竞争条件而导致的延迟。
在附图和以下描述中阐述本说明书的主题的一个或多个实施例的细节。主题的其它特征、方面和优点从本说明书、附图和权利要求将变得显而易见。
附图说明
图1是用于处理事件流的示例系统的图。
图2图示处理事件流的第一示例。
图3图示处理事件流以执行人脸识别的第二示例。
图4是用于定义由系统执行的操作的示例过程的流程图。
图5是用于处理事件流的示例过程的流程图。
图6图示用于通过第一示例路由策略使用场境数据处理事件流的示例系统。
图7是用于使用场境数据处理事件流的示例过程的流程图。
图8图示用于处理事件流并且在处理期间更新路由策略的示例系统。
图9图示用于确定事件流中的突然趋势或趋势改变的示例系统。
各个附图中的相同的附图标记和名称指示相同的元素。
具体实施方式
本说明书描述能够被用来执行事件的大事件流的实时分析和建模的系统和方法。
示例系统包括作为流处理系统操作的一个或多个计算系统。该流处理系统包括执行该流处理系统的操作的多个本地建模器。操作能够被组织为与流处理图的相应顶点——如有向非循环图(dag)中的顶点——相关联的操作。与顶点相关联的操作是例如由用户逻辑上组织的、待由相同本地建模器执行的操作。在执行相同操作集的多个本地建模器之间,针对每个顶点,划分事件流,使得每个本地建模器接收事件流的一部分。以这种方式能够并行地执行事件流的处理,从而增加吞吐量。
本地建模器对与事件流相关联的信息进行聚合(aggregate),例如,本地建模器在处理接收的事件的同时对信息进行聚合。与事件流相关联的聚合信息能够包括对包括在事件中的特定信息的出现次数进行聚合、对涉及包括在每个事件中的信息的数学运算的相应结果进行聚合等。在对与多个经处理的事件相关联的信息进行聚合之后,本地建模器将聚合信息提供给中心建模器。
中心建模器接收聚合信息并且确定相应机器学习模型的参数。中心建模器能够向一个或多个其它中心建模器提供机器学习模型的模型参数。还能够将参数提供给本地建模器,所述本地建模器然后对事件流应用机器学习模型。另外,本地建模器继续对要向中心建模器提供的与事件流相关联的信息进行聚合,所述信息被中心建模器用来确定并提供对机器学习模型的更新。
图1是用于处理事件流102的示例系统100的图。系统100包括多个本地建模器110a-n以及例如通过网络与本地建模器110a-n通信的中心建模器120。这些建模器中的每一个能够作为例如计算节点的一个或多个计算机系统的系统、作为在一个或多个计算机系统上执行的软件或者作为在一个或多个计算机系统上执行的相应虚拟机器被实现。在一些实施方式中,每个建模器可以是与其它建模器通信的单独的计算系统。
系统100包括与本地建模器110a-n通信的路由器(例如,路由节点104)。路由节点104(例如,摄取系统)接收事件的事件流102,并且例如通过网络将每个事件路由到本地建模器110a-n中的一个。
事件流102是事件的序列,例如,数据元组,其中每个事件包括能够被识别为键-值对映射的信息。例如,事件能够包括描述事件的时间戳的信息。时间戳能够在事件中被识别为键,例如“timestamp”、“input.timestamp”,该键被映射到值,例如,1408741551。事件能够包括任何任意信息,例如,由商店销售的衬衫的数目、拔打电话的电话号码等。
在一些实施方式中,路由节点104通过在本地建模器110a-n当中随机地或伪随机地选择来路由事件。在一些实施方式中,路由节点104能够循环将事件路由到本地建模器110a-n,例如,路由节点104将第一事件路由到本地建模器110a,将紧接的后续事件路由到本地建模器110b等。在一些实施方式中,路由节点104能够根据包括在每个事件中的信息(例如,包括在数据元组中的信息)将事件路由到本地建模器110a-n。例如,路由节点104能够根据包括在每个事件中的识别本地建模器的路由键将事件路由到本地建模器110a-n。
每个本地建模器(例如,本地建模器110a)接收从路由节点104提供的事件流的一部分,例如,被路由的事件106。本地建模器110a-n使用流处理引擎112a-n(例如,定义流处理系统的操作的软件应用)处理被路由的事件106。流处理引擎112a-n根据流处理系统的第一操作集处理事件。
本地建模器110a-n通常包括相同的流处理引擎112a-n,使得每个本地建模器110a-n执行相同的第一操作集。因此,本地建模器110a-n并行地处理相应被路由的事件106。
本地建模器110a-n能够存储机器学习模型的参数。参数能够由在下面描述的中心建模器120提供给本地建模器。本地建模器110a-n能够处理每个被路由的事件106以使用机器学习模型执行事件流的评分。评分是指表征事件。在一些实施方式中,评分是指应用接收的机器学习模型,例如,应用从机器学习模型确定的规则的集合。例如,每个本地建模器110a-n能够在处理期间将标记指派给每个事件,并且将该标记包括在事件中。也就是说,事件能够被处理以使用机器学习模型为事件最好地确定适当的标记(例如,分类)。在一些实施方式中,本地建模器能够接收可执行分段(例如,代码分段)的参考(例如,标识符),并且能够执行这些分段以执行评分。
本地建模器110a-n能够聚合被路由的事件106所关联的信息114。例如,本地建模器能够存储识别包括在被路由的事件106中的一条特定信息的出现次数的数据。附加地,本地建模器能够存储识别与每个被路由的事件106相关联但是不包括在被路由的事件106它本身中的信息的出现次数的数据。例如,事件能够包括识别电话号码的信息,并且本地建模器110a-n能够例如从数据库获得与该电话号码相关联的业务的分类。本地建模器110a-n能够对识别相应业务分类的出现次数的信息114进行聚合。本地建模器110a-n将此聚合信息114提供给中心建模器120。
中心建模器120能够与本地建模器110a-n进行通信,并且能够在一些实施方式中在与本地建模器110a-n不同的计算机系统上执行。每个本地建模器110a-n存储对中心建模器120的参考,例如,中心建模器120的标识符,例如,网络地址。类似地,中心建模器120存储对每个本地建模器110a-n的参考。在一些实施方式中,每个本地建模器向中心建模器120注册,并且中心建模器120存储识别已注册的本地建模器的信息。参考图4在下面描述向中心建模器注册。
中心建模器能够从本地建模器110a-n异步地请求聚合信息114,例如,在一些实施方式中中心建模器能够向每个本地建模器提供请求并且不等待来自本地建模器110a-n的响应。中心建模器能够从配置文件获得识别当满足时使中心建模器120请求聚合信息114的条件的信息。例如,配置文件能够识别阈值量的时间,例如,50毫秒、100毫秒、1秒,以用于中心建模器在向每个本地建模器110a-n提供对聚合信息的请求之前等待。在一些实施方式中,每个本地建模器能够存储阈值量的时间并且将聚合信息自动地提供给中心建模器120。参考图4在下面描述配置文件。
替选地或附加地,本地建模器能够确定它已处理定义阈值数目的被路由的事件106,例如,100、300或6000个,并且将聚合信息114提供给中心建模器120,例如,作为到中心建模器120的推送。能够在参考图4在下面描述的由本地建模器110a-n读取的配置文件中定义阈值数目。在一些实施方式中,本地建模器能够确定它已处理阈值量的数据,例如,聚合信息已超过阈值量的信息,例如,如用字节测量的。
本地建模器110a-n连续地接收被路由的事件106并且处理它们。在处理之后,本地建模器110a-n能够将经处理的事件116a-n提供给执行流处理系统的第二操作集的本地建模器。
中心建模器120存储机器学习模型122,例如,识别机器学习模型122的预测模型标记语言(pmml)文件。在从本地建模器110a-n接收到聚合信息114之后,中心建模器能够确定机器学习模型122的参数,例如,经更新的参数。中心建模器120能够基于有多少本地建模器110a-n已将聚合信息提供给中心建模器120来确定何时确定参数,例如,经更新的参数。例如,当至少阈值百分比(例如,50%、60%或用户可定义百分比)的本地建模器110a-n已提供聚合信息时,中心建模器120能够确定经更新的参数。在一些实施方式中,中心建模器120能够使用指定混合分量的数目、经处理的事件的数目、相应分量的均值等的聚合信息来确定高斯混合模型的参数。
中心建模器120能够确定是否将参数124提供给本地建模器110a-n。如果中心建模器120从未向本地建模器110a-n提供参数,则中心建模器120能够提供参数以用于存储。此外,如果中心建模器120具有先前提供的参数,则中心建模器120能够确定这些参数是否与先前提供的参数不同,例如,相差大于阈值百分比。在肯定确定之后,中心建模器120将参数124提供给本地建模器110a-n。本地建模器110a-n使用参数124来执行以上所描述的被路由的事件106的评分。
附加地,中心建模器120能够将参数124提供给本地建模器110a-n的子集。也就是说,中心建模器120能够例如从配置文件获得识别要接收参数124的本地建模器110a-n的信息。
中心建模器120能够将所确定的参数124提供给不同的中心建模器,例如,与执行第二操作集的本地建模器通信的中心建模器。参数能够被不同的中心建模器用来确定不同的机器学习模型或总体机器学习模型的不同步骤。例如,每当中心建模器120已将参数提供给本地建模器110a-n,中心建模器120能够通过确定中心建模器120自阈值量的时间以来尚未提供经更新的参数124或者通过确定参数124与最近提供的参数充分地不同(例如,大于阈值百分比)来确定要提供参数124。例如,能够将参数124表示为参数的向量,并且能够将最近提供的参数表示为参数的不同向量。系统能够计算参数的向量以及参数的不同向量的范数(例如,l1范数或l2范数),并且识别结果是否超过阈值。
中心建模器120和不同的中心建模器异步地通信。也就是说,每个中心建模器能够将参数的更新推送给不同的中心建模器,或者例如通过提供对经更新的参数的请求或者通过从不同的中心建模器接收参数作为推送来接收参数的更新。附加地,每个中心建模器120能够与多个其它中心建模器进行通信。
例如,通过向不同的中心建模器提供请求,中心建模器120能够从不同的中心建模器拉取参数。请求能够包括不同的中心建模器的标识符,或者请求能够包括由不同的中心建模器存储的特定机器学习模型的标识符。中心建模器120能够访问表示机器学习模型的标识符与中心建模器的标识符之间的映射的数据,并且获得中心建模器的期望标识符。
在一些实施方式中,本地建模器110a能够与超过一个中心建模器(例如,第二中心建模器和中心建模器120)通信。本地建模器110a能够为每个中心建模器对以上所描述的信息进行聚合。例如,本地建模器110a能够为中心建模器120对与事件流102相关联的第一类型的信息进行聚合,并且为不同的中心建模器对与事件流102相关联的第二类型的信息进行聚合。中心建模器能够接收相应聚合信息,并且确定相应机器学习模型的参数。本地建模器110a-n能够接收不同的参数,并且使用两个机器学习模型执行评分。
如上所述,并且在下面,本地建模器110a-n和中心建模器120能够存储信息,例如,机器学习模型的参数、聚合信息、机器代码、指令以及任何任意信息。此信息的全部能够被以快速高效的方式跨越存储系统复制并且提供给每个建模器。
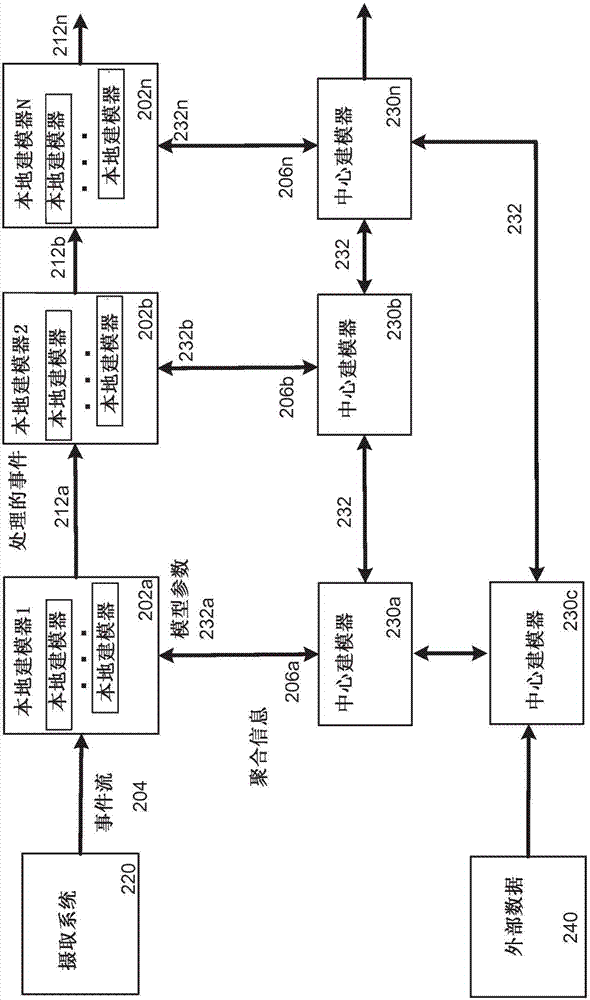
图2图示处理事件的事件流204的第一示例。图2的示例包括与中心建模器230a通信的流处理系统的第一组本地建模器202a、与中心建模器230b通信的流处理系统的第二组本地建模器202b以及与中心建模器230n通信的流处理系统的第n组本地建模器202n。
事件流204在可以为例如像路由节点104(图1)一样的路由节点的摄取系统220处被接收,并且路由到第一组本地建模器202a。如上所述,本地建模器202a中的每个本地建模器接收事件流204的一部分以用于处理。本地建模器202a执行流处理系统的第一操作集。
因为本地建模器202a作为流处理系统而操作,所以本地建模器202a始终处理接收的事件,例如,同步地接收事件、处理事件并且将经处理的事件提供给其它本地建模器,例如,第二组本地建模器202b中的本地建模器。如果本地建模器202a已存储机器学习模型的参数,则它们能够处理事件流以使用机器学习模型执行评分,并且还并行地对信息进行聚合。如果本地建模器202a仍然尚未接收到机器学习模型的参数,则它们能够对信息进行聚合。能够将此聚合信息206a提供给与本地建模器202a通信的第一中心建模器230a。
聚合信息206a能够在本地建模器已处理阈值数目的事件之后或者在阈值数目的本地建模器202a已处理阈值数目的事件之后被从本地建模器202a中的本地建模器提供给中心建模器230a。附加地,能够在自本地建模器202a最后将聚合信息206a提供给中心建模器230a以来阈值量的时间已过去之后提供聚合信息206a。
在处理事件流204的事件之后,本地建模器202a将经处理的事件212提供给第二组本地建模器202b中的本地建模器,例如,执行流处理系统的第二操作集的本地建模器。在一些实施方式中,经处理的事件212被提供给路由节点,该路由节点将事件路由到第二组202b中的特定本地建模器。类似地,在第二组202b的本地建模器处理事件212a之后,本地建模器将经处理的事件212b提供给第n组本地建模器202n中的本地建模器。在任何特定情况下,可以或者可能不修改经处理的事件,即,它们可以或者可能不与所接收的事件不同。
每个中心建模器能够使用接收的聚合信息确定相应机器学习模型的参数232。在一些实施方式中,中心建模器230a-n能够各自确定不同的机器学习模型的参数。在一些其它实施方式中,每个中心建模器确定总体机器学习模型的一部分。每个中心建模器然后能够确定要将参数提供给与中心建模器通信的本地建模器,并且提供给其它中心建模器。参考图5在下面描述中心建模器如何能够提供机器学习模型的参数。
附加地,中心建模器能够异步地并且独立于每个其它中心建模器从相应本地建模器接收聚合信息。也就是说,中心建模器230b能够不顾不同的中心建模器230n而接收聚合信息206b。
外部数据240能够由中心建模器230c例如从数据库获得以供由中心建模器230c使用。中心建模器230c还能够从另一中心建模器(例如,中心建模器230a)接收相应机器学习模型的参数,并且使用外部数据240和/或参数来执行计算密集计算。例如,中心建模器230a能够确定机器学习模型的参数,并且将这些参数提供给中心建模器230c。中心建模器230c然后能够获得外部数据240并且将该外部数据240映射到由中心建模器230a确定的机器学习模型。在映射外部数据240之后,中心建模器能够将机器学习模型的参数以及所确定的映射提供给不同的中心建模器,例如,中心建模器230n。在另一示例中,中心建模器230a能够确定机器学习模型的参数,并且将这些参数提供给中心建模器230c。中心建模器230c然后能够获得外部数据240,并且使用从中心建模器230a接收的参数以及外部数据240确定相应机器学习模型的参数。附加地,中心建模器230c能够使用外部数据240确定从中心建模器230c接收的参数的经更新的参数,并且将经更新的参数提供给另一中心建模器,例如,返回给中心建模器230a或中心建模器230n。
注意,中心建模器中的全部、没有一个或一些在特定实施方式中可以获得外部数据,并且不同的中心建模器可以获得不同的外部数据。
注意,中心建模器能够以循环方式彼此谈话并且循环的大小可以是任何大小。特别地,循环可能大小为2:在特定实施方式中,中心建模器a能够更新中心建模器b,该中心建模器b然后能够稍后更新中心建模器a,依此类推。图2中所示出的拓扑仅仅是说明性的。
图3图示处理事件流的第二示例。图3的示例能够被用来将标记指派给例如从一个或多个视频相机获得的图像中看见的相应个体。图示包括本地建模器(例如,本地建模器320、本地建模器322和本地建模器324)以及中心建模器(例如,中心建模器330、332和334)。
事件的事件流310被提供给本地建模器320。事件流的每个事件编纂单个人的人脸图像,同时事件流310中的事件对许多不同的个体(例如,在视频相机数据中捕获的未知人们)的图像进行编码。
本地建模器320对与事件流相关联的信息进行聚合,例如,将事件加在一起。周期性地,本地建模器320将聚合信息312提供给中心建模器330。中心建模器计算由本地建模器320处理的事件的平均,并且获得平均人脸向量。也就是说,中心建模器330根据由本地建模器320看见的所有人脸确定平均人脸。中心建模器330然后向本地建模器320中的每一个提供定义平均人脸的参数(例如,平均像素值的向量)以用于存储。
在确定参数之后,本地建模器320使用这些参数来确定包括在事件中的特定人脸与由中心建模器330确定的平均人脸之间的差异向量。在处理事件流310的事件之后,该事件被提供给本地建模器322。
本地建模器322接收每个事件并且对与该事件相关联的信息进行聚合。例如,本地建模器322接收特定人在每个事件中的人脸与平均人脸之间的差异,并且对这些差异进行聚合以生成协方差矩阵。周期性地,本地建模器322将聚合信息(例如,相应协方差矩阵)提供给中心建模器332。
中心建模器332从本地建模器322接收聚合信息(例如,协方差矩阵)并且在整个事件流310之上计算协方差矩阵。中心建模器332然后继续对此协方差矩阵执行特征向量分析以便计算数据中的特征人脸。每个特征人脸是所确定的人脸空间中的向量。这些特征人脸因此定义从像素值空间到人脸空间的线性变换。潜在地,中心建模器332可以丢弃其特征值小于预定阈值的特征人脸或者仅保持其特征值最大的预定数目的特征人脸。
中心建模器332向本地建模器322提供识别变成人脸空间的线性变换的参数以用于存储。每个本地建模器接收事件流310并且将每个事件投影到人脸空间中,例如,本地建模器计算识别事件的特征人脸分量的权重的权重向量。在处理事件之后,本地建模器322将经处理的事件提供给本地建模器324。
本地建模器324接收包括描述在人脸空间的投影的信息的每个经处理的事件。本地建模器324然后例如通过借助于高斯混合模型近似数据在人脸空间中的分布来对与事件流310相关联的信息进行聚合。
周期性地,本地建模器324将经近似的分布参数提供给中心建模器334,该中心建模器334进一步对信息进行聚合,以便计算来自整个事件流310的数据的近似分布。中心建模器334使用此近似分布以便表征例如通过聚类矩心及其半径所描述的数据中的聚类的位置。中心建模器334然后将聚类参数提供给本地建模器324以用于存储。
本地建模器324利用聚类参数数据以便将与每个传入事件相关联的人脸空间向量映射成聚类中的一个。聚类的身份形成本地建模器324包括在事件中的标记,例如,以为通过事件识别的人脸指定标记。经标记的事件然后被转发以用于在下游进一步处理。
图4是用于定义工作流并且处理事件的示例过程400的流程图。一般而言,系统向开发者提供用于识别待由系统执行的操作的框架。开发者能够利用该框架来定义流处理系统(例如,本地建模器110a-n)的操作的集合。附加地,开发者能够定义待由与本地建模器通信的一个或多个中心建模器(例如,中心建模器120)执行的操作。在定义操作之后,开发者能够定义本地建模器与中心建模器之间的通信链路,以定义例如图3中所图示的总体工作流。工作流能够由系统使用定义本地建模器和中心建模器的开发框架(例如,库中的函数,例如,用javatm、c或c++编程语言编写的函数)来实现。一般而言,工作流的开发者不必具有关于系统正在如何实现工作流的知识。过程400将被描述为由一个或多个计算机的适当地编程的系统(例如,图1中所图示的系统100)来执行。
系统接收定义本地建模器的信息(402)。开发者能够定义待由本地建模器执行的操作的集合。例如,开发者能够利用定义本地建模器的函数(例如,库中的java函数)的开发框架。开发者能够定义执行各种操作(例如,对事件流中的特定信息进行聚合、使用机器学习模型对事件流进行评分)的本地建模器的模板。开发者还能够例如使用库中的函数来对本地建模器如何通信进行编程。
系统接收定义中心建模器的信息(404)。开发者能够定义能够被用来实现不同的机器学习模型的不同的中心建模器。开发者能够利用执行用于生成机器学习模型的过程的操作来定义机器学习模型。附加地,开发者能够包括用于读入机器学习模型的参数或者将机器学习模型的参数存储在文件或数据结构(例如,预测模型标记语言(pmml)文件,例如,定义输入数据到机器学习模型中使用的数据的映射、输出数据的映射以及机器学习模型的体系结构的文件)中的操作。开发者还能够定义中心建模器能够在实现特定机器学习模型之外执行的任意操作。例如,中心建模器能够存储先前的机器学习模型,生成警报,例如从数据库获得外部数据等。
系统接收定义本地建模器实例的信息(步骤406)。在定义本地建模器和中心建模器的模板之后,开发者能够定义实现流处理系统的本地建模器。也就是说,开发者能够从参考步骤402描述的本地建模器中识别特定本地建模器。开发者能够利用配置文件(例如,可扩展标记语言(xml)文件)来识别本地建模器。
系统接收用于本地建模器的配置参数(步骤408)。开发者能够为本地建模器定义配置参数,例如,在本地建模器推送聚合信息时指定每个事件中的信息如何被本地建模器利用的参数等。
开发者能够利用配置文件来指定来自事件流的信息到本地建模器(例如,独立地到每个本地建模器或者到所有本地建模器)的映射。例如,事件流的每个事件能够具有以上所描述的三个键-值对,并且开发者能够识别从每个键-值对到本地建模器的操作中所使用的变量的映射。
开发者能够指定本地建模器何时将向中心建模器提供聚合信息的策略。例如,开发者能够指定本地建模器需要在向中心建模器提供聚合信息(例如,作为推送)之前处理阈值数目的事件。开发者还能够指定本地建模器需要在向中心建模器提供聚合信息之前已处理或者生成阈值量的信息。
开发者能够指定本地建模器应该取决于它们是否已从中心建模器接收到参数而执行不同的操作,例如,开发者能够在参数已被接收的情况下指定任何事件中的信息的聚合以及事件流的评分。
系统接收用于中心建模器的配置参数(步骤410)。开发者能够在配置文件中识别一个或多个中心建模器。开发者还能够例如在配置文件中指定机器学习模型将由中心建模器获得,并且在配置文件中包括机器学习模型(例如,ppml文件)的位置。
附加地,开发者能够指定两个或更多个中心建模器将频繁地在彼此之间提供机器学习模型参数。系统能够据此确定两个中心建模器应该在相同计算机系统(处理节点)上或者在相同操作系统进程(例如,相同java虚拟机)中执行。
开发者能够识别定义中心建模器的一个或多个配置参数的策略。例如,开发者能够包括定义中心建模器等待直到从本地建模器请求聚合信息为止的时间的量的策略。替选地,策略能够定义本地建模器在向中心建模器提供聚合信息之前必须处理的事件的阈值量。策略能够指定在任何时候中心建模器确定对机器学习模型的更新,它将会将经更新的参数提供给它通信的本地建模器。类似地,策略能够指定中心建模器何时将更新的机器学习模型推送给另一中心建模器,例如,经更新的参数何时与现有参数相差大于阈值百分比。此外,开发者能够指定中心建模器仅在确定阈值数目的本地建模器已提供聚合信息时确定对机器学习模型的更新。类似地,策略能够指定中心建模器仅在确定阈值数目的本地建模器已处理了阈值数目的事件时确定更新,例如,中心建模器能够接收聚合信息并且根据聚合信息的大小识别已被处理的事件的数目。
系统接收定义本地建模器与中心建模器之间的通信链路的信息(步骤412)。
在一些实施方式中,开发者能够利用配置文件(例如,可扩展标记语言(xml)文件)来识别本地建模器与中心建模器之间的通信链路,例如,事件如何应该在它们之间流动。每个本地建模器在配置文件中通过标识符(例如,名称或识别号码)来识别。连同每个本地建模器的标识符一起,配置文件包括与每个本地建模器通信的中心建模器的标识符。在一些实施方式中,开发者能够识别应该执行由步骤408中所识别的本地建模器识别的操作的本地建模器的数目,例如,多个本地建模器能够并行地执行以增加吞吐量。
在一些实施方式中,系统能够提供被配置成从开发者接收识别通信链路的输入的用户界面,例如,流处理图。例如,界面能够允许开发者识别通过有向边连接的流处理顶点,其中每个有向边将事件流传递给顶点。顶点能够被图式地表示为例如用户界面中的框或节点,并且开发者能够将名称或标识符指派给每个顶点。每个顶点能够与一个操作集相关联,并且在选择顶点时,系统能够识别执行该操作集的本地建模器。
系统初始化本地建模器(步骤414)。在定义工作流之后,例如,利用在步骤412中以上所描述的通信链路,系统根据配置文件初始化本地建模器。系统获得并执行实现配置文件中所识别的本地建模器的开发代码。也就是说,系统根据配置文件初始化一个或多个本地建模器,例如,识别与本地建模器通信的中心建模器、输入数据到内部变量的映射等。系统能够执行定义本地建模器的函数的库的函数,例如,初始化函数。
系统初始化中心建模器(步骤416)。系统根据配置文件初始化中心建模器。系统初始化每个中心建模器,例如,注册与中心建模器通信的每个本地建模器,获得配置文件中所识别的机器学习模型等。如果被识别在配置文件中,则中心建模器能够将机器学习模型提供给与该中心建模器通信的本地建模器。系统通过执行定义中心建模器的函数的库的函数(例如,初始化函数)来实现初始化。类似地,系统通过执行中心建模器函数以提供机器学习模型并且执行本地建模器函数以接收和存储机器学习模型来实现向本地建模器提供机器学习模型。
系统根据工作流处理事件(步骤418)。参考图5在下面描述处理事件。
图5是用于处理事件流的示例过程500的流程图。过程500将被描述为由一个或多个计算机的适当地编程的系统(例如,图1中所图示的系统100)来执行。
系统接收事件流(步骤502)。系统能够通过网络(例如,互联网)从用户设备接收事件流。事件是可识别的发生的事情,例如,电话呼叫被拨打、顾客在企业处买咖啡、在特定风力涡轮机的实测风速。每个事件已经包括信息,例如,电话号码、咖啡的类型、咖啡的价格、顾客买咖啡的等待时间。
系统接收事件流并且将每个事件路由到流处理系统的多个本地建模器中的特定本地建模器。在一些实施方式中,每个事件是根据事件的场境数据很可能被维持在哪里路由的。
系统根据流处理系统的第一操作集来处理事件(步骤504)。每个事件被路由到特定本地建模器,并且系统通过执行第一操作集来处理每个事件,其中每个本地建模器并行地对接收的事件执行相同的操作。
操作能够包括用于执行所接收的事件流的评分的操作。评分可能是指通过对包括在事件中的信息应用机器学习模型来表征事件。在一些实施方式中,评分能够包括例如在如参考图3所描述的人脸空间中确定要附加到包括在每个事件中信息的信息,例如,对事件进行表征或者分类的标记或特定坐标地址。附加地,评分能够包括修改包括在每个事件中的信息。机器学习模型可能先前已由系统确定并且提供给本地建模器,参考步骤508和510在下面描述。替选地机器学习模型可能已由中心建模器提供,例如,中心建模器能够从配置文件中所指定的位置获得机器学习模型。
此外,系统能够对与每个事件相关联的信息进行聚合。例如,本地建模器能够对包括在每个事件中的特定信息(例如,包括在定义事件的数据元组中的一条特定信息)的出现进行聚合。
在对相应事件执行操作之后,系统将经处理的事件提供给执行流处理系统的后续操作集的本地建模器。经处理的事件可以包括由本地建模器插入的信息(例如,标记、数据值),例如,以执行事件的评分。
系统向中心建模器提供聚合信息(步骤506)。系统能够将聚合信息从一个或多个本地建模器提供给中心建模器。中心建模器能够向每个本地建模器提供对聚合信息的请求。本地建模器然后接收该请求,并且异步地将聚合信息提供给中心建模器。在一些实施方式中,中心建模器能够在等待阈值量的时间(例如,50ms、100ms、1秒)之后提供请求。能够在参考图4以上所描述的配置文件中定义阈值量的时间。
此外,中心建模器能够在本地建模器已处理阈值数目的事件(例如,500、1000、10000个事件)之后从本地建模器接收聚合信息。中心建模器也能够从仅已处理阈值数目的事件的本地建模器接收聚合信息。附加地,中心建模器能够在阈值百分比(例如,50%、60%、92%)已处理阈值数目的事件之后从每个本地建模器接收聚合信息。
系统确定与机器学习模型相关联的参数(步骤508)。中心建模器接收聚合信息,并且确定机器学习模型的参数。中心建模器例如在配置文件中确定由开发者指定的参数机器学习模型(例如,线性判别分析、k均值聚类、贝叶斯混合模型)的参数。
在一些实施方式中,系统向每个本地建模器提供参数以用于存储,参考步骤510进行描述,并且向第二中心建模器提供参数,参考步骤512进行描述。系统能够例如从配置文件获得定义中心建模器将据此向本地建模器或者向第二中心建模器提供参数的情况的信息。
系统将参数提供给一个或多个本地建模器(步骤510)。中心建模器能够在异步呼叫中将参数提供给本地建模器。本地建模器接收参数,存储它们,并且使用机器学习模型执行事件流的评分。本地建模器然后能够将经评分的事件流提供给后续本地建模器,例如,执行流处理系统的后续操作的本地建模器。附加地,本地建模器与执行评分并行地对与事件流相关联的信息进行聚合。
在接收到参数之后,本地建模器能够用从中心建模器接收的新参数覆写机器学习模型的任何现有参数。替选地,本地建模器能够存储现有参数以及从中心建模器接收的新参数。以这种方式,本地建模器能够使用两个机器学习模型执行评分。
系统将参数提供给第二中心建模器(步骤512)。在确定参数之后,系统能够自动地将参数提供给第二中心建模器,例如,异步地提供参数。在一些实施方式中,如果系统某时仅具有确定的参数,则系统将自动地将参数提供给第二中心建模器。
如果系统已在先前的时间将参数提供给第二中心建模器,则系统确定是否提供这些参数。在一些实施方式中,系统确定所确定的参数与先前提供的参数相差大于或者小于阈值百分比,例如,0.5%、1%或2%。
在一些实施方式中,系统能够执行步骤510,并且向后续本地建模器提供经评分的事件,而不用向第二中心建模器提供参数。类似地,系统能够向第二中心建模器提供参数,而不用向后续本地建模器提供经评分的事件。
图6图示用于使用场境数据通过示例路由策略来处理事件流的示例系统600。系统600包括参考图1以上所描述的与中心建模器620通信的流处理系统的多个本地建模器610a-n。系统600还包括路由节点604,其接收事件流602并且根据路由策略将事件流中的每个事件路由例如到存储与事件的处理有关的场境数据的特定本地建模器。场境数据是与事件有关的未出现在该事件它本身的数据属性内的原有数据。例如,表示被发起的电话呼叫的事件可以包括用户的电话号码的数据属性。然而,事件将通常不包括关于用户的其它信息,例如,用户的家庭地址。
本地建模器610a-n各自包括操作存储器,例如,为通过处理器的快速随机存取而设计的高速存储器,例如,动态随机存取存储器。本地建模器610a-n中的每一个维护场境数据的分区,其中场境数据的每个分区由相应本地建模器维护在操作存储器中。在一些实施方式中,场境数据612a-n的分区通过执行流处理引擎614a-n的操作的相同操作系统进程来维护,例如,在java虚拟机的相同进程中。例如,操作系统进程能够包含特定事件的场境数据并且然后在相同操作系统进程内使用该场境数据处理事件。
场境数据一般地跨越本地建模器610a-n被分割,其中每个本地建模器接收场境数据612a-n的特定分区。然而,如果场境数据足够小则一些场境数据能够由每个本地建模器存储。系统600能够分割场境数据,使得与特定事件有关的特定场境数据很可能位于与和该特定事件有关的其它场境数据(例如,处理事件所需的场境数据)相同的本地建模器上。
当路由节点604接收到包括在事件流602中的事件时,路由节点604根据与场境数据612a-n的分区的数据亲和度来路由事件。按数据亲和度路由是指向很可能维护与事件有关的场境数据的本地建模器分发事件。在一些实施方式中,路由节点604能够通过获得包括在每个事件中的信息并且确定存储与所获得的信息有关的场境数据的场境数据的分区来路由每个接收的事件。路由节点604能够识别用于在每个事件中从配置文件获得的识别特定键-值对的信息,例如,开发者能够定义事件将被按电话号码路由。
例如,路由节点604能够获得包括在事件中的路由键,并且确定存储与特定路由键有关的场境数据的场境数据的分区。在一些实施方式中,路由节点604能够对路由键执行散列过程,并且获得场境数据的分区的标识符。在一些实施方式中,路由节点604能够存储识别路由键的范围与存储与范围中包括的路由键有关的场境数据的场境数据的相应分区之间的映射的信息。
附加地,路由节点604能够存储识别场境数据的分区以及存储相应分区的本地建模器的映射的信息。
路由节点604然后能够将事件提供给存储场境数据的分区的本地建模器。
在一些实施方式中,事件能够包括数据亲和度提示。数据亲和度提示识别对于事件来说很可能具有场境数据的场境数据的分区。在一些实施方式中,数据亲和度提示可以是包括在事件中的识别场境数据的分区的元数据。数据亲和度提示还可以是附加到定义事件的数据元组的信息,或者可以是包括在用来将事件路由到特定本地建模器的消息报头中的信息。
在接收到被路由的事件606之后,每个本地建模器根据流处理系统的第一操作集处理每个事件,如参考图1以上所描述的。在处理事件之后,本地建模器610a将事件616a提供给不同的路由节点。不同的路由节点将事件路由到根据流处理系统的第二操作集来处理事件的本地建模器。
在处理事件流时,本地建模器610a-n对事件流进行评分,例如,修改要包括的每个事件或者修改信息。不同的路由节点能够使用由本地建模器610a-n修改的信息来路由每个事件。例如,本地建模器610a-n能够基于存储的机器学习模型对每个事件进行分类(例如,标记)。不同的路由节点能够基于分类路由每个事件。
在一些实施方式中,本地建模器610a能够修改事件616a中的数据亲和度提示。经修改的数据亲和度提示通知不同的路由节点如何使用场境数据路由事件616a。
在一些其它实施方式中,不同的路由节点能够接收事件616a并且基于包括在事件616a中的信息来定义场境数据的分区,例如,开发者能够定义在每个事件中用来路由事件的键-值对。包括在事件中的信息(例如,键-值对)可能不同于路由节点604使用的信息。也就是说,例如,开发者能够识别事件应该根据电话号码被路由,然后根据姓被路由。
图7是用于使用场境数据处理事件流的示例过程700的流程图。过程700将被描述为由一个或多个计算机的适当地编程的系统(例如,系统600)来执行的。
系统接收包括在事件流中的事件(702)。系统能够通过网络(例如,互联网)接收包括事件的事件流。
系统在路由节点(例如,路由节点604)处接收事件,并且将事件路由到特定本地建模器(例如,本地建模器610a)(步骤704)。事件是根据处理事件所需的场境数据很可能被维护在哪里而路由的。
在一些实施方式中,能够通过对包括在事件中的信息(例如,路由键)执行散列过程来路由事件。路由键能够识别包括在事件中的特定类型的信息,例如,名字、电话号码、地址,其中每种类型的信息被识别为包括在事件中的键-值对中的键。在执行散列过程之后,能够例如通过把识别场境数据的分区的路由键进行散列来获得值,例如,能够将值映射到分区的标识符。例如,散列过程能够产生值,并且系统能够计算该值以及识别本地建模器的数目的值的模数。计算的结果是建模器号码,例如,可能范围从0到本地建模器的数目减一的数字。系统能够将事件提供给通过建模器号码识别的特定本地建模器。
在一些实施方式中,事件能够包括系统能够用来确定场境数据的分区的数据亲和度提示,并且本地建模器维护场境数据的那个分区。数据亲和度提示能够识别处理事件所需的场境数据的类型。路由节点能够获得包括在事件中的信息,例如,与场境数据的类型相对应的路由键,并且对该信息执行散列过程。路由节点能够从散列过程获得值并且获得识别映射到该值的场境数据的类型的分区的信息。
系统执行请求事件的场境数据的操作(706)。例如,事件能够表示从特定电话号码拨打的电话呼叫,并且该操作能够请求对与该特定电话号码相关联的用户账户号码的访问。在一些实施方式中,本地建模器在相同操作系统进程(例如,java虚拟机进程)中执行操作,所述操作系统进程还维护存储在操作存储器中的场境数据的分区。
系统从操作存储器获得所请求的场境数据(708)。因为场境数据被维护在操作存储器中,所以系统能够迅速地获得所请求的场境数据,避免数据锁定问题和竞争条件,并且避免必须从外部数据库调用并获得场境数据。例如,与通过网络从外部计算机系统预取相比,以这种方式用于预取场境数据的时间减少了。
系统使用场境数据执行操作(710)。本地建模器使用场境数据对事件执行操作。在对事件执行操作时,本地建模器能够基于功能模块的特定操作来修改事件。一些操作还可以修改场境数据,在此情况下,当系统访问后续事件的场境数据时,系统将检索经修改的场境数据。
图8图示用于处理事件流并且在处理期间更新路由策略的示例系统800。系统800包括参考图1和图6以上所描述的与中心建模器820通信的流处理系统的多个本地建模器810a-n。系统800还包括路由节点804,该路由节点804接收事件流802并且根据路由策略路由事件流中的每个事件。
路由节点804接收事件流802并且根据路由策略将每个事件提供给特定本地建模器810a-n。路由策略是路由节点804执行来接收事件并且识别要接收该事件的本地建模器的过程。路由策略最初能够由开发者识别,例如,路由节点能够通过执行本地建模器的循环过程或者通过确定存储处理事件所需的场境数据的本地建模器来向本地建模器随机地提供事件,例如,如参考图7所描述的。
如例如参考图1和图6以上所描述的,本地建模器810a-n接收被路由的事件806a-n,并且执行包括对与每个事件相关联的信息进行聚合的操作。本地建模器806a-n将聚合信息814a-n提供给中心建模器820,该中心建模器820使用聚合信息来确定机器学习模型822的参数。
在确定机器学习模型822的参数的过程中,中心建模器820能够基于包括在每个事件中的特定信息来确定本地建模器应该接收事件。也就是说,中心建模器820能够确定相应本地建模器应该接收事件流802的特定子总体,并且对与该子总体相关联的信息进行聚合。在肯定确定之后,中心建模器820更新路由节点804的路由策略824,例如,中心建模器820发送指定事件应该通过定义每个事件的数据元组中的一个或多个数据元素来路由的信息824。中心建模器820然后从对事件流802的子总体进行聚合的本地建模器接收聚合信息,并且为每个子总体确定机器学习模型的相应参数。
提供给路由节点804的经更新的路由策略824可以是识别用于路由事件的过程的一个或多个规则。例如,规则能够识别取决于包括在事件中的一条特定信息的值,例如,映射到特定键的值,应该将事件路由到特定本地建模器。规则能够被表示为例如以包括在事件中的信息为条件的一系列“ifthen”语句,其最终识别用于接收事件的本地建模器。附加地,规则能够被表示为树。
为了确定事件流的子总体,中心建模器820能够对事件流执行聚类过程(例如,k均值聚类过程)或混合模型过程(例如,高斯混合模型过程),并且识别事件的聚类或各自定中心在多个均值中的一个附近的事件的混合物。在一些实施方式中,中心建模器820能够通过在轻微程度上改变路由策略来更新路由节点804的路由策略。中心建模器820然后能够确定聚类过程是否确定更好地对事件进行分类的聚类,例如,每个聚类包括相差包括在每个事件中的特定信息的事件。如果是这样的话,则中心建模器820能够继续更新路由策略,直到它确定路由策略最好地将事件分成聚类为止。例如,中心建模器820能够确定事件应该通过事件中所识别的位置来路由,例如,应该基于识别事件的其中每个聚类包括具有相同位置的事件的聚类来与各自具有识别拉斯维加斯的信息的事件不同地路由各自具有识别旧金山的信息的事件。
附加地,为了确定子总体中心建模器820能够例如从配置文件获得识别一个或多个预定义配置的信息。每个配置识别特定路由策略,并且中心建模器820能够执行每个路由策略以确定配置是否比不同的配置更好地确定事件的聚类。在确定最好地确定事件的聚类的配置时,中心建模器820能够向路由节点820提供用于根据该配置路由事件的信息。
在一些实施方式中,本地建模器810a-n存储参考图6以上所描述的与事件有关的场境数据。在这些实施方式中,在更新路由策略之后,每个本地建模器必须在经更新的路由策略中获得与路由到它们的事件有关的场境数据。中心建模器820能够根据经更新的路由策略来确定应该被存储在每个本地建模器的操作存储器中的场境数据。例如,中心建模器820能够访问包括在事件中的特定信息以及与该信息有关的场境数据被存储在哪里的映射。在确定之后,每个本地建模器能够从一个或多个其它本地建模器或者从使所有信息重复的存储系统获得场境数据。
图9图示用于处理事件流以确定事件流中的突然趋势或趋势改变的示例系统。能够根据机器学习模型的参数方面的突然偏移来识别突然趋势或趋势改变。在一些实施方式中,处理能够确定断点。为了识别突然趋势或趋势改变,使用了用于确定机器学习模型的第一参数集的第一系统910(例如,像参考图1所描述的系统100一样的系统)以及用于确定相同机器学习模型的第二参数集的第二系统920(例如,像参考图1所描述的系统100一样的另一系统)。
两个系统中的每一个通过接收相同事件流904并且在对信息进行聚合的同时使用每个事件的时间戳对与事件流904相关联的信息进行加权来确定机器学习模型的相应参数。两个系统中的每一个不同地对信息进行加权,例如,一个系统910能够对较旧事件给予更高加权,而第二系统920能够对较新事件给予更高加权。
学习速率参数指定待应用于与事件相关联的聚合信息的一个或多个权重。学习速率参数指定考虑到事件的特定时间戳输出待应用于与事件相关联的信息的权重的函数,例如,线性或非线性函数。以这种方式能够完全低估较旧事件。
摄取系统902接收事件流904,并且将该事件流904提供给具有第一学习速率参数的系统910并给具有第二学习速率参数的系统920。
如参考图4以上所描述的,开发者能够在识别工作流时为每个系统指定相应学习速率参数。开发者能够识别包括学习速率参数的本地建模器的使用,并且在定义工作流的配置文件中指定学习速率参数,例如,函数。
两个系统910和920接收事件流904,并且对与事件流904相关联的信息进行聚合。在与每个事件相关联的信息的聚合期间,例如,通过每个系统的相应本地建模器,每个系统对聚合信息应用相应学习速率参数,并且基于事件的时间戳对该信息进行加权。以这种方式每个系统能够低估较旧事件,对较旧事件进行更大地加权,对较新事件进行更高地加权等。
在对信息进行聚合之后,每个系统的相应中心建模器确定机器学习模型的参数。每个系统确定仅在每个系统的学习速率参数方面不同的相同机器学习模型的参数。在一些实施方式中,例如取决于学习速率参数,参数912和参数922表示机器学习模型在相应时间点的参数。
来自每个系统的参数(例如,参数912和参数922)被提供给概念漂移引擎930。概念漂移引擎930可以是在执行系统910和920的系统上执行的系统上执行的软件。在一些实施方式中,概念漂移引擎930能够在通过网络(例如,互联网)连接到两个系统910和920的外部系统上执行。
概念漂移引擎930接收参数912和922,并且确定参数之间的差异。在确定差异时,概念漂移引擎930能够确定参数912和922中的每个特定参数之间的差异的和,例如,l1-范数。在一些其它实施方式中,概念漂移引擎930能够确定每个参数集的l2-范数。
概念漂移引擎930确定差异是否大于阈值,并且如果是这样的话则生成识别事件流中的趋势或趋势改变的信息。识别趋势或趋势改变的信息能够包括来自相差大于阈值百分比的参数912和参数922的参数的识别。然后能够将此信息提供给用户设备。例如,每个事件能够识别特定用户与由系统提供的服务的交互。概念漂移引擎930能够确定事件流的事件突然地包括用户使用特定服务。例如,参数912和参数922能够各自表示系统服务的直到不同的时间点为止的使用模型。如果概念漂移引擎930检测到参数的突然改变,例如,机器学习模型的参数的导数改变,则概念漂移引擎930能够提供识别该突然改变的信息以及恶意软件已被安装在用户系统上的指示。
本说明书中所描述的主题和操作或动作的实施例能够用数字电子电路、用有形地具体化的计算机软件或固件、用包括本说明书中公开的结构及其结构等同物的计算机硬件或者用它们中的一个或多个的组合来实现。本说明书中所描述的主题的实施例能够作为一个或多个计算机程序(即,在有形非暂时性程序载体上编码以供由数据处理装置执行或者控制数据处理装置的操作的计算机程序指令的一个或多个模块)被实现。替选地或此外,能够将程序指令编码在人工生成的传播信号(例如,被生成来对信息进行编码以便传输到适合的接收器装置以供由数据处理装置执行的机器生成的电、光学或电磁信号)上。计算机存储介质可以是机器可读存储设备、机器可读存储基底、随机或串行存取存储器设备,或它们中的一个或多个的组合。
一些系统和组件可以在本说明书中被表征为被“配置成”或者“可操作来”执行特定操作或动作。对于计算机系统来说,这意味着系统已在其上安装了在操作中使该系统执行特定操作或动作的软件、固件、硬件或它们的组合。对于一个或多个计算机程序来说,这意味着一个或多个程序包括当由数据处理装置执行时使该装置执行特定操作或动作的指令。
术语“数据处理装置”是指数据处理硬件并且包含用于处理数据的所有类型的物理装置、设备和机器,作为示例包括可编程处理器、计算机或多个处理器或计算机。装置还可以是或者还包括专用逻辑电路,例如,fpga(现场可编程门阵列)或asic(专用集成电路)。装置除了包括硬件之外,还能够可能地包括为计算机程序创建执行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统或它们中的一个或多个的组合的代码。
计算机程序(其还可以被称为或者描述为程序、软件、软件应用、模块、软件模块、脚本或代码)能够用任何形式的编程语言(包括编译或解释型语言)或者描述性或过程语言编写,并且它能够被以任何形式(包括作为独立程序或者作为适合于在计算环境中使用的模块、组件、子例程或其它单元)部署。计算机程序可以但不必与文件系统中的文件相对应。能够在保持其它程序或数据的文件的一部分(例如,存储在标记语言文档中的一个或多个脚本)中、在专用于所述的程序的单个文件中或者在多个协同文件(例如,存储一个或多个模块、子程序或代码的部分的文件)中存储程序。能够将计算机程序部署成在一个计算机上或者在位于一个站点处或跨越多个站点分布并且通过数据通信网络互连的多个计算机上执行。
如本说明书中使用的,“引擎”或“软件引擎”是指提供与输入不同的输出的软件实现的输入/输出系统。引擎可以是功能性的编码块,例如库、平台、软件开发套件(“sdk”)或对象。每个引擎能够被实现在包括一个或多个处理器和计算机可读介质的任何适当类型的计算设备上,所述计算设备例如服务器、移动电话、平板计算机、笔记本计算机、音乐播放器、电子书阅读器、膝上型或台式计算机、pda、智能电话或其它固定或便携式设备。附加地,这些引擎中的两个或更多个可以被实现在相同计算设备上或者在不同的计算设备上。
本说明书中所描述的过程和逻辑流程能够由执行一个或多个计算机程序的一个或多个可编程处理器来执行以通过对输入数据进行操作并且生成输出来执行功能。过程和逻辑流程还能够由专用逻辑电路来执行,并且装置还能够作为专用逻辑电路被实现,所述专用逻辑电路例如fpga(现场可编程门阵列)或asic(专用集成电路)。
作为示例,适合于执行计算机程序的计算机能够基于通用微处理器或专用微处理器或两者,或任何其它类型的中央处理单元。一般地,中央处理单元将从只读存储器或随机存取存储器或两者接收指令和数据。计算机的必要元素是用于执行或者实行指令的中央处理单元以及用于存储指令和数据的一个或多个存储器设备。一般地,计算机还将包括或者在操作上耦合以从用于存储数据的一个或多个大容量存储设备(例如,磁盘、磁光盘或光盘)接收数据或者向一个或多个大容量存储设备转移数据或两者。然而,计算机不必具有这些设备。而且,能够将计算机嵌入在另一设备(例如,移动电话、个人数字助理(pda)、移动音频或视频播放器、游戏机、全球定位系统(gps)接收器或便携式存储设备(例如,通用串行总线(usb)闪存驱动器)等等)中。
适合于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储器设备,作为示例包括:半导体存储器设备,例如,eprom、eeprom和闪速存储器设备;磁盘,例如,内部硬盘或可移除盘;磁光盘;以及cd-rom和dvd-rom盘。处理器和存储器能够由专用逻辑电路补充或者并入专用逻辑电路。
本说明书中所描述的各种系统或者它们的各部分的控制能够用包括被存储在一个或多个非暂时性机器可读存储介质上的指令并且可在一个或多个处理设备上执行的计算机程序来实现。本说明书中所描述的系统或它们的各部分能够各自作为装置、方法或可以包括一个或多个处理设备和存储器以存储可执行指令来执行本说明书中所描述的操作的电子系统被实现。
为了提供与用户的交互,能够将本说明书中所描述的主题的实施例实现在具有用于向用户显示信息的显示设备(例如,crt(阴极射线管)或lcd(液晶显示)监视器)以及用户能够用来向计算机提供输入的键盘和指针设备(例如,鼠标、轨迹球或触摸板)的计算机上。其它类型的设备也能够被用来提供与用户交互;例如,提供给用户的反馈可以是任何形式的感觉反馈,例如,视觉反馈、听觉反馈或触觉反馈;并且能够以包括声输入、语音输入或触觉输入的任何形式接收来自用户的输入。此外,计算机可能通过向由用户使用的设备发送文档并且从由用户使用的设备接收文档(例如,通过响应于从web浏览器接收的请求而向用户的客户端设备上的web浏览器发送web页面)来与用户交互。
本说明书中所描述的主题的实施例能够被实现在计算系统中,该计算系统包括后端组件(例如,作为数据服务器),或者其包括中间件组件(例如,应用服务器),或者其包括前端组件(例如,具有用户能够用来与本说明书中所描述的主题的实施方式交互的图形用户界面或web浏览器的客户端计算机),或一个或多个这种后端组件、中间件组件或前端组件的任何组合。本系统的组件能够通过任何形式或介质的数字数据通信(例如,通信网络)来互连。通信网络的示例包括局域网(“lan”)和广域网(“wan”),例如,互联网。
计算系统能够包括客户端和服务器。客户端和服务器一般地彼此远离并且通常通过通信网络交互。客户端和服务器的关系借助于在相应计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生。
除所附实施例以及以上所描述的实施例的实施例之外,以下实施例也是创新的:
实施例1是一种方法,所述方法包括:
由流处理系统的第一多个第一本地建模器接收事件的事件流,其中每个第一本地建模器接收所述事件的相应部分,并且其中所述第一本地建模器在一个或多个计算机的系统上执行;
由每个第一本地建模器并行地处理由该第一本地建模器接收的事件,包括聚合每个接收的事件所关联的信息以生成聚合信息;
由一个或多个第一本地建模器向在一个或多个计算机的系统上执行的第一中心建模器提供由所述一个或多个第一本地建模器生成的聚合信息;以及
由所述第一中心建模器使用所接收的聚合信息确定第一机器学习模型的参数。
实施例2是根据实施例1所述的方法,其中:
将所述聚合信息提供给所述第一中心建模器包括将所述聚合信息异步地提供给所述第一中心建模器;并且
每个第一本地建模器从在一个或多个计算机的系统上执行的路由器接收所述事件的相应部分。
实施例3是根据权利要求1所述的方法,其中提供由一个或多个所述第一本地建模器生成的聚合信息包括,由所述第一本地建模器中的每一个:
确定所述本地建模器已处理阈值数目的事件并且然后作为结果向所述第一中心建模器提供由所述本地建模器生成的聚合信息。
实施例4是根据权利要求1所述的方法,其中所述第一中心建模器是作为分布式处理系统在一个或多个计算机的系统上执行的多个中心建模器中的一个。
实施例5是根据权利要求1所述的实施例,包括:
由所述第一中心建模器接收指定学习程序的数据,学习程序用于根据聚合信息确定所述第一机器学习模型的参数;以及
由所述第一中心建模器通过对由所述第一中心建模器接收的聚合信息执行所述学习程序来确定所述第一机器学习模型的参数。
实施例6是根据权利要求1所述的方法,进一步包括:
由所述第一中心建模器将所述第一机器学习模型的参数提供给在一个或多个计算机的系统上执行的第二中心建模器。
实施例7是根据权利要求6所述的实施例,其中将所述第一机器学习模型的参数提供给所述第二中心建模器包括:
由所述第一中心建模器确定要将所述参数提供给所述第二中心建模器。
实施例8是根据权利要求6所述的实施例,其中将所述第一机器学习模型的参数提供给所述第二中心建模器包括:
响应于从所述第二中心建模器接收到对提供参数的请求而提供所述参数。
实施例9是根据权利要求6所述的实施例,进一步包括:
由所述第二中心建模器从所述第一中心建模器接收所述第一机器学习模型的参数;
由所述第二中心建模器获得外部数据;以及
由所述第二中心建模器使用所述外部数据和从所述第一中心建模器接收的所述参数确定第二机器学习模型的参数。
实施例10是根据权利要求1所述的实施例,进一步包括:
由所述第一中心建模器将所述第一机器学习模型的参数中的一个或多个提供给一个或多个第一本地建模器以用于存储;
由应用所述第一机器学习模型的所述一个或多个第一本地建模器处理由所述一个或多个第一本地建模器接收的事件,以执行所述事件流的评分并且生成经处理的事件;以及
由所述一个或多个第一本地建模器中的每一个聚合该本地建模器接收的每个事件所关联的信息以生成更新的聚合信息。
实施例11是根据权利要求10所述的实施例,进一步包括:
由所述一个或多个第一本地建模器将经处理的事件提供给所述流处理系统的第二多个第二本地建模器。
实施例12是根据权利要求10所述的实施例,进一步包括:
由所述第一本地建模器中的一个或多个向所述第一中心建模器提供更新的聚合信息;
由所述第一中心建模器使用更新的聚合信息确定与所述第一机器学习模型相关联的更新的参数;
由所述第一中心建模器确定要将更新的参数提供给第二中心建模器;以及
由所述第一中心建模器将更新的参数异步地提供给第二中心建模器以用于存储。
实施例13是根据权利要求12所述的实施例,其中确定要提供更新的参数包括:
由所述第一中心建模器确定一个或多个更新的参数与对应的先前确定的参数相差超过阈值量。
实施例14是一种方法,所述方法包括:
由一个或多个中心建模器中的第一中心建模器接收从多个本地建模器生成的相应聚合信息,其中所述多个本地建模器中的每一个执行流处理系统的第一操作集并且通过对事件的事件流的相应部分并行地操作来生成聚合信息,并且其中所述中心建模器和所述本地建模器在一个或多个计算机的系统上执行;
由所述第一中心建模器使用所接收的聚合信息确定与所述相应机器学习模型相关联的参数;以及
由所述第一中心建模器将所述参数提供给所述多个本地建模器中的每一个以用于存储,以便所述多个本地建模器在对所述事件流进行评分时使用。
实施例15是根据权利要求14所述的实施例,进一步包括:
由所述多个本地建模器执行所述事件流的评分以生成经处理的事件;以及
将经处理的事件提供给执行所述流处理系统的后续操作集的本地建模器。
实施例16是根据权利要求14所述的实施例,进一步包括:
在由所述第一中心建模器确定参数之后,将所确定的参数提供给与所述第一中心建模器通信的本地建模器。
实施例17是根据权利要求14所述的实施例,其中由所述第一中心建模器接收聚合信息包括:
从与所述第一中心建模器通信的本地建模器请求聚合信息。
实施例18是根据权利要求14所述的实施例,进一步包括:
从与所述第一中心建模器通信的一个或多个本地建模器接收聚合信息;
由所述第一中心建模器确定已经从超过第一阈值数目的本地建模器接收到聚合信息;以及
由所述第一中心建模器使用所接收的聚合信息确定与所述相应机器学习模型相关联的参数。
实施例19是根据权利要求14所述的实施例,其中所述一个或多个中心建模器包括多个中心建模器,所述方法包括:
对于所述多个中心建模器的一些中心建模器构成的集合中的每个中心建模器,其中所述集合的每个中心建模器与相应的多个本地建模器通信:
从与该中心建模器通信的所述相应的多个本地建模器中的一个或多个接收聚合信息;以及
使用所接收的聚合信息确定与相应机器学习模型相关联的参数。
实施例20是根据权利要求19所述的实施例,其中从与所述中心建模器通信的所述相应的多个本地建模器中的一个或多个接收聚合信息包括从各自执行所述流处理系统的相同操作集的本地建模器接收聚合信息。
实施例21是根据权利要求19所述的实施例,进一步包括:
对于中心建模器的集合中的每个中心建模器:
由该中心建模器向多个本地建模器中的每一个提供由所述中心建模器生成的参数以用于存储,其中接收到所生成的参数的所述本地建模器中的每一个根据由该本地建模器接收的参数来执行所述事件流的评分,以生成经处理的事件并且将经处理的事件提供给执行所述流处理系统的后续操作集的本地建模器。
实施例22是根据权利要求19所述的实施例,进一步包括:
由所述第一中心建模器向中心建模器的集合中的第二中心建模器提供所述相应机器学习模型的参数。
实施例23是根据权利要求19所述的实施例,进一步包括:
由所述多个中心建模器中的特定中心建模器向用户设备提供作为最终机器学习模型的相应机器学习模型的参数。
实施例24是根据权利要求19所述的实施例,进一步包括:
对于与所述第一中心建模器不同的第二中心建模器:
由所述第二中心建模器获得外部数据;
由所述第二中心建模器从所述第一中心建模器接收参数;以及
由所述第二中心建模器使用所述外部数据和所述参数确定与相应机器学习模型相关联的参数。
实施例25是根据权利要求24所述的实施例,进一步包括:
由包括在中心建模器的集合中的第三中心建模器从所述第二中心建模器接收参数;
由所述第三中心建模器从多个本地建模器中的每一个接收聚合信息;以及
由所述第三中心建模器使用所接收的聚合信息和从所述第二中心建模器接收的所述参数确定与相应机器学习模型相关联的参数。
实施例26是一种方法,所述方法包括:
由路由器接收事件的事件流,其中该路由器在一个或多个计算机的系统上执行;
由所述路由器针对每个事件来识别包括与所述事件有关的第一场境数据的第一场境数据的分区;
由所述路由器向流处理系统的第一多个本地建模器中的被识别为将针对所述事件识别的第一场境数据的分区存储在所述本地建模器的操作存储器中的本地建模器,并且其中所述本地建模器在一个或多个计算机的系统上执行;
由每个本地建模器并行地通过执行第一多个动作使用第一场境数据的相应分区中的所述第一场境数据来处理从所述路由器接收的事件,所述动作包括对与由所述本地建模器接收的每个事件相关联的信息进行聚合以生成聚合信息;
由所述本地建模器中的一个或多个向在一个或多个计算机的系统上执行的第一中心建模器提供由所述本地建模器中的所述一个或多个生成的相应聚合信息;以及
由所述第一中心建模器使用由所述第一中心建模器接收的所述聚合信息确定第一机器学习模型的多个参数。
实施例27是根据权利要求26所述的实施例,其中所述第一多个本地建模器中的第一本地建模器和第二本地建模器各自将第一场境数据的相同分区存储在操作存储器中。
实施例28是根据权利要求26所述的实施例,进一步包括:
在识别第一场境数据的分区之前,确定所述第一多个动作中的一个动作请求第一场境数据。
实施例29是根据权利要求26所述的实施例,其中:
对于每个本地建模器,实现所述第一多个动作的指令和第一场境数据的相应分区在相应操作系统进程中被存储在操作存储器中;以及
每个本地建模器在所述相应操作系统进程中根据通过执行所述第一多个动作来处理由所述本地建模器接收的事件。
实施例30是根据权利要求26所述的实施例,进一步包括:
由所述第一中心建模器将所述参数提供给所述第一多个本地建模器中的一个或多个以用于存储。
实施例31是根据权利要求26所述的实施例,进一步包括:
由应用所述第一机器学习模型的所述第一多个本地建模器中的一个或多个中的每一个处理由所述本地建模器接收的所述事件以执行所述事件流的评分;以及
由所述第一多个本地建模器中的一个或多个中的每一个对与由所述本地建模器接收的每个事件相关联的信息进行聚合以生成更新的聚合信息。
实施例32是根据权利要求26所述的实施例,其中识别包括与事件有关的场境数据的场境数据的分区包括:
获得包括在所述事件中的识别第一信息类型的信息;
获得包括在所述事件中的与所述第一信息类型相关联的数据;以及
使用所获得的数据执行散列过程以识别所述分区。
实施例33是根据权利要求26所述的实施例,其中所述路由器是第一路由器,所述方法进一步包括:
由所述第一多个本地建模器向与所述第一路由器不同的第二路由器提供经处理的事件;
由所述第二路由器针对每个经处理的事件来识别包括与经处理的事件有关的场境数据的第二场境数据的分区;以及
由所述第二路由器向所述流处理系统的第二多个本地建模器的相应本地建模器提供每个经处理的事件,其中所述相应本地建模器是将针对经处理的事件识别的第二场境数据的分区存储在所述本地建模器的操作存储器中的本地建模器,并且其中所述第二多个本地建模器中的所述本地建模器在一个或多个计算机的系统上执行。
实施例34是根据权利要求33所述的实施例,进一步包括:
由所述第二多个本地建模器中的每个本地建模器通过执行第二多个动作使用第二场境数据的相应分区中的所述第二场境数据来处理从所述第二路由器接收的事件。
实施例35是根据权利要求26所述的实施例,其中所述路由器是第一路由器,所述方法进一步包括:
由所述第一多个本地建模器向与所述第一路由器不同的第二路由器提供经处理的事件,其中经处理的事件包括由所述第一多个本地建模器中的本地建模器添加的进一步的信息;以及
由所述第二路由器针对每个经处理的事件使用添加到经处理的事件的所述进一步的信息识别所述流处理系统的第二多个本地建模器的相应本地建模器,其中所述第二多个本地建模器中的所述本地建模器在一个或多个计算机的系统上执行。
实施例36是根据权利要求35所述的实施例,其中所述进一步的信息是对相应事件进行分类的标记。
实施例37是根据权利要求26所述的实施例,包括:
由所述第一多个本地建模器中的一个或多个本地建模器向在所述系统上执行的第二中心建模器提供由所述第一多个本地建模器中的一个或多个建模器生成的聚合信息;以及
由所述第二中心建模器使用由所述第二中心建模器接收的所述聚合信息确定第二机器学习模型的参数。
实施例38是根据权利要求37所述的实施例,包括:
由所述第一中心建模器接收指定用于根据由所述第一中心建模器接收的聚合信息确定所述第一机器学习模型的参数的第一学习程序的数据;以及
由所述第二中心建模器接收指定用于根据由所述第二中心建模器接收的聚合信息确定第三机器学习模型的参数的第三学习程序的数据。
实施例39是根据权利要求26所述的实施例,其中:
场境数据是与事件有关的未出现在该事件它本身的数据属性内的原有数据。
实施例40是根据权利要求26所述的实施例,其中:
对于每个本地建模器,实现所述第一多个动作的指令和第一场境数据的相应分区在相应操作系统进程中被存储在操作存储器中;
对于每个本地建模器,公共场境数据在每个相应操作系统进程中被存储在操作存储器中;并且
每个本地建模器在所述相应操作系统进程中通过使用第一场境数据的相应分区和所述公共场境数据执行所述第一多个动作来处理由所述本地建模器接收的事件。
实施例41是一种方法,所述方法包括:
由路由器接收事件的事件流,其中该路由器在一个或多个计算机的系统上执行;
由所述路由器根据包括在每个事件中的识别本地建模器的路由键向流处理系统的第一多个本地建模器的相应本地建模器提供每个事件,其中所述本地建模器在一个或多个计算机的系统上执行;
由每个本地建模器并行地通过执行包括对与由所述本地建模器接收的每个事件相关联的信息进行聚合以生成聚合信息的第一多个动作来处理从所述路由器接收的事件;
由所述本地建模器中的一个或多个向在一个或多个计算机的系统上执行的第一中心建模器提供由所述本地建模器中的所述一个或多个生成的相应聚合信息;以及
由所述第一中心建模器使用由所述第一中心建模器接收的所述聚合信息确定第一机器学习模型的多个参数。
实施例42是根据权利要求41所述的实施例,其中:
用于每个事件的所述路由键识别所述相应本地建模器。
实施例43是根据权利要求41所述的实施例,进一步包括:
由所述路由器访问路由键的范围与存储与范围中包括的路由键有关的场境数据的场境数据的相应分区之间的映射;以及
针对每个事件将所述第一多个本地建模器中的存储通过所述事件的路由键的映射所识别的场境数据的分区的本地建模器识别为所述相应本地建模器。
实施例44是根据权利要求41所述的实施例,进一步包括,针对每个事件:
对包括在所述事件中的所述路由键进行散列以获得场境数据的分区的标识符;以及
将所述第一多个本地建模器中的存储通过所述标识符所识别的场境数据的分区的本地建模器识别为所述相应本地建模器。
实施例45是一种方法,所述方法包括:
由在一个或多个计算机的系统上执行的路由器接收事件流的事件;
由所述路由器向由所述路由器根据初始路由策略选择的相应本地建模器提供每个事件,所述相应本地建模器是从在所述系统上执行的多个本地建模器中选择的;
由每个本地建模器并行地根据第一多个操作处理从所述路由器接收的事件,其中所述操作包括对与每个事件相关联的信息进行聚合以生成聚合信息;
向在所述系统上执行的中心建模器提供由所述本地建模器中的一个或多个生成的聚合信息,该中心建模器是在所述系统上执行的多个中心建模器中的一个;
由所述中心建模器使用由所述中心建模器接收的所述聚合信息确定机器学习模型的多个参数;
由所述中心建模器基于所述机器学习模型的参数中的一个或多个生成经更新的路由策略;
由所述中心建模器将经更新的路由策略提供给所述路由器;以及然后
由所述路由器根据经更新的路由策略路由所述事件流的后续事件。
实施例46是根据权利要求45所述的实施例,进一步包括:
由所述中心建模器在确定所述机器学习模型的所述多个参数的过程中确定相应本地建模器应该接收所述事件流的事件的特定子总体并且对与该子总体相关联的信息进行聚合;
由所述中心建模器生成经更新的路由策略以指定应该根据所述子总体路由事件;
由所述中心建模器从对所述事件流的子总体进行聚合的本地建模器接收聚合信息;以及
由所述中心建模器针对每个子总体确定机器学习模型的相应参数。
实施例47是根据权利要求46所述的实施例,进一步包括:
由所述中心建模器通过执行聚类过程确定所述事件流的子总体。
实施例48是根据权利要求47所述的实施例,其中所述聚类过程是识别事件的聚类或各自定中心在多个均值中的一个附近的事件的混合物的k均值聚类过程或混合模型过程。
实施例49是根据权利要求46所述的实施例,进一步包括:
由所述中心建模器通过获得识别两个或更多个预定义配置的信息来确定所述事件流的子总体,其中每个配置识别特定路由策略;
由所述中心建模器执行每个特定路由策略以识别所述预定义配置中的最好地确定事件的聚类的配置;以及
由所述中心建模器将所述特定路由策略提供给所述路由器作为用于路由事件的经更新的路由策略。
实施例50是根据权利要求45所述的实施例,其中经更新的路由策略通过定义每个事件的数据元组中的一个或多个数据元素来指定所述路由器应该路由事件。
实施例51是根据权利要求45所述的实施例,进一步包括:
在将经更新的路由策略提供给所述路由器之后,由所述中心建模器从所述多个本地建模器中的一个或多个本地建模器接收聚合信息;
由所述中心建模器使用来自所述多个本地建模器的第一子集的聚合信息确定与所述机器学习模型相关联的第一参数;以及
由所述中心建模器使用来自所述多个本地建模器的第二不同子集的聚合信息确定与所述机器学习模型相关联的第二参数。
实施例52是根据权利要求51所述的实施例,进一步包括:
由所述中心建模器将所述第一参数提供给本地建模器的第一子集以用于存储;以及
由所述中心建模器将所述第二参数提供给本地建模器的第二子集以用于存储。
实施例53是根据权利要求45所述的实施例,进一步包括:
由所述中心建模器根据经更新的路由策略确定应该被存储在所述本地建模器中的每一个的操作存储器中的相应场境数据;以及
由所述本地建模器中的每一个获得所述相应场境数据以用于存储在所述本地建模器的操作存储器中。
实施例54是根据权利要求53所述的实施例,进一步包括:
由所述本地建模器中的每一个从一个或多个其它本地建模器或者从具有所有所述场境数据的存储系统获得所述相应场境数据。
实施例55是一种方法,所述方法包括:
接收各自由多个第一本地建模器中的一个并且由多个第二本地建模器中的一个经处理的事件流的事件,其中所述第一本地建模器和所述第二本地建模器各自在一个或多个计算机的系统上执行;
由每个第一本地建模器对与由所述第一本地建模器接收的每个事件相关联的信息进行聚合以生成相应的第一本地聚合信息;
由每个第二本地建模器对与由所述第二本地建模器接收的每个事件相关联的信息进行聚合以生成相应的第二本地聚合信息;
由所述第一本地建模器中的一个或多个向第一中心建模器提供由所述一个或多个第一本地建模器生成的第一本地聚合信息;
由所述第二本地建模器中的一个或多个向第二中心建模器提供由所述一个或多个第二本地建模器生成的第二本地聚合信息,其中所述第一中心建模器和所述第二中心建模器在一个或多个计算机的系统上执行;
由所述第一中心建模器和所述第二中心建模器分别对分别由所述第一中心建模器和所述第二中心建模器接收的本地聚合信息进行聚合,以分别生成第一中心聚合信息和第二中心聚合信息;
其中由所述第一本地建模器或所述第二中心建模器或两者聚合是根据第一学习速率参数完成的并且由所述第二本地建模器或所述第一中心建模器或两者聚合是根据与所述第一学习速率参数不同的第二学习速率参数完成的,其中每个学习速率参数指定待应用于与事件相关联的聚合信息的一个或多个相应权重;
由所述第一中心建模器使用所述第一中心聚合信息确定机器学习模型的第一参数;
由所述第二中心建模器使用所述第二中心聚合信息确定所述机器学习模型的第二参数;以及
确定所述第一参数与所述第二参数之间的差异确定该差异大于阈值量并且结果输出识别所述事件流中的趋势改变的信息。
实施例56是根据权利要求55所述的实施例,其中:
识别所述趋势改变的所述信息包括所述第一参数和所述第二参数中的相差超过阈值量的一个或多个参数的识别。
实施例57是根据权利要求55所述的实施例,其中:
每个事件具有时间戳;并且
所述第一学习速率参数和所述第二学习速率参数分别各自指定考虑到所述事件的时间戳输出待应用于与事件相关联的信息的权重的第一函数和不同的第二函数。
实施例58是根据权利要求57所述的实施例,其中所述第一函数和所述第二函数分别由所述第一本地建模器和所述第二本地建模器应用。
实施例59是根据权利要求58所述的实施例,其中所述第一本地建模器比所述第二本地建模器对较旧事件进行更低地加权。
实施例60是根据权利要求58所述的实施例,其中所述第一本地建模器比所述第二本地建模器对较旧事件进行更高地加权。
实施例61是根据权利要求55所述的实施例,其中:
所述第一中心建模器和所述第二中心建模器根据所述第一学习速率参数和所述第二学习速率参数来确定所述第一参数和所述第二参数以表示所述机器学习模型在相应不同的时间点的参数。
实施例62是根据权利要求55所述的实施例,其中:
确定所述第一参数与所述第二参数之间的差异包括确定所述第一参数与所述第二参数之间的l1-范数或l2-范数差异。
实施例63是一种方法,所述方法包括:
从处理事件流的第一系统生成机器学习模型的第一参数集,该第一系统包括从第一多个本地建模器接收聚合信息的第一中心建模器;
从处理事件流的第二系统生成机器学习模型的第二参数集,该第二系统包括从第二多个本地建模器接收聚合信息的第二中心建模器;
确定所述第一参数集与所述第二参数集之间的差异;以及
确定所述差异大于阈值量并且结果输出识别所述事件流中的趋势改变的信息。
实施例64是根据权利要求63所述的实施例,其中:
所述第一参数集和所述第二参数集表示所述机器学习模型在不同的时间点的参数。
实施例65是根据权利要求63所述的实施例,其中:
确定所述第一参数集与所述第二参数集之间的差异包括确定所述第一参数与所述第二参数之间的l1-范数或l2-范数差异。
实施例66是根据权利要求63所述的实施例,其中:
识别所述趋势改变的所述信息包括所述第一参数和所述第二参数中的相差超过阈值量的一个或多个参数的识别。
实施例67是根据权利要求63所述的实施例,其中:
所述第一系统和所述第二系统分别根据第一学习速率参数和不同的第二学习速率参数操作。
实施例68是一种方法,所述方法包括:
由流处理系统的第一多个第一本地建模器接收第一事件的事件流,其中每个第一本地建模器接收所述第一事件的相应部分,并且其中所述第一本地建模器在一个或多个计算机的系统上执行;
由每个第一本地建模器并行地处理由所述第一本地建模器接收的事件,包括(i)对与每个接收的事件相关联的信息进行聚合以生成第一聚合信息,并且(ii)生成经处理的事件;
由所述流处理系统的第二多个第二本地建模器接收由第一本地建模器生成的经处理的事件的事件流,其中每个第二本地建模器接收经处理的事件的相应部分,并且其中所述第二本地建模器在一个或多个计算机的系统上执行;
由每个第二本地建模器并行地处理由所述第二本地建模器接收的经处理的事件,包括对与每个接收的经处理的事件相关联的信息进行聚合以生成第二聚合信息;
由所述第一本地建模器中的一个或多个向在一个或多个计算机的系统上执行的第一中心建模器提供第一聚合信息;
由所述第二本地建模器中的一个或多个向所述第一中心建模器提供第二聚合信息;以及
由所述第一中心建模器使用由所述第一中心建模器接收的聚合信息确定第一机器学习模型的第一参数。
实施例69是根据权利要求68所述的实施例,其中:
将所述第一聚合信息提供给所述第一中心建模器包括将所述聚合信息异步地提供给所述第一中心建模器;并且
每个第一本地建模器从在一个或多个计算机的系统上执行的路由器接收所述事件的相应部分。
实施例70是根据权利要求68所述的实施例,其中提供所述第一聚合信息包括由所述第一本地建模器中的每一个:
确定所述本地建模器已处理阈值数目的事件并且然后结果向所述第一中心建模器提供由所述本地建模器生成的第一聚合信息。
实施例71是根据权利要求68所述的实施例,包括:
由所述第一中心建模器接收指定用于根据聚合信息确定所述第一机器学习模型的参数的学习程序的数据;以及
由所述第一中心建模器通过对由所述第一中心建模器接收的聚合信息执行所述学习程序来确定所述第一机器学习模型的参数。
实施例72是根据权利要求68所述的实施例,进一步包括:
由所述第一中心建模器将所述第一机器学习模型的参数提供给在一个或多个计算机的系统上执行的第二中心建模器。
实施例73是根据权利要求72所述的实施例,进一步包括:
由所述第二中心建模器从所述第一中心建模器接收所述第一机器学习模型的参数;
由所述第二中心建模器获得外部数据;以及
由所述第二中心建模器使用所述外部数据和从所述第一中心建模器接收的所述参数确定第二机器学习模型的参数。
实施例74是根据权利要求68所述的实施例,进一步包括:
由所述第一中心建模器将所述第一机器学习模型的参数中的一个或多个提供给一个或多个第一本地建模器以用于存储;
由应用所述第一机器学习模型的所述一个或多个第一本地建模器处理由所述一个或多个第一本地建模器随后接收的第一事件,以执行第一事件的事件流的评分并且生成经处理的事件;以及
由所述一个或多个第一本地建模器中的每一个对与由所述本地建模器随后接收的每个第一事件相关联的信息进行聚合以生成第一经更新的聚合信息。
实施例75是根据权利要求74所述的实施例,进一步包括:
由所述第一本地建模器中的一个或多个向所述第一中心建模器提供第一经更新的聚合信息;
由所述第一中心建模器使用第一经更新的聚合信息确定与所述第一机器学习模型相关联的经更新的参数;以及
由所述第一中心建模器将所述第一机器学习模型的经更新的参数中的一个或多个提供给一个或多个第一本地建模器以用于存储。
实施例76是根据权利要求75所述的实施例,进一步包括:
由所述第一中心建模器确定所述第一机器学习模型的一个或多个经更新的参数与对应的先前确定的参数相差超过阈值量。
实施例77是根据权利要求68所述的实施例,进一步包括:
由所述第一本地建模器中的一个或多个第一本地建模器向在一个或多个计算机的系统上执行的第三中心建模器提供由所述一个或多个第一本地建模器生成的第一聚合信息;以及
由所述第三中心建模器使用由所述第三中心建模器接收的所述第一聚合信息确定第三机器学习模型的第三参数。
实施例78是根据权利要求77所述的实施例,包括:
由所述第一中心建模器接收指定用于根据由所述第一中心建模器接收的聚合信息确定所述第一机器学习模型的第一参数的第一学习程序的数据;以及
由所述第三中心建模器接收指定用于根据由所述第三中心建模器接收的聚合信息确定所述第三机器学习模型的第三参数的第三学习程序的数据。
实施例79是根据权利要求77所述的实施例,进一步包括:
由所述流处理系统的第三多个第三本地建模器接收第三事件的事件流,其中每个第三本地建模器接收所述第三事件的相应部分,并且其中所述第三本地建模器在一个或多个计算机的系统上执行;
由每个第三本地建模器并行地处理由该第三本地建模器接收的第三事件,包括对与每个接收的事件相关联的信息进行聚合以生成第三聚合信息;
由所述第三本地建模器中的一个或多个向所述第一中心建模器提供第三聚合信息;以及
由所述第三本地建模器中的一个或多个向所述第三中心建模器提供第三聚合信息。
实施例80是根据权利要求79所述的实施例,进一步包括:
向一个或多个第一本地建模器提供所述第三机器学习模型的一个或多个第三参数以用于存储;以及
向一个或多个第三本地建模器提供所述第三机器学习模型的一个或多个第三参数以用于存储。
实施例81是根据权利要求79所述的实施例,进一步包括:
向所述第一中心建模器提供所述第三机器学习模型的一个或多个第三参数;以及
由所述第一中心建模器使用由所述第一中心建模器接收的聚合信息以及由所述第一中心建模器接收的一个或多个机器学习参数确定所述第一机器学习模型的第一参数。
实施例82是一种方法,所述方法包括:
由第一中心建模器接收由第一多个第一本地建模器生成的相应的第一聚合信息,其中所述第一本地建模器中的每一个执行第一流处理操作集并且通过并行地对第一事件的事件流的相应部分操作来生成相应的第一聚合信息,并且其中所述第一中心建模器和所述第一本地建模器在一个或多个计算机的系统上执行;
由所述第一中心建模器接收由第二多个第二本地建模器生成的相应的第二聚合信息,其中所述第二本地建模器中的每一个执行第二流处理操作集并且通过并行地对第二事件的事件流的相应部分操作来生成相应的第二聚合信息,并且其中所述第二本地建模器在一个或多个计算机的系统上执行;
由所述第一中心建模器使用由所述第一中心建模器从第一本地建模器和第二本地建模器接收的所述聚合信息确定与第一机器学习模型相关联的一个或多个第一参数;以及
由所述第一中心建模器将所述一个或多个第一参数提供给所述第一本地建模器、所述第二本地建模器或所述第一本地建模器和所述第二本地建模器两者以用于存储。
实施例83是根据权利要求82所述的实施例,其中由所述第一中心建模器提供所述第一或多个第一参数以用于存储包括提供所述参数以便本地建模器在对事件进行评分时使用。
实施例84是根据权利要求82所述的实施例,进一步包括:
由所述第一本地建模器生成第二事件的事件流。
实施例85是根据权利要求82所述的实施例,其中由所述第一中心建模器接收聚合信息包括:
从与所述第一中心建模器通信的本地建模器请求聚合信息。
实施例86是根据权利要求82所述的实施例,进一步包括:
由所述第一中心建模器确定已经从超过第一阈值数目的本地建模器接收到聚合信息;以及
由所述第一中心建模器在由所述第一中心建模器确定已经从超过第一阈值数目的本地建模器接收到聚合信息之后确定与相应机器学习模型相关联的参数。
实施例87是根据权利要求82所述的实施例,进一步包括:
由第二中心建模器接收由所述第一本地建模器生成的相应的第一聚合信息,其中所述第二中心建模器在一个或多个计算机的系统上执行;
由所述第二中心建模器接收由所述第二本地建模器生成的相应的第二聚合信息;
由所述第二中心建模器使用由所述第二中心建模器从第一本地建模器和第二本地建模器接收的所述聚合信息来确定与第二机器学习模型相关联的一个或多个第二参数;以及
由所述第二中心建模器将所述第二参数提供给所述第一本地建模器、所述第二本地建模器或所述第一本地建模器和所述第二本地建模器两者以用于存储。
实施例88是根据权利要求87所述的实施例,其中由所述第二中心建模器提供第二参数以用于存储包括提供所述参数以便本地建模器在对事件进行评分时使用。
实施例89是根据权利要求87所述的实施例,进一步包括:
由所述第二本地建模器从所述第二中心建模器接收第二参数;以及
由所述第二本地建模器根据由所述第二本地建模器接收的所述第二参数生成经处理的事件,并且将经处理的事件提供给执行后续操作集的本地建模器。
实施例90是根据权利要求87所述的实施例,进一步包括:
由所述第一中心建模器向所述第二中心建模器提供所述第一机器学习模型的一个或多个第一参数。
实施例91是根据权利要求87所述的实施例,进一步包括:
由在一个或多个计算机的系统上执行的特定中心建模器向用户设备提供作为最终机器学习模型的相应机器学习模型的参数。
实施例92是根据权利要求87所述的实施例,进一步包括:
由所述第二中心建模器获得外部数据;
由所述第二中心建模器从所述第一中心建模器接收参数;以及
由所述第二中心建模器使用所述外部数据和从所述第一本地建模器接收的所述第一参数确定与所述第二机器学习模型相关联的所述一个或多个第二参数。
实施例93是一种系统,所述系统包括:一个或多个计算机以及存储指令的一个或多个存储设备,所述指令当由所述一个或多个计算机执行时,可操作来使所述一个或多个计算机执行根据实施例1至92中的任一项所述的方法。
实施例94是一种编码有计算机程序的计算机存储介质,该程序包括当由数据处理装置执行时可操作来使该数据处理装置执行根据实施例1至92中的任一项所述的方法的指令。
虽然本说明书包含许多特定实施方式细节,但是这些不应该被解释为对任何发明的范围或可能要求保护的范围构成限制,而是相反被解释为可能特定于特定发明的特定实施例的特征的描述。还能够在单个实施例中相结合地实现在本说明书中在单独的实施例背景下描述的特定特征。相反地,还能够单独地在多个实施例中或者在任何适合的子组合中实现在单个实施例背景下描述的各种特征。而且,尽管特征可以被以上描述为在特定组合中行动并且还甚至最初要求保护,然而来自要求保护的组合的一个或多个特征能够在一些情况下被从组合中删除,并且所要求保护的组合可以针对子组合或子组合的变化。
类似地,虽然按照特定次序在附图中描绘操作,但是这不应该被理解为要求这些操作被以所示出的特定次序或以顺序次序执行,或者要求执行所有图示的操作,以实现所希望的结果。在特定情况下,多任务处理和并行处理可能是有利的。而且,在以上所描述的实施例中使各种系统模块和组件分离不应该被理解为在所有实施例中要求这种分离,并且应该理解,所描述的程序组件和系统一般地能够被一起集成在单个软件产品中或者封装到多个软件产品中。
已经描述了本主题的特定实施例。其它实施例在以下权利要求的范围内。例如,权利要求中所记载的动作能够被以不同的次序执行并且仍然实现所希望的结果。作为一个示例,附图中所描绘的过程未必要求所示出的特定次序或顺序次序,以实现所希望的结果。在特定实施方式中,多任务处理和并行处理可能是有利的。
- 还没有人留言评论。精彩留言会获得点赞!