用于推测性编译器优化的轻量级受限事务存储器的制作方法
本公开属于处理逻辑、微处理器、和相关联的指令集架构的领域,所述相关联的指令集在被处理器或者其他处理逻辑执行时执行逻辑、数学、或者其他函数运算。
背景技术:
锁定是一种用于在多处理器系统中管理共享数据访问的常用解决方案。锁定将数据访问串行化,这保持数据完整性,但是可能降低整体性能。推测性锁定省略(speculativelockelision,sle)可以被用于减少由并发进程导致的不必要串行化,所述并发进程需要访问相同锁相关变量或者必须等待相同锁队列。sle依赖于如下特性动态地移除不必要的由锁引起的串行化,即:对于正确执行而言,锁不总是必须被取得。测试或者设置锁的同步指令被推测性地绕过(例如,被省略)。这允许多个线程并发地执行由相同锁保护的临界区段,而不必实际取得锁。由于线程间数据冲突造成的丢失的推测可以被检测,并且推测性指令可以通过恢复机制被回滚(rolledback)。成功的推测性省略然后可以被生效和提交,而不取得锁。
附图说明
在附图的图中,用示例而不是限制的方式图示了实施例,在附图中:
图1a是图示按照实施例的示范性有序提取、解码、引退(retire)管线和示范性寄存器重命名、无序发布/执行管线两者的框图;
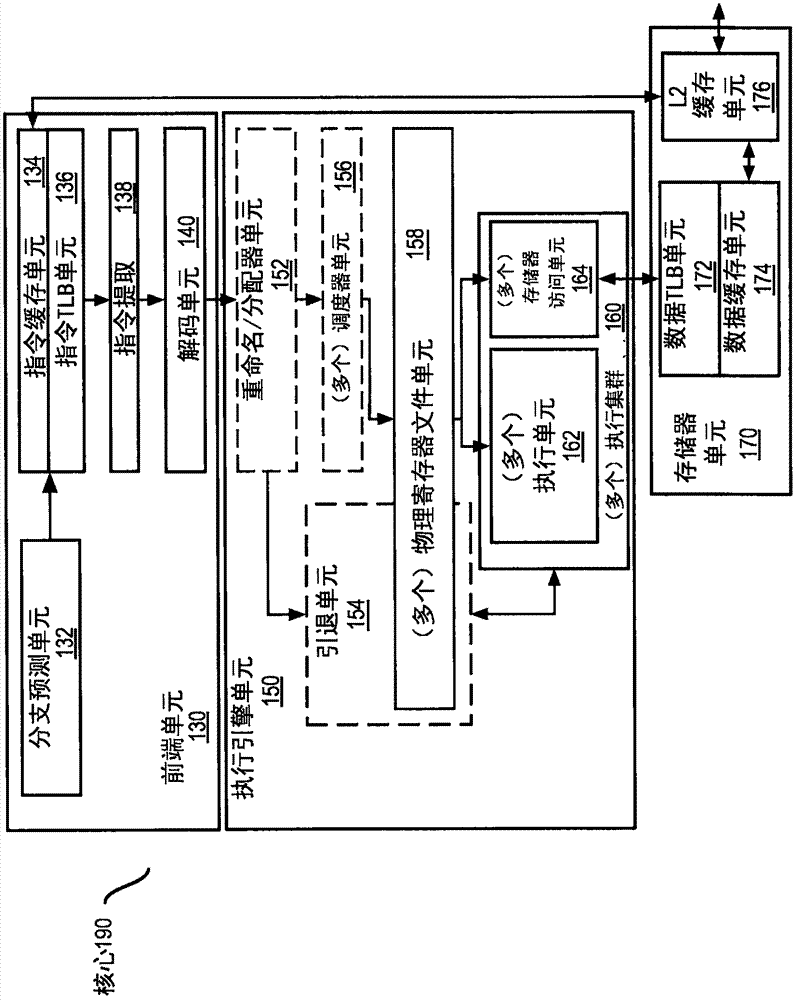
图1b是图示有序提取、解码、引退核心的示范性实施例和按照实施例要被包括在处理器中的示范性寄存器重命名、无序发布/执行架构核心两者的框图;
图2a-b是更具体的示范性有序核心架构的框图;
图3是具有集成存储器控制器和专用逻辑的单核心处理器和多核心处理器的框图;
图4图示按照一个实施例的系统的框图;
图5图示按照一个实施例的第二系统的框图;
图6图示按照一个实施例的第三系统的框图;
图7图示按照一个实施例的芯片上系统(soc)的框图;
图8图示按照实施例的对比软件指令转换器的使用的框图,该软件指令转换器用于将源指令集中的二进制指令转换成目标指令集中的二进制指令;
图9是示范性处理器的框图,在该示范性处理器中可以实施实施例;
图10是按照一个实施例的被配置成存储用于受限事务存储器实施方案的推测性数据的缓存的框图;
图11是图示用于实施优化编译器的数据处理系统的框图;
图12是按照一个实施例的用于利用事务存储器区域优化程序代码的逻辑的流程图;
图13是按照一个实施例的用于利用一个或者多个事务存储器区域优化程序代码的逻辑的流程图;
图14是按照一个实施例的包括轻量级rtm实施方案的处理系统的框图;
图15是按照一个实施例的用于处理轻量级rtm指令的逻辑的流程图;
图16a-b是图示按照实施例的通用矢量友好指令格式及其指令模板的框图;
图17a-d是图示按照本发明的实施例的示范性具体矢量友好指令格式的框图;以及
图18是按照一个实施例的寄存器架构的框图。
具体实施方式
sle可以使用受限事务存储器(rtm)的硬件实施方案来实施。rtm为代码区域(被称为rtm区域)提供推测性执行机制,使得区域执行可以在丢失推测的情况下被回滚。处理器可以使用任何数量的机制来实施rtm事务。在一个实施例中,处理器在对其他线程不可见的存储器的受限内部区域中执行推测性事务。如果与其他并发执行的线程不存在存储器冲突,则事务被原子地提交给全局可见的存储器。
除了推测性锁定省略之外,可以配置优化编译器以使用rtm来执行推测性编译器优化。例如,当频繁执行的循环被确定为是数据并行时,如果目标处理器架构包含矢量或者单指令多数据(simd)硬件,则优化编译器可以尝试将该循环矢量化。对于具有交叉迭代存储器相关性的循环,执行诸如循环矢量化之类的优化可能是不安全的。然而,本文中所描述的实施例利用rtm指令来实施推测性编译时间优化,所述推测性编译时间优化将由硬件在丢失推测的情况下自动地回滚。在一个实施例中,描述了用于推测性编译器优化的rtm的轻量级版本,其与当执行推测性编译器优化时所使用的常规rtm实施方案相比提供更低的操作开销。
按照实施例,以下描述了处理器核心架构,接着是示范性处理器和计算机架构、使用示范性rtm实施方案的编译器优化的描述、和轻量级rtm描述。阐述了许多具体细节,以便提供对以下描述的本发明的实施例的透彻理解。然而,对于本领域技术人员而言将显而易见的是,实施例可以在没有这些具体细节中的一些细节的情况下被实践。在其他实例中,众所周知的结构和设备以框图形式被示出,以避免使本发明的实施例的基本原理难理解。
处理器核心可以以不同方式、为了不同目的、并且在不同的处理器中实施。例如,这样的核心的实施方案可以包括:1)打算用于通用计算的通用有序核心;2)打算用于通用计算的高性能通用无序核心;3)主要打算用于图形和/或科学(吞吐量)计算的专用核心。不同处理器的实施方案可以包括:1)包括一个或者多个打算用于通用计算的通用有序核心和/或一个或者多个打算用于通用计算的通用无序核心的cpu;2)包括一个或者多个主要用于图形和/或科学的专用核心(例如,许多集成核心处理器)的协处理器。这样的不同的处理器导致不同计算机系统架构,所述计算机系统架构可以包括:1)在与cpu分开的芯片上的协处理器;2)在与cpu相同的封装中的单独管芯上的协处理器;3)在与cpu相同的管芯上的协处理器(在此情况下,这样的协处理器有时被称为专用逻辑、诸如集成图形和/或科学(吞吐量)逻辑,或者被称为专用核心);以及4)可以在同一管芯上包括所描述的cpu(有时被称为(多个)应用核心或者(多个)应用处理器)、以上描述的协处理器、和附加的功能的芯片上的系统。
示范性核心架构
有序和无序核心框图
图1a是按照一个实施例图示示范性有序管线和示范性寄存器重命名无序发布/执行管线的框图。图1b是图示有序架构核心的示范性实施例和按照一个实施例要被包括在处理器中的示范性寄存器重命名、无序发布/执行架构核心两者的框图。在图1a-b中的实线框图示有序管线和有序核心,而虚线框的可选附加图示寄存器重命名、无序发布/执行管线和核心。考虑到有序方面是无序方面的子集,将描述无序方面。
在图1a中,处理器管线100包括提取阶段102、长度解码阶段104、解码阶段106、分配阶段108、重命名阶段110、调度(也叫做分派或者发布)阶段112、寄存器读取/存储器读取阶段114、执行阶段116、写回/存储器写入阶段118、异常处理阶段122、和提交阶段124。
图1b示出处理器核心190,其包括耦合到执行引擎单元150的前端单元130,并且前端单元和执行引擎单元都耦合到存储器单元170。核心190可以是精简指令集计算(risc)核心、复杂指令集计算(cisc)核心、超长指令字(vlw)核心、或者混合或者替代核心类型。作为又一个选项,核心190可以是专用核心,诸如、例如网络或者通信核心、压缩引擎、协处理器核心、通用计算图形处理单元(gpgpu)核心、图形核心等等。
前端单元130包括耦合到指令缓存单元134的分支预测单元132,该指令缓存单元耦合到指令翻译后备缓冲器(tlb)136,该指令翻译后备缓冲器耦合到指令提取单元138,该指令提取单元耦合到解码单元140。解码单元140(或者解码器)可以对指令进行解码,并且作为输出生成一个或者多个微操作、微代码入口点、微指令、其他指令、或者其他控制信号,其从原始指令被解码、或者以其他方式反映原始指令、或者从原始指令导出。解码单元140可以使用各种不同机制来实施。合适的机制的示例包括、但不限于查找表、硬件实施方案、可编程逻辑阵列(pla)、微代码只读存储器(rom)等等。在一个实施例中,核心190包括微代码rom或者存储用于特定微指令的微代码的其他介质(例如,在解码单元140中或者以其他方式在前端单元130内)。解码单元140耦合到执行引擎单元150中的重命名/分配器单元152。
执行引擎单元150包括耦合到引退单元154和一个或者多个调度器单元156的集合的重命名/分配器单元152。(多个)调度器单元156表示任何数量的不同调度器,包括保留站、中央指令窗等等。(多个)调度器单元156耦合到(多个)物理寄存器文件单元158。物理寄存器文件单元158中的每一个表示一个或者多个物理寄存器文件,所述物理寄存器文件中的不同物理寄存器文件存储一个或者多个不同数据类型、诸如标量整数、标量浮点、紧缩整数(packedinteger)、紧缩浮点、矢量整数、矢量浮点、状态(例如,为要执行的下一指令的地址的指令指针)等等。在一个实施例中,物理寄存器文件单元158包括矢量寄存器单元、写屏蔽寄存器单元、和标量寄存器单元。这些寄存器单元可以提供架构的矢量寄存器、矢量屏蔽寄存器、和通用寄存器。(多个)物理寄存器文件单元158被引退单元154重叠,以图示各种方式,可以以所述各种方式实施寄存器重命名和无序执行(例如,使用(多个)重排序缓冲器和(多个)引退寄存器文件;使用(多个)未来文件、(多个)历史缓冲器、和(多个)引退寄存器文件;使用寄存器映射和寄存器池等等)。引退单元154和(多个)物理寄存器文件单元158耦合到(多个)执行集群160。(多个)执行集群160包括一个或者多个执行单元162的集合和一个或者多个存储器访问单元164的集合。执行单元162可以执行各种操作(例如,移位、加、减、乘)并且对各种类型的数据(例如,标量浮点、紧缩整数、紧缩浮点、矢量整数、矢量浮点)执行各种操作。虽然一些实施例可以包括专用于具体功能或者功能集合的若干执行单元,但是其他实施例可以仅包括一个执行单元或者全部都执行所有功能的多个执行单元。(多个)调度器单元156、(多个)物理寄存器文件单元158、和(多个)执行集群160被示出为可能是多个,因为某些实施例为特定类型的数据/操作创建单独的管线(例如,各自具有其自己的调度器单元、物理寄存器文件单元、和/或执行集群的标量整数管线、标量浮点/紧缩整数/紧缩浮点/矢量整数/矢量浮点管线、和/或存储器访问管线,并且在单独的存储器访问管线的情况下,实施特定实施例,在这些实施例中只有该管线的执行集群具有(多个)存储器访问单元164)。还应该理解,在使用单独的管线的情况下,这些管线中的一个或者多个可能是无序发布/执行的,并且剩余管线是有序的。
存储器访问单元164的集合耦合到存储器单元170,该存储器单元包括耦合到数据缓存单元174的数据tlb单元172,该数据缓存单元耦合到2级(l2)缓存单元176。在一个示范性实施例中,存储器访问单元164可以包括加载单元、存储地址单元、和存储数据单元,其中的每一个都耦合到存储器单元170中的数据tlb单元172。指令缓存单元134进一步耦合到存储器单元170中的2级(l2)缓存单元176。l2缓存单元176耦合到缓存的一个或者多个其他级,并且最终耦合到主存储器。
用示例的方式,示范性寄存器重命名无序发布/执行核心架构可以如下实施管线100:1)指令提取138执行提取和长度解码阶段102和104;2)解码单元140执行解码阶段106;3)重命名/分配器单元152执行分配阶段108和重命名阶段110;4)(多个)调度器单元156执行调度阶段112;5)(多个)物理寄存器文件单元158和存储器单元170执行寄存器读取/存储器读取阶段114;执行集群160执行执行阶段116;6)存储器单元170和(多个)物理寄存器文件单元158执行写回/存储器写入阶段118;7)各种单元可以参与异常处理阶段122;以及8)引退单元154和(多个)物理寄存器文件单元158执行提交阶段124。
核心190可以支持一个或者多个指令集(例如,x86指令集(具有已经随着更新版本添加的一些扩展);sunnyvale,ca的mipstechnologies的mips指令集;英国剑桥的armholdings的
应该理解,核心可以支持多线程(执行操作或者线程的两个或者更多个并行集合),并且可以以各种各样的方式这样做,包括时间切片多线程、同时多线程(其中单个物理核心为该物理核心正在同时多线程操作的线程中的每一个提供逻辑核心)、或者其组合(例如,时间切片提取和解码和此后同时多线程,诸如在
虽然在无序执行的上下文中描述了寄存器重命名,但是应该理解寄存器重命名可以在有序架构中使用。虽然处理器的所图示的实施例还包括单独的指令和数据缓存单元134/174和共享的l2缓存单元176,但是替代的实施例可以具有用于指令和数据两者的单个内部缓存,诸如例如1级(l1)内部缓存、或者多个级的内部缓存。在一些实施例中,系统可以包括内部缓存和在核心和/或处理器外部的外部缓存的组合。替代地,所有缓存都可以在核心和/或处理器外部。
具体示范性有序核心架构
图2a-b是更具体的示范性有序核心架构的框图,该核心将是芯片中的几个逻辑块(包括相同类型和/或不同类型的其他核心)之一。取决于应用,逻辑块通过高带宽互连网络(例如,环形网络)与某个固定功能逻辑、存储器i/o接口、和其他必要的i/o逻辑进行通信。
图2a是按照一个实施例的单个处理器核心连同其到管芯上互连网络202和与其2级(l2)缓存204的本地子集的连接的框图。在一个实施例中,指令解码器200支持具有紧缩数据指令集扩展的x86指令集。l1缓存206允许低延迟访问以将内存缓存到标量和矢量单元中。虽然在一个实施例中(为了简单起见设计),标量单元208和矢量单元210使用单独的寄存器集合(分别地,标量寄存器212和矢量寄存器214),并且在其之间传输的数据被写入到内存,并且然后从1级(l1)缓存206读回,但是替代实施例可以使用不同方法(例如,使用单个寄存器集合或者包括允许数据在不被写入和读回的情况下在两个寄存器文件之间传输的通信路径)。
l2缓存204的本地子集是全局l2缓存的一部分,该全局l2缓存被划分成单独的本地子集,每个处理器核心一个本地子集。每个处理器核心具有到l2缓存204的该处理器核心自己的本地子集的直接访问路径。由处理器核心读取的数据被存储在其l2缓存子集204中,并且可以与其他访问其自己的本地l2缓存子集的处理器核心并行地快速地被访问。由处理器核心所写入的数据被存储在该处理器核心自己的l2缓存子集204中,并且如果必要则从其他子集被刷新(flushed)。环形网络确保共享数据的一致性。环形网络是双向的,以允许代理(agents)(诸如处理器核心、l2缓存和其他逻辑块)在芯片内彼此通信。每个环形数据路径每个方向是1012位宽。
图2b是按照一个实施例的图2a中的处理器核心的一部分的展开图。图2b包括l1缓存204的l1数据缓存206a部分,以及关于矢量单元210和矢量寄存器214的更多细节。具体地,矢量单元210是16宽矢量处理单元(vpu)(参见16宽alu228),其执行整数、单精度浮点和双精度浮点指令中的一个或者多个。vpu支持利用拌和单元220拌和寄存器输入、利用数字转换单元222a-b的数字转换以及利用复制单元224对存储器输入的复制。写屏蔽寄存器226允许断定所产生的矢量写入。
具有集成存储器控制器和专用逻辑的处理器
图3是按照一个实施例的可以具有多于一个核心、可以具有集成存储器控制器并且可以具有集成图形的处理器300的框图。图3中的实线框图示具有单个核心302a、系统代理310、一个或者多个总线控制器单元316的集合的处理器300,而虚线框的可选附加图示具有多个核心302a-n、系统代理单元310中的一个或者多个集成存储器控制器单元314的集合、和专用逻辑308的替代存储器300。
因此,处理器300的不同实施方案可以包括:1)具有专用逻辑308、和核心302a-n的cpu,该专用逻辑是集成图形和/或科学(吞吐量)逻辑(其可以包括一个或者多个核心),以及所述核心是一个或者多个通用核心(例如,通用有序核心、通用无序核心、两者的组合);2)具有核心302a-n的协处理器,所述核心是大量专用核心,所述专用核心主要打算用于图形和/或科学(吞吐量);以及3)具有核心302a-n的协处理器,所述核心是大量通用有序核心。因此,处理器300可以是通用处理器、协处理器或者专用处理器,诸如例如网络或者通信处理器、压缩引擎、图形处理器、gpgpu(通用图形处理单元)、高吞吐量集成众核(mic)协处理器(包括30个或者更多核心)、嵌入式处理器等等。该处理器可以在一个或者多个芯片上实施。处理器300可以是使用若干处理技术(诸如例如bicmos、cmos或者nmos)中的任何处理技术的一个或者多个基板的一部分和/或可以实施在所述一个或者多个基板上。
存储器分级体系包括核心内的一个或者多个级的缓存、一个或者多个共享缓存单元306的集合、耦合到集成存储器控制器单元314的集合的外部存储器(未示出)。共享缓存单元306的集合可以包括一个或者多个中级缓存、诸如2级(l2)、3级(l3)、4级(l4)、或者其他级的缓存、最后一级缓存(llc)、和/或其组合。虽然在一个实施例中基于环的互连单元312将集成图形单元308、共享缓存单元306的集合、和系统代理单元310/(多个)集成存储器控制器单元314互连,但是替代的实施例可以使用任何数量的众所周知的用于将这样的单元互连的技术。在一个实施例中,在一个或者多个缓存单元306与核心302a-n之间保持一致性。
在一些实施例中,核心302a-n中的一个或者多个能够进行多线程操作(multithreading)。系统代理310包括协拌和操作核心302a-n的那些组件。系统代理单元310可以包括例如功率控制单元(pcu)和显示单元。pcu可以是或包括用于调节核心302a-n和集成图像逻辑308的功率状态所需要的逻辑和组件。显示单元用于驱动一个或者多个外部连接的显示器。
就架构指令集而言,核心302a-n可以是同构的或者异构的;也就是说,核心302a-n中的两个或者更多个可能能够执行相同的指令集,而其他核心可能能够仅执行该指令集的一个子集或者不同的指令集。
示范性计算机架构
图4-7是示范性计算机架构的框图。在本领域中已知的用于膝上型电脑、台式电脑、手持式pc、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、手机、便携式媒体播放器、手持式设备和各种其他电子设备的其他系统设计和配置也是适用的。一般而言,能够合并如本文中所公开的处理器和/或其他执行逻辑的各种各样的系统或者电子设备一般是适用的。
现在参考图4,示出了按照本发明的一个实施例的系统400的框图。系统400可以包括一个或者多个处理器410、415,其耦合到控制器集线器420。在一个实施例中,控制器集线器420包括图形存储器控制器集线器(gmch)490和输入/输出集线器(ioh)450(其可以在单独的芯片上);gmch490包括存储器和图形控制器,存储器440和协处理器445耦合到所述存储器和图形控制器;ioh450将输入/输出(i/o)设备460耦合到gmch490。替代地,存储器和图形控制器中的一个或者两者被集成在控制器内(如本文中所描述的),存储器440和协处理器445直接耦合到处理器410,并且控制器集线器420与ioh450在单个芯片中。
附加处理器415的可选性质在图4中用虚线表示。每个处理器410、415可以包括本文中所描述的处理核心中的一个或者多个,并且可以是处理器300的某一版本。
存储器440可以是例如动态随机存取存储器(dram)、相变存储器(pcm)、或者两者的组合。对于至少一个实施例而言,控制器集线器420经由多点分支总线(multi-dropbus)与(多个)处理器410、415通信,所述多点分支总线诸如是前端总线(fsb)、诸如quickpath互连(qpi)之类的点对点接口、或者相似连接495。
在一个实施例中,协处理器445是专用处理器,诸如例如高吞吐量mic处理器、网络或者通信处理器、压缩引擎、图形处理器、gpgpu、嵌入式处理器等等。在一个实施例中,控制器集线器420可以包括集成图形加速器。
就优点度量范围(包括架构特性、微架构特性、热特性、功率消耗特性等等)而言,在物理资源410、415之间可能存在各种各样的差别。
在一个实施例中,处理器410执行控制通用类型的数据处理操作的指令。嵌入在指令内的可以是协处理器指令。处理器410将这些协处理器指令识别为具有应该由附接的协处理器445执行的类型。因此,处理器410在协处理器总线或者其他互连上向协处理器445发布这些协处理器指令(或者表示协处理器指令的控制信号)。(多个)协处理器445接受并且执行接收到的协处理器指令。
现在参考图5,示出了按照本发明的实施例的更具体的第一示范性系统500的框图。如在图5中示出的,多处理器系统500是点对点互连系统,并且包括经由点对点互连550耦合的第一处理器570和第二处理器580。处理器570和580中的每一个可以是处理器300的某一版本。在本发明的一个实施例中,处理器570和580分别是处理器410和415,而协处理器538是协处理器445。在另一实施例中,处理器570和580分别是处理器410和协处理器445。
处理器570和580被示出为分别包括集成存储器控制器(imc)单元572和582。处理器570还包括点对点(p-p)接口576和578作为其总线控制器单元的一部分;相似地,第二控制器580包括p-p接口586和588。处理器570、580可以经由点对点(p-p)接口550使用p-p接口电路578、588来交换信息。如图5中示出的,imc572和582将处理器耦合到相应存储器、即存储器532和存储器534,所述存储器可以是本地附接到相应处理器的主存储器的部分。
处理器570、580可以各自与芯片集590经由各个p-p接口552、554使用点对点接口电路576、594、586、598交换信息。芯片集590可以可选地经由高性能接口539与协处理器538交换信息。在一个实施例中,协处理器538是专用处理器,诸如例如高吞吐量mic处理器、网络或者通信处理器、压缩引擎、图形处理器、gpgpu、嵌入式处理器等等。
共享缓存(未示出)可以被包括在任一处理器中,或者在两个处理器之外,但是与处理器经由p-p互连连接,使得如果处理器被置于低功率模式中,任一处理器或者两个处理器的本地缓存信息可以被存储在共享缓存中。
芯片集590可以经由接口596耦合到第一总线516。在一个实施例中,第一总线516可以是外围组件互连(pci)总线、或者是诸如pciexpress总线或者另一第三代i/o互连总线之类的总线,尽管本发明的范围并不如此受限制。
如图5中示出的,各种i/o设备514连同总线桥518可以耦合到第一总线516,所述总线桥将第一总线516耦合到第二总线520。在一个实施例中,一个或者多个附加处理器515(诸如协处理器、高吞吐量mic处理器、gpgpu、加速器(诸如例如图形加速器或者数字信号处理(dsp)单元)、现场可编程门阵列、或者任何其他处理器)耦合到第一总线516。在一个实施例中,第二总线520可以是低引脚数(lpc)总线。在一个实施例中,各种设备可以耦合到第二总线520,所述设备包括例如键盘和/或鼠标522、通信设备527和存储单元528,所述存储单元诸如是盘驱动器或者可以包括指令/代码和数据530的其他大容量存储设备。此外,音频i/o524可以耦合到第二总线520。注意:其他架构是可能的。例如,代替图5的点对点架构,系统可以实施多点分支总线或者其他这样的架构。
现在参考图6,示出了按照本发明的实施例的更具体的第二示范性系统600的框图。在图5和6中的同样的元件具有同样的参考数字,并且图5的特定方面已经从图6中被省略,以便避免使图6的其他方面难理解。
图6图示处理器570、580可以分别包括集成存储器和i/o控制逻辑(“cl”)572和582。因此,cl572、582包括集成存储器控制器单元并且包括i/o控制逻辑。图6图示不仅存储器532、534耦合到cl572、582,而且i/o设备614也耦合到控制逻辑572、582。旧有的i/o设备615耦合到芯片集590。
现在参考图7,示出了按照本发明的实施例的soc700的框图。在图3中的相似元件具有同样的参考数字。而且,虚线框是更先进的soc上的可选特征。在图7中,(多个)互连单元702耦合到:包括一个或者多个核心202a-n的集合和(多个)共享缓存单元306的应用处理器710;系统代理单元310;(多个)总线控制器单元316;(多个)集成存储器控制器单元314;可以包括集成图形逻辑、图像处理器、音频处理器、和视频处理器的一个或者多个协处理器720的集合;静态随机存取存储器(sram)单元730;直接存储器访问(dma)单元732;和用于耦合到一个或者多个外部显示器的显示单元740。在一个实施例中,(多个)协处理器720包括专用处理器,诸如例如网络或者通信处理器、压缩引擎、gpgpu、高吞吐量mic处理器、嵌入式处理器等等。
本文中所公开的机制的实施例以硬件、软件、固件或者这样的实施方法的组合来实施。实施例被实施为在可编程系统上执行的计算机程序或者程序代码,所述可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备、和至少一个输出设备。
诸如图5中图示的代码530之类的程序代码可以被应用于输入指令,以执行本文中所描述的功能并生成输出信息。输出信息可以以已知方式被应用于一个或者多个输出设备。为了本申请的目的,处理系统包括具有处理器的任何系统,所述处理器诸如例如是数字信号处理器(dsp)、微控制器、专用集成电路(asic)、或者微处理器。
程序代码可以以高级过程或者面向对象编程语言来实施,以便与处理系统通信。如果期望,程序代码也可以以汇编语言或者机器语言来实施。实际上,本文中所描述的机制在范围上不限于任何特定编程语言。在任何情况下,语言可以是编译或者解译语言。
至少一个实施例的一个或者多个方面可以由存储在机器可读介质上的代表性指令实施,所述机器可读介质表示处理器内的各种逻辑,所述机器可读介质当被机器读取时促使机器制造逻辑以执行本文中所描述的技术。这样的叫做“ip核心”的表示可以被存储在有形的机器可读介质上,并且被供应给各种客户或者生产设施,以加载到实际制作逻辑或者处理器的制造机器中。
这样的机器可读存储介质可以包括但不限于:由机器或者设备生产或者形成的物品的非瞬时性有形布置,包括存储介质,诸如硬盘、任何类型的盘(包括软盘、光盘、紧凑型盘只读存储器(cd-rom)、可重写紧凑型盘(cd-rw)和磁光盘)、半导体设备(诸如只读存储器(rom)、诸如动态随机存取存储器(dram)、静态随机存取存储器(sram)之类的随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、闪速存储器、电可擦除可编程只读存储器(eeprom)、相变存储器(pcm)、磁卡或者光卡)、或者任何其他类型的适用于存储电子指令的介质。
因此,一个实施例也包括包含指令或者包含设计数据、诸如硬件描述语言(hdl)的非瞬时性有形机器可读介质,该硬件描述语言定义本文中所描述的结构、电路、装置、处理器和/或系统特征。这样的实施例也可以被称为程序产品。
仿真(包括二进制翻译、代码融合等等)
在一些情况下,指令转换器可以被用于将指令从源指令集转换成目标指令集。例如,指令转换器可以将指令翻译(例如,使用静态二进制翻译、包括动态编译的动态二进制翻译)、融合、仿真或者以其他方式转换成一个或者多个要被核心处理的其他指令。指令转换器可以以软件、硬件、固件、或者其组合来实施。指令转换器可以在处理器上、在处理器外、或者部分在处理器上并且部分在处理器外。
图8是按照一个实施例的对比软件指令转换器的使用的框图,该软件指令转换器用于将源指令集中的二进制指令转换成目标指令集中的二进制指令。在所图示的实施例中,指令转换器是软件指令转换器,尽管替代地该指令转换器可以以软件、固件、硬件或者其各种组合来实施。图8示出用高级语言802的程序可以使用x86编译器804来编译,以生成可以由具有至少一个x86指令集核心816的处理器本地执行的x86二进制代码806。
具有至少一个x86指令集核心816的处理器表示如下任何处理器,所述处理器可以通过兼容地执行或者以其他方式处理以下项而基本上执行与具有至少一个x86指令集核心的
指令转换812被用于将x86二进制代码806转换为可以由不具有x86指令集核心814的处理器本地执行的代码。该所转换的代码不大可能与替代的指令集二进制代码810相同,因为能够进行该转换的指令转换器难以制作;然而,所转换的代码将完成一般操作并且由来自替代指令集的指令构成。因此,指令转换器812表示如下软件、固件、硬件或者其组合,该软件、固件、硬件或者其组合通过仿真、模拟或者任何其他过程允许不具有x86指令集处理器或者核心的处理器或者其他电子设备执行x86二进制代码806。
受限事务存储器
受限事务存储器(rtm)提供一种用于代码区域(被称为rtm区域)的推测性执行机制,使得区域执行可以在丢失推测的情况下被回滚。处理器可以使用任何数量的机制来实施rtm事务。在一个实施例中,处理器在对其他线程不可见的存储器的受限区域中执行推测性事务。如果不存在与其他并发执行的线程的存储器冲突,则事务被原子地提交给全局可见存储器。在一个实施例中,启用rtm的轻量级版本,其提供与被配置成执行推测性锁定省略的rtm实施方案相比更低的开销。
图9是示范性处理器的框图,在该示范性处理器中可以实施实施例。单个处理器核心990(例如,核心0)的细节为简单起见被图示,尽管有其他核心(例如,核心1-n可以具有相似逻辑)。在一个实施例中,处理器核心990包括在图1的示范性处理器190中图示的处理器组件。附加地,每个核心包括专用存储器单元970,其包括被配置成为了实施rtm而执行推测性事务存储器操作的数据tlb单元972、数据缓存单元(例如,1级(l1)缓存)、存储缓冲器973、和加载缓冲器975。重命名/分配器单元952、(多个)物理寄存器文件单元958和引退单元954也可以被修改以支持rtm实施方案。
在一个实施例中,处理器核心990被配置成执行存储器指令,所述存储器指令包括加载(ld)和存储(st)指令。加载指令可以读取存储器并且在与加载指令相关联的数据被加载到(多个)物理寄存器文件单元中的处理器寄存器中之后引退。在一个实施例中,当发布加载时,加载缓冲器975中的条目被保留用于地址。一旦指令已经引退了,就可以释放在加载缓冲器975中的条目,并且将加载数据写入到(多个)物理寄存器文件单元958中。
当与存储指令相关联的数据从处理器寄存器被传输到存储缓冲器973时,可以引退存储指令。本文中所使用的术语“引退”意味着指令由cpu执行并且离开cpu队列。在一个实施例中,核心990是无序核心,并且当为了重命名和调度而发布存储时,针对存储指令为地址和数据分配在存储缓冲器973中的条目。在一个实施例中,存储缓冲器973将保持存储指令的地址和数据,直到指令已经引退并且数据已经被写入到数据缓存单元974为止。引退的存储指令在本文中被称为“高级存储”。
rtm实施方案可以包括附加存储缓冲器973,供用作高级存储缓冲器,其存储引退存储以用于随后对全局可见存储器的刷新。高级存储缓冲器可以在用于rtm区域的提交阶段期间使用。在一个实施例中,提交在加载指令和存储指令从处理器核心引退之后发生。在一个实施例中,提交在多个阶段中发生。在第一提交阶段中,与加载指令相关联的数据可以从缓存/存储器中的适当位置被读取,并且然后被加载到寄存器中。然后加载指令被引退。与存储指令相关联的数据可以从寄存器被移动并且写入到存储缓冲器,并且存储指令被引退。然而,在第一提交阶段之后,与引退的存储指令(高级存储)相关联的数据可以保留在存储缓冲器中,等待在第二提交阶段中被写入到缓存/存储器。在高级存储缓冲器在将事务提交给全局可见存储器之前被排空的同时,事务性地执行的线程将事务缓冲到推测性缓存。在常规的(例如,基于sle的)rtm实施方案中,提交可能不发生,除非事务可以在不具有与其他执行线程的数据冲突的情况下原子提交,如以下进一步描述的。在一个实施例中,使用修改的缓存一致性系统来检测冲突。
图10是按照一个实施例的被配置成存储用于受限事务存储器实施方案的推测性数据的缓存的框图。在一个实施例中,事务加载和存储可以在私有(例如,受限)事务存储器、诸如缓存单元1002的区域内执行。缓存单元1002可以是耦合到处理器的任何缓存单元,诸如图9中耦合到处理器核心990的数据缓存单元974。缓存单元1002包括多个缓存行1010、1015、1020、1025。在一个实施例中,控制逻辑1030包括具有属性的集合的标签阵列1035,所述属性指示事务读取1011.r、1016.r、1021.r、1026.r、或者事务写入1011.w、1016.w、1021.w、1026.w。
在一个实施例中,每对读取和写入属性与缓存行相关联。例如,第一读取属性1011.r和第一写入属性1011.w与第一缓存行1010相关联。第二读取属性1016.r和第二写入属性1016.w与第二缓存行1015相关联。在一个实施例中,标签阵列1035附加地包括一致性状态阵列,其中属性被包括在一致性状态内。
在一个实施例中,属性1011.r-1026.r和1011.w-1026.w被用于向缓存一致性系统指示哪些数据项或者数据元素、诸如被缓存的数据元素1001a参与事务操作、诸如事务加载或者事务存储操作。例如,被缓存的数据元素1001a已经由于来自存储器1004中的数据元素1001b的事务加载而被加载到缓存单元1002中。被缓存的数据项1001a占据第一缓存行1010的整体以及第二缓存行1015的一半。因此,控制逻辑1030更新字段1011.r和1016.r以指示已经发生了来自缓存行215和216的事务加载。例如,字段1011.r和1016.r可以从未被监控的逻辑值、诸如逻辑零被更新为被监控的逻辑值、诸如逻辑一。在标签阵列1035是一致性状态阵列的实施例中,字段1011和1016被转变成适当的一致性状态、诸如被监控的读取共享一致性状态。
在一个实施例中,冲突逻辑被包括在缓存控制逻辑1030内,或者与该缓存控制逻辑相关联,以检测与属性相关联的冲突。基于设计实施方案,属性状态、请求、通信协议、或者一致性协议的任何组合可以被利用以确定冲突存在。作为基本示例,对被监控的读取的写入潜在地是冲突,并且对被监控的写入的读取或者写入潜在地是冲突。在一个实施例中,控制逻辑1030中的监听逻辑1032检测由对写入到缓存行1010或者1015的请求造成的冲突。一旦检测到冲突,在一个实施例中,报告逻辑就报告该冲突,以用于由处理器硬件、系统固件、或者其组合进行处理。
在一个实施例中,数据冲突造成实施事务的处理器中止该事务。在中止时,处理器回滚事务执行,以将处理器的状态恢复到在事务开始之前的点。这可能包括丢弃一直到事务中止为止所执行的任何存储器更新。执行然后可以非事务性地继续。
受限事务存储器和推测性编译器优化
虽然rtm的现有的基于处理器的实施方案一般被用于经由硬件实施推测性锁定省略(sle),其中数据访问串行化通过移除对在推测性执行期间不是并发访问的数据的不必要锁定而被潜在地防止,但是优化编译器可以被配置成使用rtm来执行推测性编译器优化。特别地,当频繁执行的循环被确定为是数据并行时,如果目标处理器架构包含矢量或者单指令多数据(simd)硬件,优化编译器可以尝试将该循环矢量化。然而,将具有编译器不能静态解决的潜在交叉迭代存储器相关性的循环矢量化是不安全的。在这样的情况下,如果这些相关性不在运行时实现,或者如果这些相关性在运行时非常不频繁地实现,则simd循环矢量化的潜在益处可能无法实现。因此,优化编译器可以使用rtm以在编译时间实施推测性优化。
图11是图示用于实施优化编译器的数据处理系统的框图。该系统包括一个或者多个本地或者分布式处理器核心1102a-1102n,其经由互连1104(例如,高速总线和/或分组网络)耦合到本地或者分布式存储器1110。存储器可以包括一个或者多个辅助存储器或者存储设备,并且可以包括虚拟存储器,该虚拟存储器包括在易失性存储器设备或者非易失性存储设备中的数据。存储器1110包括源代码1112和编译器/优化器1120,该编译器/优化器用于优化源代码以创建优化的代码/二进制1114。
在一个实施例中,源代码1112包括用高级语言(例如,c、c++)、低级语言(例如,汇编语言)或者中间语言(例如,llvm中间表示)的指令。编译器/优化器1120可以是独立的编译器、和优化器模块、特定于架构的优化器/编译器、模块化编译系统、或者任何其他类型的编译器或者优化器。优化的代码/二进制1114可以是几种形式的程序代码中的一种或者多种,包括高级表示、中间表示、低级表示、或者已编译的对象二进制。在一个实施例中,编译器/优化器1120利用静态分析模块来生成优化的代码/二进制1114,该静态分析模块包括但不限于控制流分析模块1122、数据流分析模块1123、和相关性分析模块1124。在一个实施例中,用于源代码的编译器/优化器1120功能可以用二进制优化器和运行时概要分析(profiling)代替,以优化现有二进制。
可以受益于推测性循环矢量化的指令的示例在以下的表1中示出。
(01)t=(someinitialvalue)
(02)…
(03)for(i=0;i<8;i++){
(04)a[i]=b[i]+t
(05)if(a[i]<0)//很少为真
(06)t=(someothervalue)
(07)}
表1-代码1
表1中的示范性代码1示出如图10中的示范性源代码1112。代码1包括在行(03)到(07)中的循环操作,以将阵列‘b’的每个元素的值加上变量‘t’指派给阵列‘a’。变量‘t’具有某个初始值,其在行(1)处被设置。然而,变量‘t’的值可以在循环执行期间基于在行(5)处的条件分支在行(6)处改变。针对阵列‘a’的任何小于零的元素采取条件分支。在一些情况下,用于更新‘t’的分支条件很少为真。在一个实施例中,编译器/优化器1120经由静态分析模块(例如,1122、1123、1124)或者经由分支预测暗示来确定分支条件的可能性。如果适当,则编译器/优化器1120将矢量化代码以使用simd/矢量指令来推测性地更新阵列‘a’的具有阵列‘b’的元素与变量‘t’的标量循环初始值的矢量相加的元素(例如,a[i])。在用于更新变量‘t’的值的分支条件随后在循环的特定迭代中被确定为真的罕见情况下,循环执行可以使用rtm逻辑被回滚,并且原始代码可以在不推测的情况下运行。
在一个实施例中,当优化以上的表1的代码1以生成由以下的表2的示范性代码2表示的指令时优化编译器利用rtm硬件。
(08)rtm_begin(offset)
(09)a[0:7]=b[0:7]+t;
(10)if(a[0:7]<0)
(11)rtm_abort(status);
(12)rtm_end();
offset:(3-7){(code1)//rtm后退}
表2-代码2
如表2中示出的,可以使用处理器rtm实施方案执行推测性编译器优化。在一个实施例中,优化编译器可以将标记插入到程序代码中,以规定rtm区域的开始(例如在行(8)处的rtm_begin)和结束(例如,在行(12)处的rtm_end)。在一个实施例中,标记是由处理器指令集提供的指令。优化编译器推测性地生成原始代码的优化版本,并且将优化的代码插入到rtm区域中。如在行(09)上示出的,编译器可以使用单个simd指令优化代码1的行(3)-(7)的八个串行执行的循环指令。simd指令将阵列‘b’的多个元素与由‘t’变量的初始值所规定的值相加,并且将结果指派给阵列‘a’的多个元素。
优化是以‘t’的值不改变为条件的。因此,在一个实施例中,编译器插入矢量指令,以检查中止条件,如由行(10)示出的。如由行(11)示出的,插入以导致‘t’的值改变的分支事件的发生为条件的中止指令。虽然在代码2中示出了逻辑分支,但是中止指令也可以经由断言或者指令执行的任何其他条件方法而有条件地执行。如在行(11)上示出的,在一个实施例中,明确的中止可以指示中止状态,以指示该中止的原因。
在一个实施例中,在行(08)处的区域开始标记指示在丢失推测的情况下要执行的后退(fallback)指令集的位置。用于代码2的后退指令可以是未优化的,或者是来自原始代码的指令的不太积极的优化版本(例如,代码1的行(3)到行(7))。
因此,在各种实施例中,优化编译器可以使用为推测性锁定省略所设计的rtm指令实施推测性编译器优化。然而,现有的经由rtm的推测性锁定省略的实施方案对rtm区域的执行提出两个要求:1)提交要求,和2)回滚要求。提交要求说明,如果rtm区域提交,该区域必须看来像是原子执行,而不与其他并发线程交织。回滚要求说明,如果rtm区域中止,则部分执行的区域必须在没有任何副作用的情况下完全被回滚。提交要求和回滚要求有助于确保对推测性锁定省略和推测性事务的执行的正确性。
为了实现提交要求和回滚要求两者,现有rtm实施方案针对rtm区域中的所有加载操作和存储操作检测存储器冲突。对于基于缓存并发的事务存储器实施方案,存储器冲突可以通过在位于处理器附近的缓存中设置推测性读取/写入位来检测,并且将该缓存用于该区域中的所有加载/存储操作(例如,针对事务所设置的读取/写入),如图10中图示的。缓存存储器系统然后可以在区域执行期间经由读取/写入位监听来自并发线程的冲突访问,直到该区域提交为止。然而,用于实施提交要求和回滚要求两者的处理器逻辑引入用于基于rtm的推测性优化的附加开销,该推测性优化在不执行锁定省略时可能是不要求的。
在一个实施例中,两阶段提交区域实施方案包括降低由rtm逻辑施加的开销的优化。在现有实施方案中的一种优化包括当存储指令从处理器指令管线被引退时延迟这些指令的全局可见性。在rtm区域内的非全局可观测的存储可以被置于用于引退的存储指令的‘高级’存储缓冲器中,而不阻止随后的指令引退。这实现那些存储指令的无序引退,所述存储指令可以通过使用单个操作使高级存储缓冲器中的存储全局可见而被原子提交。
然而,由于提交要求,rtm区域可能仅在rtm区域内的所有存储是全局可见之后提交。因此,现有rtm实施方案在提交区域之前排出高级存储缓冲器中的所有待决的存储,从而允许所述存储变得全局可见。在本文中所描述的实施例中,引入一种rtm实施方案以比起现有rtm实施方案来并且超过现有rtm实施方案进一步降低rtm开销,以提供轻量级rtm以供推测性编译器优化中使用。
用于推测性编译器优化的轻量级受限事务存储器
用于推测性编译器优化的轻量级rtm在检测到误推测的情况下仅施加对回滚区域的回滚要求,同时移除阻止轻量级rtm区域提交的提交要求。对于轻量级rtm而言,这足以确保当rtm区域中止时,在该区域内的所有存储对于并发线程是不可见的,并且可以在没有任何副作用的情况下完全被回滚,这满足回滚要求。提交要求可以被消除,因为不使用轻量级rtm指令来执行推测性锁定省略。
由于阻止轻量级rtm区域的提交的提交要求的移除,所以一个实施例消除用于在轻量级rtm区域内的加载操作的冲突检测,同时保持用于在该区域内的存储操作的冲突检测。在一个实施例中,轻量级rtm不包括用于在提交该区域之前排出高级存储缓冲器中的待决存储的要求。因此,区域提交可以在不等待所有待决存储全局可观测之前被执行。
在以下的表3中示出了代码3,其是使用轻量级rtm(例如,ltrx)指令的示范性优化代码。
(13)ltrx_begin(offset)
(14)a[0:7]=b[0:7]+t;
(15)if(a[0:7]<0)
(16)ltrx_abort();
(17)ltrxend();
offset:(3-7){(code1)//ltrx后退}
表3-代码3
在表3中示出的轻量级rtm指令允许经由rtm的推测性优化,以避免涉及使用基于锁定省略的rtm实施方案的开销。在一个实施例中,提供轻量级rtm指令来规定轻量级事务区域的开始(例如,在行(13)处的ltrx_begin)和结束(例如,在行(17)处的ltrx_end)。当处理器成功地到达轻量级rtm区域的结束时,事务可以在不被提交要求阻止的情况下提交。在一个实施例中,还提供单独的轻量级中止指令(例如,在行(13)处的ltrx_abort)。
正执行在轻量级事务区域内的指令的处理器与执行在针对sle所配置的rtm区域中的指令的处理器相比执行不同的操作。例如,用于实施行(14)的矢量操作的simd指令不针对推测性缓存中的事务属性设置读取位(例如,图10的1011.r、1016.r、1021.r、1026.r)。省略针对存储元素b[0:7]的缓冲数据行对推测性读取位的设置节省处理器执行资源,并且在与基于推测性锁定省略的rtm实施方案相比时减少用于实施轻量级rtm实施方案所要求的逻辑。
相比与用于sle的rtm实施方案,避免设置读取位允许在用于轻量级rtm实施方案的开销方面的若干减少。例如,在一个实施例中,处理器包括供sle中使用的rtm实施方案,同时也支持用于在无序窗口内的指令的推测性加载执行。在这样的处理器中,额外的“高级”加载在加载引退之后被分派,以设置缓存中的推测性读取位。高级加载是在执行之前引退的加载指令,从而通过允许已经完成并且在高级加载之后被分派的指令在没有延迟的情况下被引退来改进性能。实施轻量级rtm的实施例可以由于消除提交要求而省略额外的高级加载分派。省略额外的高级加载分派可以减少处理器内的加载端口压力。减少加载端口压力允许处理器设计者减少在实施处理器的高级加载队列时所消耗的处理器管芯区域的数量,尽管逻辑和管芯区域仍然可能被保留以供常规rtm实施方案使用。
在一个实施例中,实施轻量级rtm避免区域回滚,该区域回滚由于推测性缓存上的读取位溢出而发生。当已经被标记为推测性读取的缓存区域(例如,缓存行)例如由于耗尽推测性缓存中的资源而被其他数据(例如,其他推测性数据)重写时,发生读取位溢出。虽然存在可以(例如,使用压缩过滤器来跟踪事务读取、多级推测性缓存等等)减少与读取位溢出相关联的风险的rtm实施方案,但是没有这样的细节的实施例不能执行针对包含推测性数据的缓存行的缓存行驱逐。包含推测性数据的缓存行的驱逐将导致推测性数据泄露,这可能危害其他并发执行的线程。因此,在许多rtm实施方案中,推测性缓存读取位溢出造成事务中止。然而,使用轻量级rtm的实施例可以在没有缓存读取位溢出的风险的情况下操作。
在一个实施例中,轻量级rtm避免由于排空高级存储缓冲器造成的区域提交的停止。在代码3中,区域可以在不等待到a[0:7]的所有存储全局可见的情况下提交。在一些处理器架构中,用于全局可观测存储的高级存储缓冲器的排空是存储防护(fences)和被锁定指令的已知开销。因此,使用轻量级rtm的推测性优化可以实现比起使用现有的基于硬件的rtm实施方案的推测性优化来的改进性能。
在一个实施例中,轻量级rtm避免由于加载操作上的假存储器冲突而造成的不必要的区域回滚。在现有rtm实施方案中,如下并发线程可以促使区域中止和回滚,该并发线程更新被缓存在与用于矢量元素b[0:7]的数据相同的缓存行上的不相关数据。例如,对存储在图9的缓存行915的一部分中的不相关数据的更新可能促使事务中止,即使该更新是与事务性地加载的被缓存的数据元素901a不相关的。这样的假的回滚不会在本文中所描述的轻量级rtm的实施例中发生。在涉及事务加载和并发数据访问方面的任何真冲突可以经由程序员实施的锁定而解决。在一个实施例中,这样的锁定也可以在运行时或者在编译时使用基于锁定省略的rtm实施方案在单独的事务区域中来优化。
图12是按照一个实施例的用于利用事务存储器区域优化程序代码的逻辑的流程图。在一个实施例中,程序代码的第一部分被传送到优化编译器,并且如在框1202处示出的,编译器、或者在编译器内的优化模块接收程序代码的第一部分。在框1204处,优化逻辑生成程序代码的推测性优化版本,其假设不发生控制或者数据事件或者条件。
在框1206处,优化逻辑使用标记或者指令将推测性优化的程序代码封入事务区域中。标记或者指令要用于向事务存储器实施方案指示程序代码的推测性优化版本要被实施为原子事务。在框1208处,优化逻辑将事务区域插入到程序代码中,作为程序代码的区段。在一个实施例中,优化逻辑用优化的程序代码代替程序代码的原始区段。在框1210处,后退区域被配置用于在事务中止的情况下执行。
图13是按照一个实施例的用于利用一个或者多个事务存储器区域优化程序代码的逻辑的流程图。在框1302处,标识要被优化的程序代码的区段。该区段可以被指定为程序代码的第一区段。如在框1304处示出的,优化逻辑的一个实施例定义在程序代码中的、将包括程序代码的第一区段的优化版本的第二区段。在一个实施例中,被标识用于优化的代码区段要被变换成要在事务存储器区域内执行的程序代码的推测性优化表示。事务区域可以在具有本文中所描述的任何受限事务存储器区域实施方案的处理设备上被执行。在一个实施例中,事务区域被配置成在包括为了在推测性编译器优化中使用所设计的轻量级受限事务存储器区域实施方案的处理器上执行。
在框1306处,优化逻辑在程序代码中的第二区段的开始处插入指令以指示事务区域的开始。在框1308处,优化逻辑在程序代码中的第二区段的结束处插入指令以指示事务区域的结束。
在框1310处,优化逻辑生成程序代码的第一区段的推测性优化版本。推测性优化包括但不限于迭代程序代码的推测性矢量化,其包括矢量加载/聚集/存储/分散操作的插入、或者跨多个数据元素执行单个指令或者操作的其他矢量指令。可以被执行的推测性代码优化的几个附加且非限制性示例包括数据流优化、代码生成优化、边界检查消除、分支偏移量优化、未使用代码消除、或者跳转线程。
在框1312处,确定条件中止点和中止条件。注意:可以在要被优化的代码区域内确定或者指派多个条件中止点,但是为了便于讨论,仅详细讨论了一个中止点。确定条件中止点可以基于任何代码分析算法来确定推测性事务执行何时可以不再进行。附加地,硬件实施方案可以在执行事务区域期间由于各种原因而触发自动中止,这些原因包括推测性缓存溢出或者由加载或者存储操作造成的数据冲突。
在框1314处,优化逻辑在中止点处插入有条件地执行的事务中止。在一个实施例中,事务中止是用于向事务存储器逻辑指示回滚事务区域的中止指令。在框1316处,优化逻辑配置后退区域,该后退区域可以是程序代码的第一区段的不太积极地优化的版本。不太积极地优化意味着所利用的后退可以是程序代码的第一区段的优化版本,但是如下优化版本,该优化版本不是被推测性优化以假设不发生分支或者数据条件。在一个实施例中,可以组合多个嵌套的事务存储器区域,并且被用作是后退区域的程序代码的不太积极地优化的版本是具有更高成功机会或者显著更低频率的中止条件的事务存储器区域。
虽然图12和图13的流程图以基本上串行的方式来图示,但是所图示的逻辑可以按与所示出的次序不同的次序来执行。此外,逻辑的部分可以与其他部分并行地执行。
如本文中所描述的,程序代码可以指代编译器代码、优化代码、应用代码、库代码、或者任何其他已知形式化的代码。例如,程序代码包括要在本文中所描述的处理器中的任何一个或者多个处理器上执行的代码。在一个实施例中,被配置成优化已编译程序代码的二进制优化器相当于未编译程序代码的编译器优化。插入代码(操作、函数调用、等等)和优化代码通过经由一个或者多个处理器执行不同程序代码、诸如编译器和/或优化代码来执行。例如,优化代码可以在运行时在处理器上动态地执行,以及时(jit)优化程序代码以用于在处理器上执行该程序代码。
在一个实施例中,标识要被优化的程序代码的区段包括指示要被优化的程序代码的区段/区域的代码。例如,具体指令或者划分被用于指示要被优化或者将很可能受益于优化的代码区段。作为另一选项,程序员提供关于程序代码的区段的暗示,所述暗示被优化代码利用以标识用于优化的区段。在另一实施例中,基于概要分析信息标识/选择区域。例如,程序代码在执行期间通过硬件、在处理器上执行的软件、固件、或者其组合进行概要分析。此处,对代码的概要分析生成暗示或者修改原始软件暗示,以及提供对用于优化的区域的直接标识。附加地,代码区段潜在地由特定属性、诸如具体类型、格式、或者代码次序来标识。作为具体说明性示例,包括循环的代码针对潜在优化。在执行期间对循环的概要分析确定循环中的哪个应该被优化。而且,如果该循环包括要被优化的具体代码、诸如加载和存储,则包括这样的代码的区域被标识用于优化。
如本文中所使用的,“优化”被定义为被设计成改进源代码的性能的一个或者多个操作。贯穿本文件被提及的术语“进行优化”和“优化”具体地指代执行对代码的修改。这些优化通常地以改进代码的性能吞吐量的意图来执行。然而,存在具有其他意图或者其他结果的特定优化。在特定情况下,可以对代码执行优化以修改在执行代码时所收集的所产生的输出数据,而不是尝试改进代码的任何性能吞吐量。附加地,在其他目标中,也可以执行优化以修改性能监控代码的数据收集能力。在其他潜在情况下,代码优化可以以实现代码的性能吞吐量的增益的意图被引入到代码中,却不实现任何增益并且可能导致由于未预见到的情况造成的不想要的性能降级。
因此,术语“进行优化”和“优化”不具体指代将实现理想性能的代码的最优配置。不一定是如下情况,即:在本文件内所提及的任何“优化”能够导致真正最优的性能(例如,最佳理论性能吞吐量)。更确切地说,在本文件内对“进行优化”和“优化”的引用意味着重建代码以便比起原始代码来潜在地获得某个水平的性能改进或者为了用户利益修改代码的某个其他方面(例如,修改如上指代的所产生的输出)的尝试。如果“优化”打算实现性能改进,则是否实现了实际性能改进完全依赖于所执行的修改的类型、原始代码的具体结构和行为、以及在其内执行代码的环境。示范性二进制优化操作包括存储器操作、例如重新排序加载和/或存储指令、以及非存储器操作、诸如消除未使用的代码、或者以其他方式精简(streamlining)源二进制代码。
轻量级rtm实施方案
图14是图示按照一个实施例的轻量级rtm实施方案的框图。包括轻量级rtm实施方案的示范性处理器1455可以包括专用推测性缓存1424或者可以给另一内部缓存、诸如数据缓存1421的部分分派任务,供用作推测性缓存,该推测性缓存用于充当用于事务区域内的指令的受限事务存储器。在一个实施例中,处理存储器指令(例如,加载/存储指令)包括分配、解除分配、和利用加载缓冲器1422和存储缓冲器1423内的空间。加载缓冲器1422和存储缓冲器1423的操作被配置成支持轻量级rtm事务。对于轻量级事务,针对区域中的存储操作执行冲突检测。然而,由于实施轻量级rtm的实施例假设:在轻量级事务期间将不发生真正的数据冲突。
因此,在一个实施例中,对于区域中的加载操作,不执行冲突检测。在一个实施例中,执行轻量级rtm区域内的指令的处理器不中止假的数据冲突(例如,在与推测性数据相同的缓存行上写入不相关数据,如果推测性数据未被干扰的话)。在一个实施例中,处理器不要求在事务结束时的原子提交。当轻量级rtm区域提交时,不要求该区域看来像是原子地执行的(例如,在没有与其他并发线程交织的情况下)。对于轻量级rtm而言,足以确保当事务区域中止时,在该区域中的所有存储对并发线程不可见,并且可以在没有任何副作用的情况下完全被回滚。在一个实施例中,缓存一致性协议被用于监听来自由在轻量级rtm区域内期间所执行的事务存储指令造成的可能的存储器冲突。在一个实施例中,当在轻量级事务区域内执行存储指令时,缓存一致性协议跟踪缓存行写入属性(例如,图10的1011.r、1016.r、1021.r、1026.r)集合。
如上提及的,轻量级事务存储器指令(例如,ltrx指令)的新集合向处理器指示指令集要作为事务被执行。所图示的实施例包括具有用于对轻量级rtm指令进行解码的解码逻辑1431的解码单元1430。附加地,执行单元1440一起包括用于执行轻量级rtm指令的附加执行单元1441。附加地,在执行单元1440执行指令流时,寄存器集合1405为操作数、控制数据和其他类型的数据提供寄存存储器。
为了简单起见,在图14中图示了单个处理器核心(“核心0”)的细节。然而,将理解,在图14中示出的每个核心可以具有与核心0相同的逻辑集合。如所图示的,每个核心还可以包括按照所规定的缓存管理策略的用于缓存指令和数据的专用1级(l1)缓存1412和2级(l2)缓存1411。l1缓存1411包括用于存储指令的单独的指令缓存1420和用于存储数据的单独的数据缓存1421。存储在各种处理器缓存内的指令和数据以缓存行的粒度进行管理,所述缓存行可以是固定大小的(例如,长度上为64、128、512字节)。该示范性实施例的每个核心具有用于从主存储器1400和/或共享的3级(l3)缓存1416提取指令的指令提取单元1410;用于对指令进行解码的解码单元1420;用于执行指令的执行单元1440;和用于引退指令和写回结果的写回单元1450。
指令提取单元1410包括各种众所周知的组件,所述组件包括用于存储要从存储器1400(或者缓存之一)提取的下一指令的地址的下一指令指针1403;用于存储最近使用的虚拟到物理指令地址的映射以提高地址翻译速度的指令翻译后备缓冲器(itlb)1404;用于推测性预测指令分支地址的分支预测单元1402;和用于存储分支地址和目标地址的分支目标缓冲器(btb)1401。一旦被提取,指令然后流动到指令管线的剩余阶段,其包括解码单元1430、执行单元1440和写回单元1450。
图15是按照一个实施例的用于处理轻量级rtm指令的逻辑的流程图。在框1502处,指令管线带来包括第一操作数的指令的提取,所述第一操作数指示到后退区域的偏移量。在框1504处,处理器将指令解码成已解码指令。在一个实施例中,已解码指令是单个操作。在一个实施例中,已解码指令是包括一个或者多个逻辑微操作以执行指令的每个子元素。微操作可以是硬连线的或者微代码操作,以可以促使处理器的组件(诸如执行单元)执行各种操作来实施指令。
在框1506处,处理器的执行单元执行已解码指令。在一个实施例中,已解码指令促使处理器进入事务执行模式,在该事务执行模式中,在事务区域中的指令使用事务存储器来执行。如在框1508处示出的,在事务区域内执行指令促使执行单元响应于推测性存储指令而设置与事务存储器相关联的写入属性。换言之,在事务区域内执行的推测性存储针对数据冲突而被跟踪。在一个实施例中,在事务区域内执行的推测性加载不针对数据冲突被跟踪。在框1510处,执行单元通过将事务存储器提交给非事务存储器而退出事务模式。在一个实施例中,执行单元在不要求原子提交的情况下自动地退出事务模式(例如,可能非原子地退出)。例如,执行单元可以基于待决的高级存储指令在不阻止的情况下退出事务模式。本文中所描述的轻量级rtm指令可以按以下描述的示范性指令格式中的任一种被编码。
示范性指令格式
本文中所描述的(多个)指令的实施例可以以不同格式体现。附加地,以下详述了示范性系统、架构和管线。(多个)指令的实施例可以在这样的系统、架构和管线上执行,但是不限于那些所详述的内容。
矢量友好指令格式是适合于矢量指令(例如,存在特定于矢量操作的特定字段)的指令格式。虽然描述了矢量和标量操作两者通过矢量友好指令格式都得以支持的实施例,但是替代实施例仅以矢量友好指令格式使用矢量操作。
图16a-16b是图示按照一个实施例的通用矢量友好指令格式及其指令模板的框图。图16a是图示按照一个实施例的通用矢量友好指令格式及其类别a指令模板的框图;而图16b是图示按照一个实施例的通用矢量友好指令格式及其类别b指令模板的框图。具体地,针对通用矢量友好指令格式1600定义了类别a和类别b指令模板,这两者都不包括存储器访问1605指令模板和存储器访问1620指令模板。在矢量友好指令格式的上下文中的术语“通用”指代不束缚于任何具体指令集的指令格式。
将描述矢量友好指令格式支持以下项的实施例:具有32位(4字节)或者64位(8字节)数据元素宽度(或者大小)的64字节矢量操作数长度(或者大小)(并且因此,64字节矢量由16个双字大小元素或者替代地8个四倍字大小元素组成);具有16位(2字节)或者8位(1字节)数据元素宽度(或者大小)的64字节矢量操作数长度(或者大小);具有32位(4字节)、64位(8字节)、16位(2字节)、或者8位(1字节)数据元素宽度(或者大小)的32字节矢量操作数长度(或者大小);以及具有32位(4字节)、64位(8字节)、16位(2字节)、或者8位(1字节)数据元素宽度(或者大小)的16字节矢量操作数长度(或者大小)。然而,替代实施例支持具有更多、更少或者不同数据元素宽度(例如,128位(16字节)数据元素宽度)的更多、更少和/或不同矢量操作数大小(例如,256字节矢量操作数)。
在图16a中的类别a指令模板包括:1)在无存储器访问1605指令模板内,示出了无存储器访问、完全舍入(fullround)控制类型操作1610指令模板和无存储器访问、数据变换类型操作1615指令模板;以及2)在存储器访问1620指令模板内,示出了存储器访问、临时1625指令模板和存储器访问、非临时1630指令模板。在图16b中的类别b指令模板包括:1)在无存储器访问1605指令模板内,示出了无存储器访问、写屏蔽控制、部分舍入控制类型操作1612指令模板和无存储器访问、写屏蔽控制、vsize类型操作1617指令模板;以及2)在存储器访问1620指令模板内,示出了存储器访问、写屏蔽控制1627指令模板。
通用矢量友好指令格式1600包括按图16a-16b中所图示的次序的、以下列出的下列字段。
格式字段1640——在该字段中的具体值(指令格式标识符值)唯一地标识矢量友好指令格式,并且因此标识按矢量友好指令格式的指令在指令流中出现。像这样,该字段在如下意义上是可选的:该字段对于仅具有通用矢量友好指令格式的指令集来说是不需要的。
基本操作字段1642——其内容区分不同基本操作。
寄存器索引字段1644——其内容直接地或者通过地址生成规定源和目的操作数的位置,源和目的操作数是在寄存器中还是在存储器中。这些内容包括用于从pxq(例如,32x512、16x128、32x1024、64x1024)寄存器文件中选择n个寄存器的足够数量的位。虽然在一个实施例中,n可以最多是三个源和一个目的寄存器,但是替代实施例可以支持更多或者更少源和目的寄存器(例如,可以支持最多两个源,其中这些源之一还充当目的地,可以支持最多三个源,其中这些源之一还充当目的地,可以支持最多两个源和一个目的地)。
修改器字段1646——其内容区分按通用矢量指令格式的规定存储器访问的指令的出现与那些不规定存储器访问的指令的出现;即,在无存储器访问1605指令模板和存储器访问1620指令模板之间进行区分。对存储器分级体系的存储器访问操作读取和/或写入(在一些情况下使用寄存器中的值规定源和/或目的地址),而非存储器访问操作不这么做(例如,源和目的地是寄存器)。虽然在一个实施例中,该字段也在用于执行存储器地址计算的三个不同方式之间选择,但是替代实施例可以支持用于执行存储器地址计算的更多、更少或者不同方式。
扩充操作字段1650——其内容区分除了基本操作之外要执行各种各样不同操作中的哪个操作。该字段是特定于上下文的。在本发明的一个实施例中,该字段被划分成类别字段1668、alpha字段1652、和beta字段1654。扩充操作字段1650允许在单个指令、而不是2、3或者4个指令中执行公用操作组。
缩放字段1660——其内容允许缩放索引字段的内容以用于存储器地址生成(例如,以用于使用2缩放*索引+基础的地址生成)。
位移字段1662a——其内容被用作存储器地址生成的一部分(例如,用于使用2缩放*索引+基础+位移的地址生成)。
位移因数字段1662b(注意:位移字段1662a直接在位移因数字段1662b之上的并置指示使用一个或者另一个)——其内容被用作地址生成的一部分;其规定要通过存储器访问的大小(n)缩放的位移因数——其中n是在存储器访问中的字节数(例如,用于使用2缩放*索引+基础+缩放的位移的地址生成)。忽略了冗余的低阶位,并且因此,位移因数字段的内容乘以存储器操作数的总大小(n)以便生成要被用于计算有效地址的最终位移。n的值由处理器硬件在运行时基于完整操作码字段1674(在本文中随后描述)和数据操纵字段1654c来确定。位移字段1662a和位移因数字段1662b在如下意义上是可选的:其不被用于无存储器访问1605指令模板和/或不同实施例仅可以实施两者之一或者不能实施两者中任何一个。
数据元素宽度字段1664——其内容区分若干数据元素宽度中的哪一个要被使用(在一些实施例中针对所有指令;在其他实施例中仅针对指令中的一些指令)。该字段在如下意义上是可选的:如果仅支持一个数据元素宽度和/或使用操作码的某个方面支持数据元素宽度,则该字段是不需要的。
写屏蔽字段1670——其内容在每个数据元素位置的基础上控制在目的地矢量操作数中的数据元素位置是否反映基本操作和扩充操作的结果。类别a指令模板支持合并写屏蔽,而类别b指令模板支持合并和归零写屏蔽。当合并时,矢量屏蔽允许在目的地中的任何元素集合被保护不受在执行任何操作(由基本操作和扩充操作规定)期间的更新的影响;在另一实施例中,在对应屏蔽位具有0的情况下,保留目的地的每个元素的旧值。相比之下,当归零时,矢量屏蔽允许目的地中的任何元素集合在执行任何操作(由基本操作和扩充操作规定)期间被归零;在一个实施例中,当对应屏蔽位具有0值时,目的地的元素被设置为0。该功能的子集是用于控制被执行的操作的矢量长度(换言之,从第一个到最后一个的被修改的元素的范围)的能力;然而,不必要的是被修改的元素是连续的。因此,写屏蔽字段1670允许部分矢量操作,其包括加载、存储、算术、逻辑等等。虽然描述了写屏蔽字段1670的内容选择若干写屏蔽寄存器中的包含要使用的写屏蔽的一个写屏蔽寄存器(并且因此写屏蔽字段1670的内容间接地标识要执行的屏蔽)的实施例,但是替代实施例替代地或者附加地允许屏蔽写字段1670的内容直接地规定要执行的屏蔽。
即时字段1672——其内容允许对即时的规定。该字段在如下意义上是可选的:该字段不存在于不支持即时的通用矢量友好格式的实施方案中,并且该字段不存在于不使用即时的指令中。
类别字段1668——其内容在不同类别指令之间进行区分。参考图16a-b,该字段的内容在类别a和类别b指令之间选择。在图16a-b中,圆角方形被用于指示在字段中存在具体值(例如,在图16a-b中分别用于类别字段1668的类别a1668a和类别b1668b)。
类别a的指令模板
在类别a的非存储器访问1605指令模板的情况下,alpha字段1652被解译为rs字段1652a,其内容区分不同扩充操作类型中的哪一个要被执行(例如,舍入1652a.1和数据变换1652a.2分别被规定用于无存储器访问、舍入类型操作1610和无存储器访问、数据变换类型操作1615指令模板),而beta字段1654区分所规定的类型的操作中的哪一个要被执行。在无存储器访问1605指令模板中,不存在缩放字段1660、位移字段1662a和位移缩放字段1662b。
无存储器访问指令模板——完全舍入控制类型操作
在无存储器访问完全舍入控制类型操作1610指令模板中,beta字段1654被解译为舍入控制字段1654a,其(多个)内容提供静态舍入。虽然在所描述的实施例中舍入控制字段1654a包括抑制所有浮点异常(sae)字段1656和舍入操作控制字段1658,但是替代的实施例可支持可以将这两个概念都编码到同一字段中或者仅具有这些概念/字段中的一个或者另一个(例如,可以仅具有舍入操作控制字段1658)。
sae字段1656——其内容区分是否要禁用异常事件报告;当sae字段1656的内容指示启用了抑制时,给定的指令不报告任何种类的浮点异常标记并且不发动任何浮点异常处理程序。
舍入操作控制字段1658——其内容区分要执行舍入操作组中的哪一个舍入操作(例如,向上舍入、向下舍入、向零舍入和就近舍入)。因此,舍入操作控制字段1658允许在每个指令的基础上改变舍入模式。在处理器包括用于规定舍入模式的控制寄存器的本发明的一个实施例中,舍入操作控制字段1650的内容改写该寄存器值。
无存储器访问指令模板——数据变换类型操作
在无存储器访问数据变换类型操作1615指令模板中,beta字段1654被解译为数据变换字段1654b,其内容区分若干数据变换中的哪一个要被执行(例如,没有数据变换、拌和、广播)。
在类别a的存储器访问1620指令模板的情况下,alpha字段1652被解译为驱逐暗示字段1652b,其内容区分驱逐暗示中的哪一个要被使用(在图16a中,临时1652b.1和非临时1652b.2分别被规定用于存储器访问、临时1625指令模板和存储器访问、非临时1630指令模板),而beta字段1654被解译为数据操纵字段1654c,其内容区分若干数据操纵操作(也叫做基元)中的哪一个要被执行(例如,不操纵;广播;源的升频转换;以及目的地的降频转换)。存储器访问1620指令模板包括缩放字段1660,并且可选地包括位移字段1662a或者位移缩放字段1662b。
矢量存储器指令使用转换支持执行来自存储器的矢量加载和对存储器的矢量存储。与普通矢量指令一样,矢量存储器指令以按数据元素的方式从存储器传输数据/向存储器传输数据,其中实际上被传输的元素由被选择作为写屏蔽的矢量屏蔽的内容指示。
存储器访问指令模板——临时
临时数据是很可能很快被重用以受益于缓存的数据。然而,这是暗示,并且不同处理器可以以不同方式实施它,包括完全忽略暗示。
存储器访问指令模板——非临时
非临时数据是不太可能很快被重用以受益于第一级缓存中的缓存的数据,并且应该被给予驱逐的优先级。然而,这是暗示,并且不同处理器可以以不同方式实施它,包括完全忽略暗示。
类别b的指令模板
在类别b的指令模板的情况下,alpha字段1652被解译为写屏蔽控制(z)字段1652c,其内容区分由写屏蔽字段1670控制的写屏蔽应该是合并还是归零。
在类别b的非存储器访问1605指令模板的情况下,beta字段1654的一部分被解译为rl字段1657a,其内容区分不同扩充操作类型中的哪一个要被执行(例如,舍入1657a.1和矢量长度(vsize)1657a.2分别被规定用于无存储器访问、写屏蔽控制、部分舍入控制类型操作1612指令模板和无存储器访问、写屏蔽控制、vsize类型操作1617指令模板),而beta字段1654的剩余部分区分所规定的类型的操作中的哪一个要被执行。在无存储器访问1605指令模板中,不存在缩放字段1660、位移字段1662a、和位移缩放字段1662b。
在无存储器访问、写屏蔽控制、部分舍入控制类型操作1610指令模板中,beta字段1654的剩余部分被解译为舍入操作字段1659a,并且异常事件报告被禁用(给定指令不报告任何种类的浮点异常标记,并且不发动任何浮点异常处理程序)。
舍入操作控制字段1659a——正如舍入操作控制字段1658,舍入操作控制字段1659a的内容区分要执行舍入操作组中的哪一个舍入操作(例如,向上舍入、向下舍入、向零舍入和就近舍入)。因此,舍入操作控制字段1659a允许在每个指令基础上改变舍入模式。在处理器包括用于规定舍入模式的控制寄存器的本发明的一个实施例中,舍入操作控制字段1650的内容改写该寄存器值。
在无存储器访问、写屏蔽控制、vsize类型操作1617指令模板中,beta字段1654的剩余部分被解译为矢量长度字段1659b,其内容区分要对若干数据矢量长度中的哪一个执行(例如,128、256、或者512字节)。
在类别b的存储器访问1620指令模板的情况下,beta字段1654的一部分被解译为广播字段1657b,其内容区分广播类型数据操纵操作是否要被执行,而beta字段1654的剩余部分被解译为矢量长度字段1659b。存储器访问1620指令模板包括缩放字段1660,并且可选地包括位移字段1662a或者位移缩放字段1662b。
关于通用矢量友好指令格式1600,示出了完整操作码字段1674,其包括格式字段1640、基本操作字段1642、和数据元素宽度字段1664。虽然示出了一个实施例,在该实施例中完整操作码字段1674包括所有这些字段,但是在不支持所有这些字段的实施例中,完整操作码字段1674包括少于所有这些字段的字段。完整操作码字段1674提供操作码(opcode)。
扩充操作字段1650、数据元素宽度字段1664和写屏蔽字段1670允许这些特征在每个指令的基础上按通用矢量友好指令格式规定。
写屏蔽字段和数据元素宽度字段的组合创建键入的指令,因为其允许屏蔽基于不同数据元素宽度来施加。
在类别a和类别b内找到的各种指令模板在不同情形下是有益的。在一些实施例中,不同处理器或者在一个处理器内的不同核心可能仅支持类别a、仅支持类别b或者支持两个类别。例如,打算用于通用计算的高性能通用无序核心可能仅支持类别b,主要打算用于图形和/或科学(吞吐量)计算的核心可能仅支持类别a,并且打算用于两者的核心可能支持两者(当然,具有来自两个类别的模板和指令的某种混合、但不具有来自两个类别的所有模板和指令的核心处于本发明的范围内)。而且,单个处理器可以包括多个核心,所述多个核心全部都支持同一类别,或者在所述多个核心中不同核心支持不同类别。例如,在具有单独的图形和通用核心的处理器中,主要打算用于图形和/或科学计算的图形核心之一可能仅支持类别a,而通用核心中的一个或者多个可能是具有无序执行和寄存器重命名的、打算用于通用计算的、高性能专用核心,其仅支持类别b。不具有单独的图形核心的另一处理器可以包括支持类别a和类别b两者的一个多个通用有序或者无序核心。当然,来自一个类别的特征也可以在不同的实施例中在其他类别中实施。用高级语言编写的程序将被置于(例如,及时编译或者静态编译成)各种各样的不同的可执行形式,这些可执行形式包括:1)仅具有由目标处理器支持以用于执行的(多个)类别的指令的形式;或者2)具有替代例程并且具有控制流代码的形式,所述替代例程使用所有类别的指令的不同组合来编写,所述控制流代码基于由当前正执行代码的处理器支持的指令来选择要执行的例程。
示范性具体矢量友好指令格式
图17是图示按照一个实施例的示范性具体矢量友好指令格式的框图。图17示出具体矢量友好指令格式1700,该格式在如下意义上是具体的:该格式规定字段的位置、大小、解译、和次序以及用于那些字段中的一些字段的值。具体矢量友好指令格式1700可以被用于扩展x86指令集,并且因此字段中的一些字段与在现有x86指令集及其扩展(例如,avx)中使用的那些字段相似或者相同。该格式保持与具有扩展的现有x86指令集的前缀编码字段、实际操作码字节字段、modr/m字段、sib字段、位移字段、和即时字段一致。来自图16的字段被图示,来自图17的字段映射到来自图16的字段。
应该理解,虽然为了说明目的在通用矢量友好指令格式1600的上下文中参考具体矢量友好指令格式1700描述了实施例,但是本发明不限于该具体矢量友好指令格式1700,除非被主张。例如,通用矢量友好指令格式1600预期用于各种字段的各种各样的可能大小,而具体矢量友好指令格式1700被示出为具有具体大小的字段。用具体示例的方式,虽然数字元素宽度字段1664被图示为在具体矢量友好指令格式1700中的1位字段,但是本发明并非如此受限制(即,通用矢量友好指令格式1600预期数据元素宽度字段1664的其他大小)。
通用矢量友好指令格式1600包括按图17a中所图示的次序的以下列出的下列字段。
evex前缀(字节0-3)1702——以四字节形式被编码。
格式字段1640(evex字节0,位[7:0])——第一字节(evex字节0)是格式字段1640,并且其包含0x62(在本发明的一个实施例中被用于区分矢量友好指令格式的唯一值)。
第二字节至第四字节(evex字节1-3)包括提供具体能力的若干位字段。
rex字段1705(evex字节1,位[7-5])——由evex.r位字段(evex字节1,位[7]-r)、evex.x位字段(evex字节1,位[6]-x)、和1657bex字节1,位[5]-b)构成。evex.r、evex.x和evex.b位字段提供与对应的vex位字段相同的功能,并且使用1的补码形式来编码,即,zmm0被编码为1111b,zmm15被编码为0000b。指令的其他字段对寄存器索引的较低三个位进行编码,如在本领域中已知的(rrr、xxx和bbb),使得rrrr、xxxx和bbbb可以通过添加evex.r、evex.x和evex.b而形成。
rex’字段1610——这是rex’字段1610的第一部分,并且是被用于对扩展的32个寄存器集合的较高16个寄存器或者较低16个寄存器编码的evex.r’位字段(evex字节1,位[4]-r’)。在本发明的一个实施例中,该位连同如以下指示的其他位以位反转的格式被存储,以与bound指令相区分(在众所周知的x8632位模式中),所述bound指令的实际操作码字节是62,但是在modr/m字段(以下描述)中不接受mod字段中的11的值;替代的实施例不以反转格式存储这个位和其他以下所指示的位。1的值被用于对较低16个寄存器进行编码。换言之,r’rrrr是通过将evex.r’、evex.r和来自其他字段的其他rrr组合形成的。
操作码映射字段1715(evex字节1,位[3:0]-mmmm)——其内容对所暗示的前导操作码字节(0f、0f38或者0f3)进行编码。
数据元素宽度字段1664(evex字节2,位[7]-w)——由符号evex.w表示。evex.w被用于定义数据字节(32位数据元素或者64位数据元素)的粒度(大小)。
evex.vvvv1720(evex字节2,位[6:3]-vvvv)——evex.vvvv的角色可以包括以下项:1)evex.vvvv对以反转(1的补码)形式规定的第一源寄存器操作数进行编码并且对具有2个或者更多个源操作数的指令有效;2)evex.vvvv对以1的补码形式规定的目的寄存器操作数进行编码,以用于特定矢量移位;或者3)evex.vvvv不对任何操作数进行编码,该字段被预留并且应该包含1111b。因此,evex.vvvv字段1720对以反转(1的补码)形式存储的第一源寄存器说明符的4个低阶位进行编码。取决于指令,使用额外的不同evex位宇段来将说明符大小扩展至32个寄存器。
evex.u1668类别字段(evex字节2,位[2]-u)——如果evex.u=0,则其指示类别a或者evex.u0;如果evex.u=1,则其指示类别b或者evex.u1。
前缀编码字段1725(evex字节2,位[1:0]-pp)——提供用于基本操作字段的附加位。除了提供对evex前缀格式的旧有sse指令的支持之外,这也具有压缩simd前缀的益处(而不是要求字节表达simd前缀,evex前缀仅要求2位)。在一个实施例中,为了支持使用simd前缀(66h、f2h、f3h)的按旧有格式并按evex前缀格式的旧有sse指令,这些旧有simd前缀被编码到simd前缀编码字段中;并且在运行时在被提供到解码器的pla(所以pla可以在没有修改的情况下执行这些旧有指令的旧有和evex格式)之前被扩展成旧有simd前缀。虽然更新的指令可以直接使用evex前缀编码字段的内容作为操作码扩展,但是确定实施例为了一致性以相似方式扩展,但允许由这些旧有simd前缀规定不同意义。替代实施例可以将pla重新设计成支持2位simd前缀编码,并且因此不要求扩展。
alpha字段1652(evex字节3,位[7]-eh;也叫做evex.eh、evex.rs、evex.rl、evex.写屏蔽控制和evex.n;也以α图示)——如先前所描述的,该字段是特定于上下文的。
beta字段1654(evex字节3,位[6:4]-sss;也叫做evex.s2-0、evex.r2-0、evex.rr1、evex.ll0、evex.llb;也以βββ图示)——如先前所描述的,该字段是特定于上下文的。
rex’字段1610——这是rex’字段的剩余部分,并且是evex.v’位字段(evex字节3,位[3]-v’),其可以被用于对扩展的32个寄存器集合的较高16个寄存器或者较低16个寄存器编码。该位可以以位反转格式被存储。1的值被用于对较低16个寄存器编码。换言之,v’vvvv是通过组合evex.v’、evex.vvvv形成的。
写屏蔽字段1670(evex字节3,位[2:0]-kkk)——其内容规定如先前所描述的写屏蔽寄存器中的寄存器的索引。在本发明的一个实施例中,具体值evex.kkk=000具有暗示没有写屏蔽被用于特定指令(这可以以各种各样的方式实施,所述方式包括使用硬连线到所有1的写屏蔽或者绕过屏蔽硬件的硬件)的特殊行为。
实际操作码字段1730(字节4)也叫做操作码字节。操作码的一部分在该字段中规定。
modr/m字段1740(字节5)包括mod字段1742、reg字段1744、和r/m字段1746。如先前所描述的,mod字段1742的内容在存储器访问和非存储器访问操作之间进行区分。reg字段1744的角色可以被总结为两种情形:对目的寄存器操作数或者源寄存器操作数编码,或者被看作操作码扩展,并且不被用于对任何指令操作数编码。r/m字段1746的角色可以包括以下项:对引用存储器地址的指令操作数编码,或者对目的寄存器操作数或者源寄存器操作数编码。
缩放、索引、基础(sib)字节(字节6)——如先前所描述的,缩放字段1650的内容被用于存储器地址生成。sib.xxx1754和sib.bbb1756——这些字段的内容先前已经关于寄存器索引xxxx和bbbb被提及。
位移字段1662a(字节7-10)——当mod字段1742包含10时,字节7-10是位移字段1662a,并且其与旧有32位位移(disp32)相同地工作,并且以字节粒度工作。
位移因数字段1662b(字节7)——当mod字段1742包含01时,字节7是位移因数字段1662b。该字段的位置与旧有x86指令集8位位移(disp8)的位置相同,其以字节粒度工作。因为disp8是符号扩展的,所以其仅能在-128和127字节偏移量之间寻址;就64字节缓存行而言,disp8使用可以被设置成仅四个真正有用的值-128、-64、0和64的8位;因为常常需要更大范围,所以使用disp32;然而,disp32要求4字节。与disp8和disp32相反,位移因数字段1662b是disp8的重新解译;当使用位移因数字段1662b时,实际位移由位移因数字段的内容乘以存储器操作数访问的大小(n)来确定。这种类型的位移被称为disp8*n。这减少平均指令长度(用于位移但具有大得多的范围的单个字节)。这样的压缩位移基于如下假设:有效的位移是存储器访问的粒度的倍数,并且因此,地址偏移量的冗余低阶位不需要被编码。换言之,位移因数字段1662b替代旧有的x86指令集8位位移。因此,位移因数字段1662b以与x86指令集8位位移相同的方式编码(所以在modrm/sib编码规则方面没有改变),其中唯一例外是disp8被过载成disp8*n。换言之,在编码规则或者编码长度方面不存在改变,但是仅仅在硬件对位移值的解译方面存在改变(其需要将位移缩放存储器操作数的大小,以获取按字节的地址偏移量)。
即时字段1672如先前所描述的那样操作。
完整操作码字段
图17b是图示按照本发明的一个实施例的具体矢量友好指令格式1700的字段的框图,所述字段构成完整操作码字段1674。具体地,完整操作码字段1674包括格式字段1640、基本操作字段1642、和数据元素宽度(w)字段1664。基本操作字段1642包括前缀编码字段1725、操作码映射字段1715、和实际操作码字段1730。
寄存器索引字段
图17c是图示按照本发明的一个实施例的具体矢量友好指令格式1700的字段的框图,所述字段构成寄存器索引字段1644。具体地,寄存器索引字段1644包括rex字段1705、rex’字段1710、modr/m.reg字段1744、modr/m.r/m字段1746、vvvv字段1720、xxx字段1754、和bbb字段1756。
扩充操作字段
图17d是图示按照本发明的一个实施例的具体矢量友好指令格式1700的字段的框图,所述字段构成扩充操作字段1650。当类别(u)字段1668包含0时,其意味着evex.u0(类别a1668a);当其包含1时,其意味着evex.u1(类别b1668b)。当u=0并且mod字段1742包含11(意味着无存储器访问操作)时,alpha字段1652(evex字节3,位[7]-eh)被解译为rs字段1652a。当rs字段1652a包含1(舍入1652a.1)时,beta字段1654(evex字节3,位[6:4]-sss)被解译为舍入控制字段1654a。舍入控制字段1654a包括1位sae字段1656和2位舍入操作字段1658。当rs字段1652a包含0(数据变换1652a.2)时,beta字段1654(evex字节3,位[6:4]-sss)被解译为3位数据变换字段1654b。当u=0并且mod字段1742包含00、01或者10(意味着存储器访问操作)时,alpha字段1652(evex字节3,位[7]-eh)被解译为驱逐暗示(eh)字段1652b,并且beta字段1654(evex字节3,位[6:4]-sss)被解译为3位数据操纵字段1654c。
当u=1时,alpha字段1652(evex字节3,位[7]-eh)被解译为写屏蔽控制(z)字段1652c。当u=1并且mod字段1742包含11(意味着无存储器访问操作)时,beta字段1654的一部分(evex字节3,位[4]-s0)被解译为rl字段1657a;当其包含1(舍入1657a.1)时,beta字段1654的剩余部分(evex字节3,位[6-5]-s2-1)被解译为舍入操作字段1659a,而当rl字段1657a包含0(vsize1657.a2)时,beta字段1654的剩余部分(evex字节3,位[6-5]-s2-1)被解译为矢量长度字段1659b(evex字节3,位[6-5]-l1-0)。当u=1并且mod字段1742包含00、01或者10(意味着存储器访问操作)时,beta字段1654(evex字节3,位[6:4]-sss)被解译为矢量长度字段1659b(evex字节3,位[6-5]-l1-0)和广播字段1657b(evex字节3,位[4]-b)。
示范性寄存器架构
图18是按照本发明的一个实施例的寄存器架构1800的框图。在所图示的实施例中,存在512位宽的32个矢量寄存器1810;这些寄存器被称为zmm0到zmm31。较低16个zmm寄存器的低阶256位被覆加在寄存器ymm0-16上。较低16个zmm寄存器的低阶128位(ymm寄存器的低阶128位)被覆加在寄存器xmm0-15上。具体矢量友好指令格式1700对以下表4中所图示的这些被覆加的寄存器文件起作用。
表4-寄存器
换言之,矢量长度字段1659b在最大长度和一个或者多个其他较短长度之间进行选择,其中每个这样的较短长度是在前长度的一半长度;并且没有矢量长度字段1659b的指令模板对最大矢量长度起作用。此外,在一个实施例中,具体矢量友好指令格式1700的类别b指令模板对紧缩或者标量单精度/双精度浮点数据和紧缩或者标量整数数据起作用。标量操作是对zmm/ymm/xmm寄存器中的最低阶数据元素位置执行的操作;取决于该实施例,更高阶数据元素位置或者与其在指令之前保持相同,或者被归零。
写屏蔽寄存器1815——在所图示的实施例中,存在8个写屏蔽寄存器(k0到k7),每个大小为64位。在替代实施例中,写屏蔽寄存器1815大小为16位。如先前所描述的,在本发明的一个实施例中,矢量屏蔽寄存器k0不能被用作写屏蔽;当将通常指示k0的编码被用于写屏蔽时,其选择0xffff的硬连线写屏蔽,从而有效禁用对该指令的写屏蔽。
通用寄存器1825——在所图示的实施例中,存在16个64位通用寄存器,这些通用寄存器与现有x86寻址模式一起被用于对存储器操作数寻址。这些寄存器通过名称rax、rbx、rcx、rdx、rbp、rsi、rdi、rsp、和r8到r15来引用。
标量浮点堆栈寄存器文件(x87堆栈)1845,在该标量浮点堆栈寄存器文件上混叠了mmx紧缩整数平面寄存器文件1850——在所图示的实施例中,x87堆栈是8元素堆栈,其被用于使用x87指令集扩展对32/64/80位浮点数据执行标量浮点操作;在mmx寄存器被用于对64位紧缩整数数据执行操作的同时,以及用于针对在mmx和xmm寄存器之间执行的一些操作保持操作数。
替代实施例可以使用更宽或者更窄的寄存器。附加地,替代实施例可以使用更多、更少或者不同寄存器文件和寄存器。
在前述说明书中,本发明已经参考其具体示范性实施例被描述。然而,将明显的是,可以对所述具体示范性实施例作出各种修改和改变,而不偏离在所附权利要求中阐述的本发明的更宽的精神和范围。说明书和附图因此应在说明性的而不是限制性的意义上来看待。
本文中所描述的指令指代诸如专用集成电路(asic)之类的硬件的具体配置,所述硬件被配置成执行特定操作或者具有预定功能。这样的电子设备典型地包括耦合到一个或者多个其他组件的一个或者多个处理器的集合,所述一个或者多个其他组件诸如是一个或者多个存储设备(非瞬时性机器可读存储介质)、用户输入/输出设备(例如,键盘、触摸屏、和/或显示器)、和网络连接。处理器集合与其他组件的耦合典型地通过一个或者多个总线和桥(也被称为总线控制器)。存储设备和承载网络业务的信号分别表示一个或者多个机器可读存储介质和机器可读通信介质。因此,给定的电子设备的存储设备典型地存储用于在该电子设备的一个或者多个处理器的集合上执行的代码和/或数据。
当然,本发明的实施例的一个或者多个部分可以使用软件、固件、和/或硬件的不同组合来实施。贯穿本详细的说明书,为了解释的目的,阐述了许多具体细节,以便提供对本发明的透彻理解。然而,对于本领域技术人员将显而易见的是,本发明可以在不具有这些具体细节中的一些细节的情况下被实践。在特定实例中,众所周知的结构和功能没有以详尽细节描述,以便避免使本发明的主题难理解。因此,本发明的范围和精神应该就随后的权利要求而言来评判。
- 还没有人留言评论。精彩留言会获得点赞!