一种自动寻优型电力负荷分类方法与流程
本发明涉及一种自动寻优型电力负荷分类方法,属于负荷特性分类技术领域。
背景技术:
目前的电力负荷分类主要是按照用电负荷的行业性质来分的,分为居民生活、商业、工业、农业生产等几类用电负荷。这种分类方法并不能反应用户负荷的具体特性,该分类方法不仅缺乏分类科学依据,并且没有实际意义,特别是对于工业负荷,由于工业负荷种类繁多,如冶金、钢铁、石油、化工、机械、水泥、煤炭、电气化铁道、铝业加工等,仅仅简单地把其分为大工业及不同工业用户太过简单。因此,到目前为止,虽然对于电力负荷分类有很多种分类方法,但这些分类方法都没有考虑到负荷的具体特性,没有利用负荷的典型日负荷曲线数据,这些负荷分类方法在电力需求侧管理及电力市场的电价政策制定上缺乏根据。
技术实现要素:
本发明的目的是提供一种自动寻优型电力负荷分类方法,以解决目前分类方法没有利用负荷的典型日负荷曲线数据导致在电力需求侧管理及电力市场的电价政策制定上缺乏根据。
本发明为解决上述技术问题提供了一种自动寻优型电力负荷分类方法,该分类方法的步骤如下:
1)获取典型日负荷曲线数据,并对其进行归一化处理;
2)令电力负荷分类数n=2;
3)采用k-means均值聚类算法对电力负荷进行分类,并计算每个分类的聚类中心值曲线,计算聚类中心值曲线的平均距离ma,以及每个分类的各负荷曲线到聚类中心值曲线的距离mb,并以这两者的比值kn=mb/ma作为最优分类结果比较变量z;
4)令n=n+1,重复步骤3)得到更新后的比值kn,将更新后的比值kn与z进行比较,若kn<z,用当前的kn值替换z,在kn>z时不做替换,直至分类结果中含有空的数据或相邻两次分类结果中的kn的差值δkn=|kn+1-kn|与kn的比值小于设定的收敛条件δkn/kn<εset,并以此时的变量z对应的分类作为最终的最优分类。
所述步骤1)中的典型日负荷曲线的获取过程如下:
a.提取日负荷曲线数据库中一段时间内有相近负荷特性的日负荷曲线数据;
b.对所提取的日负荷曲线数据中的空数据或奇异点数据进行插值拟合处理;
c.对拟合处理后的日负荷曲线数据进行加权平均值处理。
所述当负荷分类数n大于或等于1/4电力负荷数时,自动停止寻优操作。
本发明的有益效果是:本发明采用k-means均值聚类算法对电力负荷进行分类,并计算每个分类的聚类中心值曲线,计算聚类中心值曲线的平均距离ma,以及每个分类的各负荷曲线到聚类中心值曲线的距离mb,并以这两者的比值kn=mb/ma作为最优分类结果比较变量z;令n=n+1,重复上述过程得到更新后的比值kn,将更新后的比值kn与z进行比较,若kn<z,用当前的kn值替换z,在kn>z时不做替换,直至分类结果中含有空的数据或相邻两次分类结果中的kn的差值与kn的比值小于设定的收敛条件,并以此时的变量z对应的分类作为最终的最优分类。本发明大大减少了负荷分类的人工寻优判别时间,同时减少了人工判别的误差与不准确度,特别适应于多负荷数据的后台系统中应用。本发明提出的自动寻优型负荷分类方法不需要人工参与,可以利用编制的软件自动实现最优负荷分类。
附图说明
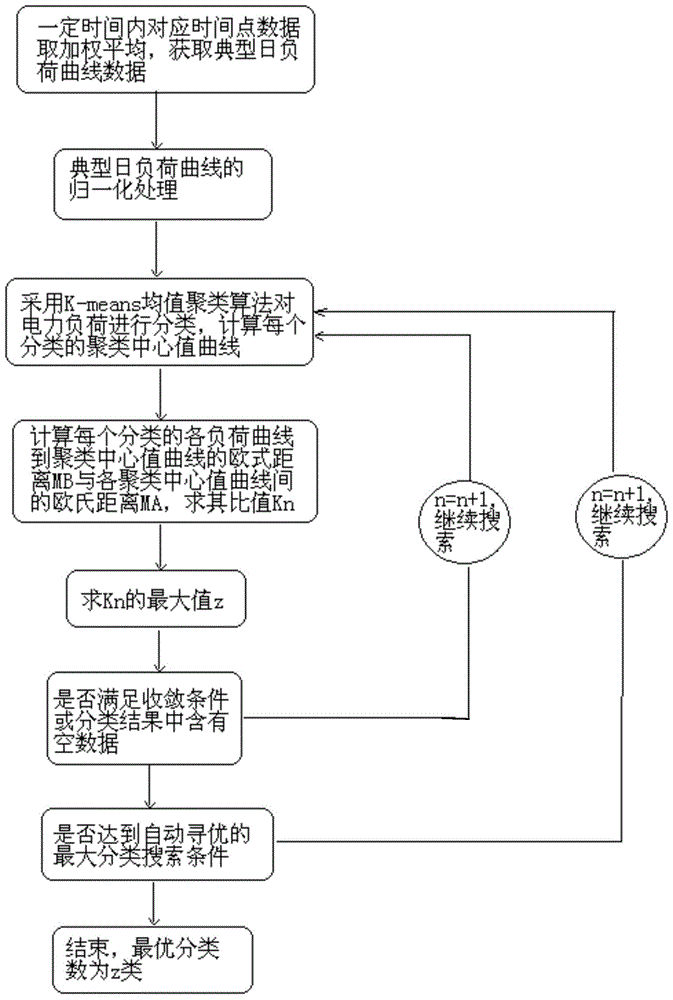
图1是本发明自动寻优型电力负荷分类方法的流程图。
具体实施方式
下面结合附图对本发明的具体实施方式做进一步的说明。
本发明针对目前电力负荷分类方法所存在的缺陷,提供了一种自动寻优型电力负荷分类方法,该方法采用k-means均值聚类算法对电力负荷进行分类,并计算每个分类的聚类中心值曲线,计算聚类中心值曲线的平均距离ma,以及每个分类的各负荷曲线到聚类中心值曲线的距离mb,并以这两者的比值kn=mb/ma作为最优分类结果比较变量z;令n=n+1,重复上述过程得到更新后的比值kn,将更新后的比值kn与z进行比较,若kn<z,用当前的kn值替换z,在kn>z时不做替换,直至分类结果中含有空的数据或相邻两次分类结果中的kn的差值与kn的比值小于设定的收敛条件,并以此时的变量z对应的分类作为最终的最优分类。该方法的具体流程如图1所示,具体实施步骤如下。
1.获取典型日负荷特征曲线,并对其进行归一化处理。
首先利用一段时间内(通常取一个月)的日负荷有功功率曲线数据,将这些数据中的对应时间点数据取加权平均值,作为该负荷的典型日负荷曲线数据,获取各种进行分类负荷的典型日负荷特征曲线。在具体实施时其数据源为用电信息管理系统的每个用户的日负荷曲线数据库,提取该数据库中一段时间内有相近负荷特性的日负荷曲线数据(如夏季时统一取空调运行的连续相近日),通过对数据库中提取的日负荷曲线数据中的空数据或奇异点数据进行插值拟合处理后,再进行加权平均值处理,所得到的日负荷特征曲线即为典型日负荷特征曲线。
然后取每个用户的典型日负荷曲线的有功功率最大值作为功率基准值,将96点的日负荷曲线数据除以该功率基准值,得到各种需要分类负荷的日96点的典型日负荷曲线数据的归一化处理值(标幺值),处理后的日负荷曲线数据标幺值的最大值为1,其它点的数据标幺值λ在0-1之间变化。
2.取电力负荷分类数n=2。
3.采用k-means均值聚类算法对电力负荷进行分类,并计算每个分类的聚类中心值曲线,计算聚类中心值曲线的平均距离ma,以及每个分类的各负荷曲线到聚类中心值曲线的距离mb,并以这两者的比值kn=mb/ma作为最优分类结果比较变量z。
本实施例中采用k-means均值聚类算法对电力负荷特性进行分类,计算分类结果的每类聚类中心值曲线,然后分别计算聚类中心值曲线的平均欧式距离ma,计算每个聚类的各个负荷曲线到聚类中心的平均欧式距离mb,求这两者的比值kn=mb/ma.将该值暂时作为最优值存入最优分类结果比较变量z中,z=kn。
4.取n=n+1,重复步骤3计算新分类结果的聚类中心值曲线及ma、mb,同时取比值kn=mb/ma,将该值与z进行比较,若kn<z,用当前的kn值替换z;在kn>z时不做替换。
5.若分类结果中含有空的数据或相邻两次分类结果中的kn的差值δkn=|kn+1-kn|与kn的比值小于设定的收敛条件δkn/kn<εset,停止寻优分类,进入步骤e,否则,取n=n+1,重复步骤a,继续寻优分类;或者在负荷分类数n大于或等于1/4电力负荷数时,自动停止寻优操作。
6.将最后的z作为最优负荷分类的最终分类结果。
本发明提出的自动寻优型电力负荷类方法的通常用于供电公司的用电信息管理系统,用于对用电信息管理系统的所有用户进行负荷分类、负荷特性分析、用电能效分析与管理以及用户节电效果分析与指导等工作。得到最优化的负荷分类结果(负荷分类数n及分类的聚类中心值曲线),利用这些最优分类结果的数据即可进行负荷特性分析(计算其峰谷差值比等)、分析其能效特性,并能够和同行业的负荷特性进行类比,寻找出用电能效较差和较好的用户,对能效及节电效果差的用户提出节电及提升能效的改进措施,从而达到降峰填谷的效果,节省用户的用电支出,使供电部门与用户双方都获利。
- 还没有人留言评论。精彩留言会获得点赞!