图像数据库的建立方法及图像识别方法与流程
本发明涉及图像识别技术领域,特别是涉及一种图像数据库的建立方法及图像识别方法。
背景技术:
目前的图像识别系统结构,每张图片的特征值用一个特征值矩阵表述,数据量巨大,耗费大量的内存,单台服务器能够存储的数据量有限,因此限制了大规模的图像搜索的实现,且图像搜索的速度也受到了限制。
因此,需要提供一种图像数据库的建立方法及图像识别方法以解决上述技术问题。
技术实现要素:
本发明主要解决的技术问题是提供一种图像数据库的建立方法及图像识别方法,以解决现有技术的图像存储数据量巨大造成搜索大量图像难以实现、搜索速度慢的问题。
为解决上述技术问题,本发明采用的第一技术方案是提供一种图像数据库的建立方法,包括步骤:
⑴采集目标图片,并为每张图片打上名称标签,并把打上标签的目标图片存放进图片集队列;
⑵推出图片集队列的首位图片;
⑶提取所述首位图片的局部特征点;
⑷计算局部特征点的特征值,并将每张图片的特征值以一个n×m矩阵的形式表述;
⑸把上述n×m矩阵所表述的数据放进一个向量化引擎中,使得图片的特征点表达为一个低纬度的向量[v1v2...vk];
⑹把低纬度的向量[v1v2...vk]存入特征向量数据库;
⑺判断图片集队列是否为空,若是,则结束,若否,则回到步骤⑵;
其中,m、n和k都是正整数,且k<<n×m。
本发明的图像数据库的建立方法的优选实施例中,所述步骤(5)包括:
a、加载所有图片的特征矩阵,并合并这些特征矩阵形成一个矩阵m;
b、在特征值空间随机生成10000个中心特征值,所述的10000个中心特征值组成中心特征点向量c=[c1c2c3...c10000];
c、取出m的每一行fi=m[i],找到fi最邻近的中心特征值cj;
d、更新c=[c1c2c3...c10000]里的每一个cj,使得cj是最邻近fi的几何中心点;
e、重复步骤c和d,直到每一个cj的位置变化都小于一个预定的阈值,保存中心特征点向量c=[c1c2c3...c10000];
f、对于一个新图片的特征矩阵m′的每一行fi′=m′[i],找到c=[c1c2c3...c10000]里面与之最邻近的中心点;
g、计算c=[c1c2c3...c10000]在m′的直方图,得到向量v=[v1v2...vk],并输出向量v=[v1v2...vk],结束;
其中,i是矩阵m的行数,j是cj在c=[c1c2c3...c10000]中序数。
为解决上述技术问题,本发明采用的第二技术方案是提供一种图像识别方法,该图像识别方法基于上述任意一项所述的图像数据库的建立方法,包括步骤:
(8)输入图片;
(9)提取图片的局部特征点;
(10)计算特征点特征值,所述特征值采用一个n×m矩阵的形式表述;
(11)向量化输入图片的特征点矩阵表述;
(12)搜索特征向量数据库以匹配输入的图片的向量化特征点矩阵;
(13)输出匹配结果,完成搜索;
其中,m和n都是正整数。
本发明的有益效果是:区别于现有技术的情况,本发明提供的图像数据库的建立方法及图像识别方法,通过将图像的特征值矩阵描述进行低纬度向量化转化,可以有效降低需要保存的数据量,单台服务器可以保存更多的图像数据,能够支持大规模的图像搜索的实现,且可加快图像匹配搜索的速度。
附图说明
图1是本发明的图像数据库的建立方法的实施例的流程示意图;
图2是图1中步骤(5)的详细流程示意图;
图3是本发明的图像识别方法的流程示意图。
具体实施方式
下面结合图示对本发明的技术方案进行详述。
请参见图1所示,本发明的图像数据库的建立方法,包括步骤:
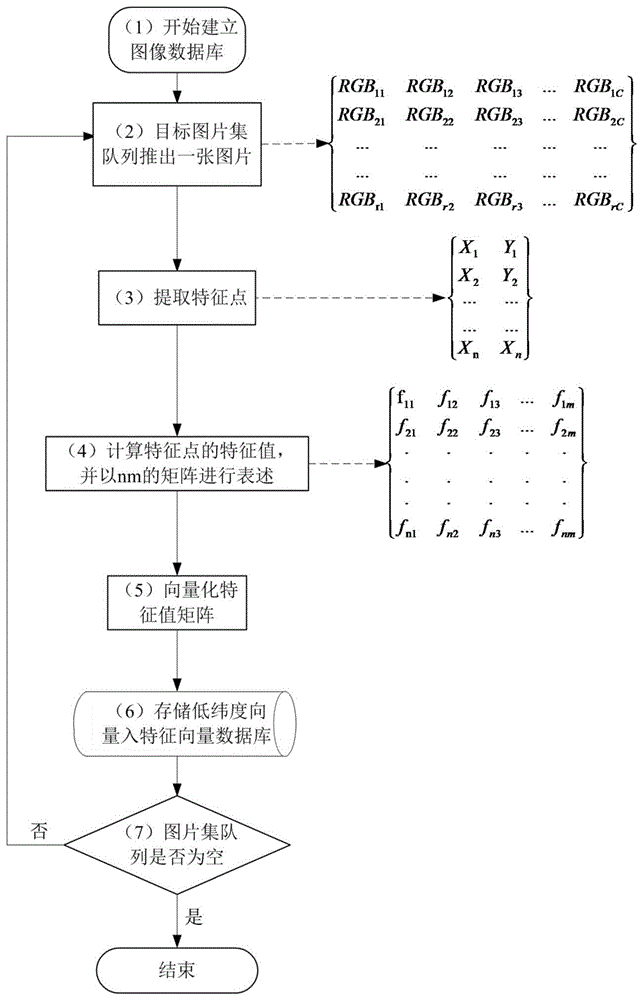
⑴开始建立图像数据库:采集目标图片,并为每张图片打上名称标签,并把打上标签的目标图片存放进图片集队列;
⑵推出图片集队列的首位图片,如图1所示,推出的该张图片可以用行列式
⑶提取该首位图片的局部特征点,局部特征点集合可以用坐标集
⑷计算局部特征点的特征值,并将该图片的特征值以一个n×m矩阵
⑸向量化特征值矩阵,具体为:把上述n×m矩阵所表述的数据放进一个向量化引擎中,使得图片的特征点表达为一个低纬度的向量[v1v2...vk];
⑹把低纬度的向量[v1v2...vk]存入特征向量数据库;
⑺如图1所示,判断图片集队列是否为空,若是,则结束,若否,则回到步骤⑵;
其中,m、n和k都是正整数,且k<<n×m。
由于k<<n×m,使得图片的特征值表述的数据量大大减少,节约了内存空间。
在本发明的图像数据库的建立方法的一个优选实施例中,如图2所示,图1中步骤(5)包括:
a、加载所有图片的特征矩阵,并合这些特征矩阵形成一个矩阵m,因此每个图片的小矩阵特征值表述变为所有图片的大矩阵特征值表述,该步骤a包括依次按时间顺序排列的步骤a1、a2和a3,a1为:开始,a2为:加载所有图片的特征矩阵,a3为:合并这些特征矩阵形成一个矩阵m;
b、在特征值空间随机生成10000个中心特征值,所述的10000个中心特征值组成中心特征点向量c=[c1c2c3...c10000];
c、取出m的每一行fi=m[i],找到fi最邻近的中心特征值cj,包括依次按时间顺序进行的步骤λ1、λ2、λ3和λ4,其中,λ1为i=0,λ2为fi=m[i],λ3为找到与fi最邻近的点cj,λ4为判断i的行数是否小于m的总行数,若是则回到步骤λ2,否则执行步骤d;
d、更新c=[c1c2c3...c10000]里的每一个cj,使得cj是最邻近fi的几何中心点,具体如依次按时间顺序排列的d1、d2、d3,d1为:i=0,d2为更新cj,使得cj是最邻近fi的几何中心点,d3为判断i是否小于10000,若是,在回到步骤d1,若否,则执行步骤e;
e、重复步骤c和d,直到每一个cj的位置变化都小于一个预定的阈值,保存中心特征点向量c=[c1c2c3...c10000],其中步骤e步骤按时间顺序排列的e1和e2,步骤e1具体为判断每一个cj的位置变化都小于一个预定的阈值?若是,则执行步骤e2保存中心特征点向量c=[c1c2c3...c10000],否则回到步骤c;
f、包括f1和f2,f1:引入新图片的特征值矩阵m′,f2:对于一个新图片的特征矩阵m′的每一行fi′=m′[i],找到c=[c1c2c3...c10000]里面与之最邻近的中心点cj;
g、计算c=[c1c2c3...c10000]在m′的直方图,得到向量v=[v1v2...vk],并输出向量v=[v1v2...vk],结束,步骤g包括按时间顺序排列的步骤g1、g2、g3,其中,步骤g1为统计每一个cj的数量,并把该数量的数目设成c=[c1c2c3...c10000]在该维度上的值,步骤g2为输出向量,g3为结束;
其中,i是矩阵m的行数,j是cj在c=[c1c2c3...c10000]中序数。
如图3所示,本发明提供的图像识别方法,该图像识别方法基于上述任意一项所述的图像数据库的建立方法,包括步骤:
(8)输入图片,该张图片可以用行列式
(9)提取该图片的局部特征点
(10)计算特征点特征值,所述特征值采用一个n×m矩阵的形式表述;
(11)向量化输入图片的特征点矩阵表述;
(12)搜索特征向量数据库以匹配输入的图片的向量化特征点矩阵;
(13)输出匹配结果,完成搜索,其中,输出匹配的结果包括:1、在特征向量数据库中找到了相匹配的图片,则调取相匹配的图片的目录信息,否则,输出未找到匹配的信息,然后结束搜索;
其中,m和n都是正整数。
其中,在图3中步骤(1)-(7)是本发明的第一技术方案的图像数据的建立方法的步骤,对此不做赘述。
本发明提供的图像识别方法,单次搜索的时间得到有效缩短,且由于图像数据库的建立方法特征向量数据库占用内存得到减少,使得图像识别方法可以实现大规模的图像的搜索的实现。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!