文本特征提取方法、文本分类方法及装置与流程
本申请涉及互联网数据处理
技术领域:
,尤其涉及一种文本特征提取、文本分类方法及装置。
背景技术:
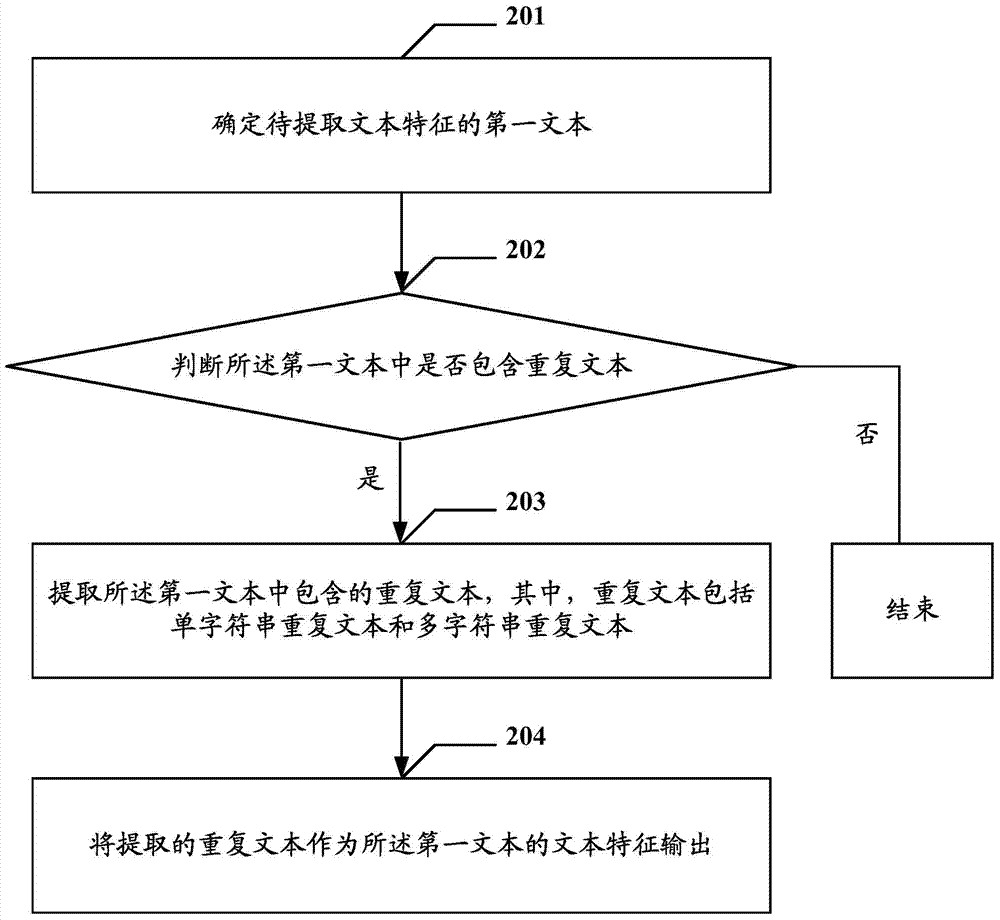
:随着微博、社交网站和即时通讯工具等应用的发展,越来越多的信息开始以短文本的形式呈现,并且呈爆炸式增长,尤其是大型电子商务的服务中心接收到的咨询。为了高效地处理海量的短文本信息,通常需要先对短文本信息进行自动分类,而后再按照类别对短文本信息进行相应的处理,而文本特征提取则是文本分类的重要基础。现有的文本特征提取方法大多通过对文本使用分词算法进行分词处理后得到文本特征。常见的分词算法是基于词典匹配的算法。词典是基于词典的匹配算法所必须的数据。现有技术中,词典生成都必须依靠人工筛选和分词器切分,这就使得当面对新的业务,微博的评论或商品的评论等比较自由的短文本的时候,由于会出现未在已有的分词器使用的词典中登录的新词语,因此,分词器就无法切分出正确的词条,分词效果就不好。若想取得较好的分词效果,就要不断的更新或优化词典和优化分词算法,而且不同的业务就要更新或优化不同的词典。例如,针对下表(1)中所示的客户问题,如果是由比较常规的分词器,不知道“支付宝”以及“余额宝”是一个产品,则将在分词时,会把“支付”和“宝”分开,以及“余额”和“宝”分开,进而把“支付”和“宝”以及“余额”和“宝”作为独立的特征去参与分类,此时表达的意思就会有问题。此外,针对新的网络用语“萌妹纸”、“冷暖男”;分词器分出的特征为“萌妹”和“纸”,以及“冷”“暖男”,显然,分词后表达的意思也是错误的。用户问题不好的特征支付宝付不了款怎么办支付|宝|付不了款|怎么办余额宝查不到收益怎么办余额|宝|查不到|收益|怎么办充电宝没有收到货怎么办充电|宝|没有|收到货|怎么办你这个萌妹纸你|这个|萌妹|纸淘宝你们就是冷暖男淘宝|你们|就是|冷|暖男表(1)综上所述,现有的文本特征提取方法存在过于依赖已有分词器,无法提取未登录的词条等文本特征。技术实现要素:本申请实施例提供一种文本特征提取、文本分类方法及装置,用以解决方法存在过于依赖已有分词器,无法提取未登录的词条等文本特征的问题。一种文本特征提取方法,包括:确定待提取文本特征的第一文本,以及至少一个用于提取文本特征的第一滑动窗口和相应的滑动步长;针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符;将提取的字符串作为所述第一文本的文本特征输出。一种文本分类方法,包括:利用文本特征提取方法提取待分类文本中的文本特征,其中,所述文本特征提取方法包括:确定待提取文本特征的第一文本,以及至少一个用于提取文本特征的第一滑动窗口和相应的滑动步长;针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符;将提取的字符串作为所述第一文本的文本特征输出;将提取的待分类文本中的文本特征输入文本分类模型,得到待分类文本的类别,得到待分类文本的类别,其中,所述文本分类模型为预先根据文本样本对预置的分类模型进行训练,得到根据待分类文本的文本特征对该待分类文本进行分类的文本分类模型。一种文本特征提取装置,包括:确定单元,用于确定待提取文本特征的第一文本,以及至少一个用于提取文本特征的第一滑动窗口和相应的滑动步长;第一处理单元,用于针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符;输出单元,用于将提取的字符串作为所述第一文本的文本特征输出。一种文本分类装置,包括:文本特征提取单元,用于利用文本特征提取方法提取待分类文本中的文本特征,其中,所述文本特征提取方法包括:确定待提取文本特征的第一文本,以及至少一个用于提取文本特征的第一滑动窗口和相应的滑动步长;针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符;将提取的字符串作为所述第一文本的文本特征输出;分类单元,用于将提取的待分类文本中的文本特征输入文本分类模型,得到待分类文本的类别,得到待分类文本的类别,其中,所述文本分类模型为预先根据文本样本对预置的分类模型进行训练,得到根据待分类文本的文本特征对该待分类文本进行分类的文本分类模型。本申请实施例中直接利用第一滑动窗口对待提取文本特征的第一文本进行文本特征提取,具体提取过程是针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符。由于是直接利用第一滑动窗口去提取待处理文本特征的文本,不需要使用分词器去提取,也就不需要更新词典以及优化相应的分词算法,只要第一文本的特征落入第一滑动窗口内,即可提取该特征,解决了现有的文本特征提取方法存在的过于依赖已有分词器,无法提取未登录的词条等文本特征的问题。附图说明图1为本申请实施例一提供的文本特征提取方法的流程图;图2为本申请实施例二提供的文本特征提取方法的流程图;图3为本申请实施例二提供判断第一文本中是否包含重复文本的流程图;图4为本申请实施例二提供的判断第三文本中是否包含单字符串重复文本的流程图;图5为本申请实施例二提供的判断第四文本中是否包含多字符串重复文本的流程图;图6为本申请实施例三提供的文本分类方法的流程图;图7为本申请实施例四提供的文本特征提取装置的结构示意图;图8为本申请实施例五提供的文本分类装置的结构示意图。具体实施方式为了清楚地理解本申请的方案,下面首先对本申请实施例中涉及到的概念进行说明:文本分类:也叫classification。对于分类,输入的训练数据有特征(feature),有标签(label)。所谓的分类算法学习,其本质就是找到特征和标签间的关系(mapping)。当有特征而无标签的未知数据输入时,就可以通过已有的关系得到未知数据标签。滑动窗口:这个概念来自计算机网络协议tcp中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为0时,发送方一般不能再发送数据报。而在本文是指在处理文本时,指定一个或多个窗口,窗口的尺寸(大小)是可以指定,窗口从文本开始一直滑动到文本的结尾,在滑动的过程中,将窗口内的内容(也即字符串)抽取成出来。在滑动的过程中窗口的大小是可以变化的。特征:人或事物可供识别的特殊的征象或标志。在文本处理中,只一个个的词或者短文本。特征提取:给定一个文本,提取特征列表的过程。重复文本:一个或多个字符串不间断重复出现的文本。包括单字符串重复文本和多字符串重复文本。例如:对于文本“我的支付宝付不了款,怎么办怎么办?????”,其中的“怎么办怎么办”即为重复文本,具体为多字符串重复文本,“怎么办”是重复文本的最小单元;“好好好好好”及“?????”也为重复文本,具体为单字符重复文本,一个“好”及“?”构成了重复文本的最小单元。以下结合说明书附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。并且在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。实施例一:如图1所示,其为本申请实施例一提供的文本特征提取方法的流程图,包括以下步骤:步骤101:确定待提取文本特征的第一文本;其中,可以对已有数据进行收集,确定上述第一文本。例如,从即时通讯工具或社交网站中发表的文本中确定第一文本。可以将即时通讯工具中记录的每一条聊天记录作为待提取文本特征的第一文本,通常一条聊天记录的语句比较短小,直接就可以作为第一文本,例如“我的支付宝付不了款,怎么办怎么办?????”;对于比较长的文本,可以依据文本中出现的标点符号或空格将文本划分为多个第一文本。在确定第一文本后,还可以对第一文本进行以下几个方面中任一方面或几个方面进行处理,处理之后再执行步骤102;第一方面:对所述第一文本进行进行公共预处理,所述公共预处理包括以下一种或多种的组合:过滤文本中的网络地址信息、过滤文本中的设定日期信息、过滤文本中的钱款信息、过滤文本中的订单号信息、将文本中的多个空格替换成一个空格。其中,处理文本中的网络地址信息是把文本中的网络地址信息去掉,处理文本中的设定日期信息去掉,过滤文本中的订单号信息去掉。进行上述第一方面的处理,是考虑到文本中的网络地址信息、设定日期信息、钱款信息、订单号信息是涉及到一系列的数字及网址符号,即使提取出来,这类文本特征对后续的文本识别来说意义不大,甚至会对后续的文本识别造成干扰,因此,这里要滤除这些信息,以减轻后续文本特征提取的计算量,提高文本特征提取的效率。第二方面:对所述第一文本进行进行自定义预处理,所述自定义预处理包括以下一种或多种的组合:过滤文本中的设定地址和名称信息、过滤文本中的设定前缀信息、过滤文本中的设定后缀信息。在一些业务中,文本中一些前缀和后缀、地址和名称对特征的提取也是没有意义的。因此,这里要对第一文本根据业务需求和业务特点进行自定义预处理,以减少后续文本特征提取的计算量,提高文本特征提取的效率。第三方面:确定所述第一文本中包含空格和/或单个标点符号;若包含空格,则用设定字符对所述第一文本中包含的空格进行替换处理,其中,所述设定字符为除标点符号和空格外的字符;若包含单个标点符号,则用设定字符对所述第一文本中包含的空格进行替换处理;若包含空格和单个标点符号,则用设定字符分别对所述第一文本中包含的空格和单个标点符号进行替换处理。假设用“ψ”这一设定字符对上述第一文本“我的支付宝付不了款,怎么办怎么办?????”中的单个标点符号进行替换,替换之后即为“我的支付宝付不了款ψ怎么办怎么办?????”。实现上述第三方面的核心代码可以如下代码1所示:代码1这里之所以对单个标点符号进行替换,而不是对出现的多个标点符号进行替换,是考虑到多个标点符号通常会表达一些较强烈的情绪,对特征的提取很有意义。例如,一个问号表示疑问,多个问号就表示强烈质疑,同样,一个叹号表示强调,多个叹号就表示强烈强调。由于空格和单个标点符号是对文本的断句,对文本特征的抽取也是有意义的,这里并不是将空格和单个标点符号进行过滤,而是采用对空格和单个标点符号用设定字符替换,这样可以减少标点符号的种类,简化文本特征提取,提高文本特征提取效率。第四方面:判断所述第一文本中包含重复文本,其中,重复文本包括单字符串重复文本和多字符串重复文本;若包含重复文本,则对所述第一文本进行去重处理,得到第二文本;对“我的支付宝付不了款,怎么办怎么办?????”去重处理后,得到的第二文本即为“我的支付宝付不了款,怎么办?”。由于通常情况下,重复文本表达的含义与去重后表达的字面含义是相同的,因此,这里将重复文本进行去重处理,以减少后续文本特征提取的计算量,提高文本特征提取的效率。步骤102:确定至少一个用于提取文本特征的第一滑动窗口和相应的滑动步长,其中,第一滑动窗口的尺寸大于1个字符,滑动步长不小于1个字符;这里,针对汉字,考虑到词是构成文本特征的特征项,而一个词通常用2个字或3个字(其中,一个汉字就是一个字符)来表达,成语通常用4个字来表达,因此,这里为了能提取出第一文本中的文本特征,可以采用一个尺寸为2个字符、3个字符或者4个字符的第一滑动窗口。也可以采用两个第一滑动窗口。例如,可以采用一个尺寸为2个字符的第一滑动窗口,另一个尺寸为3个字符的第一滑动窗口;也可以采用一个尺寸为2个字符的第一滑动窗口,另一尺寸为4个字符的第一滑动窗口。还可以采用三个第一滑动窗口。例如,第一个第一滑动窗口的尺寸为2,第二个第一滑动窗口的尺寸为3,第三个第一滑动窗口的尺寸为4。针对外语,第一滑动窗口的最合适的个数和相应的尺寸的大小可以依据外语本身的特点来进行确定。步骤103:针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符;上述设定的初始滑动位置可以是第一文本的起始字符所处的位置,也可以是第一文本的结束字符所处的位置,还可以是第一文本的其他字符所处的位置。上述排列路径是指从第一文本的起始字符到结束字符的排列路径。通常字符按照一定的顺序排列之后即可构成表达某种含义的文本。具体的,可以通过以下两种方式来实现步骤103:第一种方式:各第一滑动窗口顺次执行滑动操作,也即:一个第一滑动窗口按照其对应的滑动步长滑过构成所述第一文本的各字符(可以是从第一文本的起始字符滑到结束字符),之后,下一个第一滑动窗口按照其对应的滑动步长滑过构成所述第一文本的各字符。下面对上述第一种方式进行举例说明:假设步骤102中确定的第一滑动窗口的个数为两个,尺寸分别为2个字符和3个字符,尺寸为2的第一滑动窗口对应的滑动步长为1,尺寸为3的第一滑动窗口对应的滑动步长为1;则针对“我的支付宝付不了款”这一第一文本,首先,使用尺寸为2的第一滑动窗口,提取滑动过程中该第一滑动窗口内的字符串即为:我的、的支、支付、付宝、付不、不了、了款;其次,使用尺寸为3的第一滑动窗口,提取滑动过程中该第一滑动窗口内的字符串即为:我的支、的支付、支付宝、付宝付、宝付不、付不了、不了款。第二种方式:各第一滑动窗口交叉执行滑动操作,在采用两个第一滑动窗口及以上,各第一滑动窗口的尺寸不相同且相应的滑动步长均为1个字符,所述设定的初始滑动位置为所述第一文本的起始字符所在位置;从所述第一文本的起始字符所在位置开始,遍历所述第一文本中的字符,执行以下步骤a1至步骤a5:步骤a1、将当前遍历的字符所在位置作为各第一滑动窗口的当前开始位置;步骤a2、从尺寸最小的第一滑动窗口的当前结束位置开始,遍历每个第一滑动窗口的当前结束位置,执行以下步骤a3至步骤a5,直至尺寸最大的第一滑动窗口的当前结束位置:步骤a3、判断当前遍历的当前结束位置是否为所述第一文本的结束字符所在位置,若是,则执行步骤a4,若否,则执行步骤a5;步骤a4、取出当前开始位置和当前遍历的当前结束位置之间的字符串,之后结束;若需要对由结束字符构成的字符串进行标记,可以在这里的步骤a4中,对取出的字符串前/后加上结束标记。例如,结束标记可以为“e-”。步骤a5、取出当前开始位置和当前遍历的当前结束位置之间的字符串。若需要对第一文本的由起始字符构成的字符串进行标记,可以在这里的步骤a5可以变为,判断当前开始位置是否为第一文本的起始字符所在位置,若是,则对取出的字符串前/后加上起始标记。起始标记可以为“s-”。若不是,则直接执行取出当前开始位置和当前遍历的当前结束位置之间的字符串。除了在步骤a4和步骤a5中进行起始字符的判断,还可以在对第一文本进行文本特征提取之后,判断提取的文本特征的字符串中的字符在第一文本中的位置中是否为起始位置/结束位置,若是,则可以复制一份该字符串,并在复制的字符串前加起始标记/结束标记。这里对包含第一文本起始位置处的字符(起始字符)的字符串和第一文本结束位置处的字符(结束字符)的字符串进行标记,是考虑到通常文本(尤其是短文本)的结尾和文本的开始位置前后的特征相对于其他位置包含的信息对整个文本来说较为重要,因此,这里对文本结尾位置的字符串和文本开始位置的字符串进行标记,以便于在后续文本分类时,对文本结尾位置和为本结束位置赋予相对较高的权重,取得较好的分类效果。下面对上述第二种方式进行举例说明:假设步骤102中确定的第一滑动窗口的个数为两个,尺寸分别为2个字符和3个字符;则针对“我的支付宝付不了款”这一第一文本,从所述起始字符“我”所在位置开始,遍历该第一文本中的字符,执行上述步骤a1至步骤a5的过程具体如下(由于循环次数较多,这里仅以一次循环的执行进行示意说明):步骤a1:将起始字符“我”所在位置作为尺寸为2的第一滑动窗口和尺寸为3的第一滑动窗口的当前开始位置;这里,由于获知了第一滑动窗口的当前开始位置及尺寸,因此,可以确定尺寸为2的第一滑动窗口的当前结束位置为“的”字符所处位置,尺寸为3的第一滑动窗口的当前结束位置为“支”字符所处位置。步骤a2:从尺寸为2的第一滑动窗口的当前结束位置(“的”字符所处位置)到尺寸为3的第一滑动窗口的当前结束位置(“支”字符所处位置)开始遍历;步骤a3:判断当前遍历的当前结束位置(“的”字符所处位置)不为所述第一文本的结束字符所在位置(“款”字符所在位置),执行步骤a5;步骤a5、取出当前开始位置(字符“我”所在位置)和当前遍历的当前结束位置(“的”字符所处位置)之间的字符串“我的”;步骤a3:判断当前遍历的当前结束位置(“支”字符所处位置)不为所述第一文本的结束字符所在位置(最后一个“?”字符所在位置),则执行步骤a5;步骤a5、取出当前开始位置(字符“我”所在位置)和当前遍历的当前结束位置(“支”字符所处位置)之间的字符串“我的支”;步骤a1:将第二个字符“的”所在位置作为尺寸为2的第一滑动窗口和尺寸为3的第一滑动窗口的当前开始位置……经过上述循环过程,上述第二种方式提取出的字符串即为:我的、我的支、的支、的支付、支付、支付宝、付宝、付宝付、宝付、宝付不、付不、付不了、不了、不了款、了款。上述第二种方式提取出的字符串加上起始标记“s-”和结束标记“e-”之后即为:s-我的、s-我的支、我的、我的支、的支、的支付、支付、支付宝、付宝、付宝付、宝付、宝付不、付不、付不了、不了、不了款、了款、s-不了款、s-了款。上述第二种方式相对于第一种方式,由于采用的循环次数较少,因此,可以提高第一文本的字符串的提取效率。步骤104:将提取的字符串作为所述第一文本的文本特征输出。这里输出的文本特征可以以特征列表的形式展现,也可以以其他形式展现;输出的文本特征可以作为分类算法的输入数据,以进行分类模型的训练以及分类识别。实现上述步骤101至步骤105的核心代码可以如下代码2所示:代码2由对“我的支付宝付不了款”这一文本利用本申请实施例一的文本特征提取方法提取出的文本特征:我的、我的支、的支、的支付、支付、支付宝、付宝、付宝付、宝付、宝付不、付不、付不了、不了、不了款、了款,可知,本申请实施例的方案,提取的特征中包含“支付宝”这个特征,该词的提取并不依赖于词典中的登录,这就为后续的分类算法提供了较好的基础。此外,本申请实施例一的方案可以应用在分类算法中,也可以应用在比较两段文本的相似度上,利用相似度来确定文本的表达的意思的差别的大小,例如:下表(2)萌妹纸和卖萌妹提取的特征7个只有1个是相同的,基本代表两者的意思很大不一样。“冷暖男”是一个新词,“牛暖男”可能是一个人名。两种的意思也不一样,提取的7个特征中有3个是一样。大体可以代表两段文本的相似度。文本提取的特征萌妹纸b-萌妹萌妹b-萌妹纸e-萌妹纸萌妹纸e-妹纸,妹纸卖萌妹b-卖萌卖萌b-卖萌妹e-卖萌妹卖萌妹e-萌妹萌妹冷暖男b-冷暖冷暖b-冷暖男e-冷暖男冷暖男e-暖男暖男牛暖男b-牛暖牛暖b-牛暖男e-牛暖男牛暖男e-暖男暖男表(2)此外,本申请在下面的实施例二中还提供一种文本特征提取方法,实施例二中的文本特征提取方法主要是针对重复文本的特征提取方法,可以单独使用,也可以作为本申请实施例一的基础上的辅助特征提取方法,以便于从包含重复文本的第一文本中提取出更多的特征,将实施例一中提取到的文本特征和实施例二中提取到的文本特征共同作为文本分类的依据,使得分类较为准确。这是因为重复文本通常是表达强调的含义以及强烈的情绪,是文本分类(尤其是分类中包含文本情绪分类、重要等级分类)中需要考虑的一个重要因素。实施例二如图2所示,其为本申请实施例二提供的文本特征提取方法的流程图,包括以下步骤:步骤201:确定待提取文本特征的第一文本;这里与实施例一中的步骤201相同,不再赘述。步骤202:判断所述第一文本中是否包含重复文本,若是,则执行步骤202,若否,则结束。其中,重复文本包括单字符串重复文本和多字符串重复文本;步骤203:提取所述第一文本中包含的重复文本。本申请实施例二中,考虑到重复文本中通常表达了强调的含义或者强烈的情绪,因此,将重复文本单独提取出来,作为第一文本的文本特征,以客观、真实地反映第一文本表达的真正含义,使得利用提取出的重复文本进行文本分类的分类结果较为准确。上述步骤202至步骤203中,可以先判断是否包含单字符串重复文本,之后判断是否包含多字符串重复文本;也可以先判断是否包含多字符串重复文本,之后判断是否包含单字符串重复文本。较佳的,先判断是否包含单字符串重复文本,之后判断是否包含多字符串重复文本,具体可以包括以下步骤301至步骤301,如图3所示:步骤301:判断所述第一文本中是否包含单字符串重复文本;若是,则执行步骤302;若否,则执行步骤303;步骤302:提取所述单字符串重复文本;步骤303:判断所述第一文本中是否包含多字符串重复文本,若是,则执行步骤304,若否,则结束。步骤304:提取所述多字符串重复文本。上述步骤301至步骤304中,先判断是否包含单字符串重复文本,后判断是否包含多字符串重复文本,也就是说判断单字符串重复文本的优先级判断高于字符串重复文本,这是因为相对于单字符串重复文本的判定来说,多字符串的判定过程较为复杂,计算量较大,在进行单字符串重复文本的判定之后,就可以把文本中单字符串结束位置之前的文本排除在外,减少多字符串文本判定的计算量。上述较佳的方式可以通过以下步骤b1至步骤b10实现,如图4所示:步骤b1:将所述第一文本的起始字符所在位置作为最小第二滑动窗口的当前开始位置,其中,最小第二滑动窗口的尺寸为2个字符;针对“我的支付宝付不了款,怎么办怎么办?????”这一第一文本,步骤b1即为将起始字符“我”所在位置,作为最小第二滑动窗口的当前开始位置,由于这里的最小第二滑动窗口的尺寸为2个字符,因此,最小第二滑动窗口的当前结束位置即为字符“的”所在位置,也即此时,最小第二滑动窗口中包含的字符为“我”和“的”。字符“支”在最小第二滑动窗口之外。步骤b2:判断最小第二滑动窗口的当前开始位置距离所述第一文本的结束字符所在位置是否小于设定值,该设定值为最小第二滑动窗口的尺寸减1个字符;若否,则执行步骤b3,若是,则结束;在第一次执行步骤b2时,最小第二滑动窗口的当前开始位置距离所述第一文本的结束字符“?”所在位置是20个字符,因此,不小于1个字符。步骤b3:判断第三文本中是否包含单字符串重复文本,所述第三文本为从最小第二滑动窗口的当前开始位置处的字符至第一文本的结束字符之间的字符,若是,则执行步骤b4;若否,则执行步骤b6;在第一次执行步骤b3时,第三文本和第一文本相同。这里的步骤b3具体可以通过如下步骤b31至步骤b33实现,如图4所示:步骤b31:判断最小第二滑动窗口的当前开始位置处的字符与最小第二滑动窗口的当前结束位置处的字符是否相同;若相同,则执行步骤b32;若不相同,则执行步骤b6;在第一次执行步骤b31时,判断最小第二滑动窗口内的“我”和“的”字符不相同,因此,执行步骤b6;步骤b32:沿着构成第三文本的字符的排列路径,查找最小第二滑动窗口外的字符中,第一个与最小第二滑动窗口的当前开始位置处的字符不相同的字符,并将找到的不相同的字符所在位置作为单字符串重复文本的结束位置处的字符之后的一个字符所在位置;这里,假设第一文本为“好好好啊,我忙了”,则第一次执行步骤b31时,判断结果为相同,之后执行步骤b32,此时,查找到的第一个与最小第二滑动窗口的当前开始位置处的字符“好”不相同的字符即为字符“啊”,单字符串重复文本的结束位置即为第三个字符“好”所在位置。步骤b4:提取第三文本中的单字符串重复文本,之后执行步骤b5;本步骤b4中,在步骤b32中找到了第一个与最小第二滑动窗口的当前开始位置处的字符不相同的字符,提取的第三文本中的单字符串重复文本即为步骤31中最小第二滑动窗口的当前开始位置处的字符至第一个与最小第二滑动窗口的当前开始位置处的字符不相同的字符之前的一个字符之间的字符。针对步骤b32中的例子,这里步骤b4中提取到的字符即为“好好好”。步骤b5:用单字符串重复文本的结束位置处的字符之后相邻的字符所在位置更新步骤b2中的最小第二滑动窗口的当前开始位置,之后跳转至步骤b2;这里,针对步骤b4中的例子,步骤b5即为将字符“啊”所在位置更新步骤b2中的最小第二滑动窗口的当前开始位置。步骤b6:判断最小第二滑动窗口的当前开始位置距离所述第一文本的结束字符所在位置是否小于最小第二滑动窗口的尺寸,若否,则执行步骤b7,若是,则执行步骤b10;沿用步骤b31中的例子,这里第二滑动窗口当前开始位置为字符“我”所处位置,因此,距离所述第一文本的结束字符“?”所在位置不小于最小第二滑动窗口的尺寸。步骤b7:判断第四文本中是否包含多字符串重复文本,所述第四文本为从最小第二滑动窗口的当前开始位置处的字符至第一文本的结束字符之间的字符,若是,则执行步骤b8,若否,则执行步骤b10;沿用步骤b6中的例子,第一次执行步骤b7时,第四文本与第一文本也是相同的。这里的步骤b7可以通过如下步骤b701至步骤b712实现,如图5所示:步骤b701至步骤712的基本思想是,从尺寸为2的第二滑动窗口开始,判断第二滑动窗口内字符与窗口外相邻的两个字符是否相同,相同时,继续进行第二滑动窗口内字符与窗口外相邻的两个字符后面的两个字符是否相同,直至不相同时结束;不相同时,逐步扩大第二滑动窗口的尺寸,判断尺寸扩大后第二滑动窗口内字符与窗口外相邻的三个字符是否相同,如此循环。由于循环次数较多,这里不再进行举例,具体可按照步骤b701至步骤b712进行循环,或者将例子代入按照下面的代码3进行验证。步骤b701:将第四文本的长度的一半作为最大第二滑动窗口的尺寸;步骤b702:判断最小第二滑动窗口的当前开始位置是否为第一文本的起始字符所在位置,若是,则执行步骤b703;若否,则执行步骤b704;步骤b703:用第一文本的起始字符之后相邻的字符所在位置作为第四文本的起始字符的位置,之后执行步骤b705;步骤b704:将最小第二滑动窗口的当前开始位置作为第四文本的起始字符的位置,之后执行步骤b705;步骤b705:将最小第二滑动窗口的尺寸作为当前第二窗口的尺寸;之后执行步骤706;步骤706:判断当前第二窗口的尺寸是否不大于步骤701中的最大第二滑动窗口的尺寸;若是,则执行步骤b707;若否,则执行步骤b713;步骤b707:判断当前第二滑动窗口中的字符串和第三滑动窗口中的字符串是否相同,其中,第三滑动窗口是当前第二滑动窗口沿着第四文本的排列路径滑动当前第二滑动窗口的尺寸个字符后得到的滑动窗口;若相同,则执行步骤b708;若不相同,则执行步骤b711;步骤b708:保存当前第二滑动窗口的字符串和第三滑动窗口中的字符串,之后执行步骤b709;这里,为了体现重复文本中的最小单元的重复次数,达到强化重复文本的在分类中的作用,使得分类较为准确,这里还可以第一次执行步骤708后(此时即确定最小单元重复出现),自动扩展第五滑动窗口的大小,第五滑动窗口扩展的算法是:重复串最小单位(>=2)的n次方或者重复串的最大长度,利用第五滑动窗口进行重复文本特征的提取。例1:比如“你好你好”,提取的特征就是“你好”,和“你好你好”。例2:“你好你好你好你好你好你好”提取的特征就是“你好”,“你好你好”,“你好你好你好你好”和“你好你好你好你好你好你好”。例3:“支付宝支付宝支付宝”提取的特征就是“支付宝”,“支付宝支付宝”,和“支付宝支付宝支付宝”。例4:“?????”,提取的特征就是“??”,“????”,和“?????”。例5:“???”提取的特征就是“??”,和“???”。步骤b709:将当前第二滑动窗口沿着第四文本的排列路径滑动当前第二滑动窗口的尺寸个字符,之后执行步骤b710;步骤b710:将当前第二滑动窗口的结束位置作为第四文本的起始字符的位置,之后执行步骤b707;步骤b711:用当前第二滑动窗口的尺寸加1个字符后得到的值更新步骤b707中的当前第二滑动窗口的尺寸,之后执行步骤b712;步骤b712:用更新尺寸后的当前第二滑动窗口外至第一文本结束字符之间的字符的个数的一半更新步骤b706中的最大第二滑动窗口的尺寸,之后跳转至步骤b706;步骤b713:用第四文本的起始字符的位置处的字符之后相邻的字符所在位置更新最小第二滑动窗口的当前开始位置,之后跳转至步骤b2。步骤b8:提取第四文本中的多字符串重复文本,之后执行步骤b9;步骤b9:用多字符串重复文本的结束位置处的字符之后相邻的字符所在位置更新步骤b2中的最小第二滑动窗口的当前开始位置,之后跳转至步骤b2;步骤b10:用最小第二滑动窗口的当前开始位置处的字符之后的下一个字符所在位置更新步骤b2中的最小第二滑动窗口的当前开始位置,之后跳转至步骤b2。步骤204:将提取的重复文本作为所述第一文本的文本特征输出。实现上述步骤201至步骤204的核心代码可以如下代码3所示:代码3此外,可以将本申请实施例一和实施例二的方案进行有机结合,以达到最佳的文本特征提取效果。具体地,将代码1所表示的算法1、代码3所表示的算法3(也即实施例二中的方案)和代码2所表示的算法2(也即实施例一中的方案)进行结合,先用算法1进行处理,之后将算法1的处理结果输入再用算法3,算法3进行重复文本处理,然后算法2将算法3中的重复文本的最小单位保留,进行文本特征的提取,但重复的标点信息不保留,避免生成太多标点信息,最后将算法3和算法2输出的文本特征进行合并。比如,第一文本是“我的支付宝付不了款,怎么办怎么办?????”1.先经过算法1的处理单个标点,结果:“我的支付宝付不了款ψ怎么办怎么办?????”2.算法3的处理重复文本,对“我的支付宝付不了款ψ怎么办怎么办?????”中的重复文本抽取出来,得到特征:怎么办、怎么办怎么办、???、?????。3.算法2提取特征文本,会将算法3中重复文本的最小单位保留,但是重复标点信息不保留。比如上面的“怎么办”会保留,重复的标点不会进入,避免生成太多标点信息。结果算法2的输入文本就是:“我的支付宝付不了款ψ怎么办”。算法3的输出特征:s-我的、我的、s-我的支、我的支、的支、的支付、支付、支付宝、付宝、付宝付、宝付、宝付不、付不、付不了、不了、不了款、了款、了款ψ、款ψ、款ψ怎、ψ怎、ψ怎么、怎么、e-怎么办、怎么办、e-么办、么办。4.将算法2和算法3的特征合并,最后得到的特征列表:s-我的、我的、s-我的支、我的支、的支、的支付、支付、支付宝、付宝、付宝付、宝付、宝付不、付不、付不了、不了、不了款、了款、了款ψ、款ψ、款ψ怎、ψ怎、ψ怎么、怎么、e-怎么办、怎么办、e-么办、么办怎么办、怎么办怎么办、????????。实施例三如图6所示,其为本申请实施例三提供的文本识别方法的流程图,包括以下步骤:步骤601:利用文本特征提取方法提取待分类文本中的文本特征;这里的文本特征提取方法可以采用实施例一及实施例二中的任一文本特征提取方法。步骤602:将提取的待分类文本中的文本特征输入文本分类模型,得到待分类文本的类别;其中,所述文本分类模型为预先根据文本样本对预置的分类模型进行训练,得到根据待分类文本的文本特征对该待分类文本进行分类的文本分类模型。上述预置的分类模型可以为常用的分类算法,例如:朴素贝叶斯分类算法、最大熵法以及k-最近近邻分类算法等。预先根据文本样本对预置的分类模型进行训练,得到根据待分类文本的文本特征对该待分类文本进行分类的文本分类模型,包括:利用所述文本特征提取方法对文本样本分别进行文本特征提取;利用提取的文本样本的文本特征对预置的分类模型进行训练,得到文本分类模型。由于分类模型和训练方法与现有的相同,这里不再详细说明。下面对本申请实施例三的文本识别方法在一种可能的场景下的应用进行说明:目前,用户越来越多的使用手机上安装的应用软件(如具有即时通讯功能的软件)上的服务中心寻求的实时服务,手机端由于屏幕等因素,用户的输入的文本比较随意和松散。例如,出现很多带正面情感的新词,“萌妹纸”,“冷暖男”等。还有手机端客户不耐烦会输入很多带感情色彩的标点,例如质问“??!!”,“!!!???”。或者各个输入法带入的表情等“[:愤怒][:愤怒][:愤怒][:愤怒][:愤怒]”。还有用户无聊测试的输入“sfsfsfsf”,“ssskjjkk”。此时,可以利用本申请实施例三的方案,先对接收的来自用户使用的客户端的文本,进行特征提取,之后进行文本分类,最后从预先保存的类别与服务方式的对应关系中,查找待分类文本的类别对应的服务方式,所述服务方式为针对分类文本做出响应的方式;最后将该待分类文本转发给查找到的服务方式所对应的服务设备。可以依据涉及业务的复杂程度和情绪进行分类;如果用户的文本分类为复杂程度较高的类别,比如维权纠纷等等,可以将该待分类文本转发给服务专家所使用的设备,进而去为用户提供服务。同时可以分类出用户的情绪的是否负面,如果分类结果为用户有情绪问题,会向客服发送提醒消息,提醒客服主要安抚或者升级服务等级。比如,刚开始是机器人回答客户的问题,若用户聊天中出现情绪问题或者骂人等,将转成人工渠道去服务客户。实施例四基于与实施例一和实施例二的同一发明构思,本申请实施例四提供一种文本特征提取装置,其结构示意图如图7所示,包括:确定单元71、第一处理单元72和输出单元73;其中:确定单元71,用于确定待提取文本特征的第一文本,以及至少一个用于提取文本特征的第一滑动窗口和相应的滑动步长;第一处理单元72,用于针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符;输出单元73,用于将提取的字符串作为所述第一文本的文本特征输出。较佳的,用于提取文本特征的第一滑动窗口的个数大于1,各第一滑动窗口的尺寸不相同且相应的滑动步长均为1个字符,所述设定的初始滑动位置为所述第一文本的起始字符所在位置;所述第一处理单元72,具体用于从所述第一文本的起始字符所在位置开始,遍历所述第一文本中的字符,执行以下步骤:步骤a1、将当前遍历的字符所在位置作为各第一滑动窗口的当前开始位置;步骤a2、从尺寸最小的第一滑动窗口的当前结束位置开始,遍历每个第一滑动窗口的当前结束位置,执行以下步骤a3至步骤a5,直至尺寸最大的第一滑动窗口的当前结束位置:步骤a3、判断当前遍历的当前结束位置是否为所述第一文本的结束字符所在位置,若是,则执行步骤a4,若否,则执行步骤a5;步骤a4、取出当前开始位置和当前遍历的当前结束位置之间的字符串,之后结束;步骤a5、取出当前开始位置和当前遍历的当前结束位置之间的字符串。较佳的,所述装置还包括:第二处理单元,用于在确定单元确定待提取文本特征的第一文本之后,第一处理单元针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符之前,确定所述第一文本中包含重复文本,其中,重复文本包括单字符串重复文本和多字符串重复文本;对所述第一文本进行去重处理,得到第二文本;所述第一处理单元,具体用于针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第二文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符。较佳的,所述装置还包括:第三处理单元,用于在确定单元确定待提取文本特征的第一文本之后,第二处理单元对所述第一文本进行去重处理,得到第二文本之前,确定所述第一文本中包含空格和/或单个标点符号;若包含空格,则用设定字符对所述第一文本中包含的空格进行替换处理,其中,所述设定字符为除标点符号和空格外的字符;若包含单个标点符号,则用设定字符对所述第一文本中包含的空格进行替换处理;若包含空格和单个标点符号,则用设定字符分别对所述第一文本中包含的空格和单个标点符号进行替换处理。较佳的,所述装置还包括:第四处理单元,用于在确定单元确定待提取文本特征的第一文本之后,若确定所述第一文本中包含重复文本,则提取所述第一文本中包含的重复文本,其中,重复文本包括单字符串重复文本和多字符串重复文本;所述输出单元,还用于将提取的重复文本作为所述第一文本的文本特征输出。较佳的,所述第四处理单元,具体用于判断所述第一文本中是否包含单字符串重复文本;若包含单字符串重复文本,则提取所述单字符串重复文本;若不包含单字符串重复文本,则判断所述第一文本中是否包含多字符串重复文本;若包含多字符串重复文本,则提取所述多字符串重复文本。较佳的,所述第四处理单元,具体用于执行以下步骤:步骤b1:将所述第一文本的起始字符所在位置作为最小第二滑动窗口的当前开始位置,其中,最小第二滑动窗口的尺寸为2个字符;步骤b2:判断最小第二滑动窗口的当前开始位置距离所述第一文本的结束字符所在位置是否小于设定值,该设定值为最小第二滑动窗口的尺寸减1个字符;若否,则执行步骤b3,若是,则结束;步骤b3:判断第三文本中是否包含单字符串重复文本,所述第三文本为从最小第二滑动窗口的当前开始位置处的字符至第一文本的结束字符之间的字符,若是,则执行步骤b4;若否,则执行步骤b6;步骤b4:提取第三文本中的单字符串重复文本,之后执行步骤b5;步骤b5:用单字符串重复文本的结束位置处的字符之后相邻的字符所在位置更新步骤b2中的最小第二滑动窗口的当前开始位置,之后跳转至步骤b2;步骤b6:判断最小第二滑动窗口的当前开始位置距离所述第一文本的结束字符所在位置是否小于最小第二滑动窗口的尺寸,若否,则执行步骤b7,若是,则执行步骤b10;步骤b7:判断第四文本中是否包含多字符串重复文本,所述第四文本为从最小第二滑动窗口的当前开始位置处的字符至第一文本的结束字符之间的字符,若是,则执行步骤b8,若否,则执行步骤b10;步骤b8:提取第四文本中的多字符串重复文本,之后执行步骤b9;步骤b9:用多字符串重复文本的结束位置处的字符之后相邻的字符所在位置更新步骤b2中的最小第二滑动窗口的当前开始位置,之后跳转至步骤b2;步骤b10:用最小第二滑动窗口的当前开始位置处的字符之后的下一个字符所在位置更新步骤b2中的最小第二滑动窗口的当前开始位置,之后跳转至步骤b2。较佳的,所述第四处理单元,具体用于通过以下步骤执行步骤b3:步骤b31:判断最小第二滑动窗口的当前开始位置处的字符与最小第二滑动窗口的当前结束位置处的字符是否相同;若相同,则执行步骤b32;若不相同,则执行步骤b33;步骤b32:沿着构成第三文本的字符的排列路径,查找最小第二滑动窗口外的字符中,第一个与最小第二滑动窗口的当前开始位置处的字符不相同的字符,并将找到的不相同的字符所在位置作为单字符串重复文本的结束位置处的字符之后的一个字符所在位置;步骤b33:执行判断最小第二滑动窗口的当前开始位置距离所述第一文本的结束字符所在位置是否小于最小第二滑动窗口的尺寸的步骤。较佳的,所述第四处理单元,具体用于通过以下步骤执行步骤b7:步骤b701:将第四文本的长度的一半作为最大第二滑动窗口的尺寸;步骤b702:判断最小第二滑动窗口的当前开始位置是否为第一文本的起始字符所在位置,若是,则执行步骤b703;若否,则执行步骤b704;步骤b703:用第一文本的起始字符之后相邻的字符所在位置作为第四文本的起始字符的位置,之后执行步骤b705;步骤b704:将最小第二滑动窗口的当前开始位置作为第四文本的起始字符的位置,之后执行步骤b705;步骤b705:将最小第二滑动窗口的尺寸作为当前第二窗口的尺寸;之后执行步骤706;步骤706:判断当前第二窗口的尺寸是否不大于最大第二滑动窗口的尺寸;若是,则执行步骤b707;若否,则执行步骤b713;步骤b707:判断当前第二滑动窗口中的字符串和第三滑动窗口中的字符串是否相同,其中,第三滑动窗口是当前第二滑动窗口沿着第四文本的排列路径滑动当前第二滑动窗口的尺寸个字符后得到的滑动窗口;若相同,则执行步骤b708;若不相同,则执行步骤b711;步骤b708:保存当前第二滑动窗口的字符串和第三滑动窗口中的字符串,之后执行步骤b709;步骤b709:将当前第二滑动窗口沿着第四文本的排列路径滑动当前第二滑动窗口的尺寸个字符,之后执行步骤b710;步骤b710:将当前第二滑动窗口的结束位置作为第四文本的起始字符的位置,之后执行步骤b707;步骤b711:用当前第二滑动窗口的尺寸加1个字符后得到的值更新步骤b707中的当前第二滑动窗口的尺寸,之后执行步骤b712;步骤b712:用更新尺寸后的当前第二滑动窗口外至第一文本结束字符之间的字符的个数的一半更新步骤b706中的最大第二滑动窗口的尺寸,之后跳转至步骤b706;步骤b713:用第四文本的起始字符的位置处的字符之后相邻的字符所在位置更新最小第二滑动窗口的当前开始位置,之后跳转至步骤b2。较佳的,所述装置还包括:公共预处理单元,用于在确定单元确定待提取文本特征的第一文本之后,针对每一滑动窗口,第一处理单元从设定的初始滑动位置开始,沿着构成第一文本的字符的排列路径,以该滑动窗口相应的滑动步长滑动该滑动窗口,并提取滑动过程中该滑动窗口内的字符串,直至滑过构成所述第一文本的各字符之前,对所述第一文本进行进行公共预处理,所述公共预处理包括以下一种或多种的组合:过滤文本中的网络地址信息、过滤文本中的设定日期信息、过滤文本中的钱款信息、过滤文本中的订单号信息、将文本中的多个空格替换成一个空格。较佳的,所述装置还包括:自定义预处理单元,用于在确定单元确定待提取文本特征的第一文本之后,针对每一滑动窗口,第一处理单元从设定的初始滑动位置开始,沿着构成第一文本的字符的排列路径,以该滑动窗口相应的滑动步长滑动该滑动窗口,并提取滑动过程中该滑动窗口内的字符串,直至滑过构成所述第一文本的各字符之前,对所述第一文本进行进行自定义预处理,所述自定义预处理包括以下一种或多种的组合:过滤文本中的设定地址和名称信息、过滤文本中的设定前缀信息、过滤文本中的设定后缀信息。实施例五基于与实施例一、实施例二和实施例三的同一发明构思,本申请实施例四提供一种文本特征提取装置,其结构示意图如图8所示,包括:文本特征提取单元81和分类单元82;其中:文本特征提取单元81,用于利用文本特征提取方法提取待分类文本中的文本特征,其中,所述文本特征提取方法包括:确定待提取文本特征的第一文本,以及至少一个用于提取文本特征的第一滑动窗口和相应的滑动步长;针对每一第一滑动窗口,从设定的初始滑动位置开始,沿着构成所述第一文本的字符的排列路径,以该第一滑动窗口相应的滑动步长滑动该第一滑动窗口,并提取滑动过程中该第一滑动窗口内的字符串,直至滑过构成所述第一文本的各字符;将提取的字符串作为所述第一文本的文本特征输出;分类单元82,用于将提取的待分类文本中的文本特征输入文本分类模型,得到待分类文本的类别,得到待分类文本的类别,其中,所述文本分类模型为预先根据文本样本对预置的分类模型进行训练,得到根据待分类文本的文本特征对该待分类文本进行分类的文本分类模型。较佳的,所述装置还包括:训练单元83,用于利用所述文本特征提取方法对文本样本分别进行文本特征提取;利用提取的文本样本的文本特征对预置的分类模型进行训练,得到文本分类模型。较佳的,所述待分类文本为从即时通讯工具中接收到的来自客户端的文本,所述装置还包括:查找单元84,用于从预先保存的类别与服务方式的对应关系中,查找待分类文本的类别对应的服务方式,所述服务方式为针对分类文本做出响应的方式;发送单元85,用于将该待分类文本转发给查找到的服务方式所对应的服务设备。上述实施例四和实施例五的具体实现细节,可参照实施例一至实施例三中的方法部分,这里不再赘述。通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本发明实施例可以通过硬件实现,也可以借助软件加必要的通用硬件平台的方式实现。基于这样的理解,本发明实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。本领域技术人员可以理解附图只是一个优选实施例的示意图,附图中的模块或流程并不一定是实施本发明所必须的。本领域技术人员可以理解实施例中终端中的模块可以按照实施例描述进行分布于实施例的终端中,也可以进行相应变化位于不同于本实施例的一个或多个终端中。上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块。上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1