基于深度学习的跨模态主题相关性建模方法与流程
本发明属于跨媒体相关性学习技术领域,具体涉及基于深度学习的跨模态图像-文本主题相关性学习方法。
背景技术:
随着互联网技术的发展与Web2.0的成熟,在互联网上累计海量的多模态文档,如何分析和处理这些多模态文档的复杂结构,从而为跨媒体检索等实际应用提供理论支持已经变成一个非常重要的研究热点。通常来说,一个多模态文档通常以多种模态共现的形式存在,例如,许多的web图像附带着很多用户自定义的图像描述或者标注,另外也有一些网络的文档包含一些插图的形式。然而,虽然这些多模态的数据常常彼此关联,但由于语义鸿沟的问题,在图像的视觉信息和文本描述信息之间有着很大的区别和差异[1],这使得充分利用不同模态之间的语义关联变得十分困难。因此,如何充分挖掘不同模态数据背后隐含的关系,并且更好地融合多模态信息来对多模态文档进行建模变得十分的重要[2,3]。而利用主题模型来对多模态文档进行建模,进而挖掘不同模态之间的关联是一个重要策略,在跨模态主题建模的研究中,存在着三个相互关联的问题需要同时得到解决:
1、发现和构建更加有代表性、更加有价值的文档元素来对多模态文档中的图像和文本内容分别进行描述表示。
2、能够建立更加合理的主题相关性模型来更好地对多模态文档中不同模态数据之间的关联进行描述,即视觉图像和文本描述之间的关联。
3、通过跨模态主题相关性学习来针对图像和文本内容之间的内在关联性建立一种客观的衡量机制。
为解决第一个问题,最重要的就是探索如何能够建立一组优化的文档元素,从而利用这些优化的文档元素能够更加精确、更加全面地对多模态文档中的视觉和语义特征进行表达。
为解决第二个问题,最重要的是能够建立一个更加鲁棒的概率主题模型,从而挖掘背后的隐含主题信息使得观察到的多模态主题文档的似然度值达到最大。
为解决第三个问题,最有效的解决方式是把不同模态的属性特征映射到共同的嵌入子空间中,从而最大化不同模态信息之间的关联信息。
当前已有一些研究者针对多模态数据建模提出不同方法,从建模角度来看这些方法大致可以分为两类,第一类是统计依赖建模方法,第二类是构建联合概率生成模型方法。
(1)统计依赖的建模方法
统计建模方法的核心思想是将不同模态的数据特征映射到相同的潜在空间,从而期望最大程度地挖掘不同模态数据特征之间的统计相关性。以图像和文本为例,通过构建相应的映射矩阵,分别将不同结构的图像特征和文本特征映射到相同的公共子空间中,在公共子空间中计算图像和文本的相关性,越相关的图像和文本在公共子空间中的距离也就越近,反之距离越远意味着图像与文本的相关性也越低。典型相关性分析方法(Canonical Correlation Analysis,CCA)是一种最典型的统计依赖方法,其通过求取视觉特征矩阵和语义特征矩阵的最大相关性得到其相应的空间基向量矩阵;空间基向量矩阵最大化地保持图像视觉特征和语义特征的相关性,并提供其映射到同构子空间的映射关系;进而将图像的视觉特征向量和语义特征向量映射到同维度下同构子空间中并构建跨模态融合特征,实现媒体数据不同模态信息的统一表示。之后的工作如KernelCCA(KCCA)以及deepCCA(DCCA)在更深层次里来对图像和文本之间的依赖关系进行探讨。
工作[4]将统计建模方法与主题模型相结合起来,该方法首先利用潜在狄利克雷模型来分别提取图像的视觉主题特征和文本的文本主题特征,之后利用典型相关性方法将视觉主题特征与文本主题特征映射到同构子空间中以发现并计算其相关性。其在[5]中扩展其的工作,并利用KCCA来计算其相关性。
(2)构建联合概率生成模型方法
多模态主题模型是构建联合概率生成模型的典型代表方法,最近几年已有不少相关工作来针对多模态文档中的视觉内容和语义描述来进行概率主题建模[6,7,8,9,10]。[Blei2003]在其2003年的工作中建立一系列的逐级复杂的主题模型[11],其中Correspondence Latent Dirchlet Allocation(Corr-LDA)是其中最优的跨模态主题模型,该模型假设不同模态之间的隐含主题之间存在相应的依赖关系,即相应的标注隐含主题是来自于图像视觉信息背后的隐含主题。这一假设建立一个单向的映射关系即文本词汇的生成依赖于图像的视觉内容信息。之后,[Wang2009]提出一种有监督的主题模型来学习图像和标注词之间的潜在关系[12],[Putthividhva 2010]则提出一种基于主题回归的多模态潜在狄利克雷模型[13]。[Rasiwasia2010]研究多模态文档中文本和图像内容联合建模[3]。[Nguyen 2013]提出一种图像标注的方法,该方法是基于联合特征与词的分布以及词与主题的分布[9]。[Niu2014]提出一种半监督的关系主题模型来对图像内容以及图像之间的关系进行显式建模[14]。[Wang2014]则提出一种半监督的多模态共同主题加强模型,该模型探讨不同模态主题之间相互促进的关系[15]。[Zheng2014]提出一种针对DocNADE的有监督变种模型来对图像的视觉词汇、标注词汇以及类标的联合分布进行建模[16]。[Chen,2015]通过构建视觉-情感LDA模型来解决图像和文本之间的建模鸿沟[17]。
通过以上分析可以看出,当前方法在多模态文档建模时都取得一些进展,然而以上所有方法仍未充分考虑以下三个方面所带来的影响:
(1)多模态文档中深度信息挖掘——大多数现有的图像-标签相关度学习方法通常只关注于传统的视觉特征表示方法以及标注信息特征来探索不同模态之间的关联,并没有考虑这些不同模态中所蕴含的深度特征。对于构建全局视觉语义和内部语义关联来说,这将会导致一系列严重的信息缺失问题。而对多模态文档的深度探索则可以弥补这一缺陷,使得得到的特征元素更好地来表示多模态文档。
(2)基于深度分析的关系主题相关性建模——多数现有的主题建模方法在考虑构建不同模态的主题相关性时,通常基于这样的假设,即不同模态背后所隐藏的主题是一致的。而这样的假设通常来说过于绝对,会在构建主题相关性的同时引入一些不必要的噪声,因此构建一个更加合理的假设,融合深度的特征信息,形成一个更加优化的关系主题相关性建模机制变得十分重要。
(3)基于深度主题特征的跨模态相关度学习——多数现有的多模态主题模型在计算不同模态之间相关性时通常直接考虑去匹配不同模态背后所隐藏的主题分布特征,从而抓到视觉图像与文本描述之间的内在关联。然而,这样的一种直接匹配方式并没有很好地考虑图像和文本的异构性,因此通过将深度主题特征映射到公共空间从而学习其相关性能够很好地挖掘其相关性,从而解决上面所提出的问题。
因此,非常有必要借鉴当前已有的相关成熟技术,同时从各方面考虑以上问题,更加全面地分析与计算不同模态之间的主题相关性计算方法。本发明就是由此激发,从局部到整体,设计一种新颖的技术框架(包括三个主要算法)涵盖,多模态文档中的深度词汇构建、关系主题模型构建、异源主题相关性学习,从而建立有效的跨模态主题相关性计算方法,最终为跨媒体图像检索性能进行改进。
技术实现要素:
本发明的目的在于提出一种基于深度学习的跨模态主题相关性建模方法,以提高跨媒体社会图像检索性能。
本发明首先提出一个新颖的深度跨模态主题相关性关联模型,该模型针对大规模多模态语料进行建模,能够深入分析和理解多模态文档中图像和文本之间的关联信息,利用所构建模型,能够有效促进跨媒体检索的性能。该模型主要包括以下几个部分:
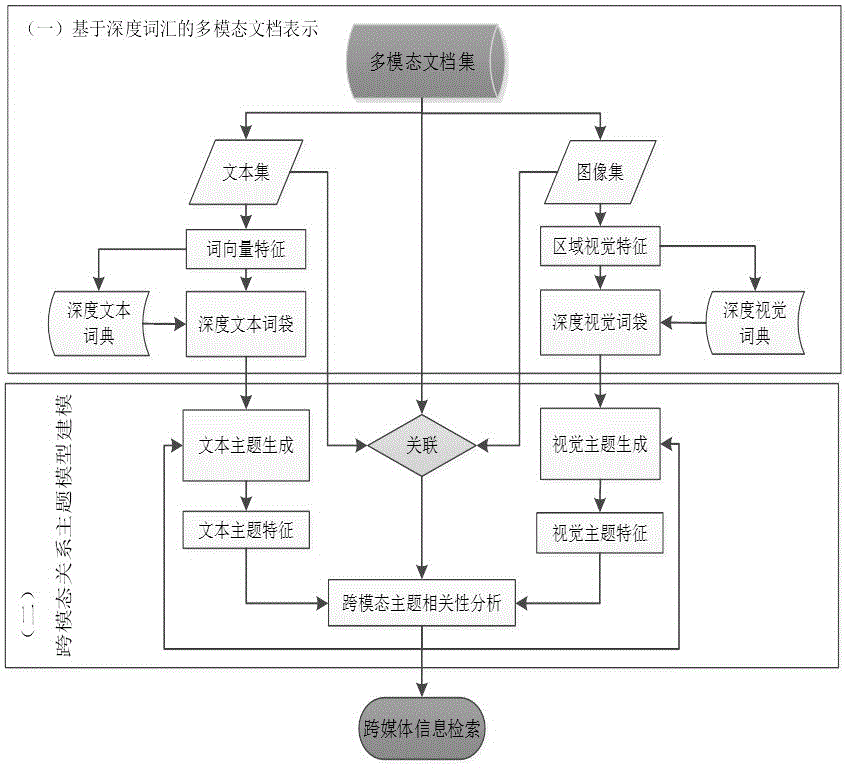
(1)深度词汇构建(DeepWordConstruction)。针对多模态文档,利用深度学习技术分别构建深度词汇作为基本元素进行表示;深度词汇包括深度视觉词汇和深度文本词汇,其中,深度视觉词汇用来更好地描述文档中的图像视觉内容,而深度文本词汇则作为用来描述文档中文本内容的基本元素。与传统的视觉词汇和文本词汇相比,深度词汇能够更深层次地挖掘文档的语义信息。通过这样的构建方式,多模态的文档可以用深度词汇来更好地表示。
(2)多模态主题信息生成(Multimodal Topic Information Generation)。在构建的深度词汇基础上,进一步地利用主题模型LDA来挖掘不同模态数据背后所隐藏的主题信息。主题模型假设文档集背后有一组共同的主题集,并且文档中每一个词都对应着一个主题,基于这样的假设,通过推导可以得到每一个文档背后的主题特征来对文档进行进一步的表示。
(3)跨模态主题关联分析(Cross-modal Topic Correlation Analysis)。假设不同模态的文档背后所隐藏的主题是异源但又相关的,比如在文本文档中“婚礼”对应的主题可能与图像背后“白色”主题有着很高的关联信息,因此通过构建共同子空间的方法把不同模态的主题特征映射到公共子空间中,以找到不同模态之间的关联信息。
(4)关系主题建模(Relational Topic Modeling)。关系主题模型在生成不同模态的主题特征时,同时考虑图像和文档的关联信息,即在构建某一文档的主题时不但考虑同一模态的信息,同时还考虑与其他模态的关联信息,从而使得最终的主题融合多模态信息,并最终构建得到多模态文档背后的主题分布以及跨模态关联信息。
较之于当前已有的多模态主题建模方法而言,本发明所提出的方法在应用中存在着两大优势:第一,准确度高,主要体现在:本方法利用构建的深度词汇来代替传统词汇,能够更深入地挖掘模态深层次信息,能够很好地缓解语义鸿沟所带来的问题,从而能够更好地促进跨媒体检索的效率。第二,适应性强,因为所构建的模型很好地针对不同模态之间的关联进行建模,所以可以适用于图像检索文本以及文本检索图像双向跨媒体信息检索,而且该模型也可以更加方便地扩展到针对其他模态的跨媒体信息检索上(如音频等)。
本发明提供的基于深度学习的跨模态主题相关性建模方法,具体步骤如下:
(1)数据预处理:从多媒体数据集中采集不同模态的数据图像,得到图像和图像描述数据,整理图像标注数据集中不常出现或者无用的标注词;
(2)提取多模态深度特征:利用深度学习方法来提取图像的视觉特征与图像描述的语义特征。具体来说,分别利用Region-CNN(Convolutional Neural Network)模型和Skip-gram模型来抽取图像的区域特征和文本的词汇特征。其中,Region-CNN首先检测图像中有代表性的区域候选集,之后利用预训练的卷积神经网络来对抽取相应区域所对应的特征;Skip-gram模型则是利用文本词汇与词汇之间的共现信息直接训练得到词汇的特征向量表示。
(3)构建深度词袋模型:首先采用聚类算法K-means将步骤(2)中所得到的图像区域特征和文本词汇特征进行聚类,得到限定维度的深度视觉词典和深度文本词典,进而将相应图像中所有的区域特征映射到相应的视觉词典,从而构建得到深度视觉词袋模型,相似地,所有的文本中的词汇也可以映射到文本词典得到深度文本词袋模型;
(4)多模态主题生成:利用潜在狄利克雷模型的假设来模拟整个多模态数据集的生成过程,并且推导得到文本集合和图像集背后所隐藏的主题分布特征,充分利用词汇之间的共现信息;
(5)融合跨模态主题相关性分析的关系主题模型建模:构建相应的关系主题模型,即在构建主题模型的同时考虑不同模态之间主题特征的相关性,将步骤(4)中得到的多模态主题特征作为初始值,同时利用图像和文本之间的关联信息来计算图像和文本之间的相关性,利用计算得到的相关性来更新多模态文档的主题信息,从而交叉迭代地进行相关性计算与主题分布更新进而构建得到最终的关系主题模型;
(6)基于主题相关性的跨媒体信息检索:将得到的跨模态主题相关性应用到跨媒体信息检索中,分别是给定某种模态的查询,利用相关性计算得到与该查询最相关的其他模态的数据。
下面对以上各步骤进行详细的描述:
(一)数据预处理
该步骤主要对采集不同模态的数据图像进行初步的预处理,具体来说,因为图像所包含的标注当中包含一些噪音,这些噪音是因为用户标注的随意性造成,因此可以通过词频过滤的方式,将词频低于某个阈值的词过滤掉从而得到新的词典。
(二)提取多模态深度特征
本发明中,分别利用Region-CNN和Skip-gram模型来抽取图像的区域特征和文本的词汇特征。下面分别进行说明:
给定图像,Region-CNN首先利用选择搜索的方法从图像选择出物体可能出现的位置作为候选集(通常2,000个左右),以region的形式存在。之后,再针对每个区域提取CNN特征。在具体实现上,Region-CNN将每个图像区域转换成为固定的像素尺寸227*227,用于提取特征的卷积网络由5个卷积层和2个完全连接层构成。用Region-CNN提取视觉特征相比较传统的视觉特征,其优势主要体现在CNN所提取的深层次特征更加接近图像本身的语义,可以在一定程度上缓解语义鸿沟的问题。
给定文本文档,利用Skip-gram模型训练得到文本文档中出现的每一个词对应的特征向量。Skip-gram模型是一种非常有效的方法来学习文本词汇的分布式表示,该模型最早由Mikolov等人在2013年提出,之后在不同的自然语言处理的任务中得到广泛应用。该模型能够很好地捕捉文本词汇之间的语法和语义关系,并且使得语义相似的词语能够聚合在一起,相比较传统的文本词向量学习方法。Skip-gram的一个重要的优势在于因为不涉及到复杂的密度矩阵操作,其针对海量数据训练时的训练效率极高。用TD来表示整个多模态文档数据集合的文本描述部分,TW是在TD中出现过的所有的文本词汇,TV是文本词汇对应的词典,对于TW中的每一个词汇tw,ivtw和ovtw是针对tw的输入特征向量和输出特征向量,Context(tw)是词tw在其上下文中出现的词汇,在本发明中将上下文对应的窗口大小设置为5,将整个文本数据集所对应的所有输入向量和输出向量统一用一个长参数向量来表示W∈R2*|TV|*dim,其中dim是输入向量和输出向量的维度。因此,整个Skip-gram模型的目标函数可以如下描述:
对于Skip-gram训练来说,利用传统的softmax来训练所带来的计算代价会非常的高,因此负样本采样方法被利用来近似计算logP(twj|twi),其计算公式如下所示:
其中,σ(·)是sigmoid函数,m是负样本的数量,每一个负样本都是从基于词频的噪音分布P(tw)所生成的。
(三)构建深度词袋模型
在步骤(二)得到相应深度词汇的基础上,进一步通过向量量化(Vector Quantization)[25]的方法来构建深度词袋模型。具体来说,对于利用R-CNN提取得到的区域候选集以及相应的特征,首先利用K-means的方法将多模态文档数据集中所有图像所包含的区域特征来进行聚类,得到固定数量的类别,每一个聚类类别的中心点作为该类别的代表元素,所有这些类别构成一个相应的词典。之后,把图像里的每一个候选区域都映射到相应的类别当中来表示,映射方法是通过计算每一个区域的特征与类别中心特征的欧氏距离,从而找到与区域特征最近的相应的类别,在向量对应该类别的位置累加。利用这样的做法可以把整个数据集中的每一幅图像都表示成为深度视觉词袋的形式,即每一幅图像对应一个向量,向量的维度是类别的数目,而向量的元素值是该类别在图像中出现的次数,用向量VT∈RC来表示,其中C是聚类得到的类别数目。同样地,对于文本文档所对应的所有的词向量,也都可以通过聚类的方式来得到相应的深度文本词典,而最终用同样的映射方法将每一个文本都表示成深度文本词袋的形式。
(四)多模态主题生成
多模态信息对于多模态文档内容来说是一种非常重要的表达方式,也就是说,把图像的视觉信息与语义描述结合起来。因此,为更好地计算视觉图像与文本标注之间的跨模态相关性,更加准确地提取出有代表性的多模态特征变得十分重要,而多模态特征表示能够更好地探索图像的视觉属性与语义表达特征之间的关联。
潜在狄利克雷分配(LDA)算法是一个针对离散数据的生成式概率模型,该算法受到图像/文本研究领域的高度关注,LDA利用一组概率分布来表示每篇文档,而文档中的每个词都是从一个单独的主题所生成。LDA的优势在于其考虑文档的内在统计结构比如不同词在整个文档集合中的共现信息等,它假设每篇文档中的每一个词汇都是从一个单独的主题所生成,而该主题是由一个在所有主题上的狄利克雷分布所生成。LDA将每一篇文档都表示成一组在主题集合上的概率分布向量,这些向量用于表示社会图像的视觉特征以及文本特征。
在步骤(四)中,利用潜在狄利克雷模型分别对图像和文本集合进行概率建模,潜在狄利克雷模型假设在文档集的背后隐藏着一个共同的主题集合,而具体的每一篇文档背后又分别对应着在该主题集合上的一个概率分布,该文档中的每一个词背后都对应着一个由该概率分布所生成的主题;而所有文档的概率分布不是毫无关系的,都是从一个共同的狄利克雷分布所生成;在此模型假设的基础上,将步骤(三)得到的深度视觉词袋与深度文本词袋作为输入,利用LDA模型来推导得到不同模态文档(文本文档和视觉文档)背后所隐藏的概率主题分布,为下一步建立融合跨模态关联信息的关系主题模型建立基础。
(五)融合跨模态主题相关性分析的关系主题模型建模
构建关系主题模型将不同模态之间的相关性信息融入到主题模型构建过程中,具体来说,将步骤(四)得到的不同模态的主题分布作为初始值,通过将不同模态的主题特征映射到公共子空间的方式来计算得到不同模态主题特征之间的相关性,并将该相关性的计算融入到主题模型中,进而在推导某一模态的文档背后所隐藏的主题时考虑与另一模态的相关性信息,从而使得最终得到的主题信息不仅考虑到同模态之间的分布信息,同时也考虑与其他模态之间的关系。
这一步骤的主要目标在于构建一个联合概率分布,使得观察到的多模态文档似然度值达到最大。在构建模型的过程中,将多模态文档集合DM分为三部分构成,即第一部分是视觉图像集合DV,第二部分是文本描述集合DT,第三部分是链接集合LVT(该集合指示图像和文本之间的关联信息)。其中,DV由深度视觉词汇集合DWV构成,而DVV是深度视觉词典,同时文本描述集合DT由深度文本词汇集合DWT构成,DVT是深度文本词典。对于lvt∈LVT,lvt=1意味着视觉图像dv∈DV与文本描述dt∈DT是相关的,而lvt=0则意味着视觉图像dv与文本描述dt是不相关的。基于以上描述,关系主题模型形式化表示如下:给定TSV为视觉主题集合,TST是文本主题集合,α和β是两个超参数,其中α针对主题的狄利克雷分布,β针对主题-深度词汇的狄利克雷分布,θv对应视觉图像dv背后的主题分布,θt对应视觉图像dt背后的主题分布,Φ是每个主题对应所有深度词汇所对应的多项式分布,z是由θ实际生成的对应所有词汇的背后主题信息,Dir()与Mult()分别表示狄利克雷分布与多项式分布,Nd表示在文档d中的深度词汇的数量,n表示第n个深度词汇。整个关系主题模型的生成过程如下所示:
(1)对于视觉主题集合中的每个主题tv∈DTV:
(a)根据主题-视觉词汇的狄利克雷分布采样得到tv对应所有视觉词汇的多项式分布,即:φvtv~Dir(φv|βv)。
(2)对于文本主题集合中的每个主题tt∈DTT:
(a)根据主题-文本词汇的狄利克雷分布采样得到tt对应所有文本词汇的多项式分布,即:φttt~Dir(φt|βt)。
(3)对于每一个视觉文档d∈DV:
(a)根据在主题集合上的狄利克雷分布采样得到d背后对应的主题分布,即:θvd~Dir(θv|αv)。
(b)对于d中的每一个深度视觉词汇wvd,n:
i.根据文档d背后的主题分布得到该词汇对应的主题,即:zvd,n~Mult(θvd)
ii.根据主题-视觉词汇采样得到在文档该位置对应的词汇,即:wvd,n~Mult(φvzd,n)
(4)对于每一个文本文档d∈DT:
(a)根据在主题集合上的狄利克雷分布采样得到d背后对应的主题分布,即:θtd~Dir(θt|αt);
(b)对于d中的每一个深度文本词汇wtd,n:
i.根据文档d背后的主题分布得到该词汇对应的主题,即:ztd,n~Mult(θtd);
ii.根据主题-文本词汇采样得到在文档该位置对应的词汇,即:wtd,n~Mult(φtzd,n);
(5)对于每一个链接lvt∈LVT,表示视觉文档dv与文本文档dt之间的关联信息:
(a)根据dv与dt的主题特征来计算其相关性从而对lvt进行采样,即:Mv,Mt),其中和分别对应文档dv与dt的经验主题分布,和是两个映射矩阵分别映射视觉和文本主题特征到公共子空间,其中公共子空间的维度是dim维,TCor(lvt=1)表示文档dt与dv的主题相关性,而TCor(lvt=0)表示文档dt与dv的主题非相关性。
基于以上过程,最终构建联合概率分布形式来针对整个多模态文档集合进行建模,如下所示:
其中,第一项对应主题-深度词汇的生成过程,中间两项对应深度视觉词汇与深度文本词汇的生成过程,最后一项表示图像-描述连接的生成过程。
(六)跨媒体信息检索(关系主题模型的应用)
步骤(六)是步骤(五)所建立的关系主题模型,用于跨媒体信息检索,以图像和文本为例,跨媒体信息检索可以分为两类,即文本-查询-图像和图像-查询-文本,文本-查询-图像考虑的是根据给定的查询文本,利用关系主题模型计算不同图像对该文本相关度来对所有图像进行排序,而图像-查询-文本则是根据不同文本文档对于给定查询图像的相关度来对所有文本文档进行排序。
对于给定查询(例如利用图像查询文本),利用关系主题模型推导出相应的主题特征,并且利用步骤(五)中得到的主题特征的相关性计算方法来计算与其他模态文档之间的相关性信息(比如文本文档),通过相关性信息的高低来对文本文档进行排序,从而返回得到与查询图像最相关的文本文档。同样地,上述过程也适用于利用文本查询图像的跨媒体信息检索过程。
综上所述,本发明针对多模态文档中不同模态之间的内容异构性和关联性,提出一种基于深度学习的跨模态主题相关性建模方法,进而可以用概率模型的形式对整个多模态文档的生成过程进行描述,并将不同模态的文档之间的相关性进行量化。本发明方法可以有效运用于针对大规模图像的跨媒体信息检索中,提高检索相关性,增强用户体验。
附图说明
图1是本发明的流程图。
图2是构建深度词汇表示多模态文档的示意图。
图3为跨模态关系主题相关性建模过程的示意图。
图4为所提出的关系主题模型与传统的多模态主题模型的对比图。
图5为利用所构建的关系主题模型进行跨媒体信息检索的效果图。
具体实施方式
下面结合附图,详细介绍本发明针对社会图像的跨模态相关度计算方法。
(一)采集数据对象
采集数据对象,得到图像和图像标注数据,整理图像标注数据中在整个数据集里不常出现或者无用的标注词。一般在取得的数据集中,其中带有很多噪音数据,所以在使用这些数据进行特征提取之前就应该对其进行适当的处理和过滤。对于图像而言,得到的图像都是统一的JPG格式,不需要做任何变换。对于图像的文本标注而言,得到的图像标注含有很多的无意义单词,如单词加数字没有任何含义的单词。有些图像标注多至几十个,为了让图像标注很好地描述图像的主要信息,应舍弃那些无用的、无意义的标注。因此,所采取的处理方法步骤如下:
步骤1:统计数据集标注中所有单词在数据集中出现的频率;
步骤2:过滤掉那些单词中带有数字的无意义单词;
步骤3:对于每个图像标注中在整个数据集中出现频率较少的单词,将其认为是图像中比较次要的信息,并予以删除。
通过上述步骤,便可得到处理后的图像标注。对于步骤3中去除频率较少的单词,其理由在于图像聚类里同一类图像的标注还是存在很多相同、意义相近的单词。因此按照出现频率来对其进行过滤完全合理。
(二)多模态特征提取
图2展示利用深度学习方式提取特征并构建深度词汇的过程,在本发明中利用Region-CNN来对图像的区域进行检测并且提取出对应的CNN特征,特征的维度是4,096维。通常来说,Region-CNN针对每一幅图像会选择出2,000个左右的区域作为候选,这样一幅图像对应的特征矩阵就有2,000*4,096维。而之后如果对所有图像的所有区域进行聚类的话,数据量为M*2,000*4,096,M为图像的数目,显然这样的数据量带来的时空代价是巨大的。为解决这样一个实际问题,在具体操作中进行内部-外部聚类结合的方法,即首先对于每一幅图像中包含的所有区域进行一次内部聚类(聚成10类),之后再对所有区域进行一次外部聚类(聚成100类),这样实际上最终进行外部聚类的数据量就为M*10*4,096,很大程度上降低聚类的时空代价。另外一个需要说明的问题,无论是Region-CNN提取视觉特征还是Skip-gram提取词汇特征都利用预训练模型来进行操作,其中Region-CNN是在ImageNet上利用AlexNet进行预训练,而Skip-gram则利用在包含60亿词汇的维基百科文档上训练得到的模型。这主要是因为深度神经网络的训练需要大量的数据,因此为避免过拟合的问题,利用在大规模数据集上训练好的模型来对实际数据进行操作以提取相应的特征。
(三)跨模态主题相关性计算
图3展示跨模态关系主题相关性建模过程,在之前的介绍中提到利用来计算视觉文档dv与文本文档dt的相关性,Mv和Mt分别是针对视觉主题特征和文本主题特征的映射矩阵,TCor(lvt=1)表示文档dt与dv的主题相关性,而TCor(lvt=0)表示文档dt与dv的主题非相关性,TCor()的定义如下所示:
这里采用两种模式来针对不同的数据类型,模式一是利用Sigmoid函数来将点积映射到[0,1]范围内,而模式二则通过归一化两个向量的余弦相似度来计算主题相关性。同时,基于生成的多模态主题分布,可以利用最大似然估计(MLE)的方法来训练得到参数Mv和Mt,即最大化公式(4)的log似然度值,目标函数定义为如下所示:
基于这样的目标函数,映射矩阵Mv和Mt可以通过梯度下降法计算得到。需要说明的是,在实际的训练过程中,假设多模态文档的数量为|DM|,通常情况下每一个多模态文档中只包含一组图像和文本,图像文档的数目和文本文档的数目大体上相同,且都等于多模态文档的数量,即|Dv|=|DT|=|DM|。如果在同一多模态文档中出现的文本和图像是相关的,而不在同一多模态文档则不相关,这样转换得到的训练数据的正样本(即图像-文本相关对)和负样本(图像-文本不相关对)的比例约为1/|DM|。这样的比例会导致负样本与正样本的比例严重失调,另外图像和文本不在同一多模态文档也不能完全说明该图像和文本完全不相关(可能属于同一类别),因此在实际中令负样本与正样本的比例为1:1,且在随机选择负样本时满足如下的约束,即对应的图像和文本不能来自同一类别。
(四)多模态关系主题模型推导
公式(3)展示在本发明中所构建的关系主题模型,利用吉普斯采样的方法来推导得到模型的参数[26]。吉普斯采样的目的是要得到多模态文档中每一个词汇背后所隐含的主题,在采样的过程中首先推导得到关于深度词汇、词汇对应的主题信息以及相应的跨模态关联链接的边缘分布,如下所示:
其中,md,tt对应的是在文档d中主题tt出现的次数,ntt,w对应的是在整个文档集中主题tt所生成的词汇的数目。根据公式(6)可以进一步推导得到针对主题信息z的单变量概率分布,进而得到针对文档中每一个词的背后主题的采样规则。如公式(7)所示,
其中表示在文档d中除去当前词后主题tt的出现次数,而表示除去当前词主题tt所包含的词的数目。基于这样的采样规则,可以采样得到整个文档集中每一个词背后所隐含的主题信息。同样地,在每一次的采样结束后,都利用公式(5)计算在当前采样得到的主题分布基础上如何得到映射矩阵Mt和Mv,而在当前采样时间内得到的Mt和Mv将作为下一次采样过程的输入,如此循环往复,直到达到迭代结束条件,从而得到最终的主题信息以及映射矩阵Mt和Mv。相应地,关系主题模型中其他参数如θV、θT则可以通过计算公式(8)最终得到:
(五)应用示例
图5为利用所构建的关系主题模型进行跨媒体信息检索的效果图,其中分为两种模式,一种是利用图像检索文本(Image Query-to-Text),另一种是利用文本检索图像(Text Query-to-Image),其相关度分数计算如公式(9)所示。
参考文献
[1]Fan,J.P.;He,X.F.;Zhou,N.;Peng,J.Y.;and Jain,R.2012.Quantitative Characterization of Semantic Gaps for Learning Complexity Estimation and Inference Model Selection.IEEE Transactions on Multimedia 14(5):1414-1428.
[2]Datta,R.;Joshi,D.;Li,J.;and Wang,J.Z.2008.Image Retrieval:Ideas,Influences,and Trends of the New Age.ACM Computing Surveys(CSUR)40(2),Article5.
[3]Rasiwasia,N.;Pereira,J.C.;Coviello,E.;Doyle,G.;Lanckriet,G.R.G.;Levy,R.;and Vasconcelos,N.2010.A New Approach to Cross-modal Multimedia Retrieval.In Proceedings of MM 2010,251-260.
[4]Pereira,J,C.;Coviello,E.;Doyle,G.;Rasiwasia,N.;Lanckriet,G.R.G.;Levy,R.;and Vasconcelos,N.2014.On the Role of Correlation and Abstraction in Cross-Modal Multimedia Retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence(PAMI)36(3):521-535.
[5]Barnard,K.;Duygulu,P.;Forsyth,D.;Freitas,N.;Blei,D.M.;and Jordan,M.I.2003.Matching Words and Pictures.Journal of Machine Learning Research.3:1107-1135.
[6]Wang,X.;Liu,Y.;Wang,D.;and Wu,F.2013.Cross-media Topic Mining on Wikipedia.In Proceedings of MM 2013,689-692.
[7]Frome,A.;Corrado,G.S.;Shlens,J.;Bengio,S.;Dean,J.;Ranzato,M.A.;and Mikolov,T.2013.DeViSE:A Deep Visual-Semantic Embedding Model.In Proceedings of NIPS 2013.
[8]Feng,F.X.;Wang,X.J.;and Li,R.F.2014.Cross-modal Retrieval with Correspondence Autoencoder.In Proceedings of MM 2014,7-16.
[9]Nguyen,C.T.;Kaothanthong,N.;Tokuyama,T.;and Phan X.H.2013.A Feature-Word-Topic Model for Image Annotation and Retrieval.ACM Transactions on the Web 7(3),Article 12.
[10]Ramage,D.;Heymann,P.;Manning,C.D.;and Molina,H.G.2009.Clustering the Tagged Web.In Proceedings of WSDM 2009,54-63.
[11]Blei,D.M.;and Jordan,M.I.2003.Modeling Annotated Data.In Proceedings of SIGIR 2003,127-134.
[12]Wang,C.;Blei,D.;and Fei-Fei L.2009.Simultaneous Image Classification and Annotation.In Proceedings of CVPR 2009,1903-1910.
[13]Putthividhya,D.;Attias,H.T.;and Nagarajan,S.S.2010.Topic Regression Multi-Modal Latent Dirichlet Allocation for Image Annotation.In Proceedings of CVPR2010,3408-3415.
[14]Niu,Z.X.;Hua,G.;Gao,X.B.;and Tian,Q.2014.Semi-supervised Relational Topic Model for Weakly Annotated Image Recognition in Social Media.In Proceedings of CVPR2014,4233-4240.
[15]Wang,Y.F.;Wu,F.;Song,J.;Li,X.;and Zhuang,Y.T.2014.Multi-modal Mutual Topic Reinforce Modeling for Cross-media Retrieval.In Proceedings of MM 2014,307-316.
[16]Zheng,Y.;Zhang,Y.J.;and Larochelle,H.2014.Topic Modeling of Multimodal Data:an Autoregressive Approach.In Proceedings of CVPR 2014,1370-1377.
[17]Chen,T.;SalahEldeen,H.M.;He,X.N.;Kan,M.Y.;and Lu,D.Y.2015.VELDA:Relating an Image Tweet’s Text and Images.In Proceedings of AAAI 2015.
[18]Girshick,R.;Donahue,J.;Darrell,T.;and Malik,J.2014.Rich feature hierarchies for accurate object detection and semantic segmentation.In Proceedings of CVPR 2014,580-587.
[19]Hariharan,B.;Arbelaez,P.;Girshick,R.;and Malik,J.2014.Simultaneous Detection and Segmentation.In Proceedings of ECCV 2014,297-312.
[20]Karpathy,A.;Joulin,A.;and Fei-Fei,L.2014.Deep Fragment Embeddings for Bidirectional Image Sentence Mapping.In Proceedings of NIPS 2014.
[21]Zhang,N.;Donahue,J.;Girshick,R.;and Darrell,T.2014.Part-Based R-CNNs for Fine-Grained Category Detection.In Proceedings of ECCV 2014,834-849.
[22]Mikolov,T.;Sutskever,I.;Chen,K.;Corrado,G.;and Dean,J.2013.Distributed Representations of Words and Phrases and their Compositionality.In Proceedings of NIPS 2013.
[23]Tang,D.Y.;Wei,F.R.;Qin,B.;Zhou,M.;and Liu,T.2014.Building Large-Scale Twitter-Specific Sentiment Lexicon:A Representation Learning Approach.In Proceedings of COLING 2014,172-182.
[24]Karpathy,A.;Joulin,A.;and Fei-Fei,L.2014.Deep Fragment Embeddings for Bidirectional Image Sentence Mapping.In Proceedings of NIPS 2014.
[25]Sivic,J.,and Zisserman,A.2003.Video Google:A Text Retrieval Approach to Object Matching in Videos.In Proceedings of ICCV 2003,2:1470-1477.
[26]Griffiths,T.L.;and Steyvers,M.2004.Finding Scientific Topics.
In Proceedings of the National Academy of Sciences of the United States of America,101(1):5228-5235。
- 还没有人留言评论。精彩留言会获得点赞!