一种量化确定专业领域词汇集最优维度的方法与流程
本发明属于计算机技术领域,涉及专业领域词汇的构建方法,具体涉及一种量化确定专业领域词汇集最优维度,进而得到专业领域词汇集的方法。
背景技术:
专业领域词表是领域信息处理的基础必备条件,领域词表的缺乏会显著影响领域信息的搜索和分类性能。目前多数词汇选择方法是基于文档频率、术语频率等统计特征来选择,其固有缺点是不利于低频词;或通过在文档中选择那些与预设的种子词共同出现的或满足某些关联规则的词汇;其固有缺点是需要人工专家事先设计大量的规则;或基于概率统计方法选择词汇,但专业领域的文档数量较通用文档极少,难以满足概率统计的方法需要用到的大量的领域信息。
专业领域词汇的选择一般很难选出全部的词汇,而词汇集合的维度太大则不利用于计算机的处理。因此专业领域词汇选择方法所遵循的原则可以描述为:足够代表性、足够区分度、足够简单性。综观目前已有的各种方法,多集中在代表性、区分度、简单性方面对典型的算法进行改进,对于什么是“足够”则一般依赖人工经验在算法中设定阈值来衡量。然而一些专业词汇可能与其它专业领域交叉使用,也可能明显属于通用词汇,人工判定易引入较多的主观因素,也不易确定一个适用的维度大小。
技术实现要素:
本发明提供一种自动量化确定专业领域词汇集合最优维度,进而得到专业领域词汇集的方法,以解决现有专业领域词汇表构建过程需要大量人工经验的问题,将词汇特征维度的选取由经验判断改为定量分析,有效平衡了词汇空间的足够区分度和计算性能。
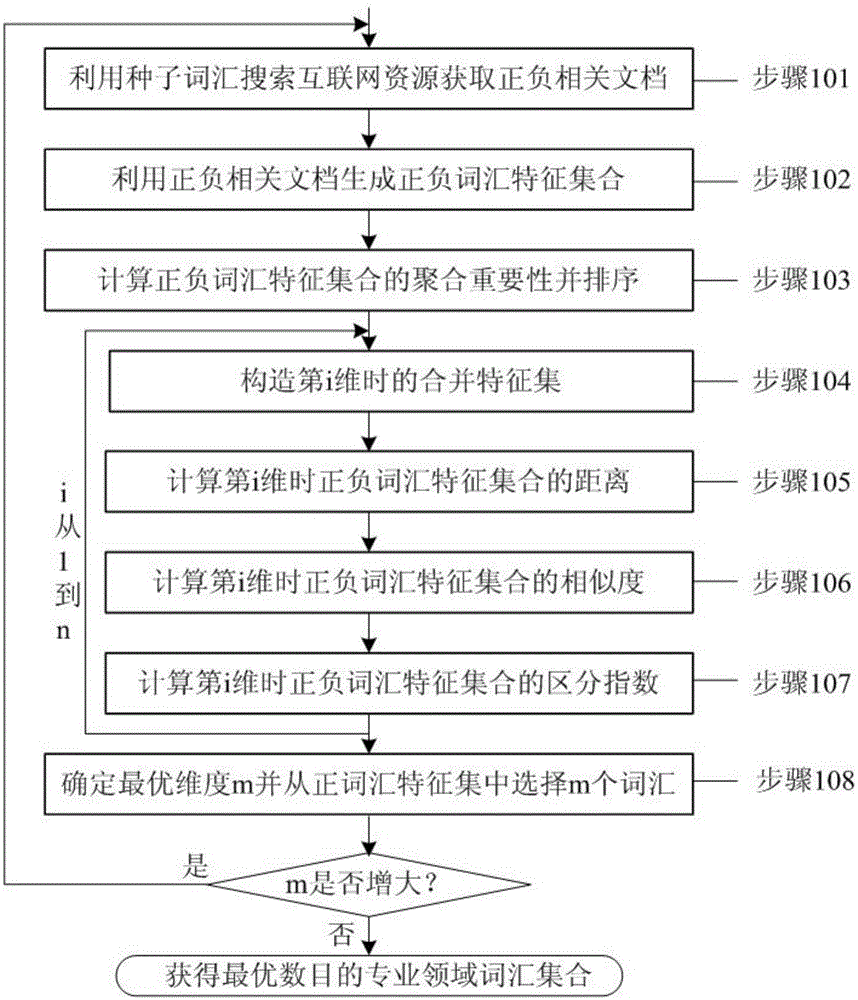
本发明的量化确定专业领域词汇集合最优维度的方法,具体包括以下步骤:
1)选择少量专业领域种子词汇,以定制接口搜索互联网搜索引擎和专业文献索引网站获取样本文档,利用专家标注的样本文档,生成正、负文档相关的词汇集合;
2)计算词汇的聚合重要性,以其建立正、负词汇特征集合的权序关系,生成有序的正、负词汇特征集合;
3)递增特征维度,按序选择该维度数目的正、负词汇,生成合并特征集合;
4)基于合并特征集合计算正、负词汇特征集合之间的距离和相似度,并进一步计算得到区分指数;
5)以区分指数的变化率确定最优的专业词汇集合特征维度,按序从正词汇特征集中选择该维度数目的词汇,生成最优数目的专业领域词汇特征集。
进一步地,以新选择的专业领域词汇作为种子词,重复上述过程进行迭代自举,直至不再获得新的专业领域词汇,从而得到最终的专业领域词汇集。
本发明的优点与积极效果在于:以少量种子词,通过迭代自举,即可获得较为适用的专业领域词汇集合,可以平衡词汇特征空间的足够区分度和计算性能。以聚合重要性来衡量某个词汇在语料库中的重要程度并建立权序关系,基于此重要性计算不同维度正、负词汇特征集合之间的距离、相似性和区分指数,确定最优的专业词汇集合特征维度。
附图说明
图1是本发明的量化确定专业领域词汇集合最优维度的方法的步骤流程图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实例例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整地传达给本领域的技术人员。
如图1所示,本发明的量化确定专业领域词汇集合最优维度的方法具体包括以下步骤:
步骤101,定制到互联网通用搜索引擎及文献资料库的元搜索接口,自动实现互联网文档的抽取。通过此接口,将确定的种子词汇提交搜索,解析返回的结果页面,抽取其中的摘要信息,作为正相关文档,建立正语料库;同时用确定的非种子词汇提交搜索,解析返回的结果页面,抽取其中的摘要信息,作为负相关文档,建立负语料库。优选地,由领域专家对正、负语料库进行人工核验。
步骤102,对正、负语料库中的正、负相关文档进行分词、去除停用词等预处理,生成正、负词汇特征集合。
步骤103,计算正、负词汇特征集合的聚合重要性,以聚合重要性大小对正、负词汇特征集建立权序关系,聚合重要性越大,其在集合中的排列越靠前。
优选地,基于类TF/IDF(term frequency/inverse document frequency)方法计算词汇的聚合重要性。对于TF/IDF方法来说,假设用n表示在语料库中总的文档数,用nt表示所有包含特征项t的文档总数,tft表示语料库中t的词频,用以下公式计算t在整个语料中的聚合重要性Wt,其中0.01为微扰调节系数,C为语料库:
步骤104,对于维度i,利用正、负词汇特征集合构造一个i维的合并特征集,作为正、负词汇集合之间对比计算的基础。
优选地,由于正、负词汇特征集的前i/2个词汇中可能存在相同的词汇,因此为得到i个词汇,可以分别选择以下模式之一继续向后选择更多词汇:平衡模式、左偏模式、右偏模式。其中:
平衡模式是从正、负词汇特征集中轮流按权序逐个选择添加,直至合并特征集的维度达到i;
左偏模式是从正词汇集合中按权序选择添加词汇,直至合并特征集的维度达到i;
左偏模式是从负词汇集合中按权序选择添加词汇,直至合并特征集的维度达到i。
优选地,实验表明平衡模式构造的合并特征集效果更优。
步骤105,对于维度i,计算正、负特征词汇集合之间的距离。
优选地,采用Jaccard距离来计算。
步骤106,对于维度i,计算正、负特征词汇集合之间的相似度。
优选地,采用余弦相似度来计算。
步骤107,对于维度i,计算正、负特征词汇集合之间的区分指数,区分指数是指两个集合间的个体的差异性程度,考虑两方面因素:(1)使得正、负词汇特征集合中的公共元素较少,(2)使得正、负词汇特征集合的综合相似性较小。
优选地,维度i的区分指数定义为维度i时的Jaccard距离和余弦相似度的乘积。
步骤108,确定最优维度m,并从正语汇特征集中选择对应的词汇,得到当前的最优专业领域词汇集合。
优选地,令A、B分别为正、负词汇特征集,Ai、Bi为A、B依权序关系确定的前i个词汇组成的集合,ψ(Ai,Bi)为维度i时的区分指数,Δψ(Ai,Bi)为ψ(A,B)在i点的变化率,表明其变化情况,定义为相邻两点间的变化幅度,Δψ(Ai,Bi)越大,说明ψ(A,B)幅度变化越明显,在图形上对应于拐点。若ψ(Ai,Bi)在维度m时取得最大,则最优维度确定为m。
优选地,利用最近构造的专业领域词汇集,作为新的种子词汇,重复步骤101,直至再得到的专业领域词汇集不再增大或增大幅度低于某个既定的阈值。
本发明采用的方法同时具有自举增大词汇特征集和弹性约束特征集两种功效,与传统的依赖人工经验或基于统计方法的专业领域词汇选择方法相比,可完全自动实现,既能够高效地选择出足够选用的专业领域词汇,又能够有效地控制专业领域词汇特征空间的维度,避免在后续信息处理中造成计算复杂度高甚至“维度灾难”。采用本发明方法构建了中国古建筑领域词汇表,利用22个著名宫殿的名称作为种子词进行自举,处理某通用搜索引擎返回的前10页信息,经过信息抽取共锋利相关结果1989篇(取标题和摘要之内容),在此基础上,构造为正负相关语料,对其进行分词、去除停用词等预处理,按本发明方法最终获取宫殿类领域词汇3843个。
- 还没有人留言评论。精彩留言会获得点赞!