预测请求流量的凭证预签系统及方法与流程
本发明有关于一种凭证预签系统及方法,特别是一种根据预测请求流量并预签凭证的系统及方法。
背景技术:
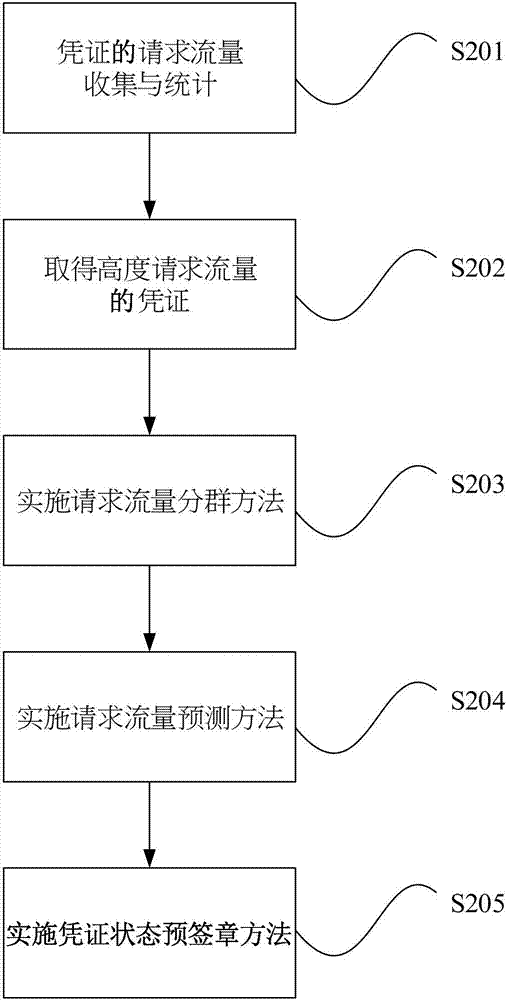
:目前,在线凭证状态通讯协议方法在运作上仍主要是采用实时在线查询凭证和回复凭证等方式,但因目前的回复签章系统在进行签章时会花费较多处理时间,将会进一步造成回复客户端设备时的延宕,另外,请求流量因时段增加也会对凭证服务器和回复签章系统造成无法预期的负担,在无法负荷时最严重将导致系统当机。而为了避免上述状况,目前已有些网络流量预测方法实行于现行技术中,目前的网络流量预测方法主要采用统计方法和灰色理论来进行预估,然而该些技术皆需要进行大量统计,并且因为用户的请求流量变异很大,该些技术很可能得到较大的请求流量估计误差,导致预测不准确。关于流量预测的技术,可参照中华民国专利号第i234974号「植基于灰预测来预测分布式阻断服务攻击的机制」的技术,其主要是以数据收集分类模块,并结合灰色理论与防范策略进行网络流量模式的分析与预测,以藉此判断及防御分布式阻断服务攻击;然而,此方法虽然可以进行网络流量预测和防范网络攻击在实施过程中,其运用灰色理论且需要进行大量统计,和承受网络流量变异过大的可能性,实证出其网络流量估计值实非相当准确。且就算系统已预测出特定时段的可能流量值,该如何纾解高峰时段的负载量,先前技术中仍未见有配合的处理模式。综上所述,故提出一种有效率且系统性的预测凭证请求流量系统或方法,并据其预先处理特定时段的凭证可能高负载量,实为本发明所属领域极其需要的一个课题。技术实现要素:本发明是包含一种预测请求流量的凭证预签系统,其是由下列系统与数据库所组成:其中,本发明预测请求流量的凭证预签系统,包含:一凭证数据库,该凭证数据库是与外部一凭证状态通讯协议服务器链接,该凭证数据库储存有多个凭证被请求的纪录,前述各该凭证被请求的纪录是为外部多个终端设备向外部该凭证状态通讯协议服务器请求凭证的纪录,也即该凭证数据库会将所有时段中终端设备请求某一凭证的时间数据储存于其中;一请求流量预测子系统,该请求流量预测子系统是通过分析该凭证数据库中各该凭证被请求的纪录,通过请求流量分群方法将纪录分群,或是直接使用纪录数据,以建立多个类神经网络来预测各该凭证的被请求流量,该请求流量预测子系统预测后将产生一请求流量预测值;该请求流量预测子系统可通过一种请求流量分群方法将纪录分群后来训练各该类神经网络,或是直接使用纪录数据来训练各该类神经网络,以保留其中预测准确度较高者;该请求流量预测子系统更可通过分析各该凭证被请求的纪录以找出被请求流量较高的凭证,以对这些需求量较高的凭证进行预测;一回复签章子系统,该回复签章子系统接收该请求流量预测值,并依据该请求流量预测值对相应数量的各该凭证预签章以产生多个预签章凭证状态,也即该回复签章子系统即为对某一凭证在特定时段会被请求的数量预先对凭证作签章,以应对该时段到来时的凭证需求;该回复签章子系统会将各该预签章凭证状态储存至该凭证数据库,该凭证数据库提供各该预签章凭证状态至外部该凭证状态通讯协议服务器以供外部各该终端设备请求凭证。其中,该请求流量预测子系统将进行请求流量分群,所述请求流量分群是指该请求流量预测子系统将依据时段统计后的各该凭证的各时段流量数据化为群集,并计算且逐步将群集合并,该请求流量预测子系统可依据合并后的群集对各该类神经网络进行训练。其中,该请求流量预测子系统是通过设定随机类神经网络群算法的相关参数值以建立各该类神经网络。其中,该请求流量预测子系统是依据各该类神经网络的预测准确度是否通过一正确率门坎值以决定是否保留各该类神经网络。其中,该请求流量预测子系统是将保留下的各该类神经网络各自产生的预测值进行权重平均最后产生该请求流量预测值。其中,该回复签章子系统更可向该凭证数据库取得各该凭证被请求的纪录以分析各该凭证的请求离峰时段。其中,该回复签章子系统可在各该凭证的请求离峰时段进行预签章。而本发明也包含了一种预测请求流量的凭证预签方法,其步骤包含:1.一请求流量预测子系统自一凭证数据库中取得各该多个凭证被请求的纪录;2.该请求流量预测子系统分别依据各该凭证对各该凭证被请求的纪录依据时段统计出各该凭证的各时段流量,得依据凭证的各时段流量排序以挑选出高请求流量的多个凭证;3.该请求流量预测子系统分别依据挑选出的各该凭证随机建立多个类神经网络以进行预测各该凭证的被请求流量;4.该请求流量预测子系统依据各该凭证被请求的纪录训练各该类神经网络,该请求流量预测子系统并分析各该类神经网络的预测准确度以保留高准确度的各该类神经网络;5.该请求流量预测子系统依据各该类神经网络的预测产生该请求流量预测值并传输至一回复签章子系统;6.该回复签章子系统接收该请求流量预测值,并得依据该请求流量预测值对相应数量的各该凭证预签章以产生多个预签章凭证状态;以及7.该回复签章子系统将各该预签章凭证状态储存至一凭证数据库以备取用。而该请求流量预测子系统为了进一步训练各该类神经网络,该预测请求流量的凭证预签方法步骤还包含:该请求流量预测子系统将进行请求流量分群,以将历史的请求流量数据分群再输入训练,所述请求流量分群是为该请求流量预测子系统将依据时段统计后的各该凭证的各时段流量数据化为群集,并计算且逐步将群集合并,该请求流量预测子系统可依据合并后的群集对各该类神经网络进行训练。所述请求流量分群包含下列步骤:1.设定初始群集步骤,是将各该凭证请求和查询的纪录中任一凭证的每个时点的请求流量纪录视为一请求流量集合,并以单一时段中的所有集合作为一群集;2.计算标准偏差步骤,是计算前述群集内部各请求流量集合的标准偏差;3.计算距离步骤,是计算前述群集之间的请求流量集合的距离;4.计算距离标准偏差步骤,是计算前述群集之间的请求流量集合的距离的标准偏差;5.相似群集合并步骤,是在前述群集中有一群集符合内部标准偏差大于该群集与另一群集之间距离的标准偏差的状况下,将该群集与该另一群集合并,并计算群集合并后的群集中心;以及6.重复合并步骤,是重复前述相似群集合并步骤直至无有群集符合可合并的状况。其中,该请求流量预测子系统是通过设定随机类神经网络群算法的相关参数值以建立各该类神经网络。其中,该请求流量预测子系统是依据各该类神经网络的预测准确度是否通过一正确率门坎值以决定是否保留各该类神经网络。其中,该请求流量预测子系统是将保留下的各该类神经网络各自产生的预测值进行权重平均最后产生该请求流量预测值。其中,该回复签章子系统更可向该凭证数据库取得各该凭证被请求的纪录以分析各该凭证的请求离峰时段。其中,该回复签章子系统可在各该凭证的请求离峰时段进行预签章。如前所述,该请求流量预测子系统用以产生该请求流量预测值的请求流量预测方法,更可分列详述如下:首先,可以将请求流量预测方法分为两阶段,分别为训练阶段以及实施阶段,其中,训练阶段可以包含两个步骤:1.随机产生多个类神经网络:主要是通过设定随机类神经网络群算法参数值,并向凭证数据库读取凭证状态请求查询纪录的历史数据,以随机建立r个类神经网络模型;2.保留多个预测正确率高的类神经网络:将随机产生的r个类神经网络模型的预测准确度与一准确度门坎值进行比对,以排除低于准确度门坎值的类神经网络模型,保留g个正确率的类神经网络;而若无任何类神经网络模型的正确率高于准确度门坎值时,将回到第1个步骤,重新设定门坎值,并重新训练随机类神经网络。其中,实施阶段也可以包含两个步骤:1.输入实时数据至训练阶段中所保留的预测正确率高的类神经网络:取得实时的凭证状态请求查询纪录,并且依此输入至训练阶段所保留的g个类神经网络模型,进行预测计算;2.加权平均以产生预测值:最后,该请求流量预测子系统将保留下的各该类神经网络各自产生的预测值,运用训练阶段时所得到的正确率作为权重,进行权重平均后以产生该请求流量预测值。其中,本发明还包含了一种请求流量分群方法,包含下列步骤:1.纪录取得步骤,是为一请求流量预测子系统自一凭证数据库中取得多个凭证被请求的纪录;2.设定初始群集步骤,是为该请求流量预测子系统将各该凭证请求的纪录中任一凭证的每个时点的请求流量纪录视为一请求流量集合,并以单一时段中的所有集合作为一群集;3.计算标准偏差步骤,是为该请求流量预测子系统计算前述群集内部各请求流量集合的标准偏差;4.计算距离步骤,是为该请求流量预测子系统计算前述群集之间的请求流量集合的距离;5.计算距离标准偏差步骤,是为该请求流量预测子系统计算前述群集之间的请求流量集合的距离的标准偏差;6.相似群集合并步骤,是为该请求流量预测子系统在前述群集中有一群集符合内部标准偏差大于该群集与另一群集之间距离的标准偏差的状况下,将该群集与该另一群集合并,并计算群集合并后的群集中心;以及7.重复合并步骤,是为该请求流量预测子系统重复前述相似群集合并步骤直至无有群集符合可合并的状况。其中,本发明还包含了一种请求流量预测方法,包含下列步骤:1.一请求流量预测子系统自一凭证数据库中取得多个凭证被请求的纪录;2.该请求流量预测子系统是通过设定随机类神经网络群算法的相关参数值,分别依据各该凭证随机建立多个类神经网络以进行预测各该凭证的被请求流量;3.该请求流量预测子系统依据各该凭证被请求的纪录训练各该类神经网络;4.该请求流量预测子系统依据各该类神经网络的预测准确度是否通过一正确率门坎值以决定是否保留各该类神经网络;以及5.该请求流量预测子系统将保留下的各该类神经网络各自产生的预测值进行权重平均最后产生一请求流量预测值。其中,本发明还包含了一种预签章方法,包含下列步骤:1.一回复签章子系统接收一请求流量预测值,并对该请求流量预测值所预测的多个凭证进行相应数量的各该凭证预签章以产生多个预签章凭证状态;2.该回复签章子系统将各该预签章凭证状态储存至一凭证数据库以备取用;其中,该回复签章子系统得在各该凭证的请求离峰时段进行预签章。如上述的预测请求流量的凭证预签系统及方法,其中,该回复签章子系统是实施了凭证状态预签章方法以进行预签章,其主要也可分为四个步骤:1.接收等待预签章的凭证信息:回复签章子系统可接收凭证信息和前述的请求流量预测值。2.侦测离峰时段:为了节省系统资源并降低高峰时段的负载,该回复签章子系统向该凭证数据库取得各该凭证被请求的纪录以统计分析出各该凭证被请求次数较少的离峰时段,并可以于离峰时段时对凭证状态进行预签章,以达到分流的效果。3.对凭证状态产制签章值:对该请求流量预测值所预测出的多个凭证预签章相应数量的各该凭证以产生多个预签章凭证状态。4.储存预签章凭证状态:将预签章凭证状态的数据储存至凭证数据库,供后续客户端设备查询使用。如前所述,可知本发明详细为一种根据历史资料预测请求流量,并进行凭证预签的系统以及其方法,当可预先对使用量大的凭证进行预签处理,并一再训练进化预测的准确率,是为高效率凭证管理系统的重要一环。附图说明图1为本发明预测请求流量的凭证预签系统的整体系统架构示意图。图2为本发明预测请求流量的凭证预签方法的步骤流程示意图。图3为本发明中请求流量分群方法的步骤流程示意图。图4为本发明中请求流量预测方法的步骤流程示意图。图5为本发明中请求流量预测方法以类神经网络模型1为实例的示意图。图6为本发明中请求流量预测方法的实施阶段举一实例的步骤流程示意图。图7为本发明中请求流量预测方法中凭证状态预签章方法的步骤流程示意图。符号说明:100客户端设备101在线凭证状态通讯协议服务器102请求流量预测子系统103凭证数据库104回复签章子系统s201~s205步骤流程s301~s307步骤流程s401~s402步骤流程s4011~s4012步骤流程s4021~s4022步骤流程s601~s602步骤流程s701~s704步骤流程具体实施方式以下将以实施例结合图式对本发明进行进一步说明。本发明详细来说是一种根据请求流量预测的在线凭证状态通讯协议(onlinecertificatestatusprotocol,ocsp)预签方法与系统;有鉴于现有技术中凭证状态通讯协议的方法运作上仍主要采用实时在线查询以及回复的方式,但由于回复签章子系统在签章时将可能花费许多处理时间,故现有技术的方法将造成回复客户端设备时有所延宕,另外,随着请求流量增加,将逐渐对凭证状态通讯协议服务器和回复签章子系统造成负担,接着在系统无法负荷时即会发生当机情事。此外目前现有技术中,网络流量预测方法一般需要经过大量统计过程后得出,而由于用户的请求流量变异程度较大,故利用现有技术所得出的请求流量估计误差将可能较大。故本发明主要是收集和分析各个凭证在一日的每个时段的被请求流量的集合,再运用将请求流量分群方法将相似时段的请求流量结合为一群,将数据分为多个群组,后续再各别依不同的群组运用将请求流量预测方法进行预测,最后再按照请求流量预测值对该凭证状态签章,以取得较准确的预签章凭证状态数量,并达成回复签章子系统的负载平衡。首先,请参照图1所示,本发明的系统包含至少一个客户端设备100、一在线凭证状态通讯协议(ocsp)服务器101、一回复签章子系统104、一凭证数据库103以及一请求流量预测子系统102,其相互运作的模式及步骤将在后段中详细叙述;再请同时参照下列表一,表一是为以一实施例举出2014/07/01到2014/07/28的期间的凭证请求查询纪录,若配合图1以举例,其中,当多个客户端设备100中的一客户端设备d1于2014/07/01日的00:00:29时欲确认凭证c1状态时,发出请求至在线凭证状态通讯协议服务器101,并由在线凭证状态通讯协议服务器101向凭证数据库103查询和取得凭证c1状态,且在凭证数据库103中留下请求查询纪录,即如表一之中的第一行所示的数据,而该在线凭证状态通讯协议服务器101后续再将凭证c1状态传送至回复签章子系统104进行签章,以及将签章后的凭证c1状态回复给客户端设备100中的客户端设备d1,以完成整个凭证要求及签章的动作;依此类推下,每个客户端设备将针对本身所需求的凭证进行查询,并且其每笔请求查询纪录在凭证数据库中将分别被储存。本发明的方法可将请求查询纪录集合依周期和时段分别统计,即请求流量预测子系统102将表一所示整体2014/07/01~2014/07/28期间的凭证被请求查询纪录为例的集合再进行统计计算,以计算出须预签章的凭证状态数量并传输至回复签章子系统104,并由回复签章子系统104进行预签章凭证状态储存至凭证数据库103;而当客户端设备100查询的凭证已经具备预签章凭证状态时,直接由在线凭证状态通讯协议服务器101向凭证数据库103查询和取得经过本发明的方法预签章的凭证状态,再将预签章凭证状态回复予客户端设备100,凭证数据库103并将已被取走的预签章凭证状态销毁。下表为表一:客户端设备ip凭证时间d1的ipc12014/07/0100:00:29d2的ipc12014/07/0100:00:30d3的ipc22014/07/0100:00:30d2的ipc32014/07/0100:00:31d4的ipc12014/07/0100:00:32d5的ipc42014/07/0100:00:32d6的ipc52014/07/0100:00:32d7的ipc12014/07/0100:00:33………d500000的ipc300002014/07/2823:59:58本发明的方法流程如图2所示,此方法可包含有五个步骤,分别为:步骤s201凭证的请求流量收集与统计、步骤s202取得高度请求流量的凭证、步骤s203实施请求流量分群方法、步骤s204实施请求流量预测方法以及步骤s205实施凭证状态预签章方法。本方法包含上述步骤的主要目的是于进行请求流量预测方法之前,取得高度请求流量的凭证,并各别对高度请求流量凭证进行统计和预签章的处理,本方法并可结合请求流量分群方法以针对每个凭证的请求流量记录依时段进行分群,用于训练以增加预测正确率,以下,将配合实施例详细分述各步骤。首先是为第一步骤s201,凭证的请求流量收集与统计步骤:本发明的请求流量预测子系统向凭证数据库取得凭证的请求查询纪录,如表一所示的2014/07/01~2014/07/28期间的请求查询纪录,请求流量预测子系统依周期(在本实施例中是以周作为周期单位)、时段(在本实施例中是以日作为时段单位)、时点(在本实施例中以小时为时点单位)分别统计每个时点请求查询纪录的数量,将可得到多个周期、多个时段、多个时点的请求查询纪录集合,如下列表二,是以如表一所举的纪录数据整理后所示。下表为表二:再来,是为第二步骤s202,是取得高度请求流量的凭证的步骤:如表二所示,取得每个凭证依各个时段的请求查询纪录数量后,本发明的请求流量预测子系统将依请求查询纪录数量进行由高至低地排序,即可取得排名较前的高度请求流量的凭证,即为较常被请求的凭证,也可被解释为本发明可选择性地针对较需纾解延宕情形的凭证。以前述表一的2014/07/01~2014/07/28期间为例,请求流量预测子系统可得到每个凭证的请求流量总数,再依其请求流量由高到低排序,整理结果可如下列表三所示;即可取出多个高度请求流量的凭证的信息以进行后续分析,在此实施例中由于是以凭证c1其请求流量总数为208728次,为最高度请求流量的凭证,故在此实施例中将对凭证c1为例,请求流量预测子系统将进行后续的请求流量分群方法、请求流量预测方法、凭证状态预签章方法。表三如下所示:凭证请求流量总数c1208728…………c3000028再来,是为第三步骤s203,是为实施请求流量分群方法步骤:请求流量预测子系统取得欲分析的凭证各个时段的请求流量集合,初始时将每个时段的请求流量集合视为一个群集,分别计算群内请求流量集合标准偏差、群间请求流量集合距离以及群间请求流量集合标准偏差,再将相似请求流量集合的群集进行合并和重新计算群中心,直至无群集可再合并。而第四步骤s204是为实施请求流量预测方法步骤:即请求流量预测子系统取得欲分析的凭证各个时段的请求流量集合,并于训练阶段随机建立多个类神经网络,再以历史数据进行训练和分析各个类神经网络的请求流量预测准确度,并保留多个准确度高的类神经网络;而在实施阶段中,请求流量预测子系统将实时的请求流量集合输入至训练阶段所保留的多个准确度高的类神经网络,分别得到请求流量预测值后,再进行加权平均得到最后的请求流量预测值,并将请求流量预测值传送予一回复签章子系统。最后,第五步骤s205为实施凭证状态预签章方法步骤:回复签章子系统接收请求流量预测值,由回复签章子系统针对请求流量预测值所预测的待预签章的凭证信息产制签章值,并将预签章凭证状态储存至凭证数据库;另外,该回复签章子系统为了减少流量负载,其可于预签章前向凭证数据库查询请求流量的时段分布,以分析出离峰时段,再于负载较小的离峰时间进行预签章的流程。而本发明的预测请求流量的凭证预签方法流程中,包含有前述的请求流量分群方法,其方法的步骤流程图如图3所示;主要包含六个步骤,分列如下:步骤s301设定初始群集、步骤s302计算群内请求流量集合的标准偏差、步骤s303计算群间请求流量集合的距离、步骤s304计算群间请求流量集合距离的标准偏差计算、步骤s305相似群集合并,并计算群集中心的请求流量集合以及步骤s306确认是否有群集未计算合并,以重复计算至无群集可合并,若无则进入步骤s307结束,上述各该步骤将详细在以下段落中作出解释。请求流量分群方法的步骤一s301为设定初始群集:以请求流量预测子系统所被设定的时段单位,请求流量预测子系统将每一个时段单位内每个时点的请求流量集合分别作为一个群集,或是可以将每个周期中同时段的请求流量集合作为一个群集,以计算每个群集的中心。以表三的2014/07/01~2014/07/28期间的请求流量为例,统计后凭证c1的请求流量集合可整理如下列表四所示,其中,凭证c1第1个周期第1个时段(即2014/07/01星期二)第1个时点(即凌晨0时)的请求流量为0,本实施例中表示该请求流量值的逻辑为q冯证编号,周期编号,时段编号,时点编号,而以同样的表示方式,凭证c1第4个周期第7个时段(即2014/07/28星期一)第24个时点(即晚上23时)的请求流量为82,而本实施例中更以同一个时段的时点请求流量集合表示为q冯证编号,周期编号,时段编号,时点编号,如凭证c1第1个周期第1个时段的请求流量为表四如下所示:在此实施例中,本发明的请求流量预测子系统所被设定的时段单位共有n个周期、m个时段、o个时点,系统可以将每个周期中同一时段的请求流量集合群聚成一个群集,若以星期二为例,可将第1周星期二07/01、第2周星期二07/08、第3周星期二07/15、第4周星期二07/22的请求流量集合群聚成一个群集,即将聚为一个群集,并且运用下列公式(1)举例的方式计算群中心计算结果举例如公式(2)所示;依此类推逐一计算,可得以每个周期中同时段为基础的群中心,分别表示为结果如下表五所示。公式(1)如下所示,其是举例计算c1凭证第j个周期内的群中心;其中,是代表c1凭证第j个周期第1个时段的群中心,以下相同型式的表示,其逻辑则以此类推:而据上述公式(1)的举例计算,计算c1凭证第1个周期的群中心的结果的公式(2)如下所示:其中,每个值是代表第1周期内各时段的群中心,以下将以此类推。表五如下所示:请求流量分群方法的步骤二s302为计算群内请求流量集合的标准偏差:请求流量预测子系统计算每个群集内请求流量集合的标准偏差值;在本实施例中将以下列的公式(3)举例,以此类推分别计算群集内部请求流量集合的标准偏差值,计算的结果如下列表六所示。公式(3)如下所示,其中σ表示标准偏差,μ表示平均数,本公式是计算c1凭证第1个周期群集内集合的标准偏差:其中,表六如下所示:请求流量分群方法的步骤三s303为计算群集间请求流量集合的距离:请求流量预测子系统计算以前述周期或时段等分类的各个群集与其他的群集间的请求流量集合的距离值或相似度值;在本实施例中,是运用下列公式(4)分别计算群集间请求流量集合每个时点向量值的距离值而如表七所示,是以群中心与其他群集间距离计算结果为例。公式(4)如下所示,公式的意义在计算c1凭证第j个周期群集群中心与c1凭证第a个周期群集群中心的距离值:表七如下所示,是计算群中心与其他群集间之间距离的结果:请求流量分群方法的步骤四s304为群间请求流量集合距离的标准偏差计算:请求流量预测子系统计算每个群集与其他群集间请求流量集合距离的标准偏差值;在本实施例中将以下列公式(5)分别计算群集间请求流量集合距离的标准偏差值如表八所示,是以群中心与其他群集间距离的计算结果为例来计算标准偏差。公式(5)如下所示:其中,表八如下所示,是计算群中心与其他群集间之间距离的标准偏差值的结果:请求流量分群方法的步骤五s305为相似群集合并并计算群集中心的请求流量集合:请求流量预测子系统判断前述群集内部请求流量集合的标准偏差值以及该群集与另一个群集间请求流量集合距离的标准偏差值,若群集内部请求流量集合的标准偏差值大于该群集与另一个群集间请求流量集合距离的标准偏差值,此时,判断该群集与另一个群集是为相似的群集,故将该两群集进行合并且计算合并后群集的中心。在本实施例中,可以观察到群中心为与群中心为的群集间的标准偏差值相对最小(标准偏差值为40.74),且群中心的群集的标准偏差值故可判断群中心的群集与群中心为为相似群集,将进行合并把群中心的群集并入至群中心为的群集,且运用下列公式(6)的范例计算合并后群集的中心,以得到新的群中心,作并将被合并的群中心的群集删除,其结果如下列表九所示。公式(6)如下所示,是为将群中心为的群集合并入群中心为的群集的计算方式,其中,为表示第1周期群中心计算前后间的差异,在下列公式及表中是以代表合并后的第1周期群中心:表九如下所示,是计算2014/07/01~2014/07/28期间统计后的凭证c1请求流量经第一回合合并后群中心,其中各栏表示在第一栏为群中心的群集,其各时段的群中心:请求流量分群方法的步骤六s306为确认是否有群集未计算合并,以重复计算至无群集可合并:请求流量预测子系统将重复计算每个群集其群集内请求流量集合的标准偏差、群集间请求流量集合的距离以及群集间请求流量集合距离的标准偏差,以进行相似群集的合并,且计算新群集中心的请求流量集合,直至没有相似群集可以被合并时即停止,即为进入步骤s307结束。在本实施例中,在发生如前列表九中,群中心为群集与群中心的群集合并后,将再依标准偏差值的大小顺序,依序的对群中心群集与群中心为群集合并(此时的是代表经合并过的原第1至第7周期群中心,未免经过多次合并运算后出现过于复杂难辨的符号表示,尔后经每步骤合并后的第1至第x周期群中心皆表示为唯其所代表的意义不同);合并后,再进行新群中心群集与群中心群集合并以及新群中心群集与群中心群集合并;经上述合并步骤后,由于群中心的群集与群中心的群集与其他群集的距离皆过大(距离并未小于其内部标准偏差值),所以可判断各该群集各自为独立的一群,最后,完成全部的合并运算后,可将原本的7个群集合并分为3群。其为:周期内星期一至五可分为一群集,星期六为一独立群集,且星期日也为一独立群集。另外,本发明的请求流量分群方法也得使用在以每个时段同时点为基础的群中心方式上进行分群,在本实施例中,将可得出凌晨0时至6时可分为一群集,而6时至24时则为另一群集,接着,本发明的请求流量预测子系统将可依分群之后的结果数据,用以训练请求流量预测方法的多个类神经网络模型,以提升系统的预测正确率。至此,进入步骤s307结束后,本发明的请求流量分群方法步骤实施过程即结束。而本发明的预测请求流量的凭证预签方法流程中,包含有前述的请求流量预测方法,其方法的步骤流程图如图4所示,主要将包含两个阶段,分别为训练阶段s401和实施阶段s402,将详细分述如下。在训练阶段s401主要可包含两个步骤:步骤s4011随机产生多个类神经网络、步骤s4012保留多个预测正确率高的类神经网络。其中,训练阶段s401中的步骤s4011随机产生多个类神经网络是为:请求流量预测子系统可被设定随机类神经网络群算法的参数值,且请求流量预测子系统向凭证数据库读取凭证被请求查询纪录的历史数据,以随机建立r个类神经网络模型。首先,由开发人员设定请求流量预测子系统中的随机类神经网络群算法的相关参数值,包含有建立类神经网络模型的数量(以r个为例)、类神经网络模型中隐藏层最大数量(以hmax个为例)、类神经网络模型中每个隐藏层最大神经元数量(以cmax个为例)、训练类神经网络模型的训练数据数占总训练阶段数据数的比例(后续说明将以ρ%为例)以及正确率门坎值(以wthreshold为例);在本实施例中,将设定共建立10个类神经网络模型(即r=10)、类神经网络模型中隐藏层最大数量为5(即hmax=5)、类神经网络模型中每个隐藏层最大神经元数量为7(即cmax=7)、训练类神经网络模型的训练数据数占总训练阶段数据数的比例为60%(即ρ%=60%)以及正确率门坎值为0.945(即wthreshold=0.945,即为94.5%),本实施例将依前述参数值以产生10个类神经网络模型以进行请求流量预测。本实施例中,将以凭证c1被请求流量为例来进行说明;首先,请求流量预测子系统向凭证数据库读取凭证状态请求查询纪录的历史数据(即表四所示的资料),如第1个周期第1个时段(即2014/07/01星期二)的请求流量集合为且在此数据集合的下一个时段的请求流量集合的总和为10537,故开发人员将设定输入值为时段请求流量集合而目标输出值则应为该输入时段的下一个时段的请求流量集合的总和值10537。另外,若在此之前有进行过请求流量分群方法,则依群集各别进行随机类神经网络群算法的训练和计算。依据前述被设定的随机类神经网络群算法参数值,请求流量预测子系统应随机产生10个类神经网络模型,且因为被设定的类神经网络模型中隐藏层最大数量为5且类神经网络模型中每个隐藏层最大神经元数量为7,意即每个类神经网络模型的隐藏层数量必须要介于0至5层,且每个隐藏层的神经元数量将介于0至7个,本实施例根据设定所产生的结果如下表十所示。表十如下所示:类神经网络模型编号隐藏层数神经元数集合11{2}22{3,4}31{6}43{2,6,2}51{4}64{3,1,5,4}72{6,4}83{6,2,7}94{2,6,5,5}103{3,2,7}另外,见表十时请同时参考图5,其为以类神经网络模型1为例的一示意图,类神经网络模型1的隐藏层为1层(第二字段的隐藏层数),该层隐藏层的神经元数为2个(第三字段的神经元数集合{2});类神经网络模型2的隐藏层有2层,其中第1层隐藏层的神经元数为3个,而第2层隐藏层的神经元数有4个(第三字段的神经元数集合{3,4});依此类推,以得出全部共10个类神经网络模型。并且,由于设定的训练类神经网络模型的训练数据数占训练阶段数据总笔数的60%,若以表四为例来说,训练阶段数据数的总笔数为20笔,所以每一个类神经网络模型将随机取出12笔数据作为训练类神经网络模型学习使用,而剩余的8笔训练阶段中的测试资料(testingdataintrainingstage,tdtrs)将分别作为本训练阶段时每个类神经网络模型以验证使用;在本步骤中,每个类神经网络模型所取得的12笔数据的集合皆各自随机产生,每一个类神经网络模型都将取得不同的数据集合以反复进行训练和学习。当完成前述所有类神经网络模型的训练后,请求流量预测子系统可运用剩余的8笔数据来进行每个类神经网络模型的验证,用以计算平均正确率来作为每个类神经网络模型的权重;以类神经网络模型1为例,将训练阶段中的测试数据全部输入至训练后的类神经网络模型1中以计算出正确率。例如:请求流量集合输入时,将得出预测值为10911,接着以下式计算出正确率,式子为1-(|正确值-预测值|/正确值),结果为1-(|10537-10911|/10537)=96.45%;依此方法类推计算,可得出8笔训练阶段中的测试数据(tdtrs)的正确率,进而计算出平均正确率,在本实施例中类神经网络模型1平均正确率为93.23%。而全部10个类神经网络模型所对应的平均正确率分列如下,如表十一所示。表十一所示如下:其中,训练阶段s401中的步骤s4012保留多个预测正确率高的类神经网络是为:请求流量预测子系统将随机产生的r个类神经网络模型的正确率与正确率门坎值wthreshold进行比对,排除低于此门坎值的类神经网络模型(即正确率过低的模型),余下g个类神经网络模型;若无任何类神经网络模型的正确率高于门坎值时,将回到前一个s4011步骤,再重新设定门坎值以重新训练随机类神经网络群。在本实施例中,请求流量预测子系统将分析每个类神经网络模型的平均正确率,并将低于正确率门坎值wthreshold(即本实施例所设定的94.5%)过滤掉,请参考表十一,其中类神经网络模型1、类神经网络模型3、类神经网络模型4、类神经网络模型6、类神经网络模型9、类神经网络模型10等6个将被过滤掉,剩下其余4个类神经网络模型(即g值为4)及其分别的权重值留待实施阶段使用。在前述请求流量预测方法中,实施阶段s402主要也可包含两个步骤:步骤s4021输入实时数据至训练阶段中所保留的多个预测正确率高的类神经网络、步骤s4022将多个类神经网络产生的预测值进行加权平均得到最后的预测值。其中,实施阶段s402中,步骤s4021输入实时数据至训练阶段中所保留的多个预测正确率高的类神经网络步骤为:请求流量预测子系统取得实时的凭证请求查询纪录,用以输入至训练阶段所保留的g个类神经网络模型以进行预测计算。请参考图6所示,例如,凭证c1在2014/07/28该日期的请求流量集合为将其作为随机类神经网络群的输入数据,进行步骤s601输入实时请求流量集合,将其分别输入至在训练阶段所剩下的4个类神经网络模型(类神经网络模型2、类神经网络模型5、类神经网络模型7、类神经网络模型8),以分别得出目标2014/07/29日期凭证c1请求流量预测值。其中,实施阶段s402中,步骤s4022将多个类神经网络产生的预测值进行加权平均得到最后的预测值的步骤为:由该g个类神经网络模型所产生出来的预测值,运用训练阶段时所得到的正确率作为权重,进行加权平均,以得到最终的请求流量预测值。请求流量预测子系统经过将数据输入每个余下的类神经网络模型(即类神经网络模型2、类神经网络模型5、类神经网络模型7、类神经网络模型8,如表十所示)的步骤s601后,可见图6中,由类神经网络模型2、类神经网络模型5、类神经网络模型7、类神经网络模型8得出的凭证c1请求流量预测值分别为12716、12582、12565、12401,也如下列表十二所示;最后,进行步骤s602,依每个类神经网络模型的权重对各预测值进行加权平均(类神经网络模型2为94.90%、类神经网络模型5为94.61%、类神经网络模型7为94.93%、类神经网络模型8为95.21%)以得到最终的凭证c1的请求流量预测值12566。表十二所示如下:类神经网络模型2578权重94.90%94.61%94.93%95.21%旅行时间预测值12716125821256512401而本发明的预测请求流量的凭证预签方法流程中,包含有前述的回复签章子系统进行的凭证状态预签章方法,其方法的步骤流程图如图7所示,主要将包含四个步骤,分别为:步骤s701接收待预签章的凭证信息、步骤s702侦测离峰时段、步骤s703对凭证状态产制签章值、步骤s704储存预签章凭证状态;此凭证状态预签章方法可于离峰时间进行凭证状态产制,以平衡负载。其中,该步骤s701接收待预签章的凭证信息的步骤为:回复签章子系统接收凭证信息和该凭证状态请求流量预测值,以本实施例中的2014/07/29日期为例,请求流量预测子系统通过请求流量预测方法预测得出凭证c1状态的请求流量预测值为12566,回复签章子系统接收此值为12566的请求流量预测值。其中,该步骤s702侦测离峰时段的步骤为:回复签章子系统可向凭证数据库取得历史的凭证被请求查询纪录,以统计和分析离峰时段;以本实施例中2014/07/01~2014/07/28期间的凭证被请求查询纪录中,离峰时段为凌晨0时至6时。其中,该步骤s703对凭证状态产制签章值的步骤为:回复签章子系统依请求流量预测值对特定凭证状态进行预签章,产生预签章凭证状态的数据;在本实施例中,因被预测的凭证c1状态的请求流量预测值为12566,故将由回复签章子系统对凭证c1状态进行预签章,以产生12566笔预签章凭证状态;本预签章步骤端看前述步骤s702是否有执行,若步骤s702有执行并得出离峰时段,回复签章子系统可于离峰时间进行凭证状态产制,以进行负载平衡。其中,该步骤s704储存预签章凭证状态的步骤为:在本实施例中,回复签章子系统将把12566笔预签章凭证状态的数据储存至凭证数据库,以供客户端设备查询及使用;且在客户端设备查询并取得预签章凭证状态之后,凭证数据库将销毁被取用的预签章凭证状态,即当被客户端设备取走1笔后,凭证数据库将剩余12565笔预签章凭证状态,直至该预签章凭证状态被取完,凭证数据库再无剩余的预签章凭证状态。至此,本发明的预测请求流量的凭证预签方法流程已结合实施例、图式以及列表完毕。而该些详细说明乃针对本发明的最佳实施例进行具体说明,惟该些实施例并非用以限制本发明的专利范围,凡是未脱离本发明技艺精神所为的等效实施或变更,均应被包含于本案的专利范围中。综上所述,本发明于技术思想上确属创新,充分符合新颖性及进步性等法定发明专利要件,爰依法提出专利申请,恳请贵局核准本件发明专利申请案以励发明,至感德便。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1