数据的处理方法及装置与流程
本公开总体涉及计算机技术领域,具体涉及一种数据的处理方法及装置。
背景技术:
现在的大数据处理中,由于数据量大,有时需要计算的内容较复杂,采用单一的处理技术较难满足要求。例如,在大型的电商企业中,为评价商品的价值,一般使用关键价值商品kvi(keyvalueitem)的概念,在计算kvi指数时,需要处理海量数据。而海量数据在单机上无法处理或运算的时间过长,无法保证计算的实时性,但是单一的处理技术又较难保证计算的完整性和准确性。
因此,针对海量数据的计算,例如kvi指数的计算,需要一种新的方法。
在所述背景技术部分公开的上述信息仅用于加强对本公开的背景的理解,因此它可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现要素:
本公开提供一种数据的处理方法及装置,能够快速、准确地处理海量数据的计算。
本公开的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本公开的实践而习得。
根据本公开的第一方面,一种数据的处理方法,包括:对数据进行查询,生成按预定时间段汇总的数据交换表;利用spark运算框架对所述数据交换表进行处理,包括:
读取所述数据交换表,按一数据属性对数据进行切块;
将切块的数据分发到服务器集群的各节点;
各节点进行与所述数据属性相关的计算;汇集各所述节点的执行结果;
其中,各节点配置有r语言或者python语言计算模块,用于处理spark运算框架中无法计算的部分。
根据本公开的一实施方式,所述对数据进行查询包括:采用hive查询语言hql在数据仓库中进行查询。
根据本公开的一实施方式,所述读取所述数据交换表包括:采用sparksql语言读取所述数据交换表。
根据本公开的一实施方式,所述切块的数据以弹性分布式数据集的形式存储。
根据本公开的一实施方式,所述spark运算框架与所述r语言或者python语言计算模块通过管道进行数据交换。
根据本公开的一实施方式,所述数据属性为商品品类,所述数据交换表包括商品表、订单表和流量表,所述各节点进行与所述数据属性相关的计算包括计算商品定价指数,商品定价指数根据一预定时间段内的用户访问量、商品页面平均停留时间、销量、拉动金额的不同权重进行计算。
根据本公开的一实施方式,所述预定时间段为7天或者30天。
根据本公开的一实施方式,按照计算出的所述商品定价指数的分数从大到小排序,排序表中前20%的商品确定为最重要商品,排序表中20%后至50%前的商品确定为关键商品,排序表中50%后至80%前的商品确定为一般商品,排序表中80%后的商品确定为不重要商品。
根据本公开的第二方面,一种数据的处理装置,包括:汇总模块,用于对数据进行查询,生成按预定时间段汇总的数据交换表;处理模块,用于利用spark运算框架对所述数据交换表进行处理,包括:
读取所述数据交换表,按一数据属性对数据进行切块;
将切块的数据分发到服务器集群的各节点;
各节点进行与所述数据属性相关的计算;
汇集各所述节点的执行结果;
r语言或者python语言计算模块,用于处理spark运算框架中无法计算的部分。
根据本公开的一实施方式,所述数据属性为商品品类,所述数据交换 表包括商品表、订单表和流量表,所述各节点进行与所述数据属性相关的计算包括计算商品定价指数,商品定价指数根据一预定时间段内的用户访问量、商品页面平均停留时间、销量、拉动金额的不同权重进行计算。
根据本公开的一实施方式,所述预定时间段为7天或者30天。
根据本公开的一实施方式,按照计算出的所述商品定价指数的分数从大到小排序,排序表中前20%的商品确定为最重要商品,排序表中20%后至50%前的商品确定为关键商品,排序表中50%后至80%前的商品确定为一般商品,排序表中80%后的商品确定为不重要商品。
本实施方式的数据处理方法及装置,基于spark运算框架,具备处理海量数据的能力,能够快速处理海量数据,并且结合r语言或者python语言计算模块,使数据处理更加准确完整。在计算商品定价指数kvi(keyvalueitem)的过程中,还同时考虑了商品页面平均停留时间和拉动金额两个因素,使商品定价指数kvi更准确,为更好地把握商品定价策略提供了基础。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本公开。
附图说明
通过参照附图详细描述其示例实施例,本公开的上述和其它目标、特征及优点将变得更加显而易见。
图1示出根据本公开示例实施方式的系统技术架构图。
图2示出根据本公开示例实施方式的数据的处理方法流程图。
图3示出根据本公开示例实施方式的另一数据的处理方法流程图。
图4示出根据本公开示例实施方式的数据的处理装置方框图。
具体实施方式
现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本公开将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。附图仅为本公开的示意性图解,并非一定是按比例绘制。图中相同的附图标记表示相同或类似的部分,因而将省略对 它们的重复描述。
此外,所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。在下面的描述中,提供许多具体细节从而给出对本公开的实施方式的充分理解。然而,本领域技术人员将意识到,可以实践本公开的技术方案而省略所述特定细节中的一个或更多,或者可以采用其它的方法、组元、步骤等。在其它情况下,不详细示出或描述公知结构、方法、实现或者操作以避免喧宾夺主而使得本公开的各方面变得模糊。
附图中所示的一些方框图是功能实体,不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
图1示出根据本公开示例实施方式的系统技术架构图。
如图1所示,本发明采用的系统技术架构是基于spark运算框架的,使用hive查询语言hql到数据仓库中查询数据交换表100。利用sparksql读取数据交换表100,数据交换表100可包括记录各计算参数的数据记录表101、记录表102和记录表103。
对汇总的各记录表进行加工处理,按照计算的需要进行切块。切块的数据以弹性分布式数据集rdd(resilientdistributeddatasets)的形式存储。弹性分布式数据集rdd(resilientdistributeddatasets)是分布式内存的一个抽象概念,rdd提供了一种高度受限的共享内存模型,即rdd是只读的记录分区的集合,只能通过在其他rdd执行确定的转换操作而创建,然而这些限制使得实现容错的开销很低。对开发者而言,rdd可以看作是spark的一个对象,它本身运行于内存中,如读文件是一个rdd,对文件计算是一个rdd,结果集也是一个rdd,不同的分片、数据之间的依赖、key-value类型的map数据都可以看做rdd。
将切成小块的数据分发到服务器集群中的各节点服务器进行计算,其中,每个节点服务器预装的r或python语言模块。计算过程中如果遇到spark中无法实现的部分,可以利用预装的r或python语言模块进行计算。计算完成后,spark收集各节点数据分块的执行结果汇总成一个大的结果文件200,调用hive的导入语句将结果文件200导入到hive数据仓库中,作 为结果供查询使用。其中,spark与r或python利用操作系统的管道(pipe)进行数据交换。
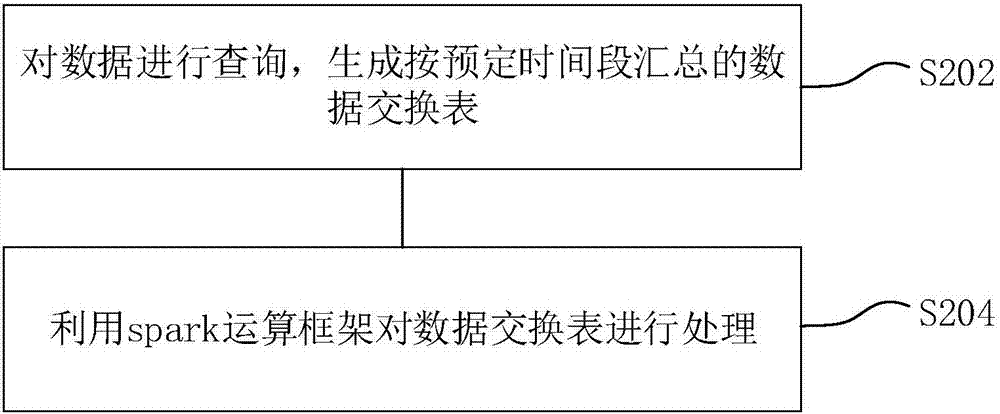
图2示出根据本公开示例实施方式的数据的处理方法流程图。
如图2所示,该数据的处理方法是基于图1的系统技术架构的,包括步骤s202~s204:
在步骤s202中,对数据进行查询,生成按预定时间段汇总的数据交换表。
查询收集要处理的数据,将收集到的数据生成按照预定时间段汇总的数据交换表,该预定时间段可根据业务需要由人为设定。
在步骤s204中,利用spark运算框架对数据交换表进行处理。
采用spark运算框架对数据交换表进行处理。读取数据交换表,按照一数据属性对数据进行切块,该数据属性可以是计算中涉及的参数,例如,在计算电商企业销售关键价值商品kvi(keyvalueitem)时,涉及商品品类,此时的数据属性可为商品品类,将数据按照商品品类进行切块。由于需要处理的数据量较大,通过将数据切块将海量数据分割成多个小块数据。
在spark运算框架下,将切成小块的数据分发到服务器集群的各节点服务器。
各节点服务器进行与数据属性相关的计算,例如,在计算电商企业销售关键价值商品kvi(keyvalueitem)时,各节点服务器按照商品品类进行分类,根据每种商品的销售量和点击量,计算商品的kvi指数。
各节点服务器计算完毕后,汇集各节点服务器的执行结果,将所有的计算结果汇总成一个大的结果文件,导入到数据仓库中。例如,可调用hive的导入语句将结果数据导入到hive数据仓库表中供使用。
在上述计算过程中,各节点服务器可配置r语言或者python语言计算模块,用于处理spark运算框架中无法计算的部分。在计算过程中,如果spark科学计算库中存在缺少的算法包,则可以通过利用r语言或者python语言计算模块来进行补充,以进行完整的计算。
本实施方式的数据处理方法,基于spark运算框架,具备处理海量数据的能力,能够快速处理海量数据,并且结合r语言或者python语言计算 模块,使数据处理更加准确完整。
根据一示例实施例,在对数据进行查询时,可采用hive查询语言hql在数据仓库中进行查询。
根据一示例实施例,spark运算框架与r语言或者python语言计算模块通过操作系统管道进行数据交换。
图3示出根据本公开示例实施方式的另一数据的处理方法流程图。
大型电商企业销售的商品数量巨大,非常需要很好地了解哪些商品更加影响用户对商城的印象,以保持对竞争对手的优势地位。在评价商品的价值方面,使用关键价值商品kvi(keyvalueitem)的概念。kvi商品是指对价格敏感商品,价格的变化会对商品和相关的其它商品的销量产生较大的影响。而一个商品是不是kvi商品,可以从多个维度去衡量,包括浏览量、购买量等方面。综合考虑每个商品的这几个方面,即可得出哪些商品最吸引用户浏览、最易使顾客购买,这些kvi商品比其他商品更能影响用户对商城的印象。现有评价商品价值是根据商品的销量和点击量分成a、b、c、d4个档次来评价商品的重要程度,a为最重要,d为最不重要。销量和点击量按一定权重综合计算出代表商品的重要程度的值。其中,商品的销量是利用数据库中记录销量的数据表查询获得,点击量可以是利用用户访问页面时页面代码记录所获得。然后把销量和点击量准标化处理获得从0到1的一个数据值,再按一定权重计算出一个综合的数值:
k=w1*sales_quantity+w2*traffic,
其中sales_quantity表示销量,traffic表示点击量。现有技术对商品的评价不全面,没有考虑拉动、页面停留时间这些重要影响商品的指标。一种商品它本身的销量可能并不大,但可能会拉动其它商品的销售。
为了很好地计算商品的kvi指数,需要采用一系列数据处理技术进行支撑。r语言是很强大的数据分析处理语言,很适合对kvi指数计算进行数据预处理和算法的实现;python语言也有很强的科学计算能力,有丰富的科学计算库,对kvi指数计算有很好的准确度和性能的保证;hadoop平台可以对kvi指数计算需求的数据存储和运算提供底层支撑;hive平台是基于hadoop的数据库平台。
如图3所示,可利用上述数据处理方法计算商品定价指数kvi(keyvalueitem),其中数据属性可为商品品类sku(stockkeepingunit),数据交换表包括商品表、订单表和流量表,各节点服务器进行与商品品类sku(stockkeepingunit)相关的计算,包括计算商品的定价指数kvi(keyvalueitem)。其中,商品品类sku(stockkeepingunit)即库存进出计量的单位,可以是以件,盒,托盘等。sku(stockkeepingunit)一般是大型连锁超市配送中心物流管理的一种必要方法,现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的sku(stockkeepingunit)号。包括步骤步骤s302~s304:
在步骤s302中,对数据进行查询,生成按预定时间段汇总的商品表、订单表和流量表。
查询收集商品销售的相关数据,可采用hive查询语言hql在数据仓库中收集汇总各项数据,将收集到的数据生成按照预定时间段汇总的数据交换表,生成的数据交换表包括商品表、订单表和流量表。该预定时间段可根据业务需要由人为设定,可以7天,即一周为期限,也可以30天,即一个月为周期,可根据分析的需要设定。采用spark运算框架对数据交换表进行处理,可按照商品表中的商品品类sku(stockkeepingunit)对数据进行切块,将切成小块的数据分发到服务器集群的各节点服务器,各节点服务器进行相关的计算。
在步骤s304中,利用spark运算框架对商品表、订单表和流量表进行处理。
在计算商品定价指数kvi(keyvalueitem)时,利用商品表、订单表和流量表中的信息,得出用户访问量、商品页面平均停留时间、销量和拉动金额等内容,综合考虑上述每个因素,可设置不同的权重,权重的设置可综合考虑多方面需要,根据业务要求自行设定。
各节点服务器计算完毕后,汇集各节点服务器的执行结果,将所有的计算结果汇总成一个大的结果文件,导入到数据仓库中。例如,可调用hive的导入语句将结果数据导入到hive数据仓库表中作为结果供使用。
在上述计算过程中,各节点服务器可配置r语言或者python语言计算 模块,用于处理spark运算框架中无法计算的部分。如果spark科学计算库中存在缺少的算法包,则可以通过利用r语言或者python语言计算模块来进行补充,以进行完整的计算。
本实施方式的数据处理方法,基于spark运算框架,具备处理海量数据的能力,能够快速处理海量数据,并且结合r语言或者python语言计算模块,使数据处理更加准确完整。在计算商品定价指数kvi(keyvalueitem)的过程中,还同时考虑了商品页面平均停留时间和拉动金额两个因素,使商品定价指数kvi更准确,为更好地把握商品定价策略提供了基础。
根据一示例实施例,对于计算得到的商品定价指数kvi(keyvalueitem),可按照商品定价指数的分数从大到小进行排序,排序表中前20%的商品可确定为最重要商品,排序表中20%后至50%前的商品可确定为关键商品,排序表中50%后至80%前的商品可确定为一般商品,排序表中80%后的商品可确定为不重要商品。在制定销售策略时,可根据商品的重要程度分别制定不同的销售策略,可重点考虑最重要商品和关键商品。上述对于商品重要程度的划分,只是举例说明,对于商品定价指数kvi(keyvalueitem)的利用,可根据实际情况自行确定范围。
图4示出根据本公开示例实施方式的数据的处理装置方框图。
如图4所示,一种数据的处理装置,包括:
汇总模块402,用于对数据进行查询,生成按预定时间段汇总的数据交换表。
查询收集要处理的数据,将收集到的数据生成按照预定时间段汇总的数据交换表,该预定时间段可根据业务需要由人为设定。
处理模块404,用于利用spark运算框架对数据交换表进行处理。
采用spark运算框架对数据交换表进行处理。读取数据交换表,按照一数据属性对数据进行切块,该数据属性可以是计算中涉及的参数,例如,在计算电商企业销售关键价值商品kvi(keyvalueitem)时,涉及商品品类,此时的数据属性可为商品品类,将数据按照商品品类进行切块。由于需要处理的数据量较大,通过将数据切块将海量数据分割成多个小块数据。
在spark运算框架下,将切成小块的数据分发到服务器集群的各节点 服务器。各节点服务器进行与数据属性相关的计算,例如,在计算电商企业销售关键价值商品kvi(keyvalueitem)时,各节点服务器根据销售量和点击量进行kvi指数计算。
各节点服务器计算完毕后,汇集各节点服务器的执行结果,将所有的计算结果汇总成一个大的结果文件,导入到数据仓库中。例如,可调用hive的导入语句将结果数据导入到hive数据仓库表中作为结果供使用。
r语言或者python语言计算模块406,用于处理spark运算框架中无法计算的部分。
在上述计算过程中,各节点服务器可配置r语言或者python语言计算模块,用于处理spark运算框架中无法计算的部分。在计算过程中,如果spark科学计算库中存在缺少的算法包,则可以通过利用r语言或者python语言计算模块来进行补充,以进行完整的计算。
本实施方式的数据处理装置,基于spark运算框架,具备处理海量数据的能力,能够快速处理海量数据,并且结合r语言或者python语言计算模块,使数据处理更加准确完整。
在大型电商企业中,可利用上述数据处理装置,计算商品定价指数kvi(keyvalueitem),其中数据属性可为商品品类sku(stockkeepingunit),数据交换表包括商品表、订单表和流量表,各节点服务器进计算商品的定价指数kvi(keyvalueitem),各模块具体执行以下功能:
汇总模块402,用于查询收集商品销售的相关数据,将收集到的数据生成按照预定时间段汇总的数据交换表,该预定时间段可根据业务需要由人为设定,可以以7天,即一个星期为期限,也可以30天,即一个月为期限,可根据分析的需要设定。
可采用hive查询语言hql在数据仓库中收集汇总各项数据,生成数据交换表,包括商品表、订单表和流量表。
处理模块404,用于采用spark运算框架对数据交换表进行处理,将切成小块的数据分发到服务器集群的各节点服务器,各节点服务器进行商品定价指数kvi(keyvalueitem)计算。
在计算商品定价指数kvi(keyvalueitem)时,综合考虑用户访问量、 商品页面平均停留时间、销量和拉动金额等因素,每个因素可设置不同的权重,权重的设置可综合考虑多方面需要,根据业务要求自行设定。
r语言或者python语言计算模块406,用于处理spark运算框架中无法计算的部分。
本实施方式的数据处理装置,基于spark运算框架,具备处理海量数据的能力,能够快速处理海量数据,并且结合r语言或者python语言计算模块,使数据处理更加准确完整。在计算商品定价指数kvi(keyvalueitem)的过程中,还同时考虑了商品页面平均停留时间和拉动金额两个因素,使商品定价指数kvi更准确,为更好地把握商品定价策略提供了基础。
以上具体地示出和描述了本公开的示例性实施方式。应可理解的是,本公开不限于这里描述的详细结构、设置方式或实现方法;相反,本公开意图涵盖包含在所附权利要求的精神和范围内的各种修改和等效设置。
- 还没有人留言评论。精彩留言会获得点赞!