海量脑组织三维图像数据快速调用方法与流程
本发明涉及海量数据的处理,具体地指一种基于神经纤维走势预测的海量脑组织三维数据缓存调用方法,属于生物医学图像处理领域。
背景技术:
神经元形态结构重建指的是从包含神经元形态结构的图像中提取出神经元的形态,将图像数据转换成神经元形态的矢量数据。神经元形态结构重建是脑科学研究的基础方法,准确的重建神经元形态结构对认知大脑功能起到极大的帮助。神经元的形态有局部的,也有长程投射的,长程投射的神经元揭示了脑内脑区或核团的连接关系,所以神经纤维的长程分割具有重大意义。
对于长程投射的神经纤维来说,由于神经纤维跨度较长,所需要从大范围、高分辨的三维图像中分割出神经纤维,数据的处理分析需要面对海量的数据,少则数百GB,多则近百TB。由于整体的数据量非常大,海量图像数据一般会按照某些规则以较小数据块的形式分块保存,需要时仅读取当前需要处理的数据块,然后采用进行自动或人工的分割操作,完成当前数据块后,再接着读取其他包含神经纤维的数据块进行分割,如此反复,直到完成整个神经纤维的重建。但是,在分割重建的过程中,每次读取数据的阶段都会消耗比较多的时间,例如数分钟,严重影响了神经元重建过程的连续性,总的工作效率大大降低。
技术实现要素:
本发明目的在于克服现有技术在解决上述问题上的不足,提供一种海量脑组织三维图像数据快速调用方法,在对长程投射的神经纤维进行交互 式分割的时候,通过对神经纤维的走势进行分析,预为了可能用到的数据,并提前加载到缓存中。这个方法使重建过程中读取数据的平均时间大大缩短,减少用户或计算程序的等待时间,提高了神经元形态结构重建的效率。
实现本发明目的采用的技术方案是:一种海量脑组织三维图像数据快速调用方法,该方法包括:
在采用分块结构进行存储的海量脑组织三维图像数据中,通过拟合神经纤维的走势,沿着神经纤维自然延伸方向预测将要使用的三维图像数据块,并提前加载至计算机缓存区中;若用户实际请求调用的三维图像数据块已位于缓存区当中,则从缓存区读取,实现快速调用。
所述缓存区为在具有高速读写性能的存储设备中,可用于存放三维图像数据块的存储区域。
所述实际请求调用的三维图像数据块如存在于缓存区中,则从缓存区读取,否则从存储了海量脑组织三维图像数据的低速存储设备上读取。
所述拟合神经纤维的走势包括:
在已分割的神经元纤维上取离当前待分割数据块位置最近的一段,对这段已知纤维的路径进行拟合,拟合线延长线进入当前待分割数据块中,预测了神经纤维在当前待分割数据块中的延伸路径。
所述预测将要使用的三维图像数据块的方法为:
所述拟合线延长线进入当前待分割数据块,并从其中一个面穿出,选取与该面相邻的数据块作为优先读取的数据块;继续选取拟合线穿出待分割数据块时的交点,确定当前待分割数据块上与该交点距离最近的另一个面,将与该面相邻的数据块作为次优先读取的数据块。
建立缓存区时,同时建立相同数量的两组动态标签,其中一个保存每个数据块空闲时间,另一个保存每个数据块与当前待分割数据块间的距离;利用所述动态标签中的信息对缓存区中的数据块进行排序,依据最久未使用和最远距离两个指标删除缓存区中的部分数据块,并更新所述动态标签。
传统的分割神经元方式为先读一个数据块,然后再计算或处理,该数据块完成之后,再根据分割出的神经纤维的方向去读取下一个数据块。由于读取数据块的等待时间太长,影响工作效率。因此,与传统的分割神经元方式相比,本发明方法具有以下优点:
本发明方法在对采用分块结构进行存储的海量脑组织三维图像数据进行神经元纤维长程分割时,在分割某个数据块的同时,即在还没有处理完当前数据块的时候,通过获取已分割神经纤维的位置,计算出神经纤维走势来预取数据块到缓存中,预判出下一个数据块的大概范围,提前进行数据加载,使得数据块加载的时间大大缩短,提高工作效率。
附图说明
图1为本发明一种海量脑组织三维图像数据快速调用方法的流程图。
图2a为数据块被神经纤维分割的示意图,图2b为DCC'D'面分割为4部分的示意图,图2c为计算得到需要读进缓存区的2个数据块的示意图。
图3a为采用最久未使用排序的结果示意图,图3b为采用最久未使用排序的结果示意图,图3c为采用最久未使用排序的结果示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的详细说明。
本实施例中,低速读写的存储设备选用硬盘,高速读写的存储设备选用内存。
本发明所针对的待分割三维数据采用分块结构进行存储,存储在硬盘上。本实施例中采用的分块结构进行存储的三维图像数据由很多个512×512×512大小的数据块组成。每个数据块的大小为128MB。参阅图1,本发明缓存调用的方法包括如下步骤:
S100、建立缓存区
在内存中建立用于存放若干数据块大小的缓存区,存放数据块的数量可以依据计算机的配置来更改,如果内存足够大,可以建立的多,如果不 够大,则可建立的少。另外建立同样数量的两组标签,一个保存每个数据块多久没有被加载(即停留在缓存区中的时间),另一个保存该数据块中心点离当前分割的数据块中心点的距离。
S200、拟合神经纤维走势,计算所需读取数据
在读取数据到缓存区时,将当前待分割数据块的相邻的6个面全部读取进入缓存区,这样下一次取数据块时总有一个数据块在缓存区中,但是由于分割时间没有读取6个数据块的时间长,而且每次读取6个数据块也没有太大必要,所以本实施例采用选择性的读取2个数据块。
在神经纤维分割过程中,由于神经纤维的走势一般情况下不会发生突然非常剧烈的变化,在一定范围内,该纤维的走势大概方向是不变的。所以通过已经分割的神经纤维结果,可以预测还未分割部分的走势。
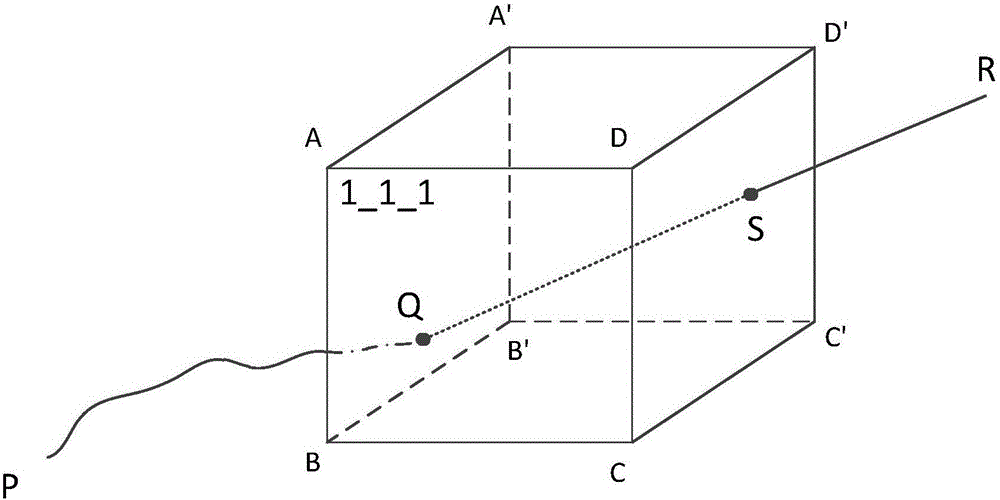
该过程参阅图2所示,图2a中数据块1_1_1是当前读取的数据块用于神经纤维的分割,PQ为已经分割的神经纤维,在PQ上靠近Q的一侧取一定数量的点,例如5-10个,采用一定的拟合方式,例如最小二乘法,进行拟合,拟合可以得到一条穿过当前数据块的一条拟合线QR,拟合线QR为直线或曲线(依据拟合方法),该条拟合线QR与数据块的DCC'D'面相交于S点。
取当前数据块的中心作为原点,三个正交面将数据块分为8部分,拟合出的线QR与待分割数据块会相交于ABCD面和DCC'D'面两个面,该线从ABCD面穿进,从DCC'D'面穿出。拟合线QR与穿出的DCC'D'面和相交的一点S。将DCC'D'面分割为4个区域,如图2b所示,S点落在区域JOKD'中,计算S点距离穿出的DCC'D'面所在的四条边的距离,很显然,S点与边DC和边CC'的距离要比与DD'边和C'D'边的距离远,因此,只需将S点与边DD'和边C'D'的距离m和n并比较,得到n的距离短,所以要读取进缓存区的数据块为与DCC'D'相邻的数据块2_1_1,以及与n垂直面A'B'C'D'相邻的数据块1_1_2,如图2c所示。优先读取DCC'D'相邻的数据块2_1_1,次优先读取垂直于S点与边C'D'所在线段的相邻数据块。
S300、数据加载与读取
计算得到所要读取的数据块后,按照先后次序将数据块加载进缓存区中。加载完成后等待用户读取数据,如果用户需要读取的数据在缓存区中,则直接从缓存区读取,说明拟合的结果比较准确,数据加载有效;如果数据不在缓存区中,则从硬盘读取,说明拟合的结果与实际的不相符,没有加载到需要的数据。
如果数据在加载过程中,用户请求读取数据,则停止数据向缓存区的加载,读取数据,如果缓存区中有,则从缓存区中加载,如果缓存区中没有,则直接从硬盘加载。
S400、刷新缓存区
在加载数据进入缓存区时,由于缓存区的大小有限,所以存在缓存区满的情况,需要刷新缓存区,将一些数据块从缓存区中清除,即缓存区的刷新。
缓存区的刷新采用最久未使用和最远距离两个指标进行加权排序,删除部分数据块。缓存区中的两组标签对缓存区中的每个数据块多久没有被加载以及数据块离当前数据块的距离进行了记录。在每次刷新缓存区时,对缓存区中的所有数据块依据这两个标签进行排序,将这两个序列按照权值为0.5再加权排序,得到一个加权排序,依据该排序更新缓存区中的数据。该过程可以参阅图3所示:采用最久未使用排序的结果如图3a所示,得到数据块A排在待淘汰的第一位,采用最远距离排序的结果图3b所示,得到数据块C排在待淘汰的第一位,对数据块A和数据块C按照权值为0.5再加权排序,得到一个加权排序,排序结果如图3c所示,数据块C被淘汰,即对数据块C刷新。
- 还没有人留言评论。精彩留言会获得点赞!