数据库访问系统及其访问方法与流程
本发明涉及数据库应用技术领域,更为具体地,涉及一种数据库访问系统及其访问方法。
背景技术:
由于网络的飞速发展,出现了很多基于java的web开发框架,其中,Hibernate是当前流行的java web开发架构中数据库持久层访问技术,通过提供各式接口,并提供SQL的转换语言HQL来进行操作,简化了SQL的写法,使之更容易与一个实体bean进行映射,将数据库的关联操作通过配置与bean的复杂关联形式实现,依赖程序来保证数据库的完整性,这种开发框架只是对SQL进行了封装,对业务操作时还是交由开发者自主实现,对于纯粹业务开发的开发人员来说更多是一种额外的负担,增加了错误的机率与学习成本。
另外,对于市场所有的持久化方案都是将SQL作为切入数据库的方式,而数据处理则交给开发进行。
技术实现要素:
鉴于上述问题,本发明的目的是提供一种只写类SQL语言从而达到操作数据库的能力的数据库访问系统及其访问方法。
根据本发明的一个方面,提供一种数据库访问系统包括业务层、逻辑层和数据层,其中,所述业务层包括接口模块,所述接口模块包括一个以上的接口,每一个接口采用注解方式定义有类SQL语句和接口方法;所述逻辑层,位于所述业务层和所述数据层之间,用于接收数据库操作请求数据,根据所述数据库操作请求数据触发所述接口模块中相应的接口,解析所述接口的类SQL语句,实现所述接口的接口方法的处理逻辑;所述数据层,执行所述逻辑层的处理逻辑,获得返回值并反馈给所述逻辑层。
根据本发明的另一个方面,提供一种利用上述数据库访问系统对数据库进行访问的方法包括:在业务层的接口模块内设置有一个以上的接口,其中,所述接口采用注解方式定义有类SQL语句和接口方法;通过逻辑层接收数据库操作请求数据,根据所述数据库操作请求数据触发业务层中相应的接口,对所述接口内的类SQL语句进行解析,生成实现所述接口方法的处理逻辑;在数据层执行所述逻辑层的处理逻辑,获得返回值并反馈给所述逻辑层,实现所述接口方法。
本发明所述数据库访问系统通过注解方式采用类SQL语言在业务层的接口内定义接口方法,从持久化对象中获取数据并且实例化实体对象,开发者利用类SQL语言实现关注业务层,而不需要了解底层机制,提高开发者在开发时的开发效率,减少开发公司经济与时间上的投入,以及扩展的维护成本。更加关注类似SQL语言开发方式,对于开发及错误排查更有效率。
另外,本发明所述本发明所述数据库访问系统直接在接口上查看接口方法,相对于在配置文件查看接口方法中,不需要切换视图,能够解决配置文件过大,维护乏味的问题。
附图说明
通过参考以下结合附图的说明及权利要求书的内容,并且随着对本发明的更全面理解,本发明的其它目的及结果将更加明白及易于理解。在附图中:
图1是本发明数据库访问系统第一实施例的构成示意图;
图2是本发明数据库访问系统第二实施例的构成示意图。
在所有附图中相同的标号指示相似或相应的特征或功能。
具体实施方式
在下面的描述中,出于说明的目的,为了提供对一个或多个实施例的全面理解,阐述了许多具体细节。然而,很明显,也可以在没有这些具体细节的情况下实现这些实施例。以下将结合附图对本发明的具体实施例进行详细描述。
以下将结合附图对本发明的具体实施例进行详细描述。
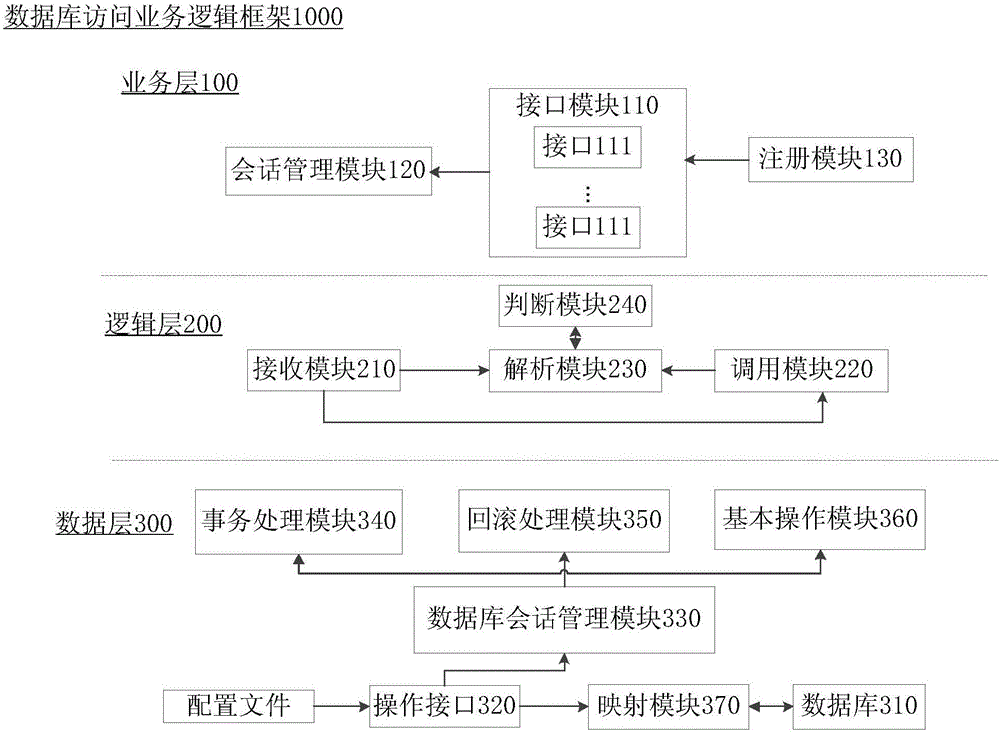
图1是本发明数据库访问系统第一实施例的构成示意图,如图1所示,所述数据库访问系统1000包括业务层100、逻辑层200和数据层300,其中:
业务层100,包括接口模块110,所述接口模块110包括一个以上的接口111,每一个接口111采用注解方式定义有类SQL语句和接口方法,例如,接口A
上述接口A中采用注解(@SQL)方式定义类SQL语句和接口方法(select方法);
逻辑层200,位于业务层100和数据层300之间,逻辑层200接收数据库操作请求数据,根据所述数据库操作请求数据触发业务层100的接口模块110中相应的接口111,对所述接口111内的类SQL语句进行解析,实现所述接口111的接口方法的处理逻辑;
数据层300,执行所述逻辑层200的处理逻辑,获得返回值并反馈给所述逻辑层200。
利用上述数据库访问系统100对数据库进行访问的方法包括:
在业务层100的接口模块110内设置有一个以上的接口111,其中,所述接口采用注解方式定义有类SQL语句和接口方法;
通过逻辑层200接收数据库操作请求数据,根据所述数据库操作请求数据触发业务层100中相应的接口111,对所述接口111内的类SQL语句进行解析,生成实现所述接口方法的处理逻辑;
在数据层300执行所述逻辑层200的处理逻辑,获得返回值并反馈给所述逻辑层200,实现所述接口方法。
在本实施方式中,数据库访问系统1000将业务封装到类SQL语句中,并结合接口的方式构建了数据库访问业务通用的逻辑框架,因此,开发者在开发过程中能够利用类SQL语句实现所关注的业务本身,而不需要了解底层机制,能够大幅降低开发难度,从而能够大幅缩短开发周期,并大幅消减开发成本。
另外,由于类SQL语句定义在业务层的接口中,因此,能够在业务层集中管理类SQL语句,能够有效地降低维护成本,并能够有效地提高排错效率。
再者,开发者能够直接在接口上查看类SQL语句,与在xml等配置文件中查看的方法相比,不需要切换视图,既能够解决配置文件过大、过多的问题,又能够提高开发效率。
上述数据库访问系统1000实际业务开发时,SQL语句已经能表达绝大部分的业务需要,以一个简单的SQL语句来复用各种逻辑处理,比如访问数据库,过滤规则,参数传递,生成对象则对于业务来说其一保证了底层的一致,其二极大复用了以前需要重复实现或依赖特定编程模式实现的程序段。
图1示出了本发明数据库访问系统的业务层的一个实施例,如图1所示,所述业务层100包括接口模块110和会话管理模块120,
其中,所述会话管理模块120,用于管理业务层100与其他层之间的会话;
其中,所述接口模块110的接口111可以采用注解的方式定义有执行查询、更新、删除、插入等的类SQL语句,所述类SQL语句设置有sql和sqlType两个参数,其中,
sql参数用于定义待解析类SQL语句,如接口A的例子中,sql参数定义的待解析类SQL语句中包含两个待替换变量“#{semester}”和“#{year}”,即,以“#{待替换变量名}”的方式设置一个以上的待替换变量,该待替换变量将在解析处理中被替换为类SQL输入参数中的相应的实际值,优选地,所述替换变量的类型还包括参数的位置,此外,对于待替换变量,还可以以“#{待替换变量名@参数位置}”的形式指定获取实际值的参数位置,例如,可以以指定为“#{semester@1}”,当bean中的成员变量semester为参数列表(例如List、String数组等)时,能够指定将该待替换变量“#{semester@1}”替换为成员变量semester的参数列表中的第一个参数,能够在类SQL语句的paramType参数中使用具有参数列表形式的成员变量的bean,从而提高易用性,有助于功能的扩展,另外,所述类SQL语句中,可以采用注解来指定sql选择的列项映射到javabean的成员变量或者全部变量,也可以采用设定别名(例如as)的方式实现sql到返回值javabean的变量的映射,如接口A的例子中,使用“as”关键字对“ID”字段指定了别名“id”,对“Year”字段指定了别名“year”,对“Semester”字段指定了别名“semester”,对“Status”指定了别名“status”;
sqlType参数用于定义待解析SQL语句的CRUD操作类型,例如,对应插入操作的SQLTYPE.INSERT类型、对应查询操作的SQLTYPE.SELECT类型、对应更新操作的SQLTYPE.UPDATE类型以及对应删除操作的SQLTYPE.DELETE类型。
优选地,接口111的所述类SQL语句还设置有resultType和paramType参数中的一个或两个,其中,
resultType参数用于定义SQL执行返回值的类型,所述SQL执行返回值的类型既可以是开发者自定义的bean类型(如接口A中的“com.cuc.beans.LabManageBatcher”),也可以是String、List等Java标准API提供的类型;
paramType参数用于定义SQL输入参数的类型,所述SQL输入参数的类型既可以是开发者自定义的bean类型(如接口A的例子中的“com.cuc.beans.LabManageBatcher”),也可以是String、List等Java标准API提供的类型,例如,接口B是采用注解方式定义有类SQL语句执行更新操作的接口111,如下所示:
在上述接口B中包括采用注解方式定义的类SQL语句和接口方法(update),sql参数定义的待解析SQL语句中包含四个待替换变量“#{status}”、“#{id}”、“#{semester}”和“#{year}”,sqlType参数定义的待解析SQL语句的CRUD操作类型为对应更新操作的SQLTYPE.UPDATE。
“com.cuc.beans.LabManageBatcher”,paramType参数定义的SQL输入参数的类型为开发者自定义的bean类型“com.cuc.beans.LabManageBatcher”,在该类SQL语句中并没有设置resultType参数。
图1还示出了是本发明数据库访问系统的逻辑层一个实施例,如图1所示,所述逻辑层200包括:
接收模块210,接收例如查询、删除、更新、插入等的数据库操作请求数据。进一步,接收模块210可以将数据库操作请求数据保存在规定的bean中。例如,接口A的例子中,接收模块210可以将数据库操作请求数据保存在与数据表“labmanagebatcher”对应的开发者自定义的“com.cuc.beans.LabManageBatcher”类型的bean中;
调用模块220,根据接收模块210接收的数据库操作请求数据,调用业务层100相应的接口111,从而触发用于实现所述接口111的接口方法的操作,优选地,所述调用模块220采用调用方式通过映射表触发相应的接口111,例如,
DefaultQuery query=new DefaultQuery();
SelectRecord test=(A)query.getMapper(A.class);
test.select(batcher);
当调用getMapper方法时,将会触发实现上述接口A的接口方法select的操作,例如添加一个数据层的相关类的操作,比如打开数据库连接,打开Session,打开事务等。实现所述接口方法的操作可以是预先设定的默认的操作,也可以是开发者根据业务需求具体开发的操作,对此并不作任何特别限定;
解析模块230,根据所述数据库操作请求数据,将所述接口111的类SQL语句解析成标准SQL语句,实现业务层100所述接口方法的处理逻辑,例如,对接口A的解析,当解析#{semester}这个时,将会解析成对方法参数的解析,也就是对参数LabManageBatche中的semester字段进行获取值。
下面,举例说明逻辑层200的具体处理。
例如,在接收模块210接收到的数据库操作请求数据是对数据表“labmanagebatcher”进行查询操作的请求,并且在该数据库操作请求数据中包含查询条件“Semester:1,Year:2016”。在这种情况下,接收模块210可以将请求数据中的查询条件保存在与数据表“labmanagebatcher”对应的开发者自定义的“com.cuc.beans.LabManageBatcher”类型的bean中,假设该bean的变量名为“batcher”。在“com.cuc.beans.LabManageBatcher”类型的bean中,定义有用于保存“ID”信息的成员变量“id”,用于保存“Year”信息的成员变量“year”,用于保存“Semester”信息的成员变量“semester”以及用于保存“Status”信息的成员变量“status”。由接收模块210接收到的查询条件中的“Semester”和“Year”信息被分别保存在成员变量“semester”和“year”中,即,在变量名为“batcher”的bean中,成员变量“semester”的变量值被设定为“1”,成员变量“year”的变量值被设定为“2016”。
接下来,调用模块220根据数据库操作请求数据(例如操作对象的数据表名称或者操作对象的业务识别编码等),调用相应的接口111,在此,假设调用上述接口A,从而触发预先设定的默认的操作或者开发者自定义的用于实现该接口A的接口方法select()的操作。
解析模块230根据数据库操作请求数据,将上述接口SelectRecord中的类SQL语句解析成标准SQL语句。例如,在上述接口SelectRecord的类SQL语句中,sql参数中包含待替换变量“#{semester}”和“#{year}”,在这种情况下,解析模块230根据保存在上述变量名为“batcher”的bean中的相应的成员变量的变量值,将待替换变量替换为实际值,即,将“#{semester}”替换为成员变量“semester”的变量值“1”,并将“#{year}”替换为成员变量“year”的变量值“2016”。
由此,上述接口SelectRecord中的类SQL语句被解析为标准SQL语句:select ID as id,Year as year,Semester as semester,Status as status from labmanagebatcher where Semester='1'and Year='2016'。
在此,使用别名的目的在于,在该标准SQL语句的执行结果中,字段名称“ID”、“Year”、“Semester”和“Status”以别名的形式返回,即返回字段“id”、“year”、“semester”和“status”,由此,使SQL执行结果中的字段名称与resultType参数中指明的作为返回值的类型的“com.cuc.beans.LabManageBatcher”类型中的各个成员变量名称相对应,从而能够使用公知的赋值方法将SQL执行结果顺利地赋予到“com.cuc.beans.LabManageBatcher”类型的bean中。
图1还示出了本发明数据库访问系统的数据层一个实施例,如图3所示,所述数据层300包括:
数据库310;
操作接口320,在数据库中存储或者获得数据的接口,提供可变粒度的数据库操作接口;
数据库会话管理模块330,用于完成数据库操作过程中的会话管理;
事务处理模块340,用于执行数据库事务;
回滚处理模块350,用于执行数据库操作的回滚;
基本操作模块360,用于执行普通的数据库增、删、改、查操作。
优选地,在数据层300中还包括映射模块370,该映射模块370用于实现数据库310与bean对象的映射,使用类SQL语句将数据库310中的数据表与指定的bean对象关联起来,从而实现数据表中字段与bean中的成员变量之间的自动映射。
图2是本发明所述数据库访问系统的第二实施例的示意图,如图2所示,在此实施方式中,业务层100还包括注册模块130,所述注册模块130,注册有一个以上的自定义数据处理函数,包括一个以上的自定义数据处理类和自定义数据处理函数配置文件,其中,
所述自定义数据处理函数具有的一个以上的待处理参数;
所述自定义数据处理类用于实现自定义数据处理函数的具体处理逻辑,例如,当用户想要自定义实现正则过滤功能的自定义数据处理函数filterReg时,可以自定义一个自定义数据处理类FilterReg,并在该FilterReg类中描述实现正则过滤功能的具体处理逻辑,即通过自定义数据处理类FilterReg实现自定义数据处理函数filterReg的具体处理逻辑。
所述自定义数据处理函数配置文件用于描述自定义数据处理函数与自定义数据处理类之间的映射关系,在自定义数据处理函数配置文件中,可以采用“自定义数据处理函数名=自定义数据处理类名.class”的形式定义一个以上的映射关系,例如,在自定义数据处理函数配置文件中定义有“filterReg=FilterReg.class”,使自定义数据处理函数filterReg与用于实现该函数的具体逻辑处理的自定义数据处理类FilterReg相互对应。
优选地,为了使处理逻辑共通化,可以使自定义数据处理类均继承自规定的基础类,并在规定的基础类中实现各种共通处理逻辑,从而能够减少重复开发,能够提高维护的效率。
在类SQL语句的sql参数中,可以进一步使用在注册模块120中注册的自定义数据处理函数,例如,为了对特定字段的查询结果数据进行正则过滤,可以在类SQL语句中使用自定义数据处理函数filterReg,所述类SQL语句如下:
@SQL(sql="select filterReg(ID,'[0-9A-Z]')as id,Year as year,Semester as semester,Status as status from labmanagebatcher where Semester='#{semester}'and Year='#{year}'",sqlType=SQLTYPE.SELECT,resultType="com.cuc.beans.LabManageBatcher",paramType="com.cuc.beans.LabManageBatcher")。
在上述例子中,字段“ID”的字段值将作为“待处理参数”被传递给自定义数据处理函数filterReg,通过自定义数据处理类FilterReg对字段“ID”的字段值进行开发者自定义的数据处理。
在第二实施方式中,逻辑层200还包括判断模块240,判断调用模块220调用的接口111的类SQL语句中是否存在自定义数据处理函数,当存在自定义数据处理函数时,发送不翻译自定义数据处理函数的指令给解析单元230,并将所述自定义数据处理函数的名称和位置发送给数据层;当不存在自定义数据处理函数时,发送解析类SQL语句的指令给解析单元230。
此时,解析模块230根据判断模块240的指令对所述类SQL语句进行解析,具体而言,当解析模块230从判断模块接收到不翻译自定义数据处理函数的指令时,对除自定义数据处理函数以外的类SQL语句进行解析;当判断模块240判断为在待解析SQL语句中不存在自定义数据处理函数时,解析模块230执行与上述第一实施方式相同的处理。
例如,对于上述存在有自定义数据处理函数filterReg的待解析SQL语句,解析模块230将其解析为标准SQL:select ID as id,Year as year,Semester as semester,Status as status from labmanagebatcher where Semester='1'and Year='2016'。在第二实施方式中,对待解析SQL语句中的待替换变量进行替换的方法与上述第一实施方式相同。
在第二实施方式中,与上述第一实施方式同样地,数据层300执行逻辑层200解析后的标准SQL语句并获取该标准SQL语句执行的返回值之后,根据判断模块240的判断结果,对标准SQL语句执行的返回值执行自定义数据处理。即,当数据层300接收到所述自定义数据处理函数的名称和位置时,数据层300根据注册模块120中的自定义数据处理函数配置文件,查找与该自定义数据处理函数对应的自定义数据处理类,并将标准SQL语句执行的返回值中的作为自定义数据处理函数的待处理参数的字段值传递给该自定义数据处理类,并且用该自定义数据处理类的返回值替换该标准SQL语句执行的返回值中的作为自定义数据处理函数的待处理参数的字段值;当数据层300没有接收到所述自定义数据处理函数的名称和位置时,数据层300执行与上述第一实施方式同样的处理。
在上述的例子中,数据层300将字段“ID”的字段值作为自定义数据处理函数filterReg的待处理参数传递给与自定义数据处理函数filterReg对应的自定义数据处理类FilterReg,并用自定义数据处理类FilterReg的返回值替换字段“ID”的字段值,进而作为别名“id”的值返回给逻辑层200。
根据第二实施方式,开发者能够根据业务需求开发并注册自定义数据处理函数,能够以标准SQL函数的方式在待解析SQL语句中描述想要进行的数据处理,能够封装自定义数据处理函数,从而有效地提高开发效率和维护效率。
在本发明的一个优选实施例中,注册模块130还注册返回值对象,对接口111的接口方法中的返回值进行处理,数据返回时,根据返回值类型来处理数据,例如,根据返回值对象进行分页:
@SQL(sqlType=SQLTYPE.SELECT,sql="select ID as id,StudentClass as studentClass,TeacherID as teacherID,StudyTime as studyTime,Type as type,BatcherID as batcherID,LabID as labID FROM Course",resultType="com.cuc.beans.Course")
PageResult<Course>getAll()。
上述例子中,分页根据返回值的类型决定的,例如PageResult返回值,通过PageResult返回值来自动进行实现分页的业务逻辑,不再需要开发者自己实现,其中,分页查询在得到用户的请求后,会根据配置信息也就是返回值PageResult决定是否进行分页,并返回一个课程的列表对象在页面进行数据迭代以及分页信息获取,使得开发无需关心是如何实现的,只要做相关配置即可。
通过注册模块130注册的返回值对象将已经处理好的从SQL里返回的数据映射成另外一种类型,使用者可以进行多种数据映射开发。实施时,会判断接口方法是否具有注册对象,如果具有注册对象,则进行相应处理,如分页,过滤等。
综上所述,参照附图以示例的方式描述了根据本发明提出的数据库访问系统及其访问方法。但是,本领域技术人员应当理解,对于上述本发明所提出的系统及方法,还可以在不脱离本发明内容的基础上做出各种改进。因此,本发明的保护范围应当由所附的权利要求书的内容确定。
- 还没有人留言评论。精彩留言会获得点赞!