计算机系统的制作方法
交叉引用
本申请要求2008年3月26日递交的美国临时申请第61/039,721号的优先权,该申请通过引用合并于此。
技术领域
本发明涉及一种计算机系统。
背景技术:
评估患者的临床结果的传统方法主要是基于临床医生的判断和过去的经验。传统的方法一般涉及在孤立时间点的实验室测试、患者调查和诊所就诊,所有这些都不可伸缩来进行时间系列分析,尤其是进行实时追踪或预测患者的临床结果的趋势的分析。传统方法本质上有明显的缺点,即在进行临床决策时只考虑相对少量的一组信息,例如单个临床医生的个人喜好。因此,在现有医疗系统下,当涉及多个变量时,病人护理变得越来越困难。特别是,缺乏一种用于实现多维分析的系统和方法,其中用一大组生物标志物来帮助临床结果的诊断、预后和治疗,或是临床试验的设计和执行。
多元统计学通常涉及基于多个变量来确定一个结果或一系列结果的统计分布。本质上,由于生理学的复杂性,多数医学状况和治疗是多元性的。大量疾病生物标志物的发现以及小型化分析系统的建立形成了使得多元分析变得可行的新患者护理模式。一种理想的新模式可以提供对表征临床结果的信息的快速访问,然后通过定制的通信信道将这些信息自动链接,以便进行所需的医疗行为(适应性剂量范围确定、临床决策制定等等)。也需要将来自个体的血液测试的信息与其它生理相关因素整合起来,并且以可操作的格式来呈现这些信息。本发明所述的技术满足了这些需求并且也提供了相关的优点。
技术实现要素:
本发明提供了一种用于对象数据分析的医疗信息系统。在一个方面,本发明的系统对于推动血液测试和数据分析的未来非常有用。例如,该系统可以作为构建在实时、现场护理消费者血液监测装置的周围的整合基础架构的一部分,该基础架构分析少量血液样品(例如500μl、50μl、25μl、10μl甚至更少),并且将这些信息无线地发送到数据库,该数据库将实时数据和来自不同数据库的所存储的数据(患者病历、遗传/基因组信息、来自关键试验的数据)一起整合到中央储存库中。该系统然后允许对该数据储存库自动应用多元、多维数学来执行特定的命令或任务,例如在给定医学状况的病理生理学的情况下动态地绘制实时PK/PD。
在另一个方面,本发明的系统可用于通过适应性临床研究来改进关键药物的标注,这可以为新的适应症、患者亚群、以及改进安全问题来生成标注扩展的公示。开发这样的用于家庭实时血液监测的系统具有重要的意义,可以使人能够收集本来不能通过使用传统实验室测试来获得的信息。
该医疗信息系统通常包括(a)用于接收对象数据并且与处理器通信的输入装置;(b)与带有数据库的处理器通信的存储单元,用于(i)存储对应于由一组离散临床结果定义的概率空间的数据,其中每一个临床结果由至少一个生物学标志物的统计分布来表征;并且(ii)存储对应于至少一个生物学标志物的对象数据;(c)计算所述对象数据在所述概率空间中的位置来作为评估所述对象的离散临床结果的概率的方式的处理器;以及(d)将与(c)的离散临床结果相关的信息发送给最终用户的输出装置。
对该系统进行自适应来预测的非限制性临结果现可选自下组:包括但不限于,完全应答(CR)、部分应答(PR)、病情稳定(SR)、无应答(NR)、药物不良反应(ADR)和药物毒性。在使用该医疗信息系统时,最终用户可以是医务人员或是对象本人。在一些情况下,最终用户来自制药公司。
在一个方面,该系统的处理器计算所述对象数据在所述概率空间中的位置来作为评估所述对象的离散临床结果的概率的方式。
在另一个方面,该系统的输入装置包括触摸屏。在需要时,该输入系统可包括数据输入入口或键盘。输入到系统的、由系统处理的或由系统作为输出发送的对象数据可以是文本的、数字的或是类别。在需要时,文本或数字信息是最终用户要求的。
在一些情况下,对象数据代表体液中存在的至少一个生物学标志物的测定。在一些情况下,测量是由对象操作的现场护理装置获得的。可以在不同时间点进行测量以产生概率空间内的轨迹,其中所述轨迹代表所评估的临床结果的时间系列。不同时间点可以覆盖一段少于或约24小时的时期。
在另一个方面,该医疗信息系统包括带有自动报警系统的输出装置。该自动报警系统可由最终用户来编程。在需要时,该自动报警系统是根据用于临床试验的预定义协议来编程的。在另一个方面,该系统的输出装置响应于来自最终用户的指令来发送对象数据和概率空间的所选部分。在又一个方面,输出装置所发送的信息被加密。在还有一个方面,输出装置所发送的信息代表在单个时间点对于所述对象的临床结果的评估。输出装置所发送的信息可代表所评估的临床结果的时间系列。
在另外一个方面,该系统的输入装置和/或输出装置包含可远程访问网络的用户界面。
在又一个方面,该医疗信息系统包括网络。
在又一个方面,该系统的存储元件存储与至少一个生物学标志物有关系的多个对象的历史参考数据。在需要时,存储在存储元件中的数据选自下列类别:包括病理、解剖、治疗选项、治疗结果、药理学参数、药物动力学参数、心理学参数和基因组信息。数据库可以是公共数据库、内部数据库。
该医疗信息系统的最终用户可以是医疗服务提供者,包括但不限于健康维护组织(HMO)。
本发明还提供了一种表征对象的临床结果的概率的方法。该方法包括下列步骤:(a)构造由一组离散临床结果定义的概率空间,其中每一个临床结果由至少一个生物学标志物的统计分布来表征;(b)获得对应于至少一个生物学标志物的对象数据;并且(c)计算所述对象数据在所述概率空间中的位置,从而表征所述对象的临床结果的概率。
还提供了一种表征对象的临床结果的方法,包括:(a)在服务器内构造概率空间,其中该概率空间是由一组离散的临床结果来定义的,每一个临床结果由至少一个生物学标志物的统计分布来表征;(b)将对象的数据输入到服务器,所述数据对应于至少一个生物学标志物;并且(c)计算所述对象数据在所述概率空间中的位置,从而表征对象的临床结果。在一些实施方式中,在实施本方法时,在不同时间点重复至少步骤b和c以产生概率空间内的轨迹,其中所述轨迹表明临床结果的发展的可能性。本方法可包括一旦评估或表征了所述对象数据在所述概率空间中的位置就向医务人员或对象通知采取医疗行为的需要。在一些情况下,医疗行为涉及至少一个选自下组的行为:包括改变给予所述对象的现有治疗剂的用量,给予不同的治疗剂,以及给予治疗剂的不同组合。对医疗行为的通知可以电子地发送,例如无线地发送。本方法还可包括下述步骤:一旦选择了至少一个行为,则进行结果分析来评估所述所选行为的结果,并且自动更新所述对象的离散临床结果的概率。
本发明还提供了一种包含计算机可读指令的计算机可读介质,该指令在被执行时使得处理器:a)提供由一组离散临床结果定义的概率空间,其中每一个临床结果由至少一个生物学标志物的统计分布来表征;b)获得对应于至少一个生物学标志物的对象数据;并且c)计算所述对象数据在所述概率空间中的位置,来评估所述对象的临床结果的概率。一般而言,该指令在软件运行时环境中操作。在一个方面,该在被执行时还使得处理器提供基于对概率空间中的对象数据的轨迹参数的评估的用户定义报警条件,其中所述轨迹参数为速度、加速度、方向和位置中的至少一个。
在一个方面,本发明提供了一种预测需要医疗干预的医学状况的发生的方法,该方法包括:(a)测定对象中的第一组生物标志物的浓度,并且以给定频率测定所述对象的一个或多个生理指标,其中第一组生物标志物被认为是对医学状况的预测;(b)根据(a)中的浓度测定,从第一组生物标志物中产生与医学状况的发生相关性更强的生物标志物子集和/或生物标志物的新测定频率;以及(c)测定(b)的子集的浓度和/或遵循一个或多个生物标志物的新测定频率,从而预测医学状况的发生。
在一些情况下,一方法还包括用多元统计软件分析反映浓度和/或生理指标的数据。在一些情况下,生物学标志物存在于所述对象的生物样品中。生物样品可以稀释合适的倍数,以确保例如检测到合适的浓度水平范围。
在本发明的另一个方面,一种监测对象的败血症形成的方法包括:多次测定至少两个选自下组的参数:(1)所述对象的体温、(2)所述对象的蛋白C浓度、(3)所述对象的白细胞介素6(IL-6)浓度,以产生温度趋势、蛋白C趋势和/或IL-6趋势;并且其中体温升高超出正常体温、蛋白C浓度下降和/或IL-6浓度升高表明所述对象中的败血症形成。在一些方面,蛋白C降低和IL-6上升可表明所述对象中的败血症形成。在其他一些方面,蛋白C降低和IL-6上升以及体温升高超过正常体温可表明所述对象中的败血症形成。在一些情况下,所述对象中IL-6浓度升高至少约10倍表明所述对象中的败血症形成。在又一个情况下,所述对象中IL-6浓度升高至少约100倍表明所述对象中的败血症形成。本方法还可包括一旦体温升高超过正常体温和/或蛋白C浓度降低,则提高测量IL-6浓度的频率的步骤。例如,IL-6测量的频率可被提高到每天一次、每12小时一次、每8小时一次、每6小时一次或每4小时一次。确定败血症的形成之后可以立即跟上合适的医疗干预。
本发明还描述了一种表征对象的医学状况的方法,包括:获得第一组对象数据,包括来自对象的至少一个生物学标志物和至少一个生理参数;用获得的第一组对象数据确定该对象的医学状况的概率;从医学状况的概率中选择第二组对象数据;并且从该对象获得第二组对象数据,从而表征该对象的医学状况。
在又一个方面,公开了一种表征对象的临床状况的周期性的方法,该方法包括:标识临床相关状况的一组生物标志物;获得对应于所述一组生物标志物中的至少一个生物标志物的纵向对象数据,以获得对象数据的趋势;分析所述趋势来标识至少一个生物标志物的周期性变化;测定趋势的周期性变化的峰值测量值;并且表征该峰值从而表征临床相关状况的周期性。在一些情况下,分析步骤包括开发ARIMA模型来确定潜在模型中的差异滞后。差异滞后可以用于消除趋势并且建立固定趋势。在一些情况下,分析步骤包括计算自相关函数,并且测量步骤包括标识自相关函数中的统计上显著的峰。在一些情况下,分析步骤包括计算频谱密度,并且计算频谱密度是用快速傅立叶变换来进行的。测量步骤可包括标识最大频谱密度频率的功率谱。
在本发明所述的一个方面,一种监测对象对于治疗的应答的方法包括获得对应于临床相关状况的一组生物标志物中的至少一个生物标志物的纵向对象数据以获得对象数据的趋势,其中对象数据是从接收治疗的对象获得的;监测趋势的周期性;并且将周期性与对于对象接收的治疗的应答对应起来。在一些情况下,治疗为周期性给药方案。在一些情况下,对治疗的应答由趋势的峰值水平的时间依赖行为来表征。在一些情况下,时间依赖行为是基本恒定的。在其他情况下,时间依赖行为是呈线性变化的。在又一些其他情况下,时间依赖行为是呈指数变化的。
在一个方面,本发明公开了一种表征接触治疗剂的临床相关患者亚群的发病的方法,该方法包括:标识在血液样品中作为治疗剂的替代标志物的一组生物标志物;从接触治疗剂的患者群纵向测定一组生物标志物;在患者群的一组生物标志物的测定值的多元聚类空间中标识不同的聚类;以统计学方式确定不同聚类的分离速率,并测定不同聚类之间的距离;从患者群获得患者信息以便对临床相关亚群中的患者进行分类;并且将不同的聚类和临床相关亚群进行比较以表征不同聚类的灵敏度和特异性来预测临床相关亚群。在一些情况下,该方法还包括标识第二组生物标志物,该第二组生物标志物被配置成改进不同聚类的发病的表征来预测临床相关亚群。在一些情况下,接触治疗剂的患者群是临床试验的参与者。在一些情况下,临床试验是剂量范围试验。在其他情况下,临床试验是适应性临床试验的一部分。适应性临床试验可被设计成表征最优给药方案,或可被设计成表征最优应答人群。在一些情况下,测量距离的步骤包括测量不同聚类质心之间的马氏(Mahalanobis)距离。在其他情况下,测量距离的步骤包括测量不同聚类之间的最近邻居距离。在又一些其他情况下,测量距离的步骤包括测量不同聚类之间的欧氏(Euclidean)距离。在一些情况下,测量距离的步骤包括测量不同聚类之间的曼哈顿(Manhattan)距离。
通过引用的合并
本说明书中提到的所有出版物和专利申请在此以与每个单独的出版物或专利申请专门且单独地通过引用来合并相同的意义而通过引用合并于此。
附图说明
本发明的许多特征都在所附的权利要求书中得以阐明。对本发明的特征和优点的更好理解可以参照以下阐明了各说明性实施方式的详细描述来获得,在各实施例方式中使用了本发明的许多原理,并且附图如下:
图1示出了马氏距离法的一般表示和代表性的椭圆。本图还包括马氏距离的数学方程式。
图2示出了临床结果的聚类分析结果的一个示例。
图3是示出评估对象的临床结果并向其分配概率的示例性方法的流程图。
图4示出了概率空间几何表示的示例。
图5示出了概率空间中对象的数据轨迹。
图6是示出提醒用户来评估对象的临床结果的示例性方法的流程图。
图7显示了建立临床结果的概率空间的规则的方法。
图8示出了概率空间的规则的图形呈现。
图9是示出实现数学模型来评估临床结果的示例性方法的流程图。
图10是示出包含用于传递和处理医疗数据的服务器的示例性系统的流程图。
图11示出了本发明的系统的一个示例性实施方式,该系统尼能够实时采集对象数据并且将信息实时发送给能够将信息或数据转换成生理相关上下文的服务器或系统。
图12显示了本发明的一个示例性系统,其中健康护理操作系统包括数据基础架构、模型和算法、以及软件应用程序。
图13显示了包含与某些类型的医学状况相关的生物学标志物的本体的示例性数据库。
图14示出了本发明的健康护理操作系统的示例性分层结构,其中中央操作系统能够访问数据基础架构以及监测装置以获得对象数据。
图15显示了本发明的一个示例性系统,其中分析数据库可以接收来自一个数据库的信息,该数据库包含来自读取器或盒数据库、历史数据库、能包含由患者输入的数据的患者数据库、以及客户数据库的数据。
图16示出了代表前列腺癌离散临床结果的概率空间中的两个对象的示例性轨迹。
图17示出了代表形成败血症的对象的临床结果的概率空间中的两个对象的示例性轨迹。
图18示出了代表使用胰岛素增敏剂的糖尿病对象的医学状况的概率空间中的两个对象的示例性轨迹。
图19示出了以二维方式图形地表示概率空间中的对象数据的轨迹的方法。
图20示出了以二维方式图形地表示概率空间中的对象数据的轨迹以及定义离散临床结果的数据的位置的方法。
图21显示了基于对两队列临床方案的蒙特卡罗模拟的聚类分析的动态亚群发生率。
图22显示了聚类调用统计数据对比假设的聚类数量的绘图。
图23示出了具有标志物空间分离的临床效果的标志物,其是临床研究终点的剂量的函数。
图24显示了示出两个I型生物标志物随时间的季节性的患者数据。
图25显示了生物标志物值的时间系列与化疗递送时间的关系。
图26显示了从随时间测得的循环热原水平计算的参数和/或到达高峰的时间之间的关系。
图27是IL-1β浓度与时间点数字的关系。
图28是IL1–β的样品-样品倍率变化与时间点数字的关系。
图29是IL-6浓度与时间点数字的关系,其中患者4发生败血症。
图30是IL-6的样品-样品倍率变化与时间点数字的关系,其中患者4发生败血症。
图31日是TNF-α浓度与时间点数字的关系。
图32是TNF–α的样品-样品倍率变化与时间点数字的关系。
图33示出了具有发热高峰并且没有标志物下降的患者5的残差图。
图34显示了患者4的数据点,表明在达到发热高峰前,蛋白C降低而IL-6上升。
图35是Th1-Th2转换和代表每个表型的细胞因子的示意图。
图36和图37显示了该系统采用一个方程式,该方程式用马氏距离平方方程和贝叶斯概率来预测败血症。
图38示出了在败血症试验中患者的多个标志物蛋白对比时间的图表。
图39示出了同一患者中两个特定标志物(蛋白C和C反应蛋白)的二元时间进程。
具体实施方式
在一个实施方式中,本发明提供了一种表征对象的临床结果的概率的方法。方法包括下列步骤,(a)构造由一组离散临床结果定义的概率空间,其中每一个临床结果由至少一个生物学标志物的统计分布来表征;(b)获得对应于至少一个生物学标志物的对象数据;并且(c)计算所述对象数据在所述概率空间中的位置,从而表征所述对象的临床结果的概率。
在实施本发明的方法时,通常采用一组与给定临床结果相关的生物学标志物(本发明中也称为生物标志物)。为了改善数学计算的可靠性和准确性,根据从与临床结果相关的数据的多元统计来选择生物标志物,该临床结果可以是例如疾病或医疗过程。在一些实施方式中,进行判别分析来确定与特定医疗临床记过最相关的生物标志物。
在一个方面,本发明提供了一种预测需要医疗干预的医学状况的发生的方法,该方法包括:(a)测定对象中存在第一组生物标志物的浓度,并且以给定频率测定所述对象的一个或多个生理指标,其中第一组生物标志物可以预测医学状况;(b)根据(a)中浓度测定,从第一组生物标志物中产生一个与医学状况的发生相关性更强的生物标志物子集和/或生物标志物的新测定频率;以及(c)测定(b)的子集的浓度和/或遵循一个或多个生物标志物的新测定频率,从而预测医学状况的发生。
以几何学方式对特定医学状况的多个离散临床结果(有时称为医疗结果)绘图。选择一组最能代表每个临床结果的生物标志物的值。使用本发明所述的数学方法,每个离散临床结果的类型分配的概率可被分配给任意一组观察到的生物标志物的值。然后可以通过在多个离散临床结果定义的几何空间内标绘任意一组观察到的生物学标志物的值的概率,来构造概率空间。
模型构建
在一些情况下,数学建模描述了系统的动态状态。在一些情况下,该模型采用了代表结果参数、生物标志物和药物浓度等随时间的方程式的系统。这些方程式可以简单到足以用闭合式解出,从而产生一个算法公式。然而,在一些情况下,人类疾病模型可以过于复杂而不允许有简单的闭合式解。在一些情况下,如本发明所述的解法可以是随时间向前投影数值解,也称为预测性生物模拟。
聚类分析的目的是将观察资料分组成聚类,使得每一个聚类就聚类变量而言尽可能的同源。基于所识别的生物标志物,可以采用任何传统聚类算法来确定的一组离散临床结果。除了判别函数分析外,存在许多这样的算法,例如“单连锁(Single Linkage)”、“完全连锁(Complete Linkage)”、“K均值”、“Ward法”或“质心法”。此外,可以用“决策树”来标识聚类。这些算法是熟悉本领域任何人所熟知的,并且可以在如SAS和SPSS等标准统计学套装中找到。聚类算法将类似的对象分组在一起,并且将不相似的对象分在不同的组中。
用来标识样品群中相似对象的类型的多元统计学也可用于构建合适的模型。目前采用的技术包括但不限于,判别函数分析(DFA)、分层聚类分析、因子分析(其中假设潜在模型或关系)、自组织映射(SOM)、支持矢量机(SVM)以及神经网络。每一个都是采用多元描述符矢量的模式识别技术,其中对象为同类成员,以便更全面地管理适应性临床试验。
估算模型参数空间的其他技术包括一些常规方法,例如图形方法和基于梯度的非线性优化(Mendes和Kell,1998)。图形方法通常应用于可以转换为线性回归问题的那些问题,并且通常不适用于闭环学习,因为他们在每一步都需要人的干预。基于梯度的非线性优化方法没有这样的限制,但是它需要有关参数估值的误差函数的信息。因此它通常收敛到局部最小值。包括遗传算法、进化规划、遗传规划和他们的变体(Back等人,1997;McKay等人,1997;Edwards等人,1998)的进化算法已经用于克服这些限制。
在一些情况下,为了最好地说明生物系统的动力学,上述方程式系统可包含计算固定时间段中生物体的变化速率的常微分方程式。这些定量是在分析时刻的系统状态的函数,并且包括系统中会影响变化速率的所有其他实体的项。
在许多情况下,如本发明所述,在血液中发现感兴趣的生物实体包括但不限于循环蛋白。在建模空间内,每个生物实体的时间变化速率称为导数,并且被量化为在时域内生物实体浓度曲线的瞬时斜率。
可以计算每个选定取样时间点处任何选定的目标生物实体的值,以及在取样空间内每个实体的变化速率。这会产生对于单位导数的每一个生物实体的点估值,包括但不限于每个单位时间内浓度的变化。
在一些情况下,一方法可以使用两个点斜率以及通过最后K个观察值的K点模型拟合回归方程式来估算一阶、二阶和高阶导数,例如:
dP(t)/dt=f(P(t),{其他蛋白、细胞类型等},模型参数)
其中P(t)是给定蛋白浓度,其是时间的函数。其中f是P(t)以及影响特定蛋白浓度曲线的生物实体的函数,包括第二信号、细胞数量等等。并且模型参数是量化这些关系的方程式中的系数,例如包括产生速率和清除速率。该系统可以是线性或非线性的。
本机制的一个替代实施方式是一个实体系统,其中P(t)是蛋白矢量Π(t)=[P1(t),P2(t),…PN(t)],N是被选择来取样的蛋白的数量,并且f(P,等)形成矩阵M(Π(t);β(Π(t))。这些系统参数成为矢量β(Π(t))。
例如,在矢量Π(t)中每个Pj(t)的清除速率以该矢量形式获得。β(Π(t))表征了矩阵M的函数系数。当β不依赖Π(t)或时间时,该系统是线性的。当β依赖t且随着时间线性变化时,该系统是线性的并且其参数是时间依赖的。
在另一示例中,当清除速率随时间变化并且能表示随时间上调或下调时,该系统是非线性的。该系统用但不限于以下矢量方程式来表示:
dΠ(t)/dt=M(Π(t);β(Π(t))*Π(t)
在又一个示例中,生物学系统的动态状态具有一特异性水平,其由示例性生物模拟系统获得。系统中的每个实体都通常作用于其他实体的小子集。例如,蛋白2通过结合到活化效应细胞的细胞表面受体上改变了蛋白1的产生速率。蛋白2的浓度改变了蛋白1的产生速率。当有第三蛋白作用于蛋白2的产生时,蛋白1的产生速率间接依赖于蛋白2的产生水平。
最佳地代表这一生物模拟系统中的上述示例的方程式为:
dP1/dt=β12P2(t)
dP2/dt=-β22P2(t)+β23P3(t)
dP3/dt=0
在这些示例性方程式中,蛋白3的浓度是恒定的,并且蛋白1的产生速率是蛋白2水平的增函数,并乘以因子β12>0。此外,蛋白2的水平是从系统中清除蛋白2的速率的函数,在这一情况下,以因子β22>0成比例,并且在其产生中P3(t)的作用以因子β23>0来描述,并且由矢量(β12,β22,β23)来参数化。一般情况下,任何三重矢量可用于产生蛋白1和2随时间的任何轨迹族。蛋白3在该模型中是不变的,因为它的导数保持为0。
通过在监测期间的每个时间点测量蛋白1和3,获得P1(t)和P3(t)的值,以及dP1/dt和dP3/dt的估值。然后可以解出P2(t),并且将解约束为参数矢量(β*12,β*22,β*23),这是由明确的代数方程式来定义的。P2(t)和dP2/dt的估值来自于基于来源于样品的点估值的受限系统的状态。这使得当模型轨迹可能在下一个样品点时随着时间向前投影,并且在动态反馈自校正系统中根据需要重新调整模型参数。
自校正机制和反馈系统可以在周期性采样测量空间中实现,并且可以在每一个采样间隔进行模型的精调和重新参数化。在每一次应用这一自校正方法后,可接受的参数矢量的空间应开始收敛到在预测轨迹中向前投影的患者特定矢量。
基于预测蛋白分布图的纵向取样来动态表征患者亚群的系统可利用这些信息作为1型生物标志物,以便向研究科学家验证化合物象预期的那样作用于靶标。化合物的作用机制也可研究它是否如同预期那样发挥作用。对亚群的动态发生的表征基于他们的行为和他们表现的蛋白分布图。
在一个示例中,一个群体用测试化合物进行治疗,而另一个群体是没有处理的对照。如果治疗的群体的蛋白分布图与潜在假设的行为一致,假设涉及化合物的作用机制,蛋白分布图可作为集合模式用作1型生物标志物。如果这个群体中的个体表现为在蛋白分布图的方向和速率上都有相当的变化,可以调节较慢群体成员的剂量,并且可以相应改变试验协议。
各种统计学分析可以用来构建概率空间或模型。图1示出了在二维(多元)空间中由马氏距离来测量的相似度的示例性表征。判定函数分析的结果通常为在分析数据集中每个对象的马氏距离。以这种方式或相似的方式进行判定分析的方法是本领域熟练技术人员已知的。在该示例中,相对于彼此来标绘来自两个电影库变量(例如生物标志物)的数据。在分析集中的每一个患者由图中的单个点来表示。每个患者的生物标志物配对模式和数据聚类的质心之间的距离计算为马氏距离,并且在图1中用椭圆表示,其中质心通常可以被定义为感兴趣的空间内所有独立测量值的均值矢量。任何特定患者属于本发明所述的聚类的概率与到该聚类的质心的距离成反比。以此方式,图1的曲线图上的马氏距离椭圆用作两组自变量之间相似度的测量值。该方法还通过基于在潜在聚类数据中观察到的变化对特定患者分配分类分配的概率来说明合适的距离度量中的噪声。因此,该方法可以说明在概率空间中的不确定性。
在传统聚类中,通常从距离矩阵开始工作,该矩阵列出了要分类的每一对象对每一其他对象的相似度。如本领域熟练技术人员所知,该过程以创建距离矩阵开始。必须计算所有患者对之间的距离的三角矩阵。对象数据之间的每一个距离可以是所测量的生物标志物的函数。该函数可以采取总和或加权和的形式。给定变量的距离则是该变量的独立观察值之间的距离的总和。该总和也可以被加权。例如,每一对象聚类潜在地代表一个离散临床结果。
距离矩阵度量可以包括计算统计学差异,例如马氏距离、欧氏距离和曼哈顿距离。矩阵以统计学上严格的方式来表示多维空间中两个多元模式的相似度。根据这些距离,将个体一起分组在一个聚类中。
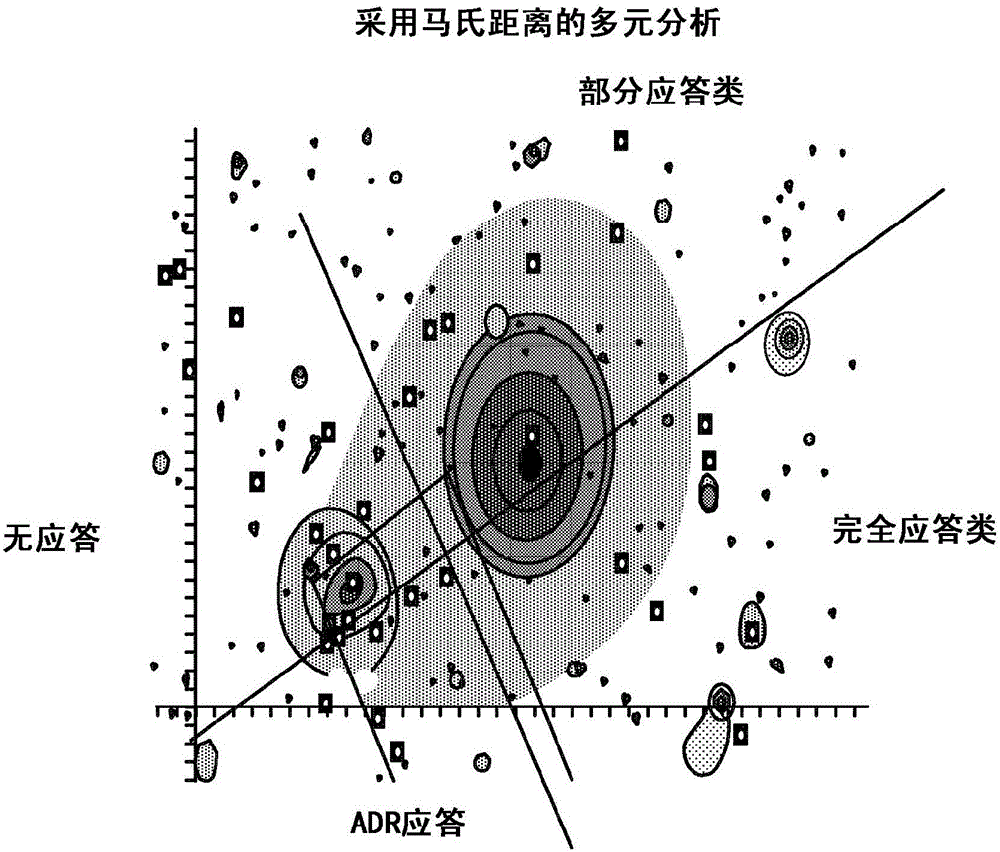
图2示出了定义离散临床结果的示例性聚类方法。在该示例中,采用质心法来确定生物标志物数据模式的多个质心。每个质心基于所测得的生物标志物信息或者限定或属于不同的一组离散临床结果。在图2中,医学状况的生物标志物模式的分类的示例包括部分应答类、无应答类、完全应答类和药物不良反应类。每个数据点与其分入的类的质心相关。质心可以被设为最能代表该类的点。
在已经构造了距离矩阵并且已经由一组生物标志物定义了离散临床结果后,可以通过应用说明数据的方差-协方差结构的度量来从多元分布(例如聚类)中构造概率空间。根据测得的距离,计算任何观测到的生物标志物模式的分类分配的概率。所计算的任何获得的生物标志物模式的概率定义了概率空间。
在需要时,通过贝叶斯计算来进行概率测定。计算分类分配的概率的其他方法包括但不限于,Nelson-Aalen估计、普通最小二乘估计、加权最小二乘估计和极大似然估计。另一种方法是采用决策树分析,并且从测量值中确定导出规则的最终灵敏度和特异性。
图3示出了构建用于评估医学状况的数学模型的本发明的示例性方法。根据医学状况的先前历史,用户(例如医生)标识相关的一个或多个临床结果。然后,利用生理状况、化合物或药物的作用方法和/或脱靶治疗效果来帮助限定概率空间的边界。
图4示出了概率空间和限定概率空间边界的离散临床结果的图形示例。每个数字代表一个不同的临床结果。
与给定医学状况的临床结果最为相关的生物标志物是用多元判定分析来标识的。根据与独立数据最密切相关的离散临床结果,对来自一组生物标志物的数据进行分类。
在用聚类分析和/或判定函数分析对数据集进行分类并且将其标识为临床结果后,确定临床结果的质心位置。对于每一个参照点或独立生物标志物数据点,评估分类到每个参考临床结果的概率。
当获得来自一个别对象的数据对应于至少一个生物标志物时,该数据被输入到数学模型中,并且确定它在概率空间内的几何位置。然后用距离度量来确定该对象数据相对于每个临床结果的位置。在一个优选实施方式中,该距离度量为马氏距离。对于对象数据,该模型获得对应于每一个离散临床结果的距离度量。
使用统计学估计方法将多个距离度量转换为对象数据的多个概率。多个概率中每一个概率对应于一个离散临床结果。在一个实施方式中,统计学估计为贝叶斯估计。多个概率用作在几何概率空间中对象数据的坐标,例如图4中所示。对象数据在概率空间中的位置是对该对象的医学状况的评估。
规则可由用户(例如医务人员)分配给概率空间内的任一点。规则可以引导用户理解对象当前的医学状况,并且引导用户选择行动过程。
本发明描述的方法可以在对象观察期间的任何时间点执行。对象数据可以在各个时间点获得。然后可用如本发明所述的数学方法来计算对象数据在概率空间内的位置。可以重复获得并计算对象数据在概率空间内的位置的步骤,以产生在概率空间内的轨迹,其中所述轨迹表明所评估的临床结果的时间系列。
轨迹
随着医学状况发展,通常由医务人员来监控对象。可以通过进行一系列的测试来执行监控。因为测试方法和例如现场护理微流体装置等装置变得更加可靠和容易获得,所以可以在多个时间点获取并且处理来自患者的数据。所获得的数据的序列结构常常是时间系列或一组纵向数据,但是也可以是反映与时间没有特定关系的顺序发生的变化的数据。该系统不要求时间或序列值是等距的。事实上,时间参数可以是随机变量本身。
在一些实施方式中,获得对象数据的时间系列是至少6小时、24小时、48小时、72小时或96小时。在其他实施方式中,该时间系列可以是至少7天、30天、60天、90天、180天或更多天。该时间系列也可以是一段几年的系列。
纵向数据提供了对医学状况或治疗的进展的有价值的观点。然而,随着测试项目的数量增加,分析纵向数据的复杂性增加。可能变得非常难以理解或确定关于医学状况或治疗的相关数据。
从对象获取的纵向数据可以分组为矢量或轨迹来评估医学状况。矢量在几何上被定义为箭头,其中尾部是初始点而头部是终止点。矢量的分量可涉及地理坐标系统,例如经度和纬度。作为具体示例,导航广泛使用矢量来定位目标,并且确定飞机和船舶的移动方向。
物理和工程领域可能是矢量分析的最常见用户,并且刺激了许多数学研究。在力学领域,矢量分析目标包括运动方程式,包括位置、速度、方向和加速度;重心;惯性矩;力,例如摩擦力、压力和附着力;电磁场和引力场。
速度,即位置的时间变化率,是速度(矢量长度)和方位(矢量方向)的组合。加速度是另一个常见的矢量,其是速度的时间变化率。速度和加速度都是通过矢量分析中获得的,这是对矢量的性质和/或行为的数学判定。
与医学状况相关的纵向对象数据的矢量分析可用于理解医学状况并且在统计上确定离散临床结果。
例如,可通过标绘个体的生物标志物数据来观察个体的正常状况。稳定的、正常的状况可以位于该图的一部分中。
个体的正常状况可以因给予药物或医学状况的变化而打乱。在给予药物的效果下,个体的正常状况会变得不稳定并且从图上的其原始位置移动到图中的新位置。当停止给予药物或者药效结束时,个体的正常状况可以再次被打乱,这会导致正常状况在图中的另一次移动。当停止给予药物或是药效结束时,个体的正常状况可回到给予药物前它在图中的原始位置上,或是与药物处理前的第一位置和药物处理后的第二位置不同的一个新的或第三位置上。
在一些情况下,生物标志物值可以变化很快,导致标准取样(例如实验室测试)会错过值的很大变化。在一个示例中,当患者正使用药物或是药物临床试验的成员时,很快发生败血症。很多时候不能看到关于患者的医学状况的早期暗示,因为目前的测试程序不够快。目前的测试程序在一段短时间内也不够灵活,因此如果需要在一段短时间内(例如4小时)测试患者的不同的生物标志物值或生理参数,常常无法接收到测试结果。
生物标志物值会发生大的变化,从而由于装置的量程导致只采用一个样品稀释水平的常规实验室方法不能对分析物进行测量。通常,采用延伸一个范围的多重稀释范围的更精密的实验室方法也会承受不了生物标志物值的巨大变化(例如超过1000倍)。如果重复稀释来获得合适的范围,在很多情况下,在获得测试的结果前可能已经过去了24小时。如上所述,本发明的系统或方法可以按接近实时的方式来报告结果,所以医务人员有能力从所获得的生物标志物值中按照需要来改变医疗行为过程。例如,当测试之间分析物的上升增加100倍、200倍、500倍、1000倍、10000倍或更高时,除了改变分析物的测量频率之外,还可以提高用于下一个样品的稀释水平(例如100倍、200倍、500倍、1000倍、10000倍或更高)。
在本发明的一个方面,一种监测对象败血症形成的方法包括:多次测定至少两个选自下组的参数:(1)所述对象的体温、(2)所述对象的蛋白C浓度、(3)所述对象的白细胞介素6(IL-6)浓度,以产生一个温度趋势、蛋白C趋势和/或IL-6趋势;以及其中温度升高超出正常体温、蛋白C浓度下降和/或IL-6浓度升高表明所述对象中的败血症形成。蛋白C降低后IL-6上升表明所述对象中的败血症形成。蛋白C降低后IL-6上升并且温度升高超过正常温度表明所述对象中的败血症形成。在一些情况下,所述对象中IL-6浓度升高至少约10倍、100倍、200倍、500倍、1000倍、10000倍、500000倍或更多表明所述对象中的败血症形成。在又一个情况下,所述对象中蛋白C浓度降低至少约10倍、100倍、200倍、500倍、1000倍或更多表明所述对象中的败血症形成。
在一个示例中,当接受化疗的患者在家没有发生重大事件时,可降低分析物的测量频率。在一些情况下,系统可以根据前面的结果来提示用户采取合适的行为。
在一些情况下,本发明所述的方法和系统允许在小到几天的时间范围内监测对象的健康状态或医学状况。例如,可以通过纵向取样的血液来监测疾病过程的进展和病理生理学、对于治疗的应答、以及在接触药物后可能的不良副作用发作。从这些样品中,可以建立关键循环生物标志物的分布图。特定生物标志物可根据例如但不限于对疾病过程及其分子病理生理学的了解、给定化合物的作用机制、及其所观察到的效果分布图。
图5示出了与前面所述的相似的纵向数据移动的表示。在每一个时间点(T=0到T=9),数据点被标绘在概率空间中。从一个点行进到下一个点的线是矢量。
可以通过研究个体的医学状况在概率空间内的移动的几个方面来帮助对个体的诊断。医学状况在其在图中移动时所遵循的路径的方向(例如角度和/或定向)可以帮助对给定临床结果的诊断、预后和治疗决策制定。医学状况在图中的移动的速度和加速度也可以是诊断性的。并且,在独立时间点处个体的医学状况的位置本身也可以是诊断性的
鉴于正常状况在图中的移动的方向和/或速度是诊断性的,可以使用正常状况的初始移动的方向和/或速度来预测随之发生的正常状况的新位置;尤其是如果确立了在某个药剂(例如药物)的效果下,图中只有在某几个位置上个体的正常状况是稳定的。
然而,在本发明的一些方面,评估对象医学状况的诊断和预测由合格的医务人员来执行,并且数学模型提供了一种教育工具和资源。
图6示出了实时地纵向应用数据模型的本发明的示例性方法。相关生物标志物和对应于不同生物标志物模式的离散临床结果是从历史数据预先确定的。然后从对象获得数据,并且测量对应于每个相关生物标志物的数据。数据优选用现场护理微流体装置从对象获得,然而,也可用任何方式获得。每次获得数据时,计算相对于从历史数据的聚类分析获得的每一个质心的距离度量(例如马氏距离)。质心代表从历史数据确定的离散临床结果。
跟随如图6中的流程图,对于每个个体随时间的数据集,计算数据属于每个临床结果的概率。该概率用诸如贝叶斯估计等统计估计过程从距离度量中计算。根据该组计算的概率,将对象数据的每个时间点的位置分配到概率空间。对每个时间点重复该计算。
然后,通过链接相邻的时间点来创建轨迹或矢量。可以计算矢量的距离、方向、速度和加速度,并且对其进行标绘以供显示或审阅。如果用户(例如医生)认为数据具有重大意义,则用户可以激活警报或预警系统并且相应地改变治疗或监测医学状况的行为过程。在调整了行为过程之后,可以重复评估对象的医学状况的步骤,以继续监测对象的轨迹。
图7示出了为评估对象的医学状况或在进行该评估后开发警报或早期预警系统的本发明的示例性方法。通过多元统计学计算,如图6所示的方法来获得对象的医学状况的轨迹和对应于该轨迹的信息(例如速度或加速度)。为了分析从数学分析中获得的信息,合格的医务人员(例如医生)可以建立根据来自个体对象的生物标志物模式的测定来激活警报或预警系统的准则。
该方法允许每个个人用户根据个人用户的优先级来定义他们认为合适的值和一组标准。应该了解,每个用户或医生对每个医学状况的看法不同,并且图7的示例方法考虑到了这些差异。
本发明的一个示例性方法向每个离散临床结果分配进度线。进度线可代表对象经历的医学状况的不同临床标准。优选地,进度线由个人用户,例如医务人员定位并且确定。用户可根据对象病史、医学状况的历史数据或个人经验来分配进度线的不同位置。图8示出了概率空间的一个示例,其中规则用进度线来表示。例如,如果对象的轨迹符合如图8所示的进度线之一,则可以激活报警或预警系统来通知用户或对象。其他可能的结果包括但不限于,医疗数据的系统打印输出,显示信息的用户界面,闪烁的灯、报警系统、警报、蜂鸣器、电子邮件、电话通信和寻呼机系统。警报系统不仅评估了对象的当前医学状况,也可引导用户的行动过程。
当轨迹的一个或多个特征超过了由模型用户确定的特定值时,可以激活警报或预警系统。然后用户可以确定下一步行动来评估对象的医学状况。
在本发明的一个实施方式中,在评估或表征了对象数据在概率空间中的位置后可以通知医务人员或对象需要采取医疗行动。通知的例子包括报警系统、警报、蜂鸣器、电子邮件、电话通信和寻呼机系统。
当本发明的方法通知对象的医学状况违背了医务人员设定的规则时,医务人员可采取医疗行动。医疗行动包括但不限于,对患者进行更多的测试、改变给予的治疗剂的剂量、给予治疗剂、终止给予治疗剂、联合治疗、给予替代治疗、将对象放置在透析机或心肺机上、以及给予止痛药。在一些实施方式中,对象可以采取医疗行动。例如,糖尿病对象可以给予胰岛素。
在采取或选择了医疗行动后,可以进行结果分析来表征所选行动的结果。结果分析可以导致自动更新对象的离散临床结果的概率。
与特定医学状况相关的任何临床结果、成果或行动可以用作离散临床结果。例如,离散临床结果可以为普遍性的,例如有应答、无应答、部分应答以及败血病,或者它们可以更特殊,例如药物不良反应。此外,离散临床结果可以是后遗症、下游临床相关事件或结果。可以获得任何药理学、病理生理学或病理心理学临床结果的对象数据。对象数据可以在给予患者干预之前的第一时间段内获得,也可在给予患者干预之后的第二或更多的时间段内获得。干预可以包括药物和/或安慰剂。干预可被认为具有影响特定医学状况发生的升高风险的倾向。干预可被认为具有使得特定医学状况发生的升高的风险降低的倾向。特定的医学状况可以是不想要的副作用。干预可包括给予药物,并且其中药物具有使得特定医学状况的风险升高的倾向,特定的医学状况可以是不想要的副作用。
医学状况包括但不限于,药理、病理、生理和心理状况。例如,异常、痛苦、不安、反常、焦虑、病因、疾病、紊乱、病症、不适、虚弱、病痛、问题或不适,并可包括积极的医疗状况,例如生育、怀孕和男性脱发延迟或逆转。特定的医学状况包括但不限于,神经退行性疾病、生育系统疾病、心血管疾病、自身免疫疾病、炎性疾病、癌症、细菌和病毒感染、糖尿病、关节炎和内分泌疾病。其他医学状况包括但不限于,红斑狼疮、类风湿关节炎、子宫内膜异位、多发性硬化症、中风、阿尔兹海默症、帕金森氏病、亨廷顿氏症、朊病毒疾病、肌萎缩侧索硬化症(ALS)、缺血、动脉硬化、心肌梗死的风险、高血压、肺动脉高压、充血性心力衰竭、血栓、I或II型糖尿病、肺癌、乳腺癌、结肠癌、前列腺癌、卵巢癌、胰腺癌、脑癌、实体瘤、黑色素瘤、脂质代谢疾病、HIV/艾滋病、包括甲肝、乙肝和丙肝等肝炎、甲状腺疾病、异常老化、以及任何其他疾病或病症。
生物学标志物
生物学标志物,在本发明中也称为生物标志物,根据本发明,包括但不限于,药物,前药、药物制剂、药物代谢物、例如表达的蛋白和细胞标志物等生物标志物、抗体、血清蛋白、胆固醇、多糖、核酸、生物分析物、生物标志物、基因、蛋白或激素,或其任意组合。在分子水平,生物标志物可以是多肽、糖蛋白、多糖、脂类、核酸、以及其组合物。
特别感兴趣的是与特定疾病或疾病的特定阶段相关联的生物标志物。这样的生物标志物包括但不限于那些与自身免疫疾病、肥胖、高血压、糖尿病、神经和/或肌肉退行性疾病、心脏病、内分泌疾病、或其任意组合相关联的生物标志物。
感兴趣的还有在一种或多种身体组织中丰度存在差异的生物标志物,所述组织包括心、肝、前列腺、肺、肾、骨髓、血、皮肤、膀胱、脑、肌肉、神经,以及所选的受到各种疾病影响的组织,这些疾病例如不同种类的癌症(恶性或非转移性)、自身免疫疾病、炎性或退行性疾病。
感兴趣的还有能指示微生物的分析物。示例性微生物包括但不限于细菌、病毒、真菌和原生动物。从对象获得的其他生物标志物还包括选自下组的血生病原体,包括但不限于,表皮葡萄球菌、大肠埃希氏菌、耐甲氧苯青霉素金黄色葡萄球菌(MSRA)、金黄色葡萄球菌、人葡萄球菌、粪肠球菌、铜绿假单胞菌、头状葡萄球菌、沃氏葡萄球菌、肺炎克雷伯菌、流感嗜血菌、模仿葡萄球菌、,肺炎链球菌和白色念珠菌。
生物标志物还包括选自下组的各种性传播疾病:淋病(淋病奈瑟球菌)、梅毒(梅毒螺旋体)、结膜菌(Clamyda tracomitis)、非淋菌性尿道炎(解脲尿枝原体)、酵母感染(白色念珠菌)、软性下疳(杜克雷嗜血杆菌)、滴虫病(阴道毛滴虫)、生殖器疱疹(I和II型HSV)、HIV I、HIV II、和甲型、乙型、丙型和庚型肝炎、以及由TTV引起的肝炎。
生物标志物包括各种呼吸道病原体,包括但不限于,铜绿假单胞菌、耐甲氧苯青霉素金黄色葡萄球菌(MSRA)、肺炎克雷伯菌、流感嗜血杆菌、金黄色葡萄球菌、嗜麦芽糖寡养单胞菌、副流感嗜血杆菌、大肠埃希氏菌、粪肠球菌、粘质沙雷氏菌、副溶血性嗜血杆菌、阴沟肠球菌、白色念珠菌、卡他莫拉菌、肺炎链球菌、弗氏柠檬酸杆菌、粪肠球菌、产酸克雷伯氏菌、荧光假单胞菌、脑膜炎奈瑟氏菌、酿脓链球菌、卡氏肺囊虫、肺炎克雷伯菌、侵肺军团菌、肺炎支原体和结核杆菌。
下面列出了根据本发明的另外的示例性标志物:茶碱、CRP、CKMB、PSA、肌红蛋白、CA125、黄体酮、TxB2、6-酮-PGF-1α、以及茶碱、雌甾二醇、黄体形成激素、高灵敏度CRP、甘油三酯、类胰蛋白酶、低密度脂蛋白胆固醇、高密度脂蛋白胆固醇、胆固醇、IGFR。
示例性肝脏标志物包括但不限于,精氨酸酶1(肝型)、甲胎蛋白(AFP)、碱性磷酸酶、丙氨酸转氨酶(ALT)、乳酸脱氢酶(LDH)、蛋白C和胆红素。
示例性肾脏标志物包括但不限于、TNF-α受体、胱抑素C、Lipocalin型尿前列腺素D合成酶(LPGDS)、肝细胞生长因子受体、多囊蛋白2、多囊蛋白1、纤囊素(Fibrocystin)、尿调节蛋白、丙氨酸、氨基肽酶、N-乙酰-β-D-氨基葡萄糖苷酶、白蛋白和视黄醇结合蛋白(RBP)。
示例性心脏标志物包括但不限于,肌钙蛋白I(TnI)、,肌钙蛋白T(TnT)、CK、CKMB、肌球蛋白、脂肪酸结合蛋白(FABP)、CRP、D二聚体、S-100蛋白、BNP、NT-proBNP、PAPP-A、髓过氧化物酶(MPO)、糖原磷酸化酶同工酶BB(GPBB)、凝血酶激活的纤溶抑制剂(TAFI)、纤维蛋白原、缺血修饰白蛋白(IMA)、心肌营养素-1和MLC-I(肌球素轻链-I)。
示例性胰腺标志物包括但不限于、胰岛素、淀粉酶、胰腺炎相关蛋白(PAP-1)和再生素蛋白(REG)。
示例性肌肉组织标志物包括但不限于肌肉生长抑素。
示例性血液标志物包括但不限于促红细胞生成素(EPO)。
示例性骨标志物包括但不限于交联的骨I型胶原的N-端肽(NTx)、骨胶原的羧基端交联端肽、赖氨酰-吡啶啉(脱氧吡啶啉)、吡啶啉、抗酒石酸酸性磷酸酶、I型前胶原C前肽、I型前胶原N前肽、骨钙素(骨钙蛋白)、碱性磷酸酶、组织蛋白酶K、COMP(软骨寡聚基质蛋白)、护骨素、骨保护素(OPG)、RANKL、sRANK、TRAP5(TRACP 5)、成骨细胞特异性因子1(OSF-1,多效生长因子)、可溶性细胞粘附分子、sTfR、sCD4、sCD8、sCD44和成骨细胞特异性因子2(OSF-2,骨膜素)。
在一些实施方式中,根据本发明的标志物为疾病特定的。示例性癌症标志物包括但不限于,PSA(总前列腺特异性抗原)、肌酐、前列腺酸性磷酸酶、PSA复合物、前列腺特异性基因-1、CA 12-5、癌胚抗原(CEA)、甲胎蛋白(AFP)、hCG(人绒毛膜促性腺激素)、抑制素、卵巢CAA C1824、CA 27.29、CA15-3、乳腺CAA C1924、Her-2、胰腺CA19-9、癌胚抗原、胰腺CAA、神经元特异性烯醇化酶、血管抑素、DcR3(可溶性诱骗受体3)、内皮抑素、EP-CAM(MK-1)、游离免疫球蛋白轻链κ、游离免疫球蛋白轻链λ、Herstatin、嗜铬粒蛋白A、肾上腺髓质素、整合素、表皮生长因子受体、表皮生长因子受体酪氨酸激酶、肾上腺髓质素原N端20肽、血管内皮生长因子、血管内皮生长因子受体、干细胞因子受体、c-kit/KDR、KDR和中期因子。
示例性传染病标志物的例子包括但不限于病毒血症、菌血症、败血症、PMN弹性蛋白酶、PMN弹性蛋白酶/α1-PI复合物、表面活性蛋白D(SP-D)、HBVc抗原、HBVs抗原、HBVc抗体、HIV抗体、抑制型T细胞抗原、T细胞抗原比、辅助性T细胞抗原、HCV抗体、热原、p24抗原、胞壁酰二肽。
示例性糖尿病标志物包括但不限于C肽、血红素A1c、糖化白蛋白、晚期糖基化终产物(AGE)、1,5–脱水葡萄糖醇、抑胃多肽、胰岛素、葡萄糖、血红蛋白、ANGPTL3和4。
示例性炎症标志物包括但不限于类风湿因子(RF)、肿瘤坏死因子-α(TNF-α)、抗核抗体(ANA)、C-反应蛋白(CRP)、克拉拉细胞蛋白(子宫珠蛋白)。
示例性过敏标志物包括但不限于,总IgE和特异性IgE。
示例性自闭症标志物的例子包括但不限于,铜蓝蛋白、金属硫蛋白、锌、铜、B6、B12、谷胱甘肽、碱性磷酸酶、以及载脂蛋白-碱性磷酸酶的活化。
示例性凝血病症标志物包括但不限于,β-血小板球蛋白、血小板因子4、血管性假性血友病因子。
在一些实施方式中,标志物可以是治疗特定的。COX抑制剂包括但不限于TxB2(Cox-1)、6-酮-PGF-1α(Cox 2)、11-脱氢-TxB-1a(Cox-1)。
本发明的其他标志物包括但不限于,瘦素、瘦素受体和降钙素原、脑S100蛋白、P物质、8-异-PGF-2α。
示例性衰老标志物包括但不限于,神经元特异性烯醇酶、GFAP和S100B。
示例性营养状况标志物包括但不限于,前白蛋白、白蛋白、视黄醇结合蛋白(RBP)、转铁蛋白、酰化刺激蛋白(ASP)、脂联素、刺鼠相关蛋白(AgRP)、血管生成素样蛋白4(ANGPTL4,FIAF)、C-肽、AFABP(脂肪细胞脂肪酸结合蛋白,FABP4)、酰化刺激蛋白(ASP)、EFABP(表皮脂肪酸结合蛋白,FABP5)、肠高血糖素、胰高血糖素、胰高血糖素样肽-1、胰高血糖素样肽-2、饥饿激素、胰岛素、瘦素、瘦素受体、PYY、RELMs、抵抗素和sTfR(可溶性转铁蛋白受体)。
示例性脂代谢标志物包括但不限于(几个)载脂蛋白-脂蛋白、载脂蛋白A1、载脂蛋白-B、载脂蛋白-C-CII、载脂蛋白-D、载脂蛋白-E。
示例性凝血状态标志物包括但不限于,因子I:纤维蛋白原;因子Ⅱ:凝血酶原;因子III:组织因子;因子IV:钙;因子V:促凝血球蛋白原;因子VI;因子VII:转变加速因子前体;因子VIII:抗溶血因子,因子IX:克里斯马斯因子;因子X:斯图尔特-普劳尔因子;因子XI:血浆凝血激酶前质;因子XII:哈格曼因子,因子XIII:纤维蛋白稳定因子;激肽释放酶原;高分子量激肽原;蛋白C;蛋白S;D二聚体;组织纤溶酶原激活剂;纤溶酶原;α2-抗纤溶酶;纤溶酶原激活因子抑制剂1(PAI1)。
示例性单克隆抗体包括EGFR、ErbB2和IGF1R的单克隆抗体。
示例性酪氨酸激酶抑制剂包括但不限于Ab1、Kit、PDGFR、Src、ErbB2、ErbB 4、EGFR、EphB、VEGFR1-4、PDGFRb、FLt3、FGFR、PKC、Met、Tie2、RAF和TrkA。
示例性丝氨酸/苏氨酸激酶抑制剂包括但不限于AKT、Aurora A/B/B、CDK、(泛)CDK、CDK1-2、VEGFR2、PDGFRb、CDK4/6、MEK1-2、mTOR和PKC-β。
GPCR目标包括但不限于组胺受体、血清素受体、血管紧张素受体、肾上腺素受体、毒蕈碱乙酰胆碱受体、GnRH受体、多巴胺受体、前列腺素受体、和ADP受体。
在一个单独的实施方式中,本发明的方法采用了能用于评估治疗剂功效和/或毒性以及药剂对医学状况的作用的药理学参数。出于本发明的目的,“治疗剂”旨在包括具有治疗效用和/或潜力的任何物质。这些物质包括但不限于,生物或化学化合物,例如简单的或复杂的有机或无机分子、肽、蛋白(例如抗体)或多核苷酸(例如反义多核苷酸)。可以合成大量的化合物,例如,如多肽和多核苷酸等多聚物,以及基于各种核心结构的合成有机化合物,并且这些也都包括在术语“治疗剂”中。此外,各种天然来源可提供供筛选的化合物,例如植物或动物提取物等等。应该理解,尽管不是一直明确指出,但药剂可以单独使用或与另一个药剂联用,这具有与发明性筛选所确定的药剂相同或不同的生物学活力。药剂和方法也旨在与其他治疗联用。
方法的实现
可以理解,本发明描述的示例性方法和系统可以用各种形式的硬件、软件、固件、专用处理器或其组合来实现。本发明的方法可以用软件实现为有形地包含在一个或多个程序存储设备上的应用程序。应用程序可以由包含合适体系结构的任何机器、装置或平台来执行。还应该理解,因为附图中描述的一些系统和方法优选用软件来实现,但取决于本发明编程的方式,系统组件(或过程步骤)之间的实际连接可以有差异。给予本发明的教导,相关领域的普通技术人员能够预期或实行这些和类似的本发明的实现或配置。
图9示出了构建用于评估对象的医学状况的模型和系统的处理流程。对象将个人信息输入到数据库中。同一或不同数据库包含来自具有相似医学状况的其他对象的数据。来自其他对象的数据可以是来自公共或私人机构的历史数据。来自其他对象的数据也可以是来自临床研究的内部数据。
对象可用各种方式或使用各种装置来输入数据。例如,可以使用现场护理微流体装置在护理现场获取生物标志物数据。然后将来自装置的数据直接从该装置传递到数据库或处理器。计算机或数据输入系统也可以将对象数据输入到数据库或处理器中。数据可以从另一个计算机或数据输入系统自动获得并且输入到计算机中。将数据输入到数据库的另一个方法是使用例如键盘、触摸屏、轨迹球、或鼠标等输入装置来直接将数据输入到数据库中。
数据库是为了医学状况而开发的,其中相关临床信息是通过通信网络(例如因特网)从一个或多个数据源过滤或挖掘的,数据源例如公共远程数据库、内部远程数据库和本地数据库。公共数据库可包括大众使用的在线免费临床数据源,例如由美国卫生和人类服务部提供的数据库。例如,内部数据库可以是属于特定医院的私有内部数据库,或是提供临床数据的SMS(共享医疗系统)。本地数据库可包括例如与离散临床结果相关的生物标志物数据。本地数据库可包括来自临床试验的数据。它也可包括临床数据,例如温度和实验室信息、EKG结果、血液测试结果、患者调查的回答、或来自住院患者或内部医院检测系统的其他项目。数据库也可包括与至少一个生物学标志物有关系的多个对象成员的历史参考数据。
数据库也可在各种市场有售的创作包来实现。
数据库可在医疗信息系统的存储单元中。
来自数据库的数据可根据具体情况或医学状况或是一组诊断和情况来过滤和分类。例如,数据库中的分类可以遵循标准国际诊断代码(ICD-9编码系统)。医学状况可包括例如对象的身体状态或是对象所患的疾病。
在一个实施方式中,存储在数据库中的数据可以选自下列类别:病理学、解剖学、治疗方案、治疗结果、药理学参数、药物动力学参数、生理参数和基因组信息。
对象数据可与一唯一标识符一起存储以便由处理器或用户来识别。在另一个步骤中,处理器或用户可通过选择用于特定患者数据的至少一个标准来进行对所存储的数据的搜索。然后可以检索特定患者数据。
可以在公共数据库、内部数据库的各元素和对象数据之间建立关系。显式关系声明并且记录了基于轨迹或其他可用观察结果展现的信息所建立的推论。
图9示出了从包括来自对象的数据的数据库到执行如本发明所述的数学方法以构造概率空间的处理器的数据流。对象数据也可以与存储在数据库中的与离散临床结果相关的数据分开输入到处理器中。
处理器可以执行概率空间的计算。一旦准备了概率空间图,同一个处理器或不同处理器可以在概率空间内标绘来自个体对象的生物标志物数据。概率空间图本身可以发送给输出,例如显示监视器。对象数据在概率空间内的位置也可发送给输出。处理器可以带有用于直接从输入装置接收患者数据的装置、用于在存储单元内存储对象数据的装置、以及用于处理数据的装置。处理器还可包括用于接收来自用户或用户界面的指令的装置。处理器还可有存储器,例如随机存取存储器,这是本领域所熟知的。在一个实施方式中,提供了与处理器通信的输出。
用户界面指呈现给用户的图形、文本或声音信息。用户界面也可指用于控制程序或装置的控制序列,例如按键、移动或选择。
用户界面可以是用于显示对象数据和/或对象数据在概率空间内的位置的商用软件应用程序。用户界面通常向用户提供对一组任务特定功能的访问来查看和修改内容。在本发明的优选实施方式中,用户界面是图形用户界面(GUI)。在一些实施方式中,可以用GUI来查看构造的二维概率空间。也可以用GUI来查看定位在概率空间内的对象数据的轨迹。GUI可以在显示监视器上显示。可用于本发明方法的其他用户界面包括但不限于,报警系统、基于web的界面、文本界面、声音界面、批量界面和智能界面。在本发明的一个实施方式中,用户界面可以与系统进行远程通信。
通过在多个时间点获取来自对象的数据,可以处理对象数据的轨迹。对每个时间点,处理器可以计算对象数据时间点在概率空间内的位置。通过连接至少两个时间点的对象数据创建轨迹。可以计算轨迹的不同矢量参数,例如距离、速度、方向和加速度。矢量参数可以由处理器来计算。处理器可以是与用于构造概率空间的处理器相同的或不同的处理器。
根据用户施加的规则,对象数据的位置或轨迹可以激活警报。当对象数据与用户施加的规则冲突时,警报或警报系统通知用户。例如,规则可包括对象发生药物不良反应(ADR)的概率超过60%。当对象数据的概率超过规则时,警报被传递给用户。
警报的例子包括但不限于,声音、光、打印输出、读出、显示、页面、电子邮件、传真警报、电话通信、或其组合。警报可以通知用户原始对象数据、计算出的对象数据在概率空间内的位置、对象数据的轨迹、或其组合。
用户最优选为医务人员。在一个实施方式中,同一用户能访问对象数据,建立用于向用户报警的规则,并且用警报进行报警。用户也可以是对象。例如,糖尿病患者可以监测他的个人葡萄糖水平或是其他生物标志物水平。在另一个实施方式中,用户可以在数学模型的任何步骤访问对象数据。
图10显示了评估对象的医学状况的联网方法。传递信息的系统可以包括或不包括用于读取对象数据的读取器。例如,如果生物标志物数据是从微流体现场护理装置获取的,则分配给不同个体生物标志物的值可以由该装置本身或是一个单独的装置来读取。读取器的另一个示例是扫入已经输入到电子医疗记录或医生图表中的对象数据的系统。读取器的另一个示例可包括电子患者病历数据库,从中可以经由通信网络直接获得对象数据。
用户站可以合并到本发明的方法和系统中。用户站可以用作用于读取对象数据的读取器或是用作数据输入系统。用户站也可用于将数据信息直接传递给如医务人员或对象等用户。用户站平台可以是计算机或是运行任何操作系统的各种硬件平台之一。平台可以从存储单元中读取和向存储元件写入。存储单元可以合并到用户站中。对本领域的普通技术人员而言显而易见的是可以用其他硬件来执行本发明的方法。
根据进一步的实施方式,可以提供服务器来用于评估对象的医学状况。在一些实施方式中,读取器和/或用户站与服务器进行通信。服务器可包括网络接口和处理器。服务器内也可提供存储单元。存储单元可以被耦合来从输入装置、读取器或用户界面接收患者数据并存储患者数据。
存储单元可以是能够长时间存储数据的任何装置,或者作为平台的组件或者作为耦合到网络的独立实体。尽管可以使用任何合适的存储容量,但容量一般为至少10兆字节,并且更常见为至少20吉字节。存储单元可以是永久性的或可移动的。例如,存储单元可以是磁性随机存取,例如软盘或硬盘驱动器;磁性顺序存取,例如磁带;光随机存取,例如CD、DVD或磁性光驱动器;以及固态存储器,例如EPROM、MRAM和闪存。此外,本发明预见了其他存储装置。所有前述的存储单元都是举例,并不旨在限制在本领域中已有或可能有的选择。
在一些实施方式中,在由处理器压缩数据之前对数据进行进一步操作。一些数据非常大,并且压缩可以节省存储空间。在不压缩的情况下,这大量的数据可以呈现出关于医疗信息存储的特定问题。
在用于评估对象的医学状况的系统的其他实施方式中,数据存储、数据处理和控制在与用户站通信的服务器上实现。任选地,数据的计算也可以在服务器上执行。在该客户机-服务器实施方式中,服务器经由用以太网、Wi-Fi、蓝牙、USB或火线实现的局域网(LAN),例如因特网等由宽带电缆、xDSL、T1、城市Wi-Fi或是其他下至普通老式电话服务(POTS)的高速通信实现的广域网(WAN)来通信耦合到一个或多个用户站。
用户站与服务器通信来输出由服务器处理的信息。用户站可以与用于将对象数据输入到系统中的用户站或装置相同或不同。用户站也可以是警报或预警系统。用户站的示例包括但不限于,计算机,PDA,无线电话、以及如iPod等个人装置。用户站可以与打印机或显示监视器进行通信来输出由服务器处理的信息。
在包括服务器的联网系统中,任何数量的装置可以是医疗网络企业的成员并且访问存储在服务器中的中央医疗数据集合。给定的用户站可以访问来自世界任何地方的卫生保健数据源的海量患者数据。在一个应用中,对于确定的临床试验研究累积来自多个从业者的数据。
可以优选地在护理现场向系统的用户提供统计信息。护理现场是实施治疗的地方。有利地,在该特征中捕捉到了因特网使用的动态和实时特性。这使得在办公室或在现场的医务人员或对象能够即刻得到通知并且获得例如对象的医学状况和关于对象数据的统计信息的呈现。
在数据传输前,用户站、警报系统或输出装置可以加密数据。数据也可由处理器加密以保护私人信息。可以使用各种加密方案,例如公钥加密或私钥加密。加密组件可以是独立组件或是软件组件。服务器也可包括用于在存储前解密所接收的对象数据的解密单元。
在一个替代实施方式中,如果用户和服务器之间的通信带宽成为限制(例如,如果服务器“停机”),则该模型可被复制并且存放在用户站处的镜像服务器中。服务器和镜像服务器之间的更新和通信可以在预定时间离线进行。来自用户的在线请求可以由镜像服务器本地地处理。这个替代方案为用户提供了更高的可靠性,因为在线过程不依赖于外部网络。
在数据分析系统的一个替代配置中,当在用户站上执行存储、数据处理和运算时,采用基于客户机的架构。输入装置将数据从源发送到平台。平台通过显示控制器耦合到显示器。显示器可以是多种传统显示装置中的任何一种,例如液晶显示器或视频显示器。平台包含存储单元、处理器和用于与输入装置通信的接口。存储单元具有用于存储、操纵和检索对象数据的数据库。存储单元也可存储和运行操作系统。用户站平台可以是计算机或运行任何操作系统的各种硬件平台之一。平台可以从它的存储单元中读取并且向存储单元写入。对于本领域的普通技术人员而言显而易见的是可以使用其他硬件来执行软件。
在另一个方面,提供了计算机可读指令,这些指令在被执行时使得处理器:提供由一组离散临床结果定义的概率空间,其中每一个临床结果由至少一个生物学标志物的统计分布来表征;获取对应于至少一个生物学标志物的对象数据;并且计算所述对象数据在所述概率空间中的位置,以评估所述对象的医学状况的概率。
计算机可读指令可以是软件包的一部分。软件包可以与本发明的服务器或例如微流体现场护理装置等输入装置一起提供。
在一个实施方式中,计算机可读指令包括用于创建对象数据的两个时间点之间的轨迹的指令。该指令也可使得处理器计算轨迹的矢量参数,例如速度、位置、指向和加速度。
计算机可读指令可指示处理器或输出装置输出对于医学状况的评估。当执行时,该指令可以在监视器上显示图形表示,在打印机上打印输出,或是激活警报或警铃。
在另一个方面,计算机可读指令可以存储在计算机可读介质中。在一些实施方式中,存储指令的计算机可读介质是本发明所述的存储单元。还有其他实施方式可以提供其中存储有多个指令序列的计算机可读介质,这些指令序列当由处理器执行时执行本发明的方法。
当执行时,计算机可读指令能使得处理器提供基于对概率空间内的对象数据的轨迹参数的评估的用户定义的报警条件。在一个实施方式中,轨迹参数是速度、加速度、方向和位置中的至少一个。
如本发明所使用的,“计算机可读介质”指可由计算机或处理器直接读取和访问的任何介质。特征性的计算机可读介质包括但不限于,磁性存储介质、光存储介质、电子存储介质、以及任何这些类别的混合存储介质。
计算机可读指令可以在处理器的软件运行时环境中操作。在一个实施方式中,软件运行时环境提供了软件包所需的常用功能和工具。软件运行时环境的示例包括但不限于,计算机操作系统、虚拟机或分布式操作系统。如本领域普通技术人员所意识到的,存在运行时环境的几个其他示例。
计算机可读介质可以是如本发明所述的本发明的存储单元。本领域的技术人员会意识到,计算机可读介质也可以是能够被服务器、处理器或计算机访问的任何可用介质。
计算机可读介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术来实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括但不限于,RAM、ROM、EPROM、EEPROM、闪存或其他固态存储器技术、CD-ROM、DVD或其他光存储、盒式磁带、磁带、磁盘存储或其他磁性存储装置、或是可用于存储所需信息并且可由计算机访问的任何其他介质。熟练的技术人员可以很容易采用任何目前已知的方法来把信息记录到计算机可读介质上。
计算机可读介质可以作为本发明的基于计算机的系统的一部分来合并,并且可以用于对医学状况进行基于计算机的评估。
健康护理操作系统
本发明的不同方面可用于并且开发健康护理系统。这样的系统的示例包括现场护理系统、健康护理操作系统或两者的组合。例如,用户可以用装置测试血样,并且将来自测试的信息提供给本发明的系统或方法,后者进而将附加信息发送给用户。
在一个实施方式中,健康护理系统是构建在实时现场护理血液监测装置附近的整合基础架构的一部分,该基础架构以与中央实验室进行的手动过程的自动化复制相类似的方式来分析约10微升样品。在整合基础架构中,信息可以从化验装置无线地发送到数据库,该数据库将来自装置的数据与来自不同的数据库的所存储的数据(患者病历、遗传或基因组信息、来自临床试验的数据)整合到中央数据库中。然后系统可以在给定病症的病理生理的情况下自动将数学方法应用于数据库。例如,可以使用健康护理系统来通过适应性临床研究快速改善核心药物的标签,这可以产生对于新的适应症、患者亚群以及用于改善安全问题的标签扩展的公示。
在本发明的一个实施方式中,健康护理系统可以用于家庭实时血液检测具有重要的意义,这使得我们可以收集到不能用传统血液测试基础架构获得的信息。
图11示出了本发明的系统的一个示例性实施方式。可以使用现场护理装置实时获取对象数据。现场护理装置可以获取、存储和/或管理基于特定疾病或化合物的信息。现场护理装置也可与用户或属于用户的计算机或系统进行通信。该示例中的现场护理环境可以在家里或是诊所。图11中也示出了从现场护理装置向服务器或系统实时发送信息,该服务器或系统能将信息或数据转换为生理相关上下文。这可以通过将信息传递给一个数据库或多个数据库来实现。数据库可以在一个服务器或多个服务器上。在一个实施方式中,使用集中式数据库存储库来分析数据并且在生理相关上下文中将数据返回给最终用户。可以将数据,以及在图11的示例中的诸如临床相关和可执行信息等的信息通过基于浏览器的软件应用程序来返回给用户。如果最终用户是医学研究人员或制药公司,则信息可用于适应性临床试验和公布。
包含与健康护理系统通信的现场护理装置的本发明的系统可以不需要样品传递,例如运送到实验室,而这可以提高样品的完整性。在本发明的系统或方法中对分析物的监测可以在护理现场实时提供。与健康护理中央数据库系统整合的实时检测可以创建由免疫测定装置获取的复杂纵向数据系列。
图12显示了本发明的一个示例性系统,其中健康护理操作系统包含数据基础架构、模型和算法、以及软件应用程序。该数据基础架构可以由制药公司在整个制药渠道中用于临床试验。健康护理操作系统的模型或算法可包括,例如预测性且动态的、多元、多维模型,该模型能够为了程序特定目的而进行定制,并且能够图示疾病进展和衰退。系统可以与后端算法、模型和数据基础架构中的数据整合。例如,系统可以在装置触摸屏或移动电话上向用户传送个性化内容。反馈可以帮助进行行为修改并且提高治疗的顺应性。本发明所述的算法能够将血液数据与功效动态分布图、行为、生活方式、饮食和副作用相关。
内容可基于患者类的数据,其识别生理和心理的易患病体质以及当地社会环境的影响。在另一个实施方式中,系统可以通过社交网络来链接用户,其中成功的示例通过每个定制的家用保健系统与给定治疗的组合而增加。
医疗操作系统可以在护理现场与例如化验盒、化验读取装置或诸如蜂窝电话等移动装置等的消费者系统交互。现场单元可以与现场护理家用和移动监测系统相整合。现场单元可以是远程、便携式患者护理系统,并且能够提供对化验盒的现场、实时、自动处理来进行血液分析。在一些情况下,现场单元包含允许患者发起化验并且图形地输入诸如患者日常、环境、行为和心理信息等各种相关信息的用户界面,以及从仪器到医务人员或移动电话并且以相关内容、消息和健康信息返回到患者的双向通信系统。在一些情况下,血液和环境数据被实时自动地(例如无线地)发送到模型中。
如本发明所述,健康护理操作系统可包括信息整合和开发基础架构,该基础架构能允许例如但不限于,对现场护理结果的实时数据获取和存储,将血液参数和患者日常数据与其他生理相关信息的整合,以及中央数学软件程序。中央数学软件程序可以图形地可视化,帮助解释并分析一个地方的所有数据,并且将任何新信息链接到疾病管理系统,该疾病管理系统然后将信息映射到临床结果的概率空间上。健康护理操作系统或现场单元可以将临床相关且可执行信息的图形显示提供回给健康护理提供者和/或患者或用户。
本发明的医疗系统的可能的应用包括但不限于,到适应性临床试验或健康护理管理系统的整合链接、用于诊断后监测的药物和系统的组合、健康护理操作系统(例如服务器控制的现场护理全血监测系统)、以及在临床研究中对与关键化合物功效的相关的标识。
在一个实施方式中,系统可向用户提供可用数据集的整合的图形描绘。
在另一个实施方式中,本发明的系统可产生能在今后研究中用作历史数据的数据。系统可以根据用户的需求来定制,例如从制药公司的现有数据库提取相关数据,中央数学软件系统能让制药公司在一个地方可视地看到、解释并且分析其所有数据并且链接到临床试验系统
当与药物的临床试验一起使用时,本发明的系统可提供对化合物功效、疾病进展和患者应答的理解,这是不可能用传统血液测试基础架构获得的。
数据库和健康护理系统可以被定制成监测随时间的趋势蛋白化验以及它们与不同适应症的疾病进展的关系,同时考虑了疾病的病理生理学中的其他相关变量或生物标志物。定制可被设计成自动合并所有相关数据,用于对在相关适应症中的疾病进展绘图,并且是历史数据的基础。可以在设计将来的研究时且在将来的研究中使用该图和基线,以便从血液测试结果中提取更好的信息并提供对不同适应症上的功效的早期读取。
图13显示了包含与几种医学状况相关的生物标志物的本体的示例性数据库。例如,作为一种疾病,败血症被归类为病理生理学,并且在这个本体上链接到急性肝衰竭(ALF)、弥漫性血管内凝血(DIC)等等。这些病理中的每一个都可以在这个本体的上下文中被视为败血症的后遗症。在这个示例中,用于治疗败血症的药物为CytoFab。在一些情况下,后遗症由生物标志物的图谱来表征,如图13所述。例如,ALF由ALT、AST、GGT和碱性磷酸酶的特定模式来表征。
在本发明的一个方面,本发明公开的方法、装置和系统可包括健康护理操作系统。健康护理操作系统可包括中央控制系统,用于向客户传递护理并且用于付款人和收款人的经济模型。
在一个实施方式中,健康护理操作系统可提供可能监测疾病发生的早期系统。系统还可包括学习引擎,该学习引擎根据药物可利用度、靶向应答速率或付款结构来与用户或保险供应商的偏好联系起来。
本发明的计算机系统或服务器可包括动态学习引擎,例如,在系统或服务器接收数据时,可以更新系统或服务器的操作。系统或服务器也可访问竖井型数据库、在中央数据储存库中提取和本地(永久或临时)存储信息。
在另一个实施方式中,健康护理系统可包括通信门户,以供用户将例如体重、尼古丁消耗、食物消耗、锻炼和精神科变量等信息数组传递到系统。
图14示出了本发明的健康护理操作系统的示例性分层结构。中央操作系统能够访问数据基础架构和监测装置以获得对象数据。如图14中的示例所示,该数据基础架构可包括搜索工具、通信链路、数据分析以及应用程序。例如,通信链路可与客户、临床医生或HMO进行通信。临床医生可以使用信息来使他的决策制定更为简化和有效,或是用作数据/知识库背景。例如,HMO可例如接收临床试验的信息,例如药物功效和使用药物的成本。如图14所示在数据基础架构中的信息分析可包括产生轨迹、模糊逻辑指引、协作式过滤预测、疾病图和数据报告,用于临床试验或新药开发。数据基础架构的应用的示例包括(公共的或私人的)报告、警报(例如向用户、临床医生、临床测试或药房报警)、以及动态的可调整试验。
图14也显示了由示例性操作系统从监测装置接收的信息的分层结构。如果需要,装置或操作系统可以监测和释放药物。在一个优选实施方式中,装置监测体液中的分析物。例如,当监测血液时,该装置能够执行用于临床或预防性设置的血液测试,或是评估所示药物系统。
在一个方面,公开了一种系统请求来自用户或其代理人(例如医生)的输入以促进对象及其代理人之间关于一个时间点的个人健康状态的对话的系统。可由系统请求的输入的示例包括但不限于,建立报警水平、医学标注和个人标注。该系统可获取关于个人的临床相关信息,并且将信息放置在生理上合理的上下文中。临床相关信息的示例包括但不限于,年龄、性别、种族、病史和基因组信息。
在一个实施方式中,时间依赖数据可以代表整体临床健康或应答,包括需要监测的所诊断的疾病状况、对于特定药物或药物组合的应答分布图、或是对象观察到的他的健康观察资料。
计算或是观察到的信息可被提供给用户。用户的示例包括但不限于,患者、医生、临床试验的临床监测者、以及其他医务人员。
信息也可被整合到中央储存库中,以便例如包括在医疗记录或临床测试报告中。
图15显示了本发明的一个示例性系统,其中分析数据库可接收来自一个数据库的信息,该数据库包含来自读取器或盒数据库、历史数据库、能包含由患者输入的数据的患者数据库、以及客户数据库的数据。本发明的系统的其它特征显示在图15中。该系统能够对系统接收的数据进行分析。分析可以是本发明所述的任何方法,并且可包括开发或使用疾病图,使用统计学对系统内的信息进行统计分析,报告或图表,和/或所述不同方法的组合。
图15还示出了能用于本发明系统的用户界面。该用户界面能与图15中所示的任何组件交互。在一个优选实施方式中,该用户界面允许用户与系统交互来确定测试数据或分析结果,例如生理相关信息。该用户界面可以是触摸屏、监视器、键盘、鼠标、或允许用户与本发明的系统交互的任何其他物品,这对本领域的技术人员是显而易见的。
如图15所示,系统可用于管理读取器或现场护理装置。这可以包括对要插入到读取器中来测量数据的盒的管理。例如,该系统可以向读取器提供用于运行盒的免疫测定的协议。本发明的系统也可将信息给读取器,以校正盒上运行的由读取器来运行或执行免疫测定。读取器管理也可包括用于分配用于合适额读取系统的读取器以便从现场护理盒读取免疫测定的信息。读取器管理也可包括纠正性和预防性措施(CAPA),这是综合且全面的依从管理的工具。CAPA方法的一个要素是对品质缺陷、差错和故障的有效且系统化的处理,其目的在于提供合适的纠正性行为并且持续预防再次发生不依从的情况。CAPA策略是由食品和药品管理局(FDA)为了检查医疗产品而开发的。
本发明所述的系统和方法可用于药物临床试验。在一些情况下,该系统和方法使测试时间表加快了平均18个月。在一些情况下,本发明的系统或方法可在不到18个月、不到15个月、不到12个月、不到10个月、不到9个月或甚至不到6个月中,提供剂量应答和功效动态分布图。实时药物动力学和药效学可提供更好的功效和更多的安全信息。本发明的方法也可降低毒性的风险,通过在亚群、附随药物和多种适应症上改变剂量来放缓审核或限制使用。在其他情况下,本发明的系统或方法可以改善对于途径动力学的预测可见性。所述模型可产生预测观点和有力的战略决策。系统可以支持与监管部门的国际交流,并且促进对适应性临床试验战略的“学习和确认”。
本发明的系统可包括数据管理系统。该数据管理系统可以由多个装置或系统,或由单个中央服务器来操作。图15示出了本发明的系统的数据管理的一个示例。数据管理系统可接收来自例如现场护理读取器、数据库(例如分析数据库或历史数据库)和终端(例如用户界面)的输入和输出。数据管理系统也可进行存储管理,例如患者个人数据的存储或关于特定疾病或药物资料的信息的存储。例如,如果使用本发明的系统和/或方法来进行对实验药物的临床试验,则数据管理和存储管理系统可从现场护理的读取器接收数据,然后把信息存储在数据库中以便分析该数据。然后,患者数据和分析数据都可被存储以供系统的进一步使用。例如,如果在I期临床试验的患者注意到一个副作用,则该副作用信息可用于分析III期临床试验中患者的结果。作为另一个示例,糖尿病患者可在一个较早的时间接收葡萄糖测定,该测定然后可用于在另一次测定后的一个较晚的时间评估个体的状况。
示例1
前列腺癌和抗血管生成治疗
在用抗血管生成药物治疗诊断为前列腺癌的对象的I期和IIa期临床试验中,可以在试验过程中调整剂量。在临床研究中随着时间进程监测对象。抗血管生成药物作用的方法是使肿瘤内和周围的血管停止生长,从而剥夺肿瘤的充足血液供应。这会诱导肿瘤缺血和营养性坏死,从而使肿瘤减小。
在确定了作用的方法后,例如医生或临床监控者等医务人员选择离散临床结果。在这个示例中选择的离散临床结果是完全应答(CR)、部分应答(PR)、无应答(NR)和药物不良反应(ADR)。在该示例中,与抗血管生成药物相关的ADR为高血压脑病。
选择代表患有前列腺癌的对象的临床结果的六个生物标志物来定义离散临床结果。这些生物标志物为PSA、TPS、hK2、VCAM-1、内皮素-1和6-酮-PGF-1-α。采用这些生物标志物和在用抗血管生成药物治疗前列腺癌的进展中的对应历史数据以及来自临床试验中的其他对象的数据,执行聚类分析。每个离散临床结果被分配到一个聚类的质心。
在对象用药物治疗之前,根据来自相关生物标志物的对象数据,向对象分配概率空间内的一个位置。用马氏距离来确定对象属于任何离散临床结果类的概率,从中使用贝叶斯估计来计算概率。这个计算的结果返回了对应于该示例的4个临床结果的4个概率。通过在概率空间内标绘这4个概率确定对象的位置。
对应于四个临床结果的概率空间被图形地显示为一个二维的正方形。该模型的用户,在该示例中为医务人员,根据对象数据在概率空间中的位置和/或轨迹建立关于对象的医学状况的规则。每个离散临床结果有一条代表由医务人员建立的规则的现,如图16中的虚线所示。当对象穿过指向CR或PR状况的点状线时,对象基本没有ADR,并且改善了他/她的预后。
在图16中,标绘两个不同对象的轨迹。对象1具有从概率空间的中间开始然后指向ADR状况的轨迹。在该示例中,医务人员可以注意到该轨迹的速度或加速度以及治疗中的干预。当对象1的轨迹穿过指向ADR状况的点状线时,激活警报。医务人员相应地作出反应。
对象2具有指向NR状况的轨迹。抗血管生成药物的剂量可以对应于由医务人员建立的规则来进行调节。在剂量调整后,轨迹指向变为指向PR状况。该示例示出了用于监测临床试验的本发明的方法和实施方式。
示例2
败血症和抗-TNF治疗
在IIb期(允许调整剂量)或III期(不允许调整剂量)临床试验过程中,对确诊或疑似具有败血症或全身炎症反应综合征的对象用抗-TNF疗法进行治疗。在临床研究的过程中随时间对对象进行监测。抗-TNF药物作用的方法是抗炎症。药物用于预防或限制下游的败血症后遗症。通常,抗-TNF药物是与广谱抗生素联合给予的。
当确定了作用方法后,由医生来选择离散临床结果。在该示例中所选的离散临床结果为应答(R)、无应答(NR)和四个后遗症(弥漫性血管内凝血(DIC)、急性呼吸窘迫综合征(ARDS)、急性肝衰竭(ALF)和急性肾衰竭(ARF))。
选择代表确诊或疑似为败血症的对象的医学状况的二十个生物标志物来定义离散临床结果。在该示例中,生物标志物落入多个分类,以监测由医生定义的不同的离散临床结果。脂蛋白结合蛋白(LBP)生物标志物测定感染发展以及R和NR状况。LBP生物标志物为LBP、TNF、CRP、IL-6和IL-8。与DIC状况相关的生物标志物有血管假性血友病因子、蛋白C、凝血酶、降钙素原、新喋呤和PAF-1。ARDS状况的生物标志物为血管假性血友病因子、IL-6、IL-8、IL-1和TNF。ALF状况的生物标志物为ALT、AST、GGT、LDH、碱性磷酸酶、胆红素和蛋白C。ARF状况的生物标志物为肌酐和胱氨酸C。
使用本示例中所述的生物标志物和关于败血症的进展和用抗-TNF疗法进行败血症治疗的对应历史数据、以及来自临床试验中的其他对象的数据,执行聚类分析。每个离散临床结果可以被分配到一个聚类的质心。
在用药物治疗对象前,根据来自二十个生物标志物的对象数据,向对象分配概率空间中的一个位置。用马氏距离来确定对象属于任何离散临床结果类的概率,从中使用贝叶斯估计来计算概率。该计算的结果返回对应于该示例的6个临床结果的6个概率。通过在概率空间内标绘这6个概率来确定对象的位置。
对应于6个离散临床结果的概率空间被图形地显示为一个二维的六边形。医生建立了追踪无应答对象和可能发生的后遗症的规则。该规则在六边形图上被标绘为线,如图17中所示。对象的医学状况是基于对象数据在概率空间内的位置和/或轨迹。
在图17中,标绘两个不同对象的轨迹。对象1具有从成为DIC状况的成员的高概率开始的轨迹。然而,随着采用后续时间点,该对象轨迹从DIC状况移开,并且指向NR状况。当医生注意到T=6时轨迹的速度和指向时,他提高了剂量。在T=9时,该对象在概率空间内的位置具有成为R状况的一部分的高概率。医生沿着对象的轨迹在任何时间点评估对象的医学状况。
对象2具有从概率空间的中间开始并且在T=1时指向NR状况的轨迹。然而,在T=2时,对象的位置和轨迹违背了由医生建立的规则,并且可以听到警报。该警报提醒医生对象有很高的概率患有败血症的危险临床结果之一。
示例3
糖尿病和胰岛素增敏
非胰岛素依赖的II型糖尿病对象用市售的胰岛素增敏剂进行治疗,并且监测其功效和安全性,其中考虑的主要ADR为充血性心力衰竭(CHF)。在临床研究的时间进程中监测对象。胰岛素增敏剂作用的方法涉及通过脂肪组织和肝脏中的核受体的对抗作用重新建立对象中的胰岛素敏感性。胰岛素增敏剂和作用方法提高外周组织中葡萄糖的吸收,且因而降低血糖循环。
对象和医生选择基于个人信息一组最佳的离散临床结果以及用于对象的规则。离散临床结果为应答(R)、无应答(NR)、和药物不良反应(ADR)。ADR为充血性心力衰竭。
在选择了三个临床结果后,通过判定分析确定最能代表对象的医学状况的生物标志物。代表胰岛素增敏治疗的功效的生物标志物为葡萄糖、胰岛素、脂联素和抵抗素。充血性心力衰竭的ADR将代表性生物标志物标识为脑利钠肽(BNP)、氨基端原BNP(N-BNP)、心房利钠因子(ANF)、IL-1β、肌钙蛋白-C、心脏脂肪酸结合蛋白、肌球蛋白轻链-1、肌红蛋白、MMP-9。采用这些生物标志物和关于II型糖尿病的对应历史数据,执行聚类分析。每个离散临床结果被分配给聚类之一的质心。
在对象用胰岛素增敏剂来治疗前,根据来自相关生物标志物的对象数据,向对象分配概率空间内的一个位置。用马氏距离来确定对象属于任何离散临床结果类的概率,从中采用贝叶斯估计来计算概率。该计算的结果返回对应于该示例的3个临床结果的3个概率。通过在概率空间内标绘这3个概率来确定对象的位置。
对应于3个临床结果的概率空间被图形显示为一个二维三角形。医生和对象建立对于个体糖尿病对象最重要的规则。规则是追踪NR和ADR状况。当属于ADR状况类的概率升高超过由规则定义的界限时,触发了警报。当对象有高概率发生NR时,根据规则提高剂量。
在图18中,标绘两个不同对象的轨迹。对象1具有从概率空间的中间开始然后指向ADR状况的概率。在该示例中,对象可注意到轨迹的速度或加速度,并且询问医生是否需要改变治疗。当对象1的轨迹穿过指向ADR状况的点状线时,触发警报。对象可以通过去医院来做出反应。
对象2具有指向NR状况的轨迹。可以根据由医生和患者建立的规则来调节胰岛素增敏剂的剂量。在调节剂量后,轨迹方向改变为指向R状况。该示例示出了本发明的用于监测使用商用胰岛素增敏剂的糖尿病对象并且在医生的帮助下在家监测对象自己的状况的方法。
示例4
对象的临床结果的图形表示
本示例显示了一种将来自数学模型的结果传递给用户的方法。该方法是在由多边形界定的空间内标绘一系列的点和矢量。多边形的顶点代表离散临床结果的聚类的质心。点的位置代表对象数据属于每个质心的概率。点属于离散临床结果的概率与该点离顶点的距离成反比。由于顶点代表了所有重要临床结果,因此对于给定点的概率的总和必须为1。
创建一组矢量,其中矢量的每个值代表成为每一个聚类的成员的概率。值的模数(大小)为概率,并且矢量的辐角(角度)指向顶点,其为等距的。把矢量相加,且所得的点位于综合概率空间内。
表1
例如,在表1中,每行代表一个点的位置。在顶部标注的列代表了该点是那个聚类的成员的概率。所以,在第一行中,点在聚类“R”中的概率为20%,且该点在聚类“NR”中的概率也为20%,并且以此类推。
对于表中的数据,如图19中所示,创建一个图形表示。我们看到周围的多边形有5个顶点,每一顶点被标注为上述表格数据中的列之一。在箭头链的尾部,数据集的第一个点位于图的中心,表明该点在任何聚类中的百分比概率与在其他聚类中的概率是相同的。在该示例中,随着轨迹随时间而增长,对象数据的概率达到终点,终点有100%的机会在聚类“R”中,有0%的机会在其他地方。相应地,终点在“R”顶点处。
其他信息可以包含在概率空间的输出中,包括代表由聚类和质心定义的离散临床结果的数据的点。图20示出了聚类数据点的图形表示。
示例5
药物开发是一个极度冒险的命题。在过去10年中,临床项目的失败率高达90%,每个被批准的药物的摊销成本接近10亿美金。这些失败可由于任何因素。这些因素包括但不限于,关于靶标在疾病发展和病理生理上的作用的错误假设;在不合适的、且不具有预测性的动物模型上对这一假设的测试;关于化合物MOA的错误假设;对目标亚群内的个体的不合适的给药方案,包括不合适的药物动力学/药效学(PK/PD)特征;以及在患者群的一些部分中产生不良生理反应(例如,药物不良反应-ADR),从而降低了化合物在该人群中的治疗指数。
本示例显示了在特定的治疗区域中使用一个化合物的1型生物标志物,来(a)验证关于测试化合物的作用方法的基本假设;(b)在确定性测试中标识并且然后充实合适的应答亚群;以及(c)基于应答人群的个体PK和PD开发真正的适应性给药方法。
用实时监测系统来更早而不是较晚地标识这些特征亚群的发病,从而高效地管理和控制临床试验,并且让临床研究团队能够对试验管理做出精确的决策。在一个患者接一个患者的基础上,它动态标识该化合物对一个特定试验对象的效果,然后物理滴定该患者的给药方案来提供药物开发的真正的适应性“学习和确认”模型。
对每个患者进行蛋白纵向取样,其中蛋白代表疾病的病理生理和化合物的作用方法。在纵向取样空间内的每个样品时间点应用标准的聚类分析,该取样空间与疾病的病理生理的进展动力学、以及假设的作用方法和测试化合物的PD相一致。
对测试样本人群中的独立亚群的发病率的动力学的标识可以用两个互补的聚类统计量来执行:立方聚类准则(CCC)和伪F,这帮助最终用户确立几何结构内形成的聚类的数量,如图21中所示。
最终用户采用上面强调的两种统计量和聚类散点图的目视检查,来做出关于在临床研究中存在多少离散亚群的最终确定。引导这一决定的将是治疗(组)分支的数量的在前知识,以及关于可能的ADR的特性的任何在前知识。该方法将向最终用户建议多种聚类,并且然后向每个患者呈现他/她的聚类分配。然后,聚类分配和患者到治疗组或ADR结果的已知分配采用标准分配统计量来计算分配规则的敏感性和特异性。
在确定聚类是相当特异的以后,表征每个聚类的质心的动态轨迹、它们的分离速度、以及在每个聚类中每个患者的速度和方向的分布。例如,如果一个患者聚类是相当均一的,因为他们都接触了给定剂量的化合物,并且如果距离、速度和方向的分布提示一些可能是缓慢应答者,则最终用户可以决定那些患者应该接收更高的剂量。
根据本发明提出的假设,为每个假设患者亚类创建虚拟患者的电脑模拟人群。运行时间依赖蒙特卡洛模拟来标识出现的聚类。在运行模拟后,建立一组新的平均矢量和协方差结构,并且重复模拟研究。测量每一个动力学的聚类分配规则的灵敏性和特异性,并且将其图形地标绘为受试者工作特性曲线,其中诊断变量将是提示聚类的时间。
该示例中描述了所述方法的蒙特卡罗模拟的发生动力学的结果,并且后来发生的动力学的结果如图21所示。图21显示了根据两队列临床设计的蒙特卡罗模拟的聚类分析的动态亚群发病。在时间=4时,明显出现两个聚类,而在时间=8时,分歧是完全的并且该方法的灵敏度和特异性都是100%。图22显示了在时间=4时聚类调用统计量对聚类的假设数量的曲线图。图23示出了分离标志物空间的临床效果的标志物,其是临床研究的终点的剂量的函数。
示例6
对指示周期性给药方案的1类生物标志物的标识
周期性给药作为一种治疗策略,是治疗许多慢性疾病或状况的主要方法。其中最重要的是抗癌化疗方案和自身免疫疾病治疗。无论是治疗上还是在适应性临床试验的情况下,监测和表征特定给药方案在任何给定患者中的功效和毒性分布图的能力向临床专业人员提供关于他/她的给药策略的最终功效的重要信息。这样的反馈机制的好处在于,反馈是及时的,并且代表了化合物的作用机制和临床效果。例如,在癌症化疗中,通过成像技术提供反馈,该技术帮助量化肿瘤的量,这在许多情况下不是及时的。
该示例表征了分子功效测量的周期性,来标识临床相关度的趋势和其他测量(例如,增加不应响应)来进一步帮助临床决策制定。如本发明所示,实时反馈监测系统可说明给药方案的周期性,并且表征数据中的任何临床趋势。
该系统可以在统计上是有效并且稳健的方法,其动态地表征了在周期性治疗的患者亚群中药物活力的分子标志物的时间依赖分布图,然后使用那些信息作为优化治疗方案的实时反馈监测器。
所治疗的人群的蛋白分布图按照的关于化合物作用机制的潜在假设来发挥作用,他们应该以聚集的模式反映治疗方案的周期性,并且作为一个整体,作为化合物活力的I型生物标志物在作用位点发挥作用。此外,如果有证据表明这些分布图蛋白的周期性表达随着时间发生变化,则该变化的趋势能让临床医生调整给药方案,例如频率和/或剂量,使得治疗个性化。
对于纵向(在个体患者中)蛋白分布图应用基于时间系列的统计方法系统性地说明了给定给药方案在个体患者中的周期性,并且采用该信息来标识和表征应答中的任何临床相关趋势的出现。然后这一认知可用于监测个体患者中的治疗方案,并设计和管理适应性临床试验的动力学。
通过在周期性给药方案的情况下开发化合物活力的有效纵向I型生物标志物,可以:(a)验证关于测试化合物的作用方法的潜在假设;(b)标识潜在相关的临床状况,包括:化合物的顽固性提高,对于方案的靶向应答,并且然后对治疗本身的频率或剂量进行合适的调节;以及(c)基于应答人群的个体PD开发适应性给药协议。
采用实时监测和反馈来标识这些特征动力学的发生帮助临床医生作出对于患者治疗和/或试验管理的更为精确的决策。
使用统计时间系列分析来表征在接受周期性治疗的患者中的标志物蛋白的周期性或季节性,该周期性治疗类似于癌症化疗中所采用的每周甲氨蝶呤注射。对于数据列的季节性的系统调节如图24中所示,并且根据需要进行应答的去趋势化,如应用于自回归综合移动平均(ARIMA)模型的一个或两个滞后差异方案,来表征患者对于治疗的实际应答分布图。图24显示了表明2个I型生物标志物随时间的季节性的患者数据。如果两个或多个蛋白标志物被标识为标志物,则他们之间的任何时间关系(例如但不限于,血液中和/或临床读数中药物的水平)可以用同一建模上下文中的分布滞后分析来标识和表征。每个分析取决于在时间系列中观察到的时间-时间相关性的显式特征、自相关函数(ACF)及其相关的部分自相关函数(PACF))。这些函数中的每一个可用一个相关矢量来表示,其功能上依赖于测量之间的滞后。函数可用于标识数据中的线性趋势、数据中的周期性、以及数据中的非线性曲率动态。函数本身可以使用称为相关图的直方图来可视化以便进行检查。一旦数据被去趋势化并且考虑到周期性,则分析标志物分布图中的独立尖峰,来看化合物是否如所预期的发挥作用。
开发这一方法中涉及的第一步是标识那些最能代表疾病的病理生理学和化合物的假设的作用方法的蛋白。一旦建立,在每个患者中对这些蛋白进行纵向取样。
根据治疗方案预期的季节性和治疗剂量的频率,建立合适的取样频率,以确保标志物蛋白的可能的周期性表达将在样品数据集中捕捉到。
该系统自动地产生并检查带有0、1或2个滞后差异的差异时间系列,包括ARIMA(0,0,0)、ARIMA(0,1,0)和ARIMA(0,2,0)模型,并且通过均方根误差将他们与最佳拟合比较,从而对数据合适地去趋势化,使得该系列固定。一旦已经建立了固定系列,包含线性趋势线的斜率的去趋势化参数可以从数据中估计,并且产生对于固定系列的ACF和PACF。
任何周期性表达模式被标识并表征为峰的周期以及他们的后续振幅。这样的一个示例如图25所示,其显示了生物标志物值的时间系列对化学治疗递送时间的关系。
当涉及包括两个或多个蛋白标志物和/或化合物在血中的水平的多个时间系列时,执行分布式滞后分析来标识并表征该系列和它们的滞后之间的相关。该方法标识了蛋白标志物波列的出现的动力学,并且将这些与临床相关事件和/或方案的给药日程联系起来。
如上所述采用4个时间系列的蒙特卡洛模拟方法是使用一个固定时间系列、一个带有线性上升斜率的时间系列、一个带有指数降低效果以便模拟患者的药物衰减的时间系列、以及一个带有线性降低峰的固定时间系列来产生的,以便对患者的药物适应或代谢通路的上调进行建模。
示例7
从对循环热原和其他生物标志物水平的时间系列测量判断达到发热高峰和败血症的时间
采用本发明所述的方法和系统,对住院化疗的患有急性髓系白血病(AML)的患者进行监测,每4-8小时采集血样。也经常监测患者的体温。发现在表2内定为0的时间点IL-6升高(连续测量间升高>1000倍),且在14小时后连续测量之间显著下降>30%。在8小时后首次发现发烧。本发明的方法预期可以按8小时对败血症进行后续识别。
表2
该系统标识在引起发热的白血病攻击性化疗期间到达发热高峰的时间与急剧变化的循环热原(蛋白C、IL-6、IL-1β、TNF-α、IL-10)水平之间的关系。这是通过采用标准统计建模方法来执行的。该系统可以推广到发生败血症的其他情况。这也可用于可以有益地反映重大疾病过程和治疗结果的其他情况。
科学和工程通常涉及采用容易测量的变量称为因子或自变量因子,来解释或预测其他变量的行为,称为应答。当因子数量很少、没有明显冗余(非共线)并且与应答有明确的函数关系时,可以利用多元线性回归来表征这一关系。然而,如果这三个先决条件中的任一个没有满足,则多元线性回归可能被证明是低效的或是在统计上不适当的。在这种情况下,可以采用一个称为偏最小二乘回归的替代模型构建策略。该方法尤其适用于当有很多可能高度共线性的因子的时候,以及当自变量因子和因变量应答之间的关系是不明确的时候。这种类型的分析的目的是构造一个良好的预测模型。
预测到达发热高峰的时间基于采用数个循环热原水平的统计模型。图26显示了从随时间测得的循环热原水平中计算的参数和/或到达高峰的时间(也标注为前导时间)之间的关系。参数随时间的变化率和形状是由发生率、感染时间、感染程度、生物体数量、生物体的致病力、以及患者的医学状况和遗传构成来确定的。激活阈值是身体生理上开始产生发热高峰的点。检测阈值是其下指示一些治疗干预的参数水平。该系统确定热原水平和模型中的因变量(前导时间)之间的关系,从而能够足够早地预测发热高峰,使得干预获得有益的结果。
此方法和数据能够提供对与患者最可能经历发热高峰的时间的预测。然后医生可以预先支配和/或改善发烧事件的发生,例如通过提供预防性的抗生素治疗。
对于急性髓系白血病(AML)患者的治疗用作一个范例。这类患者通常采用诱导化疗(住院化疗通常采用一种以上的药物并且打算消除所有的癌症细胞)进行治疗。诱导化疗的有害副作用通常为发热性中性粒细胞减少。这是由于化疗使得主动免疫失活,感染性微生物可以侵入患者。发热性中性粒细胞减少的定义为发热高峰,为患者体温测量超过39摄氏度或是在6小时内患者两次连续体温测量超过38.5摄氏度的一种临床医生确定的状态。
发烧作为一种防御机制,是由称为热原的循环细胞因子对下丘脑施压所引起的。这些细胞因子在炎症反应中从免疫系统产生。最熟知的细胞因子有IL-6、IL-1β和TNF-α。该示例的目的在于标识导致发热高峰的循环热原模式,并且从中构建能够最好地预测到达高峰的时间的模型。
在研究中开发的方法可以推广到产生用于其他高危疾病状态和治疗程序中的监测手段。
本系统构建了一个统计学模型,该模型表征到达高峰的时间和两个特定热原(IL-6和IL-1β)的循环水平之间的关系。本系统尽管独立于测量装置,但需要在达到发烧高峰前的时期内频繁取样(每天3-6次测量中的任一种)。
开发该方法时涉及的第一步需要明确的类别中的一种发烧表征,并且尽可能接近地标识最初发烧事件的时间。所选的定义为患者体温测量值超过39摄氏度或是在6小时内两次连续体温记录超过38.5摄氏度。
根据取样间隔,IL-6、IL-1β和TNF-α以及其他生物标志物的循环水平的独立患者数据被记录在数据库中。研究中的样品(以8小时为单位每天3次测量)进行事后分析,并且用于填充模型。
这些标志物是基于大量的当前研究来选择的,研究表明,当与没有败血症的重症患者以及正常对照相比时,败血症患者的循环IL-1β、IL-6和TNF-α水平升高(Casey,L.Annals of Internal Medicine(1993)119;8:771-778)。
IL-6主要调控在急性期反应中由肝细胞(肝)制造的CRP的合成。CRP的转录也受到TNF和IL-1的略微调控。CRP是一种穿透素蛋白,其在细菌细胞壁、内源细胞膜和凋亡体上与胆碱磷酸结合。由感染/败血症、炎性和自身免疫疾病、外伤和一些恶性肿瘤引起的炎症中,观察到CRP量上升,使其成为监测败血症和感染时有用的生物标志物。CRP产生不受到中性粒细胞减少的影响。有大量的文献关注于在中性粒细胞减少的发烧以及诊断发热性中性粒细胞减少的严重程度中CRP的水平。
蛋白C是在肝中合成的抗凝血蛋白。它在维持凝血动态平衡中发挥重要的作用。蛋白C被凝血酶激活成活性蛋白,与蛋白S和磷脂一起作为辅助因子,它切割凝血因子VIII和V,从而抑制凝血。最近,已经发现了蛋白C的抗炎症反应。
败血症和感染性休克患者具有蛋白C损耗,其可在败血症的病理生理中发挥作用。通过加入活化的蛋白C来抵消蛋白C损耗,可以在特定的患者亚群中看到改善。蛋白C可用作患者败血症诊断的生物标志物,以及作为治疗剂。一项研究发现,蛋白C浓度与在发烧开始时的中性粒细胞减少败血症的严重程度成比例。
招募10个接受化疗的成年白血病患者。在发热高峰开始前每8小时取血样,并且此后每6小时取样直到观察期结束。对这些样品进行生物标志物分析。观察发热高峰前8小时和发热高峰后6小时的患者取样。
根据高峰前(36小时窗口)的IL-6、IL-1β和TNF-α的测量值以及他们的样品-样品倍率变化,构建偏最小二乘模型。给定从该研究导出的数据集,8小时的最小取样期和高峰前36小时的最小窗口足以导出到达高峰时间的预测模型。
采用已知用于测量IL-6、IL-1β和TNF-α的熟知的ELISA免疫测定,来导出定量生物标志物浓度数据。记录所测得的皮克/毫升的浓度以及浓度的样品-样品倍率变化,并且进行如下分析。
浓度数据首先进行目视检查来寻找其高斯正态性。因为他们是对数正态分布的,所以通过计算原始数据测量值的对数来变换该数据。根据这些测量值,构建初步的偏最小二乘回归模型,其包括所有3个热原以及他们从样品到样品的倍率变化。该模型表征了相关矢量(到达高峰的时间)和独立矢量(热原水平)的协方差结构中考虑的变化量。在该数据集中,有比自由度更多的自变量。为了解决这个问题,采用标准统计建模工具,例如自顶向下排除和自底向上加入。
完整的模型(IL-6、TNF-α和IL-1β,以及他们的样品-样品变化)说明了整个模型内协方差结构的变化百分比,以及因变量(到达高峰的时间)的变化百分比。采用特征选择过程,包括但不限于自底向上建模和自顶向下建模,开发一系列7个子模型。
所选的模型包括log(IL-6)、log(IL-1β)、log(IL-6的样品-样品倍率变化)、log(TNF-α),并且占整个模型协方差的93%,以及在因变量(到达高峰的时间)变化的27.5%。
模型用带有下列参数集的标准多次线形回归方程式给出:截距=36.5;log(IL-6)=-8.0;log(IL-6倍率变化)=2.4;log(IL-1β)=-0.3;且log(TNF-α)=4.4。每个测量值是在观察到的到达高峰的时间的即时测量值。例如在发热高峰前24小时IL-6、IL-1β的浓度的对数,以及从30小时点开始他们的样品-样品倍率变化,采用拟合参数加入到模型中,表明线形模型的系数。
最终模型从这总共7个子模型中选择,因为它说明了在依赖矢量中变量的百分比的最高水平。最终模型包括log(IL-6)、log(IL-1β)以及他们的样品-样品倍率变化的对数,作为到达高峰的时间的预测因子。通过临床相关性来选择36小时的预测窗口的大小,但不限于这个预测窗口。所选模型的方程式如下:
到达高峰的时间=36.6-8*log(IL6)+2.4*Log(IL-6倍率变化)-0.3*Log(IL-1β+4.4*Log(TNFα)
在该示例中,评估10个患者的结果,来确定在发热高峰前36小时的生物标志物模式。图27-32中是每个热原和它们的样品-样品倍率变化的数据。图27是IL-1β浓度对时间点数的关系。图28是IL-1β的样品-样品倍率变化对时间点数的关系。图29是IL-6浓度对时间点数的关系,其中患者4发生败血症。图30是IL-6的样品-样品倍率变化对时间点数的关系,其中患者4发生败血症。图31是TNF-α浓度对时间点数的关系。图32为TNF-α的样品-样品倍率变化对时间点数的关系。
该模型预测所有患者到达高峰的时间,并且解释了因变量中观察到的差异百分比。患者6患有ATRA综合征,并且所以在用于构造模型的患者群外。
图33中给出了患者5的残差曲线图。患者5具有发热高峰,并且没有标志物减少。温度用摄氏度(右坐标轴),生物标志物浓度用皮克/毫升给出,其中IL-6上升10倍,并不一定表示败血症。残差分析表明,该模型对于发热高峰前12小时和24小时之间的时期的预测是非系统性的,这意味着随机分布在零轴周围并且残差的大小不超过预测的到达高峰时间的百分比,这是由该模型用方程式1来预测的。
对于患者4,当实际到达高峰的时间为7小时,该模型预测到达高峰的时间为3.3小时,并且在另一个极端,当实际到达高峰的时间为34小时,预测到达高峰的时间为39小时,如图34所示。患者4的数据点显示在正好到达发热高峰前,蛋白C降低且IL-6升高。归一化的参数是(在时间t的参数值减去范围内的最低值)与参数的最大值和最小值之间的差异的比率。患者4的残差分析产生对患者4中测得数据的完美拟合,这表明残差随机分布在零轴周围,并且没有残差大于预测到达高峰时间的20%,如从方程式1导出的。
总结该示例,诱导癌症化疗是败血症的潜在病因之一。其他包括但不限于,严重烧伤和热烧伤或外伤。在烧伤和外伤中,患者表现出免疫系统的变化,导致辅助型T细胞-2淋巴细胞表型占优势,其中辅助细胞群的表型从Th1转换为Th2。这称为Th1-Th2转换,并且使得患者更容易发生感染。图35是Th1-Th2转换以及代表每种表型的细胞因子的示意图。一旦患者发生感染,如果确定了潜在的病原体,则感染的速率和传播会导致全身性的炎症反应,称为败血症。如果病原体不明,则炎症反应称为全身炎症反应综合征(SIRS)。因此,发展为败血症的潜在病因可以是可被分为3个生理学上不同的间隔的过程:易受感染,由Th1-Th2转换代表;感染发展;以及败血症/SIRS的发生和发展。表3中显示了与监测每个阶段相关的生物标志物。
表3
图36和37显示了系统采用一个方程式,该方程式用马氏距离平方方程式和贝叶斯概率来预测败血症。马氏距离平方为:
Dj2(x)=(μj–x)TΣ-1(μj),其中j=1,2,3
并且贝叶斯概率为:
Pr(j|x)=exp(-0.5Dj2(x))/Σexp(0.5Dk2(x))
其中μ是代表患者群的质心的均值矢量,且j是3个不同的结果(败血症、发烧、感染)。
图38示出了在败血症试验中患者的多个标志物蛋白的时间图。标记该患者的败血症发生时间,并且所有到达那个点的模式都与对该患者发生败血症的判定相关。
图39示出了同一个患者中两个特定标志物(蛋白C和C反应蛋白)的二元时间进程。在图中央的方向变化代表了疾病的快速发生。在该示例中,患者迅速恶化,并且在二元空间的一个非常特定的区域内显示为败血症。在该示例中,取样间隔是相当规则的,所以每条线段的长度代表了在该特定空间中生物标志物的变化速度。
- 还没有人留言评论。精彩留言会获得点赞!