一种基于服务器查找数据流分割点的方法及服务器与流程
本发明涉及信息技术领域,尤其涉及一种基于服务器查找数据流分割点的方法及服务器。
背景技术:
数据量的不断增长,使得提供充足的数据存储成为当前存储领域面临的严峻挑战。目前应对这一挑战的一种方式为利用需要存储的数据的冗余特性,使用重复数据删除技术,从而减少存储的数据量。
现有技术中,基于内容分块(Content Defined Chunk,CDC)的重复数据删除算法,首先要将待存储的数据流分成很多数据块,而将数据流分成数据块就需要在数据流中查找合适的分割点,两个相邻数据流分割点之间的数据构成一个数据块。计算数据块的特征值,从而查找是否存在相同特征值的数据块,如果查找到相同特征指的数据块,则认为存在重复数据。具体的,基于内容分块的重复数据删除技术是应用滑动窗口技术(Sliding Window Technique)基于文件的内容来查找分块的分割点,即通过计算窗口内数据的Rabin指纹来确定数据流分割点。假设从数据流的左边向右边查找分割点,每次计算滑动窗口内数据的指纹,并且将指纹值基于给定的整数K取模后,与给定的余数R进行比对;若相等则窗口的右端为数据流分割点,否则将窗口继续往右滑动一个字节,依次循环地进行计算和比对,直到到达数据流末尾。在基于内容分块的重复数据删除过程中,查找数据流分割点,需要消耗大量的计算资源,从而成为提升重复数据删除性能的瓶颈。
技术实现要素:
第一方面,本发明实施例提供了一种基于服务器查找数据流分割点的方法,在所述服务器上预设有规则,所述规则为:为潜在分割点
k确定M个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;所述方法包括:
a)依据所述规则为当前潜在分割点ki确定点piz及所述点piz对应的窗口Wiz[piz-Az,piz+Bz],i和z为整数,并且1≤z≤M;
b)判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖+‖(ki-pix)‖),获得新的潜在分割点,执行步骤a);
c)当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[pix-Ax,pix+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第一方面,第一种可能的实现方式中,所述规则还包括:至少两个点pe和pf,满足条件Ae=Af,Be=Bf,Ce=Cf。
结合第一方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf,相对于所述潜在分割点k,在所述数据流分割点查找反方向上。
结合第一方面的第一种可能的实现方式或第二种可能的实现方式,第三种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf之间的距离为1个U。
结合第一方面,或第一方面第一至第三种任一可能的实现方式,第四种可能的实现方式中,判断所述窗口Wiz[piz-Az,piz+Bz]中至少部 分数据是否满足所述预定条件Cz,具体包括:
使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第一方面的第四种可能的实现方式,第五种可能的实现方式中,所述使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体为使用hash函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第一方面,或第一方面第一至第五种任一可能的实现方式,第六种可能的实现方式中,当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的点pic对应的窗口Wic[pic-Ac,pic+Bc]的左边界与所述窗口Wiz[piz-Az,piz+Bz]的右边界重合或者为所述新的潜在分割点确定的所述点pic对应的所述窗口Wic[pic-Ac,pic+Bc]的左边界位于所述窗口Wiz[piz-Az,piz+Bz]范围之内;其中,为所述新的潜在分割点确定的所述点pic是根据所述规则,为所述新的潜在分割点确定的M个点按照数据流查找方向获得的序列中排序第一的点。
结合第一方面的第四种可能的实现方式,第七种可能的实现方式中,使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[piz-Az,piz+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字 节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据满足所述预定条件Cz。
第二方面,本发明实施例提供了一种基于服务器查找数据流分割点的方法,在所述服务器上预设有规则,所述规则为:为潜在分割点k确定M个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;
所述方法包括:
a)依据所述规则为当前潜在分割点ki确定对应的窗口Wiz[ki-Az,ki+Bz],i和z为整数,并且1≤z≤M;
b)判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖),获得新的潜在分割点,执行步骤a);
c)当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[ki-Ax,ki+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第二方面,第一种可能的实现方式中,所述规则还包括:至少两个窗口Wie[ki-Ae,ki+Be]与Wif[ki-Af,ki+Bf],满足条件:|Ae+Be|=|Af+Bf|,Ce=Cf。
结合第二方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:Ae和Af为正整数。
结合第二方面的第一种可能的实现方式或第二种可能的实现方式,在第三种可能的实现方式中,所述规则还包括:Ae-1=Af,Be+1=Bf。
结合第二方面,或第二方面第一至第三任一可能的实现方式,第四种可能的实现方式中,判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否所述满足预定条件Cz,具体包括:
使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第二方面的第四种可能的实现方式,第五种可能的实现方式中,所述使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体为使用hash函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第二方面,或第二方面第一至第五任一可能的实现方式,第六种可能的实现方式中,当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的窗口Wic[ki-Ac,ki+Bc]的左边界与所述窗口Wiz[ki-Az,ki+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]的左边界位于所述窗口Wiz[ki-Az,ki+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]是根据所述规则,为所述新的潜在分割点确定的M个窗口按照数据流查找方向获得的序列中排序第一的窗口。
结合第二方面的第四种可能的实现方式,第七种可能的实现方式中,使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[ki-Az,ki+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选 择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据满足所述预定条件Cz。
第三方面,本发明实施例提供了一种用于查找数据流分割点的服务器,所述服务器包括中央处理单元和主存储器,所述中央处理单元与所述主存储器通信,在所述服务器上预设有规则,所述规则为:为潜在分割点k确定M个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;
所述主存储器用于存储可执行指令,所述中央处理单元执行所述可执行指令,以执行如下步骤:
a)依据所述规则为当前潜在分割点ki确定点piz及所述点piz对应的窗口Wiz[piz-Az,piz+Bz],i和z为整数,并且1≤z≤M;
b)判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖+‖(ki-pix)‖),获得新的潜在分割点,执行步骤a);
c)当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[pix- Ax,pix+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第三方面,第一种可能的实现方式中,所述规则还包括:至少两个点pe和pf,满足条件Ae=Af,Be=Bf,Ce=Cf。
结合第三方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf,相对于所述潜在分割点k,在所述数据流分割点查找反方向上。
结合第三方面的第一种可能的实现方式或第二种可能的实现方式,第三种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf之间的距离为1个U。
结合第三方面,或第一至第三任一可能的实现方式,第四种可能的实现方式中,所述中央处理单元具体用于
使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第三方面的第四种可能的实现方式,第五种可能的实现方式中,所述中央处理单元具体用于使用hash函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第三方面,或第一至第五任一可能的实现方式,第六种可能的实现方式中,当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的点pic对应的窗口Wic[pic-Ac,pic+Bc]的左边界与所述窗口Wiz[piz-Az,piz+Bz]的右边界重合或者为所述新的潜在分割点确定的所述点pic对应的所述窗口Wic[pic-Ac,pic+Bc] 的左边界位于所述窗口Wiz[piz-Az,piz+Bz]范围之内;其中,为所述新的潜在分割点确定的所述点pic是根据所述规则,为所述新的潜在分割点确定的M个点按照数据流查找方向获得的序列中排序第一的点。
结合第三方面的第四种可能的实现方式,第七种可能的实现方式中,所述中央处理单元使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[piz-Az,piz+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据满足所述预定条件Cz。第四方面,本发明实 施例提供了一种用于查找数据流分割点的服务器,所述服务器包括中央处理单元和主存储器,所述中央处理单元与所述主存储器通信,在所述服务器上预设有规则,所述规则为:为潜在分割点k确定M个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;
所述主存储器用于存储可执行指令,所述中央处理单元执行所述可执行指令,以执行以下步骤:
a)依据所述规则为当前潜在分割点ki确定对应的窗口Wiz[ki-Az,ki+Bz],i和z为整数,并且1≤z≤M;
b)判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖),获得新的潜在分割点,执行步骤a);
c)当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[ki-Ax,ki+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第四方面,第一种可能的实现方式中,所述规则还包括:至少两个窗口Wie[ki-Ae,ki+Be]与Wif[ki-Af,ki+Bf],满足条件:|Ae+Be|=|Af+Bf|,Ce=Cf。
结合第四方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:Ae和Af为正整数。
结合第四方面的第一种可能的实现方式或第二种可能的实现方式,在第三种可能的实现方式中,所述规则还包括:Ae-1=Af,Be+1= Bf。
结合第四方面,或第一至第三任一可能的实现方式,第四种可能的实现方式中,所述中央处理单元具体用于
使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第四方面的第四种可能的实现方式,第五种可能的实现方式中,所述中央处理单元具体用于使用hash函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第四方面,或第一至第五任一可能的实现方式,第六种可能的实现方式中,当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的窗口Wic[ki-Ac,ki+Bc]的左边界与所述窗口Wiz[ki-Az,ki+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]的左边界位于所述窗口Wiz[ki-Az,ki+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]是根据所述规则,为所述新的潜在分割点确定的M个窗口按照数据流查找方向获得的序列中排序第一的窗口。
结合第四方面的第四种可能的实现方式,第七种可能的实现方式中,所述中央处理单元使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[ki-Az,ki+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字 节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据满足所述预定条件Cz。
第五方面,本发明实施例提供了一种用于查找数据流分割点的服务器,在所述服务器上预设有规则,所述规则为:为潜在分割点k确定M个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;
所述服务器包括:处理单元,用于执行步骤a):
a)依据所述规则为当前潜在分割点ki确定点piz及所述点piz对应的窗口Wiz[piz-Az,piz+Bz],i和z为整数,并且1≤z≤M;
判断处理单元,用于判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分 数据是否满足预定条件Cz;
当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖+‖(ki-pix)‖),获得新的潜在分割点,则所述确定单元为所述新的潜在分割点执行步骤a);
当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[pix-Ax,pix+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第五方面,第一种可能的实现方式中,所述规则还包括:至少两个点pe和pf,满足条件Ae=Af,Be=Bf,Ce=Cf。
结合第五方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf,相对于所述潜在分割点k,在所述数据流分割点查找反方向上。
结合第五方面的第一种可能的实现方式或第二种可能的实现方式,在第三种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf之间距离为1个U。
结合第五方面,或第一至第三任一可能的实现方式,第四种可能的实现方式中,所述判断处理单元具体使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第五方面的第四种可能的实现方式,第五种可能的实现方式中,所述判决处理单元具体用于使用hash函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第五方面,或第一至第五任一可能的实现方式,第六种可能的实现方式中,所述判断处理单元用于当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流 分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,所述确定单元为所述新的潜在分割点执行步骤a),根据所述规则,为所述新的潜在分割点确定的点pic对应的窗口Wic[pic-Ac,pic+Bc]的左边界与所述窗口Wiz[piz-Az,piz+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[pic-Ac,pic+Bc]的左边界位于所述窗口Wiz[piz-Az,piz+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[pic-Ac,pic+Bc]是根据所述规则,为所述新的潜在分割点确定的M个点按照数据流查找方向获得的序列中排序第一的点。
结合第五方面的第四种可能的实现方式,第七种可能的实现方式中,所述判断处理单元具体用于使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[piz-Az,piz+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据满足所述预定条件Cz。
第六方面,本发明实施例提供了一种用于查找数据流分割点的服务器,在所述服务器上预设有规则,所述规则为:为潜在分割点k确定M个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;
所述服务器包括:确定单元,用于执行步骤a:
a)依据所述规则为当前潜在分割点ki确定对应的窗口Wiz[ki-Az,ki
+Bz],i和z为整数,并且1≤z≤M;
判断处理单元,用于判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖),获得新的潜在分割点,执行步骤a);
c当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[ki-Ax,ki+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第六方面,第一种可能的实现方式中,所述规则还包括:至 少两个窗口Wie[ki-Ae,ki+Be]与Wif[ki-Af,ki+Bf],满足条件:|Ae+Be|=|Af+Bf|,Ce=Cf。
结合第六方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:Ae和Af为正整数。
结合第六方面的第一种可能的实现方式或第二种可能的实现方式,在第三种可能的实现方式中,所述规则还包括:Ae-1=Af,Be+1=Bf。
结合第六方面,或第一至第三任一可能的实现方式,第四种可能的实现方式中,所述判断处理单元具体用于
使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第六方面的第四种可能的实现方式,第五种可能的实现方式中,所述判断处理单元具体用于使用hash函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第六方面,或第一至第五任一可能的实现方式,第六种可能的实现方式中,所述判断处理单元用于当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,所述确定单元为所述新的潜在分割点执行步骤a),根据所述规则,为所述新的潜在分割点确定的窗口Wic[ki-Ac,ki+Bc]的左边界与所述窗口Wiz[ki-Az,ki+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]的左边界位于所述窗口Wiz[ki-Az,ki+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]是根据所述规则,为所述新的潜在分割点确定的M个窗口按照数据流查找方向获得的序列中排序第一 的窗口。
结合第六方面的第四种可能的实现方式,第七种可能的实现方式中,所述判断处理单元使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[ki-Az,ki+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据满足所述预定条件Cz。
第七方面,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储可执行指令,服务器执行所述可执行指 令以查找数据流分割点,在所述服务器上预设有规则,所述规则为:为潜在分割点k确定M个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;
当所述服务器执行所述可执行指令,以执行以下步骤:
a)依据所述规则为当前潜在分割点ki确定点piz及所述点piz对应的窗口Wiz[piz-Az,piz+Bz],i和z为整数,并且1≤z≤M;
b)判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖+‖(ki-pix)‖),获得新的潜在分割点,执行步骤a);
c)当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[pix-Ax,pix+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第七方面,第一种可能的实现方式中,所述规则还包括:至少两个点pe和pf,满足条件Ae=Af,Be=Bf,Ce=Cf。
结合第七方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf,相对于所述潜在分割点k,在所述数据流分割点查找反方向上。
结合第七方面的第一种可能的实现方式或第二种可能的实现方式,在第三种可能的实现方式中,所述规则还包括:所述至少两个点pe和pf之间的距离为1个U。
结合第七方面,或第七方面第一至第三任一可能的实现方式,第四种可能的实现方式中,所述服务器判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
所述服务器使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第七方面的第四种可能的实现方式,第五种可能的实现方式中,所述服务器使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
所述服务器使用hash函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第七方面,或第七方面第一至第五任一可能的实现方式,第六种可能的实现方式中,当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的点pic对应的窗口Wic[pic-Ac,pic+Bc]的左边界与所述窗口Wiz[piz-Az,piz+Bz]的右边界重合或者为所述新的潜在分割点确定的所述点pic对应的所述窗口Wic[pic-Ac,pic+Bc]的左边界位于所述窗口Wiz[piz-Az,piz+Bz]范围之内;其中,为所述新的潜在分割点确定的所述点pic是根据所述规则,为所述新的潜在分割点确定的M个点按照数据流查找方向获得的序列中排序第一的点。
结合第七方面的第四种可能的实现方式,第七种可能的实现方式中,使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[piz-Az,piz+Bz]中选择F个字节,将所述F个字节 反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据满足所述预定条件Cz。
第八方面,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储可执行指令,服务器执行所述可执行指令以查找数据流分割点,在所述服务器上预设有规则,所述规则为:为潜在分割点k确定M个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;当所述服务器执行所述可执行指令,以执行以下步骤:
a)依据所述规则为当前潜在分割点ki确定对应的窗口Wiz[ki-Az,ki
+Bz],i和z为整数,并且1≤z≤M;
b)判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖),获得新的潜在分割点,执行步骤a);
c)当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[ki-Ax,ki+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
结合第八方面,第一种可能的实现方式中,所述规则还包括:至少两个窗口Wie[ki-Ae,ki+Be]与Wif[ki-Af,ki+Bf],满足条件:|Ae+Be|=|Af+Bf|,Ce=Cf。
结合第八方面的第一种可能的实现方式,第二种可能的实现方式中,所述规则还包括:Ae和Af为正整数。
结合第八方面的第一种可能的实现方式或第二种可能的实现方式,在第三种可能的实现方式中,所述规则还包括:Ae-1=Af,Be+1=Bf。
结合第八方面,或第八方面第一到第三任一可能的实现方式,第四种可能的实现方式中,所述服务器判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第八方面的第四种可能的实现方式,第五种可能的实现方式中,所述服务器使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部 分数据是否满足所述预定条件Cz,具体为所述服务器使用hash函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
结合第八方面,或第八方面第一到第五任一可能的实现方式,第六种可能的实现方式中,当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的窗口Wic[ki-Ac,ki+Bc]的左边界与所述窗口Wiz[ki-Az,ki+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]的左边界位于所述窗口Wiz[ki-Az,ki+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]是根据所述规则,为所述新的潜在分割点确定的M个窗口按照数据流查找方向获得的序列中排序第一的窗口。
结合第八方面的第四种可能的实现方式,第七种可能的实现方式中,使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[ki-Az,ki+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述 F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据满足所述预定条件Cz。
本发明实施例中通过判断M个窗口中某一个窗口中至少部分数据是否满足预定条件,来查找数据流分割点,当某一个窗口中至少部分数据不满足预定条件,则跳过N*U个长度,获得下一个潜在分割点,提高了数据流分割点查找效率。
附图说明
图1为本发明实施例一种应用场景示意图;
图2为数据流分割点示意图;
图3为查找数据流分割点示意图;
图4为本发明实施例方法示意图;
图5和图6为查找数据流分割点实施方式示意图;
图7和图8为查找数据流分割点实施方式示意图;
图9和图10为找数据流分割点实施方式示意图;
图11和图12和图13为找数据流分割点实施方式示意图;
图14和图15为找数据流分割点实施方式示意图;
图16和图17为判断窗口中至少部分数据是否满足预定条件示意图;
图18为去重服务器结构图;
图19为去重服务器结构图;
图20为本发明实施例方法示意图;
图21和图22为查找数据流分割点实施方式示意图;
图23和图24为查找数据流分割点实施方式示意图;
图25和图26为找数据流分割点实施方式示意图;
图27和图28和图29为找数据流分割点实施方式示意图;
图30和图31为找数据流分割点实施方式示意图;
图32和图33为判断窗口中至少部分数据是否满足预定条件示意图。
图34和35为判断是否满足预定条件的概率示意图。
具体实施例
随着存储技术的不断进步,数据产生量也在不断增加,大量的数据对存储容量提出了最高的要求。存储容量增加的同时,也增加了IT设备采购成本,为了缓解数据量与存储容量之间的需求矛盾,节约IT设备采购成本,在数据存储领域引入了重复数据删除技术。
本发明实施例一种使用场景为数据备份场景。数据备份是为防止各种原因导致的数据丢失,通过备份服务器将数据备份到其他存储介质的过程。如图1所示的数据备份系统架构。数据备份系统包括客户端(101a、101b…101n)、备份服务器102、重复数据删除服务器(简称去重服务器或重删服务器)103和存储设备(104a、104b…104n)。其中客户端(101a、101b…101n)可以为应用服务器、工作站等;备份服务器102用于备份客户端生成的数据;去重服务器103用于执行备份数据的重复数据删除任务;存储设备(104a、104b…104n)作为存储重复数据删除后的数据的存储介质,可以为磁盘阵列、磁带库等存 储介质。客户端(101a、101b…101n)、备份服务器102、重复数据删除服务器103和存储设备(104a、104b…104n)可以通过交换机、局域网、互联网、光纤等方式连接,上述设备可以位于同一地点,也可以位于不同地点。备份服务器102、重删服务器103、存储设备(104a、104b…104n)可以为独立的物理设备,或者在具体实现中物理上集成为一体,或者备份服务器102与重删服务器103集成为一体,或者重删服务器103与存储设备(104a、104b…104n)集成为一体等。
去重服务器103对备份数据的数据流执行重复数据删除操作,一般包括以下步骤:
1)数据流分割点查找:根据特定算法在数据流中查找数据流分割点;
2)根据查找到的数据流分割点划分数据块;
3)计算数据块的特征值:计算数据块的特征值作为标识该数据块的特征;将计算得到的特征值添加到该数据流对应的文件的数据块的特征列表中;一般利用SHA-1或MD5算法计算数据块的特征值;
4)相同数据块检测:将计算得到的数据块的特征值与数据块特征列表中已存在的特征值进行比对以确定是否存在相同数据块;
5)删除重复数据块:通过相同数据块检测,如果发现数据块特征列表中存在与该数据块相同的特征值,则不需要再存储该数据块或者根据备份策略确定的重复数据块存储数量决定是否存储该数据块。
通过去重服务器103对备份数据的数据流执行重复数据删除操作的步骤可知,数据流分割点查找作为重复数据删除操作的关键步骤,直接决定了重复数据删除的性能。
本发明实施例中,去重服务器103接收备份服务器102发送的备份文件,对该文件执行重复数据删除处理。通常待处理备份文件在去重服务器103中以数据流形式呈现,去重服务器103查找数据流中的分割 点时,通常要确定数据流分割点最小查找单位,具体如图2所示,如潜在分割点k1位于序号分别为1和2的连续两个数据流分割点最小查找单位之间,潜在分割点是指需要进行判断是否可以作为数据流分割点的点;当点k1为一个数据流分割点,数据流分割点查找方向如图2中箭头所示,查找下一个潜在分割点为k7,即位于序号分别为7和8的连续两个数据流分割点最小查找单位之间,当潜在分割点k7为数据流分割点,则相邻的两个数据流分割点k1、k7之间的数据为1个数据块。数据流分割点最小查找单位具体可以根据实际需要确定,这里以1个字节(Byte)为例,即序号为1、2、7和8的数据流分割点最小查找单位大小均为1个字节。如图2所示的数据流分割点查找方向通常表示由文件头向文件尾方向查找,或者由文件尾向文件头方向,本实施例中以从文件头向文件尾方向查找为例。
在重复数据删除场景,通常数据块越小,重复数据删除率越高,越容易查找到重复数据块,但是由此生成的元数据数量越大,而且数据块小到一定程度之后,重复数据删除率就不会增加了,但是元数据数量却会急剧增加。因此,必须控制数据块大小,实际应用中,通常会设定数据块的最小值,例如4KB(4096个字节),同时考虑到重复数据删除率,也会设定数据块的最大值,即数据块大小不能超过最大值,例如12KB(12288个字节)。一种具体实现方式如图3所示,去重服务器103在沿着箭头所示方向查找数据流分割点,ka为当前查找到的数据流分割点,从ka向数据流分割点查找方向查找下一个潜在分割点,为满足最小数据块要求,通常会从数据流分割点开始沿着数据流分割点查找方向跳过最小数据块大小,从最小数据块结束位置开始查找,也就是将最小数据块结束位置作为下一个潜在分割点ki。在本发明实施例中,可以先从ka点沿数据流分割点查找方向跳跃最小数据 块4KB,即4*1024=4096字节。从ka点沿数据流分割点查找方向跳跃4096个字节,在第4096个字节的结束位置获得点ki,作为潜在分割点,例如ki位于序号分别为4096和4097的连续两个数据流分割点最小查找单位之间。仍然以图3为例,ka为当前查找到的数据流分割点,沿如图3所示方向查找下一个数据流分割点,如果超过数据块最大值仍然没有找到下一个数据流分割点,则在从ka点开始向数据流分割点查找方向达到数据块最大值的点kz作为下一个数据流分割点,进行强制分割。
本发明实施例提供一种基于去重服务器查找数据流分割点的方法,如图4所示,包括:
在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定M个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;其中,px与潜在分割点k之间距离dx个数据流分割点最小查找单位,数据流分割点最小查找单位以U表示,本实施例中U=1个字节,。在图3所示的实现方式中,关于M的取值,其中一种实现方式,M*U取值不大于预设的两个相邻的数据流分割点之间的最大距离,即预设的数据块最大长度。判断点pz对应的窗口Wz[pz-Az,pz+Bz]中至少部分数据是否满足预定条件Cz,其中,z为整数,1≤z≤M,(pz-Az)与(pz+Bz)分别表示窗口Wz的两个边界。当判断任意一个点pz的窗口Wz[pz-Az,pz+Bz]中至少部分数据不满足预定条件Cz,则从不满足预定条件的窗口Wz[pz-Az,pz+Bz]对应的点pz沿数据流分割点查找方向跳跃N个字节,N≤‖Bz‖+maxx(‖Ax‖+‖(k-px)‖)。其中,‖(k-px)‖表示M个点px中任一个点与潜在分割点k之间的距离,maxx(‖Ax‖+‖(k-px)‖)表示M个点px中任一个点与潜在分割点k之间的距离及该点对 应的Ax的绝对值之和的最大值;‖Bz‖表示Wz[pz-Az,pz+Bz]中Bz的绝对值,将在下面实施例中具体介绍N取值的原理。当判断M个窗口中的每一个窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx,则潜在分割点k为数据流分割点。
具体的,对当前潜在分割点ki,依据所述规则,执行以下步骤:
步骤401:依据所述规则为当前潜在分割点ki确定点piz及所述点piz对应的窗口Wiz[piz-Az,piz+Bz],i和z为整数,并且1≤z≤M;
步骤402:判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖+‖(ki-pix)‖),获得新的潜在分割点,执行步骤401;
当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[pix-Ax,pix+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
进一步地,所述规则还包括:至少两个点pe和pf,满足条件Ae=Af,Be=Bf,Ce=Cf;
所述规则还包括:所述至少两个点pe和pf,相对于所述潜在分割点k,在所述数据流分割点查找反方向上。
所述规则还包括:所述至少两个点pe和pf之间的距离为1个U。
判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是 否满足所述预定条件Cz。
所述使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体为使用hash函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。
当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的点pic对应的窗口Wic[pic-Ac,pic+Bc]的左边界与所述窗口Wiz[piz-Az,piz+Bz]的右边界重合或者为所述新的潜在分割点确定的所述点pic对应的所述窗口Wic[pic-Ac,pic+Bc]的左边界位于所述窗口Wiz[piz-Az,piz+Bz]范围之内;其中,为所述新的潜在分割点确定的所述点pic是根据所述规则,为所述新的潜在分割点确定的M个点按照数据流查找方向获得的序列中排序第一的点。
本发明实施例中通过判断M个窗口中某一个窗口中至少部分数据是否满足预定条件,来查找数据流分割点,当某一个窗口中至少部分数据不满足预定条件,则跳过N*U个长度,其中,N*U不大于‖Bz‖+maxx(‖Ax‖+‖(ki-pix)‖),获得下一个潜在分割点,提高了数据流分割点查找效率。
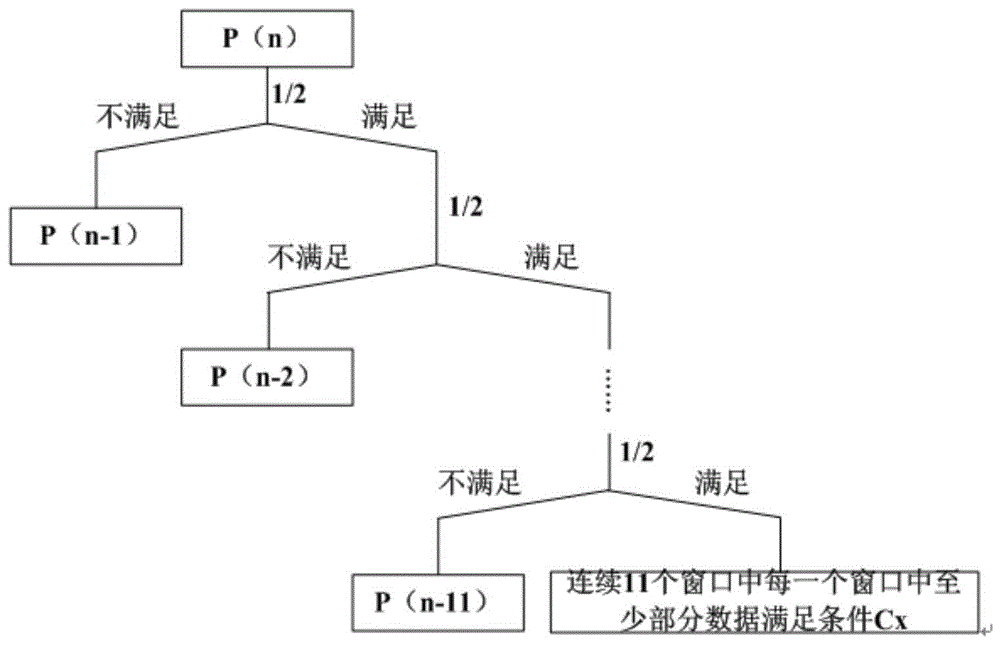
在重复数据删除过程中,为保证数据块大小均匀,会考虑平均数据块(也称为平均分块)大小,即在满足最小数据块大小和最大数据块大小限定的同时,会确定平均数据块大小,以保证获得的数据块大小均匀。点px个数M与点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率,这两个因素决定了找到数据流分割点的概率(以P(n)表示)。前者影响跳跃的长度,后者影响跳跃的概率,二者共同影响平均分块大小。一般而言,在平均分块大小固定时,点 px个数M增加,则单个点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率也增加,例如在去重服务器103上预设的规则为:为潜在分割点k确定11个点px,x分别为1到11连续的自然数,11个点中任一个点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率为1/2。而在去重服务器103上预设的另一组规则为:为潜在分割点k选择的24个点px,x分别为1到24连续的自然数,24个点中任一个点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率3/4。具体窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率设定可参见判断窗口Wx[px-Ax,px+Bx]中至少部分数据是否满足预定条件Cx部分的描述。点px个数M与点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率这两个因素决定P(n),P(n)表示:从数据流起始位置/上一数据流分割点查找n个数据流分割点最小查找单位后没找到数据流分割点的概率。关于这两个因素决定P(n)的计算过程,实际上是一个多步长Fibonacci数列,后面将具体描述。得到P(n)后,1-P(n)即为数据流分割点的分布函数,(1-P(n))-(1-P(n-1))=P(n-1)-P(n),即为在第n个点找到数据流分割点的概率,也就是数据流分割点的密度函数,根据数据流分割点的密度函数就可以积分从而求得数据流分割点的期望长度,即平均分块大小,其中,4*1024(字节)表示最小数据块长度,12*1024(字节)表示最大数据块长度。
如图3所示的数据流分割点查找的基础上,在图5所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个点px、点px对应的窗口Wx[px-Ax,px+Bx](简称窗口Wx)和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中,A1=A2=A3=A4=A5=A6=A7 =A8=A9=A10=A11=169,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11。其中,点px与潜在分割点k之间距离dx个字节,具体的,点p1与潜在分割点k之间距离0个字节,点p2与潜在分割点k之间距离1个字节,点p3与潜在分割点k之间距离2个字节,点p4与潜在分割点k之间距离3个字节,点p5与潜在分割点k之间距离4个字节,点p6与潜在分割点k之间距离5个字节,点p7与潜在分割点k之间距离6个字节,点p8与潜在分割点k之间距离7个字节,点p9与潜在分割点k之间距离8个字节,点p10与潜在分割点k之间距离9个字节,点p11与潜在分割点k之间距离10个字节,并且点p2、p3、p4、p5、p6、p7、p8、p9、p10和p11相对于潜在分割点k均位于数据流分割点查找反方向。ka为数据流分割点,图5中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,最小数据块4KB结束位置作为下一个潜在分割点ki,为潜在分割点ki确定点pix,在本实施例中,根据在去重服务器103上预设的规则,x分别为1到11连续的自然数。在图5所示的实施方式中,为潜在分割点ki确定的点为11个,分别为pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11,点pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11对应的窗口分别为Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]和Wi11[pi11-169,pi11]。上述窗口分别简称为Wi1、Wi2、Wi3、Wi4、Wi5、Wi6、Wi7、Wi8、Wi9、Wi10和Wi11。其中,点pix与潜在分割点ki之间距离dx个字节,具体的,pi1与ki间距0个字节、pi2与ki间距1个字节、pi3与ki间距2个字节、pi4与ki间距3个字节、pi5与ki间距4个字节、pi6与ki间距5个字节、pi7与 ki间距6个字节、pi8与ki间距7个字节、pi9与ki间距8个字节、pi10与ki间距9个字节,pi11与ki间距10个字节,并且pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11相对于潜在分割点ki均位于数据流分割点查找反方向。判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1、判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2、判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11-169,pi11]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图6所示,Wi5[pi5-169,pi5]中至少部分数据不满足对应的预定条件C5,则从点pi5沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B5‖+maxx(‖Ax‖+‖(ki-pix)‖),在图6所示的实 施方式中,跳跃N个字节不大于179字节,在本实施例中,N=11,得到下一个潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj。根据图5所示的实施方式中在去重服务器103上预设的规则,为潜在分割点kj确定的点为11个,分别为pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11,确定点pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11对应的窗口分别为Wj1[pj1-169,pj1]、Wj2[pj2-169,pj2]、Wj3[pj3-169,pj3]、Wj4[pj4-169,pj4]、Wj5[pj5-169,pj5]、Wj6[pj6-169,pj6]、Wj7[pj7-169,pj7]、Wj8[pj8-169,pj8]、Wj9[pj9-169,pj9]、Wj10[pj10-169,pj10]和Wj11[pj11-169,pj11]。其中,pjx与潜在分割点kj之间距离dx个字节,具体的,pj1与kj间距0个字节、pj2与kj间距1个字节、pj3与kj间距2个字节、pj4与kj间距3个字节、pj5与kj间距4个字节、pj6与kj间距5个字节、pj7与kj间距6个字节、pj8与kj间距7个字节、pj9与kj间距8个字节、pj10与kj间距9个字节,pj11与kj间距10个字节,并且pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11相对于潜在分割点kj均位于数据流分割点查找反方向。如图6所示实施方式中,当为潜在分割点kj确定的第11个窗口Wj11[pj11-169,pj11],在保证潜在分割点ki与潜在分割点kj之间的范围都在判断范围之内,则在本实施方式中,必须保证窗口Wj11[pj11-169,pj11]的左边界与Wi5[pi5-169,pi5]的右边界pi5重合或者位于Wi5[pi5-169,pi5]范围之内,其中,所述潜在分割点kj确定的点pj11是根据所述规则,为所述潜在分割点kj确定的M个点按照数据流查找方向获得的序列中排序第一的点。因此,在这一限定内,当Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5,从pi5沿着数据流分割点查找方向跳跃的距离为不大于‖B5‖+maxx(‖Ax‖+‖(ki-pix)‖),其中,M=11,11*U不大于maxx(‖Ax‖+‖(ki-pix)‖),因此,从pi5沿着数据 流分割点查找方向跳跃的距离为不大于179。判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1、判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2、判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3、判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11。当然在本发明实施例中,判断潜在分割点ka是否为数据流分割点时也遵循该规则,具体实现不再描述,可以参照判断潜在分割点ki的描述。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜 在分割点kj不是数据流分割点时,按照与ki相同的方式跳跃11个字节获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。
在图5所示的实施方式中,根据在去重服务器103上预设的规则,从判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1开始,当判断Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1、判断Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2、判断Wi3[pi3-169,pi3]中至少部分数据满足预定条件C3和判断Wi4[pi4-169,pi4]中至少部分数据满足预定条件C4,判断Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5时,从点pi5沿着数据流分割点查找方向跳跃10个字节,在第10个字节的结束位置获得新的潜在分割点,为与其他潜在分割点区别,这里表示为kg,按照在去重服务器103上预设的规则,为潜在分割点kg确定11个点pgx,x分别为1到11连续的自然数,分别为pg1、pg2、pg3、pg4、pg5、pg6、pg7、pg8、pg9、pg10和pg11,确定点pg1、pg2、pg3、pg4、pg5、pg6、pg7、pg8、pg9、pg10和pg11对应的窗口分别为Wg1[pg1-169,pg1]、Wg2[pg2-169,pg2]、Wg3[pg3-169,pg3]、Wg4[pg4-169,pg4]、Wg5[pg5-169,pg5]、Wg6[pg6-169,pg6]、Wg7[pg7-169,pg7]、Wg8[pg8-169,pg8]、Wg9[pg9-169,pg9]、Wg10[pg10-169,pg10]和Wg11[pg11-169,pg11]。其中,pgx与潜在分割点kg之间距离dx个字节,具体的,pg1与kg间距0个字节、pg2与kg间距1个字节、pg3与kg间距2个字节、pg4与kg间距3个字节、pg5与kg间距4个字节、pg6与kg间距5个字节、pg7与kg间距6个字节、pg8与kg间距7个字节、pg9与kg间距8个字节、pg10与kg间距9个字节,pg11与 kg间距10个字节,并且pg2、pg3、pg4、pg5、pg6、pg7、pg8、pg9、pg10和pg11相对于潜在分割点kg均位于数据流分割点查找反方向。判断Wg1[pg1-169,pg1]中至少部分数据是否满足预定条件C1、判断Wg2[pg2-169,pg2]中至少部分数据是否满足预定条件C2、判断Wg3[pg3-169,pg3]中至少部分数据是否满足预定条件C3、判断Wg4[pg4-169,pg4]中至少部分数据是否满足预定条件C4、判断Wg5[pg5-169,pg5]中至少部分数据是否满足预定条件C5、判断Wg6[pg6-169,pg6]中至少部分数据是否满足预定条件C6、判断Wg7[pg7-169,pg7]中至少部分数据是否满足预定条件C7、判断Wg8[pg8-169,pg8]中至少部分数据是否满足预定条件C8、判断Wg9[pg9-169,pg9]中至少部分数据是否满足预定条件C9、判断Wg10[pg10-169,pg10]中至少部分数据是否满足预定条件C10和判断Wg11[pg11-169,pg11]中至少部分数据是否满足预定条件C11。因此,潜在分割点kg对应的点pg11与潜在分割点ki对应的点pi5重合,并且点pg11对应的窗口Wg11[pg11-169,pg11]与点pi5对应的窗口Wi5[pi5-169,pi5]重合,并且C5=C11,因此,对当潜在分割点ki,当判断Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5时,从点pi5沿着数据流分割点查找方向跳跃10个字节,获得的潜在分割点kg仍然不符合作为数据流分割点的条件。因此,如果从点pi5沿着数据流分割点查找方向跳跃10个字节会存在重复计算,从点pi5沿着数据流分割点查找方向跳跃11个字节可以减少重复计算,效率更高。因此提高了查找数据流分割点的速度。当预设规定中点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率为1/2时,即是说以1/2的概率执行跳跃,每次最多可以跳跃179个字节。
在本实施方式中,预定规则为:为潜在分割点k确定11个点px、点 px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,x分别为1到11连续的自然数,其中,点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件的概率为1/2,通过这两个因素可以计算P(n)。并且A1=A2=A3=A4=A5=A6=A7=A8=A9=A10=A11=169,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11,其中,px与潜在分割点k之间距离dx个字节,具体的,p1与潜在分割点k之间距离0个字节,p2与k之间距离1个字节,p3与k之间距离2个字节,p4与k之间距离3个字节,p5与k之间距离4个字节,p6与k之间距离5个字节,p7与k之间距离6个字节,p8与k之间距离7个字节,p9与k之间距离8个字节,p10与k之间距离9个字节,p11与k之间距离10个字节,并且p2、p3、p4、p5、p6、p7、p8、p9、p10和p11相对于潜在分割点k均位于数据流分割点查找反方向。因此是否存在连续11个点对应窗口中的每一个窗口中至少部分数据均满足预定条件Cx就决定潜在分割点k是否为数据流分割点。从数据流起始位置/上一数据流分割点跳跃最小分块长度4096个字节后,向数据流分割点查找反方向回退10个字节,找到第4086个点,在该点处不存在数据流分割点,所以P(4086)=1,依次类推,P(4087)=1,……P(4095)=1。在第4096个点处,即在最小分块大小处,以(1/2)^11的概率这11个点对应的窗口中每一个窗口中至少部分数据满足预定条件Cx,因此以(1/2)^11的概率存在数据流分割点,以1-(1/2)^11的概率不存在数据流分割点,所以P(11)=1-(1/2)^11。
如图34所示,在第n个点处,可以分为12种情况来递推P(n)。
情况1:第n个点对应的窗口中至少部分数据以1/2的概率不满足预定条件,此时第n个点前面的n-1个点以P(n-1)的概率不存在连续的11个点对应的窗口中每一个窗口中至少部分数据分别满足预定条 件,因此P(n)包含1/2*P(n-1)。第n个点对应的窗口中至少部分数据不满足预定条件,并且第n个点前面的n-1个点存在连续的11个点对应的窗口中每一个窗口中至少部分数据分别满足预定条件的情况与P(n)无关。
情况2:第n个点对应的窗口中至少部分数据以1/2的概率满足预定条件,第n-1个点对应的窗口中至少部分数据以1/2的概率不满足预定条件,此时第n-1个点前面的n-2个点以P(n-2)的概率不存在连续的11个点对应的窗口中每一个窗口中至少部分数据分别满足预定条件,因此P(n)包含1/2*1/2*P(n-2)。第n个点对应的窗口中至少部分数据满足预定条件,第n-1个点对应的窗口中至少部分数据不满足预定条件,并且第n-1个点前面的n-2个点存在连续的11个点对应的窗口中每一个窗口中至少部分数据分别满足预定条件的情况与P(n)无关。
依照上述描述,情况11:第n至n-9个点对应的窗口中至少部分数据以(1/2)^10的概率满足预定条件,第n-10个点对应的窗口中至少部分数据以1/2的概率不满足预定条件,此时第n-10个点前面的n-11个点以P(n-11)的概率不存在连续的11个点对应的窗口中每一个窗口中至少部分数据分别满足预定条件,因此P(n)包含(1/2)^10*1/2*P(n-11)。第n至n-9个点对应的窗口中至少部分数据均满足预定条件,第n-10个点对应的窗口中至少部分数据不满足预定条件,并且第n-10个点前面的n-11个点存在连续的11个点对应的窗口中每一个窗口中至少部分数据分别满足预定条件的情况与P(n)无关。
情况12:第n至n-10个点对应的窗口中至少部分数据以(1/2)^11的概率满足预定条件,该情况与P(n)无关。
因此,P(n)=1/2*P(n-1)+(1/2)^2*P(n-2)+……+(1/2)^11*P(n-11)。另一种预设规则:为潜在分割点k确定24个点px、点 px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,x分别为1到24连续的自然数,其中,点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率为3/4,通过这两个因素可以计算P(n)。并且A1=A2=A3=A4=A5=A6=A7=A8=A9=A10=A11=169,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=…=C22=C23=C24,其中,px与潜在分割点k之间距离dx个字节,具体的,p1与潜在分割点k之间距离0个字节,p2与k之间距离1个字节,p3与k之间距离2个字节,p4与k之间距离3个字节,p5与k之间距离4个字节,p6与k之间距离5个字节,p7与k之间距离6个字节,p8与k之间距离7个字节,p9与k之间距离8个字节,…p22与k之间距离21个字节,p23与k之间距离22个字节,p24与k之间距离23个字节,并且p2、p3、p4、p5、p6、p7、p8、p9…p22、p23和p24相对于潜在分割点k均位于数据流分割点查找反方向。因此是否存在连续24个点对应窗口中的每一个窗口中至少部分数据均满足预定条件Cx就决定潜在分割点k是否为数据流分割点,可以通过下面的公式计算:
P(4073)=1,P(4074)=1,……P(,4095)=1,P(4096)=1-(3/4)^24,
P(n)=1/4*P(n-1)+1/4*(3/4)*P(n-2)+……+1/4*(3/4)^23*P(n-24)。
经过计算,P(5*1024)=0.78,P(11*1024)=0.17,P(12*1024)=0.13,即从数据流起始位置/上一数据流分割点查找到12KB后以13%的概率仍未找到数据流分割点,强制进行分割。通过这个概率,求得数据流分割点的密度函数,经过积分求得大约平均在从数据流起始位置/上一数据流分割点查找7.6KB时找到数据流分割点,即平均分块长度大约为7.6KB。与连续的11个点对应的窗口中至少部分数据以1/2的概率 满足预定条件不同,传统CDC算法采用一个窗口以1/2^12的概率满足条件时,方可达到平均分块长度7.6KB的效果。
在图3所示的数据流分割点查找的基础上,在图7所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,x分别为1到11连续的自然数,其中,点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件Cx的概率为1/2,并且A1=A2=A3=A4=A5=A6=A7=A8=A9=A10=A11=169,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11,其中,px与潜在分割点k之间距离dx个字节,具体的,p1与潜在分割点k之间距离2个字节,p2与k之间距离3个字节,p3与k之间距离4个字节,p4与k之间距离5个字节,p5与k之间距离6个字节,p6与k之间距离7个字节,p7与k之间距离8个字节,p8与k之间距离9个字节,p9与k之间距离10个字节,p10与k之间距离1个字节,p11与k之间距离0个字节,并且p1、p2、p3、p4、p5、p6、p7、p8、p9和p10相对于潜在分割点k均位于数据流分割点查找反方向。ka为数据流分割点,图7中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,在最小数据块4KB结束位置作为下一个潜在分割点ki,为潜在分割点ki确定点pix,在本实施例中,根据在去重服务器103上预设的规则,x分别为1到11连续的自然数。在图7所示的实施方式中,依据预定规则,为潜在分割点ki确定的点为11个,分别为pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11,点pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11对应的窗口分别为Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169, pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]和Wi11[pi11-169,pi11]。其中,点pix与潜在分割点ki之间距离dix个字节,具体的,pi1与ki间距2个字节、pi2与ki间距3个字节、pi3与ki间距4个字节、pi4与ki间距5个字节、pi5与ki间距6个字节、pi6与ki间距7个字节、pi7与ki间距8个字节、pi8与ki间距9个字节、pi9与ki间距10个字节、pi10与ki间距1个字节,pi11与ki间距0个字节,并且pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9和pi10相对于潜在分割点ki均位于数据流分割点查找反方向。判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1、判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2、判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11-169,pi11]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足 预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图8所示,Wi3[pi3-169,pi3]中至少部分数据不满足预定条件C3,点pi3沿着数据流分割点查找方向跳跃11个字节为例进行描述。如图8所示,当判断W3不满足预定条件时,以p3为起始点,沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B3‖+maxx(‖Ax‖+‖(ki-pix)‖),在图6所示的实施方式中,跳跃N个字节,具体为不大于179字节,在本实施例中,N=11,在第11个字节的结束位置,获得下一个潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj,根据在去重服务器103上预设的规则,为潜在分割点kj确定的点为11个,分别为pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11,确定点pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11对应的窗口分别为Wj1[pj1-169,pj1]、Wj2[pj2-169,pj2]、Wj3[pj3-169,pj3]、Wj4[pj4-169,pj4]、Wj5[pj5-169,pj5]、Wj6[pj6-169,pj6]、Wj7[pj7-169,pj7]、Wj8[pj8-169,pj8]、Wj9[pj9-169,pj9]、Wj10[pj10-169,pj10]和Wj11[pj11-169,pj11]。其中,pjx与潜在分割点kj之间距离dx个字节,具体的,pj1与kj间距2个字节、pj2与kj间距3个字节、pj3与kj间距4个字节、pj4与kj间距5个字节、pj5与kj间距6个字节、pj6与kj间距7个字节、pj7与kj间距8个字节、pj8与kj间距9个字节、pj9与kj间距10个字节、pj10与kj间距1个字节,pj11与kj间距0个字节,并且pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9和pj10相对于潜在分割点kj均位于数据流分割点查找反方向。判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1、判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2、判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3、判断Wj4[pj4-169,pj4]中至少部分数据是否满 足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11。当然在本发明实施例中,判断潜在分割点ka是否为数据流分割点时也遵循该原则,具体实现不再描述,可以参照判断潜在分割点ki的描述。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜在分割点kj不是数据流分割点时,按照与ki相同的方式跳跃11个字节获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。当然该方法的实施受最大数据块长度和构 成该数据流的文件的大小约束,在此不再赘述。
在图3所示的数据流分割点查找的基础上,在图9所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中A1=A2=A3=A4=A5=A6=A7=A8=A9=A10=A11=169,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11。其中,px与潜在分割点k之间距离dx个字节,具体的,p1与潜在分割点k之间距离3个字节,p2与k之间距离2个字节,p3与k之间距离1个字节,p4与k之间距离0个字节,p5与k之间距离1个字节,p6与k之间距离2个字节,p7与k之间距离3个字节,p8与k之间距离4个字节,p9与k之间距离5个字节,p10与k之间距离6个字节,p11与k之间距离7个字节,并且p5、p6、p7、p8、p9、p10和p11相对于潜在分割点k均位于数据流分割点查找反方向,p1、p2和p3相对于潜在分割点k均位于数据流分割点查找方向。ka为数据流分割点,图9中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,最小数据块4KB结束位置作为下一个潜在分割点ki,为潜在分割点ki确定点pix,在本实施例中,根据在去重服务器103上预设的规则,x分别为1到11连续的自然数。在图9所示的实施方式中,为潜在分割点ki确定的点为11个,分别为pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11,点pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11对应的窗口分别为Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]和Wi11[pi11-169,pi11]。其中,pix与潜在分割点ki之间距离dx个字节,具 体的,pi1与ki间距3个字节、pi2与ki间距2个字节、pi3与ki间距1个字节、pi4与ki间距0个字节、pi5与ki间距1个字节、pi6与ki间距2个字节、pi7与ki间距3个字节、pi8与ki间距4个字节、pi9与ki间距5个字节、pi10与ki间距6个字节,pi11与ki间距7个字节,并且pi5、pi6、pi7、pi8、pi9、pi10和pi11相对于潜在分割点ki均位于数据流分割点查找反方向,pi1、pi2和pi3相对于潜在分割点ki均位于数据流分割点查找方向。判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1、判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2、判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11-169,pi11]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如 图10所示,Wi7[pi7-169,pi7]中至少部分数据不满足对应的预定条件,则从点pi7沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B4‖+maxx(‖Ax‖+‖(ki-pix)‖),在图10所示的实施方式中,跳跃N个字节,具体为不大于179个字节,在本实施例中,具体取N=8,得到新的潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj,根据图9所示的实施方式中在去重服务器103上预设的规则,为潜在分割点kj确定的点为11个,分别为pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11,确定点pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11对应的窗口分别为Wj1[pj1-169,pj1]、Wj2[pj2-169,pj2]、Wj3[pj3-169,pj3]、Wj4[pj4-169,pj4]、Wj5[pj5-169,pj5]、Wj6[pj6-169,pj6]、Wj7[pj7-169,pj7]、Wj8[pj8-169,pj8]、Wj9[pj9-169,pj9]、Wj10[pj10-169,pj10]和Wj11[pj11-169,pj11]。其中,pjx与潜在分割点kj之间距离dx个字节,具体的,pj1与kj间距3个字节、pj2与kj间距2个字节、pj3与kj间距1个字节、pj4与kj间距0个字节、pj5与kj间距1个字节、pj6与kj间距2个字节、pj7与kj间距3个字节、pj8与kj间距4个字节、pj9与kj间距5个字节、pj10与kj间距6个字节,pj11与kj间距7个字节,并且pj5、pj6、pj7、pj8、pj9、pj10和pj11相对于潜在分割点kj均位于数据流分割点查找反方向,pj1、pj2和pj3相对于潜在分割点kj均位于数据流分割点查找方向。判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1、判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2、判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3、判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分 数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11。当然在本发明实施例中,判断潜在分割点ka是否为数据流分割点时也遵循该原则,具体实现不再描述,可以参照判断潜在分割点ki的描述。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜在分割点kj不是数据流分割点时,按照与ki相同的方式跳跃8个字节获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。
在图3所示的数据流分割点查找的基础上,在图11所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k 确定11个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中A1=A2=A3=A4=A5=A6=A7=A8=A9=A10=169,A11=182,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10≠C11。其中,px与潜在分割点k之间距离dx个字节,具体的,p1与潜在分割点k之间距离0个字节,p2与k之间距离1个字节,p3与k之间距离2个字节,p4与k之间距离3个字节,p5与k之间距离4个字节,p6与k之间距离5个字节,p7与k之间距离6个字节,p8与k之间距离7个字节,p9与k之间距离8个字节,p10与k之间距离1个字节,p11与k之间距离3个字节,并且、p2、p3、p4、p5、p6、p7、p8和p9相对于潜在分割点k均位于数据流分割点查找反方向,p10和p11相对于潜在分割点k均位于数据流分割点查找方向。ka为数据流分割点,图11中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,最小数据块4KB结束位置作为下一个潜在分割点ki,为潜在分割点ki确定点pix,在本实施例中,根据在去重服务器103上预设的规则,x分别为1到11连续的自然数。在图11所示的实施方式中,为潜在分割点ki确定的点为11个,分别为pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11,点pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11对应的窗口分别为Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]和Wi11[pi11-182,pi11]。其中,pix与潜在分割点ki之间距离dx个字节,具体的,pi1与ki间距0个字节、pi2与ki间距1个字节、pi3与ki间距2个字节、pi4与ki间距3个字节、pi5与ki间距4个字节、pi6与ki间距5个字节、pi7与ki间距6个字节、pi8与ki间距7个字节、pi9 与ki间距8个字节、pi10与ki间距1个字节,pi11与ki间距3个字节,并且pi2、pi3、pi4、pi5、pi6、pi7、pi8和pi9相对于潜在分割点ki均位于数据流分割点查找反方向,pi10和pi11相对于潜在分割点ki均位于数据流分割点查找方向。判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1、判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2、判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11-169,pi11]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当判断窗口Wi11中至少部分数据不满足预定条件C11时,则从潜在分割点ki沿着数据流分割点查找方向跳跃1个字节,得到新的潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj。当Wi1、Wi2、Wi3、Wi4、Wi5、Wi6、Wi7、Wi8、Wi9和 Wi1010个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图12所示,Wi4[pi4-169,pi4],则从点pi4沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B4‖+maxx(‖Ax‖+‖(ki-pix)‖),在图12所示的实施方式中,跳跃N个字节,具体为不大于179,在本实施例中,具体取N=9,得到新的潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj,根据图11所示的实施方式中在去重服务器103上预设的规则,为潜在分割点kj确定的点为11个,分别为pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11,确定点pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11对应的窗口分别为Wj1[pj1-169,pj1]、Wj2[pj2-169,pj2]、Wj3[pj3-169,pj3]、Wj4[pj4-169,pj4]、Wj5[pj5-169,pj5]、Wj6[pj6-169,pj6]、Wj7[pj7-169,pj7]、Wj8[pj8-169,pj8]、Wj9[pj9-169,pj9]、Wj10[pj10-169,pj10]和Wj11[pj8-182,pj8]。其中,pjx与潜在分割点kj之间距离dx个字节,具体的,pj1与kj间距0个字节、pj2与kj间距1个字节、pj3与kj间距2个字节、pj4与kj间距3个字节、pj5与kj间距4个字节、pj6与kj间距5个字节、pj7与kj间距6个字节、pj8与kj间距7个字节、pj9与kj间距8个字节、pj10与kj间距1个字节,pj11与kj间距3个字节,并且pj2、pj3、pj4、pj5、pj6、pj7、pj8和pj9相对于潜在分割点kj均位于数据流分割点查找反方向,pj10和pj11相对于潜在分割点kj均位于数据流分割点查找方向。判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1、判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2、判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3、判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6 -169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-182,pj11]中至少部分数据是否满足预定条件C11。当然在本发明实施例中,判断潜在分割点ka是否为数据流分割点时也遵循该原则,具体实现不再描述,可以参照判断潜在分割点ki的描述。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜在分割点kj不是数据流分割点时,按照与ki相同的方式获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。
在图3所示的数据流分割点查找的基础上,在图13所示的实施方式中,在去重服务器103上预设有规则为:为潜在分割点k确定11个点 px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,x分别为1到11连续的自然数,其中,点px对应的窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件的概率为1/2,并且A1=A2=A3=A4=A5=A6=A7=A8=A9=A10=A11=169,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11,其中,px与潜在分割点k之间距离dx个字节,具体的,p1与潜在分割点k之间距离0个字节,p2与k之间距离2个字节,p3与k之间距离4个字节,p4与k之间距离6个字节,p5与k之间距离8个字节,p6与k之间距离10个字节,p7与k之间距离12个字节,p8与k之间距离14个字节,p9与k之间距离16个字节,p10与k之间距离18个字节,p11与k之间距离20个字节,并且p2、p3、p4、p5、p6、p7、p8、p9、p10和p11相对于潜在分割点k均位于数据流分割点查找反方向。ka为数据流分割点,图13中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,在最小数据块4KB结束位置作为下一个潜在分割点ki,为潜在分割点ki确定点pix,在本实施例中,根据在去重服务器103上预设的规则,x分别为1到11连续的自然数。在图13所示的实施方式中,依据预定规则,为潜在分割点ki确定的点为11个,分别为pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11,点pi1、pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11对应的窗口分别为Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]和Wi11[pi11-169,pi11]。其中,pix与潜在分割点ki之间距离dx个字节,具体的,pi1与ki间距0个字节、pi2与ki间距2个字节、pi3与ki间距4个字节、pi4与ki间距6个字节、pi5与ki间距8个字节、pi6与ki间 距10个字节、pi7与ki间距12个字节、pi8与ki间距14个字节、pi9与ki间距16个字节、pi10与ki间距18个字节,pi11与ki间距20个字节,并且pi2、pi3、pi4、pi5、pi6、pi7、pi8、pi9、pi10和pi11相对于潜在分割点ki均位于数据流分割点查找反方向。判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1、判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2、判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11-169,pi11]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图14所示,Wi4[pi4-169,pi4]中至少部分数据不满足预定条件C4,则选择下一个潜在分割点,为与潜在分割点ki区别,这里表示为kj,kj位于ki右边,并且kj与ki间距1 个字节。如图14所示,依据在去重服务器103上预设的规则,为潜在分割点kj确定11个点,分别为pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11,确定点pj1、pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11对应的窗口分别为Wj1[pj1-169,pj1]、Wj2[pj2-169,pj2]、Wj3[pj3-169,pj3]、Wj4[pj4-169,pj4]、Wj5[pj5-169,pj5]、Wj6[pj6-169,pj6]、Wj7[pj7-169,pj7]、Wj8[pj8-169,pj8]、Wj9[pj9-169,pj9]、Wj10[pj10-169,pj10]和Wj11[pj11-169,pj11],其中,A1=A2=A3=A4=A5=A6=A7=A8=A9=A10=A11=169,B1=B2=B3=B4=B5=B6=B7=B8=B9=B10=B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11。其中,pjx与潜在分割点kj之间距离dx个字节,具体的,pj1与kj间距0个字节、pj2与kj间距2个字节、pj3与kj间距4个字节、pj4与kj间距6个字节、pj5与kj间距8个字节、pj6与kj间距10个字节、pj7与kj间距12个字节、pj8与kj间距14个字节、pj9与kj间距16个字节、pj10与kj间距18个字节,pj11与kj间距20个字节,并且pj2、pj3、pj4、pj5、pj6、pj7、pj8、pj9、pj10和pj11相对于潜在分割点kj均位于数据流分割点查找反方向。判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1、判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2、判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3、判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足 预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点。当判断窗口Wj1、Wj2、Wj3、Wj4、Wj5、Wj6、Wj7、Wj8、Wj9、Wj10和Wj11中任一个窗口中至少部分数据不满足预定条件时,如图15所示,Wj3[pj3-169,pj3]中至少部分数据不满足预定条件C3时,点pi4相对于数据流分割点查找方向位于点pj3左边,从点pi4沿着数据流分割点查找方向跳跃21个字节,获得下一个潜在分割点,为与潜在分割点ki、kj相区别,表示为kl。根据图13所实施方式中在去重服务器103上预设的规则,为潜在分割点kl确定的点为11个,分别为pl1、pl2、pl3、pl4、pl5、pl6、pl7、pl8、pl9、pl10和pl11,点pl1、pl2、pl3、pl4、pl5、pl6、pl7、pl8、pl9、pl10和pl11对应的窗口分别为Wl1[pl1-169,pl1]、Wl2[pl2-169,pl2]、Wl3[pl3-169,pl3]、Wl4[pl4-169,pl4]、Wl5[pl5-169,pl5]、Wl6[pl6-169,pl6]、Wl7[pl7-169,pl7]、Wl8[pl8-169,pl8]、Wl9[pl9-169,pl9]、Wl10[pl10-169,pl10]和Wl11[pl11-169,pl11],其中,plx与潜在分割点kl之间距离dx个字节,具体的,pl1与潜在分割点kl之间距离0个字节,pl2与kl之间距离2个字节,pl3与kl之间距离4个字节,pl4与kl之间距离6个字节,pl5与kl之间距离8个字节,pl6与kl之间距离10个字节,pl7与kl之间距离12个字 节,pl8与kl之间距离14个字节,pl9与kl之间距离16个字节,pl10与kl之间距离18个字节,pl11与kl之间距离20个字节,并且pl2、pl3、pl4、pl5、pl6、pl7、pl8、pl9、pl10和pl11相对于潜在分割点kl均位于数据流分割点查找反方向。判断Wl1[pl1-169,pl1]中至少部分数据是否满足预定条件C1、判断Wl2[pl2-169,pl2]中至少部分数据是否满足预定条件C2、判断Wl3[pl3-169,pl3]中至少部分数据是否满足预定条件C3、判断Wl4[pl4-169,pl4]中至少部分数据是否满足预定条件C4、判断Wl5[pl5-169,pl5]中至少部分数据是否满足预定条件C5、判断Wl6[pl6-169,pl6]中至少部分数据是否满足预定条件C6、判断Wl7[pl7-169,pl7]中至少部分数据是否满足预定条件C7、判断Wl8[pl8-169,pl8]中至少部分数据是否满足预定条件C8、判断Wl9[pl9-169,pl9]中至少部分数据是否满足预定条件C9、判断Wl10[pl10-169,pl10]中至少部分数据是否满足预定条件C10和判断Wl11[pl11-169,pl11]中至少部分数据是否满足预定条件C11。当判断窗口Wl1中至少部分数据满足预定条件C1、窗口Wl2中至少部分数据满足预定条件C2、窗口Wl3中至少部分数据满足预定条件C3、窗口Wl4中至少部分数据满足预定条件C4、窗口Wl5中至少部分数据满足预定条件C5、窗口Wl6中至少部分数据满足预定条件C6、窗口Wl7中至少部分数据满足预定条件C7、窗口Wl8中至少部分数据满足预定条件C8、窗口Wl9中至少部分数据满足预定条件C9、窗口Wl10中至少部分数据满足预定条件C10和窗口Wl11中至少部分数据满足预定条件C11时,则当前潜在分割点kl为数据流分割点。当窗口Wl1、Wl2、Wl3、Wl4、Wl5、Wl6、Wl7、Wl8、Wl9、Wl10和Wl11中任一窗口中至少部分数据不满足预定条件时,选择下一个潜在分割点,为与潜在分割点ki、kj和kl区别,表示为km,km位于kl右边,并且km与kl间距1个字节。根据图13所示实施 例在去重服务器103上预设的规则,为潜在分割点km确定的点为11个,分别为pm1、pm2、pm3、pm4、pm5、pm6、pm7、pm8、pm9、pm10和pm11,点pm1、pm2、pm3、pm4、pm5、pm6、pm7、pm8、pm9、pm10和pm11对应的窗口分别为Wm1[pm1-169,pm1]、Wm2[pm2-169,pm2]、Wm3[pm3-169,pm3]、Wm4[pm4-169,pm4]、Wm5[pm5-169,pm5]、Wm6[pm6-169,pm6]、Wm7[pm7-169,pm7]、Wm8[pm8-169,pm8]、Wm9[pm9-169,pm9]、Wm10[pm10-169,pm10]和Wm11[pm11-169,pm11],其中,pmx与潜在分割点km之间距离dx个字节,具体的,pm1与潜在分割点km之间距离0个字节,pm2与km之间距离2个字节,pm3与km之间距离4个字节,pm4与km之间距离6个字节,pm5与km之间距离8个字节,pm6与km之间距离10个字节,pm7与km之间距离12个字节,pm8与km之间距离14个字节,pm9与km之间距离16个字节,pm10与km之间距离18个字节,pm11与km之间距离20个字节,并且pm2、pm3、pm4、pm5、pm6、pm7、pm8、pm9、pm10和pm11相对于潜在分割点km均位于数据流分割点查找反方向。判断Wm1[pm1-169,pm1]中至少部分数据是否满足预定条件C1、判断Wm2[pm2-169,pm2]中至少部分数据是否满足预定条件C2、判断Wm3[pm3-169,pm3]中至少部分数据是否满足预定条件C3、判断Wm4[pm4-169,pm4]中至少部分数据是否满足预定条件C4、判断Wm5[pm5-169,pm5]中至少部分数据是否满足预定条件C5、判断Wm6[pm6-169,pm6]中至少部分数据是否满足预定条件C6、判断Wm7[pm7-169,pm7]中至少部分数据是否满足预定条件C7、判断Wm8[pm8-169,pm8]中至少部分数据是否满足预定条件C8、判断Wm9[pm9-169,pm9]中至少部分数据是否满足预定条件C9、判断Wm10[pm10-169,pm10]中至少部分数据是否满足预定条件C10和判断Wm11[pm11-169,pm11]中至少部分数据是否满足预定条件C11。当判断窗口Wm1中至少部分数据满 足预定条件C1、窗口Wm2中至少部分数据满足预定条件C2、窗口Wm3中至少部分数据满足预定条件C3、窗口Wm4中至少部分数据满足预定条件C4、窗口Wm5中至少部分数据满足预定条件C5、窗口Wm6中至少部分数据满足预定条件C6、窗口Wm7中至少部分数据满足预定条件C7、窗口Wm8中至少部分数据满足预定条件C8、窗口Wm9中至少部分数据满足预定条件C9、窗口Wm10中至少部分数据满足预定条件C10和窗口Wm11中至少部分数据满足预定条件C11时,则当前潜在分割点km为数据流分割点。当任一个窗口中至少部分数据不满足预定条件时,则按照前面描述的方案执行跳跃,以获得下一个潜在分割点并判断是否为数据流分割点。
本发明实施例提供了一种判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz的方法,本实施例中使用随机函数判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz,以图5所示的实施方式为例,根据在去重服务器103上预设的规则,为潜在分割点ki确定点pi1及点pi1对应的窗口Wi1[pi1-169,pi1],判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定的条件C1,如图16所示,Wi1表示窗口Wi1[pi1-169,pi1],为判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,选择5个字节,图16中“■”表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。其中每个字节由8位组成,记为am,1…am,8,表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当 am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,255个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,可以表示为: 选取大量随机数,组成矩阵,由随机数据组成的矩阵一旦组成,保持不变,如从服从特定分布(这里以正态分布为例)的随机数中选择255*8个随机数组成矩阵R: 将矩阵Va的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8。根据该方法,获得Sa1、Sa2…到Sa255,统计Sa1、Sa2…到Sa255中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sam与矩阵R一样,仍然服从正态分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sa1、Sa2…到Sa255中,每个值大于0的概率为1/2,所以K满足二项分布:根据统计结果,判断Sa1、Sa2…到Sa255的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1;当K为奇数时,表明Wi1[pi1-169,pi1]中至少部分数据不满足预定条件C1,这里C1即指根据上述方式获得的Sa1、Sa2…到Sa255的值大于0的个数K为偶数。在图5所示的实施方式中,在Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169, pi10]和Wi11[pi11-169,pi11]中,各窗口大小相同,即窗口大小均为169字节,同时判断窗口中至少部分数据是否满足预定条件的方式也相同,具体见上述判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的描述。因此,如图16所示,表示判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。其中每个字节由8位组成,记为bm,1…bm,8,表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为:当bm,n=1时,Vbm,n=1,当bm,n=0时,Vbm,n=-1,其中bm,n表示bm,1…bm,8中的任一个,255个字节对应的位按照bm,n与Vbm,n的转换关系得到矩阵Vb,可以表示为:判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件的方式与判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件的方式相同,因此使用矩阵R:将矩阵Vb的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sbm=Vbm,1*hm,1+Vbm,2*hm,2+…+Vbm,8*hm,8。根据该方法,获得Sb1、Sb2…到Sb255,统计Sb1、Sb2…到Sb255中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sbm与矩阵R一样,仍然服从正态 分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sb1、Sb2…到Sb255中,每个值大于0的概率为1/2,所以K满足二项分布: 根据统计结果,判断Sb1、Sb2…到Sb255的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2;当K为奇数时,表明Wi2[pi2-169,pi2]中至少部分数据不满足预定条件C2,这里C2即指根据上述方式获得的Sb1、Sb2…到Sb255的值大于0的个数K为偶数。图3所示的实施方式中,Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2。
因此,如图16所示,表示判断窗口Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。然后使用判断窗口Wi1[pi1-169,pi1]和Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件的方法,判断Wi3[pi3-169,pi3]中至少数据是否满足预定条件C3。图5所示的实施方式中,Wi3[pi3-169,pi3]中至少部分数据满足预定条件。如图16所示,表示判断窗口Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。然后使用判断窗口Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]和Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件的方法,判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4。图5所示的实施方式中,Wi4[pi4-169,pi4]中至少部分数据满足预定条件C4。如图16所示,表示判断窗口Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5时选择的1个字节,相邻两个选择的字节 之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。然后使用判断窗口Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]和Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件的方法,判断Wi5[pi5-169,pi5]中至少数据是否满足预定条件C5。图5所示的实施方式中,Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5。
当Wi5[pi5-169,pi5]中至少部分数据不满足预定条件时C5,从点pi5沿着数据流分割点查找方向跳跃11个字节,在第11个字节的结束位置获得下一个潜在分割点kj,如图6所示,根据在去重服务器103上预设的规则,为潜在分割点kj确定点pj1、点pj1对应的窗口Wj1[pj1-169,pj1],判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此如图17所示,Wj1表示窗口Wj1[pj1-169,pj1],为判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1,选择5个字节,图17中“■”表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。其中每个字节由8位组成,记为am,1'…am,8',表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为: 当am,n'=1时,Vam,n'=1,当am,n'=0时,Vam,n'=-1,其中am,n'表示am,1'…am,8'中的任一个,255个字节对应的位按照am,n'与 Vam,n'的转换关系得到矩阵Va',可以表示为:判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定的条件与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定的条件的方式相同,因此使用矩阵R:将矩阵Va'的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam'=Vam,1'*hm,1+Vam,2'*hm,2+…+Vam,8'*hm,8。根据该方法,获得Sa1'、Sa2'…到Sa255',统计Sa1'、Sa2'…到Sa255'中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sam'与矩阵R一样,仍然服从正态分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sa1'、Sa2'…到Sa255'中,每个值大于0的概率为1/2,所以K满足二项分布: 根据统计结果,判断Sa1'、Sa2'…到Sa255'的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明Wj1[pj1-169,pj1]中至少部分数据满足预定条件C1;当K为奇数时,表明Wj1[pj1-169,pj1]中至少部分数据不满足预定条件C1。
判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式和判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2的方式相同,因此,如图17所示,表示判断窗口Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字 节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。其中每个字节由8位组成,记为bm,1'…bm,8',表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为:当bm,n'=1时,Vbm,n'=1,当bm,n'=0时,Vbm,n'=-1,其中bm,n'表示bm,1'…bm,8'中的任一个,255个字节对应的位按照bm,n'与Vbm,n'的转换关系得到矩阵Vb',可以表示为: 窗口W2[p2-169,p2]和W2[q2-169,q2]中至少部分数据是否满足预定条件的方式相同,因此仍使用矩阵R: 将矩阵Vb'的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sbm'=Vbm,1'*hm,1+Vbm,2'*hm,2+…+Vbm,8'*hm,8。根据该方法,获得Sb1'、Sb2'…到Sb255',统计Sb1'、Sb2'…到Sb255'中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sbm'与矩阵R一样,仍然服从正态分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sb1'、Sb2'…到Sb255'中,每个值大于0的概率为1/2,所以K满足二项分布: 根据统计结果,判断Sb1'、Sb2'…到Sb255'的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明Wj2[pj2 -169,pj2]中至少部分数据满足预定条件C2;当K为奇数时,表明Wj2[pj2-169,pj2]中至少部分数据不满足预定条件C2。同理,判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3的方式与判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11,在此不再赘述。
仍然以图5所示实施方式为例,提供了一种判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz的方法,本实施例中使用随机函数判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz,根据在去重服务器103上预设的规则,为潜在分割点ki确定点pi1及pi1对应的窗口Wi1[pi1-169,pi1],判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定的条件C1,如图16所示,Wi1表示窗口Wi1[pi1-169,pi1],为判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,选择5个字节,图16中“■”表示选择的1个字节,相邻两个选择“■”的字节之间相差42个字节。其中一种实现方式为使用HASH函数计算选择的5个字节,使用HASH函数计算得到的数值是一个固定均匀分布,如果使用HASH函数计算得到的数值为偶数,则判断Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1,即C1表示根据上述方式使用HASH 函数计算得到的数值为偶数。因此,Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件的概率为1/2。在图5所示的实施方式中,使用Hash函数判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2、Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4和Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5,具体实现可参考描述图5所示实施方式使用Hash函数判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件的方式C1,在此不再赘述。
当Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5时,从点pi5沿着数据流分割点查找方向跳跃11个字节,在第11个字节的结束位置获得当前潜在分割点kj,如图6所示,根据在去重服务器103上预设的规则,为潜在分割点kj确定点pj1、点pj1对应的窗口Wj1[pj1-169,pj1],判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此如图17所示,Wj1表示窗口Wj1[pj1-169,pj1],为判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1,选择5个字节,图17中“■”表示选择的1个字节,相邻两个选择的字节“■”之间相差42个字节。使用Hash函数计算从窗口Wj1[pj1-169,pj1]中选取的5个字节,如果得到的数值为偶数,则Wj1[pj1-169,pj1]中至少部分数据满足预定条件C1。图17中,判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式和判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2的方式相同,因此,如图17所示,表示判断窗口Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两 个选择的字节之间相差42个字节。使用Hash函数计算选择的5个字节,如果得到的数值为偶数,则Wj2[pj2-169,pj2]中至少部分数据满足预定条件C2。图17中,判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3的方式与判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3的方式相同,因此,如图17所示,表示判断窗口Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3时选择的1个字节,相邻两个选择的字节“”之间相差42个字节。使用Hash函数计算选择的5个字节,得到的数值为偶数,则Wj3[pj3-169,pj3]中至少部分数据满足预定条件C3。图17中,判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4的方式和判断窗口Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4的方式,因此,如图17所示,表示判断窗口Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4时选择的1个字节,相邻两个选择的字节之间相差42个字节。使用Hash函数计算选择的5个字节,得到的数值为偶数,则Wj4[pj4-169,pj4]中至少部分数据满足预定条件C4。根据上述方法,判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11,在此不再赘述。
以图5所示的实施方式为例,提供了一种判断窗口Wiz[piz-Az,piz +Bz]中至少部分数据是否满足预定条件Cz的方法,本实施例中使用随机函数判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz,根据在去重服务器103上预设的规则,为潜在分割点ki确定点pi1及pi1对应的窗口Wi1[pi1-169,pi1],判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,如图16所示,Wi1表示窗口Wi1[pi1-169,pi1],为判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,选择5个字节,图16中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1、a2、a3、a4和a5。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1、a2、a3、a4和a5中的任一个ar均满足0≤ar≤255。a1、a2、a3、a4和a5组成1*5的矩阵。从服从二项分布的随机数中选择256*5个随机数,组成矩阵R,表示为:
根据a1的值和所在的列,从矩阵R中查找对应的值,如a1=36,a1位于第1列,则查找h36,1对应的值;根据a2的值和所在的列,从矩阵R中查找对应的值,如a2=48,a2位于第2列,则查找h48,2对应的值;根据a3的值和所在的列,从矩阵R中查找对应的值,如a3=26,a3位于第3列,则查找h26,3对应的值;根据a4的值和所在的列,从矩阵R中查找对应的值,如a4=26,a4位于第4列,则查找h26,4对应的值;根据a5的值和所在的列,从矩阵R中查找对应的值,如a5=88,a5位于第5列,则查找h88,5对应的值。S1=h36,1+h48,2+h26,3+h26,4+h88,5,因为矩阵R服从二项分布,因此,S1也服从二项分布。当S1为偶数,则Wi1[pi1-169,pi1] 中至少部分数据满足预定条件C1,当S1为奇数,则Wi1[pi1-169,pi1]中至少部分数据不满足预定条件C1,S1为偶数的概率为1/2,C1表示按上述方式计算S1为偶数。在图5所示实施例中,Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1。如图16所示,表示判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2时分别选择的1个字节,在图16中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1、b2、b3、b4和b5。因为1个字节由8位组成,所以每个字节作为一个数值,则b1、b2、b3、b4和b5中的任一个br均满足0≤br≤255。b1、b2、b3、b4和b5组成1*5的矩阵。本实施方式中,判断Wi1和Wi2中至少部分数据是否满足预定条件的方式相同,因此仍然使用矩阵R,根据b1的值和所在的列,从矩阵R中查找对应的值,如b1=66,b1位于第1列,则查找h66,1对应的值;根据b2的值和所在的列,从矩阵R中查找对应的值,如b2=48,b2位于第2列,则查找h48,2对应的值;根据b3的值和所在的列,从矩阵R中查找对应的值,如b3=99,b3位于第3列,则查找h99,3对应的值;根据b4的值和所在的列,从矩阵R中查找对应的值,如b4=26,b4位于第4列,则查找h26,4对应的值;根据b5的值和所在的列,从矩阵R中查找对应的值,如b5=90,b5位于第5列,则查找h90,5对应的值。S2=h66,1+h48,2+h99,3+h26,4+h90,5,因为矩阵R服从二项分布,因此,S2也服从二项分布。当S2为偶数,则Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2,当S2为奇数,则Wi2[pi2-169,pi2]中至少部分数据不满足预定条件C2,S2为偶数的概率为1/2。在图5所示实施例中,Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2。使用同样的规则,分别判断Wi3[pi3-169,pi3]中至少部分数据是否满足 预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11-169,pi11]中至少部分数据是否满足预定条件C11。图5所示的实施方式中,Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5,从点pi5沿着数据流分割点查找方向跳跃11个字节,在第11个字节的结束位置获得当前潜在分割点kj,如图6所示,根据在去重服务器103上预设的规则,为潜在分割点kj确定点pj1、点pj1对应的窗口Wj1[pj1-169,pj1],判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此如图17所示,Wj1表示窗口Wj1[pj1-169,pj1],为判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1,图17中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1'、a2'、a3'、a4'和a5'。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1'、a2'、a3'、a4'和a5'中的任一个ar'均满足0≤ar'≤255。a1'、a2'、a3'、a4'和a5'组成1*5的矩阵。判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此,仍然使用矩阵 R,表示为:
根据a1'的值和所在的列,从矩阵R中查找对应的值,如a1'=16,a1'位于第1列,则查找h16,1对应的值;根据a2'的值和所在的列,从矩阵R中查找对应的值,如a2'=98,a2'位于第2列,则查找h98,2对应的值;根据a3'的值和所在的列,从矩阵R中查找对应的值,如a3'=56,a3'位于第3列,则查找h56,3对应的值;根据a4'的值和所在的列,从矩阵R中查找对应的值,如a4'=36,a4'位于第4列,则查找h36,4对应的值;根据a5'的值和所在的列,从矩阵R中查找对应的值,如a5'=99,a5'位于第5列,则查找h99,5对应的值。S1'=h16,1+h98,2+h56,3+h36,4+h99,5,因为矩阵R服从二项分布,因此,S1'也服从二项分布。当S1'为偶数,则Wj1[pj1-169,pj1]中至少部分数据满足预定条件C1,当S1'为奇数,则Wj1[pj1-169,pj1]中至少部分数据不满足预定条件C1,S1'为偶数的概率为1/2。
判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式和判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2的方式相同,因此,如图17所示,表示判断窗口Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1'、b2'、b3'、b4'和b5'。因为1个字节由8位组成,所以每个字节作为一个数值,则b1'、b2'、b3'、b4'和b5'中的任一个br'均满足0≤br'≤255。b1'、b2'、b3'、b4'和b5'组成1*5的矩阵。与判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满 足预定条件C2使用相同的矩阵R,根据b1'的值和所在的列,从矩阵R中查找对应的值,如b1'=210,b1'位于第1列,则查找h210,1对应的值;根据b2'的值和所在的列,从矩阵R中查找对应的值,如b2'=156,b2'位于第2列,则查找h156,2对应的值;根据b3'的值和所在的列,从矩阵R中查找对应的值,如b3'=144,b3'位于第3列,则查找h144,3对应的值;根据b4'的值和所在的列,从矩阵R中查找对应的值,如b4'=60,b4'位于第4列,则查找h60,4对应的值;根据b5'的值和所在的列,从矩阵R中查找对应的值,如b5'=90,b5'位于第5列,则查找h90,5对应的值。S2'=h210,1+h156,2+h144,3+h60,4+h90,5,与S2的判断条件相同,当S2'为偶数,则Wj2[pj2-169,pj2]中至少部分数据满足预定条件C2,当S2'为奇数,则Wj2[pj2-169,pj2]中至少部分数据不满足预定条件C2,S2'为偶数的概率为1/2。
同理,判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3的方式与判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11,在此不再赘述。
以图5所示的实施方式为例,提供了一种判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz的方法,本实施例中使用随机函数判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定 条件Cz,根据在去重服务器103上预设的规则,为潜在分割点ki确定点pi1及pi1对应的窗口Wi1[pi1-169,pi1],判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定的条件C1,如图16所示,Wi1表示窗口Wi1[pi1-169,pi1],为判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,选择5个字节,图16中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1、a2、a3、a4和a5。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1、a2、a3、a4和a5中的任一个as均满足0≤as≤255。a1、a2、a3、a4和a5组成1*5的矩阵。从服从二项分布的随机数中选择256*5个随机数,组成矩阵R,表示为:从服从二项分布的随机数中选择256*5个随机数,组成矩阵G,表示为:
根据a1的值和所在的列,如a1=36,a1位于第1列,则从矩阵R中查找查找h36,1对应的值,从矩阵G中查找g36,1对应的值;根据a2的值和所在的列,如a2=48,a2位于第2列,则从矩阵R中查h48,2对应的值,从矩阵G中查找g48,2对应的值;根据a3的值和所在的列,如a3=26,a3位于第3列,则从矩阵R中查找h26,3对应的值,从矩阵G中查找g26,3对应的值;根据a4的值和所在的列,如a4=26,a4位于第4列,则从矩阵R中查找h26,4对应的值,从矩阵G中查找g26,4对应的值;根据a5的值和 所在的列,如a5=88,a5位于第5列,则从矩阵R中查找h88,5对应的值,从矩阵G中查找g88,5对应的值。S1h=h36,1+h48,2+h26,3+h26,4+h88,5,因为矩阵R服从二项分布,因此,S1h也服从二项分布;S1g=g36,1+g48,2+g26,3+g26,4+g88,5,因为矩阵G服从二项分布,因此S1g也服从二项分布。当S1h和S1g中有1个为偶数,则Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1,当S1h和S1g均为奇数,则Wi1[pi1-169,pi1]中至少部分数据不满足预定条件C1,C1表述按照上述方法获得的S1h和S1g中有1个为偶数。因为S1h和S1g均服从二项分布,因此S1h为偶数的概率为1/2,S1g为偶数的概率为1/2,S1h和S1g中有1个为偶数的概率为1-1/4=3/4,因此,Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1的概率为3/4。在图5所示实施例中,Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1。在图5所示的实施方式中,在Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]和Wi11[pi11-169,pi11]中,各窗口大小相同,即窗口大小均为169字节,同时判断窗口中至少部分数据是否满足预定条件的方式也相同,具体见上述判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的描述。因此,如图16所示,表示判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2时分别选择的1个字节,在图16中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1、b2、b3、b4和b5。因为1个字节由8位组成,所以每个字节作为一个数值,则b1、b2、b3、b4和b5中的任一个bs均满足0≤bs≤255。b1、b2、b3、b4 和b5组成1*5的矩阵。本实施方式中,判断各窗口中至少部分数据是否满足预定条件的方式相同,因此仍然使用相同矩阵R和G。根据b1的值和所在的列,如b1=66,b1位于第1列,则从矩阵R中查找h66,1对应的值,从矩阵G中查找g66,1对应的值;根据b2的值和所在的列,如b2=48,b2位于第2列,则从矩阵R中查找h48,2对应的值,从矩阵G中查找g48,2对应的值;根据b3的值和所在的列,如b3=99,b3位于第3列,则从矩阵R中查找h99,3对应的值,从矩阵G中查找g99,3对应的值;根据b4的值和所在的列,如b4=26,b4位于第4列,则从矩阵R中查找h26,4对应的值,从矩阵G中查找g26,4对应的值;根据b5的值和所在的列,如b5=90,b5位于第5列,则从矩阵R中查找h90,5对应的值,从矩阵G中查找g90,5对应的值。S2h=h66,1+h48,2+h99,3+h26,4+h90,5,因为矩阵R服从二项分布,因此,S2h也服从二项分布。S2g=g66,1+g48,2+g99,3+g26,4+g90,5,因为矩阵G服从二项分布,因此,S2g也服从二项分布。当S2h和S2g中有1个为偶数,则Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2,当S2h和S2g均为奇数,则Wi2[pi2-169,pi2]中至少部分数据不满足预定条件C2,S2h和S2g中有1个为偶数的概率为3/4。在图5所示实施例中,Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2。使用同样的规则,分别判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11 -169,pi11]中至少部分数据是否满足预定条件C11。图5所示的实施方式中,Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5,从点pi5沿着数据流分割点查找方向跳跃11个字节,在第11个字节的结束位置获得当前潜在分割点kj,如图6所示,根据在去重服务器103上预设的规则,为潜在分割点kj确定点pj1、点pj1对应的窗口Wj1[pj1-169,pj1],判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此如图17所示,Wj1表示窗口Wj1[pj1-169,pj1],为判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1,图17中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1'、a2'、a3'、a4'和a5'。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1'、a2'、a3'、a4'和a5'中的任一个as'均满足0≤as'≤255。a1'、a2'、a3'、a4'和a5'组成1*5的矩阵。使用与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1相同的矩阵R和G,分别表示为: 和
根据a1'的值和所在的列,如a1'=16,a1'位于第1列,则从矩阵R中查找h16,1对应的值,从矩阵G中查找g16,1对应的值;根据a2'的值和所在的列,如a2'=98,a2'位于第2列,则从矩阵R中查找h98,2对应的值,从矩阵G中查找g98,2对应的值;根据a3'的值和所在的列,如a3'=56,a3'位于第3列,则从矩阵R中查找h56,3对应的值,从矩阵G中查找g56,3对应的 值;根据a4'的值和所在的列,如a4'=36,a4'位于第4列,则从矩阵R中查找h36,4对应的值,从矩阵G中查找g36,4对应的值;根据a5'的值和所在的列,如a5'=99,a5'位于第5列,则从矩阵R中查找h99,5对应的值,从矩阵G中查找g99,5对应的值。S1h'=h16,1+h98,2+h56,3+h36,4+h99,5,因为矩阵R服从二项分布,因此,S1h'也服从二项分布;S1g'=g16,1+g98,2+g56,3+g36,4+g99,5,因为矩阵G服从二项分布,因此S1g'也服从二项分布。当S1h'和S1g'中有1个为偶数,则Wj1[pj1-169,pj1]中至少部分数据满足预定条件C1,当S1h'和S1g'均为奇数,则Wj1[pj1-169,pj1]中至少部分数据不满足预定条件C1,S1h'和S1g'有1个为偶数的概率为3/4。
判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式和判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2的方式相同,因此,如图17所示,表示判断窗口Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。在图17中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1'、b2'、b3'、b4'和b5'。因为1个字节由8位组成,所以每个字节作为一个数值,则b1'、b2'、b3'、b4'和b5'中的任一个bs'均满足0≤bs'≤255。b1'、b2'、b3'、b4'和b5'组成1*5的矩阵。使用与判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2相同的矩阵R和G,根据b1'的值和所在的列,如b1'=210,b1'位于第1列,则从矩阵R中查找h210,1对应的值,从矩阵G中查找g210,1对应的值;根据b2'的值和所在的列,如b2'=156,b2'位于第2列,则从矩阵R中查找h156,2对应的值,从矩阵G中查 找g156,2对应的值;根据b3'的值和所在的列,如b3'=144,b3'位于第3列,则从矩阵R中查找h144,3对应的值,从矩阵G中查找g144,3对应的值;根据b4'的值和所在的列,如b4'=60,b4'位于第4列,则从矩阵R中查找h60,4对应的值,从矩阵G中查找g60,4对应的值;根据b5'的值和所在的列,如b5'=90,b5'位于第5列,则从矩阵R中查找h90,5对应的值,从矩阵G中查找g90,5对应的值。S2h'=h210,1+h156,2+h144,3+h60,4+h90,5,S2g'=g210,1+g156,2+g144,3+g60,4+g90,5。当S2h'和S2g'中有1个为偶数,则Wj2[pj2-169,pj2]中至少部分数据满足预定条件C2,当S2h'和S2g'均为奇数,则Wj2[pj2-169,pj2]中至少部分数据不满足预定条件C2,S2h'和S2g'中有1个为偶数的概率为3/4。
同理,判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3的方式与判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11,在此不再赘述。
以图5所示的实施方式为例,提供了一种判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz的方法,本实施例中使用随机函数判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz,根据在去重服务器103上预设的规则,为潜在分割点ki确定 点pi1及pi1对应的窗口Wi1[pi1-169,pi1],判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定的条件C1,如图16所示,Wi1表示窗口Wi1[pi1-169,pi1],为判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,选择5个字节,图16中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”依次看成40个位,分别表示为a1、a2、a3、a4…a40。a1、a2、a3、a4…a40中的任一at,当at=0时,Vat=-1,当at=1时,Vat=1,根据at与Vat对应关系,生成Va1、Va2、Va3、Va4…Va40。从服从正态分布的随机数中选择40个随机数,分别表示为:h1、h2、h3、h4...h40。Sa=Va1*h1+Va2*h2+Va3*h3+Va4*h4+…+Va40*h40。因为h1、h2、h3、h4...h40服从正态分布,因此,Sa也服从正态分布。当Sa为正数,则Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1,当Sa为负数或0,则Wi1[pi1-169,pi1]中至少部分数据不满足预定条件C1,Sa为正数的概率为1/2。在图5所示实施例中,Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1。如图16所示,表示判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2时分别选择的1个字节,在图16中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节依次看成40个位,分别表示为b1、b2、b3、b4…b40。b1、b2、b3、b4…b40中的任一bt,当bt=0时,Vbt=-1,当bt=1时,Vbt=1,根据bt与Vbt对应关系,生成Vb1、Vb2、Vb3、Vb4…Vb40。判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式相同,因此,使用相同的随机数:h1、h2、h3、h4...h40,Sb=Vb1*h1+Vb2*h2+Vb3*h3+Vb4*h4+…+Vb40*h40。因 为h1、h2、h3、h4...h40服从正态分布,因此,Sb也服从正态分布。当Sb为正数,则Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2,当Sb为负数或0,则Wi2[pi2-169,pi2]中至少部分数据不满足预定条件C2,Sb为正数的概率为1/2。在图5所示实施例中,Wi2[pi2-169,pi2]中至少部分数据满足预定条件C2。使用同样的规则,分别判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5、判断Wi6[pi6-169,pi6]中至少部分数据是否满足预定条件C6、判断Wi7[pi7-169,pi7]中至少部分数据是否满足预定条件C7、判断Wi8[pi8-169,pi8]中至少部分数据是否满足预定条件C8、判断Wi9[pi9-169,pi9]中至少部分数据是否满足预定条件C9、判断Wi10[pi10-169,pi10]中至少部分数据是否满足预定条件C10和判断Wi11[pi11-169,pi11]中至少部分数据是否满足预定条件C11。图5所示的实施方式中,Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5,从点pi5沿着数据流分割点查找方向跳跃11个字节,在第11个字节的结束位置获得当前潜在分割点kj,如图6所示,根据在去重服务器103上预设的规则,为潜在分割点kj确定点pj1、点pj1对应的窗口Wj1[pj1-169,pj1],判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此如图17所示,Wj1表示窗口Wj1[pj1-169,pj1],为判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1,为判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1,选择5个字节,图17中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”依 次看成40个位,分别表示为a1'、a2'、a3'、a4'…a40'。a1'、a2'、a3'、a4'…a40'中的任一at',当at'=0时,Vat'=-1,当at'=1时,Vat'=1,根据at'与Vat'对应关系,生成Va1'、Va2'、Va3'、Va4'…Va40'。判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此使用相同的随机数:h1、h2、h3、h4...h40。Sa'=Va1'*h1+Va2'*h2+Va3'*h3+Va4'*h4+…+Va40'*h40。因为h1、h2、h3、h4...h40服从正态分布,因此,Sa'也服从正态分布。当Sa'为正数,则Wj1[pj1-169,pj1]中至少部分数据满足预定条件C1,当Sa'为负数或0,则Wj1[pj1-169,pj1]中至少部分数据不满足预定条件C1,Sa'为正数的概率为1/2。
判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式和判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2的方式相同,因此,如图17所示,表示判断窗口Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。在图17中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节依次看成40个位,分别表示为b1'、b2'、b3'、b4'…b40'。b1'、b2'、b3'、b4'…b40'中的任一bt',当bt'=0时,Vbt'=-1,当bt'=1时,Vbt'=1,根据bt'与Vbt'对应关系,生成Vb1'、Vb2'、Vb3'、Vb4'…Vb40'。判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式和判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2的方式相同,因此,使用相同的随机数:h1、h2、h3、h4...h40,Sb'=Vb1'*h1+Vb2'*h2+Vb3'*h3+Vb4'*h4+…+Vb40'*h40。因为h1、h2、h3、h4...h40服从正态分 布,因此,Sb'也服从正态分布。当Sb'为正数,则Wj2[pj2-169,pj2]中至少部分数据满足预定条件C2,当Sb'为负数或0,则Wj2[pj2-169,pj2]中至少部分数据不满足预定条件C2,Sb'为正数的概率为1/2。
同理,判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3的方式与判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11,在此不再赘述。
仍然以图5所示实施方式为例,提供了一种判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz的方法,本实施例中使用随机函数判断窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz,根据在去重服务器103上预设的规则,为潜在分割点ki确定点pi1及pi1对应的窗口Wi1[pi1-169,pi1],判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,如图16所示,Wi1表示窗口Wi1[pi1-169,pi1],为判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1,选择5个字节,图16中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”转换成1个十进制数,范围为0-(2^40-1),使用均匀分布随机数生成器为0-(2^40-1)中的每一个十进制数生成1 个指定值,记录0-(2^40-1)中的每一个十进制数与指定值之间的对应关系R,一旦指定则该十进制数对应的指定值就不变,该指定值服从均匀分布,如果该指定值为偶数,则Wi1[pi1-169,pi1]中至少部分数据满足预定条件C1,如果该指定值为奇数,则Wi1[pi1-169,pi1]中至少部分数据不满足预定条件C1,C1表示按照上述方法获得的指定值为偶数。因为均匀分布的随机数为偶数的概率为1/2,因此,[pi1-169,pi1]中至少部分数据满足预定条件C1的概率为1/2。在图5所示的实施方式中,使用同样的规则,分别判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2,判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3、判断Wi4[pi4-169,pi4]中至少部分数据是否满足预定条件C4、判断Wi5[pi5-169,pi5]中至少部分数据是否满足预定条件C5,在此不再赘述。
当Wi5[pi5-169,pi5]中至少部分数据不满足预定条件C5,从点pi5沿着数据流分割点查找方向跳跃11个字节,在第11个字节的结束位置获得当前潜在分割点kj,如图6所示,根据在去重服务器103上预设的规则,为潜在分割点kj确定点pj1、点pj1对应的窗口Wj1[pj1-169,pj1],判断窗口Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的方式相同,因此,使用相同的0-(2^40-1)中的每一个十进制数与指定值之间的对应关系R,如图17所示,Wj1表示窗口Wj1[pj1-169,pj1],为判断Wj1[pj1-169,pj1]中至少部分数据是否满足预定条件C1,选择5个字节,图17中“■”表示选择的1个字节,相邻两个选择的字节“■”之间相差42个字节。将序号为169、127、85、43和1的字节“■”转换成1个十进制数,在R查找该十进制数对应的指定值,如果该指定值为 偶数,则Wj1[pj1-169,pj1]中至少部分数据满足预定条件C1,如果该指定值为奇数,则Wj1[pj1-169,pj1]中至少部分数据不满足预定条件C1,因为均匀分布的随机数为偶数的概率为1/2,因此,Wj1[pj1-169,pj1]中至少部分数据满足预定条件C1的概率为1/2。同理,判断Wi2[pi2-169,pi2]中至少部分数据是否满足预定条件C2的方式和判断Wj2[pj2-169,pj2]中至少部分数据是否满足预定条件C2的方式相同,判断Wi3[pi3-169,pi3]中至少部分数据是否满足预定条件C3的方式与判断Wj3[pj3-169,pj3]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[pj4-169,pj4]中至少部分数据是否满足预定条件C4、判断Wj5[pj5-169,pj5]中至少部分数据是否满足预定条件C5、判断Wj6[pj6-169,pj6]中至少部分数据是否满足预定条件C6、判断Wj7[pj7-169,pj7]中至少部分数据是否满足预定条件C7、判断Wj8[pj8-169,pj8]中至少部分数据是否满足预定条件C8、判断Wj9[pj9-169,pj9]中至少部分数据是否满足预定条件C9、判断Wj10[pj10-169,pj10]中至少部分数据是否满足预定条件C10和判断Wj11[pj11-169,pj11]中至少部分数据是否满足预定条件C11,在此不再赘述。
图1所示的本发明实施例中的去重服务器103,是指能够实现本发明实施例所描述的技术方案的装置,如图18所示,通常包括中央处理单元、主存储器以及输入输出接口。中央处理单元、主存储器与输入输出接口之间相互通信,主存储器存储可执行指令,中央处理单元执行主存储器中存储的可执行指令,从而执行特定的功能,如本发明实施例图4至图17所描述的查找数据流分割点。因此,如图19所示,根据图4至图17所示的本发明实施例,去重服务器103,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定M个点px、点px对 应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;去重服务器103包括确定单元1901和判断处理单元1902。其中,确定单元1901,用于用于执行步骤a):a)依据所述规则为当前潜在分割点ki确定点piz及所述点piz对应的窗口Wiz[piz-Az,piz+Bz],i和z为整数,并且1≤z≤M;判断处理单元1902,用于所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖+‖(ki-pix)‖),获得新的潜在分割点,则所述确定单元为所述新的潜在分割点执行步骤a);当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[pix-Ax,pix+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
进一步地,所述规则还包括:至少两个点pe和pf,满足条件Ae=Af,Be=Bf,Ce=Cf。进一步地,所述规则还包括:所述至少两个点pe和pf,相对于所述潜在分割点k,在所述数据流分割点查找反方向上。
进一步地,所述规则还包括:所述至少两个点pe和pf之间的距离为1个U。
进一步地,所述判断处理单元1902具体用于使用随机函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。具体地,所述判断处理单元1902具体用于使用hash函数判断所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz。具体地,所述判断处理单元1902具体用于使用随机函数判断所述窗口 Wiz[piz-Az,piz+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[piz-Az,piz+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据满足所述预定条件Cz。
进一步地,所述判断处理单元1902用于当所述窗口Wiz[piz-Az,piz+Bz]中至少部分数据不满足所述预定条件Cz,从所述点piz沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,所述确定单元1901为所述新的潜在分割点执行步骤a), 根据所述规则,为所述新的潜在分割点确定的点pic对应的窗口Wic[pic-Ac,pic+Bc]的左边界与所述窗口Wiz[piz-Az,piz+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[pic-Ac,pic+Bc]的左边界位于所述窗口Wiz[piz-Az,piz+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[pic-Ac,pic+Bc]是根据所述规则,为所述新的潜在分割点确定的M个点按照数据流查找方向获得的序列中排序第一的点。
根据图4至图17所示的本发明实施例提供的基于服务器查找数据流分割点的方法中,为潜在分割点ki确定点pix及点pix的窗口Wix[pix-Ax,pix+Bx],其中,x分别为1到M连续的自然数,M≥2,可以并行判断M个窗口中每一个窗口中至少部分数据是否满足预定条件Cx,或者依次判断窗口中至少部分数据是否满足预定条件,也可以判断窗口Wi1[pi1-A1,pi1+B1]中至少部分数据满足预定条件C1时,再判断Wi2[pi2-A2,pi2+B2]中至少部分数据满足预定条件C2时,直到判断Wim[pim-Am,pim+Bm]中至少部分数据满足预定条件Cm。实施例中其他窗口的判断与此相同,不再赘述。
另外,根据根据图4至图17所示的本发明实施例,实际应用中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定M个点px、点px对应的窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,x分别为1到M连续的自然数,M≥2,在该预设规则中,A1、A2、A3…Am可以不全部相等,B1、B2、B3…Bm可以不全部相等,C1、C2、C3…CM也可以不全部相同。在图5所示的实施方式中,在窗口Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、 Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]和Wi11[pi11-169,pi11]中,各窗口大小相同,即窗口大小均为169字节,同时判断窗口中至少部分数据是否满足预定条件的方式也相同,具体见上述判断Wi1[pi1-169,pi1]中至少部分数据是否满足预定条件C1的描述,但在图11所示的实施方式中,Wi1[pi1-169,pi1]、Wi2[pi2-169,pi2]、Wi3[pi3-169,pi3]、Wi4[pi4-169,pi4]、Wi5[pi5-169,pi5]、Wi6[pi6-169,pi6]、Wi7[pi7-169,pi7]、Wi8[pi8-169,pi8]、Wi9[pi9-169,pi9]、Wi10[pi10-169,pi10]与Wi11[pi11-182,pi11]窗口大小可以不相同,同时判断窗口中至少部分数据是否满足预定条件的方式也可以不相同。在所有实施例中,根据在去重服务器103上预设的规则,判断窗口Wi1中至少部分数据是否满足预定条件C1的方式与判断窗口Wj1中至少部分数据是否满足预定条件C1的方式必然相同,判断Wi2中至少部分数据是否满足预定条件C2的方式与判断Wj2中至少部分数据是否满足预定条件C2的方式必然相同…判断窗口WiM中至少部分数据是否满足预定条件CM的方式与判断窗口WjM中至少部分数据是否满足预定条件CM的方式必然相同。在此不再赘述,同时根据图4至图17所示的本发明实施例,虽然均以M=11为例,但根据实际需要,M的取值并不限于11,本领域技术人员根据本发明实施例中的描述,确定M的值。
根据图4至图17所示的本发明实施例,在去重服务器103上预设有规则,ka、ki、kj、kl和km为沿着数据流分割点查找方向查找分割点时获得的潜在分割点,ka、ki、kj、kl和km都依据该规则。本发明实施例中的窗口Wx[px-Ax,px+Bx]表示一个特定范围,在该特定范围选择数据以判断这些数据是否满足预定条件Cx,具体地,可以在该特定范围内选择部分数据,也可以选择全部数据以判断这些数据是否满足 预定条件Cx。本发明实施例中具体使用的窗口概念可参照窗口Wx[px-Ax,px+Bx],在此不再赘述。
根据图4至图17所示的本发明实施例,窗口Wx[px-Ax,px+Bx]中,(px-Ax)和(px+Bx)表示该窗口Wx[px-Ax,px+Bx]的两个边界,其中(px-Ax)表示窗口Wx[px-Ax,px+Bx]相对于点px位于数据流分割点查找反方向的边界,(px+Bx)表示窗口Wx[px-Ax,px+Bx]相对于点px位于数据流分割点查找方向的边界。具体地,在本发明实施例中,在图3至图15所示的数据流分割点查找方向为从左向右,则其中(px-Ax)表示窗口Wx[px-Ax,px+Bx]相对于点px位于数据流分割点查找反方向的边界(即左边界),(px+Bx)表示窗口Wx[px-Ax,px+Bx]相对于点px位于数据流分割点查找方向的边界(即右边界)。如果在图3至图15所示的数据流分割点查找方向为从右向左,则其中(px-Ax)表示窗口Wx[px-Ax,px+Bx]相对于点px位于数据流分割点查找反方向的边界(即右边界),(px+Bx)表示窗口Wx[px-Ax,px+Bx]相对于点px位于数据流分割点查找方向的边界(即左边界)。
本领域普通技术人员可以意识到,结合本发明实施例描述的各示例的单元及算法步骤,本发明实施例的关键特征可以与其他技术相结合,以更为复杂的形式呈现,但仍会包含本发明的关键特征。在真实环境中可能使用备用分割点,例如一种实施方式为,根据在去重服务器103上预设的规则,为潜在分割点ki确定11个点px,x为1到11连续的自然数,确定px对应的窗口Wx[px-Ax,px+Bx]及窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,当11个窗口中每一个窗口Wx[px-Ax,px+Bx]中至少部分数据均满足预定条件Cx,则潜在分割点ki为数据流分割点,当超过设定的最大数据块时,仍未查找到分割点,这时可能使用备用 的预设规则,备用的预设规则与在去重服务器103上预设的规则类似,备用的预设规则为:例如为潜在分割点ki确定10个点px,x为1到10连续的自然数,确定px对应的窗口Wx[px-Ax,px+Bx]及窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,当10个窗口中每一个窗口Wx[px-Ax,px+Bx]中至少部分数据均满足预定条件Cx,则潜在分割点ki为数据流分割点,当超过设定的最大数据块时,仍未查找到数据流分割点时,从最大数据块的结束位置作为强制分割点。
在去重服务器103上预设有规则,所述规则中为潜在分割点k确定M个点,并不一定要求先有一个潜在分割点k,可以通过确定的M个点来判断潜在分割点k。
本发明实施例提供一种基于去重服务器查找数据流分割点的方法,如图20所示,包括:
在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定M个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,、Ax和Bx为整数;在图3所示的实施方式中,关于M的取值,其中一种实现方式,M*U取值不大于预设的两个相邻的数据流分割点之间的最大距离,即预设的数据块最大长度。判断窗口Wz[k-Az,k+Bz]中至少部分数据是否满足预定条件Cz,其中,z为整数,1≤z≤M,(k-Az)与(k+Bz)分别表示窗口Wz的两个边界。当判断任意一个窗口Wz[k-Az,k+Bz]中至少部分数据不满足预定条件Cz,则从潜在分割点k沿数据流分割点查找方向跳跃N个字节,N≤‖Bz‖+maxx(‖Ax‖)。其中,‖Bz‖表示Wz[k-Az,k+Bz]中Bz的绝对值,maxx(‖Ax‖)表示M个窗口中Ax绝对值中的最大值,将在下面实施例中具体介绍N取值的原理。当判断M个窗口中的每一个窗口Wx[k-Ax,k+Bx]中至少部分数据满足预定条件Cx,则潜在分割点k为 数据流分割点。
具体地,对当前潜在分割点ki,依据所述规则,执行以下步骤:
步骤2001:依据所述规则为当前潜在分割点ki确定对应的窗口Wiz[ki-Az,ki+Bz],i和z为整数,并且1≤z≤M;
步骤2002:判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖),获得新的潜在分割点,执行步骤2001;
当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[ki-Ax,ki+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
进一步地,所述规则还包括:至少两个窗口Wie[ki-Ae,ki+Be]与Wif[ki-Af,ki+Bf],满足条件:|Ae+Be|=|Af+Bf|,Ce=Cf;进一步地,所述规则还包括:Ae和Af为正整数;更进一步地,所述规则还包括:Ae-1=Af,Be+1=Bf。其中,|Ae+Be|表示窗口Wie的大小,|Af+Bf|表示窗口Wif的大小。
进一步地,判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz;更进一步地,所述使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体为使用hash函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz。
当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,根据所述规则,为所述新的潜在分割点确定的窗口Wic[ki-Ac,ki+Bc]的左边界与所述窗口Wiz[ki-Az,ki+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]的左边界位于所述窗口Wiz[ki-Az,ki+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]是根据所述规则,为所述新的潜在分割点确定的M个窗口按照数据流查找方向获得的序列中排序第一的窗口。
本发明实施例中通过判断M个窗口中某一个窗口中至少部分数据是否满足预定条件,来查找数据流分割点,当某一个窗口中至少部分数据不满足预定条件,则跳过N*U个长度,其中,N*U不大于‖Bz‖+maxx(‖Ax‖),获得下一个潜在分割点,提高了数据流分割点查找效率。
在重复数据删除过程中,为保证数据块大小均匀,会考虑平均数据块(也可以称为平均分块)大小,即在满足最小数据块大小和最大数据块大小限定的同时,会确定平均数据块大小,以保证获得的数据块大小均匀。窗口Wx[k-Ax,k+Bx]的个数M与窗口Wx[k-Ax,k+Bx]中至少部分数据满足预设条件的概率这两个因素决定了找到数据流分割点的概率(以P(n)表示),前者影响跳跃的长度,后者影响跳跃的概率,二者共同影响平均分块大小。一般而言,在平均分块大小固定时,Wx[k-Ax,k+Bx]个数增加,则单个窗口Wx[k-Ax,k+Bx]中至少部分数据满足预定条件的概率也增加,例如在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个窗口Wx[k-Ax,k+Bx],x分别为1到11连续的自然数,11个窗口中任一个窗口Wx[k-Ax,k+Bx]中至少部分数据满足预设条件的概率为1/2。而在去重服务器103上预 设的另一组规则为:为潜在分割点k确定24个窗口Wx[k-Ax,k+Bx],x分别为1到24连续的自然数,24个窗口中任一个窗口Wx[k-Ax,k+Bx]中至少部分数据满足预设条件的概率3/4,具体窗口Wx[k-Ax,k+Bx]中至少部分数据满足预设条件的概率设定可参见判断窗口Wx[k-Ax,k+Bx]中至少部分数据是否满足预设条件部分的描述。窗口Wx[k-Ax,k+Bx]的个数M与窗口Wx[k-Ax,k+Bx]中至少部分数据满足的预设条件的概率这两个因素决定P(n),P(n)表示:从数据流起始位置或者从上一数据流分割点查找n个数据流分割点最小查找单位后没找到数据流分割点的概率。关于这两个因素决定P(n)的计算过程,实际上是一个多步长Fibonacci数列,后面将具体描述。得到P(n)后,1-P(n)即为数据流分割点的分布函数,(1-P(n))-(1-P(n-1))=P(n-1)-P(n)即为在n个数据流分割点最小查找单位找到数据流分割点概率,也就是数据流分割点的密度函数,根据数据流分割点的密度函数就可以积分 从而求得数据流分割点的期望长度,即平均分块大小,其中,4*1024(字节)表示最小数据块长度,12*1024(字节)表示最大数据块长度。
在图3所示的数据流分割点查找的基础上,在图21所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到11连续的自然数,Ax和Bx为整数。其中,A1=169,B1=0;A2=170,B2=-1;A3=171,B3=-2;A4=172,B4=-3;A5=173,B5=-4;A6=174,B6=-5;A7=175,B7=-6;A8=176,B8=-7;A9=177,B9=-8;A10=178,B10=-9;A11=179,B11=-10,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11,则11个窗口分别为W1[k-169,k]、W2[k-170,k-1]、W3[k-171,k-2]、W4[k-172,k-3]、 W5[k-173,k-4]、W6[k-174,k-5]、W7[k-175,k-6]、W8[k-176,k-7]、W9[k-177,k-8]、W10[k-178,k-9]和W11[k-179,k-10]。ka为数据流分割点,图21中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,最小数据块4KB结束位置作为下一个潜在分割点ki,根据为去重服务器103预设的规则,为潜在分割点ki确定窗口Wix[ki-Ax,ki+Bx],在本实施例中,x分别为1到11连续的自然数。在图21所示的实施方式中,为潜在分割点ki确定的窗口为11个,分别为Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]、Wi4[ki-172,ki-3]、Wi5[ki-173,ki-4]、Wi6[ki-174,ki-5]、Wi7[ki-175,ki-6]、Wi8[ki-176,ki-7]、Wi9[ki-177,ki-8]、Wi10[ki-178,ki-9]和Wi11[ki-179,ki-10]。判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1、判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2、判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3、判断Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4、判断Wi5[ki-173,ki-4]中至少部分数据是否满足预定条件C5、判断Wi6[ki-174,ki-5]中至少部分数据是否满足预定条件C6、判断Wi7[ki-175,ki-6]中至少部分数据是否满足预定条件C7、判断Wi8[ki-176,ki-7]中至少部分数据是否满足预定条件C8、判断Wi9[ki-177,ki-8]中至少部分数据是否满足预定条件C9、判断Wi10[ki-178,ki-9]中至少部分数据是否满足预定条件C10和判断Wi11[ki-179,ki-10]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数 据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图22所示,Wi5[ki-173,ki-4],则从潜在分割点ki沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B5‖+maxx(‖Ax‖),在图22所示的实施方式中,跳跃N个字节不大于183个字节,在本实施例中,N=7,得到新的潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj。根据图21所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点kj确定窗口Wjx[kj-Ax,kj+Bx],在本实施例中,x分别为1到11连续的自然数。为潜在分割点kj确定的窗口为11个,分别为Wj1[kj-169,kj]、Wj2[kj-170,kj-1]、Wj3[kj-171,kj-2]、Wj4[kj-172,kj-3]、Wj5[kj-173,kj-4]、Wj6[kj-174,kj-5]、Wj7[kj-175,kj-6]、Wj8[kj-176,kj-7]、Wj9[kj-177,kj-8]、Wj10[kj-178,kj-9]和Wj11[kj-179,kj-10]。如图22所示,为潜在分割点确定的第11个窗口Wj11[kj-179,kj-10],在保证潜在分割点ki与潜在分割点kj之间的范围都在判断范围之内,则在本实施方式中,必须保证窗口Wj11[kj-179,kj-10]的左边界与窗口Wi5[ki-173,ki-4]的右边界(ki-4)重合,或者位于窗口Wi5[ki-173,ki-4]范围之内,所述窗口Wj11[kj-179,kj-10]是根据所述规则,为所述潜在分割点kj确定的M个窗口按照数据流查找方向获得的序列中排序第一的窗口。因此,在这一限定内,当窗口Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5,从潜在分割点ki沿数据流分割点查找方向跳跃的距离不大于‖B5‖+maxx(‖Ax‖)。判断Wj1[kj-169,kj]中至少 部分数据是否满足预定条件C1、判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2、判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3、判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4、判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj-176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-178,kj-9]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj-10]中至少部分数据是否满足预定条件C11。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜在分割点kj不是数据流分割点时,按照与ki相同的方式获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。
在如图21所示的实施方式中,按照在去重服务器103上预设的规则,从判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1开始,当判断Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]和Wi4[ki-172,ki-3]中至少部分数据中至少部分数据分别满足预定条件C1、C2、C3和C4,判断Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5时,从潜在分割点ki沿着数据流分割点查找方向跳跃6个字节,在第6个字节的结束位置获得新的潜在分割点,为与其他潜在分割点区别,这里表示为kg,按照在去重服务器103上预设的规则,为潜在分割点kg确定11个窗口,分别为Wg1[kg-169,kg]、Wg2[kg-170,kg-1]、Wg3[kg-171,kg-2]、Wg4[kg-172,kg-3]、Wg5[kg-173,kg-4]、Wg6[kg-174,kg-5]、Wg7[kg-175,kg-6]、Wg8[kg-176,kg-7]、Wg9[kg-177,kg-8]、Wg10[kg-178,kg-9]和Wg11[kg-179,kg-10]。判断Wg1[kg-169,kg]中至少部分数据是否满足预定条件C1、判断Wg2[kg-170,kg-1]中至少部分数据是否满足预定条件C2、判断Wg3[kg-171,kg-2]中至少部分数据是否满足预定条件C3、判断Wg4[kg-172,kg-3]中至少部分数据是否满足预定条件C4、判断Wg5[kg-173,kg-4]中至少部分数据是否满足预定条件C5、判断Wg6[kg-174,kg-5]中至少部分数据是否满足预定条件C6、判断Wg7[kg-175,kg-6]中至少部分数据是否满足预定条件C7、判断Wg8[kg-176,kg-7]中至少部分数据是否满足预定条件C8、判断Wg9[kg-177,kg-8]中至少部分数据是否满足预定条件C9、判断Wg10[kg-178,kg-9]中至少部分数据是否满足预定条件C10和判断Wg11[kg-179,kg-10]中至少部分数据是否满足预定条件C11。窗口Wg11[kg-179,kg-10]与窗口Wi5[ki-173,ki-4]重合,并且C5=C11,因此,当判断Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5时,从潜在分割点ki沿着数据流分割点查找方向跳跃T个字节,获得的潜在分割 点kg仍然不符合作为数据流分割点的条件。因此,如果从潜在分割点ki沿着数据流分割点查找方向跳跃6个字节会存在重复计算,因此,从潜在分割点ki沿着数据流分割点查找方向跳跃7个字节可以减少重复计算,效率更高。因此提高了查找数据流分割点的速度。当预设规定中窗口Wx[k-Ax,k+Bx]中至少部分数据满足预定条件Cx的概率为1/2时,即是说以1/2的概率执行跳跃,每次最多可以跳跃‖B11‖+‖A11‖=189个字节。
在本实施方式中,预定规则为:为潜在分割点k确定11个窗口Wx[k-Ax,k+Bx]及窗口Wx[k-Ax,k+Bx]中至少部分数据满足预设条件Cx,其中Wx[k-Ax,k+Bx]中至少部分数据满足预设条件Cx的概率为1/2,x分别为1到11连续的自然数并且Ax和Bx为整数。其中,A1=169,B1=0;A2=170,B2=-1;A3=171,B3=-2;A4=172,B4=-3;A5=173,B5=-4;A6=174,B6=-5;A7=175,B7=-6;A8=176,B8=-7;A9=177,B9=-8;A10=178,B10=-9;A11=179,B11=-10,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11。即为潜在分割点k选择11个窗口,并且为连续11个窗口,通过这两个因素可以计算P(n)。11个窗口的选择方式及判断11个窗口中的每一个窗口中至少部分数据满足预定条件Cx遵循在去重服务器103上预设的规则,因此是否存在连续11个窗口中每一个窗口中至少部分数据满足预定条件Cx就决定潜在分割点k是否为数据流分割点。我们称两个字节之间的间隙为一个点。P(n)表示:连续的n个窗口内不存在连续的11个满足条件的窗口的概率,即不存在数据流分割点的概率。从文件头/上一分割点跳跃最小分块大小4KB后,向数据流分割点查找反方向回退10个字节,找到第4086个点,在该点处不存在数据流分割点,所以P(4086)=1,依次类推,P(4087)=1,……P(4095)=1。在第4096个点处,即在最小分块大小处,以(1/2)^11的概率这11个窗口中每 一个窗口中至少部分数据满足预定条件Cx,因此以(1/2)^11的概率存在数据流分割点,以1-(1/2)^11的概率不存在数据流分割点,所以P(4096)=1-(1/2)^11。
如图35所示,在第n个窗口处,可以分为12种情况来递推P(n)。
情况1:第n个窗口中至少部分数据以1/2的概率不满足预定条件,此时第n个窗口前面的n-1个窗口以P(n-1)的概率不存在连续的11个窗口中每一个窗口至少部分数据均满足预定条件,因此P(n)包含1/2*P(n-1)。第n个窗口中至少部分数据不满足预定条件,并且且第n个点前面的n-1个窗口存在连续的11个窗口每一个窗口中至少部分数据均满足预定条件的情况与P(n)无关。
情况2:第n个窗口中至少部分数据以1/2的概率满足预定条件,第n-1个窗口中至少部分数据以1/2的概率不满足预定条件,此时第n-1个窗口前面的n-2个窗口以P(n-2)的概率不存在连续的11个窗口中每一个窗口中至少部分数据均满足预定条件,因此P(n)包含1/2*1/2*P(n-2)。第n个窗口中至少部分数据满足预定条件,第n-1个点窗口中至少部分数据不满足预定条件,并且第n-1个窗口前面的n-2个窗口存在连续的11个窗口中每一个窗口至少部分数据满足预定条件的情况与P(n)无关。
依照上述描述,情况11:第n至n-9个窗口中至少部分数据以(1/2)^10的概率满足预定条件,第n-10个窗口中至少部分数据以1/2的概率不满足预定条件,此时第n-10个窗口前面的n-11个窗口以P(n-11)的概率不存在连续的11个窗口中每一个窗口中至少部分数据均满足预定条件,因此P(n)包含(1/2)^10*1/2*P(n-11)。第n至n-9个窗口中至少部分数据均满足预定条件,第n-10个窗口中至少部分数据不满足预定条件,并且第n-10个窗口前面的n-11个窗口存在连续的11个 窗口中每一个窗口中至少部分数据均满足预定条件的情况与P(n)无关。
情况12:第n至n-10个的窗口中至少部分数据以(1/2)^11的概率满足预定条件,该情况与P(n)无关。
因此,P(n)=1/2*P(n-1)+(1/2)^2*P(n-2)+……+(1/2)^11*P(n-11)。另一种预设规则:为潜在分割点k确定24个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到11连续的自然数,A1=169,B1=0;A2=170,B2=-1;A3=171,B3=-2;A4=172,B4=-3;A5=173,B5=-4;A6=174,B6=-5;A7=175,B7=-6;A8=176,B8=-7;A9=177,B9=-8;A10=178,B10=-9;A11=179,B11=-10,…A24=192,B24=-23,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=…=C24,窗口Wx[k-Ax,k+Bx]中至少部分数据满足预定条件Cx的概率为3/4,通过这两个因素可以计算P(n)。
因此是否存在连续24个窗口中的每一个窗口中至少部分数据均满足预定条件Cx就决定潜在分割点k是否为数据流分割点,可以通过下面的公式计算:
P(1)=1,P(2)……P(23)=1,P(24)=1-(3/4)^24,
P(n)=1/4*P(n-1)+1/4*(3/4)*P(n-2)+……+1/4*(3/4)^23*P(n-24)。
经过计算,P(5*1024)=0.78,P(11*1024)=0.17,P(12*1024)=0.13,即从数据流起始位置/上一数据流分割点查找到12KB后以13%的概率仍未找到数据流分割点,强制进行分割。通过这个概率,求得数据流分割点的密度函数,经过积分求得大约平均在从数据流起始位置/上一数据流分割点查找7.6KB时找到数据流分割点,即平均分块长度大约为7.6KB。与连续的11个窗口中至少部分数据以1/2的概率满足预定条件不同,传统CDC算法采用一个窗口以1/2^12的概率满足条件时, 方可达到平均分块长度7.6KB的效果。
在图3所示的数据流分割点查找的基础上,在图23所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到11连续的自然数,Ax和Bx为整数。其中,窗口Wx[k-Ax,k+Bx]中至少部分数据满足预定条件Cx的概率为1/2,A1=171,B1=-2;A2=172,B2=-3;A3=173,B3=-4;A4=174,B4=-5;A5=175,B5=-6;A6=176,B6=-7;A7=177,B7=-8;A8=178,B8=-9;A9=179,B9=-10;A10=170,B10=-1;A11=169,B11=0,并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11。ka为数据流分割点,图23中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,在最小数据块4KB结束位置作为下一个潜在分割点ki,根据在去重服务器103上预设的规则,为潜在分割点ki确定Wx[k-Ax,k+Bx]及窗口Wx[k-Ax,k+Bx]对应的预设条件Cx,其中x为1到11连续的自然数。确定的11个窗口分别为Wi1[ki-171,ki-2]、Wi2[ki-172,ki-3]、Wi3[ki-173,ki-4]、Wi4[ki-174,ki-5]、Wi5[ki-175,ki-6]、Wi6[ki-176,ki-7]、Wi7[ki-177,ki-8]、Wi8[ki-178,ki-9]、Wi9[ki-179,ki-10]、Wi10[ki-170,ki-1]和Wi11[ki-169,ki]。判断Wi1[ki-171,ki-2]中至少部分数据是否满足预定条件C1、判断Wi2[ki-172,ki-3]中至少部分数据是否满足预定条件C2、判断Wi3[ki-173,ki-4]中至少部分数据是否满足预定条件C3、判断Wi4[ki-174,ki-5]中至少部分数据是否满足预定条件C4、判断Wi5[ki-175,ki-6]中至少部分数据是否满足预定条件C5、判断Wi6[ki-176,ki-7]中至少部分数据是否满足预定条件C6、判断Wi7[ki-177,ki-8]中至少部分数据是否满足预定条件C7、判断Wi8[ki-178,ki-9]中至少部分数据是否满足预定条件C8、判断Wi9[ki-179,ki-10]中至少部分数据是否满足预定条件C9、判断Wi10[ki-170,ki-1]中至少部分数据是否满足 预定条件C10和判断Wi11[ki-169,ki]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图24所示,Wi3[pi3-169,pi3]中至少部分数据不满足预定条件C3,点pi3沿着数据流分割点查找方向跳跃11个字节为例进行描述。如图24所示,当判断W3不满足预定条件C3时,以ki为起始点,沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B3‖+maxx(‖Ax‖),在本实施例中,N=7,在第7个字节的结束位置,获得下一个潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj,根据在去重服务器103上预设的规则,为潜在分割点kj确定11个窗口Wjx[kj-Ax,kj+Bx],分别为Wj1[kj-171,kj-2]、Wj2[kj-172,kj-3]、Wj3[kj-173,kj-4]、Wj4[kj-174,kj-5]、Wj5[kj-175,kj-6]、Wj6[kj-176,kj-7]、Wj7[kj-177,kj-8]、Wj8[kj-178,kj-9]、Wj9[kj-179,kj-10]、Wj10[kj-170,kj-1]和Wj11[kj-169,kj]。判断Wj1[kj-171,kj-2]中至少部分数据是否满足预定条件C1、判断Wj2[kj-172,kj-3]中至少部分数据是否满足预定条件C2、判断Wj3[kj-173,kj-4]中至少部分数据是否满足预定条件C3、判断Wj4[kj-174,kj-5]中至少部分数据是否满足预定条件C4、判断Wj5[kj-175,kj-6]中至少部分数据是否 满足预定条件C5、判断Wj6[kj-176,kj-7]中至少部分数据是否满足预定条件C6、判断Wj7[kj-177,kj-8]中至少部分数据是否满足预定条件C7、判断Wj8[kj-178,kj-9]中至少部分数据是否满足预定条件C8、判断Wj9[kj-179,kj-10]中至少部分数据是否满足预定条件C9、判断Wj10[kj-170,kj-1]中至少部分数据是否满足预定条件C10和判断Wj11[kj-169,kj]中至少部分数据是否满足预定条件C11。当然在本发明实施例中,判断潜在分割点ka是否为数据流分割点时也遵循该原则,具体实现不再描述,可以参照判断潜在分割点ki的描述。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜在分割点kj不是数据流分割点时,按照与ki相同的方式获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。当然该方法的实施受最大数据块长度和构成该数据流的文件的大小约束,在此不再赘述。
在图3所示的数据流分割点查找的基础上,在图25所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中x为1到11连续自然数,A1=166,B1=3;A2=167,B2=2;A3=168,B3=1;A4=169,B4=0;A5=170,B5=-1;A6=171,B6=-2;A7=172,B7=-3;A8=173,B8=-4;A9=174,B9=-5;A10=175,B10=-6;A11=176,B11=-7;并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11,则11个窗口分别为W1[k-166,k+3]、W2[k-167,k+2]、W3[k-168,k+1]、W4[k-169,k]、W5[k-170,k-1]、W6[k-171,k-2]、W7[k-172,k-3]、W8[k-173,k-4]、W9[k-174,k-5]、W10[k-175,k-6]和W11[k-176,k-7]。ka为数据流分割点,图25中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,最小数据块4KB结束位置作为下一个潜在分割点ki,在本实施例中,根据在去重服务器103上预设的规则,为潜在分割点ki确定11个窗口Wix[k-Ax,k+Bx]及窗口Wix[k-Ax,k+Bx]对应的预定条件Cx,x分别为1到11连续的自然数。在图25所示的实施方式中,为潜在分割点ki确定11个窗口,分别为Wi1[ki-166,ki+3]、Wi2[ki-167,ki+2]、Wi3[ki-168,ki+1]、Wi4[ki-169,ki]、Wi5[ki-170,ki-1]、Wi6[ki-171,ki-2]、Wi7[ki-172,ki-3]、Wi8[ki-173,ki-4]、Wi9[ki-174,ki-5]、Wi10[ki-175,ki-6]和Wi11[ki-176,ki-7]。判断Wi1[ki-166,ki+3]中至少部分数据是否满足预定条件C1、判断Wi2[ki-167,ki+2]中至少部分数据是否满足预定条件C2、判断Wi3[ki-168,ki+1]中至少部分数据是否满足预定条件C3、判断Wi4[ki-169,ki]中至少部分数据是否满足预定条件C4、判断Wi5[ki-170,ki-1]中至少部分数据是否满足预定条件C5、判断Wi6[ki-171,ki-2]中至少部分数据是否满足预定条件C6、判断Wi7Wi7[ki-172,ki-3]中至少部分数据是否满足预 定条件C7、判断Wi8[ki-173,ki-4]中至少部分数据是否满足预定条件C8、判断Wi9[ki-174,ki-5]中至少部分数据是否满足预定条件C9、判断Wi10[ki-175,ki-6]中至少部分数据是否满足预定条件C10和判断Wi11[ki-176,ki-7]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图26所示,Wi7[ki-172,ki-3],则从潜在分割点ki沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B7‖+maxx(‖Ax‖),在图26所示的实施方式中,跳跃N个字节不大于185个字节,在本实施例中,N=5,得到新的潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj,根据图25所示的实施方式中在去重服务器103上预设的规则,为潜在分割点kj确定的窗口为11个,分别为Wj1[kj-166,kj+3]、Wj2[kj-167,kj+2]、Wj3[kj-168,kj+1]、Wj4[kj-169,kj]、Wj5[kj-170,kj-1]、Wj6[kj-171,kj-2]、Wj7[kj-172,kj-3]、Wj8[kj-173,kj-4]、Wj9[kj-174,kj-5]、Wj10[kj-175,kj-6]和Wj11[kj-176,kj-7]。判断Wj1[kj-166,kj+3]中至少部分数据是否满足预定条件C1、判断Wj2[kj-167,kj+2]中至少部分数据是否满足预定条件C2、判断Wj3[kj-168,kj+1]中至少部分数据是否满足预定条件C3、判断Wj4[kj-169,kj]中至少 部分数据是否满足预定条件C4、判断Wj5[kj-170,kj-1]中至少部分数据是否满足预定条件C5、判断Wj6[kj-171,kj-2]中至少部分数据是否满足预定条件C6、判断Wj7[kj-172,kj-3]中至少部分数据是否满足预定条件C7、判断Wj8[kj-173,kj-4]中至少部分数据是否满足预定条件C8、判断Wj9[kj-174,kj-5]中至少部分数据是否满足预定条件C9、判断Wj10[kj-175,kj-6]中至少部分数据是否满足预定条件C10和判断Wj11[kj-176,kj-7]中至少部分数据是否满足预定条件C11。当然在本发明实施例中,判断潜在分割点ka是否为数据流分割点时也遵循该原则,具体实现不再描述,可以参照判断潜在分割点ki的描述。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜在分割点kj不是数据流分割点时,按照与ki相同的方式获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。
在图3所示的数据流分割点查找的基础上,在图27所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中x为1到11连续的自然数,A1=169,B1=0;A2=170,B2=-1;A3=171,B3=-2;A4=172,B4=-3;A5=173,B5=-4;A6=174,B6=-5;A7=175,B7=-6;A8=176,B8=-7;A9=177,B9=-8;A10=168,B10=1;A11=179,B11=3;并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10≠C11,则11个窗口分别为W1[k-169,k]、W2[k-170,k-1]、W3[k-171,k-2]、W4[k-172,k-3]、W5[k-173,k-4]、W6[k-174,k-5]、W7[k-175,k-6]、W8[k-176,k-7]、W9[k-177,k-8]、W10[k-168,k+1]和W11[k-179,k+3]。ka为数据流分割点,图27中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,最小数据块4KB结束位置作为下一个潜在分割点ki,在本实施例中,根据在去重服务器103上预设的规则,为潜在分割点ki确定窗口Wix[ki-Ax,ki+Bx],x分别为1到11连续的自然数,在图27所示的实施方式中,为潜在分割点ki确定11个窗口分别为Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]、Wi4[ki-172,ki-3]、Wi5[ki-173,ki-4]、Wi6[ki-174,ki-5]、Wi7[ki-175,ki-6]、Wi8[ki-176,ki-7]、Wi9[ki-177,ki-8]、Wi10[ki-168,ki+1]和Wi11[ki-179,ki+3]。判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1、判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2、判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3、判断Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4、判断Wi5[ki-173,ki-4]中至少部分数据是否满足预定条件C5、判断Wi6[ki-174,ki-5]中至少部分数据是否 满足预定条件C6、判断Wi7[ki-175,ki-6]中至少部分数据是否满足预定条件C7、判断Wi8[ki-176,ki-7]中至少部分数据是否满足预定条件C8、判断Wi9[ki-177,ki-8]中至少部分数据是否满足预定条件C9、判断Wi10[ki-168,ki+1]中至少部分数据是否满足预定条件C10和判断Wi11[ki-179,ki+3]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当判断窗口Wi11中至少部分数据不满足预定条件C11时,则从潜在分割点ki沿着数据流分割点查找方向跳跃1个字节,得到新的潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj。当Wi1、Wi2、Wi3、Wi4、Wi5、Wi6、Wi7、Wi8、Wi9和Wi1010个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图28所示,Wi4[ki-172,ki-3],则从点ki沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B4‖+maxx(‖Ax‖),在图28所示的实施方式中,跳跃N个字节不大于182个字节,在本实施例中,N=6,得到新的潜在分割点,为与潜在分割点ki区别,这里将新的潜在分割点表示为kj,根据图27所示的实施方式中在去重服务器103上预设的规则,为潜在分割点kj确定的窗口分别为Wj1[kj-169,kj]、Wj2[kj -170,kj-1]、Wj3[kj-171,kj-2]、Wj4[kj-172,kj-3]、Wj5[kj-173,kj-4]、Wj6[kj-174,kj-5]、Wj7[kj-175,kj-6]、Wj8[kj-176,kj-7]、Wj9[kj-177,kj-8]、Wj10[kj-168,kj+1]和Wj11[kj-179,kj+3]。判断Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1、判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2、判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3、判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4、判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj-176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-168,kj+1]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj+3]中至少部分数据是否满足预定条件C11。当然在本发明实施例中,判断潜在分割点ka是否为数据流分割点时也遵循该原则,具体实现不再描述,可以参照判断潜在分割点ki的描述。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wj9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分 割点,kj与ka之间的数据构成1个数据块,同时按照与ka相同的方式跳过最小分块大小4KB,获得下一个潜在分割点,并按照在去重服务器103上预设的规则,判断下一个潜在分割点是否为数据流分割点。当判断潜在分割点kj不是数据流分割点时,按照与ki相同的方式获得下一个潜在分割点,并按照在去重服务器103上预设的规则及上述方法判断下一个潜在分割点是否为数据流分割点。当超过设定的最大数据块仍然没有找到数据流分割点时,则从最大数据块的结束位置作为强制分割点。
在图3所示的数据流分割点查找的基础上,在图29所示的实施方式中,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定11个窗口Wx[px-Ax,px+Bx]和窗口Wx[px-Ax,px+Bx]对应的预定条件Cx,x分别为1到11连续的自然数,其中,窗口Wx[px-Ax,px+Bx]中至少部分数据满足预定条件的概率为1/2,A1=169,B1=0;A2=171,B2=-2;A3=173,B3=-4;A4=175,B4=-6;A5=177,B5=-8;A6=179,B6=-10;A7=181,B7=-12;A8=183,B8=-14;A9=185,B9=-16;A10=187,B10=-18;A11=189,B11=-20;并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11,则11个窗口分别为W1[k-169,k]、W2[k-171,k-2]、W3[k-173,k-4]、W4[k-175,k-6]、W5[k-177,k-8]、W6[k-179,k-10]、W7[k-181,k-12]、W8[k-183,k-14]、W9[k-185,k-16]、W10[k-187,k-18]和W11[k-189,k-20]。ka为数据流分割点,图29中所示数据流分割点查找方向为从左向右,从数据流分割点ka跳过最小数据块4KB后,在最小数据块4KB结束位置作为下一个潜在分割点ki,为潜在分割点ki确定点pix,在本实施例中,根据在去重服务器103上预设的规则,x分别为1到11连续的自然数。在图29所示的实施方式中,依据预定规则,为潜在分割点ki确定的11个窗口分别为Wi1[ki-169,ki]、Wi2[ki-171,ki-2]、Wi3[ki-173,ki-4]、Wi4[ki-175,ki-6]、Wi5[ki-177, ki-8]、Wi6[ki-179,ki-10]、Wi7[ki-181,ki-12]、Wi8[ki-183,ki-14]、Wi9[ki-185,ki-16]、Wi10[ki-187,ki-18]和Wi11[ki-189,ki-20]。判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1、判断Wi2[ki-171,ki-2]中至少部分数据是否满足预定条件C2、判断Wi3[ki-173,ki-4]中至少部分数据是否满足预定条件C3、判断Wi4[ki-175,ki-6]中至少部分数据是否满足预定条件C4、判断Wi5[ki-177,ki-8]中至少部分数据是否满足预定条件C5、判断Wi6[ki-179,ki-10]中至少部分数据是否满足预定条件C6、判断Wi7[ki-181,ki-12]中至少部分数据是否满足预定条件C7、判断Wi8[ki-183,ki-14]中至少部分数据是否满足预定条件C8、判断Wi9[ki-185,ki-16]中至少部分数据是否满足预定条件C9、判断Wi10[ki-187,ki-18]中至少部分数据是否满足预定条件C10和判断Wi11[ki-189,ki-20]中至少部分数据是否满足预定条件C11。当判断窗口Wi1中至少部分数据满足预定条件C1、窗口Wi2中至少部分数据满足预定条件C2、窗口Wi3中至少部分数据满足预定条件C3、窗口Wi4中至少部分数据满足预定条件C4、窗口Wi5中至少部分数据满足预定条件C5、窗口Wi6中至少部分数据满足预定条件C6、窗口Wi7中至少部分数据满足预定条件C7、窗口Wi8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wi10中至少部分数据满足预定条件C10和窗口Wi11中至少部分数据满足预定条件C11时,则当前潜在分割点ki为数据流分割点。当11个窗口中任一个窗口中至少部分数据不满足对应的预定条件时,如图30所示,Wi4[ki-175,ki-6]中至少部分数据不满足预定条件C4,则选择下一个潜在分割点,为与潜在分割点ki区别,这里表示为kj,kj位于ki右边,并且kj与ki间距1个字节。如图30所示,依为去重服务器103预设的规则,为潜在分割点kj确定11个 窗口分别为Wj1[kj-169,kj]、Wj2[kj-171,kj-2]、Wj3[kj-173,kj-4]、Wj4[kj-175,kj-6]、Wj5[kj-177,kj-8]、Wj6[kj-179,kj-10]、Wj7[kj-181,kj-12]、Wj8[kj-183,kj-14]、Wj9[kj-185,kj-16]、Wj10[kj-187,kj-18]和Wj11[kj-189,kj-20],并且C1=C2=C3=C4=C5=C6=C7=C8=C9=C10=C11。判断Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1、判断Wj2[kj-171,kj-2]中至少部分数据是否满足预定条件C2、判断Wj3[kj-173,kj-4]中至少部分数据是否满足预定条件C3、判断Wj4[kj-175,kj-6]中至少部分数据是否满足预定条件C4、判断Wj5[kj-177,kj-8]中至少部分数据是否满足预定条件C5、判断Wj6[kj-179,kj-10]中至少部分数据是否满足预定条件C6、判断Wj7[kj-181,kj-12]中至少部分数据是否满足预定条件C7、判断Wj8[kj-183,kj-14]中至少部分数据是否满足预定条件C8、判断Wj9[kj-185,kj-16]中至少部分数据是否满足预定条件C9、判断Wj10[kj-187,kj-18]中至少部分数据是否满足预定条件C10和判断Wj11[kj-189,kj-20]中至少部分数据是否满足预定条件C11。当判断窗口Wj1中至少部分数据满足预定条件C1、窗口Wj2中至少部分数据满足预定条件C2、窗口Wj3中至少部分数据满足预定条件C3、窗口Wj4中至少部分数据满足预定条件C4、窗口Wj5中至少部分数据满足预定条件C5、窗口Wj6中至少部分数据满足预定条件C6、窗口Wj7中至少部分数据满足预定条件C7、窗口Wj8中至少部分数据满足预定条件C8、窗口Wi9中至少部分数据满足预定条件C9、窗口Wj10中至少部分数据满足预定条件C10和窗口Wj11中至少部分数据满足预定条件C11时,则当前潜在分割点kj为数据流分割点。当判断窗口Wj1、Wj2、Wj3、Wj4、Wj5、Wj6、Wj7、Wj8、Wj9、Wj10和Wj11中任一个窗口中至少部分数据不满 足预定条件时,如图31所示,Wj3[kj-173,kj-4]中至少部分数据不满足预定条件C3时,kj位于ki右边从ki沿着数据流分割点查找方向跳跃N个字节,其中N个字节不大于‖B4‖+maxx(‖Ax‖),在图28所示的实施方式中,N个字节不大于195个字节,在本实施例中,N=15,获得下一个潜在分割点,为与潜在分割点ki、kj相区别,表示为kl。根据图29所实施方式中为去重服务器103预设的规则,为潜在分割点kl确定11个窗口分别为Wl1[kl-169,kl]、Wl2[kl-171,kl-2]、Wl3[kl-173,kl-4]、Wl4[kl-175,kl-6]、Wl5[kl-177,kl-8]、Wl6[kl-179,kl-10]、Wl7[kl-181,kl-12]、Wl8[kl-183,kl-14]、Wl9[kl-185,kl-16]、Wl10[kl-187,kl-18]和Wl11[kl-189,kl-20]。判断Wl1[kl-169,kl]中至少部分数据是否满足预定条件C1、判断Wl2[kl-171,kl-2]中至少部分数据是否满足预定条件C2、判断Wl3[kl-173,kl-4]中至少部分数据是否满足预定条件C3、判断Wl4[kl-175,kl-6]中至少部分数据是否满足预定条件C4、判断Wl5[kl-177,kl-8]中至少部分数据是否满足预定条件C5、判断Wl6[kl-179,kl-10]中至少部分数据是否满足预定条件C6、判断Wl7[kl-181,kl-12]中至少部分数据是否满足预定条件C7、判断Wl8[kl-183,kl-14]中至少部分数据是否满足预定条件C8、判断Wl9[kl-185,kl-16]中至少部分数据是否满足预定条件C9、判断Wl10[kl-187,kl-18]中至少部分数据是否满足预定条件C10和判断Wl11[kl-189,kl-20]中至少部分数据是否满足预定条件C11。当判断窗口Wl1中至少部分数据满足预定条件C1、窗口Wl2中至少部分数据满足预定条件C2、窗口Wl3中至少部分数据满足预定条件C3、窗口Wl4中至少部分数据满足预定条件C4、窗口Wl5中至少部分数据满足预定条件C5、窗口Wl6中至少部分数据满足预定条件C6、窗口Wl7中至少部分数据满足预定条件C7、窗口Wl8中至少部分数据满 足预定条件C8、窗口Wl9中至少部分数据满足预定条件C9、窗口Wl10中至少部分数据满足预定条件C10和窗口Wl11中至少部分数据满足预定条件C11时,则当前潜在分割点kl为数据流分割点。当窗口Wl1、Wl2、Wl3、Wl4、Wl5、Wl6、Wl7、Wl8、Wl9、Wl10和Wl11中任一窗口中至少部分数据不满足预定条件时,选择下一个潜在分割点,为与潜在分割点ki、kj和kl区别,表示为km,km位于kl右边,并且km与kl间距1个字节。根据图29所示实施例为去重服务器103预设的规则,为潜在分割点km确定的11个窗口分别为Wm1[km-169,km]、Wm2[km-171,km-2]、Wm3[km-173,km-4]、Wm4[km-175,km-6]、Wm5[km-177,km-8]、Wm6[km-179,km-10]、Wm7[km-181,km-12]、Wm8[km-183,km-14]、Wm9[km-185,km-16]、Wm10[km-187,km-18]和Wm11[km-189,km-20]。判断Wm1[km-169,km]中至少部分数据是否满足预定条件C1、判断Wm2[km-171,km-2]中至少部分数据是否满足预定条件C2、判断Wm3[km-173,km-4]中至少部分数据是否满足预定条件C3、判断Wm4[km-175,km-6]中至少部分数据是否满足预定条件C4、判断Wm5[km-177,km-8]中至少部分数据是否满足预定条件C5、判断Wm6[km-179,km-10]中至少部分数据是否满足预定条件C6、判断Wm7[km-181,km-12]中至少部分数据是否满足预定条件C7、判断Wm8[km-183,km-14]中至少部分数据是否满足预定条件C8、判断Wm9[km-185,km-16]中至少部分数据是否满足预定条件C9、判断Wm10[km-187,km-18]中至少部分数据是否满足预定条件C10和判断Wm11[km-189,km-20]中至少部分数据是否满足预定条件C11。当判断窗口Wm1中至少部分数据满足预定条件C1、窗口Wm2中至少部分数据满足预定条件C2、窗口Wm3中至少部分数据满足预定条件C3、窗口Wm4中至少部分数据满足预定条件C4、窗口Wm5中至少部分数据满足预定条 件C5、窗口Wm6中至少部分数据满足预定条件C6、窗口Wm7中至少部分数据满足预定条件C7、窗口Wm8中至少部分数据满足预定条件C8、窗口Wm9中至少部分数据满足预定条件C9、窗口Wm10中至少部分数据满足预定条件C10和窗口Wm11中至少部分数据满足预定条件C11时,则当前潜在分割点km为数据流分割点。当任一个窗口中至少部分数据不满足预定条件时,则按照前面描述的方案执行跳跃,以获得下一个潜在分割点并判断是否为数据流分割点。
本发明实施例提供了一种判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz的方法,本实施例中使用随机函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz,以图21所示的实施方式为例,根据在去重服务器103上预设的规则,为潜在分割点ki确定窗口Wi1[ki-169,ki],判断Wi1[ki-169,ki]中至少部分数据是否满足预定的条件C1,如图32所示,Wi1表示窗口Wi1[ki-169,ki],为判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1,选择5个字节,图32中“■”表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。其中每个字节由8位组成,记为am,1…am,8,表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为: 当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,255个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,可以表示为: 。选取大量随机数,组成矩阵,由随机数据组成的矩阵一旦组成,保持不变,如从服从特定分布(这里以正态分布为例)的随机数中选择255*8个随机数组成矩阵R: 将矩阵Va的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8。根据该方法,获得Sa1、Sa2…到Sa255,统计Sa1、Sa2…到Sa255中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sam与矩阵R一样,仍然服从正态分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sa1、Sa2…到Sa255中,每个值大于0的概率为1/2,所以K满足二项分布: 根据统计结果,判断Sa1、Sa2…到Sa255的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明Wi1[ki-169,ki]中至少部分数据满足预定条件C1;当K为奇数时,表明W1[ki-169,ki]中至少部分数据不满足预定条件C1,这里C1即指根据上述方式获得的Sa1、Sa2…到Sa255的值大于0的个数K为偶数。在图21所示的实施方式中,在Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]、Wi4[ki-172,ki-3]、Wi5[ki-173,ki-4]、Wi6[ki-174,ki-5]、Wi7[ki-175,ki-6]、Wi8[ki-176,ki-7]、Wi9[ki-177,ki-8]、Wi10[ki-178,ki-9]和Wi11[ki-179,ki-10]中,各窗口大小相同,即窗口大小均 为169字节,同时判断窗口中至少部分数据是否满足预定条件的方式也相同,具体见上述判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的描述。因此,如图32所示,表示判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。其中每个字节由8位组成,记为bm,1…bm,8,表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为: 当bm,n=1时,Vbm,n=1,当bm,n=0时,Vbm,n=-1,其中bm,n表示bm,1…bm,8中的任一个,255个字节对应的位按照bm,n与Vbm,n的转换关系得到矩阵Vb,可以表示为:判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件的方式与判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件的方式相同,因此使用矩阵R:将矩阵Vb的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sbm=Vbm,1*hm,1+Vbm,2*hm,2+…+Vbm,8*hm,8。根据该方法,获得Sb1、Sb2…到Sb255,统计Sb1、Sb2…到Sb255中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sbm与矩阵R 一样,仍然服从正态分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sb1、Sb2…到Sb255中,每个值大于0的概率为1/2,所以K满足二项分布:根据统计结果,判断Sb1、Sb2…到Sb255的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2;当K为奇数时,表明Wi2[ki-170,ki-1]中至少部分数据不满足预定条件C2,这里C2即指根据上述方式获得的Sb1、Sb2…到Sb255的值大于0的个数K为偶数。图21所示的实施方式中,Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2。
因此,如图32所示,表示判断窗口Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。然后使用判断窗口Wi1[ki-169,ki]和Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件的方法,判断Wi3[ki-171,ki-2]中至少数据是否满足预定条件C3。图21所示的实施方式中,Wi3[ki-171,ki-2]中至少部分数据满足预定条件。如图32所示,表示判断窗口Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。然后使用判断窗口Wi1[ki-169,ki]、Wi2[ki-170,ki-1]和Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件的方法,判断Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4。图21所示的实施方式中,Wi4[ki-172,ki-3]中至少部分数据满足预定条件C4。如图32所示,表示判断窗口Wi5[ki-173,ki-4] 中至少部分数据是否满足预定条件C5时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。然后使用判断窗口Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]和Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件的方法,判断Wi5[ki-173,ki-4]中至少数据是否满足预定条件C5。图21所示的实施方式中,Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5。
当Wi5[ki-173,ki-4]中至少部分数据不满足预定条件时C5,从点pi5沿着数据流分割点查找方向跳跃7个字节,在第7个字节的结束位置获得下一个潜在分割点kj,如图22所示,根据为去重服务器103预设的规则,为潜在分割点kj确定窗口Wj1[kj-169,kj],判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式相同,因此如图33所示,Wj1表示窗口,为判断中至少部分数据是否满足预定条件C1,选择5个字节,图33中“■”表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得255字节,以增加随机性。其中每个字节由8位组成,记为am,1'…am,8',表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为:当am,n'=1时,Vam,n'=1,当am,n'=0时,Vam,n'=-1,其中am,n'表示am,1'…am,8'中的任一个,255个字节对应的位按照am,n'与Vam,n'的转换关系得到矩阵Va',可以表示为: 判断窗口中至少部分数据是否满足预定的条件与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定的条件的方式相同,因此使用矩阵R:将矩阵Va'的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam'=Vam,1'*hm,1+Vam,2'*hm,2+…+Vam,8'*hm,8。根据该方法,获得Sa1'、Sa2'…到Sa255',统计Sa1'、Sa2'…到Sa255'中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sam'与矩阵R一样,仍然服从正态分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sa1'、Sa2'…到Sa255'中,每个值大于0的概率为1/2,所以K满足二项分布:根据统计结果,判断Sa1'、Sa2'…到Sa255'的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明Wj1[kj-169,kj]中至少部分数据满足预定条件C1;当K为奇数时,表明Wj1[kj-169,kj]中至少部分数据不满足预定条件C1。
判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式和判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2的方式相同,因此,如图33所示,表示判断窗口Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。将选择的5字节数据反复利用51次,共获得 255字节,以增加随机性。其中每个字节由8位组成,记为bm,1'…bm,8',表示255个字节中第m个字节的第1到第8位,因此,255个字节对应的位可以表示为:当bm,n'=1时,Vbm,n'=1,当bm,n'=0时,Vbm,n'=-1,其中bm,n'表示bm,1'…bm,8'中的任一个,255个字节对应的位按照bm,n'与Vbm,n'的转换关系得到矩阵Vb',可以表示为: 判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C1和Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C1的方式相同,因此仍使用矩阵R:将矩阵Vb'的第m行与矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sbm'=Vbm,1'*hm,1+Vbm,2'*hm,2+…+Vbm,8'*hm,8。根据该方法,获得Sb1'、Sb2'…到Sb255',统计Sb1'、Sb2'…到Sb255'中满足特定条件(这里以大于0为例)的值的个数K。由于矩阵R服从正态分布,则Sbm'与矩阵R一样,仍然服从正态分布,根据概率论,正态分布随机数大于0的概率为1/2,在Sb1'、Sb2'…到Sb255'中,每个值大于0的概率为1/2,所以K满足二项分布:根据统计结果,判断Sb1'、Sb2'…到Sb255'的值大于0的个数K是否为偶数,二项分布的随机数为偶数的概率为为1/2,所以K以1/2的概率满足条件。当K为偶数时,表明中至少部分数据满足预定条件C2;当K为奇数时,表 明Wj2[kj-170,kj-1]中至少部分数据不满足预定条件C2。同理,判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3的方式与判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4、判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj-176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-178,kj-9]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj-10]中至少部分数据是否满足预定条件C11,在此不再赘述。
本实施例中使用随机函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz,仍然以图21所示实施方式为例,根据在去重服务器103上预设的规则,为潜在分割点ki确定窗口Wi1[ki-169,ki],判断Wi1[ki-169,ki]中至少部分数据是否满足预定的条件C1,如图32所示,Wi1表示窗口Wi1[ki-169,ki],为判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1,选择5个字节,图32中“■”表示选择的1个字节,相邻两个选择“■”的字节之间相差42个字节。其中一种实现方式为使用HASH函数计算选择的5个字节,使用HASH函数计算得到的数值是一个固定均匀分布,如果使用HASH函数计算得到的数值为偶数,则判断Wi1[ki-169,ki]中至少部分数据满足预定条件C1,即C1表示根据上述方式使用HASH函数计算得到的数值为偶数。因此,Wi1[ki-169,ki]中至少部分数据是否满足预定条件的概率为1/2。在图21所示的实施方式中,使用Hash函数判断Wi2[ki-170,ki-1]中至少部分 数据是否满足预定条件C2、Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3、Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4和Wi5[ki-173,ki-4]中至少部分数据是否满足预定条件C5,具体实现可参考描述图21所示实施方式使用Hash函数判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件的方式C1,在此不再赘述。
当Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5时,从潜在分割点ki沿着数据流分割点查找方向跳跃7个字节,在第7个字节的结束位置获得当前潜在分割点kj,如图22所示,根据为去重服务器103预设的规则,为潜在分割点kj确定窗口Wj1[kj-169,kj],判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式相同,因此如图33所示,Wj1表示窗口Wj1[kj-169,kj],为判断Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1,选择5个字节,图33中“■”表示选择的1个字节,相邻两个选择的字节“■”之间相差42个字节。使用Hash函数计算从窗口Wj1[kj-169,kj]中选取的5个字节,如果得到的数值为偶数,则Wj1[kj-169,kj]中至少部分数据满足预定条件C1。图33中,判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式和判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2的方式相同,因此,如图33所示,表示判断窗口Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。使用Hash函数计算选择的5个字节,如果得到的数值为偶数,则Wj2[kj-170,kj-1]中至少部分数据满足预定条件C2。图33中,判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3的方 式与判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3的方式相同,因此,如图33所示,表示判断窗口Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3时选择的1个字节,相邻两个选择的字节之间相差42个字节。使用Hash函数计算选择的5个字节,得到的数值为偶数,则Wj3[kj-171,kj-2]中至少部分数据满足预定条件C3。图33中,判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4的方式和判断窗口Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4的方式,因此,如图33所示,表示判断窗口Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4时选择的1个字节,相邻两个选择的字节之间相差42个字节。使用Hash函数计算选择的5个字节,得到的数值为偶数,则Wj4[kj-172,kj-3]中至少部分数据满足预定条件C4。根据上述方法,判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj-176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-178,kj-9]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj-10]中至少部分数据是否满足预定条件C11,在此不再赘述。
本实施例中使用随机函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz,以图21所示的实施方式为例,根据在去重服务器103上预设的规则,为潜在分割点ki确定窗口Wi1[ki-169,ki],判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1,如图32所示,Wi1表示窗口Wi1[ki-169,ki],为判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1,选择5个字节,图32中序号为169、127、 85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1、a2、a3、a4和a5。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1、a2、a3、a4和a5中的任一个ar均满足0≤ar≤255。a1、a2、a3、a4和a5组成1*5的矩阵。从服从二项分布的随机数中选择256*5个随机数,组成矩阵R,表示为:
根据a1的值和所在的列,从矩阵R中查找对应的值,如a1=36,a1位于第1列,则查找h36,1对应的值;根据a2的值和所在的列,从矩阵R中查找对应的值,如a2=48,a2位于第2列,则查找h48,2对应的值;根据a3的值和所在的列,从矩阵R中查找对应的值,如a3=26,a3位于第3列,则查找h26,3对应的值;根据a4的值和所在的列,从矩阵R中查找对应的值,如a4=26,a4位于第4列,则查找h26,4对应的值;根据a5的值和所在的列,从矩阵R中查找对应的值,如a5=88,a5位于第5列,则查找h88,5对应的值。S1=h36,1+h48,2+h26,3+h26,4+h88,5,因为矩阵R服从二项分布,因此,S1也服从二项分布。当S1为偶数,则Wi1[ki-169,ki]中至少部分数据满足预定条件C1,当S1为奇数,则Wi1[ki-169,ki]中至少部分数据不满足预定条件C1,S1为偶数的概率为1/2,C1表示按上述方式计算S1为偶数。在图21所示实施例中,Wi1[ki-169,ki]中至少部分数据满足预定条件C1。如图32所示,表示判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2时分别选择的1个字节,在图32中,分别用序号170、128、86、44和2表示,相邻两个选 择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1、b2、b3、b4和b5。因为1个字节由8位组成,所以每个字节作为一个数值,则b1、b2、b3、b4和b5中的任一个br均满足0≤br≤255。b1、b2、b3、b4和b5组成1*5的矩阵。本实施方式中,判断Wi1和Wi2中至少部分数据是否满足预定条件的方式相同,因此仍然使用矩阵R,根据b1的值和所在的列,从矩阵R中查找对应的值,如b1=66,b1位于第1列,则查找h66,1对应的值;根据b2的值和所在的列,从矩阵R中查找对应的值,如b2=48,b2位于第2列,则查找h48,2对应的值;根据b3的值和所在的列,从矩阵R中查找对应的值,如b3=99,b3位于第3列,则查找h99,3对应的值;根据b4的值和所在的列,从矩阵R中查找对应的值,如b4=26,b4位于第4列,则查找h26,4对应的值;根据b5的值和所在的列,从矩阵R中查找对应的值,如b5=90,b5位于第5列,则查找h90,5对应的值。S2=h66,1+h48,2+h99,3+h26,4+h90,5,因为矩阵R服从二项分布,因此,S2也服从二项分布。当S2为偶数,则Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2,当S2为奇数,则Wi2[ki-170,ki-1]中至少部分数据不满足预定条件C2,S2为偶数的概率为1/2。在图21所示实施例中,Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2。使用同样的规则,分别判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3、判断Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4、判断Wi5[ki-173,ki-4]中至少部分数据是否满足预定条件C5、判断Wi6[ki-174,ki-5]中至少部分数据是否满足预定条件C6、判断Wi7[ki-175,ki-6]中至少部分数据是否满足预定条件C7、判断Wi8[ki-176,ki-7]中至少部分数据是否满足预定条件C8、判断Wi9[ki-177,ki-8]中至少部分数据是否满足预定条件C9、判断Wi10[ki -178,ki-9]中至少部分数据是否满足预定条件C10和判断Wi11[ki-179,ki-10]中至少部分数据是否满足预定条件C11。图21所示的实施方式中,Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5,从潜在分割点ki沿着数据流分割点查找方向跳跃7个字节,在第7个字节的结束位置获得当前潜在分割点kj,如图22所示,根据为去重服务器103预设的规则,为潜在分割点kj确定窗口Wj1[kj-169,kj],判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式相同,因此如图33所示,Wj1表示窗口Wj1[kj-169,kj],为判断Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1,图33中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1'、a2'、a3'、a4'和a5'。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1'、a2'、a3'、a4'和a5'中的任一个ar'均满足0≤ar'≤255。a1'、a2'、a3'、a4'和a5'组成1*5的矩阵。判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式相同,因此,仍然使用矩阵R,表示为:
根据a1'的值和所在的列,从矩阵R中查找对应的值,如a1'=16,a1'位于第1列,则查找h16,1对应的值;根据a2'的值和所在的列,从矩阵R中查找对应的值,如a2'=98,a2'位于第2列,则查找h98,2对应的值;根据a3'的值和所在的列,从矩阵R中查找对应的值,如 a3'=56,a3'位于第3列,则查找h56,3对应的值;根据a4'的值和所在的列,从矩阵R中查找对应的值,如a4'=36,a4'位于第4列,则查找h36,4对应的值;根据a5'的值和所在的列,从矩阵R中查找对应的值,如a5'=99,a5'位于第5列,则查找h99,5对应的值。S1'=h16,1+h98,2+h56,3+h36,4+h99,5,因为矩阵R服从二项分布,因此,S1'也服从二项分布。当S1'为偶数,则Wj1[kj-169,kj]中至少部分数据满足预定条件C1,当S1'为奇数,则Wj1[kj-169,kj]中至少部分数据不满足预定条件C1,S1'为偶数的概率为1/2。
判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式和判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2的方式相同,因此,如图33所示,表示判断窗口Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1'、b2'、b3'、b4'和b5'。因为1个字节由8位组成,所以每个字节作为一个数值,则b1'、b2'、b3'、b4'和b5'中的任一个br'均满足0≤br'≤255。b1'、b2'、b3'、b4'和b5'组成1*5的矩阵。与判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2使用相同的矩阵R,根据b1'的值和所在的列,从矩阵R中查找对应的值,如b1'=210,b1'位于第1列,则查找h210,1对应的值;根据b2'的值和所在的列,从矩阵R中查找对应的值,如b2'=156,b2'位于第2列,则查找h156,2对应的值;根据b3'的值和所在的列,从矩阵R中查找对应的值,如b3'=144,b3'位于第3列,则查找h144,3对应的 值;根据b4'的值和所在的列,从矩阵R中查找对应的值,如b4'=60,b4'位于第4列,则查找h60,4对应的值;根据b5'的值和所在的列,从矩阵R中查找对应的值,如b5'=90,b5'位于第5列,则查找h90,5对应的值。S2'=h210,1+h156,2+h144,3+h60,4+h90,5,与S2的判断条件相同,当S2'为偶数,则Wj2[kj-170,kj-1]中至少部分数据满足预定条件C2,当S2'为奇数,则Wj2[kj-170,kj-1]中至少部分数据不满足预定条件C2,S2'为偶数的概率为1/2。
同理,判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3的方式与判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4、判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj-176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-178,kj-9]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj-10]中至少部分数据是否满足预定条件C11,在此不再赘述。
本实施例中使用随机函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz,以图21所示的实施方式为例,根据在去重服务器103上预设的规则,为潜在分割点ki确定窗口Wi1[ki-169,ki],判断Wi1[ki-169,ki]中至少部分数据是否满足预定的条件C1,如图32所示,Wi1表示窗口Wi1[ki-169,ki],为判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1,选择5个字节,图32中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字 节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1、a2、a3、a4和a5。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1、a2、a3、a4和a5中的任一个as均满足0≤as≤255。a1、a2、a3、a4和a5组成1*5的矩阵。从服从二项分布的随机数中选择256*5个随机数,组成矩阵R,表示为:从服从二项分布的随机数中选择256*5个随机数,组成矩阵G,表示为:
根据a1的值和所在的列,如a1=36,a1位于第1列,则从矩阵R中查找查找h36,1对应的值,从矩阵G中查找g36,1对应的值;根据a2的值和所在的列,如a2=48,a2位于第2列,则从矩阵R中查h48,2对应的值,从矩阵G中查找g48,2对应的值;根据a3的值和所在的列,如a3=26,a3位于第3列,则从矩阵R中查找h26,3对应的值,从矩阵G中查找g26,3对应的值;根据a4的值和所在的列,如a4=26,a4位于第4列,则从矩阵R中查找h26,4对应的值,从矩阵G中查找g26,4对应的值;根据a5的值和所在的列,如a5=88,a5位于第5列,则从矩阵R中查找h88,5对应的值,从矩阵G中查找g88,5对应的值。S1h=h36,1+h48,2+h26,3+h26,4+h88,5,因为矩阵R服从二项分布,因此,S1h也服从二项分布;S1g=g36,1+g48,2+g26,3+g26,4+g88,5,因为矩阵G服从二项分布,因此S1g也服从二项分布。当S1h和S1g中有1个为偶数,则Wi1[ki-169,ki]中至少部分数据满足预定条件C1,当S1h和S1g均为奇数,则Wi1[ki-169,ki]中至少部分数据不满足预定条 件C1,C1表述按照上述方法获得的S1h和S1g中有1个为偶数。因为S1h和S1g均服从二项分布,因此S1h为偶数的概率为1/2,S1g为偶数的概率为1/2,S1h和S1g中有1个为偶数的概率为1-1/4=3/4,因此,Wi1[ki-169,ki]中至少部分数据满足预定条件C1的概率为3/4。在图21所示实施例中,Wi1[ki-169,ki]中至少部分数据满足预定条件C1。在图21所示的实施方式中,在Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]、Wi4[ki-172,ki-3]、Wi5[ki-173,ki-4]、Wi6[ki-174,ki-5]、Wi7[ki-175,ki-6]、Wi8[ki-176,ki-7]、Wi9[ki-177,ki-8]、Wi10[ki-178,ki-9]和Wi11[ki-179,ki-10]中,各窗口大小相同,即窗口大小均为169字节,同时判断窗口中至少部分数据是否满足预定条件的方式也相同,具体见上述判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的描述。因此,如图32所示,表示判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2时分别选择的1个字节,在图32中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1、b2、b3、b4和b5。因为1个字节由8位组成,所以每个字节作为一个数值,则b1、b2、b3、b4和b5中的任一个bs均满足0≤bs≤255。b1、b2、b3、b4和b5组成1*5的矩阵。本实施方式中,判断各窗口中至少部分数据是否满足预定条件的方式相同,因此仍然使用相同矩阵R和G。根据b1的值和所在的列,如b1=66,b1位于第1列,则从矩阵R中查找h66,1对应的值,从矩阵G中查找g66,1对应的值;根据b2的值和所在的列,如b2=48,b2位于第2列,则从矩阵R中查找h48,2对应的值,从矩阵G中查找g48,2对应的值;根据b3的值和所在的列,如b3=99,b3位于第3列,则从矩阵R中查找h99,3对应的值,从矩阵G中查找g99,3对应 的值;根据b4的值和所在的列,如b4=26,b4位于第4列,则从矩阵R中查找h26,4对应的值,从矩阵G中查找g26,4对应的值;根据b5的值和所在的列,如b5=90,b5位于第5列,则从矩阵R中查找h90,5对应的值,从矩阵G中查找g90,5对应的值。S2h=h66,1+h48,2+h99,3+h26,4+h90,5,因为矩阵R服从二项分布,因此,S2h也服从二项分布。S2g=g66,1+g48,2+g99,3+g26,4+g90,5,因为矩阵G服从二项分布,因此,S2g也服从二项分布。当S2h和S2g中有1个为偶数,则Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2,当S2h和S2g均为奇数,则Wi2[ki-170,ki-1]中至少部分数据不满足预定条件C2,S2h和S2g中有1个为偶数的概率为3/4。在图21所示实施例中,Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2。使用同样的规则,分别判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3、判断Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4、判断Wi5[ki-173,ki-4]中至少部分数据是否满足预定条件C5、判断Wi6[ki-174,ki-5]中至少部分数据是否满足预定条件C6、判断Wi7[ki-175,ki-6]中至少部分数据是否满足预定条件C7、判断Wi8[ki-176,ki-7]中至少部分数据是否满足预定条件C8、判断Wi9[ki-177,ki-8]中至少部分数据是否满足预定条件C9、判断Wi10[ki-178,ki-9]中至少部分数据是否满足预定条件C10和判断Wi11[ki-179,ki-10]中至少部分数据是否满足预定条件C11。图21所示的实施方式中,Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5,从潜在分割点ki沿着数据流分割点查找方向跳跃7个字节,在第7个字节的结束位置获得当前潜在分割点kj,如图22所示,根据为去重服务器103预设的规则,为潜在分割点kj确定窗口Wj1[kj-169,kj],判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条 件C1的方式相同,因此如图33所示,Wj1表示窗口Wj1[kj-169,kj],为判断Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1,图33中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”分别转换成一个十进制数值,分别表示为a1'、a2'、a3'、a4'和a5'。因为1个字节由8位组成,所以每个字节“■”作为一个数值,则a1'、a2'、a3'、a4'和a5'中的任一个as'均满足0≤as'≤255。a1'、a2'、a3'、a4'和a5'组成1*5的矩阵。使用与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1相同的矩阵R和G,分别表示为: 和
根据a1'的值和所在的列,如a1'=16,a1'位于第1列,则从矩阵R中查找h16,1对应的值,从矩阵G中查找g16,1对应的值;根据a2'的值和所在的列,如a2'=98,a2'位于第2列,则从矩阵R中查找h98,2对应的值,从矩阵G中查找g98,2对应的值;根据a3'的值和所在的列,如a3'=56,a3'位于第3列,则从矩阵R中查找h56,3对应的值,从矩阵G中查找g56,3对应的值;根据a4'的值和所在的列,如a4'=36,a4'位于第4列,则从矩阵R中查找h36,4对应的值,从矩阵G中查找g36,4对应的值;根据a5'的值和所在的列,如a5'=99,a5'位于第5列,则从矩阵R中查找h99,5对应的值,从矩阵G中查找g99,5对应的值。S1h'=h16,1+h98,2+h56,3+h36,4+h99,5,因为矩阵R服从二项分布,因此,S1h'也服从二项分布;S1g'=g16,1+g98,2+g56,3+g36,4+g99,5,因为矩阵G服从二项分布,因此S1g'也服从二项分布。当S1h'和S1g'中有1个为偶数,则Wj1[kj-169,kj]中至少部分数据满足预 定条件C1,当S1h'和S1g'均为奇数,则Wj1[kj-169,kj]中至少部分数据不满足预定条件C1,S1h'和S1g'有1个为偶数的概率为3/4。
判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式和判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2的方式相同,因此,如图33所示,表示判断窗口Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。在图33中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节分别转换成一个十进制数值,分别表示为b1'、b2'、b3'、b4'和b5'。因为1个字节由8位组成,所以每个字节作为一个数值,则b1'、b2'、b3'、b4'和b5'中的任一个bs'均满足0≤bs'≤255。b1'、b2'、b3'、b4'和b5'组成1*5的矩阵。使用与判断窗口Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2相同的矩阵R和G,根据b1'的值和所在的列,如b1'=210,b1'位于第1列,则从矩阵R中查找h210,1对应的值,从矩阵G中查找g210,1对应的值;根据b2'的值和所在的列,如b2'=156,b2'位于第2列,则从矩阵R中查找h156,2对应的值,从矩阵G中查找g156,2对应的值;根据b3'的值和所在的列,如b3'=144,b3'位于第3列,则从矩阵R中查找h144,3对应的值,从矩阵G中查找g144,3对应的值;根据b4'的值和所在的列,如b4'=60,b4'位于第4列,则从矩阵R中查找h60,4对应的值,从矩阵G中查找g60,4对应的值;根据b5'的值和所在的列,如b5'=90,b5'位于第5列,则从矩阵R中查找h90,5对应的值,从矩阵G中查找g90,5对应的值。S2h'=h210,1+h156,2+h144,3+h60,4+h90,5,S2g'=g210,1+g156,2+g144,3+g60,4+g90,5。当S2h'和S2g'中有1个为偶数,则Wj2[kj-170,kj -1]中至少部分数据满足预定条件C2,当S2h'和S2g'均为奇数,则Wj2[kj-170,kj-1]中至少部分数据不满足预定条件C2,S2h'和S2g'中有1个为偶数的概率为3/4。
同理,判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3的方式与判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4、判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj-176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-178,kj-9]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj-10]中至少部分数据是否满足预定条件C11,在此不再赘述。
本实施例中使用随机函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz,以图21所示的实施方式为例,根据在去重服务器103上预设的规则,为潜在分割点ki确定窗口Wi1[ki-169,ki],判断Wi1[ki-169,ki]中至少部分数据是否满足预定的条件C1,如图32所示,Wi1表示窗口Wi1[ki-169,ki],为判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1,选择5个字节,图32中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”依次看成40个位,分别表示为a1、a2、a3、a4…a40。a1、a2、a3、a4…a40中的任一at,当at=0时,Vat=-1,当at=1时,Vat=1,根据at与Vat对应关系,生成Va1、Va2、Va3、Va4…Va40。从服从正态分布的随机数 中选择40个随机数,分别表示为:h1、h2、h3、h4...h40。Sa=Va1*h1+Va2*h2+Va3*h3+Va4*h4+…+Va40*h40。因为h1、h2、h3、h4...h40服从正态分布,因此,Sa也服从正态分布。当Sa为正数,则Wi1[ki-169,ki]中至少部分数据满足预定条件C1,当Sa为负数或0,则Wi1[ki-169,ki]中至少部分数据不满足预定条件C1,Sa为正数的概率为1/2。在图21所示实施例中,Wi1[ki-169,ki]中至少部分数据满足预定条件C1。如图32所示,表示判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2时分别选择的1个字节,在图32中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节依次看成40个位,分别表示为b1、b2、b3、b4…b40。b1、b2、b3、b4…b40中的任一bt,当bt=0时,Vbt=-1,当bt=1时,Vbt=1,根据bt与Vbt对应关系,生成Vb1、Vb2、Vb3、Vb4…Vb40。判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式相同,因此,使用相同的随机数:h1、h2、h3、h4...h40,Sb=Vb1*h1+Vb2*h2+Vb3*h3+Vb4*h4+…+Vb40*h40。因为h1、h2、h3、h4...h40服从正态分布,因此,Sb也服从正态分布。当Sb为正数,则Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2,当Sb为负数或0,则Wi2[ki-170,ki-1]中至少部分数据不满足预定条件C2,Sb为正数的概率为1/2。在图21所示实施例中,Wi2[ki-170,ki-1]中至少部分数据满足预定条件C2。使用同样的规则,分别判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3、判断Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4、判断Wi5[ki-173,ki-4]中至少部分数据是否满足预定条件C5、判断Wi6[ki-174,ki-5]中至少部分数据是否满足预定条件C6、判断Wi7[ki-175,ki-6]中至少部分数据是否满足预定条件C7、判断Wi8[ki-176,ki-7]中至少部分数据是否满足预定条件C8、判断Wi9[ki-177,ki-8]中至少部分数据是否满足预定条件C9、判断Wi10[ki-178,ki-9]中至少部分数据是否满足预定条件C10和判断Wi11[ki-179,ki-10]中至少部分数据是否满足预定条件C11。图21所示的实施方式中,Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5,从潜在分割点ki沿着数据流分割点查找方向跳跃7个字节,在第7个字节的结束位置获得当前潜在分割点kj,如图22所示,根据为去重服务器103预设的规则,为潜在分割点kj确定窗口Wj1[kj-169,kj],判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式相同,因此如图33所示,Wj1表示窗口Wj1[kj-169,kj],为判断Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1,选择5个字节,图33中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”依次看成40个位,分别表示为a1'、a2'、a3'、a4'…a40'。a1'、a2'、a3'、a4'…a40'中的任一at',当at'=0时,Vat'=-1,当at'=1时,Vat'=1,根据at'与Vat'对应关系,生成Va1'、Va2'、Va3'、Va4'…Va40'。判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式相同,因此使用相同的随机数:h1、h2、h3、h4...h40。Sa'=Va1'*h1+Va2'*h2+Va3'*h3+Va4'*h4+…+Va40'*h40。因为h1、h2、h3、h4...h40服从正态分布,因此,Sa'也服从正态分布。当Sa'为正数,则Wj1[kj-169,kj]中至少部分数据满足预定条件C1,当Sa'为负数或0,则Wj1[kj-169,kj]中至少部分数据不满足预定条件C1,Sa'为正 数的概率为1/2。
判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式和判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2的方式相同,因此,如图33所示,表示判断窗口Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2时选择的1个字节,相邻两个选择的字节之间相差42个字节。在图33中,分别用序号170、128、86、44和2表示,相邻两个选择的字节之间相差42个字节。将序号170、128、86、44和2的字节依次看成40个位,分别表示为b1'、b2'、b3'、b4'…b40'。b1'、b2'、b3'、b4'…b40'中的任一bt',当bt'=0时,Vbt'=-1,当bt'=1时,Vbt'=1,根据bt'与Vbt'对应关系,生成Vb1'、Vb2'、Vb3'、Vb4'…Vb40'。判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式和判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2的方式相同,因此,使用相同的随机数:h1、h2、h3、h4...h40,Sb'=Vb1'*h1+Vb2'*h2+Vb3'*h3+Vb4'*h4+…+Vb40'*h40。因为h1、h2、h3、h4...h40服从正态分布,因此,Sb'也服从正态分布。当Sb'为正数,则Wj2[kj-170,kj-1]中至少部分数据满足预定条件C2,当Sb'为负数或0,则Wj2[kj-170,kj-1]中至少部分数据不满足预定条件C2,Sb'为正数的概率为1/2。
同理,判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3的方式与判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4、判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj -176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-178,kj-9]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj-10]中至少部分数据是否满足预定条件C11,在此不再赘述。
本实施例中使用随机函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz,仍然以图21所示实施方式为例,根据在去重服务器103上预设的规则,为潜在分割点ki确定窗口Wi1[ki-169,ki],判断Wi1[ki-169,ki]中至少部分数据是否满足预定的条件C1,如图32所示,Wi1表示窗口Wi1[ki-169,ki],为判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1,选择5个字节,图32中序号为169、127、85、43和1的字节“■”分别表示选择的1个字节,相邻两个选择的字节之间相差42个字节。将序号为169、127、85、43和1的字节“■”转换成1个十进制数,范围为0-(2^40-1),使用均匀分布随机数生成器为0-(2^40-1)中的每一个十进制数生成1个指定值,记录0-(2^40-1)中的每一个十进制数与指定值之间的对应关系R,一旦指定则该十进制数对应的指定值就不变,该指定值服从均匀分布,如果该指定值为偶数,则Wi1[ki-169,ki]中至少部分数据满足预定条件C1,如果该指定值为奇数,则Wi1[ki-169,ki]中至少部分数据不满足预定条件C1,C1表示按照上述方法获得的指定值为偶数。因为均匀分布的随机数为偶数的概率为1/2,因此,Wi1[ki-169,ki]中至少部分数据满足预定条件C1的概率为1/2。在图21所示的实施方式中,使用同样的规则,分别判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2,判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3、判断Wi4[ki-172,ki-3]中至少部分数据是否满足预定条件C4、判断Wi5[ki-173,ki-4]中至少部 分数据是否满足预定条件C5,在此不再赘述。
当Wi5[ki-173,ki-4]中至少部分数据不满足预定条件C5,从潜在分割点ki沿着数据流分割点查找方向跳跃7个字节,在第7个字节的结束位置获得当前潜在分割点kj,如图22所示,根据为去重服务器103预设的规则,为潜在分割点kj确定窗口Wj1[kj-169,kj],判断窗口Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1的方式与判断窗口Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的方式相同,因此,使用相同的0-(2^40-1)中的每一个十进制数与指定值之间的对应关系R,如图33所示,Wj1表示窗口,为判断Wj1[kj-169,kj]中至少部分数据是否满足预定条件C1,选择5个字节,图33中“■”表示选择的1个字节,相邻两个选择的字节“■”之间相差42个字节。将序号为169、127、85、43和1的字节“■”转换成1个十进制数,在R查找该十进制数对应的指定值,如果该指定值为偶数,则Wj1[kj-169,kj]中至少部分数据满足预定条件C1,如果该指定值为奇数,则Wj1[kj-169,kj]中至少部分数据不满足预定条件C1,因为均匀分布的随机数为偶数的概率为1/2,因此,Wj1[kj-169,kj]中至少部分数据满足预定条件C1的概率为1/2。同理,判断Wi2[ki-170,ki-1]中至少部分数据是否满足预定条件C2的方式和判断Wj2[kj-170,kj-1]中至少部分数据是否满足预定条件C2的方式相同,判断Wi3[ki-171,ki-2]中至少部分数据是否满足预定条件C3的方式与判断Wj3[kj-171,kj-2]中至少部分数据是否满足预定条件C3的方式相同,同理,判断Wj4[kj-172,kj-3]中至少部分数据是否满足预定条件C4、判断Wj5[kj-173,kj-4]中至少部分数据是否满足预定条件C5、判断Wj6[kj-174,kj-5]中至少部分数据是否满足预定条件C6、判断 Wj7[kj-175,kj-6]中至少部分数据是否满足预定条件C7、判断Wj8[kj-176,kj-7]中至少部分数据是否满足预定条件C8、判断Wj9[kj-177,kj-8]中至少部分数据是否满足预定条件C9、判断Wj10[kj-178,kj-9]中至少部分数据是否满足预定条件C10和判断Wj11[kj-179,kj-10]中至少部分数据是否满足预定条件C11,在此不再赘述。
图1所示的本发明实施例中的去重服务器103,是指能够实现本发明实施例所描述的技术方案的装置,如图18所示,通常包括中央处理单元、主存储器以及输入输出接口。中央处理单元、主存储器与输入输出接口之间相互通信,主存储器存储可执行指令,中央处理单元执行主存储器中存储的可执行指令,从而执行特定的功能,使去重服务器103具备特定功能,如本发明实施例图20至图33所描述的查找数据流分割点。因此,如图19所示,根据20至图33所示的本发明实施例,去重服务器103,在去重服务器103上预设有规则,所述规则为:为潜在分割点k确定M个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,其中,x为1到M连续的自然数,M≥2,Ax和Bx为整数;
去重服务器103包括确定单元1901和判断处理单元1902。其中,确定单元1901用于执行步骤a):
a)依据所述规则为当前潜在分割点ki确定对应的窗口Wiz[ki-Az,ki+Bz],i和z为整数,并且1≤z≤M;
判断处理单元1902,用于判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz;
当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N 个数据流分割点最小查找单位U,N*U不大于‖Bz‖+maxx(‖Ax‖),获得新的潜在分割点,则所述确定单元1901为所述新的潜在分割点执行步骤a);
当所述当前潜在分割点ki的M个窗口中的每一个窗口Wix[ki-Ax,ki+Bx]中至少部分数据满足预定条件Cx,则所述当前潜在分割点ki为数据流分割点。
进一步地,所述规则还包括:至少两个窗口Wie[ki-Ae,ki+Be]与Wif[ki-Af,ki+Bf],满足条件:|Ae+Be|=|Af+Bf|,Ce=Cf。进一步地,所述规则还包括:Ae和Af为正整数。进一步地,所述规则还包括:Ae-1=Af,Be+1=Bf。
进一步地,判断处理单元1902具体用于使用随机函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz。更进一步地,判断处理单元1902具体使用hash函数判断窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足预定条件Cz。
进一步地,判断处理单元1902用于当所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据不满足所述预定条件Cz,从所述当前潜在分割点ki沿所述数据流分割点查找方向跳跃N个数据流分割点最小查找单位U,获得所述新的潜在分割点,所述确定单元1901为所述新的潜在分割点执行步骤a),根据所述规则,为所述新的潜在分割点确定的窗口Wic[ki-Ac,ki+Bc]的左边界与所述窗口Wiz[ki-Az,ki+Bz]的右边界重合或者为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]的左边界位于所述窗口Wiz[ki-Az,ki+Bz]范围之内;其中,为所述新的潜在分割点确定的所述窗口Wic[ki-Ac,ki+Bc]是根据所述规则,为所述新的潜在分割点确定的M个窗口按照数据流查找方向获得的序列中排序第 一的窗口。
进一步地,判断处理单元1902使用随机函数判断所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据是否满足所述预定条件Cz,具体包括:
在所述窗口Wiz[ki-Az,ki+Bz]中选择F个字节,将所述F个字节反复利用H次,共获得F*H个字节,其中每个字节由8位组成,记为am,1…am,8,表示所述F*H个字节中第m个字节的第1到第8位,所述F*H个字节对应的位可以表示为:当am,n=1时,Vam,n=1,当am,n=0时,Vam,n=-1,其中am,n表示am,1…am,8中的任一个,所述F*H个字节对应的位按照am,n与Vam,n的转换关系得到矩阵Va,所述矩阵Va表示为:从服务正态分布的随机数中选择F*H*8个随机数组成矩阵R,所述矩阵R表示为: 将所述矩阵Va的第m行与所述矩阵R的第m行的随机数相乘,然后求和得到一个值,具体表示为Sam=Vam,1*hm,1+Vam,2*hm,2+…+Vam,8*hm,8,同理,获得Sa1、Sa2…到SaF*H,统计Sa1、Sa2…到SaF*H中满足大于0的值的个数K,当K为偶数,则所述窗口Wiz[ki-Az,ki+Bz]中至少部分数据满足所述预定条件Cz。
根据20至图33所示的本发明实施例提供的基于服务器查找数据流分割点的方法中,为潜在分割点ki确定窗口Wix[ki-Ax,ki+Bx],其 中,x分别为1到M连续的自然数,M≥2,可以并行判断M个窗口中每一个窗口中至少部分数据是否满足预定条件Cx,或者依次判断窗口中至少部分数据是否满足预定条件,也可以依次窗口Wi1[ki-A1,ki+B1],中至少部分数据满足预定条件C1时,再判断Wi2[ki-A2,ki+B2]中至少部分数据满足预定条件C2时,直到判断Wim[ki-Am,ki+Bm]中至少部分数据满足预定条件Cm。实施例中其他窗口的判断与此相同,不再赘述。
另外,根据20至图33所示的本发明实施例,在去重服务器103上预设有规则,所述规则:为潜在分割点k确定M个窗口Wx[k-Ax,k+Bx]和窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,x分别为1到M连续的自然数,M≥2,在该预设规则中,A1、A2、A3…Am可以不全部相等,B1、B2、B3…Bm可以不全部相等,C1、C2、C3…CM也可以不全部相同。在图21所示的实施方式中,在Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]、Wi4[ki-172,ki-3]、Wi5[ki-173,ki-4]、Wi6[ki-174,ki-5]、Wi7[ki-175,ki-6]、Wi8[ki-176,ki-7]、Wi9[ki-177,ki-8]、Wi10[ki-178,ki-9]和Wi11[ki-179,ki-10]中,各窗口大小相同,即窗口大小均为169字节,同时判断窗口中至少部分数据是否满足预定条件的方式也相同,具体见上述判断Wi1[ki-169,ki]中至少部分数据是否满足预定条件C1的描述,但在图11所示的实施方式中,Wi1[ki-169,ki]、Wi2[ki-170,ki-1]、Wi3[ki-171,ki-2]、Wi4[ki-172,ki-3]、Wi5[ki-173,ki-4]、Wi6[ki-174,ki-5]、Wi7[ki-175,ki-6]、Wi8[ki-176,ki-7]、Wi9[ki-177,ki-8]、Wi10[ki-168,ki+1]和Wi11[ki-179,ki+3]窗口大小可以不相同,同时判断窗口中至少部分数据是否满足预定条件的方式也可以不相同。在所有实施例中,根据为去重服务器103预设的规则,判断窗口Wi1中至少部分数据是否 满足预定条件C1的方式与判断窗口Wj1中至少部分数据是否满足预定条件C1的方式必然相同,判断Wi2中至少部分数据是否满足预定条件C2的方式与判断Wj2中至少部分数据是否满足预定条件C2的方式必然相同…判断窗口WiM中至少部分数据是否满足预定条件CM的方式与判断窗口WjM中至少部分数据是否满足预定条件CM的方式必然相同。在此不再赘述。
根据20至图33所示的本发明实施例,在去重服务器103上预设有规则,ka、ki、kj、kl和km为沿着数据流分割点查找方向查找分割点时获得的潜在分割点,ka、ki、kj、kl和km都依据该规则。本发明实施例中的窗口Wx[k-Ax,k+Bx]表示一个特定范围,在该特定范围选择数据以判断这些数据是否满足预定条件Cx,具体地,可以在该特定范围内选择部分数据,也可以选择全部数据以判断这些数据是否满足预定条件Cx。本发明实施例中具体使用的窗口概念可参照窗口Wx[k-Ax,k+Bx],在此不再赘述。
窗口Wx[k-Ax,k+Bx]中,(k-Ax)和(k+Bx)表示该窗口Wx[k-Ax,k+Bx]的两个边界,其中(k-Ax)表示窗口Wx[k-Ax,k+Bx]相对于潜在分割点k位于数据流分割点查找反方向的边界,(k+Bx)表示窗口Wx[k-Ax,k+Bx]相对于潜在分割点k位于数据流分割点查找方向的边界。具体地,在本发明实施例中,在图20至图33所示的数据流分割点查找方向为从左向右,则其中(k-Ax)表示窗口Wx[k-Ax,k+Bx]相对于潜在分割点k位于数据流分割点查找反方向的边界(即左边界),(k+Bx)表示窗口Wx[k-Ax,k+Bx]相对于潜在分割点k位于数据流分割点查找方向的边界(即右边界)。如果在图20至图33所示的数据流分割点查找方向为从右向左,则其中(k-Ax)表示窗口Wx[k-Ax, k+Bx]相对于潜在分割点k位于数据流分割点查找反方向的边界(即右边界),(k+Bx)表示窗口Wx[k-Ax,k+Bx]相对于潜在分割点k位于数据流分割点查找方向的边界(即左边界)。
本领域普通技术人员可以意识到,结合本发明实施例图20至图33描述的各示例的单元及算法步骤,本发明实施例的关键特征可以与其他技术相结合,以更为复杂的形式呈现,但仍会包含本发明的关键特征。在真实环境中可能使用备用分割点,例如一种实施方式为,根据为去重服务器103预设的规则,为潜在分割点ki确定11个窗口Wx[k-Ax,k+Bx]及窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,x为1到11连续的自然数,当11个窗口中每一个窗口Wx[k-Ax,k+Bx]中至少部分数据均满足预定条件Cx,则潜在分割点ki为数据流分割点,当超过设定的最大数据块时,仍未查找到分割点,这时可能使用备用预设规则,备用的预设规则与在去重服务器103上预设的规则类似,备用的预设规则为:例如为潜在分割点ki确定10个窗口Wx[k-Ax,k+Bx]及窗口Wx[k-Ax,k+Bx]对应的预定条件Cx,x为1到10连续的自然数,确定当10个窗口中每一个窗口Wx[k-Ax,k+Bx]中至少部分数据均满足预定条件Cx,则潜在分割点ki为数据流分割点,当超过设定的最大数据块时,仍未查找到数据流分割点时,从最大数据块的结束位置作为强制分割点。
根据20至图33所示的本发明实施例,在去重服务器103上预设有规则,所述规则中为潜在分割点k确定M个窗口,并不一定要求先有一个潜在分割点k,可以通过确定的M个窗口来判断潜在分割点k。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件 方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在提供的几个实施例中,应该理解到,所公开的系统、方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取非易失性存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个非易失性存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部 或部分步骤。而前述的非易失性存储介质包括:U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!