一种基于多分类器集成的图像文字识别方法与流程
本发明涉及图像文字识别领域,更具体地,涉及一种基于多分类器集成的图像文字识别方法。
背景技术:
社会发展进入信息时代,随着实践活动的扩大、深入和社会化需要,人类需要去识别很多类的形式内容复杂的信息。人们已经不再停留在自己的耳朵和眼睛去直接获得这些信息,而是使用计算机将文字自动的输入计算机。由于科技水平不断提高,使得各种不同的研究对象得到“图像化”和“数字化”,以图像为主的多媒体信息迅速成为重要的信息传递媒介,图像中的文字信息包含了丰富的高层语义信息。提取出这些文字,对于图像高层次语义的理解、索引和检索非常有帮助。
现在对于文字图像识别技术的研究,还面临几个问题,一是图像数据量大,一般来说,要取得较高的识别精度,原始图像应具有较高的分辨率,至少应大于64×64。二是图像污损,由于目标环境的干扰、传输的误差、传感器的误差、噪声、背景干扰、变形等会污损图像。三是准确性,位移、旋转、尺度变化、扭曲,和人类的视觉一样,目标和传感器之间存在有位置的变化,因此,要求系统在目标产生位移、旋转、尺度变化、扭曲时,仍能够正确识别目标。四是实时性,在军事领域的应用中,大都要求系统能够实时的识别目标,这就要求系统有极快的出来速度和识别效率。
鉴于当前文字识别系统的发展现状,如何提高印刷体文字的识别率仍是当前的研究热点,如何在世界场景下识别文字将是文字识别系统发展的一个方向。此外,如何构建具有版面自动分析、容错性强、识别率高、错误自学习自修正、易扩展特点的文字识别系统是文字识别自动化的研究目标。所以,图像文字识别技术的研究显得尤为重要。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种自动化的、识别率高的基于多分类器集成的图像文字识别方法。
为解决上述技术问题,本发明的技术方案如下:
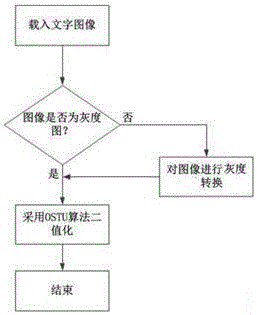
一种基于多分类器集成的图像文字识别方法,所述方法包括以下步骤:
S1:将彩色的待识别图像转换为灰度图像,若待识别图像本身为灰度图像则省略本步骤;
S2:对得到的灰度图像进行二值化处理,并将包含文字信息的图像区域分割出来;
S3:将每个汉字从整块文字图像中分割出来;
S4:提取每个汉字的网格特征和方向特征;
S5:采用最小距离分类器,选用笔画密度总长度特征来进行第一层的粗分类;
S6:采用最邻近分类器,分别选用外围特征、网格特征和方向特征相结合来完成第二层的分类匹配。
在一种优选的方案中,步骤S1中,将彩色的待识别图像转换为灰度图像时,采用加权平均值方法进行灰度转换,即对R、G、B的值加权平均:R=G=B=a*R+b*G+c*B;其中,R、G、B分别表示红色、绿色和蓝色,a,b,c分别为R、G、B的权值,其中b>a>c。
在图像文字识别时,输入的待识别图像一般都是彩色RGB图像,其包含了大量的颜色信息,要是对图像进行处理会降低系统的执行速度,加之RGB图像包含有很多与文字识别无关的颜色信息,不利于文字的定位,而灰度图像,只包含亮度信息,不包含色彩信息,有利于后期对图像进一步的处理,可以提高运行速度,有利于下一步的文字定位。由于人眼对绿色最为敏感,对红色的敏感度次之,对蓝色的敏感度最低,所以当在b>a>c的条件下,可以得到较易于识别的灰度图像。
在一种优选的方案中,步骤S2中,采用OTSU算法(大津法或最大类间方差法)对灰度图像进行二值化处理。
图像的二值化处理,是对图像上的像素点的灰度值置为0或255,即当所有灰度大于或等于阀值的像素点被判定为特定的物体,其灰度值为255,否则,其灰度值为0,表示其他的物体区域或者背景,处理后的图像将呈现明显的黑白效果。图像的二值化将是具有256个灰度等级的灰度图像经过合适的阀值选取后,将像素的灰度级分成2级。经过二值化处理后的图像,其性质只与灰度值为0或255的像素点的位置有关,不再涉及到其他灰度级的像素点,便于对图像作进一步的处理,且数据的处理量和压缩量较小,且获得的二值化图像仍旧可以反映图像整体与局部的特征。为了得到理想的二值化图像,阀值的选取至关重要。选取适当的阀值,不仅可以有效地去除噪声,而且可将图像明显地分成目标区域和背景,大大减少信息量,提高处理的速度。
在一种优选的方案中,步骤S3中,采用字切分法识别图像区域里的单个文字,即利用字和字之间的空白间隙在图像水平方向上的垂直投影形成的波峰与波谷将单个字符分割出来。
在一种优选的方案中,步骤S3中,为了提高准确率,采用回归式字切分法识别单个文字,即根据汉字是方形图形、具有大致的均匀尺寸的特点,利用行切分时获取的文字高度来估计文字的宽度,从而预测下一个文字的位置。
在一种优选的方案中,步骤S4中,提取文字网格特征的具体方法如下:
1)将文字点阵分成8×8份;
2)求出每份中的黑点数,用P11,P12,…P18,P21…P88表示;
3)求出文字总的黑点数P=P11+P12+…+Pl8+P21+…+P88;
4)求出每份中黑点数所占整个文字黑点数的百分比Pij=Pij× 100 / P,其中i、j为大于等于1且小于等于8的整数,特征向量(P11,P12,…P18,P21…P88)就是文字的网格特征。
在一种优选的方案中,步骤S4中,提取文字方向特征的具体方法如下:
对文字点阵图像进行二值化和归一化,并提取轮廓信息,对轮廓上的每个点赋予一个或两个方向的属性,方向取水平、垂直及正反45°共四个角度,将文字点阵划分为n×n个网格,计算每个网格中包括的4个方向属性的个数,从而构成一个4维向量,综合所有的网格特征,形成一个4×n×n维的特征向量,即为方向特征。
在一种优选的方案中,步骤S5中,构建最小距离分类器的具体方法如下:
1)从样本中提取文字的笔画密度长度作为粗分类的特征向量。2)分别计算每一个类别的样本所对应的特征,每一类的每一维都有特征集合,通过集合,可以计算出一个均值,也就是特征中心。3)通常为了消除不同特征因为量纲不同的影响,我们对每一维的特征,需要做一个归一化,或者是放缩到(-1,1)等区间,使其去量纲化。4)利用选取的距离准则,对待分类的本进行判定。
在一种优选的方案中,步骤S6中,构建最邻近分类器的具体方法如下:
1)初始化距离为最大值
2)计算未知样本和每个训练样本的距离dist
3)得到目前K个最临近样本中的最大距离maxdist
4)如果dist小于maxdist,则将该训练样本作为K-最近邻样本
5)重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
6)统计K-最近邻样本中每个类标号出现的次数
7)选择出现频率最大的类标号作为未知样本的类标号
与现有技术相比,本发明技术方案的有益效果是:本发明提供一种基于多分类器集成的图像文字识别方法,将彩色的待识别图像转换为灰度图像;对灰度图像进行二值化处理,并将包含文字信息的图像区域分割出来;将每个汉字从整块文字图像中分割出来;提取每个汉字的网格特征和方向特征;采用最小距离分类器,选用笔画密度总长度特征来进行第一层的粗分类;采用最邻近分类器,分别选用外围特征、网格特征和方向特征相结合来完成第二层的分类匹配。对于特征提取,采用网格和方向特征结合的方法,使文字识别既有较强的抗干扰能力、又有较强的描述文字局部结构的能力,而且受笔画宽度的影响较小;对于图像文字识别中,应用了人工智能学习技术,提高系统的适应性并且识别率高;对于分类器设计,采用了最小距离分类器、最临近分类器互补结合的分类器集成技术,使系统更具可靠性。
附图说明
图1为基于多分类器集成的图像文字识别方法的流程图。
图2为灰度转换和二值化的示意图。
图3为回归式字切分法的示意图。
图4为提取文字网格特征的示意图。
图5为提取方向网格特征的示意图。
图6为多个分类器集成的文字识别示意图。
图7为整段文字分割成单个的字体的示意图。
图8为以文本框的形式输出文字的示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1所示,一种基于多分类器集成的图像文字识别方法,所述方法包括以下步骤:
S1:将彩色的待识别图像转换为灰度图像,若待识别图像本身为灰度图像则省略本步骤;
将彩色的待识别图像转换为灰度图像时,采用加权平均值方法进行灰度转换,即对R、G、B的值加权平均:R=G=B=a*R+b*G+c*B;其中,R、G、B分别表示红色、绿色和蓝色,a,b,c分别为R、G、B的权值,其中b>a>c。
在图像文字识别时,输入的待识别图像一般都是彩色RGB图像,其包含了大量的颜色信息,要是对图像进行处理会降低系统的执行速度,加之RGB图像包含有很多与文字识别无关的颜色信息,不利于文字的定位,而灰度图像,只包含亮度信息,不包含色彩信息,有利于后期对图像进一步的处理,可以提高运行速度,有利于下一步的文字定位。由于人眼对绿色最为敏感,对红色的敏感度次之,对蓝色的敏感度最低,所以当在b>a>c的条件下,可以得到较易于识别的灰度图像。
S2:对得到的灰度图像进行二值化处理,并将包含文字信息的图像区域分割出来;
如图2所示,步骤S2中,采用OTSU算法对灰度图像进行二值化处理。图像的二值化处理,是对图像上的像素点的灰度值置为0或255,即当所有灰度大于或等于阀值的像素点被判定为特定的物体,其灰度值为255,否则,其灰度值为0,表示其他的物体区域或者背景,处理后的图像将呈现明显的黑白效果。图像的二值化将是具有256个灰度等级的灰度图像经过合适的阀值选取后,将像素的灰度级分成2级。经过二值化处理后的图像,其性质只与灰度值为0或255的像素点的位置有关,不再涉及到其他灰度级的像素点,便于对图像作进一步的处理,且数据的处理量和压缩量较小,且获得的二值化图像仍旧可以反映图像整体与局部的特征。为了得到理想的二值化图像,阀值的选取至关重要。选取适当的阀值,不仅可以有效地去除噪声,而且可将图像明显地分成目标区域和背景,大大减少信息量,提高处理的速度。
OTSU算法是按图像的灰度特性,将图像分成背景和目标2部分,背景和目标之间的类间方差越大,说明构成图像的2部分的差别越大,当部分目标错分为背景或部分背景错分为目标都会导致2部分差别变小,因此,使类间方差最大的分割意味着错分概率最小;
Otsu算法步骤如下:
设图象包含L个灰度级(0,1…,L-1),灰度值为i的的象素点数为Ni ,图象总的象素点数为N=N0+N1+...+N(L-1),灰度值为i的点的概率为:P(i) = N(i)/N;
门限t将整幅图象分为暗区c1和亮区c2两类,则类间方差σ是t的函数:σ=a1*a2(u1-u2)^2 ;式中,aj 为类cj的面积与图象总面积之比,a1=sum(P(i)) i->t, a2 = 1-a1;
uj为类cj的均值,u1 = sum(i*P(i))/a1 0->t, u2 = sum(i*P(i))/a2, t+1->L-1,该法选择最佳门限t^使类间方差最大,即:令Δu=u1-u2,σb = max{a1(t)*a2(t)Δu^2}。
S3:将每个汉字从整块文字图像中分割出来;
如图3所示,步骤S3中,采用字切分法识别图像区域里的单个文字,即利用字和字之间的空白间隙在图像水平方向上的垂直投影形成的波峰与波谷将单个字符分割出来。为了提高准确率,采用回归式字切分法识别单个文字,即根据汉字是方形图形、具有大致的均匀尺寸的特点,利用行切分时获取的文字高度来估计文字的宽度,从而预测下一个文字的位置。
S4:提取每个汉字的网格特征和方向特征;
抽取单一种类的特征进行汉字识别,误识率不易降低,且抗干扰性也不易提高。因为这样所利用的汉字信息量有限,不能全面反映汉字的特点,对任何一种特征来说,必然存在其识别的“死角”,即利用这种特征很难区分汉字。从模式识别的角度来看,若将汉字的全部矢量化特征所组成的空间称作空间Ω(i=1,2,...),那么利用整个空间Ω的信息进行汉字识别,由于提供的汉字信息很充分,抗干扰性会大大增强。但是,在实际应用中,必须考虑到识别正确率与识别速度(运算量)及系统资源三者的折衷。所以任何一个实用的OCR系统只利用其中部分子空间的信息。由于信息的缺陷,便不可避免地遇到识别“死角”的问题。
在这些方法研究的基础上,本发明选择了汉字的网格特征和方向特征进行汉字识别,这些特征具有较强的抗干扰能力,又有较强的描述文字局部结构的能力,而且受笔画宽度的影响较小,相得益彰,使汉字识别的“死角”大幅减小,从而提高识别率。
如图4所示,步骤S4中,提取文字网格特征的具体方法如下:
1)将文字点阵分成m×m份,本实施例中分为8×8份。
2)求出每份中的黑点数,用P11,P12,…P18,P21…P88表示。
3)求出文字总的黑点数P=P11+P12+…+Pl8+P21+…+P88。
4)求出每份中黑点数所占整个文字黑点数的百分比Pij=Pij× 100 / P,其中i、j为大于等于1且小于等于8的整数,特征向量(P11,P12,…P18,P21…P88)就是文字的网格特征。
如图5所示,步骤S4中,提取文字方向特征的具体方法如下:
对文字点阵图像进行二值化和归一化,并提取轮廓信息,对轮廓上的每个点赋予一个或两个方向的属性,方向取水平、垂直及正反45°共四个角度,将文字点阵划分为n×n个网格,计算每个网格中包括的4个方向属性的个数,从而构成一个4维向量,综合所有的网格特征,形成一个4×n×n维的特征向量,即为方向特征。
S5:如图6所示,采用最小距离分类器,选用笔画密度总长度特征来进行第一层的粗分类;
最小距离分类器选用笔画密度总长度特征来进行第一层的粗分类。在这种方法中,被识别模式与所属模式类别样本的距离最小。假定c 个类别代表模式的特征向量用R1,…,Rc表示,x是被识别模式的特征向量,|x-Ri|是x与Ri(i=1,2,…,c)之间的距离,如果|x-Ri|最小,则把x分为第i类。
S6:采用最邻近分类器,分别选用外围特征、网格特征和方向特征相结合来完成第二层的分类匹配。
最邻近分类器分别选用网格特征和方向特征相结合来完成第二层的分类匹配。最近邻分类器是在最小距离分类的基础上进行扩展,将训练集中的每一个样本作为判别依据,寻找距离待分类样本最近的训练集中的样本,以此为依据来进行分类。
经过多次试验与研究,结论表明基于单个识别器原理不能从根本上提高系统性能,应依靠多个分类器的识别结果的集成。多分类器集成即通过多个互补的分类器来改善单个分类器的性能,得到一个可靠性更高的识别系统。因此,本发明采用最小距离分类器及最邻近分类器集成,通过分类器设计上的优化,进一步提高了文字的可以别率和准确率。
为验证本发明的有效性,需进行相关实验,本发明使用包含697个汉字的原始图像来进行测试。首先把该原始图片转化为灰度图像以便进行下一步的操作。通过回归式字切分法把整段文字分割成单个的字体,测试效果如图7,可以准确地分割每个汉字。最后,采用多特征提取和多分类器集成的方法识别分割出来的文字,并以文本框的形式输出,测试结果如图8,结果全部正确。
多特征提取方法及多分类器集成方法使提高图像文字识别率成为可能,其良好的识别效果引起了人们的普遍重视,具有广阔的应用前景。本发明基于多分类器集成方法实现图像文字识别,使图像文字信息的处理及提取更具可行性。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!