基于视觉注意机制的目标零件识别方法与流程
本发明涉及零件识别的
技术领域:
,特别涉及一种基于视觉注意机制的目标零件识别方法。
背景技术:
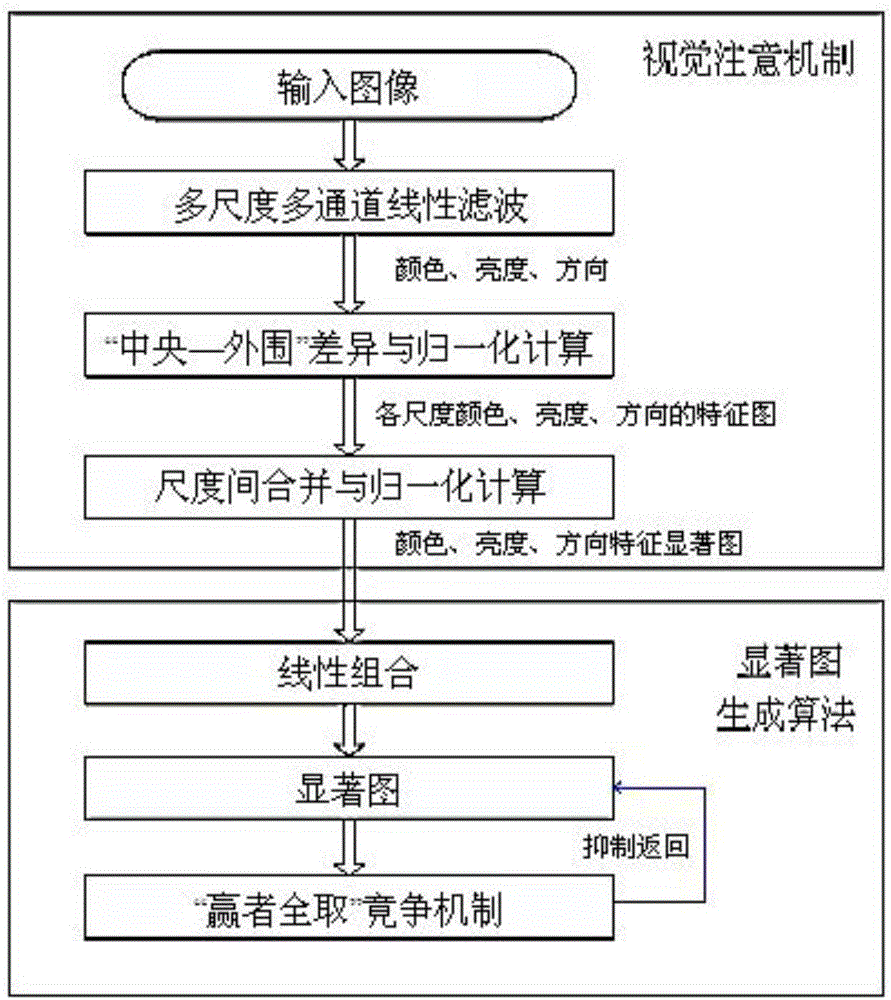
:通过机器视觉进行零件识别和定位,并引导工业机器人的机械手抓取和装配零件是工业机器人应用领域中的关键问题。目前,在各类流水生产线上,工业机器人执行得最多的作业就是对目标零件进行识别、定位、抓取、安装。但有时由于受到许多客观因素的影响,目标零件的位置和姿态可能发生改变,如果工业机器人还是按照预先设定好的程序去识别、定位、抓取、安装目标零件的话,则有可能会发生许多意想不到的后果。因此,为了提高流水生产线的适应能力,需要工业机器人对抓取和安装的目标零件进行高效的识别和定位,获取目标零件的三维位置和姿态,从而控制工业机器人的机械手去进行准确的抓取和安装。此外,随着小批量和多品种生产方式的迅速发展,对于流水生产线上许多不同种类和外形及尺寸的零件而言,仅仅靠人工的方法进行识别和定位根本无法高效和准确地完成作业任务,需要采用机器视觉技术和方法才能够快速地完成目标零件识别,从而使零件装配作业具有更好的灵活性、鲁棒性、高效率等。机器视觉技术是20世纪60年代发展起来的。1961年美国麻省理工学院林肯实验室采用摄像头作为计算机的输入,把物体识别和图像处理方法引入到机器人应用中。由此开始了机器视觉研究。作为全球知名的工业机器人企业,美国的AdeptTechnology公司在研制第一代工业机器人时就加入了机器视觉技术。在随后的研发过程中,该公司获得了丰富的机器视觉经验和成熟的机器视觉技术,这促使其成为了美国最大的工业机器人制造公司。(1)视觉注意机制概述人类通过视觉、听觉、嗅觉、触觉来认识和感知世界,其中视觉又是人类获取环境信息的最重要途径,所以对这方面的研究一直都是各方关注的热点。然而,当人们进入一个视觉场景中,扑面而来的视觉信息是海量的(每秒约108~109比特),但是人类视觉系统对信息处理的能力却是有限的,不能满足实时处理所有数据的需要。这时,灵长目类生物所具备的一项超强实时处理复杂环境数据的能力引起了人们的注意。这种能力可以在进一步处理视觉信息之前,选择性地输入其中的一小部分数据作为“感兴趣”和“有意义”的数据进行分析和处理。然后再逐个地切换到不同的关注焦点,从而实现计算量的极大降低,同时提高了视觉信息处理的效率。灵长目类动物的这种在海量数据中快速提取关键数据的能力,被称为视觉选择性注意机制。如图2所示是几个视觉注意的例子,如在图2(a)中,空心圆圈会首先被注意到;在图2(b)中,则是首先注意到实心圆圈,而忽略其它的正方形。对视觉注意机制研究最先始于神经生物学和心理学领域,用于研究一些心理模型和认知模型。随着图像处理和机器视觉系统的发展,越来越多的注意机制模型在这些领域内产生与发展。视觉注意机制的几个应用领域为:①目标检测和目标识别。面对一个复杂的视觉场景时,大量其它对象的存在会严重影响对目标物体的检测和识别,其中最主要的影响还是图像处理的效率。因为大量的计算资源都花费在其它对象的识别上,处理的信息量和计算的复杂度都相对较大。引入视觉注意机制的作用就是能够合理分配计算资源,将处理的重心放在那些“疑似”或者“关注”的对象上。②图像的压缩和编码。现存一些比较主流的图像压缩方法,绝大部分都是将图像的所有数据同等对待,采用同样的压缩策略和压缩比例进行压缩,这对于每个特定的应用场景来说,都不算是一个明智之举。因为对于人的视觉系统或者计算机的视觉处理来说,每个应用场景中都只是需要图像中的一部分数据进行处理,比如:行人监控主要关注的是人,其它处于图片中的信息是可有可无的;车辆监测则关注车,其它的信息没有太大的意义。总的来说,引入视觉注意机制可以将关键信息提取出来,采取一些高保真的压缩策略,对于其它次要的信息,则可以采取一些有损压缩策略。这样就可以在保证较高数据压缩比的同时,还能保证图像中的关键信息不被丢失。③图像检索和图像分类。现今图像检索领域主要的研究方向是基于内容的检索方式,如何提取出分辨效率更高的图像特征来表示对应图像的内容就是该领域内最急迫要解决的问题。而注意机制可能就是一个有效可行的解决方案,提取出图像中的关键信息用于表征整个图像的内容,通过对比关键信息获取图像之间的相似度。这样,可以提高图像检索和分类的效率。同时,还能够有效减少或者避免图像中不相关内容的影响。(1)视觉注意机制理论1)特征整合理论(FeatureIntegratedTheory)。特征整合理论是由英属哥伦比亚大学Treisman教授和牛津大学Gelade教授提出的,之后受到了注意机制领域内的广泛关注,并在此基础上形成和发展了大量视觉注意机制计算模型。对于注意机制的特征整合理论,人们注意到单一整体的对象主要有两种方式:通过焦点注意或通过从上而下的视觉信息处理。但是处于某个既定的环境中,无法确定是哪种方式在起作用,或者不知道哪种方式对视觉系统更有用。通常情况下,这两种方式是协同工作,只是在一些极端条件下,可以看到这两个方式会以几乎完全独立的方式进行工作。该理论的结构如图3所示,描述了视觉信息的基本处理流程和关注区域的生成的过程。Treisman将基于焦点注意的物体识别方式称为特征登记阶段,即预注意阶段:此时视觉系统对整个图像区域并行地以“光点”的方式采集底层特征(包括颜色、方向、尺寸、距离等),对于人类来说,几乎是意识不到这种完全自动化的处理过程。预注意阶段的处理可以促使人们在视觉场景中进行指有向性的探索。但是,视觉早期阶段只能检测单一独立的特征,而不能检测到各个特征之间的关系,也不能确定特征与位置之间的联系。然后对特征采用相应模板进行独立的编码,生成特征地图FM(FeatureMap)。如图3中的颜色、方向、尺寸等。每个多维特征都包含多个特征图,比如颜色特征则会包含红、绿、蓝三种特征图。然后基于特征图建立反映图像显著性的位置图(MapofLocation),这可以指出关注物体在图像中所处的位置,但是无法判别显著区域内的物体是什么。Treisman将另一种基于自上而下处理物体识别方式称为特征整合阶段,在这个阶段开始识别物体。当物体发生遮挡时,就会严重影响焦点注意过程,所以需要通过自上而下的处理才能识别物体。此时,视觉系统逐个扫描位置图上的显著区域,把区域内相关特征按照既定的方式进行组合,以生成对某一物体的表征。视觉系统在处理位置时,需要集中注意力把原始的、相互独立的特征整合为一个单一的物体。当注意力被分散或者超过人们承受能力时,就会出现将某些刺激特征不恰当地结合,即错觉性结合(IllusoryConjunctions),从而造成错觉现象。特征整合理论的成立基于以下设定条件:①预注意阶段对图像中一些简单和可用的数据进行编码,生成一些特征模块。这些模块可能拥有关于空间位置关系的信息,但它们不能直接向特征整合阶段提供这些标志空间位置的数据。②在集中性注意产生作用时,就会开始对位置地图上,处于显著区域内的特征进行提取和组合。通过注意机制的处理,当前被选定域内所有特征都会融合到一个临时的物体表征或者文件中。③视觉系统对物体的识别过程为:先整合各个物体文件中有关其性质和结构关系的信息,然后形成对应的描述信息。最后将此描述与识别网络(RecognitionNetwork)中存储的物体描述进行比较,匹配则表示成功识别物体。特征整合理论存在以下性质:在一个熟悉场景中,一些可预测的物体可以通过匹配它们的一些独立特征来确定,而不需要再去检查它们在空间中的关系。这时对目标物体的搜索就相对简单,检测效率也较高。然而处于一个不太熟悉场景中,或任务相关联的是一些联合特征(ConjunctiveFeatures)时,对目标物体搜索的效率就会降低。比如搜索人脸时,当此人处于郊外旅游时,可以很快找出;但是当他与同伴穿着统一的服装照集体照时,找到他就需要花费很大的精力,即使此人很熟悉。特征分析与识别网络是特征理论中识别目标的关键,新的感知过程会在目标文件被取代时发生。2)引导搜索理论(GuidedSearchTheory)。引导搜索理论是哈佛大学Wolfe教授1994年提出的,该理论描述了视觉注意的神经机制,为认知神经心理学的发展提供了理论基础。引导搜索理论开始是在特征整合理论的基础上做一些调整,而后结合了Neisser将视觉处理分成预注意阶段和注意阶段的理论、Hoffman的两阶段模型以及Egeth在特征联合方面的研究成果。引导搜索模型的主要目的是用来解释人们在一个正常、连续的视觉场景中找出需要的视觉刺激源的能力,它认为人类主要是根据外界物体视觉上刺激的显著性来选择注意的对象。它和特征整合理论一样都认为单一特征搜索与联合特征搜索都包含两个阶段:并行阶段和序列阶段,但前者是后者的基础。其模型架构如图4所示,根据该模型架构可知其工作流程如下:首先,并行化处理整个图像,让刺激源通透过宽调谐的分类通道,生成有限个基本视觉特征组,即特征地图FM。对于颜色、方向以及尺寸等都可以有相对独立的特征地图,在每个特征类型中还可以细化成多个独立的特征地图,这一点和特征整合理论中的特征地图类似。此外,所有特征都可以集中显示在一个单独的多维特征地图中。在生成特征地图后,系统就通过计算各个区域的激活程度来确定显著程度。对于某个特定区域,其激活程度越大,就意味着被直接注意的几率越大。激活程度的计算由两个部分组成:刺激源自身特征驱动的bottom-up型激活程度与用户任务驱动的top-down型激活程度。前者用于标识某一对象在当前场景中的特殊性程度,后者用于提取那些任务需要的对象,且通常是特殊性较低的对象。对于这两种类型的激活程度还有两个计算原则:对于某个没有相关的top-down信息特征,则设置其top-down激活程度的权重为0;当干扰对象的某个属性与目标对象相同时,则降低该特征的bottom-up激活程度权重。最后,通过对各个区域计算得到的激活程度进行加权求和操作,从而生成激活地图AM(ActivationMap),视觉系统就按顺序分配有限容量的处理资源。并且可以将每个特征模型当成是一些地形图,其中的山峰就是那些激活程度较高的区域,而注意力则集中在这些山峰上。但是,山峰所标识的高激活程度并不表示其拥有任何标识对象的信息,其主要作用只是用于引导注意力,在没有任何内在命令时,就会首先注意最高激活程度的区域。在视觉搜索任务中,若在当前区域内没有找到目标物,则会重新配置注意区域到下一个拥有最高激活程度的区域上,以此类推直到找到目标或者出现搜索失败。3)整合竞争理论(IntegratedCompetitionTheory)。整合竞争理论是以英国剑桥大学Duncan教授为代表提出的。Duncan将视觉注意理论定义为研究人们应对同时发现多个物体的能力限制的方法。同时,他将这些理论分为三大派系:基于对象、差异以及空间的视觉注意理论。它们分别关注于同时察觉的独立对象数目的限制、可以生成单独差异域数目的限制以及空间区域内可以提取信息的限制。而整合竞争理论则是基于对象的视觉注意机制模型研究的重要基础之一。整合竞争理论来源于神经心理学上的视觉注意模型,在该模型中,视觉信息对于注意的竞争体现在多个视觉响应的人脑系统上,包括感觉与运动系统、大脑皮层与皮下层系统。通过多系统竞争的整合,会选择同一个对象作为注意目标。整合竞争理论的成立依赖于以下一般性原则:首先,视觉信息的输入会引起多个大脑系统的参与,这里认为在绝大多数系统中,对视觉信息的处理过程是相互竞争的:当加强对某个对象的响应时,就会导致减弱对其它对象的响应。其次,自上而下的信息对神经元活性的启动会影响与当前行为相关对象的竞争。比如,在执行查找绿色字符任务时,在纹理系统中对颜色进行编码,那么选择绿色视觉信息的神经元就会预先启动,同时其它颜色就会被大大的抑制,从而导致绿色字符的显示会占据竞争优势。最后,虽然竞争发生在各个大脑系统中,但是最终会由各部分的感觉运动神经网络完成竞争信息的整合。如果一个物体在某一个系统中获得关注,那么在其它系统中,这个物体也同样会得到大量的响应处理资源。这种信息的整合对于目标选择始于特定任务时是非常有必要的。(3)视觉注意机制模型根据生理学和心理学领域研究成果,注意分为基于空间的注意和基于目标的注意两种。根据这两个分类,在以上经典理论的基础上产生和发展了以下的注意机制计算模型。1)基于空间的注意机制模型①自底向上(bottom-up)注意模型。自底向上的注意是一种在图像基础上,由数据来驱动关注焦点的机制。Treisman的特征整合理论是自底向上注意模型的基础,也通过实验证明了该类型的注意会在某些极端条件下独立工作及其有效性。另外,这些自底向上注意模型的实现,还有一个重要的组成部分,就是Koch计算显著性的框架。Itti模型是空间注意模型的经典代表,它是第一个复杂高效的可计算注意机制模型。Itti模型的总体架构如图5所示,其实现过程如下。第一阶段:前期初级图像特征提取。Itti模型使用线性滤波器提取图像特征,并分别在每个通道和尺度下建立特征高斯金字塔。然后,在非均匀采样的基础上通过中央周边差(Center-surroundDifference)计算方法提取特征图FM。以颜色特征图计算为例,设r、g、b分别表示彩色图中的红、绿、蓝三色值,则有红R、绿G、蓝B、黄Y四个宽频颜色通道分量为:R=r-(g+b)/2,G=g-(r+b)/2,B=b-(r+g)/2,Y=(r+g)/2-∣r-g∣/2-b(1)式中,数值为负数时则置为0。然后,根据中央周边差理论计算基于高斯金字塔的红绿双向对比图RG,以及蓝黄双向对比图BY:RG(c,s)=∣(R(c)-G(c))Θ(G(s)-R(s)∣,BY(c,s)=∣(B(c)-Y(c))Θ(Y(s)-B(s)∣(2)式中,c和s均表示高斯金字塔尺度,且c∈{2,3,4},s=c+δ,δ∈{3,4},表示该模型选择的不同尺度。同理,可以得到亮度特征图和四个方向θ={0°,45°,90°,135°}上的方向特征图。第二阶段:生成显著图(SaliencyMap),使用标准化算子N(·)进行多特征合并。将所有特征图进行合并操作,生成显著图。然后根据显著图中的注意焦点,定位或者转换关注区域。标准化算子仅适用于没有top-down信息的情况下,其处理各个特征图的过程为:①标准化特征图上的值到固定范围[0,M]上,以消除各特征之间的幅值差异;②找出全局最大值M,计算其它局部最大的均值③最后全局乘以以最大程度上突出全局最大与局部最大值之间的差异。根据标准化算子计算各个特征维的显著图,尺度为4时的亮度、颜色、方向的显著图计算方法分别为:式中,表示跨尺度求和运算。然后,将这三个通道标准化后的显著图直接合并到最终的显著图S上:S=13(N(I‾)+N(C‾)+N(O‾))---(4)]]>通过胜者为王的策略,选择显著图上的最大值区域作为初始关注焦点,切换关注到下一个最大值之前需要使用禁止返回机制,避免重复访问同一个区域。通常,Itti算法具有较好的鲁棒性和准确性。但是,Itti模型生成的显著图只有原图尺寸的1/256,这极大的限制了其应用。所以,后续以Itti模型为指导,产生了一些全尺寸的图像显著性区域提取算法。②自顶向下(top-down)注意模型。自顶向下的注意是一种在学习的基础上,由任务或者知识驱动注意焦点的机制。由于在生理或心理学研究上,对于注意机制的具体工作方式还没有了解清楚,这导致几乎没有可用的自顶向下注意机制计算模型。然而,那些离开上层数据的指引,只依靠图片上的信息所产生的注意机制计算模型,会在目标自身信息有限、位置尺寸可变以及不够显著时,导致其效率大大降低。在自顶向下注意方面的研究,较突出的一个成果是Navalpakkam建立的一个任务导向模型。该模型是在其老师Itti的工作基础上形成的,其架构如图6所示。该模型的工作机理为:视觉脑以注意引导图中最有意义的图像块为当前显著区域。代理主要是作为其它三个部分的通信接口,工作记忆和长期记忆两个知识库用于计算当前显著区域的相关性,并用于更新任务相关图。目标识别的循环终止条件是,在任务相关图找到所有相关实体。2)基于目标的注意机制模型在整合竞争理论的基础上,注意机制模型是以物体为对象来进行切换、选择焦点,从而生成基于目标的注意模型。同时,这些模型基于以下观点:视觉系统在预注意阶段就会对所获取的图像进行初步聚类分析,同时注意机制就在这些聚类目标中选取特定目标。Sun和Fisher提出基于目标的视觉注意计算模型在该领域内广为流传,该模型发展了Duncan的整合竞争理论,并且融合了Koch和Itti等的视觉显著性计算模型、自底向上和自顶向下的视觉注意间的交互、基于目标的注意机制和基于空间的注意机制的结合、目标内及目标间的视觉表示等知识块。在此模型中,注意力的竞争不仅存在于目标内部,也存在与各个目标之间,而且注意力的转移分层进行。该模型架构如图7所示。Sun-Fisher模型主要解决的问题可以归纳为以下几点:首先,主要特征提取。这与Itti等提出的显著性模型类似,将输入图像分解成一系列多尺度的特征图,由此产生四个颜色金字塔(R,G,B,Y),一个亮度金字塔(I)和四个方向金字塔(θ={0°,45°,90°,135°}),实现一种自底向上的注意。其次,编组显著性映射。该模块实现了基于目标的注意和基于对象的注意融合,形成了一个目标和空间的层次结构。一个编组可以是一个点、一个物体、也可以是多个编组组成的层次结构。编组的显著性不仅由其周围的环境决定,同时还有编组内部各部件间的相互合作和竞争的影响。最后,注意竞争和焦点转移。该操作在模型中是多尺度的,具有由初次都到细尺度的层次结构。注意焦点由自底向上的显著性和自顶向下的指导共同决定。注意竞争首先在最粗的尺度下,且未被注意到过的目标上进行。综上所述,将视觉注意机制引入到流水生产线中进行目标零件识别和定位,会使工业机器人在作业过程中具有更大的灵活性。并且开发和应用视觉注意机制将有助于更进一步地提高工业机器人的智能水平。技术实现要素:本发明的目的在于克服目前在工业生产流水线上,生产零件需要通过传统的人工识别和手工装配的不足,提供了一种通用性、鲁棒性、并行性、适用性更好的基于视觉注意机制的目标零件识别方法。本发明的目的通过下述技术方案实现:一种基于视觉注意机制的目标零件识别方法,所述目标零件识别方法包括:步骤S1、视觉注意机制模型选择,选择基于特征的注意机制模型和基于空间的注意机制模型,以便能够在此基础上利用生物的中央周边滤波器结构,在多个空间尺度上提取特征,所述特征包括颜色、方向、亮度;步骤S2、特征组合的显著图生成,将颜色、方向和亮度特征组合成为特征图,从而得到对应于颜色、方向、亮度特征的显著性描述,并将这些特征的显著性描述经过归一化计算及线性组合后形成显著图;步骤S3、目标生产零件识别策略,按照采集零件图像、生成显著图、二值化处理及优化、抽取显著区域、零件区域抽取的流程来进行零件识别。进一步地,所述基于特征的注意机制模型以关键字形式给出具体任务,将生产零件的颜色、方向、亮度特征作为标本,与所需生产零件的颜色、方向、亮度特征的最小偏差作为显著度,首先用先验知识定义当前生产零件并存储起来,接着通过学习生产零件的基本特征,计算基本特征与已有特征的相识度,从而检测出最相关的生产零件,最后在目标场景中找到最显著的位置,并与已有的生产零件进行匹配。进一步地,所述基于空间的注意机制模型利用生物的中央周边滤波器结构,在多个空间尺度上提取生产零件的颜色、方向、亮度特征,然后将上述特征组合成为特征图,从而得到对应于生产零件的颜色、方向、亮度特征的显著性描述,最后将上述特征的显著性描述经过经过归一化计算及线性组合形成生产零件的显著图。进一步地,所述步骤S2、特征组合的显著图生成具体包括:步骤S21、基于颜色、亮度和方向特征生成显著图,对输入图像在不同层次上进行非均匀采样,接着通过滤波器提取不同尺度的颜色、亮度和方向特征,然后再将各尺度层上的特征变换为同一尺度多个级别的特征图,接着计算其中央—周边差后再归一化得到颜色、亮度和方向特征的关注图,最终融合颜色、亮度和方向特征的关注图生成显著图;步骤S22、基于直方图对比对显著图进行显著值提取;步骤S23、基于区域对比的算法对显著图进行显著值提取。进一步地,所述步骤S21、基于颜色、亮度和方向特征生成显著图包括:S211、采用高斯金字塔模型,在不同层次上进行非均匀采样,对一幅输入图像I(x,y)用高斯金字塔G(x,y,σ)进行如下的非均匀采样:R(x,y,σ)=I(x,y)⊗G(x,y,σ),]]>G(x,y,σ)=12πσ2exp(-x2+y22σ2),]]>式中,σ是尺度因子,也即高斯金字塔G(x,y,σ)的带宽;S212、提取图像的颜色、亮度、方向特征,采用中央—周边差算子进行特征提取,分别用r、g和b来表示红色、绿色、蓝色通道,则图像的亮度特征表示为I(x)=[r(x)+g(x)+b(x)]/3对原输入图像提取四个颜色通道红色、绿色、蓝色、黄色上的分量:红色R=r-(g+b)/2,绿色G=g-(r+b)/2,蓝色B=b-(r+g)/2,黄色Y=(r+g)/2-∣r-g∣/2-b,方向特征采用四个方向的分量,其中θ={0°,45°,90°,135°},在图像的每个颜色通道上建立高斯金字塔模型,并通过中央—周边差算子得到图像在颜色特征上的特征映射图,计算方法如下:利用中心C和周边S的高斯差分DOG(x,y)计算图像I(x,y)的特征显著度DOG(x,y)=12πσC2exp(-x2+y22σC2)-12πσS2exp(-x2+y22σ2)]]>式中,σc是中心C的尺度因子,σs是周边S的尺度因子,通过对上级图像插值放大得到周边图像,用符号Θ表示中央C和周边S差的计算,中央周边差计算结果是对应特征的关注图:亮度特征图I(c,s)=∣I(c)ΘI(s)∣,颜色特征图RG(c,s)=∣(R(c)-G(c))Θ(G(s)-I(s))∣,BY(c,s)=∣(B(c)-Y(c))Θ(Y(s)-B(s))∣,方向特征图O(c,s,θ)=∣O(c,θ)ΘO(s,θ)∣;S213、对特征关注图分别进行归一化处理并生成最终显著图,对经过归一化的N(I(c,s))、N(RG(c,s))、N(BY(c,s))及N(O(c,s,θ))使用运算结合得到最终显著图,其中,是在不同尺度层上对每一个特征的特征映射图进行降采样,得到最高的主尺度层,再进行加法运算得到颜色、亮度、方向特征上的关注图其中,亮度归一化特征图颜色归一化特征图方向归一化特征图进一步地,所述步骤S22、基于直方图对比对显著图进行显著值提取具体为:对输入图像中的每个像数都定义一个显著值,该显著值通过这个像数的颜色和其它像数的颜色对比来表示,在一幅图像中一个像素的显著值定义为S(Ik)=Σ∀Ii∈ID(Ik,Ii)]]>上式进一步扩展成为如下形式S(Ik)=D(Ik,I1)+D(Ik,I2)+...+D(Ik,IN)式中,N是图像中的像素个数,得到每种颜色的显著值如下S(Ik)=S(ci)=Σj=1nfjD(c1,cj)]]>式中,ci是像素Ik的颜色值,n是不同颜色的像素数量,fj是图像I(x,y)中颜色值为cj的像素数目,通过颜色量化和选择出现频率颜色的方式建立一个简洁的直方图。进一步地,所述步骤S23、基于区域对比的算法对显著图进行显著值提取具体为:先利用图像分割算法将图像分割成各个区域,然后对每个区域构建颜色直方图,对于一个区域,通过计算它与图像中所有其他区域的颜色对比来计算其的显著值S(rk)=Σrk≠riw(ri)Dr(rk,ri)]]>式中,w(ri)是区域ri的权值来计算,Dr(rk,ri)是两个区域的空间距离。使用区域ri中的像素个数来作为w(ri),区域r1和r2之间的颜色距离定义为Dr(r1,r2)=Σi=1n1Σj=1n2f(c1,i)f(c2,j)D(c1,i,c2,j)]]>式中,f(ck,i)是区域ck所有nk个颜色中第i个颜色的频率,其中k={1,2}。进一步地,所述步骤S3、目标生产零件识别策略具体包括:步骤S31、采集零件图像并生成显著图,在工业生产流水线上采集一幅零件图像,从图像中提取出显著的零件区域时,使用基于直方图对比方法,对零件进行显著性检测,一幅图像的每个像素使用颜色统计来定义显著值:S(Ik)=Σ∀Ii∈ID(Ik,Ii)]]>式中,D(Ik,Ii)为L*a*b空间中Ik和Ii间的距离。对于像素Ii,其颜色为ci,就可以得到每种颜色的显著值,由上式变为S(Ik)=S(cl)=Σj=1nfi×D(cl,cj)]]>式中,n为图像中所包含的颜色总数,fi为图像I中颜色cj出现的概率;步骤S32、二值化处理及优化,为实现物体和噪声分离及后续的显著区域提取,采用OTSU算法确定阈值进行二值化,使用固定阈值T∈[0,255]进行二值化;步骤S33、抽取显著区域,对优化后的二值图像在每个区域内使用一个外接矩形抽取零件显著区域,通过建立凸外壳并且旋转外壳寻找给定2D点集的最小面积包围矩形,即为最小外接矩形,这些最小外接矩形将二值图像分为不同区域,每个区域对应不同的零件,记录每个外接矩形的位置和大小,在相应的原始采集图像的相同位置添加同样大小的矩阵;步骤S34、零件区域抽取,通过零件的几何形状特征识别出零件,即采用圆形和方形形状的圆形度、矩形度、面积和周长特征识别出不同的目标零件,上述特征的特征值分别定义如下:①面积B是零件所在区域二值图像对应的矩阵;②周长P,是围绕一个区域所有像素外边界的长度;③圆形度E=4πA/P2;④矩形度R=A/AR,其中AR为最小外接矩形的面积。步骤S35、零件识别,识别工业生产流水线上是否存在目标零件。进一步地,所述步骤S35、零件识别中为分割提取每一个零件的二值图像,定义一个四元组auxi=(Ai,Pi,Ei,Ri),其中Ai,Pi,Ei,Ri分别对应第i个零件的面积、周长、圆形度、矩形度,零件识别算法具体如下:S351、定义一个目标四元组target=(A0,P0,E0,R0),为目标零件的特征向量;S352、对每个零件的auxi=(Ai,Pi,Ei,Ri),计算其与目标零件的区分度proi=Σj=14auxi(j)-target(j)]]>式中,auxi(j)表示四元组中j个元素;S353、将所有的区分度proi进行升序排列,如果最小的区分度大于某一正实数ε,则认为工业生产流水线上没有目标零件,并给出提示信息。否则,将最小区分度所对应的区域作为目标零件区域。进一步地,所述步骤S32、二值化处理及优化中固定阈值T设定在80~100之间;所述步骤S33、抽取显著区域中使用稻米轮廓最小外接矩形计算粒型或者利用顶点链码与离散格林理论相结合的方式通过主轴法和旋转法提取目标图像的最小外接矩形。本发明相对于现有技术具有如下的优点及效果:本发明公开的一种基于视觉注意机制的目标零件识别方法,使工业机器人的视觉系统能够有效地识别工作空间内的目标零件,准确地定位目标零件,从而使工业机器人在完成生产零件装配作业时具有更高的自主性、鲁棒性、适应性,可以适用于工业生产流水线上各类零件的检测、上料、装配、包装等场合。附图说明图1(a)是基于视觉注意机制的目标零件识别流程步骤示意图;图1(b)是视觉注意机制模型原理图;图2(a)是视觉注意示例一;图2(b)是视觉注意示例二;图2(c)是视觉注意示例三;图3是注意的特征整合理论;图4是引导搜索模型架构;图5是Itti模型架构;图6是任务驱动注意模型架构;图7是Sun-Fisher注意计算模型架构;图8是目标零件识别流程图;图9是工作台零件图;图10是生成的显著图;图11是OTSU二值图;图12是固定阀值二值图;图13(a)是优化过程1;图13(b)是优化过程2;图13(c)是优化过程3;图14是优化后二值图;图15是二值图像显著区域;图16是采集图像的显著区域;图17是六个样本零件;图18是区分度分布图。具体实施方式为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。实施例本实施例公开了一种通用性、鲁棒性、并行性、适用性更好的基于视觉注意机制的目标零件识别方法,具体技术方案如图1(a)和图1(b)所示。所述方法包括以下三个步骤:S1、视觉注意机制模型选择。选择基于特征的注意机制模型和基于空间的注意机制模型,以便能够在此基础上利用生物的中央周边滤波器结构,在多个空间尺度上提取特征,这些特征包括颜色、方向、亮度。S2、特征组合的显著图生成。将所述的颜色、亮度和方向特征组合成为特征图,从而得到了对应于颜色、方向、亮度特征的显著性描述,并将这些特征的显著性描述经过归一化计算及线性组合后形成显著图。S3、目标生产零件识别策略。按照采集零件图像、生成显著图、二值化处理及优化、抽取显著区域、零件区域抽取等流程来进行零件识别。下面分别对这三个步骤进行阐述。步骤S1、视觉注意机制模型选择;本发明专利选择基于特征的视觉注意机制模型和基于空间的视觉注意机制模型。基于特征的视觉注意机制模型以关键字形式给出具体任务,首先用先验知识定义当前生产零件并存储起来,接着通过学习生产零件的一些基本特征,计算这些特征与已有特征的相识度,从而检测出最相关的生产零件,最后在目标场景中找到最显著的位置,并与已有的一些生产零件进行匹配。基于空间的视觉注意机制模型首先利用生物的中央周边滤波器结构,在多个空间尺度上提取生产零件的颜色、方向、亮度特征。然后将这些特征组合成为特征图,从而得到对应于生产零件的颜色、方向、亮度等特征的显著性描述。这些特征的显著性描述经过经过归一化计算及线性组合形成生产零件的显著图。S11、基于特征的注意机制模型选择;该模型是将生产零件的颜色、方向、亮度特征作为标本,与所需生产零件的颜色、方向、亮度特征的最小偏差作为显著度。这样就可以计算空间显著图和识别生产零件的分层。所述基于特征的注意机制模型描述所需特征的方式是采用自顶向下的方法。例如,提取一幅生产零件图像中颜色、方向、亮度特征,得到不同特征下的显著图。该模型以关键字形式给出具体任务,首先用先验知识定义当前生产零件并存储起来,接着通过学习生产零件的一些基本特征,计算这些特征与已有特征的相识度,从而检测出最相关的生产零件,最后在目标场景中找到最显著的位置,并与已有的一些生产零件进行匹配。S12、基于空间的注意机制模型选择;所谓空间是指注意对象所在的场景或一定的外界空间范围,它是一种常见描述注意力的方式。该模型认为注意力开始作用时是以外界空间中的某一特定范围来选择注意的,在此空间范围内的视觉刺激会被观察者注意到,而其它地方的视觉刺激会被自动忽略。著名学者Itti等在1998年依据特征整合理论提出了经典的Itti视觉注意模型,如图7所示。本发明专利以此为基础,首先利用生物的中央周边滤波器结构,在多个空间尺度上提取生产零件的特征,这些特征包括生产零件的颜色、方向、亮度等。然后将这些特征组合成为特征图,从而得到对应于生产零件的颜色、方向、亮度等特征的显著性描述。最后将这些特征的显著性描述经过经过归一化计算及线性组合形成生产零件的显著图。步骤S2、特征组合的显著图生成;特征组合的显著图生成,实际上是采用高斯金字塔模型进行非均匀采样,并提取生产零件图像的颜色、亮度、方向等特征,以及归一化处理来生成最终融合了颜色、亮度和方向特征这三个特征的关注图生成显著图。显著图是1985年由有关学者为了衡量一幅图像的显著性而提出来的显著特征图(简称显著图)的概念。显著图是一种表征图像视觉注意区域的二维分布图,在显著图中灰度值越大表明对应的区域显著性越强,更能引起人类视觉系统的注意,灰度的局部最大值对应点称为图像的显著特征点。如果把显著图比作是一张地图,那么显著性最大的地方相当于地图上地形最高点,局部特征点相当于局部的小山峰,地势相对越高的区域越容易引起人们的关注。一幅显著图至少能够提供图像哪里的显著性较大和显著性区域的范围有多广等两项信息。S21、显著图生成;首先,对输入图像在不同层次上进行非均匀采样,接着,通过滤波器提取不同尺度的颜色、亮度和方向特征。然后再将各尺度层上的特征变换为同一尺度多个级别的特征图。接着,计算其中央——周边差后再归一化得到三个特征的关注图。最终,融合这三个特征的关注图生成显著图。本发明专利采用经典的Itti模型生成显著图,其中非均匀采样和提取特征两个步骤如下:S211、采用高斯金字塔模型,在不同层次上进行非均匀采样。对一幅输入图像I(x,y)用高斯金字塔G(x,y,σ)进行如下的非均匀采样:R(x,y,σ)=I(x,y)⊗G(x,y,σ)]]>G(x,y,σ)=12πσ2exp(-x2+y22σ2)]]>式中,σ是尺度因子,也即高斯金字塔G(x,y,σ)的带宽。S212、提取图像的颜色、亮度、方向特征;因为图像的显著度是对各个特征尺度内的对比体现,所以可以采用中央—周边差算子进行特征提取。分别用r、g和b来表示红色、绿色、蓝色通道,则图像的亮度特征表示为I(x)=[r(x)+g(x)+b(x)]/3对原图像提取四个颜色通道红色、绿色、蓝色、黄色上的分量:红色R=r-(g+b)/2,绿色G=g-(r+b)/2,蓝色B=b-(r+g)/2,黄色Y=(r+g)/2-∣r-g∣/2-b。方向特征采用了四个方向的分量,其中θ={0°,45°,90°,135°}。在图像的每个颜色通道上建立高斯金字塔模型,并通过中央—周边差算子得到图像在颜色特征上的特征映射图。计算方法如下:利用中心C和周边S的高斯差分DOG(x,y)计算图像I(x,y)的特征显著度DOC(x,y)=12πσC2exp(-x2+y22σC2)-12πσS2exp(-x2+y22σ2)]]>式中,σc是中心C的尺度因子,σs是周边S的尺度因子。通过对上级图像插值放大得到周边图像,用符号Θ表示中央C和周边S差的计算。中央周边差计算结果是对应特征的关注图:亮度特征图I(c,s)=∣I(c)ΘI(s)∣,颜色特征图RG(c,s)=∣(R(c)-G(c))Θ(G(s)-I(s))∣,BY(c,s)=∣(B(c)-Y(c))Θ(Y(s)-B(s))∣;方向特征图O(c,s,θ)=∣O(c,θ)ΘO(s,θ)∣。从式(8)可看出,中央—周边差最能反映图像显著度的高低。在得到了关注图后,会出现某种特征存在多处反差极大值的情况,这时就会出现大量的显著峰。如果直接合并这些存在大量显著峰的特征关注图,就会抑制拥有显著峰较少的其他特征。所以在合并关注图生成显著图之前,需要对其进行归一化。S213、对特征关注图分别进行归一化处理并生成最终显著图。从视觉注意机制来说,人的注意力会受到太多强反差区域的相影响,显著度反而降低。由此,需要对显著峰少的特征图进行归一化,Itti模型使用归一化因子削弱存在大量显著峰的特征图。对经过归一化的N(I(c,s))、N(RG(c,s))、N(BY(c,s))及N(O(c,s,θ))使用运算结合得到最终显著图。其中,是在不同尺度层上对每一个特征的特征映射图进行降采样,得到最高的主尺度层,再进行加法运算得到颜色、亮度、方向特征上的关注图其中,亮度归一化特征图颜色归一化特征图方向归一化特征图S22、基于直方图对比(Histogram-basedContrast,HC)对显著图进行显著值提取。通过对生物视觉注意机制的观察,有关学者发现了生物体对视觉信号对比敏感,因而提出了HC算法。该算法是一种基于直方图对比的显著图提取算法,对输入图像中的每个像数都定义一个显著值,该显著值通过这个像数的颜色和其它像数的颜色对比来表示。在一幅图像中一个像素的显著值定义为S(Ik)=Σ∀Ii∈ID(Ik,Ii)]]>式中,D(Ik,It)是L*a*b空间中像数Ik和It的空间距离。上式也可以扩展成为如下形式S(Ik)=D(Ik,I1)+D(Ik,I2)+...+D(Ik,IN)式中,N是图像中的像素个数。然而很容易看出在这个定义下相同的颜色值是有相同显著性的。因此对相同的颜色算在一组,就可以得到每种颜色的显著值如下S(Ik)=S(ci)=Σj=1nfjD(c1,cj)]]>式中,ci是像素Ik的颜色值,n是不同颜色的像素数量,fj是图像I(x,y)中颜色值为cj的像素数目。为了有效地计算颜色对比,通过颜色量化和选择出现频率颜色的方式建立一个简洁的直方图。然而量化本身也会产生噪声,一些相同的颜色经过量化后可能会产生不同的值。为了降低由此而产生的噪声干扰,需要使用平滑技术来重新定义每种颜色的显著值。S23、基于区域对比的算法(Region-basedContrast,RC)在一幅图像中,人们往往会注意到图像中与其他区域产生强烈对比的区域,除对比之外,空间关系也会对人类视觉注意产生影响。与其他区域之间的对比越强烈,这个区域的显著性就越大。有学者提出了RC算法。RC算法将空间关系整合成区域级的计算,采用各个区域的稀疏直方图对比方法,先利用图像分割算法将图像分割成各个区域,然后对每个区域构建颜色直方图。对于一个区域,通过计算它与图像中所有其他区域的颜色对比来计算它的显著值S(rk)=Σrk≠riw(ri)Dr(rk,ri)]]>式中,w(ri)是区域ri的权值来计算,Dr(rk,ri)是两个区域的空间距离。为了突出于其他大区域的对比,这里使用区域ri中的像素个数来作为w(ri)。区域r1和r2之间的颜色距离定义为Dr(r1,r2)=Σi=1n1Σj=1n2f(c1,i)f(c2,j)D(c1,i,c2,j)]]>式中,f(ck,i)是区域ck所有nk个颜色中第i个颜色的频率,其中k={1,2}。这也就是使用颜色出现的频率作为权值来表现主要颜色之间的差别。在计算每个区域的直方图时,由于每个区域中只包含了整幅图像颜色直方图中的一小部分颜色,所以通过常规矩阵来计算和存储直方图的效率很低。因此,为了更好地存储和计算,通常采用稀疏矩阵来代替。步骤S3、目标生产零件识别策略本发明专利采用的目标生产零件识别策略如图8所示,也即对工业生产流水线上采集一幅零件图像,按照采集零件图像、生成显著图、二值化处理及优化、抽取显著区域、零件区域抽取、零件识别的流程步骤来进行。S31、采集零件图像并生成显著图。在工业生产流水线上采集一幅零件图像,如图9所示。从图像中提取出显著的零件区域时,使用基于直方图对比方法,对零件进行显著性检测。该方法基于生物视觉对视觉信号对比敏感的观察。对图像中的每个像素,其显著性通过其颜色与图像中其他像素的颜色对比来表示。一幅图像的每个像素使用颜色统计来定义显著值:S(Ik)=Σ∀Ii∈ID(Ik,Ii)]]>式中,D(Ik,Ii)为L*a*b空间中Ik和Ii间的距离。对于像素Ii,其颜色为ci,就可以得到每种颜色的显著值,由上式变为S(Ik)=S(cl)=Σj=1nfi×D(cl,cj)]]>式中,n为图像中所包含的颜色总数,fi为图像I中颜色cj出现的概率。因为在工业生产流水线上采集的图像不大,用现PC机能够实时地对此进行处理。生成的显著图如图9所示。S32、二值化处理及优化。为了实现物体和噪声分离及后续的显著区域提取,需要对图11进行二值化处理。通常采用OTSU算法确定阈值进行二值化。OTSU算法是一种自适应计算单阈值的简单高效方法,该方法以最佳门限将图像灰度直方图分成目标和背景两个部分,使两部分类间方差取最大值,即分离性最大。该方法在目标和背景形成明显灰度差的图像中效果显著,对于图10中零件与背景灰度值相差不大的情况,分离效果不明显,容易造成同一零件断层现象,如图11所示,使得抽取零件时所建立的最小外接矩形不能准确地包含同一个零件。在本发明专利申请中,结合实际情况使用固定阈值T∈[0,255]进行二值化。为了可靠地凸显显著区域,经过多次试验,将T设定在0到255之间变化,对比显著效果后将阈值设定为80~100之间比较好,实际采用80最为合适,如图12所示。同时,为了排除噪声对二值图像的影响,还需要进行优化。具体优化过程如图13所示:①若当前点的像素值为0,则搜索下一个像素点,如图13(a)所示;②若当前点的像素值为1,且该点的右上、正上、左上、左前的像素值都为0,则说明遇到新的目标零件。在图像矩阵中该位置上的编号值为上一个非零编号值加1,搜索下一个像素点,如图13(b)所示;③若当前点的像素值为1,且该点的右上、正上、左上、左前中至少有一个像素值为1,则在矩阵中该位置上放置任何一个像素值为1的对应编号,搜索下一个像素点,如图13(c)所示。这样在矩阵中存在不同编号的多个区域,分别对应图10中不同的物体和噪声,统计相同编号的个数,就可以获得该区域的面积,将面积过小的区域(该区域通常情况下对应噪声部分)设为背景去掉,效果如图14所示。S33、抽取显著区域。为了方便获取零件的3D位置,对优化后的二值图像在每个区域内使用一个外接矩形抽取零件显著区域。例如,可以使用稻米轮廓最小外接矩形计算粒型,或者利用顶点链码与离散格林理论相结合的方式通过主轴法和旋转法提取目标图像的最小外接矩形。通过建立凸外壳并且旋转外壳寻找给定2D点集的最小面积包围矩形,即为最小外接矩形。如图15所示。这些外接矩形将二值图像分为不同区域,每个区域对应不同的零件。记录每个外接矩形的位置和大小,在相应的原始采集图像的相同位置添加同样大小的矩阵,为了突出显著区域,可以将外接矩形边框设为不同颜色,如图16所示。S34、零件区域抽取。由于大部分零件是由圆形或方形等简单几何形状组合构成,故可以通过零件的几何形状特征识别出零件,即采用圆形和方形形状的圆形度、矩形度、面积和周长等特征识别出不同的目标零件。充分利用零件本身的形状和几何特征,就可以避免样本训练和特征匹配等通用模式识别算法带来的复杂性等缺点。本发明专利申请采用的特征值分别定义如下:①面积B是零件所在区域二值图像对应的矩阵;②周长P,是围绕一个区域所有像素外边界的长度;③圆形度E=4πA/P2;④矩形度R=A/AR,其中AR为最小外接矩形的面积。S35、零件识别。为了在图17中分割提取每一个零件的二值图像,定义一个四元组auxi=(Ai,Pi,Ei,Ri),其中Ai,Pi,Ei,Ri分别对应第i个零件的面积、周长、圆形度、矩形度。识别算法如下:S351、定义一个目标四元组target=(A0,P0,E0,R0),为目标零件特征向量。S352、对每个零件的auxi=(Ai,Pi,Ei,Ri),计算其与目标零件的区分度proi=Σj=14auxi(j)-target(j)]]>式中,auxi(j)表示四元组中j个元素。S353、将所有的区分度proi进行升序排列,如果最小的区分度大于某一正实数ε,则认为工业生产流水线上没有目标零件,并给出提示信息。否则,将最小区分度所对应的区域作为目标零件区域。这样就可以进行后续的引导工业机器人及其机械手进行零件装配。进行零件区分度实验,选取6个不同的零件为样本,如图17所示。为了观察同一零件旋转不同的角度特征变化情况及不同零件之间特征的差异性,分别计算零件1~6以及零件1在工业生产流水线上依次按顺时针旋转60度的二值图像面积、周长、圆形度和矩形度。为了量化差异性,按照式(11)定义的区分度计算公式计算不同零件以及同一零件旋转不同的角度与目标零件1的区分度。结果如表1所示。表1物体面积A周长P圆形度E矩形度R区分度零件1样本2645721920.06920.7800--旋转60度2698420770.07860.78670.0220旋转120度2419725540.04660.82130.0118旋转180度2614720520.07800.79700.0209旋转240度2684620800.07800.79820.0195旋转300度2490625010.05000.80680.0187零件2样本2260128480.03500.68600.3696零件3样本3473629590.04990.68250.3138零件4样本2816626620.04990.68140.7394零件5样本661428020.01060.69761.3682零件6样本496828020.00800.47721.6700从表1可以看出,零件1旋转不同的角度后各个特征值变化不大,计算出来区分度的值都小于0.1,对于零件2~6与零件1比较,计算出来的区分度值都大于0.3。如图18所示,因此可以将区分度的阈值定义为0.1。如果通过计算得到某零件的区分度值大于0.1,则认为该零件与目标零件(指零件1)不是同一零件,反之则认为该零件为目标零件。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1