一种基于多源语义分析的信息检索方法与流程
本发明属于信息检索技术领域,尤其涉及一种基于多源语义分析的信息检索方法。
背景技术:
信息检索研究是伴随着科学技术的发展和各种形式信息量的剧增而兴起的研究领域。随着网络的普及,医学研究工作者和医生们经常通过搜索引擎来获取所需的医学信息,但由于目前的搜索引擎采用的都是基于关键词的字面匹配法则计算文档特征值与检索词之间的相似度,并不能表达出词语的词义内涵,更不能发掘出文本中潜在的丰富的语义知识,因此,如何准确的把握用户的检索意图,如何精确的从海量数据中提取用户感兴趣的信息返回给用户,已经成为首要课题。针对这一难题,目前利用查询扩展技术对医学文献内容的发掘和利用成为了当前最流行的提升检索性能的手段之一。
查询扩展是文本检索中提高检索召回率的关键技术之一,它利用统计学和信息学等技术,以用户原查询为基础,将与原查询相关的信息添加到原查询中构建新的查询,然后以新的查询进行检索,以便更完整地描述原查询所隐含的语义或主题,弥补用户查询信息的不足,改善信息检索的查全率和查准率。其核心问题是如何设计和利用扩展词的来源。
WordNet是由心理学家、语言学家和计算机工程师联合设计的一种基于认知语言的英语词典。在WordNet中,名词、动词、形容词和副词被组织成同义词集(Synset),每个同义词集表示一个特定的概念。WordNet为每一个同义词集都提供了简短的、概要的注释定义,并保存着不同同义词集之间的语义关系。
UMLS Metathesaurus,即超级叙词表,是UMLS知识源的基于与核心,由来自各种受控词表的概念和术语以及它们之间的关系所构成,是生物医学词表概念、术语、涵义、关系的广泛集成。
目前的查询扩展方法大致可以分成四类,即基于语义资源的查询扩展、基于查询日志的查询扩展、基于全局分析的查询扩展以及基于局部分析的查询扩展。基于语义资源的查询扩展方法一般借助于领域本体,语义网、语义词典等 语义资源,选择出与查询用词存在一定语义关联性的词来进行扩展,选择的依据通常为词之间的上下位关系与同义关系等。其缺点在于语义资源的建立需要大量人力物力和只针对用户查询进行分析的局限性。基于查询日志的查询扩展方法通过对日志进行分析给出扩展的查询建议,需要大量的查询日志的积累。基于全局分析的查询扩展方法通过挖掘大数据集上词语之间的相关度,将与查询用词关联程度最高的词或词组加入初始查询以生成新的查询进行查询扩展。但其数据集庞大,随着检索对象集合规模递增在时空代价上也会存在不可行性,因此在实际的搜索引擎中鲜有采用。基于局部分析的查询扩展方法是首先对初始查询做第一次检索,从高排名的文档中提取重要性较高的词与初始查询组成新的查询进行第二次检索。但该方法基于初始查询,若第一次检索结果不佳,可能会提取出与查询主题不相关的词进行扩展,导致查询精度降低。
另一方面,被检索的文档中也需要经过一定的处理来更为准确的表达文档的内容,从而提高用户检索文档的精度。潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)是一种主题模型,能够较好的表达文档的内容,是对文档内容的一种高度压缩模型。该模型可以提取概括文档集中每篇文档的主题。LDA基于词袋(bag of words)模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。LDA的主要思想是将文档看作主题上的概率多项式分布,主题看作在词语上的概率多项式分布。因此,利用主题的思想将高维度的词项信息以低维的主题形式来表征文本信息,同时捕捉文档的语义信息,具有很好的降维效果,有效挖掘了文本的内在结构。
技术实现要素:
本发明的目的是在医疗专业领域中,提供一种基于多源语义分析的信检索放方法,结合通用领域本体WordNet和医学专业领域本体UMLS Metathesaurus对初始查询文本进行语义扩展来更有效理解用户的查询意图,并利用LDA模型对文档集建模,分词出词项在隐主题层面对文档的表征能力,提高了文档检索的性能。
为解决上述问题,本发明采用如下的技术方案:
一种基于多源语义分析的信息检索方法包括以下步骤:
步骤S1:对采集的文档集进行预处理,得到预处理后的文档集;
步骤S2:利用LDA模型对预处理后的文档集进行建模,得到LDA降维后的文档集;
步骤S3:对用户输入的初始查询文本进行预处理,得到预处理后的查询词集;
步骤S4:对预处理后的查询词集中每个查询词项进行多维度分析并对其加权进行查询扩展,得到查询扩展词集;
步骤S5:计算查询扩展词集与LDA降维的文档集之间的相似度并按相似度的大小递减排序,提取不低于预设阈值的文档返回给用户。
作为优选,所述步骤S2具体步骤如下:
步骤S2-1:对预处理后的每篇文档中的每个词进行矢量化处理形成参数化的词向量,并结合所有文档的词向量,形成“文档-词项”矩阵;
步骤S2-2:针对“文档-词项”矩阵,利用主题模型LDA中的Gibbs采样算法,通过设定狄利克雷参数并进行不断的迭代训练,首先抽样出每个单词所对应的主题分布,然后进一步计算并获得训练后的“文档-主题”矩阵和“主题-词项”矩阵的收敛结果,得到LDA降维后的文档集,即“文档-主题”矩阵和“主题-词项”矩阵。
作为优选,所述步骤S4具体步骤如下:
步骤S4-1:选取预处理后的查询集合中某个词wi,并将该词与专业医学英文词汇库L进行关键词匹配,判断该词是否为专业医学词汇;
步骤S4-2:将所述词wi分别映射到通用领域本体WordNet和医学专业领域本体UMLS Metathesaurus中获取候选词项,存为候选词项集合QWN和QUM;
步骤S4-3:将wi与QWN中的所有词汇进行概念信息量的语义相似度计算,按语义相似度进行递减排序并提取出语义相似度不低于预设阈值的词汇及其相对应的语义相似度存为集合QWN’;
步骤S4-4:将wi与QUM中的所有词汇进行语义相似度计算,按语义相似度进行递减排序并提取出语义相似度不低于预设阈值的词汇及其相对应的语义相似度存为集合QUM’;
步骤S4-5:根据S4-1所判定的wi是否为专业医学词汇为预处理后的查询集合Q及其分别在WordNet和UMLS Metathesaurus上的扩展词集QWN和QUM分配权重以达到对初始查询文本的扩展效果,最终生成多维加权语义扩展词集QEP;
步骤S4-6:重复步骤S4-1~S4-5,得到最终的扩展集合QEP’。
作为优选,所述步骤S5具体步骤如下:
步骤S5-1:针对步骤S2中训练后得到的“文档-主题”矩阵D’_T和“主题-词项”矩阵T_W进行矢量化,采用主题作为特征,在n维向量空间中构建出某个文档d中某个主题t的所有词项Wn向量,表示为
步骤S5-2:针对步骤S3中生成的初始查询文本的多维加权语义扩展词集QEP’进行矢量化,将QEP’中的所有词项映射到n维向量空间,构建出每个查询词项的向量,表示为
步骤S5-3:利用余弦相似度公式计算查询扩展向量与某篇文档d中某个主题向量之间的相似度
步骤S5-4:计算查询扩展向量与某篇文档d中某个主题向量之间的相似度和“文档-主题”矩阵D’_T中主题t对文档d的概率的乘积,得出查询扩展词项与文档的相似度,并按相似度的大小递减排序,提取不低于预设阈值的文档返回给用户,完成整个检索过程。
作为优选,所述步骤S1中的采集的文档集包含呼吸系统疾病信息。
作为优选,所述步骤1对采集的文档集进行预处理包括:从所述文档集中分离出每篇文档以及对分离出的每篇文档进行分词、去停用词、去高频词、词干提取操作,得到预处理后的文档集。
作为优选,所述步骤S3中对获取用户输入的初始查询文本进行预处理包括分词处理、去除停用词和特征词的规范化,再生成关键词集合Q。
本发明的技术方案为:首先对预处理后的文档进行LDA建模,从中获得词项在隐主题层面对文档的表征能力,再将词项和词项对文档的表征能力同时建立倒排索引,使其以低维的主题形式来表征文本信息;然后获取用户初试查询文本并进行预处理,再根据每个查询词项是否为专业医学词汇进行多维度分析并基于WordNet和UMLS Metathesaurus对其加权进行查询扩展,使其具有理解用户查询意图的能力;最后计算查询扩展词集与LDA降维后的文档之间的相似度并按相似度的大小递减排序,提取不低于预设阈值的文档返回给用户,以完成整个查询扩展及检索。本发明综合WordNet和UMLS Metathesaurus的特点,对初始查询进行多维度分析加权扩展,能够更为精准的理解用户的查询意图,并利用LDA模型对文档集进行建模,分析出词项在隐主题层面对文档的表征能力,提高了用户对文档检索的性能。
附图说明
图1为本发明的总体流程框架图;
图2为本发明的对文档集进行LDA建模的流程图;
图3为本发明的基于语义理解的信息检索新方法的流程图;
图4为本发明的文档检索的具体流程图。
具体实施方式
为了使本技术领域的人员更好的理解本发明方案,下面将结合本发明实例中的附图对本发明方案的实施方式进行详细描述。
如图1所示,本发明一种多源语义分析的信息检索方法的总体思路是:首先对预处理后的文档进行LDA建模,从中获得词项在隐主题层面对文档的表征能力,再将词项和词项对文档的表征能力同时建立倒排索引,使其以低维的主题形式来表征文本信息;然后获取用户初试查询文本并进行预处理,再根据每个查询词项是否为专业医学词汇进行多维度分析并基于WordNet和UMLS Metathesaurus对其加权进行查询扩展,使其具有理解用户查询意图的能力;最后计算查询扩展词集与LDA降维后的文档之间的相似度并按相似度的大小递减排序,提取不低于预设阈值的文档返回给用户,以完成整个查询扩展及检索。本发明的具体步骤如下:
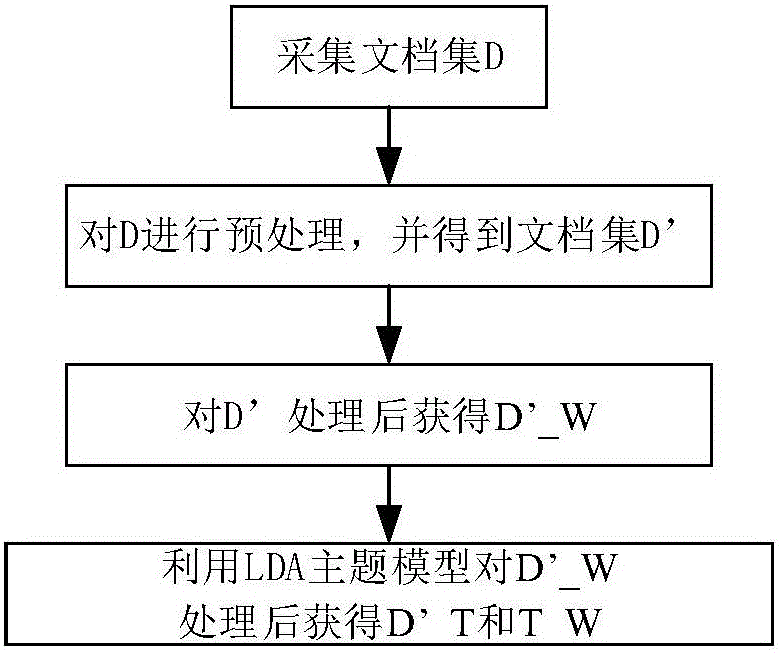
如图2所示,本发明的采集文档集并对其进行LDA建模的具体过程如下步骤S1~S2。
步骤S1:文档的采集及其预处理。为了易于提取文档,这里是从PubMed数据库中采集的是有关respiratory(呼吸系统疾病)信息的所有文档D。一篇文档的标题、关键词、摘要、方法、结果等相对而言能够综合反映出该文档的核心内容,所以获取的文档集D中每篇文档包括标题(ArticleTitle)、摘要(AbstractText)、目标(Objective)、背景(Background)、方法(Methods)、结论(Conclusion)和结果(Results)等,其为xml格式。对文档集D进行预处理,包括从D中分离出每篇文档以及对分离出的每篇文档进行分词、去停用词、去高频词、词干提取等操作,得到预处理后的文档集D’。
步骤S2:利用LDA模型对文档集建模。包括以下步骤:
步骤S2-1:对预处理后的每篇文档中的每个词进行矢量化处理形成参数化 的词向量,并结合所有文档的词向量,形成“文档-词项”矩阵D’_W,其特征权值为TF-IDF值。
步骤S2-2:针对“文档-词项”矩阵D’_W,利用主题模型LDA中的Gibbs采样算法,通过设定狄利克雷参数α和β并进行不断的迭代训练,先抽样出每个单词所对应的主题分布,然后进一步计算并获得训练后的“文档-主题”矩阵和“主题-词项”矩阵的收敛结果。采样过程中,一个特定单词w的主题赋值是从下列多项式分布抽样得出的:
其中,zi表示第i个单词对应的主题变量;zi’表示不包括其中的第i项;w被称为词汇记号;表示对变量zi进行抽样的后验概率;是除去当前赋值,单词w赋给主题k的次数;是除去当前赋值,所有单词赋给主题k的数量;是除去当前赋值,文档m中的单词赋给主题k的次数;是除去当前单词w,文档m中的所有单词的数量。
完成Gibbs采样后,将会获得“文档-主题”矩阵D’_T和“主题-词项”矩阵T_W,其中特征降维的关键矩阵就是“文档-主题”矩阵D’_T。计算公式如下:
其中,表示词汇w被分配给主题k的频数;表示分配给主题k的所有词数;φm,w表示第m篇文档中第k个潜在语义对应的多项式分布概率; 表示文本w中分配给主题k的词数;表示所有被分配了主题的词数; 表示第k个潜在语义下词项w对应的多项分布概率。
如图3所示,本发明的信息检索新方法的具体过程如下步骤S3~S4所示。
步骤S3:对用户输入的初始查询文本进行预处理。获取用户输入的初始查询文本并进行预处理,预处理包括分词处理、去除停用词和特征词的规范化等,再生成关键词集合Q。
步骤S4:对预处理后的查询词集中每个查询词项进行多维度分析并对其加权进行查询扩展。包括以下步骤:
步骤S4-1:选取预处理后的查询集合Q中某个词wi,并将该词与专业医学英文词汇库L进行关键词匹配,判断该词是否为专业医学词汇。
这里的专业医学英文词汇库L是从网上获取并结合ICD(International Classification of Diseases,国际疾病分类)整理的英语专业词汇,涉及到临床医学、医药卫生、医务等内容的各科专业英语词汇等,涵盖范围较大,词汇收集较全,因而可以作为判断关键词是否为专业医学词汇的依据。
步骤S4-2:将步骤S4-1中选取的词wi分别映射到通用领域本体WordNet和医学专业领域本体UMLS Metathesaurus中获取候选词项。其中,利用WordNet提供的接口函数,从WordNet的同义词词集(Synset)、属类词(Class Word)和意义解释(Sense explanation)这三个集合中抽取出候选同义词,再进行特征提取,存为候选词汇集合QWN;利用UMLS提供的web访问接口,提取出与wi的上下位关系词、相关关系词和同义关系词等,再进行特征提取,存为候选词项集合QUM。
步骤S4-3:利用Nuno提出的方法将wi与QWN中的所有词汇进行概念信息量的语义相似度计算,按语义相似度进行递减排序并提取出语义相似度不低于预设阈值的词汇及其相对应的语义相似度存为集合QWN’。
Nuno提出的方法是基于WordNet本身的结构,子节点越多的概念包含的信息量越少,而叶子节点的信息量越大,Nuno方法的数学模型为:
其中,Nuno方法计算的IC值值域范围是[0,1],ICwn(c)表示语义相似度,c表示关键词映射到WordNet中的概念,hypo(c)返回值是概念c的所有子概念节点数,maxwn是一个常量,表示在语义分类树中所有概念节点数。
通过Nuno方法的语义相似度计算,提取出集合QWN’中词汇与Wi语义相似度不低于预设阈值的词汇并按照语义相似度进行递减排序,然后将提取出的词汇及其相对应的语义相似度存为集合QWN'={WWN1SWN1,WWN2SWN2,...,WWNkSWNk},其中SWN1,SWN2,...,SWNk表示语义相似度的值。
步骤S4-4:利用Li提出的方法将wi与QUM中的所有词汇进行语义相似度计算,按语义相似度进行递减排序并提取出语义相似度不低于预设阈值的词汇及其相对应的语义相似度存为集合QUM’。
其中,Li提出的方法是结合最短路径和本体的深度相关信息提出的,其非线性的函数表示为:
其中,Li方法计算的SLi值值域范围是[0,1],C1、C2表示需要计算相似度的两个词汇,L表示两个概念之间的最短距离,H表示两个概念之间的深度,这里的δ和κ是恒定最短距离和深度信息在表示中所代表的权重的参数。
通过Li方法的语义相似度计算,提取出集合QUM’中词汇与Wi语义相似度不低于预设阈值的词汇并按照语义相似度进行递减排序,然后将提取出的词汇及其相对应的语义相似度存为集合QUM'={WUM1SUM1,WUM2SUM2,...,WUMkSUMk},其中SUM1,SUM2,...,SUMk表示语义相似度的值。
步骤S4-5:根据步骤S4-1所判定的wi是否为专业医学词汇为预处理后的查询集合及其分别在WordNet和UMLS Metathesaurus上的扩展词集分配权重以达到对初始查询文本的扩展效果,即为QEP=μQ+ψQWN'+γQUM'(μ+ψ+γ=1)中的μ、ψ、γ分配权重。由于用户输入的初始查询文本是最为直观准确的表达出用户的查询意图,所以应加大原查询词的权重,即μ应设为最大;ψ、γ根据步骤S4-1中所判定的是否为专业医学词汇来分配值的大小,即为如下两种情况:
a.wi是专业医学词汇时,应为γ分配较大值,其μ、ψ、γ三者之间值的大小关系为:1≥μ>γ>ψ≥0且μ+ψ+γ=1;
b.wi是非专业医学词汇时,应为βψ分配较大值,其μ、ψ、γ三者之间值的大小关系为:1≥μ>ψ>γ≥0且(μ+ψ+γ=1);
步骤S4-6:重复步骤S4-1~S4-5,得到最终的扩展集合QEP’。
由此,可以生成用户输入的初始查询文本的多维加权语义扩展词集QEP’。
如图4所示,本发明的文档检索的具体过程如下步骤S5.
步骤S5:计算查询扩展词集与文档之间的相似度并按相似度的大小递减排序,提取不低于预设阈值的文档返回给用户。包括以下步骤:
步骤S5-1:针对步骤S2中训练后得到的“文档-主题”矩阵D’_T和“主题-词项”矩阵T_W进行矢量化,采用主题作为特征,在n维向量空间中构建出某个文档d中某个主题t的所有词项Wn向量,表示为其中 表示为词项在某个主题t空间中对应文档d(d∈D’)中的权重。
步骤S5-2:针对步骤S4中生成的初始查询文本的多维加权语义扩展词集QEP’进行矢量化,将QEP’中的所有词项映射到n维向量空间,构建出每个查询词项的向量,表示为其中表示每个查询词项在其扩展查询词集QEP’中的权重。
步骤S5-3:利用余弦相似度公式计算查询扩展向量与某篇文档d中某个主题向量之间的相似度。在向量空间中度量任意两个向量间的相似度使用的是余弦相似度,即计算向量夹角的大小。余弦相似度的计算可以视作两个归一化后的向量内积,公式为:
步骤S5-4:计算查询扩展向量与某篇文档d中某个主题向量之间的相似度和“文档-主题”矩阵D’_T中主题t对文档d的概率(即步骤S2-2中φm,w的的概率分布中的元素)的乘积,即 得出查询扩展词项与文档的相似度,并按相似度的大小递减排序,提取不低于预设阈值θ的文档返回给用户,完成整个检索过程。
以上实施例仅为发明的示例性实施例,不用于限制发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!