一种MOOC课程中学生面部表情的动态识别方法与流程
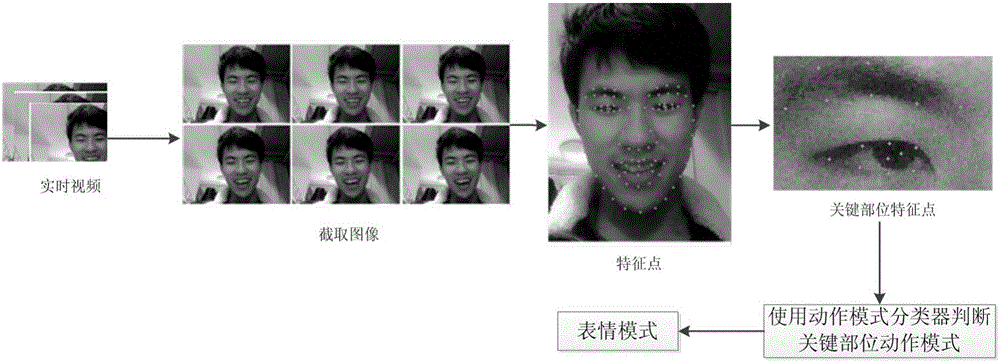
本发明属于图像处理领域,具体涉及一种MOOC课程中学生面部表情的动态识别方法。
背景技术:
:大规模在线开放课程(MassiveOpenOnlineCourse,MOOC)是近些年快速兴起一种课程形式,在全球范围内获得了政府、高校和企业的高度重视,成为推动“高等教育变革”的重要力量。MOOC课程利用视频传播的快速性和便捷性,实现授课过程的大规模传播,并针对视频单向传播带来的教学反馈不足的问题,引入交互式练习。但是交互式练习所提供的教学反馈能力与传统线下面授课过程相比仍显不足。线下课程中,授课者可以通过学生的面部表情和通过对学生提问获得反馈,从而做出及时的教学调整,MOOC课程还无法做到这一点。表情识别技术被视为未来情感人机交互的重要技术,吸引了国内外众多高校和科研机构的参与和研究。目前,针对JAFFE等标准表情数据库的多种表情识别方法已取得较高的识别率,将表情识别技术应用于MOOC课程,可以实时的获得学生课堂状态,并针对学生反映作出课堂调整,但是,已有的表情识别方法应用于MOOC课程时仍具有以下缺点:1、将人脸上存在的人为表情作为前提,而忽略了表情组成的多样性,实用性不大;2、表情不够细致。人脸表情并非只局限于6种基本表情;3、表情不具备针对性。人脸表情在特定的场景下往往会有趋势,即某些表情出现的概率较大,某一些较小。技术实现要素:针对上述现有技术存在的不足,本发明提供一种MOOC课程中学生面部表情的动态识别方法。本发明的技术方案如下:一种MOOC课程中学生面部表情的动态识别方法,包括如下步骤:步骤1:对MOOC课程上学生学习过程中的面部表情进行拍摄,得到学生面部表情视频;步骤2:获取MOOC课程中学生面部表情历史视频;步骤3:对MOOC课程学生面部表情历史视频进行分帧处理,使其转换为具有学生面部特征的n帧历史静态图像;步骤4:使用face++人脸识别系统依次提取每帧历史静态图像中学生面部特征的特征点,并将所提取的学生面部特征的特征点分别以像素坐标向量的形式保存;步骤5:对每帧历史静态图像中学生面部特征的特征点进行预处理,具体方法为:将特征点的像素坐标转换为齐次坐标,对齐次坐标依次进行旋转、平移和缩放变换处理后,再转换回像素坐标;步骤6:从预处理后的每帧图像的学生面部特征的特征点中,抽取面部关键部位:眼睛、嘴巴、眉毛的特征点;步骤7:分别根据每帧图像中眼睛、嘴巴和眉毛的特征点,建立每帧图像的眼睛特征向量、嘴巴特征向量和眉毛特征向量;步骤8:定义眼睛动作模式分别为瞪眼、正常和闭眼,嘴巴动作模式分别为正常、偏向于思考与悲伤的抿嘴、偏向于愤怒的抿嘴和咧嘴,眉毛动作模式分别为皱眉、正常和挑眉;步骤9:根据动作模式的定义,分别对每帧图像中眼睛特征向量所属的动作模式、嘴巴特征向量所属的动作模式和眉毛特征向量所属的动作模式进行标定;步骤10:将每帧图像的眼睛特征向量、嘴巴特征向量和眉毛特征向量分别保存到各自所标的动作模式的特征向量集合中;步骤11:使用支持向量机(SupportVectorMachine,SVM)对各动作模式的特征向量集合进行训练,得到各动作模式分类器;步骤12:获取MOOC课程中学生面部表情实时视频;步骤13:对学生面部表情实时视频进行分帧处理,使其转换为m帧具有学生面部特征的实时静态图像;步骤14:使用face++api依次提取每帧实时静态图像中学生面部特征的特征点,并将所提取的学生面部特征的特征点分别以像素坐标向量的形式保存;步骤15:对每帧实时图像中学生面部特征的特征点进行预处理,具体方法为:将特征点的像素坐标转换为齐次坐标,对齐次坐标依次进行旋转、平移和缩放变换处理后,再转换回像素坐标;步骤16:从每帧预处理后的实时图像中抽取眼睛、嘴巴、眉毛的特征点,并分别建立眼睛特征向量、嘴巴特征向量和眉毛特征向量;步骤17:使用动作模式分类器分别对每帧实时图像的嘴巴、眼睛和眉毛特征向量进行分类,得到每帧实时图像中嘴巴、眼睛和眉毛对应的动作模式;步骤18:根据每帧实时图像中嘴巴、眼睛和眉毛的动作模式的组合,确定在每帧实时图像中学生的表情所属的表情模式;所述步骤7和步骤16中所述的眼睛特征向量、嘴巴特征向量和眉毛特征向量的建立方法为:分别计算眼睛特征点中两两点之间的欧氏距离,即眼睛特征点欧氏距离值,嘴巴特征点中两两点之间的欧氏距离,即嘴巴特征点欧氏距离值,眉毛特征点中两两点之间的欧氏距离,即眉毛特征点欧氏距离值,分别使用眼睛特征点欧氏距离值、嘴巴特征点欧氏距离值和眉毛特征点欧氏距离值构成眼睛特征向量、嘴巴特征向量和眉毛特征向量。所述步骤18中所述表情模式采用表1中映射关系确定:表1动作模式与表情模式的映射关系表有益效果:本发明的一种MOOC课程中学生面部表情的动态识别方法,具有以下优点:1、六种基本表情模式为快乐、伤心、恐惧、愤怒、惊讶和厌恶,但在MOOC课堂中出现恐惧与厌恶的表情概率较小,即使出现,大多与课程的内容无关,因此,将恐惧和厌恶从表情模式中去掉,将出现频率较高的思考、无聊和正常添加到表情识别的结果中,使表情识别结果对MOOC课堂更加有效;2、通过对动作模式的组合得到表情模式,使表情模式的识别更准确;3、使用欧式距离构建的动作模式特征向量,特征向量具有维度低、数量少的特点,使表情识别速度更快。附图说明图1一种MOOC课程中学生面部表情的动态识别方法流程图;图2MOOC课程中表情识别过程示意图;图3(a)眼睛动作模式中瞪眼示意图;图3(b)眼睛动作模式中正常示意图;图3(c)眼睛动作模式中闭眼示意图;图4(a)嘴巴动作模式中正常示意图;图4(b)嘴巴动作模式中偏向于思考与悲伤的抿嘴示意图;图4(c)嘴巴动作模式中偏向于愤怒的抿嘴示意图;图4(d)嘴巴动作模式中咧嘴示意图;图5(a)眉毛动作模式中皱眉示意图;图5(b)眉毛动作模式中正常示意图;图5(c)眉毛动作模式中挑眉示意图;图6截取图像中部分图像示意图;图7面部特征点示意图;图8面部特征点坐标示意图;图9旋转基准示意图;图10平移及缩放基准示意图;图11眼睛特征点示意图;图12嘴部特征点示意图;图13眉毛特征点示意图;图14分类树模型示意图,其中E代表眼睛,E1、E2和E3分别代表正常、闭眼和瞪眼;M代表嘴巴,M1、M2、M3和M4分别代表正常、偏于思考与悲伤的抿嘴、偏于愤怒的抿嘴和咧嘴;B代表眉毛,B1、B2和B3分别代表正常、皱眉和挑眉。具体实施方式下面结合附图对本发明的一种实施方式作详细说明。如图1和图2所示,本实施方式的一种MOOC课程中学生面部表情的动态识别方法的表情动态识别过程包括如下步骤:本实施方式的MOOC课程中学生面部表情的动态识别方法,具体包括如下步骤:步骤1:对MOOC课程上学生学习过程中的面部表情进行拍摄,得到学生面部表情视频;步骤2:获取MOOC课程中学生面部表情历史视频;步骤3:对MOOC课程学生面部表情历史视频进行分帧处理,使其转换为具有学生面部特征的n帧历史静态图像,并从第一帧静态图像开始,每5帧静态图像截取一帧图像,直到历史视频截取完毕,这样的截取不会造成表情缺失,同时有效避免了数据冗余。本实施方式中下述的历史图像为历史视频中截取到的历史静态图像。步骤4:使用face++人脸识别系统依次提取每帧历史图像中学生面部特征的83个特征点,并将所提取的学生面部特征的特征点分别以像素坐标向量的形式保存;步骤5:由于历史图像中的人脸有大有小,且坐标比例大小不一,无法用特征点间欧氏距离值描述动作模式,因此,对学生面部特征的特征点进行预处理,使学生面部特征的特征点在图像中保持水平且可以用统一坐标描述,具体方法如下:步骤5.1:将2维的像素坐标转化为3维的齐次坐标,转化公式为:其中,C'i'k'为第i'个历史图像中第k'个特征点的像素坐标;M'i'k'为第i'个历史图像中第k'个特征点的齐次坐标;k'∈[1,83];步骤5.2:以左眼角和右眼角为水平基准,将齐次坐标进行旋转θ'角。令第i'个历史静态图像中左眼右角点为第一个特征点,即k'=1,其齐次坐标为M'i'1(x'i'1,y'i'1,1),右眼左角点为第二个特征点,即k'=2,其齐次坐标为M'i'2(x'i'2,y'i'2,1),定义旋转矩阵N'1为:N′1=cosθ′-sinθ′0sinθ′cosθ′0001=p′2-q′20q′2p′20001---(2)]]>其中,对旋转后的坐标进行平移,定义平移矩阵N'2为:N′2=100010p′1q′11---(3)]]>其中,p'1=(x'i'2-x'i'1)+x'i'2,q'1=(y'i'2-y'i'1)+y'i'2;对平移后的坐标进行缩放,令L'为鼻梁左右距离,定义缩放矩阵N'3为:N′3=10001000L′---(4)]]>步骤5.3:将齐次坐标M'i'k'进行变换,得到转换后的齐次坐标变换公式为:Mi′k′′*=M′i′k′×N′1×N′2×N′3---(5)]]>步骤5.4:将变换后的齐次坐标通过式(1)的逆过程,转换为变换后的特征点的像素坐标步骤6:由于人面部能体现表情变化的部位只有嘴巴、眼睛和眉毛,鼻子不随着表情的变化而变化,因此本发明将嘴巴、眼睛和眉毛作为面部关键部位,从预处理后的每帧历史图像的学生面部特征的特征点中,抽取面部关键部位:眼睛、嘴巴、眉毛的特征点;步骤7:分别根据每帧历史图像中眼睛、嘴巴和眉毛的特征点,建立每帧历史图像的眼睛特征向量、嘴巴特征向量和眉毛特征向量,方法为:分别计算眼睛特征点中两两点之间的欧氏距离,即眼睛特征点欧氏距离值,嘴巴特征点中两两点之间的欧氏距离,即嘴巴特征点欧氏距离值,眉毛特征点中两两点之间的欧氏距离,即眉毛特征点欧氏距离值,分别使用眼睛特征点欧氏距离值、嘴巴特征点欧氏距离值和眉毛特征点欧氏距离值构成眼睛特征向量、嘴巴特征向量和眉毛特征向量;步骤8:预先定义眼睛的动作模式、嘴巴的动作模式和眉毛的动作模式;如图3所示,眼睛动作模式分别为图3(a)所示瞪眼、图3(b)所示正常和图3(c)所示闭眼;如图4所示,嘴巴动作模式分别为图4(a)所示正常、图4(b)所示偏向于思考与悲伤的抿嘴、图4(c)所示偏向于愤怒的抿嘴和图4(d)所示咧嘴;如图5所示,眉毛动作模式分别为图5(a)所示皱眉、图5(b)所示正常和图5(c)所示挑眉。步骤9:根据动作模式的定义,分别对每帧历史图像中眼睛特征向量所属的动作模式、嘴巴特征向量所属的动作模式和眉毛特征向量所属的动作模式进行标定;步骤10:将每帧历史图像的眼睛特征向量、嘴巴特征向量和眉毛特征向量分别保存到各自所标的动作模式的特征向量集合中;步骤11:通过matlab的LIBSVM工具箱进行编程,使用支持向量机(SupportVectorMachine,SVM)对各动作模式的特征向量集合进行训练,得到动作模式分类器;步骤12:获取MOOC课程中学生面部表情实时视频;步骤13:对学生面部表情实时视频进行分帧处理,使其转换为m帧具有学生面部特征的实时静态图像,并从第一帧实时静态图像开始,每5帧实时静态图像截取一帧图像,直到历史视频截取完毕,这样的截取不会造成表情缺失,同时有效避免了数据冗余。部分图像如图6所示,本实施方式中下述的实时图像为实时视频中截取到的实时静态图像。步骤14:如图7所示,使用face++人脸识别系统依次提取每帧实时图像中学生面部特征的83个特征点,并将所提取的学生面部特征的特征点分别以如图8所示像素坐标向量的形式保存;步骤15:由于实时图像中的人脸有大有小,且坐标比例大小不一,无法用特征点间欧氏距离值描述动作模式,因此,对学生面部特征的特征点进行预处理,使学生面部特征的特征点在图像中保持水平且可以用统一坐标描述,具体方法如下:步骤15.1:将2维的像素坐标转化为3维的齐次坐标,转化公式为:其中,Cik为第i个实时图像中第k个特征点的像素坐标;Mik为第i个实时图像中第k个特征点的齐次坐标;k∈[1,83];步骤15.2:如图9所示,以左眼角和右眼角为水平基准,将得到的齐次坐标进行旋转θ角。令第i个实时图像中左眼右角点为第一个特征点,即k=1,其齐次坐标为Mi1(xi1,yi1,1),右眼左角点为第二个特征点,即k=2,其齐次坐标为Mi2(xi2,yi2,1),定义旋转矩阵N1为:N1=cosθ-sinθ0sinθcosθ0001=p2-q20q2p20001---(7)]]>其中,对旋转后的坐标进行平移,平移后坐标原点及坐标轴如图10所示,定义平移矩阵N2为:N2=100010p1q11---(8)]]>其中,p1=(xi2-xi1)+xi2,q1=(yi2-yi1)+yi2;对平移后的坐标进行缩放,如图10所示,令L为鼻梁左右距离,定义缩放矩阵N3为:N3=10001000L---(9)]]>步骤15.3:将齐次坐标Mik进行变换,得到转换后的齐次坐标变换公式为:Mik*=Mik×N1×N2×N3---(10)]]>步骤15.4:将变换后的齐次坐标Mik通过式(6)的逆过程,转换为变换后的特征点的像素坐标步骤16:从预处理后的每帧实时图像的学生面部特征的特征点中,抽取面部关键部位:眼睛、嘴巴、眉毛的特征点;步骤17:分别根据每帧实时图像中眼睛、嘴巴和眉毛的特征点,建立每帧实时图像的眼睛特征向量、嘴巴特征向量和眉毛特征向量;本实施方式中特征向量生成方法为:(1)如图11所示,将图片中的特征点去除瞳孔定位的两个点,得到眼睛部位的8个特征点,计算特征点中两两点之间的欧氏距离,即眼睛特征点欧氏距离值,共28个值构成眼睛特征向量;(2)如图12所示,将图片中的特征点去除鼻子左右两个点,以及嘴唇内部左右共4个点,得到嘴巴部位的15个特征点,其中14个特征点来自于嘴巴,还有一个特征点来自于鼻尖下部,取两两特征点之间的距离,即嘴巴特征点欧氏距离值,共105个值构成特征向量;(3)如图13所示,将图片中的特征点去除眼部所有点,得到眉毛部位的9个特征点,除了眉毛轮廓的8个点,还选取了眼角处的一个点作为参照点,取两两特征点之间的距离,即眉毛特征点欧氏距离值,共有36个值构成特征向量。步骤17:使用动作模式分类器分别对每帧实时图像的嘴巴、眼睛和眉毛特征向量进行分类,得到每帧实时图像中嘴巴、眼睛和眉毛对应的动作模式。本实施方式中,对动作模式识别准确率进行测试,测试结果如表2所示:表2动作模式识别准确率表步骤18:根据每帧实时图像中嘴巴、眼睛和眉毛的动作模式的组合,采用表3中映射关系,确定在每帧实时图像中学生的表情所属的表情模式,表3如下;表3动作模式与表情模式的映射关系表表3中表情模式的定义依据如下分类树模型的思想:如图14所示,其中E代表眼睛,E1、E2和E3分别代表正常、闭眼和瞪眼,M代表嘴巴,M1、M2、M3和M4分别代表正常、偏于思考与悲伤的抿嘴、偏于愤怒的抿嘴和咧嘴,B代表眉毛,B1、B2和B3分别代表正常、皱眉和挑眉。将动作模式识别率最高的眼睛最为树的第一层节点,嘴巴作为第二层节点,眉毛作为树叶,共36个树叶对应着36种动作模式的组合,将36种动作模式定义为7中表情模式时,定义过程中以眼睛动作模式为主,即让眼睛的动作模式识别结果对表情模式识别结果产生最主要影响,其次为嘴巴动作模式,最后为眉毛动作模式,这样的定义可以提高表情识别的准确率。本实施方式中,表情模式识别准确率如表4所示:表4表情模式识别准确率表当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1