一种用户流失预测方法及系统与流程
背景技术:
随着直播行业的飞速发展,各个直播平台之间的竞争日益激烈,导致用户流失形势严峻,对直播平台造成直接经济损失,不利于平台的长期发展。因此,需要通过机器学习算法分析用户的行为,建立潜在流失用户识别模型,精准定位潜在流失的用户,制定维系策略以挽回潜在流失用户。目前用户行为趋于多样化和复杂化,而且变化迅速,导致用户的行为信息指标数量较多,如果直接采用用户的行为参数作为模型的输入变量,将导致建模过程和模型本身较为复杂,而且模型对流失用户预测的准确性不高。
技术实现要素:
针对现有技术中存在的缺陷,本发明的主要目的在于提供一种用户流失预测方法,本发明的另一目的在于提供一种用户流失预测系统,基于选取的用户的基础信息指标和行为信息指标建立的潜在流失用户识别模型,模型固化简便,建模效率高,而且能够准确地识别潜在流失用户。
本发明提供一种用户流失预测方法,包括以下步骤:
S1.从服务器采集用户的基础信息指标和行为信息指标;
S2.从在统计期内采集的用户中选取部分用户作为采样用户,并选取所述采样用户的目标指标和M种指标,所述M种指标包括所述采样用户的基础信息指标和行为信息指标,将目标指标小于设定的阈值的用户划分为流失用户,将目标指标大于所述阈值的用户划分为非流失用户;
S3.根据所述采样用户的目标指标和M种指标,通过决策树算法构建潜在流失用户识别模型;
S4.将在所述统计期之后采集的所述M种指标的取值作为所述潜在流失用户识别模型的输入变量,获得所述M种指标对应的用户的流失概率,如果所述流失概率大于设定的阈值,则判断所述用户为潜在流失用户。
在上述技术方案的基础上,所述目标指标为用户在设定时间段内的观看时长。
在上述技术方案的基础上,所述采样用户中流失用户和非流失用户的比例为,流失用户:非流失用户=1:N,N>1;。
在上述技术方案的基础上,步骤2中,所述M种指标的具体选取方法包括:
S2.1对采集到的所述基础信息指标和行为信息指标中除目标指标之外的其它指标进行转换处理,并剔除所述其它指标在预设范围内的极大值和极小值;
S2.2对于S2.1选取的指标进行多维分析,剔除与所述目标指标无关的指标,保留的指标包括离散型指标和连续型指标;
S2.3对于所述离散型指标使用卡方检验,计算所述离散型指标与所述目标指标之间的卡方值,剔除卡方值小于预设的卡方值阈值的指标;
S2.4对于所述连续型指标使用方差分析,计算所述连续型指标与所述目标指标之间的方差,剔除方差小于预设的方差阈值的连续型指标;对于方差大于预设的方差阈值的连续型指标,计算其与所述目标指标之间的相关系数,并剔除与所述目标指标相关系数小于预设阈值的指标,最终得到M种指标。
在上述技术方案的基础上,步骤S3具体包括:
S3.1将所述采样用户划分成训练集和测试集,所述训练集和测试集均包括流失用户和非流失用户,并且所述训练集和测试集中流失用户和非流失用户的比例分别与所述采样用户中流失用户和非流失用户的比例相同;
S3.2基于所述训练集,通过决策树算法构建潜在流失用户识别模型,并得到具有最优参数组合的所述潜在流失用户识别模型,最优参数组合包括所述M种指标和每个子分支的最小记录数;
S3.3使用测试集评估具有最优参数组合的潜在流失用户识别模型,并得到最优的潜在流失用户识别模型。
在上述技术方案的基础上,得到最优的所述潜在流失用户识别模型的方法包括:
计算潜在流失用户识别模型的多个考核指标,所述考核指标包括准确率、查全率、提升度和F-Measure,选取所述考核指标均为最大的潜在流失用户识别模型为最优的潜在流失用户识别模型。
在上述技术方案的基础上,步骤S3还包括从所述最优的潜在流失用户识别模型中提取多条识别规则,并计算所述识别规则的预测概率,所述预测概率根据通过该规则预测出的所述训练集中流失用户数量n,以及所述预测出的所述训练集中流失用户数量n中真正流失的用户数n1计算得到:预测概率=n1:n,n≥0,n1≥0。
在上述技术方案的基础上,步骤S4具体包括:将在所述统计期之后采集的所述M种指标的取值作为所述识别规则的输入变量,将所述识别规则的预测概率作为所述M种指标对应的用户的流失概率,如果所述流失概率大于设定的阈值,则判断所述用户为潜在流失用户。
在上述技术方案的基础上,所述M种指标包括:观看天数、观看时长、观看房间数、观看天数波动率、观看时长波动率、观看房间数波动率、最近一次观看距离天数、最近一次发送弹幕距离天数、弹幕天数、虚拟礼物赠送天数和注册时长;
所述M种指标包括在不同时间段内的取值。
本发明还提供一种用户流失预测系统,包括:
数据采集模块,用于从服务器采集用户的基础信息指标和行为信息指标;
样本提取模块,用于从在统计期内采集的用户中选取部分用户作为采样用户,并选取所述采样用户的目标指标和M种指标,所述M种指标包括所述采样用户的基础信息指标和行为信息指标,所述采样用户根据所述目标指标划分为流失用户和非流失用户,所述流失用户的目标指标小于设定的阈值,所述非流失用户的目标指标大于所述阈值;
模型构建模块,用于根据所述采样用户的目标指标和M种指标,通过决策树算法构建潜在流失用户识别模型;
用户识别模块,用于将数据采集模块在所述统计期之后采集的所述M种指标的取值作为所述潜在流失用户识别模型的输入变量,获得所述M种指标对应的用户的流失概率,如果所述流失概率大于设定的阈值,则判断所述用户为潜在流失用户。
与现有技术相比,本发明的优点如下:
(1)本发明从用户的基础信息指标和行为信息指标选取M种指标作为构建潜在流失用户识别模型的输入变量,并通过决策树算法构建潜在流失用户识别模型,模型固化简便,建模效率高,而且模型预测的准确性高,能够准确地识别潜在流失用户。
(2)本发明将采集的采样用户划分为成训练集和测试集,基于所述训练集,通过决策树算法构建潜在流失用户识别模型,使用测试集验证和评估潜在流失用户识别模型,并得到其中最优的潜在流失用户识别模型,因此可以提高潜在流失用户识别模型对潜在流失用户预测的准确性。
(3)本发明采用多维分析、卡方检验、方差分析和相关系数分析的多种统计方法结合的方法从用户的基础信息指标和行为信息指标中选取M种指标,指标选取重复性好。
(4)本发明中采样用户中流失用户和非流失用户的比例以及训练集和测试集的比例均可以根据实际需要进行调整,使建立的模型更加灵活,反映实际情况,预测准确率高。
附图说明
图1是本发明实施例用户流失预测方法流程图;
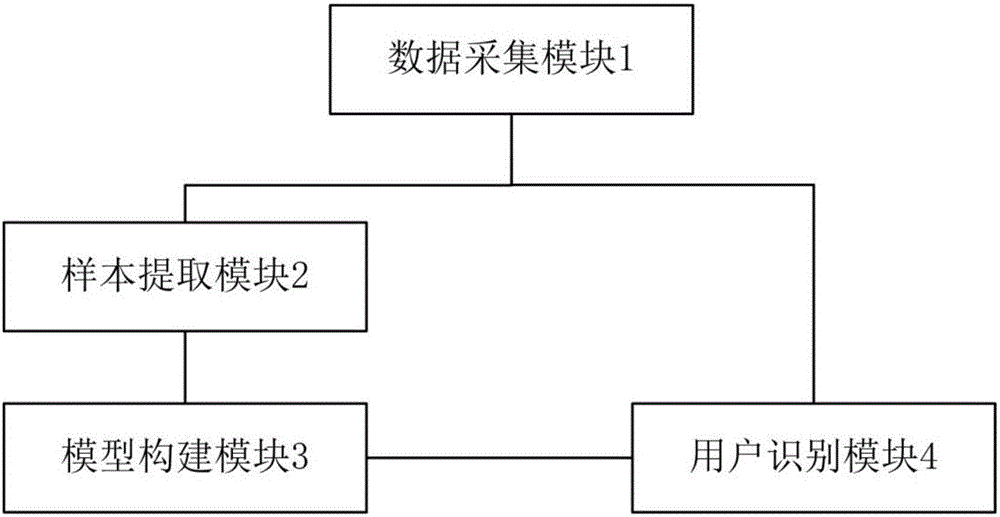
图2是本发明实施例用户流失预测系统示意图。
附图标记:
数据采集模块1,样本提取模块2,模型构建模块3,用户识别模块4。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细描述。
参见图1所示,本发明实施例提供一种用户流失预测方法,包括以下步骤:
S1.从服务器采集用户的基础信息指标和行为信息指标。
其中,基础信息指标包括用户注册时长、用户等级、用户邮箱认证状态,用户手机认证状态、来源类型,注册地。
行为信息指标包括观看信息、登录信息、充值信息、弹幕信息和交易信息。观看信息包括观看天数、观看时长和观看房间数,登录信息包括登录次数和登录天数;充值信息包括充值次数和充值金额,弹幕信息包括发送弹幕天数、发送弹幕次数和发送弹幕房间数;交易信息包括虚拟礼物赠送天数、虚拟礼物赠送次数、虚拟礼物赠送数量、虚拟礼物赠送房间数、获取虚拟礼物天数、获取虚拟礼物次数、获取虚拟礼物数量和获取虚拟礼物的方式。
从时间维度上,行为信息指标包括历史行为信息指标、历史行为信息指标波动率和最近行为信息。
S2.从在统计期内采集的用户中选取部分用户作为采样用户,并选取采样用户的目标指标和M种指标,M种指标包括采样用户的基础信息指标和行为信息指标,将目标指标小于设定的阈值的用户划分为流失用户,将目标指标大于阈值的用户划分为非流失用户。
在统计期内采集的基础信息指标和行为信息指标包括:
观看信息包括当月观看天数、当月观看时长、当月观看房间数、近三个月观看天数波动率、近三个月观看时长波动率、近三个月观看房间数波动率、近三天观看天数、近三天观看时长、近三天观看房间数和最近一次观看距离天数。
登录信息包括当月登录次数、当月登录天数、近三个月登录次数波动率、近三个月登录天数波动率、近三天登录次数、近三天登录天数和最近一次登录距离天数。
充值信息包括当月充值次数和充值金额。
弹幕信息包括当月发送弹幕天数、当月发送弹幕次数、当月发送弹幕房间数、近三个月弹幕天数波动率、近三个月弹幕次数波动率、近三个月弹幕房间数波动率、近三天弹幕天数、近三天弹幕次数、近三天弹幕房间数和最近一次发送弹幕距离天数。
交易信息包含当月虚拟礼物赠送天数、当月虚拟礼物赠送次数、当月虚拟礼物赠送量、当月虚拟礼物赠送房间数、当月获取虚拟礼物天数、当月获取虚拟礼物次数、当月获取虚拟礼物量和当月获取虚拟礼物的方式。
当月为统计期最后一个月,例如统计期为2016年1、2和3月,则当月为3月。
目标指标为用户在设定时间段内的观看时长。
具体的,在考察期观看视频直播的用户的观看时长大于30分钟,如果在预测期完全没有观看的用户为流失用户,如果在预测期内观看的用户为非流失用户。其中,考察期可以为月或周,预测期也相应地可以为月或周,预测期在考察期之后,本实施例以考察期和预测期均为月进行建模作为示例。如果用户A在上月观看时长为100分钟,在下月如果观看时长为0分钟,则记为流失用户,如果用户A在下月观看时长为80分钟,则记为非流失用户。
采样用户中流失用户和非流失用户的比例为,流失用户:非流失用户=1:N,N>1。例如,N=3.5。
本发明中采样用户中流失用户和非流失用户的比例可以根据实际需要进行调整,使建立的模型更加灵活,反映实际情况,预测准确率高。
按照上述比例抽样选取步骤S3中构建潜在流失用户识别模型所需的用户,并按照统计方法选取采样用户的M种指标。
M种指标的具体选取方法包括:
S2.1对采集到的基础信息指标和行为信息指标中除目标指标之外的其它指标进行转换处理,并剔除其它指标在预设范围内的极大值和极小值。转换处理包括对部分指标进行离散化取值,对缺失值进行填充,保证指标的完整性和精确性。
例如,预设范围设为5%,剔除指标在预设范围内的极大值和极小值具体为:剔除该指标的取值范围内的最大值5%范围内和最小值5%范围内的取值。
S2.2对于S2.1选取的指标进行多维分析,剔除与目标指标无关的指标,保留的指标包括离散型指标和连续型指标。这里剔除与目标指标无关的指标包括用户邮箱认证状态、用户手机认证状态、注册地等指标,以及缺失值多的指标。
多维分析是研究维度指标与目标指标之间的关系,例如研究用户手机认证状态与是否为流失用户的关系,认证用户与未认证用户中,流失用户占所有用户的流失比例是否有明显差异。举例说明,认证用户中流失比例为40%,未认证用户流失比例为50%,差异不明显。
S2.3对于离散型指标使用卡方检验,计算离散型指标与目标指标之间的卡方值,剔除卡方值小于预设的卡方值阈值的指标。卡方检验的基本原理是通过卡方值的大小来检验实际观察值与理论值之间的偏离程度,判断两个或两个以上指标之间是否具有关联关系的假设检验。
S2.4对于连续型指标使用方差分析,计算连续型指标与目标指标之间的方差,剔除方差小于预设的方差阈值的连续型指标;对于方差大于预设的方差阈值的连续型指标,计算其与目标指标之间的相关系数,并剔除与目标指标相关系数小于预设阈值的指标,最终得到M种指标。
方差分析是从观察指标的方差入手,研究诸多连续性指标中哪些指标是对目标指标有显著影响的变量。
下面通过具体例子解释通过计算相关系数的方法剔除与目标指标相关系数小于预设阈值的指标。例如,发送弹幕房间数与发送弹幕天数两个指标的相关系数为0.8765,属于强相关指标。通常如果相关系数大于0.8则为强相关,因此应当剔除其中一个指标。发送弹幕房间数与为流失用户的相关系数为0.1245,发送弹幕天数与为流失用户的相关系数为0.3212,因此,剔除与为流失用户相关性小的发送弹幕房间数指标。
本发明采用多维分析、卡方检验、方差分析和相关系数分析的多种统计方法结合的方法从用户的基础信息指标和行为信息指标中选取M种指标,指标选取重复性好。
经过上述步骤筛选的M种指标包括:观看天数、观看时长、观看房间数、观看天数波动率、观看时长波动率、观看房间数波动率、最近一次观看距离天数、最近一次发送弹幕距离天数、弹幕天数、虚拟礼物赠送天数和注册时长。
M种指标包括在统计期内不同时间段内的取值。
具体的,M种指标包括当月观看天数、近三个月观看天数波动率、近三个月观看时长波动率、近三个月观看房间数波动率、近三天观看天数、近三天观看时长、最近一次观看距离天数、近三天弹幕天数、最近一次发送弹幕距离天数、当月虚拟礼物赠送天数和注册时长。
S3.根据采样用户的目标指标和M种指标,通过决策树算法构建潜在流失用户识别模型,步骤S3具体包括:
S3.1将采样用户划分成训练集和测试集,训练集和测试集均包括流失用户和非流失用户,并且训练集和测试集中流失用户和非流失用户的比例分别与采样用户中流失用户和非流失用户的比例相同。
例如,训练集和测试集的比例为3:1,即75%的采样用户划分为训练集,剩余25%的采样用户划分为测试集。
本发明中训练集和测试集的比例均可以根据实际需要进行调整,使建立的模型更加灵活,反映实际情况,预测准确率高。
S3.2基于训练集,通过决策树算法构建潜在流失用户识别模型,并得到具有最优参数组合的潜在流失用户识别模型,最优参数组合包括M种指标和每个子分支的最小记录数。
本发明采用决策树分类算法构建潜在流失用户识别模型。决策树算法,以二分类预测问题为例,利用自变量构造一颗二叉树,将目标变量区分出来,二叉树的内部节点一般表示为一个逻辑判断,叶子节点表示类别标记。运用决策树算法建立潜在流失用户识别模型,并调试潜在流失用户识别模型的各种参数,对潜在流失用户识别模型进行剪枝,选择具有最优参数组合的潜在流失用户识别模型。
最优参数组合的确定通过,例如,选择每个子分支的最小记录数为30。
S3.3使用测试集评估具有最优参数组合的潜在流失用户识别模型,并得到最优的潜在流失用户识别模型。
得到最优的潜在流失用户识别模型的方法包括:
计算潜在流失用户识别模型的多个考核指标,考核指标包括准确率、查全率、提升度和F-Measure,选取考核指标均为最大的潜在流失用户识别模型为最优的潜在流失用户识别模型。
准确率为正确识别的流失用户数/识别出流失的用户数。
查全率为正确识别的流失用户数/测试集中流失的用户数。
提升度为准确率/(测试集中流失用户数/测试集中所有用户数)。
F-Measure=正确率*召回率*2/(正确率+召回率)
F值即为正确率和召回率的调和平均值。
步骤S3还包括从最优的潜在流失用户识别模型中提取多条识别规则,并计算识别规则的预测概率,预测概率根据通过该规则预测出的训练集中流失用户数量n,以及预测出的训练集中流失用户数量n中真正流失的用户数n1计算得到:预测概率=n1:n,n≥0,n1≥0。
例如,其中一条识别规则为:如果近三天观看天数>d,并且观看时长<t以及近三个月观看天数波动率<x……,其中训练集中通过该规则预测出的流失用户数量n=100,预测出的用户中真正流失的用户数n1=60,则预测概率为60/100=60%。其中d≥0,t≥0,x≥0,x和t均为实数,d为整数。
本发明从用户的基础信息指标和行为信息指标选取M种指标作为构建潜在流失用户识别模型的输入变量,并通过决策树算法构建潜在流失用户识别模型,模型固化简便,建模效率高,而且模型预测的准确性高,能够准确地识别潜在流失用户。
本发明将采集的采样用户划分为成训练集和测试集,基于所述训练集,通过决策树算法构建潜在流失用户识别模型,使用测试集验证和评估潜在流失用户识别模型,并得到其中最优的潜在流失用户识别模型,因此可以提高潜在流失用户识别模型对潜在流失用户预测的准确性。
S4.将在统计期之后采集的M种指标的取值作为潜在流失用户识别模型的输入变量,获得M种指标对应的用户的流失概率,如果流失概率大于设定的阈值,则判断用户为潜在流失用户。
步骤S4具体包括:将在统计期之后采集的M种指标的取值作为识别规则的输入变量,将识别规则的预测概率作为M种指标对应的用户的流失概率,如果流失概率大于设定的阈值,则判断用户为潜在流失用户。
下面通过具体例子进行说明。
在统计期之后采集M种指标的取值的具体方法如下:
例如,统计期为2016年1、2和3月,则在统计期之后采集M种指标的取值可以在2016年2、3和4月、2016年3、4和5月或2016年4、5和6月进行,M种指标包括在上述采集期内不同时间段内的取值。
如果预先设定的阈值=50%,并且,
如果用户B的近三天观看天数>d,并且观看时长<t以及近三个月观看天数波动率<x……,该识别规则的预测概率为60%,则判断该用户B为流失用户。
如果用户C的近三天观看天数>d并且观看时长<t以及近三个月观看天数波动率>x……该识别规则的预测概率为30%,则判断该用户C为非流失用户。
其中d≥0,t≥0,x≥0,x和t均为实数,d为整数。
可以通过撰写sql脚本,进行自动化部署,每月定期将用户的M种指标输入到潜在流失用户识别模型中,预测该用户为潜在流失用户的概率,判断用户是否为潜在流失用户。
进一步可以输出潜在流失用户清单,并分析潜在流失用户的流失原因,匹配相应的策略,进行维系挽留。
参见图2所示,本发明还提供一种用户流失预测系统,包括:
数据采集模块1,用于从服务器采集用户的基础信息指标和行为信息指标。
样本提取模块2,用于从在统计期内采集的用户中选取部分用户作为采样用户,并选取采样用户的目标指标和M种指标,M种指标包括采样用户的基础信息指标和行为信息指标,采样用户根据目标指标划分为流失用户和非流失用户,流失用户的目标指标小于设定的阈值,非流失用户的目标指标大于阈值。
模型构建模块3,用于根据采样用户的目标指标和M种指标,通过决策树算法构建潜在流失用户识别模型。
用户识别模块4,用于将数据采集模块1在统计期之后采集的M种指标的取值作为潜在流失用户识别模型的输入变量,获得M种指标对应的用户的流失概率,如果流失概率大于设定的阈值,则判断用户为潜在流失用户。
本发明采用决策树算法构建潜在流失用户识别模型,识别规则与流失原因之间关系可解释性好,因此便于针对识别出的潜在流失用户,快速、准确地确定其具体流失原因,并匹配相应的维系策略进行营销挽留,通过提升用户体验,有效地延长潜在流失用户的观看时长,避免潜在流失用户流失。
本领域的技术人员可以对本发明实施例进行各种修改和变型,倘若这些修改和变型在本发明权利要求及其等同技术的范围之内,则这些修改和变型也在本发明的保护范围之内。
说明书中未详细描述的内容为本领域技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!