一种基于依存约束和知识的形容词词义消歧方法和装置与流程
本发明涉及自然语言处理
技术领域:
,具体涉及一种基于依存约束和知识的形容词词义消歧方法和装置。
背景技术:
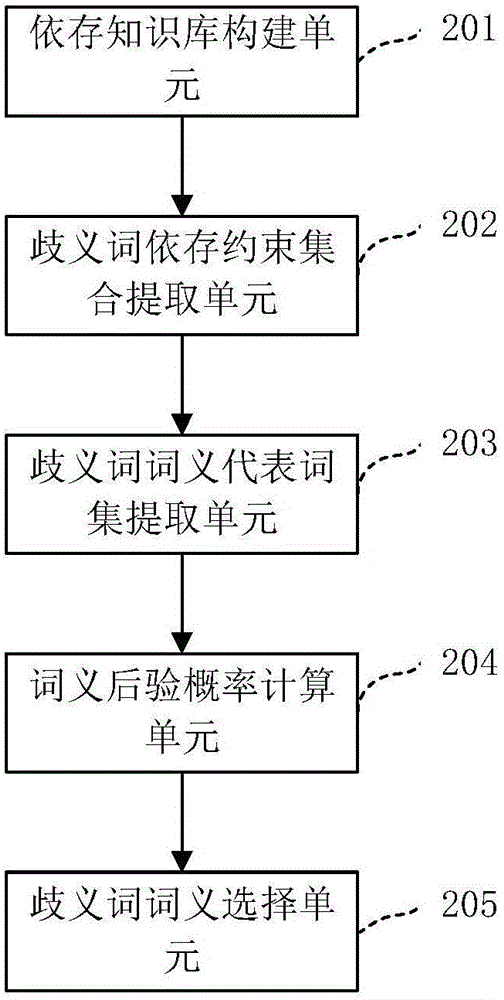
:词义消歧是指根据歧义词的上下文环境而自动判定其词义。词义消歧是自然语言处理领域的基础性任务,对机器翻译、信息检索、文本分类、自动文摘等具有直接影响。基于知识库的词义消歧方法是目前唯一能够真正应用于大规模词义消歧任务的方法。其效果主要受到三个因素的影响:一是知识库的规模和质量,二是上下文相关词选择的准确性,三是词义相关度计算方法。现有的知识库建设方法,可以划分为自动构建和人工构建两种方式。前者通过统计学习的方法从语料库中自动获取知识,比如词共现、语言模型等;这种方法并未考虑词语的句法、词义关系,其难免受到一些近距离的噪声词的干扰。后者人工构建知识库;面对词义消歧所需知识的海量规模,显然是难以实现的。现有的词义消歧方法在为歧义词选择上下文相关词时,往往采用滑动窗口的方法;这种方法无法排除近距离的噪声词,同时会忽略远距离的相关词。这种滑动窗口的选择方法,没有考虑到歧义词词性的区别;不同的词性具有不同的特点,在为其进行相关词选择时应区别对待;现有方法显然忽视了词性的区别。现有的词义相关度计算方法,往往只是利用词典考虑词义的相关程度,而忽略了从句法或语义关系上考虑词义的相关程度。现有方法存在的这些问题,制约了词义消歧效果的提升。面对现有基于知识库的词义消歧方法所存在的以上技术问题,本发明专利针对形容词词义消歧的特点,充分挖掘依存句法分析技术的优势,实现一种基于依存约束和知识的形容词词义消歧方法和装置,力求能够在一定程度上推动这些问题的解决。技术实现要素:为解决现有技术存在的不足,本发明公开了一种基于依存约束和知识的形容词词义消歧方法和装置,以更准确地判定歧义形容词的词义。为此,本发明提供如下技术方案:一种基于依存约束和知识的形容词词义消歧方法,包括以下步骤:步骤一、对大规模语料进行依存句法分析,收集所得的依存元组并统计其频数,构建依存知识库;步骤二、对歧义形容词所在句子进行依存句法分析,从中提取支配词及从属词均为实词并且依存关系为4种设定类型的依存元组,作为歧义形容词的依存约束集合;步骤三、根据语义词典,为歧义形容词的各个词义,依次提取同义词集、近义词集、反义词集作为相应词义的词义代表词集;步骤四、根据依存知识库和词义代表词集,依次计算歧义形容词的各个词义在依存约束集合的后验概率;步骤五、根据步骤四的计算结果,选择后验概率最大的词义作为歧义形容词的正确词义;若多个词义同时取得相等的最大后验概率,则从中选择词频最高的词义作为歧义形容词的正确词义。基于依存约束和知识的形容词词义消歧方法中,所述依存元组为三元组形式,包括依存关系类型、支配词、从属词,可表示为:依存关系类型(支配词,从属词);其中支配词包含支配词的原形和词性信息,从属词包含从属词的原形和词性信息。进一步的,所述步骤一中,在构建依存知识库时,具体为:步骤1-1)对大规模语料库中的各个文档,依次进行依存句法分析和词形还原处理,收集其中蕴含的依存元组,并记录各依存元组的出现频次;步骤1-2)汇总各文档中包含的依存元组集合和频次信息,得到依存知识库。进一步的,所述步骤二中,在提取歧义形容词的依存约束集合时,具体为:步骤2-1)对歧义形容词所在的句子进行依存句法分析和词形还原处理,收集其中涉及歧义形容词的依存元组;步骤2-2)对收集到的依存元组进行过滤,仅保留支配词及从属词均为实词并且依存关系为以下4种设定类型的元组:形容词补足(acomp),副词修饰(advmod),形容词修饰(amod),并列连接(conj)。步骤2-3)将过滤后所得的依存元组的集合,作为歧义形容词的依存约束集合。进一步的,所述步骤三中,在提取各个词义的词义代表词集时,具体为:步骤3-1)根据WordNet的Synonyms关系获得当前词义的同义词集;步骤3-2)根据WordNet的Similarto关系获得当前词义的近义词集;步骤3-3)根据WordNet的Antonym关系获得当前词义的反义词集;步骤3-4)将上述三类词集合并,剔除词组及歧义形容词自身后,作为当前词义的词义代表词集。进一步的,所述步骤四中,在计算词义在依存约束集合中的后验概率时,具体为:步骤4-1)依次计算各个词义代表词在各个依存约束条件下的后验概率,具体为:将词义代表词集中的某一词义代表词记作将某一依存约束元组记作r′j并表示为:rj(w1,w2);若歧义形容词为依存约束元组中的支配词,则此后验概率由公式(1)计算;P(wsi|rj′)=P(wsi|rj,w2)=c(rj,wsi,w2)+1c(rj,*,w2)+M---(1)]]>其中,表示依存关系类型为rj、支配词为从属词为w2的依存元组的数量;c(rj,*,w2)表示依存关系类型为rj、从属词为w2的依存元组的数量;M表示语义词典中包含的形容词词形的总数;若歧义形容词为依存约束元组中的从属词,则此后验概率由公式(2)计算;P(wsi|rj′)=P(wsi|rj,w1)=c(rj,w1,wsi)+1c(rj,w1,*)+M---(2)]]>其中,表示依存关系类型为rj、支配词为w1、从属词为的依存元组的数量;c(rj,w1,*)表示依存关系类型为rj、支配词为w1的依存元组的数量;M表示语义词典中包含的形容词词形的总数。步骤4-2)依次计算各个词义在依存约束集合条件下的后验概率,具体为:假定各个依存约束元组之间彼此条件独立,则此后验概率可由公式(3)计算;P(si|R)=maxwsi∈WsiΠrj′∈RP(wsi|rj′)---(3)]]>其中,si表示某一词义,R表示依存约束集合,表示词义代表词集,r′j表示某一依存约束元组,表示某一词义代表词。一种基于依存约束和知识的形容词词义消歧装置,包括:依存知识库构建单元,用于对大规模语料进行依存句法分析,收集所得的依存元组并统计其频数,构建依存知识库;歧义词依存约束集合提取单元,用于对歧义形容词所在句子进行依存句法分析,从中提取支配词及从属词均为实词并且依存关系为4种设定类型的依存元组,作为歧义形容词的依存约束集合;歧义词词义代表词集提取单元,用于根据语义词典,为歧义形容词的各个词义,依次提取同义词集、近义词集、反义词集作为相应词义的词义代表词集;词义后验概率计算单元,用于根据依存知识库和词义代表词集,依次计算歧义形容词的各个词义在依存约束集合的后验概率;歧义词词义选择单元,用于根据词义后验概率计算单元的输出数据,选择后验概率最大的词义作为歧义形容词的正确词义;若多个词义同时取得相等的最大后验概率,则从中选择词频最高的词义作为歧义形容词的正确词义。基于依存约束和知识的形容词词义消歧装置中,所述依存元组为三元组形式,包括依存关系类型、支配词、从属词,可表示为:依存关系类型(支配词,从属词);其中支配词包含支配词的原形和词性信息,从属词包含从属词的原形和词性信息。进一步的,所述依存知识库构建单元还包括:单文档依存处理单元,用于对大规模语料库中的各个文档,依次进行依存句法分析和词形还原处理,收集其中蕴含的依存元组,并记录各依存元组的出现频次;依存知识归并单元,用于汇总各文档中包含的依存元组集合和频次信息,得到依存知识库;进一步的,所述歧义词依存约束集合提取单元还包括:歧义句依存处理单元,用于对歧义形容词所在的句子进行依存句法分析和词形还原处理,收集其中涉及歧义形容词的依存元组;依存元组过滤单元,用于对收集到的依存元组进行过滤,仅保留支配词及从属词均为实词并且依存关系为以下4种设定类型的元组:形容词补足(acomp),副词修饰(advmod),形容词修饰(amod),并列连接(conj);依存约束集合收集单元,用于将过滤后所得的依存元组的集合作为歧义形容词的依存约束集合;进一步的,所述歧义词词义代表词集提取单元还包括:同义代表词提取单元,用于根据WordNet的Synonyms关系获得当前词义的同义词集;近义代表词提取单元,用于根据WordNet的Similarto关系获得当前词义的反义词集;反义代表词提取单元,用于根据WordNet的Antonym关系获得当前词义的反义词集;词义代表词归并单元,用于将同义词集、近义词集、反义词集合并,剔除词组及歧义形容词自身后,作为当前词义的词义代表词集;进一步的,所述词义后验概率计算单元还包括:词义代表词后验概率计算单元,用于计算特定词义代表词在特定依存约束条件下的后验概率;词义在依存约束集合条件下的后验概率计算单元,用于计算特定词义在依存约束集合条件下的后验概率。本发明的有益效果:1、本发明利用依存句法分析技术完成依存知识库的构建,考虑了词语之间的句法、语义关系,所构建的依存知识库具有较高质量。2、针对形容词的特点,本发明优选了4种类型的语义关系密切的依存元组,构建其依存约束集合,可减少其它无关元组的干扰,使其上下文相关词的选择更为准确。3、针对形容词的特点,本发明优选同义词集、近义词集、反义词集作为相应词义的词义代表词集,能够较为准确地评估词义在上下文环境的适合程度。4、本发明提出的词义在依存约束集合的后验概率的计算方法,考虑了句法、语义关系,能够更为全面准确地评估词义与上下文环境的匹配程度。5、本发明提出的基于依存约束和知识的形容词词义消歧方法和装置,能够自动完成依存知识库的构建,准确地选择依存约束元组,并计算词义的后验概率,具有较高的消歧正确率,改善形容词的词义消歧效果。附图说明图1为根据本发明实施方式基于依存约束和知识的形容词词义消歧方法的流程图;图2为根据本发明实施方式基于依存约束和知识的形容词词义消歧装置的结构示意图;图3为根据本发明实施方式依存知识库构建单元的结构示意图;图4为根据本发明实施方式歧义词依存约束集合提取单元的结构示意图;图5为根据本发明实施方式歧义词词义代表词集提取单元的结构示意图;图6为根据本发明实施方式词义后验概率计算单元的结构示意图。具体实施方式:为了使本
技术领域:
的人员更好地理解本发明实施例的方案,下面结合附图和实施方式对发明实施例作进一步的详细说明。以对句子“Inarecentandpublicreport,theinstituteofmedicinepresentsthatcertainhealthproblemmaypredisposeapersontohomelessness.”中的歧义形容词recent进行消歧处理为例。根据WordNet3.0,形容词recent的词义信息如表1所示。表1其中,#a代表词性为形容词,#1~#3代表三个不同的词义编号。本发明实施例基于依存约束和知识的形容词词义消歧方法的流程图,如图1所示,包括以下步骤。步骤101,构建依存知识库。对大规模语料进行依存句法分析,收集所得的依存元组并统计其频数,构建依存知识库,具体为:步骤1-1)对大规模语料库中的各个文档,依次进行依存句法分析和词形还原处理,收集其中蕴含的依存元组,并记录各依存元组的出现频次;步骤1-2)汇总各文档中包含的依存元组集合和频次信息,得到依存知识库。本发明实施例中,使用ReuterCorpus作为语料库,其中包含了路透社人工收集整理的80余万篇新闻文档;依存句法分析工具采用斯坦福大学所提供的StanfordParser句法分析器,使用englishPCFG.ser.gz语言模型,并允许对依存关系进行折叠和传递处理;借助WordNet3.0进行词形还原。首先根据步骤1-1)逐篇对ReuterCorpus中的新闻文档进行依存句法分析和词形还原处理,收集形如“relation(w1,w2)”的依存元组,并记录它们的出现频次。(本发明专利具体实施方式中所述依存元组“relation(w1,w2)”中的支配词w1和从属词w2均包括其原形和词性信息)。然后根据步骤1-2)将各新闻文档包含的依存元组集合和频次信息合并,得到依存知识库。最终得到的依存知识库中共包含不同类型的依存元组13417302个,其出现频次总和为93850841个。步骤102,提取歧义形容词的依存约束集合。对歧义形容词所在句子进行依存句法分析,从中提取4种类型的依存元组,作为歧义形容词的依存约束集合,具体为:步骤2-1)对歧义形容词所在的句子进行依存句法分析和词形还原处理,收集其中涉及歧义形容词的依存元组。本发明实施例中,依存句法分析工具采用斯坦福大学所提供的StanfordParser句法分析器,使用englishPCFG.ser.gz语言模型,并允许对依存关系进行折叠和传递处理;借助WordNet3.0进行词形还原。对句子“Inarecentandpublicreport,theinstituteofmedicinepresentsthatcertainhealthproblemmaypredisposeapersontohomelessness.”进行依存句法分析和词形还原处理后,得到的依存元组集合包含如下元组:det(report,a)、amod(report,recent)、amod(report,public)、conj(recent,public)、prep(present,report)、det(institute,the)、nsubj(present,institute)、prep(institute,medicine)、complm(predispose,that)、amod(problem,certain)、nn(problem,health)、nsubj(predispose,problem)、aux(predispose,may)、ccomp(present,predispose)、det(person,a)、dobj(predispose-16,person-18)、prep(predispose,homelessness)。从上述依存元组集合中收集涉及到歧义形容词recent的元组,得到的依存元组集合包含如下元组:amod(report,recent)、conj(recent,public)。步骤2-2)对收集到的依存元组进行过滤,仅保留支配词及从属词均为实词并且依存关系为以下4种设定类型的元组:形容词补足(acomp),副词修饰(advmod),形容词修饰(amod),并列连接(conj)。本发明实施例中,对步骤2-1)所得到的依存元组集合进行过滤,仅保留支配词及从属词均为实词并且依存关系为4种设定类型的元组,过滤后的依存元组集合包含如下元组:amod(report,recent)、conj(recent,public)。步骤2-3)将过滤后所得的依存元组的集合,作为歧义形容词的依存约束集合。本发明实施例中,将步骤2-2)所得到的依存元组集合,作为歧义形容词的依存约束集合。可得依存约束集合包含如下元组:amod(report,recent)、conj(recent,public)。需要说明的是,在本发明实施例中,依存元组中的支配词和从属词均包括原形和词性信息。对于依存约束集合中所涉及的词语,report即指名词report、recent即指形容词recent、public即指形容词public。步骤103,提取歧义形容词的词义代表词集。根据语义词典WordNet3.0,为歧义形容词的各个词义,依次提取同义词集、近义词集、反义词集作为相应词义的词义代表词集,具体为:步骤3-1)根据WordNet的Synonyms关系获得当前词义的同义词集;步骤3-2)根据WordNet的Similarto关系获得当前词义的近义词集;步骤3-3)根据WordNet的Antonym关系获得当前词义的反义词集;步骤3-4)将上述三类词集合并,剔除词组及歧义形容词自身后,作为当前词义的词义代表词集。在本发明实施例中,对于歧义形容词recent的各个词义的处理的说明,以recent#a#2为例。对于词义recent#a#2,由步骤3-1)可得其同义词集为{late,recent};由步骤3-2)可得其近义词集为{past};由步骤3-3)可得其反义词集为空集;由步骤3-4),将前述三类词集合并,并剔除词组及recent自身后,可得词义recent#a#2的词义代表词集为{late,past}。同理,对于词义recent#a#1,由步骤3-1)至步骤3-4),可得其词义代表词集为{new}。同理,对于词义recent#a#3,由步骤3-1)至步骤3-4),可得其词义代表词集为{modern}。步骤104,计算歧义形容词的各个词义后验概率。根据依存知识库和词义代表词集,依次计算歧义形容词的各个词义在依存约束集合的后验概率,具体为:步骤4-1)依次计算各个词义代表词在各个依存约束条件下的后验概率,具体为:将词义代表词集中的某一词义代表词记作将某一依存约束元组记作r′j并表示为:rj(w1,w2);若歧义形容词为依存约束元组中的支配词,则此后验概率由公式(1)计算;P(wsi|rj′)=P(wsi|rj,w2)=c(rj,wsi,w2)+1c(rj,*,w2)+M---(1)]]>其中,表示依存关系类型为rj、支配词为从属词为w2的依存元组的数量;c(rj,*,w2)表示依存关系类型为rj、从属词为w2的依存元组的数量;M表示语义词典中包含的形容词词形的总数;若歧义形容词为依存约束元组中的从属词,则此后验概率由公式(2)计算;P(wsi|rj′)=P(wsi|rj,w1)=c(rj,w1,wsi)+1c(rj,w1,*)+M---(2)]]>其中,表示依存关系类型为rj、支配词为w1、从属词为的依存元组的数量;c(rj,w1,*)表示依存关系类型为rj、支配词为w1的依存元组的数量;M表示语义词典中包含的形容词词形的总数。步骤4-2)依次计算各个词义在依存约束集合条件下的后验概率,具体为:假定各个依存约束元组之间彼此条件独立,则此后验概率可由公式(3)计算;P(si|R)=maxwsi∈WsiΠrj′∈RP(wsi|rj′)---(3)]]>其中,si表示某一词义,R表示依存约束集合,表示词义代表词集,r′j表示某一依存约束元组,表示某一词义代表词。在本发明实施例中,因WordNet3.0中形容词词形总数为22141,故公式(1)和(2)中的M值均设为22141。以词义recent#a#2为例,说明步骤4-1)至步骤4-3)的具体操作过程。由步骤102已得,依存约束集合R包含如下元组:amod(report,recent)、conj(recent,public)。由步骤103已得,词义recent#a#2(记作s2)的词义代表词集为{late,past}。由步骤4-1)依次计算中的各个词义代表词在依存约束集合R中各依存约束条件下的后验概率,过程如下:因recent为依存约束元组amod(report,recent)的从属词,故词义代表词late在该依存约束元组中的后验概率可由公式(2)计算;根据步骤101统计而得的依存知识库,可得c(amod,report,late)的值为1279,c(amod,report,*)的值为37037;故可得:P(late|amod,report)=c(amod,report,late)+1c(amod,report,*)+22141=1279+137037+22141=0.021629659670823618]]>因recent为依存约束元组conj(recent,public)的支配词,故词义代表词late在该依存约束元组中的后验概率可由公式(1)计算;根据步骤101统计而得的依存知识库,可得c(conj,late,public)的值为2,c(conj,*,public)的值为799;故可得:P(late|conj,public)=c(conj,recent,public)+1c(conj,*,public)+22141=2+1799+22141=1.3077593722755012E-4]]>同理,可得:P(past|amod,report)=1.6898171617830951E-4P(past|conj,public)=4.359197907585005E-5由步骤4-2)计算词义recent#a#2在依存约束集合条件下的后验概率,过程如下:已知依存约束集合R中所包含的依存约束元组分别为:amod(report,recent)、conj(recent,public);词义recent#a#2的为{late,past}。首先,对于词义recent#a#2的各个词义代表词分别计算其对于词义代表词late,代入步骤4-1)的计算结果,可得:Πrj′∈RP(late|rj′)=0.021629659670823618×1.3077593722755012E-4=2.828639015364902E-6.]]>对于其他词义代表词,同理可得:Πrj′∈RP(past|rj′)=1.6898171617830951E-4×4.359197907585005E-5=7.3662474358461E-9.]]>然后,根据公式(3),从中选一个最大值作为P(s2|R);可得P(s2|R)的值为2.828639015364902E-6。对于其它各个词义recent#a#1、recent#a#3,分别记作s1、s3;由步骤4-1)和步骤4-2),同理可得:P(s1|R)=3.3074450986948986E-7P(s3|R)=7.3662474358461E-10步骤105,根据词义后验概率选择歧义形容词的正确词义。根据步骤104的计算结果,选择后验概率最大的词义作为歧义形容词的正确词义;若多个词义同时取得相等的最大后验概率,则从中选择词频最高的词义作为歧义形容词的正确词义。由步骤104,比较P(s1|R)、P(s2|R)、P(s3|R)的大小,可知P(s2|R)的值最大,故将词义s2,即recent#a#2,作为歧义形容词recent的正确词义。需要说明的是,步骤105中,如果多个词义同时取得相等的最大后验概率,则根据WordNet3.0的词频信息,从中选择词频最高的词义作为歧义形容词的正确词义。通过以上操作步骤,即可完成歧义形容词recent的词义消歧工作。相应地,本发明实施例还提供一种基于依存约束和知识的形容词词义消歧装置,其结构示意图如图2所示。在该实施例中,所述装置包括:依存知识库构建单元201,用于对大规模语料进行依存句法分析,收集所得的依存元组并统计其频数,构建依存知识库;歧义词依存约束集合提取单元202,用于对歧义形容词所在句子进行依存句法分析,从中提取支配词及从属词均为实词并且依存关系为4种设定类型的依存元组,作为歧义形容词的依存约束集合;歧义词词义代表词集提取单元203,用于根据语义词典,为歧义形容词的各个词义,依次提取同义词集、近义词集、反义词集作为相应词义的词义代表词集;词义后验概率计算单元204,用于根据依存知识库和词义代表词集,依次计算歧义形容词的各个词义在依存约束集合的后验概率;歧义词词义选择单元205,用于根据词义后验概率计算单元的输出数据,选择后验概率最大的词义作为歧义形容词的正确词义;若多个词义同时取得相等的最大后验概率,则从中选择词频最高的词义作为歧义形容词的正确词义;需要说明的是,在本发明实施例中,该装置中各构成单元所述依存元组为三元组形式,包括依存关系类型、支配词、从属词,可表示为:依存关系类型(支配词,从属词);其中支配词包含支配词的原形和词性信息,从属词包含从属词的原形和词性信息。图2所示装置的依存知识库构建单元201的结构示意图如图3所示,其包括:单文档依存处理单元301,用于对大规模语料库中的各个文档,依次进行依存句法分析和词形还原处理,收集其中蕴含的依存元组,并记录各依存元组的出现频次;依存知识归并单元302,用于汇总各文档中包含的依存元组集合和频次信息,得到依存知识库。图2所示装置的歧义词依存约束集合提取单元202的结构示意图如图4所示,其包括:歧义句依存处理单元401,用于对歧义形容词所在的句子进行依存句法分析和词形还原处理,收集其中涉及歧义形容词的依存元组;依存元组过滤单元402,用于对收集到的依存元组进行过滤,仅保留支配词及从属词均为实词并且依存关系为以下4种设定类型的元组:形容词补足(acomp),副词修饰(advmod),形容词修饰(amod),并列连接(conj);依存约束集合收集单元403,用于将过滤后所得的依存元组的集合作为歧义形容词的依存约束集合。图2所示装置的歧义词词义代表词集提取单元203的结构示意图如图5所示,其包括:同义代表词提取单元501,用于根据WordNet的Synonyms关系获得当前词义的同义词集;近义代表词提取单元502,用于根据WordNet的Similarto关系获得当前词义的近义词集;反义代表词提取单元503,用于根据WordNet的Antonym关系获得当前词义的反义词集;词义代表词归并单元504,用于将同义词集、近义词集、反义词集合并,剔除词组及歧义形容词自身后,作为当前词义的词义代表词集。图2所示装置的词义后验概率计算单元204的结构示意图如图6所示,其包括:词义代表词后验概率计算单元601,用于计算特定词义代表词在特定依存约束条件下的后验概率;词义在依存约束集合条件下的后验概率计算单元602,用于计算特定词义在依存约束集合条件下的后验概率。可以将图2~图6所示的基于依存约束和知识的形容词词义消歧装置集成到各种硬件实体中。比如,可以将基于依存约束和知识的形容词词义消歧装置集成到:个人电脑、平板电脑、智能手机、工作站等设备之中。可以通过指令或指令集存储的储存方式将本发明实施方式所提出的基于依存约束和知识的形容词词义消歧方法存储在各种存储介质上。这些存储介质包括但不局限于:软盘、光盘、硬盘、内存、U盘、CF卡、SM卡等。综上所述,在本发明实施方式中,对大规模语料进行依存句法分析,收集所得的依存元组并统计其频数,构建依存知识库;对歧义形容词所在句子进行依存句法分析,从中提取支配词及从属词均为实词并且依存关系为4种设定类型的依存元组,作为歧义形容词的依存约束集合;根据语义词典,为歧义形容词的各个词义,依次提取同义词集、近义词集、反义词集作为相应词义的词义代表词集;根据依存知识库和词义代表词集,依次计算歧义形容词的各个词义在依存约束集合的后验概率;选择后验概率最大的词义作为歧义形容词的正确词义(若多个词义同时取得相等的最大后验概率,则从中选择词频最高的词义作为歧义形容词的正确词义)。由此可见,应用本发明实施方式之后,实现了基于依存约束和知识的形容词词义消歧。本发明实施方式可以利用依存句法分析技术完成依存知识库的构建,从而提高知识库的质量;优选了4种类型的依存元组,从而排除无关元组的干扰,使其上下文相关词的选择更为准确;优选了3种类型的词义代表词集,从而较为准确地评估词义在上下文环境的适合程度;提出了词义在依存约束集合的后验概率的计算方法,考虑了句法、语义关系,从而更为全面准确地评估词义与上下文环境的匹配程度。本发明实施方式所实现的基于依存约束和知识的形容词词义消歧方法和装置,能够自动完成依存知识库的构建,准确地选择依存约束元组,并计算词义的后验概率,具有较高的消歧正确率。本说明书中的实施例采用递进的方式描述,彼此相同相似的部分互相参见即可。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上对本发明实施例进行了详细介绍,本文中应用了具体实施方式对本发明进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法和装置;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,故本说明书不应理解为对本发明的限制。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1