基于混合核RVM的电子装备状态预测方法与流程
本发明涉及电子装备状态预测方法技术邻域,尤其涉及一种基于混合核RVM的电子装备状态预测方法。
背景技术:
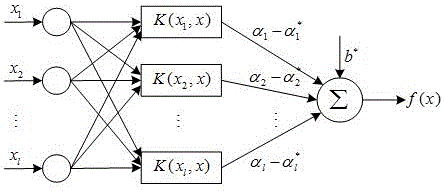
:近年来,随着大量高新技术不断涌入电子领域,电子装备逐渐呈现大型化和复杂化的趋势,其性能不断提高的同时,也给维修保障工作带来了检测诊断困难、维修费用高等诸多问题。目前,为了防止电子装备故障的发生或健康状态的退化,事后维修和定期维修是应用最为普遍的维修方式:事后维修是在装备出现故障后才进行的维修,容易导致无法预知的事故和非战斗减员;定期维修适用于寿命分布规律已知且具有耗损期的装备或部件,它虽然是一种预防性维修方式,但很难预防灾难性故障的发生,而且常引起不必要的停机,造成维修过剩或维修不足,降低了使用寿命并且浪费大量的人力、物力等。相比之下,视情维修作为一种预防性维修手段,能够根据装备所处的实际状态动态调整维修策略,确定对装备维修的最佳时机,使得维修具有预防性和灵活性,从而最大限度地降低安全隐患。如美国国防部维修技术高级指导小组开展的视情维修项目,通过优化新武器装备的维修决策和改进综合保障过程,提高系统全寿命可用度和战备完好率;美空军在联合攻击机上采用了故障预测与健康管理(PHM)系统作为视情维修技术的代表,该系统能够预测装备的剩余寿命,使维修人员能够实时了解其健康状态,据此作出合理的维修计划,大大缩短了下次出动的准备时间;美国“旅行者”号探测器在通讯系统中嵌入预测装备,为视情维修提供故障信息;瑞典国防军提出的一项横跨陆海空资产的联合自主维持能力计划,其以视情维修技术维护所用类型装备。状态预测技术作为视情维修中的重要环节,很大程度上决定了视情维修的有效性。状态预测需要对未来时刻装备的状态进行估计,进而为装备维修保障提供重要的参考信息。但是,对于不同装备而言,能够获取的状态信息种类和程度不尽相同,同时,未来时刻装备状态的变化存在诸多不确定因素,如预测模型不精确、故障状态数据不充分等,这些给健康状态预测带来了极大的困难。为此,研究切实可靠的电子装备状态预测技术,对于提高装备维修保障水平具有非常重要的科学价值和军事意义。技术实现要素:本发明所要解决的技术问题是提供一种基于混合核RVM的电子装备状态预测方法,所述方法的预测精度更高,向量数目更少,解更加稀疏,占用内存更少。为解决上述技术问题,本发明所采取的技术方案是:一种基于混合核RVM的电子装备状态预测方法,其特征在于所述方法包括如下步骤:将采集的装备原始数据划分为训练数据和测试数据两部分;将训练数据送入混合核RVM模型中进行训练,通过混合核函数的构造将训练数据映射至高维特征空间之中,对RVM模型中的超参数a和噪声方差σ2进行迭代更新,求解最优权重分布,当达到收敛精度要求时,混合核RVM模型训练结束;将测试数据送入训练好的混合核RVM模型之中进行预测,得到装备的预测输出数据;将预测输出数据送入模糊SVDD状态评估模型之中进行评估,从而得到装备的健康度预测值。进一步的技术方案在于:所述混合核RVM模型的构造方法如下:1)构造混合核函数;2)通过混合核函数构造混合核RVM模型。进一步的技术方案在于:所述的混合核函数的构造方法如下:假设核函数由M个核线性组成,其中任意一个核km均对应某一Hilbert空间Hm及相应内积运算<·,·>m,对于dm∈[0,1],任一k(x,x)=dmkm(x,x)则对应某一Hilbert空间H'm,其内积运算为:<f,g>Hm′=1dm<f,g>m]]>有:f(x)=<f,km(·,x)>m=1dm<f,dmkm(·,x)>m=<f,dmkm(·,x)>Hm′]]>根据再生核的性质,可知H'm亦为再生核Hilbert空间;定义混合核的核空间H为H'm空间的直和,则核空间H也是定义在核函数下的再生核Hilbert空间;混合核函数的组合形式为:k(xi,xj)=Σm=1Mdmkm(xi,xj)]]>式中,为混合核的权重系数,且进一步的技术方案在于:所述的通过混合核函数构造混合核RVM模型的构造方法如下:将混合核函数代入RVM模型表达式中,得到混合核RVM模型的输出为:y(x;w)=Σi=1NΣm=1Mwidmkm(x,xi)+w0ti=y(xi;w)+ϵi]]>同时对基函数矩阵进行更新,从而得到基于混合核的RVM预测模型。进一步的技术方案在于:所述的RVM模型表达式的构造方法如下:给定训练样本集t=[t1,t2,…,tN]T为目标函数值,其中xi∈Rd,ti∈R,d为输入变量的维数;假设目标值采样时附带误差εi,则RVM模型的输出定义为:y(x;w)=Σi=1Nwik(x,xi)+w0ti=y(xi;w)+ϵi]]>式中k(x,xi)为核函数。进一步的技术方案在于:所述的核函数k(x,xi)的构造方法如下:其中表示特征空间中任意样本。进一步的技术方案在于:所述的RVM模型的超参数a和噪声方差σ2的构造方法如下:设随机变量x、θ的联合分布密度为p(x,θ),它们的边际密度分别为p(x)和p(θ);设x为观测向量,θ为模型的超参数向量,通过观测向量来获得未知参数向量的估计,则贝叶斯定理为:p(θ|x)=p(θ)|p(x|θ)p(x)=p(θ)|p(x|θ)∫p(θ)p(x|θ)dθ]]>其中,p(θ)为θ的先验分布;在稀疏贝叶斯框架下,假设εi服从独立的均值为0,方差为σ2的高斯分布,即εi~N(0,σ2),则p(ti|x)=N(ti|y(xi;w),σ2),因此训练样本集的似然函数可表示为:其中,t=(t1,t2,…,tN)T,w=(w0,w1,…,wN)T,φ为一个N×(N+1)的基函数设计矩阵,即其第i(i≤N)行可表示为:由结构风险最小化原则可知,直接最大化该似然函数来估计w与σ2通常会使得w中元素大部分均不为0,从而导致模型过拟合;假设权值wi服从均值为0,方差为的先验高斯正态分布,则:p(w|a)=Πi=0NN(wi|0,αi-1)]]>式中,α=(α0,α1,…,αN)T为决定权值wi先验分布的超参数向量;由于高斯正态分布方差倒数的共轭分布为Gamma分布,因此,假设α与σ2的超先验概率分布分别为:p(α)=Πi=0NGamma(αi|a,d)]]>p(σ-2)=Gamma(σ-2|c,d)且满足:Gamma(α|a,d)=Γ(a)-1baαa-1e-ba其中为使a与σ2的超先验概率分布不提供先验信息,假定a=b=c=d=0,此时可获取一致的超先验分布;由此可得:p(wi)=∫N(wi|0,αi-1)Gamma(αi|a,b)dαi;]]>若已知模型参数的先验概率分布,根据贝叶斯公式可得训练样本集的后验概率为:p(w,α,σ2|t)=p(t|w,α,σ2)p(w,α,σ2)p(t)]]>假设待测样本为x*,则相应的预测值t*的分布为:p(t*|t)=∫p(t*|w,α,σ2)p(w,α,σ2|t)dwdαdσ2由于模型参数的后验分布p(w,α,σ2|t)不能直接通过积分获得,可采用贝叶斯定理将其分解为:p(w,α,σ2|t)=p(w|t,α,σ2)p(α,σ2|t)由于p(t|α,σ2)=∫p(t|w,σ2)p(w|α)dw可以通过积分得到,即:p(t|a,σ2)=∫p(t|w,σ2)p(w|a)dw=N(t|0,σ2I+φA-1φT)=(2π)-N/2|σ2I+φA-1φT|-1/2exp(-12tT(σ2I+φA-1φT)-1t)]]>因此权值向量w的后验概率分布p(w|t,α,σ2)可表示为:p(w|t,α,σ2)=p(t|w,σ2)p(w|α)p(t|α,σ2)=(2π)-(N+1)/2|Σ|-1/2exp(-12(w-μ)TΣ-1(w-μ))]]>其均值和方差分别为:μ=σ-2ΣφTtΣ=(A+σ-2φTφ)-1且A=diag(α0,α1,…,αN);超参数a的后验概率分布p(α,σ2|t)无法由解析公式给出,而是通过一个delta函数近似表示:p(α,σ2|t)∝δ(αMP,σMP2)]]>最大化p(α,σ2|t)∝p(t|α,σ2)p(α)p(σ2)即可得出αMP和(αMP,σMP2)=argmaxa,σ2p(t|α,σ2)]]>其中,p(t|a,σ2)被称为边缘似然分布,只需最大化该边缘似然分布就可得到αMP和对式两边取对数,可得超参数的对数似然分布为:lnp(t|a,σ2)=lnN(t|0,σ2I+φA-1φT)=-12{Nln(2π)+ln|σ2I+φA-1φT|+tT(σ2I+φA-1φT)-1t}]]>将上式分别对α和σ2求偏微分并令其等于0,得:αinew=γiμi2]]>(σ2)new=||t-φμ||2N-Σiγi]]>γi≡1-αi∑ii其中,μi为后验概率分布均值μ=σ-2∑φTt的第i个权重;∑ii为后验概率分布方差∑=(A+σ-2φTφ)-1的第i个对角线元素;通过式和的迭代更新即可逼近αMP和实现超参数的优化求解。采用上述技术方案所产生的有益效果在于:通过所述方法构建的混合核RVM预测曲线同函数的实际曲线吻合较好,表现出良好的预测能力;混合核RVM无论从平均相对误差还是向量数目上,均要优于单核RVM;同支持向量回归模型SVR相比,混合核RVM预测精度略有提高,但向量数目却大大减少,因此占用内存空间更少,性能也更优。附图说明图1是ε不敏感损失函数;图2是支持向量回归模型的结构;图3是高斯RBF核函数特性曲线;图4是多项式Poly核函数特性曲线;图5是多项式Poly核函数与高斯RBF核函数的混合核函数特性曲线;图6是基于混合核RVM的预测模型;图7是SVR模型预测结果;图8是多项式Poly核函数预测结果;图9是高斯RBF核函数预测结果;图10是混合核函数下的RVM模型预测结果;图11是某装备压控振荡器频率输出预测值同实际值比较曲线。具体实施方式下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。总体的,本发明公开了一种基于混合核RVM的电子装备状态预测方法,所述方法包括如下步骤:将采集的装备原始数据划分为训练数据和测试数据两部分;将训练数据送入混合核RVM模型中进行训练,通过混合核函数的构造将训练数据映射至高维特征空间之中,对RVM模型中的超参数a和噪声方差σ2进行迭代更新,求解最优权重分布,当达到收敛精度要求时,混合核RVM模型训练结束;将测试数据送入训练好的混合核RVM模型之中进行预测,得到装备的预测输出数据;将预测输出数据送入模糊SVDD状态评估模型之中进行评估,从而得到装备的健康度预测值。下面对上述方法所设计的理论进行分析:本发明所述方法以贝叶斯学习理论为基础,构建具有概率分布形式的相关向量机模型并对其进行分析;在此基础上采用混合核函数的形式对模型的核映射方式进行改进,提出基于混合核的RVM预测模型;利用该模型对原始数据序列进行预测后,将预测得到的数据序列送入模糊SVDD状态评估模型中进行评估,进而得到电子装备的未来健康度(状态评估)以及健康状态级别(状态识别)。支持向量回归模型SVR:给定训练集S={(x1,y1),…,(xl,yl)|xi∈Rn,yi∈R},将训练集S通过映射映射至高维特征空间中,则被估计函数f(x):式中,w为特征空间H中的权向量,b∈R,b为偏置。为得到该回归估计函数,首先采用Vapnik提出的ε不敏感损失函数Lε进行计算,该损失函数表达式为:L(x,y,f(x))=|y-f(x)|ϵ=|y-f(x)|-ϵ|y-f(x)|>ϵ0|y-f(x)|≤ϵ---(2)]]>其中,f(x)为预测值,y为对应的真实值。其含义为当f(x)与y之间的差别不大于ε时,损失为0,如图1所示。引入松弛变量εi和可以得到支持向量回归的原问题描述:将上述原问题转化为如下对偶问题,同时引入核函数可得:min12Σi,j=1l(ai-ai*)(aj-aj*)k(xi,xj)-Σi=1l[ai(yi-ϵ)-ai*(yi+ϵ)]s.t.Σi=1lai=Σi=1lai*,0≤ai,ai*≤C,i=1,2,...,l---(4)]]>通过求解上式得到的最优解为则:b*=1Nnsv{Σ0<ai<C[yi-Σxi∈SV(αi-αi*)k(xi,xj)-ϵ]+Σ0<ai<C[yi-Σxj∈SV(αj-αj*)k(xi,xj)+ϵ]}---(6)]]>其中,Nnsv为支持向量个数。于是,回归估计函数f(x)为:其中,只有部分参数不为零,其对应的样本xi即为问题中的支持向量。支持向量回归模型的结构如图2所示。基于稀疏贝叶斯框架的RVM模型:相关向量机(RelevanceVectorMachine,RVM)模型是一种基于贝叶斯学习理论的稀疏概率模型,它具有与支持向量机相似的函数形式和相当的泛化性能。贝叶斯学习理论:RVM是基于贝叶斯学习理论建立起来的,贝叶斯学习理论采用概率的方法表示不确定性关系,将先验知识、样本信息和概率表示等有机结合起来,通过贝叶斯定理实现学习和推理的过程,并将结果表示为随机变量的概率分布。贝叶斯框架下的机器学习方法考虑了模型中所包含的先验知识,避免了过拟合问题。假设随机变量x、θ的联合分布密度为p(x,θ),它们的边际密度分别为p(x)和p(θ)。一般假设x为观测向量,θ为模型的超参数向量,通过观测向量来获得未知参数向量的估计,则贝叶斯定理为:p(θ|x)=p(θ)|p(x|θ)p(x)=p(θ)|p(x|θ)∫p(θ)p(x|θ)dθ---(8)]]>其中,p(θ)为θ的先验分布。从上式可知,贝叶斯学习对超参数的估计综合了先验信息和样本信息,首先对学习模型的权空间或函数空间做一定的先验假设,然后进行贝叶斯推理,而传统参数估计的方法只能从样本数据中获取信息。RVM回归预测模型:给定训练样本集t=[t1,t2,…,tN]T为目标函数值,其中xi∈Rd,ti∈R,d为输入变量的维数。假设目标值采样时附带误差εi,则RVM模型的输出定义为:y(x;w)=Σi=1Nwik(x,xi)+w0ti=y(xi;w)+ϵi---(9)]]>式中k(x,xi)为核函数(不必满足Mercer条件)。在稀疏贝叶斯框架下,假设εi服从独立的均值为0,方差为σ2的高斯分布,即εi~N(0,σ2),则p(ti|x)=N(ti|y(xi;w),σ2),因此训练样本集的似然函数可表示为:其中,t=(t1,t2,…,tN)T,w=(w0,w1,…,wN)T,φ为一个N×(N+1)的基函数设计矩阵,即其第i(i≤N)行可表示为:由结构风险最小化原则可知,直接最大化该似然函数来估计w与σ2通常会使得w中元素大部分均不为0,从而导致模型过拟合。假设权值wi服从均值为0,方差为的先验高斯正态分布,则:p(w|a)=Πi=0NN(wi|0,αi-1)---(12)]]>式中,α=(α0,α1,…,αN)T为决定权值wi先验分布的超参数向量。由于高斯正态分布方差倒数的共轭分布为Gamma分布,因此,假设α与σ2的超先验概率分布分别为:p(α)=Πi=0NGamma(αi|a,b)---(13)]]>p(σ-2)=Gamma(σ-2|c,d)(14)且满足:Gamma(α|a,d)=Γ(a)-1baαa-1e-ba(15)其中为使a与σ2的超先验概率分布不提供先验信息,假定a=b=c=d=0,此时可获取一致的超先验分布。由此可得:p(wi)=∫N(wi|0,αi-1)Gamma(αi|a,b)dαi---(16)]]>贝叶斯参数推理:若已知模型参数的先验概率分布,根据贝叶斯公式可得训练样本集的后验概率为:p(w,α,σ2|t)=p(t|w,α,σ2)p(w,α,σ2)p(t)---(17)]]>假设待测样本为x*,则相应的预测值t*的分布为:p(t*|t)=∫p(t*|w,α,σ2)p(w,α,σ2|t)dwdαdσ2(18)由于模型参数的后验分布p(w,α,σ2|t)不能直接通过积分获得,可采用贝叶斯定理将其分解为:p(w,α,σ2|t)=p(w|t,α,σ2)p(α,σ2|t)(19)由于p(t|α,σ2)=∫p(t|w,σ2)p(w|α)dw可以通过积分得到,即:p(t|a,σ2)=∫p(t|w,σ2)p(w|a)dw=N(t|0,σ2I+φA-1φT)=(2π)-N/2|σ2I+φA-1φT|-1/2exp(-12tT(σ2I+φA-1φT)-1t)---(20)]]>因此权值向量w的后验概率分布p(w|t,α,σ2)可表示为:p(w|t,α,σ2)=p(t|w,σ2)p(w|α)p(t|α,σ2)=(2π)-(N+1)/2|Σ|-1/2exp(-12(w-μ)TΣ-1(w-μ))---(21)]]>其均值和方差分别为:μ=σ-2ΣφTt(22)Σ=(A+σ-2φTφ)-1(23)且A=diag(α0,α1,…,αN)。超参数a的后验概率分布p(α,σ2|t)无法由解析公式给出,而是通过一个delta函数近似表示:p(α,σ2|t)∝δ(αMP,σMP2)---(24)]]>最大化p(α,σ2|t)∝p(t|α,σ2)p(α)p(σ2)即可得出αMP和(αMP,σMP2)=argmaxa,σ2p(t|α,σ2)---(25)]]>其中,p(t|a,σ2)被称为边缘似然分布,表达式如式(20)所示。只需最大化该边缘似然分布就可以得到αMP和超参数优化:对式(20)两边取对数,可得超参数的对数似然分布为:lnp(t|a,σ2)=lnN(t|0,σ2I+φA-1φT)=-12{Nln(2π)+ln|σ2I+φA-1φT|+tT(σ2I+φA-1φT)-1t}---(26)]]>将上式分别对α和σ2求偏微分并令其等于0,得:αinew=γiμi2---(27)]]>(σ2)new=||t-φμ||2N-Σiγi---(28)]]>γi≡1-αi∑ii(29)其中,μi为后验概率分布均值μ=σ-2∑φTt的第i个权重;∑ii为后验概率分布方差∑=(A+σ-2φTφ)-1的第i个对角线元素。通过式(27)和(28)的迭代更新即可逼近αMP和实现超参数的优化求解。回归预测:通过最大化超参数似然分布找到其最优值aMP,后,则待测样本x*的预测值t*的概率分布表达式(18)可改写为:p(t*|t)=∫p(t*|w,α,σ2)p(w|t,α,σ2)p(α,σ2|t)dwdαdσ2≈∫p(t*|w,α,σ2)p(w|t,α,σ2)δ(α-αMP)δ(σ2-σMP2)dwdαdσ2=∫p(t*|w,σMP2)p(w|t,aMP,σMP2)dw---(30)]]>由于被积函数为两个Gauss分布函数的乘积,则式(30)可表示为:p(t*|t)=N(t*|y*,σ*2)---(31)]]>其中:式(31)和(32)即为RVM的回归预测模型。预测值t*的均值为方差为RVM模型稀疏性分析:由以上分析可知,RVM模型在贝叶斯框架下进行训练,利用先验概率分布知识为模型的每一个权值wi都配置了独立的超参数,这是稀疏贝叶斯模型最显著的特征,也是导致模型具有稀疏性的根本原因。下面从数学角度对RVM模型解的稀疏性进行分析。在超参数对数似然分布式(26)中,令C=σ2I+φA-1φT,其中A=diag(α0,α1,…,αN)。将C改写为:将αi中对回归有贡献的基向量分解出来,则C又可写为:由此可知:将上式(35)代入式(26)中,可得:其中的L(α-i)独立于超参数αi,且:令则:l(αi)=-12{-logαi+log(αi+si)-qi2αi+si}---(38)]]>将上式(38)对αi求偏导并令其等于0:dl(αi)dαi=αi-1si2-(qi2-si)2(αi+si)2---(39)]]>从而得到如下两种可能的解:αi=si2qi2-siqi2>siαi=∞qi2≤si---(40)]]>经过足够多次的迭代更新,大部分αi的解会趋近于∞,此时权值向量w的后验概率分布p(w|t,α,σ2)的方差∑和均值μ分别为:limαi→∞Σ=limαi→∞(A+σ-2φTφ)-1=0---(41)]]>由此可得:limαi→∞μ=limαi→∞σ-2ΣφTt=0---(42)]]>即当αi趋近于无穷大时,其对应的权值wi近似为0,相应的基函数矩阵项将会从中删除,这使得大部分的基函数矩阵项不会参与到实际的预测计算之中,而对于其它小部分趋于有限值的αi而言其对应的权值wi非0,这些少数非0权值所对应的样本向量被称为相关向量。相关向量代表数据中的原型样本,只与少部分训练样本有关,这是相关向量机具有高稀疏性的重要原因。基于混合核RVM的预测模型建立:RVM的超参数α和方差σ2的迭代更新公式以及模型的预测输出均与核函数有关,因此,在使用RVM模型进行预测时,首先需要选择一个有效的核函数进行映射处理,从而在映射的高维特征空间中进行非线性回归曲线的拟合。由于不同核函数具有不同的映射效果,这意味着采用不同的核函数可以得到不同的高维特征空间,因此预测模型性能的好坏很大程度上取决于核映射方式的选择。上文对RVM模型的描述采用的是单核映射方式,映射形式较单一,具有一定局限性。因此,本节在对混合核函数构造方法研究的基础上,提出一种基于混合核RVM的预测模型,并通过与SVR模型以及单核RVM模型的比较,验证该模型的有效性。混合核函数的构造:假设核函数由M个核线性组成,其中任意一个核km均对应某一Hilbert空间Hm及相应内积运算<·,·>m,对于dm∈[0,1],任一k(x,x)=dmkm(x,x)则对应某一Hilbert空间H'm,其内积运算为:<f,g>Hm′=1dm<f,g>m---(43)]]>有:f(x)=<f,km(·,x)>m=1dm<f,dmkm(·,x)>m=<f,dmkm(·,x)>Hm′---(44)]]>根据再生核的性质,可知H'm亦为再生核Hilbert空间。定义混合核的核空间H为H'm空间的直和,则核空间H也是定义在核函数(45)下的再生核Hilbert空间。混合核映射可以使数据信息在特征空间中得到更为充分的表示,有助于提高RVM的学习性能。混合核的组合形式为:k(xi,xj)=Σm=1Mdmkm(xi,xj)---(45)]]>式中,为混合核的权重系数,且目前常用的核函数大致有两种类型,一种是局部性(local)核函数,典型代表为RBF核函数、K型函数等;另一种是全局性(global)核函数,典型代表为多项式核函数(Poly核函数)、Sigmoid核函数等。局部核函数具有局部的特性,学习能力强,但泛化能力较弱;全局核函数具有全局的特性,泛化能力强,但学习能力较差。针对不同类型的输入样本,可以采用不同的核函数组合进行映射,从而充分利用各种核函数的映射特性,提高模型的预测精度。采用式(42)将局部性核函数和全局性核函数进行组合,得到的混合核函数如下:k(xi,xj)=mklocal(xi,xj)+(1-m)kglobal(xi,xj)0≤m≤1(46)以RBF核函数和Poly核函数为例进行说明。RBF核函数和Poly核函数表达式分别为:(1)Poly核函数:K(x,xi)=(xTxi+1)d(47)(2)RBF核函数:K(x,xi)=exp(-γ||x-xi||2),γ>0(48)图3-图5给出了Poly核函数和RBF核函数的特性曲线以及二者组合后的混合核函数特性曲线,其中测试点xi=0.25,混合核函数中的参数γ=40,d=2。从图3-图5中可以看出:1)对于RBF核函数而言,只有距离测试点较近的数据对核函数的值有影响,远离测试点的数据对核函数影响较小,说明RBF核函数学习能力强,但泛化能力弱;2)对于Poly核函数而言,距离测试点越远的数据对核函数值产生的影响越大,距离测试点越近的数据对核函数值的影响越小,说明Poly核函数泛化能力强,但学习能力弱;3)混合核函数同时具有RBF核函数和Poly核函数的特性,远离及靠近测试点的数据均对核函数的值产生了较大影响,说明泛化能力和学习能力均得到了提高。基于混合核RVM的预测模型:将式(45)的混合核函数代入RVM模型表达式(9)中,得到混合核RVM模型的输出为:y(x;w)=Σi=1NΣm=1Mwidmkm(x,xi)+w0ti=y(xi;w)+ϵi---(49)]]>同时对基函数矩阵进行更新,从而得到基于混合核的RVM预测模型。基于混合核RVM的预测模型如图6所示。将采集的装备原始数据划分为训练数据和测试数据两部分。模型描述如下:首先,将训练数据送入混合核RVM模型之中进行训练,通过混合核函数的构造将训练数据映射至高维特征空间之中,并采用式(27)和(28)对超参数a和噪声方差σ2进行迭代更新,求解最优权重分布,当达到收敛精度要求时,模型训练结束;然后,将测试数据送入训练好的混合核RVM模型之中进行预测,得到装备的预测输出数据;最后,将预测输出数据送入模糊SVDD状态评估模型之中进行评估,从而得到装备的健康度预测值。模型仿真分析:为验证基于混合核RVM预测模型的有效性,以某一连续函数y=sin(x)/x+0.1x,x∈[-15,15]为例进行仿真分析。利用该连续函数随机产生N=150的采样点并在输出数据上加入均值为0,方差为0.01的高斯噪声,将其作为训练样本对RVM模型进行训练;模型训练完成之后利用该函数再次产生150个测试点对模型进行测试。图7-图10给出了SVR模型以及多项式核、RBF核、混合核函数下的RVM模型预测结果,预测性能评价采用平均相对误差(MRE)指标进行衡量,对比结果如表1所示。其中混合核函数选择RBF核函数和多项式核函数的组合,其参数设置为:权重系数m=0.4,RBF核参数γ=4.5,多项式核参数d=4。表1预测结果对比从图7-图10和表1中可以看出:(1)混合核RVM预测曲线同函数的实际曲线吻合较好,表现出良好的预测能力;(2)混合核RVM无论从平均相对误差还是向量数目上,均要优于单核RVM(混合核RVM的平均相对误差为0.047217,向量数目仅为6);(3)同SVR相比,混合核RVM预测精度只是略有提高,但向量数目却大大减少,因此占用内存空间更少,性能也更优。应用实例:下面以某脉冲测量雷达中频接收组合中的压控振荡器为例,验证上述方法的有效性。压控振荡器的故障特征是渐变的,它是脉冲测量雷达中频接收组合的重要组成部分,其性能好坏直接影响雷达的正常工作。因此,为了减少由于压控振荡器故障引发的严重后果,对其健康状态进行预测是十分必要的。压控振荡器的正常输出为10MHz±1.8Hz,对其进行等间隔采样得到60个原始频率监测数据。其中,前50个用于训练,最后10个用于测试。原始频率监测数据如表2所示。表2原始频率监测数据选取表2中的前50个原始频率监测数据作为训练样本训练基于混合核RVM的预测模型,采用式(27)和(28)对超参数a和噪声方差σ2进行迭代更新,求解最优权重分布,当达到收敛精度要求时,模型训练结束;模型训练完成后对后10个原始频率监测数据进行预测,并与多项式核RVM、高斯核RVM、SVR预测模型进行仿真比较。混合核函数仍选用RBF核函数和多项式核函数的组合形式,其参数设置为:控制比例因子m=0.4,RBF核参数γ=0.8,多项式核参数d=2,噪声为0.1×randn(50,1),预测值同实际值比较曲线如图11所示。预测值与实际值的平均相对误差以及向量数目的比较结果如表3所示。表3预测结果对比从图11和表3中可以看出,混合核RVM预测精度明显高于高斯核和多项式核的,同SVR预测精度相近,但向量数目明显要少,解更加稀疏,占用内存更少,因此,选用混合核RVM对压控振荡器原始频率监测数据进行预测是行之有效的。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1